
렌더팜 GPU 벤치마크 방법론: 재현 가능한 프레임당 비용 측정법 (2026)
개요
소개
벤치마크 점수는 발표하기는 쉽지만 신뢰하기는 어렵습니다. 누구나 "RTX 5090: X점"이라고 발표할 수 있지만, 하나의 카드 대신 다른 카드에서 렌더링 작업을 실행할 가치가 있는지를 결정하는 수치는 합성 점수가 아니라 프레임당 비용입니다. 이 수치는 씬, 렌더 설정, 렌더링 엔진, 드라이버, 그리고 산술 방법에 따라 달라지는데, 리더보드 항목에는 이 중 어느 것도 거의 표시되지 않습니다.
이 페이지는 리더보드가 아닌 방법론을 다룹니다. Super Renders Farm에서 렌더팜 GPU를 벤치마크하는 방법을 문서화하여 결과가 의미 있도록 합니다: 벤치마크 씬을 선택하는 방법, 어떤 렌더 설정을 고정하는지, 하드웨어 매트릭스 전반에 걸쳐 무엇을 일정하게 유지하는지, 원시 프레임당 시간을 방어 가능한 프레임당 비용 수치로 변환하는 방법, 그리고 대부분의 문서가 생략하는 부분 — 제3자가 자체 하드웨어에서 전체 과정을 재현할 수 있는 명시적 단계들입니다. 이 방법의 결과물은 이미 발표했으며, 이것은 그 이면의 레시피입니다. 아래에 수치가 등장하는 경우, 해당 연구 중 하나에서 나온 실제 수치로서 재도출이 아닌 실제 예시로 인용됩니다.
합성 벤치마크 대 실제 프레임당 비용
GPU 벤치마킹에는 두 가지 계층이 있으며, 이를 혼동하는 것이 대부분의 혼란의 출발점입니다.
첫 번째는 합성 계층입니다: 하나의 고정된 씬을 렌더링하고 점수를 출력하는 표준화된 도구입니다. Cinebench R24, Chaos V-Ray Benchmark, OctaneBench가 모두 여기에 속합니다. 이들은 상대적인 순위 측정에 유용합니다 — 모든 머신에서 동일한 단일 반복 가능한 작업이므로 카드들을 나란히 비교할 수 있습니다. 이러한 점수를 읽는 방법은 V-Ray 벤치마크 가이드와 클라우드 렌더링용 Cinebench 점수 문서에서 설명합니다. 합성 점수가 의도적으로 제거하는 것은 실제 프로덕션에서 변동되는 모든 요소입니다: 지오메트리, 샘플링, 디노이저, 출력 해상도, 그리고 실제 큐가 처리하는 작업별 오버헤드.
두 번째는 프로덕션 계층입니다: 대표적인 실제 프레임이 실제로 얼마나 걸리는지, 그리고 그 비용은 얼마인지입니다. 이 방법론이 목표로 하는 계층이 바로 이것입니다. 합성 점수는 시작 추정치를 외삽하는 방법으로서 이에 대한 입력값이 되지만, 답 그 자체는 아닙니다. 두 계층 사이의 연결은 원칙적으로 간단합니다: 동일한 벤치마크 빌드에서 다른 머신보다 대략 두 배 점수를 받은 머신은 비슷한 프레임을 약 절반의 시간에 렌더링합니다. 이 추정 산술(효율 = 프레임 시간 ÷ 벤치마크 점수)은 V-Ray 가이드에서 설명합니다. 점수가 아닌 벤치마킹 방법의 요점은 그 외삽을 정직하게 만드는 것입니다 — 프로덕션에 가까운 씬에서 측정하고 중간값만이 아닌 분포를 보고하는 것입니다.
중요한 지표: 프레임당 비용
프레임당 비용은 방법론이 도달해야 하는 단위입니다. 이것이 렌더링 예산이 실제로 작성되는 단위이기 때문입니다. 공식은 간단합니다:
프레임당 비용 = 프레임당 벽시계 시간 × 노드 시간당 비용
프레임당 벽시계는 프레임 수로 나눈 작업 시간으로 측정됩니다 — 씬 로드, 가속 구조 빌드, 디바이스 조정을 제외하는 렌더링 엔진의 내부 "렌더 시간" 읽기가 아닙니다. 노드 시간당 비용은 어떻게 회계 처리하든 간에 하드웨어를 한 시간 동안 운영하는 데 드는 비용입니다. 당사 팜에서 GPU 렌더링은 OctaneBench-시간당 $0.003로 청구되며, 단일 RTX 5090 (32 GB)의 하드웨어 기준은 카드-시간당 약 $5.2입니다. 프레임당 비용 가이드와 가격 가이드에서 고객 대면 모델을 전반적으로 다룹니다.
두 입력값을 결합하는 것은 단순한 단위 산술입니다: 프레임당 벽시계 시간을 시간으로 변환하고 노드 시간당 비용을 곱하면, 프레임당 초와 시간당 달러가 프레임당 달러로 해결됩니다. 저렴한 노드에서의 짧은 프레임은 낮게, 비용이 높은 노드에서의 무거운 프레임은 높게 나옵니다. 이 방법론 페이지에서는 의도적으로 계산된 요금을 제외합니다 — 실제 비용은 씬 복잡도, 샘플링, 큐 대기, 적용하는 청구 모델에 따라 다르며, 프레임당 비용 가이드와 가격 가이드가 고객 대면 수치를 다루는 곳입니다. 여기서 요점은 공식이 감사 가능하다는 것입니다: 단위를 명시적으로 유지하면 누구나 그 수치를 믿음만으로 받아들이는 것이 아닌 확인할 수 있습니다.
합성 점수가 아닌 프레임당 비용이 핵심 지표인 이유: 두 카드가 벤치마크에서 비슷한 점수를 받더라도 씬에 따라 프레임당 비용이 크게 다를 수 있습니다. 씬이 각 프레임에서 병렬 처리 가능한 작업과 빠른 실리콘이 처리할 수 없는 고정 오버헤드의 비율을 결정하기 때문입니다.
벤치마크 씬과 렌더 설정
씬은 벤치마크가 프로덕션으로 전환되는지 여부에 가장 큰 영향을 미치는 요소이므로, 두 가지 종류를 의도적으로 실행합니다.
머신 간 순위를 위한 벤더 표준 씬. 목표가 공정한 사과 대 사과 비교일 때, 발표된 참조 씬을 사용합니다 — Blender의 Open Data 씬 (bmw27, classroom, junkshop), Redshift용 Maxon의 Vultures 씬, Chaos V-Ray Benchmark, OctaneBench. 이들은 반복 가능하고 독립적으로 검증 가능하며, 이것이 정확히 순위에 필요한 것입니다. 약점은 이들이 사용자의 씬이 아니라는 것이므로 절대적인 시간은 직접적으로 프로덕션으로 전환되지 않습니다.
프레임당 비용을 위한 프로덕션 대표 씬. 목표가 운영자가 계획할 수 있는 수치일 때, 씬은 실제 작업처럼 보여야 합니다 — 실제 지오메트리, 실제 텍스처 세트, 실제 샘플링, 실제 출력 해상도. 멀티 GPU 스케일링 연구에서 각 렌더가 안정적이고 신뢰할 수 있는 비율을 생성할 만큼 충분히 오래 지속되도록 Blender Cycles를 200% 해상도로 실행했습니다 — 이는 또한 원시 Cycles 시간이 공개 Open Data 점수와 비교할 수 없음을 의미합니다. 이 트레이드오프가 의도된 대로 작동하는 방법론입니다: 씬을 질문에 맞게 조정합니다.
씬에 관계없이 렌더 설정은 고정 및 기록되어야 합니다: 샘플 수(또는 노이즈 임계값), 디노이저 켜기/끄기 및 종류, 출력 해상도, 타일 또는 버킷 크기, 렌더링 엔진 빌드. 머신 간에 이 중 하나라도 다르다면 하드웨어가 아닌 차이를 측정하는 것입니다.
하드웨어 매트릭스
벤치마크 매트릭스는 그리드입니다: 테스트하는 카드가 한 축에, 렌더링 엔진과 씬이 다른 축에 있습니다. 엄격함은 그리드 전반에 걸쳐 일정하게 유지하는 것에 있습니다.
일정하게 유지: 운영 체제, 렌더링 엔진 버전과 빌드, 디노이저, 씬, 설정. 기록하지만 항상 일치시킬 수는 없는 것: GPU 드라이버 — 현재 세대 카드는 이전 카드가 실행할 수 없는 최신 드라이버가 필요할 수 있으므로 정확한 드라이버 일치는 불가능합니다. 그럴 경우 명시합니다. 멀티 GPU 연구에서 RTX 5090 노드는 드라이버 596.36으로, RTX 4090 노드는 610.62로 실행했으며, 이 차이가 세대 간 절대적 비교에만 영향을 미치고 노드 내 스케일링 비율(양쪽에서 동일한 카드와 드라이버 사용)에는 영향을 미치지 않는다고 명시했습니다.
당사 GPU 플릿은 VRAM 32 GB의 NVIDIA RTX 5090 카드로 표준화되어 있으며, 이것이 매트릭스를 내부적으로 일관되게 만드는 요소입니다 — 균일한 인벤토리는 한 노드의 추정치가 다음 노드로 전달됨을 의미합니다. 카드별 축의 실제 예시로, 멀티 GPU 연구에서 동일한 씬의 RTX 5090 대 RTX 4090 단일 카드 결과는 다음과 같습니다:
| 렌더링 엔진 / 씬 | 지표 | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | 초 (낮을수록 좋음) | 49.45 | 77.40 |
| Cycles — classroom | 초 | 23.09 | 36.87 |
| Redshift — Vultures | 초 | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (높을수록 좋음) | 15,333 | 9,608 |
| Octane | OctaneBench 점수 | 1,690.78 | 1,074.17 |
해당 테이블에는 두 가지 지표 유형이 나타납니다 — 초(낮을수록 좋음)와 벤치마크 점수(높을수록 좋음) — 이것이 절대 수치가 엔진 간에 비교되지 않는 이유입니다. 단일 엔진 내의 비율만이 공정한 비교입니다.
벤치마크를 신뢰할 수 있게 만드는 통제 요소
수치와 신뢰할 수 있는 수치의 차이는 통제 요소에 있습니다. 다음은 당사 방법론이 적용하는 통제 요소들입니다.
- GPU당 단일 작업. 당사 스케줄러는 카드당 하나의 렌더링 작업을 실행하므로, 모든 수치는 깔끔한 카드당 수치입니다 — 공유 디바이스에서 흐려진 평균이 아닌 용량을 계획하기 위해 곱하는 값입니다.
- 모든 비교를 위한 매칭 쌍. 프로덕션에서 하드웨어 세대를 비교했을 때, 씬은 양쪽에서 동일한 씬과 동일한 사용자가 실행했고, 자격을 갖추기 전에 각 측에 최소 세 개의 작업이 있어야 했습니다. RTX 5090 현장 연구에서 1,419개 작업 중 38개 씬이 그 기준을 통과했습니다 — 38은 데이터의 크기가 아니라 의도적으로 엄격한 필터를 통과한 것입니다.
- 윈도우당 하나의 드라이버. 현장 연구에서 단일 드라이버(581.80, CUDA 13.0)가 7주 전체 기간 동안 제로 변경으로 실행되었으므로, 윈도우 중간 스왑이 결과를 오염시킬 수 없었습니다.
- 디노이저 동등성. Cycles 작업의 약 83%가 새 세대와 이전 세대 하드웨어 모두에서 AI 디노이즈 패스를 실행했습니다 — 따라서 디노이저는 속도 향상 내부에 숨겨진 변수가 아닌 상수였습니다.
- 워밍업 대 콜드 스타트. 고정된 작업당 비용 — 씬 로드, 동기화, 가속 구조 빌드 — 은 짧은 프레임에서 더 큰 비율을 차지하며, 이것이 짧고 오버헤드 바운드된 프레임이 빠른 카드를 과소평가하는 이유입니다. 방법론은 하나의 배수를 가정하는 것이 아닌 분포를 보고함으로써 이를 처리합니다.
원시 시간에서 방어 가능한 수치로
시간이 수집되면, 통계가 헤드라인 수치가 정직한지를 결정합니다.
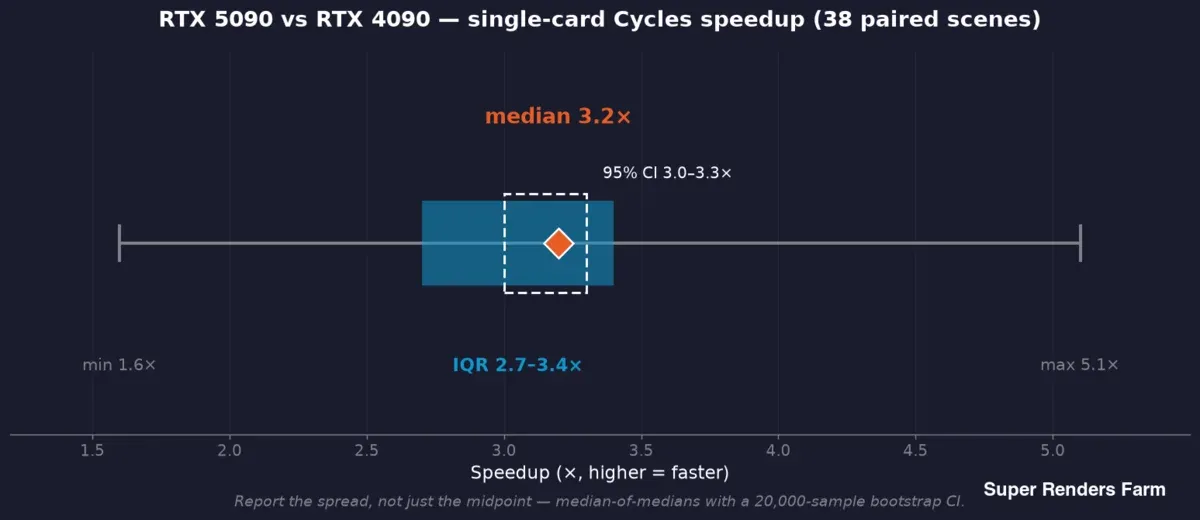
RTX 5090 대 RTX 4090 단일 카드 Cycles 속도 향상 38개 매칭 씬: 중앙값 3.2배, 95% 신뢰 구간 3.03.3배, 사분위 범위 2.73.4배, 전체 범위 1.6~5.1배
당사는 중앙값의 중앙값 방법을 사용합니다: 각 씬은 각 측면에서 자체 프레임당 시간의 중앙값을 제공하고, 헤드라인은 씬별 비율의 중앙값입니다 — 따라서 하나의 느린 프레임이 결과를 왜곡할 수 없습니다. 그 중간값 주변에 부트스트랩 신뢰 구간(현장 연구는 20,000샘플 부트스트랩을 사용하여 중앙값 3.2배 속도 향상 주변에 95% CI 3.03.3배를 제공함)과 분산도 — 사분위 범위 2.73.4배, 38개 씬에 걸쳐 전체 범위 1.6~5.1배를 보고합니다.
그 분산은 평균을 통해 제거할 노이즈가 아니라 결과 그 자체입니다. 3.2배의 일반적인 속도 향상과 1.6배의 최악의 경우 씬은 동시에 모두 사실이며, 중간점만 보고하는 벤치마크는 운영자에게 필요한 이야기의 절반을 숨깁니다. 당사가 고수하는 규칙: 중앙값 그리고 범위를 보고하고, 각 주장을 뒷받침하는 샘플과 연결합니다 — 38개 매칭 씬의 속도 향상, 57개 기록된 작업의 VRAM, 별도의 통제된 벤치 실행의 전력, 하나의 샘플이 다른 것을 지원하기 위해 빌려지지 않습니다.
이 벤치마크를 재현하는 방법
이것이 벤치마크를 마케팅 문구가 아닌 획득 가능한 신호로 만드는 부분입니다: 누구나 실행할 수 있습니다. 아래 단계는 모든 큐 또는 테스트 벤치에서 이 방법을 재현합니다.
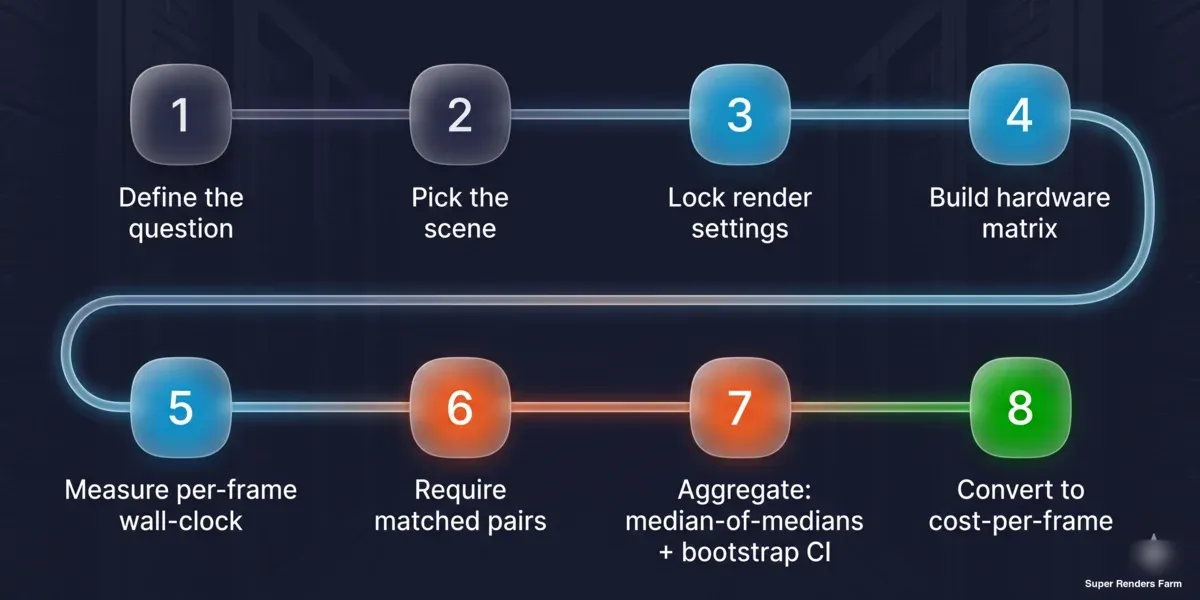
8단계 재현 가능한 프레임당 비용 벤치마크 방법: 질문 정의, 씬 선택, 렌더 설정 고정, 하드웨어 매트릭스 구성, 프레임당 벽시계 측정, 매칭 쌍 요구, 중앙값의 중앙값 및 부트스트랩 신뢰 구간으로 집계, 프레임당 비용으로 변환
- 질문을 정의합니다. 목표가 머신 간 순위입니까, 아니면 프로덕션 프레임당 비용입니까? 답이 씬 유형을 결정합니다 — 순위는 벤더 표준, 비용은 프로덕션 대표.
- 씬과 설정을 고정합니다. 샘플 수 또는 노이즈 임계값, 디노이저 선택, 출력 해상도, 타일/버킷 크기, 렌더링 엔진 빌드를 고정합니다. 기록해 두십시오; 이것들은 결과의 일부입니다.
- 매트릭스를 구성합니다. 한 축에 카드를, 다른 축에 엔진/씬 조합을 나열합니다. 일정하게 유지되는 것(OS, 엔진 빌드, 디노이저, 씬)을 결정하고 유지할 수 없는 것(드라이버)을 기록합니다.
- 프레임당 벽시계를 측정합니다. 스케줄러의 작업 시간 ÷ 프레임 수 또는 전체 작업에 대한 스톱워치를 사용합니다 — 로드와 빌드 오버헤드를 생략하는 렌더링 엔진의 내부 렌더 시간 읽기가 아닙니다.
- 매칭 쌍과 최소 샘플을 요구합니다. A 대 B 주장의 경우, 양쪽에서 동일한 씬을 실행하고, 결과가 인정되기 전에 각 측에 최소 세 개의 작업을 실행합니다.
- 중앙값의 중앙값으로 집계합니다. 각 측의 씬 중앙값을 취한 다음, 씬별 비율의 중앙값을 취합니다. 부트스트랩 신뢰 구간을 계산하고 함께 사분위 범위와 전체 범위를 보고합니다.
- 프레임당 비용으로 변환합니다. 측정된 프레임당 시간에 노드 시간당 비용을 곱합니다. 수치가 감사 가능하도록 단위를 명시적으로 유지합니다.
- 수치와 함께 주의 사항을 게시합니다. 각 주장 뒤의 샘플 크기, 드라이버 상황, 데이터가 관찰적인지 통제된 것인지, 그리고 적용되고 적용되지 않는 범위를 명시합니다.
자체 하드웨어에서 이 8단계를 실행하는 스튜디오는 방어할 수 있는 수치를 얻게 됩니다 — 그리고 방법론을 게시하는 전체 요점인 당사 수치와 비교할 수 있습니다.
정직성 참고 사항: 벤치마크가 주장할 수 있는 것과 없는 것
방법론은 거부하는 주장만큼만 신뢰할 수 있습니다. 당사가 지키는 세 가지 경계선입니다:
관찰적인 것은 통제된 것이 아닙니다. 프로덕션 현장 데이터 — 사용자가 정상적인 업무 과정에서 실행한 작업 — 는 실제적이고 유용하지만, 사용자는 재렌더링 사이에 자신의 씬을 조정하므로 관찰적입니다. 깔끔한 동일 호스트 직접 비교(예를 들어, 동일한 하드웨어에서 RTX 5090 대 현재 RTX 4090)는 별도의 통제된 실험입니다. 하나가 다른 것인 척하도록 허용하지 않습니다.
노드 대 노드 비교는 실리콘뿐만 아니라 설정을 포함합니다. 한쪽이 베어 메탈로, 다른 쪽이 가상화로 실행될 때, 측정된 차이의 일부는 칩이 아닌 설정입니다. 이것은 각주가 아닌 헤드라인 주의 사항에 속합니다.
측정하지 않은 수치는 없습니다. 벤치마크하지 않은 전력이나 열 수치는 외삽하지 않습니다. 현장 연구에서 카드당 약 360~375W를 보고하는 경우, 이는 지속적인 부하 하의 통제된 벤치 실행에서 나온 것이며 — 거기서 파생된 프레임당 에너지 수치는 측정값이 아닌 추론으로 표시됩니다. 수치가 측정되지 않았다면, 방법론은 그것을 만들어내지 않습니다. 이 엄격함이 발표된 벤치마크를 전혀 인용할 수 있는 이유입니다.
당사 팜의 실제 예시
이 방법론은 아래 연구들을 생성했습니다; 각각은 레시피와 함께 읽을 수 있는 데이터셋이며, 실제 수치를 여기서 재도출하는 것이 아닌 확인하는 곳입니다.
| 연구 | 방법론이 생성한 것 | 샘플 |
|---|---|---|
| 멀티 GPU 스케일링 | 벤더 표준 씬에서 엔진별 1x→2x 스케일링 | 2개 노드, 4개 엔진, 7개 씬/벤치마크 조합 |
| RTX 5090 현장 기록 | 프로덕션 비용/속도 향상 분포, VRAM 백분위수 | 38개 매칭 씬 / 1,419개 작업, 7주 |
| V-Ray 벤치마크 가이드 | 합성 점수에서 렌더 시간 추정 | 참조 테이블 + 실제 추정치 |
| 클라우드 렌더링용 Cinebench | 하드웨어 티어에 대한 합성 점수 해석 | 참조 점수 |
동일한 접근 방식이 당사 GPU 클라우드 렌더팜에서 용량을 계획하는 방법의 기반이 되며, Blender 관련 수치는 Blender 클라우드 렌더링 작업에 사용됩니다 — GPU는 당사 전체 작업 믹스의 소수를 차지하며(대부분의 팜 작업은 여전히 CPU 렌더링), 따라서 이 GPU 수치를 정확히 그것으로 범위를 지정하며 팜 전반의 주장으로 삼지 않습니다.
FAQ
Q: 렌더팜 GPU를 벤치마크하는 올바른 방법은 무엇입니까? A: 먼저 머신 간 순위를 원하는지 프로덕션 프레임당 비용을 원하는지 결정합니다. 순위의 경우, 반복 가능한 벤더 표준 씬과 고정된 벤치마크 빌드를 사용합니다. 프레임당 비용의 경우, 프로덕션 대표 씬을 사용하고, 프레임당 벽시계(작업 시간 ÷ 프레임 수)를 측정하고, 노드 시간당 비용을 곱합니다. 렌더 설정을 고정하고 단일 수치가 아닌 분포를 보고합니다.
Q: 왜 프레임당 비용이 벤치마크 점수보다 더 나은지요? A: 합성 점수는 프로덕션에서 변동되는 모든 것을 제거합니다 — 지오메트리, 샘플링, 디노이저, 해상도 — 따라서 두 카드가 비슷한 점수를 받더라도 씬에서의 실제 프레임당 비용은 다를 수 있습니다. 프레임당 비용은 렌더링 예산이 실제로 작성되는 단위이며, 이것이 방법론이 리더보드 포인트가 아닌 이것으로 귀결되어야 하는 이유입니다.
Q: 벤치마크 점수를 렌더 시간 추정치로 어떻게 변환합니까? A: 점수 비율을 대략적인 속도 비율로 사용합니다: 동일한 벤치마크 빌드에서 다른 것보다 두 배 점수를 받은 머신은 비슷한 프레임을 약 절반의 시간에 렌더링합니다. 머신의 효율성을 프레임 시간을 벤치마크 점수로 나눈 값으로 계산한 다음, 목표 머신의 점수로 스케일링합니다. 벤치마크 빌드를 일정하게 유지하십시오, 다른 빌드의 점수는 비교할 수 없습니다.
Q: GPU 벤치마크를 신뢰할 수 있게 만드는 통제 요소는 무엇입니까? A: 깔끔한 카드당 수치를 위해 카드당 단일 렌더링 작업을 실행하고, 매칭 쌍을 요구하며(양쪽에서 동일한 씬, 결과가 인정되기 전에 최소 작업 수), 측정 윈도우 내에서 드라이버와 엔진 빌드를 일정하게 유지하고, 비교 전반에 걸쳐 디노이저 설정을 동일하게 유지합니다. 그런 다음 중앙값의 중앙값으로 집계하고 신뢰 구간과 범위를 보고합니다.
Q: 신뢰할 수 있는 결과를 위해 테스트 씬이 몇 개 필요합니까? A: 느슨하게 통제된 많은 씬보다 고품질 매칭 쌍이 더 낫습니다. 당사 프로덕션 연구에서 1,419개 작업 중 38개 씬이 엄격한 포함 필터(양쪽 하드웨어에서 동일한 씬과 사용자, 각 측에 최소 세 개의 작업)를 통과했습니다. 중요한 샘플 크기는 필터를 통과한 것이지 원시 작업 수가 아닙니다 — 그리고 둘 다 보고해야 합니다.
Q: 귀사의 렌더팜 GPU 벤치마크를 직접 재현할 수 있습니까? A: 네 — 그것이 의도입니다. 씬과 설정을 고정하고, OS, 엔진 빌드, 디노이저를 일정하게 유지하는 하드웨어 매트릭스를 구성하고, 프레임당 벽시계를 측정하고, 매칭 쌍을 요구하고, 부트스트랩 신뢰 구간과 함께 중앙값의 중앙값으로 집계하고, 프레임당 비용으로 변환하고, 수치와 함께 주의 사항을 게시합니다. 위의 8가지 재현 단계가 전체 순서를 설명합니다.
Q: 왜 하나의 속도 향상 수치 대신 범위를 보고합니까? A: 범위가 결과의 일부이기 때문입니다. 동일한 하드웨어가 짧고 오버헤드 바운드된 씬에서 1.6배, 무거운 컴퓨팅 바운드 씬에서 5배 이상의 이득을 보일 수 있습니다. 고정된 프레임당 오버헤드가 짧은 렌더에서 더 큰 비율을 차지하기 때문입니다. 중간값만 보고하면 운영자가 용량을 계획하는 데 필요한 변동성이 숨겨지므로, 중앙값, 사분위 범위, 전체 범위를 함께 발표합니다.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



