
생산 환경의 RTX 5090: 7주간의 렌더팜 현장 노트 (38개 씬 연구)
개요
RTX 5090의 출시 벤치마크는 이미 1년이 넘었으며, 모두 동일한 조건을 묘사합니다. 하나의 카드, 하나의 준비된 씬, 이상적인 환경. 그러나 거의 아무도 그 이후의 이야기를 공개하지 않습니다. 이 카드가 실제 프로덕션 대기열에 투입되어, 스케줄을 제어할 수 없는 상황에서 다른 사람들의 씬을 렌더링할 때 어떤 성능을 보이는지 말입니다. 그래서 저희가 로그를 꺼냈습니다. 이하 내용은 대기열 수준의 현장 노트입니다. 저희가 실제로 용량 계획에 활용하는 프로덕션 데이터를 그대로 수치로 정리했습니다.
7주간의 기록입니다. 2026년 4월 1일부터 5월 22일까지 — 51일 동안 — 저희는 듀얼 RTX 5090 노드 한 대를 실제 렌더팜에 투입하여 대기열이 배정하는 작업을 그대로 처리하도록 했습니다. 스테이지 테스트 없이, 선별된 프레임 없이. 아래의 짧은 영상에서 주요 수치를 확인하실 수 있으며, 이후 전체 현장 노트가 이어집니다.
노드 자체의 구성은 평범합니다. RTX 5090 2장, RAM 128 GiB, 4.3 GHz 클럭의 논리 코어 32개, Windows 11. 모든 수치를 형성하는 핵심 사항이 하나 있습니다. 스케줄러는 GPU당 렌더링 작업을 하나씩만 실행하므로, 각 카드는 독립적인 작업을 렌더링하며 모든 수치는 카드 단위의 순수한 수치입니다. 용량을 계획할 때 곱하는 바로 그 수치입니다. 이 기간 동안 노드는 전체 작업의 99.6%를 완료했습니다. 약 4,900건 중 4,890건을 완료하고 18건이 실패했습니다. 스케줄러는 실패 상태를 기록하지만 원인은 기록하지 않으므로, 원인에 대해서는 추측하지 않겠습니다.
핵심 수치
- 기간: 2026년 4월 1일 – 5월 22일 (51일, 약 7주), 듀얼 RTX 5090 노드 1대
- 완료율: 99.6% — 약 4,900건 중 4,890건 완료, 18건 실패 (원인 미기록)
- 속도 향상: 이전 세대 RTX 3080/2080급 노드 대비 Blender Cycles 프레임당 중앙값 3.2배 (프레임당 중앙값 시간 약 69% 단축); 95% CI 3.0–3.3x
- 분산: IQR 2.7–3.4x, 38개 대응 씬 전체 범위 1.6x–5.1x — 하나의 배수값으로 대기열 전체를 설명할 수 없습니다
- AI 디노이징: Cycles 작업의 약 83%에서 AI 디노이징 패스를 실행했으며, 구세대 하드웨어에서의 비율과 동일합니다
- VRAM: 중앙값 5.6 GB, 90번째 백분위수 11.5 GB, 최대 작업 약 37 GB
- 드라이버: 전체 기간 동안 드라이버 하나(581.80 / CUDA 13.0)만 사용, 교체 없음
- 전력: 부하 시 카드당 약 360–375 W (제어 벤치 기준), 최대 약 400 W, 68–83 °C — 정격 등급 약 575 W보다 훨씬 낮은 수준
38개 대응 씬이 보여주는 것
저희가 가장 신뢰하는 비교는 합성 테스트가 아니라, 정상적인 비즈니스 과정에서 두 세대 모두에서 실행된 작업입니다. 동일한 씬, 동일한 사용자, 씬이 집계에 포함되기 위해서는 각 세대에서 최소 세 건의 작업이 필요했습니다. 프레임당 시간은 대기열에서 직접 추출한 작업 경과 시간을 프레임 수로 나눈 값입니다. 이 기간 동안 해당 기준을 충족한 씬은 38개로, 총 1,419건의 개별 렌더링 작업(5090 노드 503건, 이전 세대 916건)에서 추출했습니다. 38이라는 수는 데이터 전체의 규모가 아니라, 의도적으로 엄격한 필터를 통과한 결과입니다.
| 지표 | 수치 |
|---|---|
| 프레임당 중앙값 속도 향상 | 3.2x (시간 약 69% 단축) |
| 부트스트랩 95% CI (중앙값) | 3.0–3.3x |
| 사분위 범위 | 2.7–3.4x |
| 전체 범위 | 1.6–5.1x |
| 씬 수 / 작업 수 | 38개 씬 / 1,419건 |
| 기준선 | 이전 세대 RTX 3080/2080급 (10–12 GB) |
저희는 중앙값의 중앙값을 사용합니다. 각 씬은 양쪽 세대에서의 프레임당 시간 중앙값을 제공하며, 3.2x는 38개 비율의 중앙값입니다. 따라서 하나의 느린 프레임이 결과를 왜곡할 수 없습니다. 중간값만큼이나 분산도 중요합니다. 씬의 절반은 2.7x에서 3.4x 사이에 위치하며, 전체 범위는 1.6x에서 5.1x입니다.
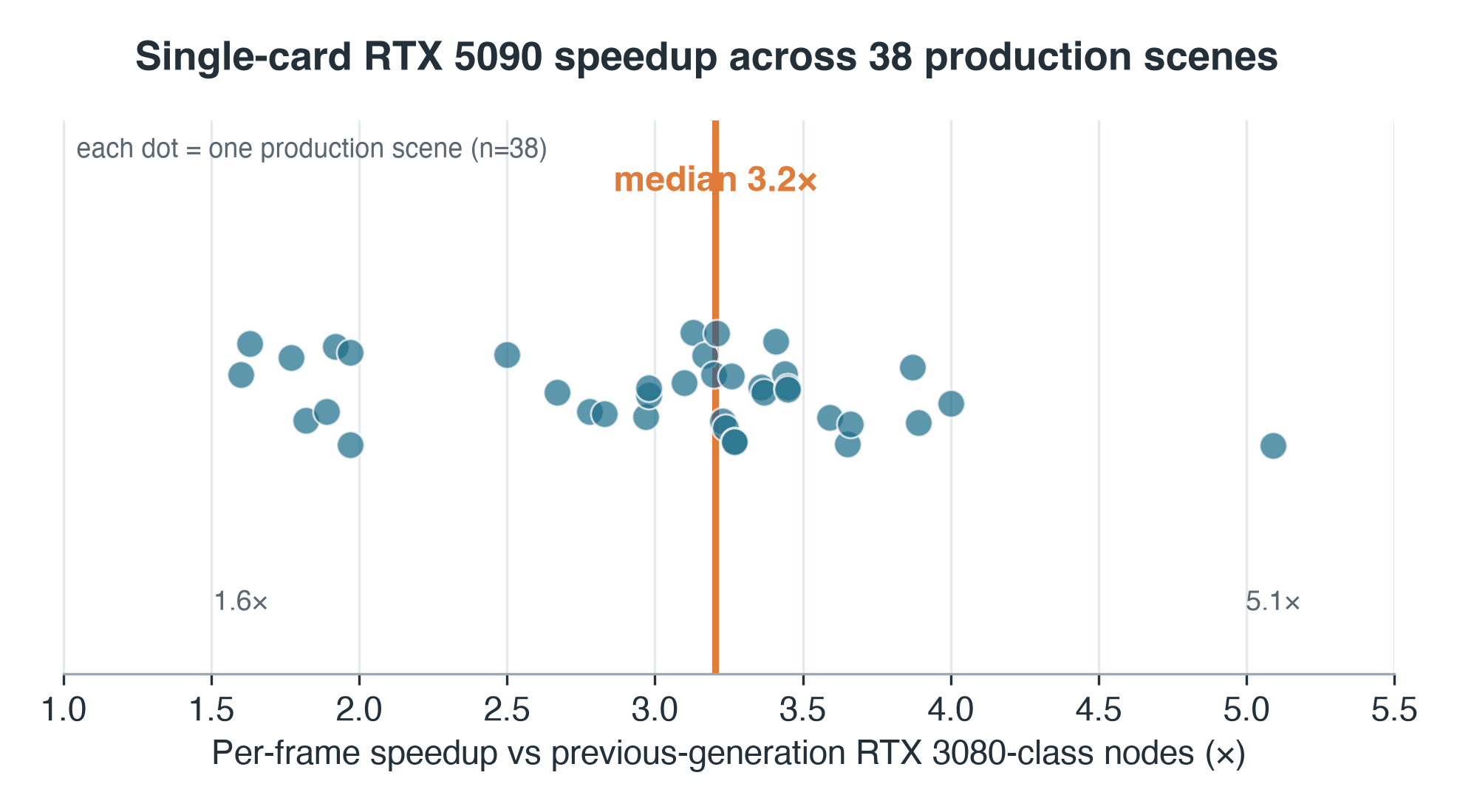
38개 Blender Cycles 프로덕션 씬에 걸친 RTX 5090 씬별 속도 향상, 중앙값 3.2x, 범위 1.6x ~ 5.1x
씬별 속도 향상, RTX 5090 대 이전 세대 노드 — 38개 씬 프로덕션 샘플. 중앙값 3.2x; 범위 1.6–5.1x.
이 수치에는 각주가 아닌 본문에서 언급해야 할 두 가지 주의 사항이 있습니다. 첫째, 이전 세대 측은 가상화 환경에서 실행되었습니다. VM 내 GPU 패스스루 방식이므로, 이 3.2x의 일정 부분은 가상화 오버헤드이지 순수한 실리콘 차이가 아닙니다. 동일한 호스트에서 RTX 5090과 현재 세대 RTX 4090을 직접 비교하는 것은 아직 수행하지 못한 후속 과제입니다. 둘째, 38개 씬은 대기열의 무작위 추출이 아닙니다. 사용자가 두 세대 모두에서 재렌더링한 작업들로, 더 길고 반복적인 작업 쪽으로 샘플이 편향되어 있습니다. 따라서 이 분포는 전체 대기열이 아닌 대응 쌍의 분포로 이해하시기 바랍니다.
세 가지 솔직한 사항은 핵심적입니다. 이것은 관찰 데이터입니다. 사용자는 재렌더링 사이에 설정을 조정하기도 하며, 저희는 씬을 고정하지 않았습니다. 비교는 노드 대 노드 방식입니다. 5090 측은 베어메탈 카드 하나이고, 이전 세대 측은 가상 머신 내 GPU 패스스루로 실행됩니다. 따라서 격차의 일부는 설정 차이이지 실리콘 차이가 아닙니다. 기준선은 실제로 이 작업들이 실행된 RTX 3080/2080급 카드입니다. 현재 세대 RTX 4090과의 비교가 아닙니다. 순수한 현재 세대 비교는 별도의 통제된 실험이 필요합니다. 이 수치들은 단일 노드, Cycles 전용 수치이며, 저희 대기열을 설명하는 것으로, 다른 엔진이나 하드웨어로 일반화해서는 안 됩니다.
1.6x 씬과 5.1x 씬의 차이는 데이터에서 부분적으로 확인할 수 있습니다. 씬별 속도 향상을 구세대 하드웨어에서의 프레임 소요 시간과 비교하면 느슨한 양의 상관관계가 나타납니다. Spearman ρ ≈ 0.34 (양측 검정 p ≈ 0.04). 짧고 오버헤드 지배적인 프레임은 하단에 위치합니다. 프레임이 5초 만에 완료되는 경우, 씬 로드, 동기화, 구세대 가상화 레이어와 같은 고정 작업 비용이 대부분의 시간을 차지하므로 더 빠른 카드가 실제로 기여할 여지가 거의 없습니다. 더 무거운 연산 집약적 프레임에서는 더 많은 이득을 얻습니다. 그러나 실제 분산이 존재합니다. 한 무거운 씬은 GPU가 아닌 스토리지 또는 CPU 병목으로 인해 1.6x에 머물렀습니다. 중앙값은 한 가지를 말하고, 범위는 씬에 따라 다르다는 것을 말합니다.
AI 디노이징은 이미 기본값이었습니다
2026년 프로덕션 렌더링 파이프라인에서 AI가 실제로 어디에 위치하는지 묻는다면, 저희 로그는 평범한 답을 줍니다. 바로 디노이저입니다. 5090 노드의 Cycles 작업 약 83%에서 AI 디노이징 패스가 실행되었습니다. OptiX 또는 Intel Open Image Denoise를 사용했으며, 이전 세대 노드에서의 비율과 사실상 동일합니다. 새 카드가 이 관행을 시작한 것이 아닙니다. 구세대 하드웨어에서 이미 표준이었고, 신세대 하드웨어에서도 그대로 표준입니다. 디노이징 집약적 파이프라인의 경우, 세대 전환으로 이미 사용 중이던 "AI"를 새로 얻는 것이 아닙니다. 이미 일상적인 단계 주변의 경로 추적 처리량을 구입하는 것입니다. 이 수치는 의도적으로 Cycles로 범위를 제한했습니다. 하나의 엔진에 묶이지 않은 팜 전체 "AI %" 수치에 대해서는 회의적으로 접근하시기 바랍니다.
실제 환경의 VRAM
Cycles는 렌더 로그에 피크 디바이스 메모리 수치를 기록합니다. 이는 프로덕션이 VRAM에 실제로 무엇을 요구하는지 파악할 수 있는 간단하지만 유용한 지표입니다. 해당 줄이 기록된 57개의 Cycles 작업에 걸쳐, 피크 렌더 디바이스 메모리는 중앙값 약 5.6 GB, 90번째 백분위수 약 11.5 GB였습니다. 이전 세대 카드는 10–12 GB 제품이므로, 중앙값 작업은 충분히 수용 가능했지만 90번째 백분위수 작업은 이미 한계에 근접하고 있었습니다. 그리고 꼬리는 더 멀리 뻗어 있습니다. 가장 무거운 작업은 약 37 GB를 기록했으며, 이는 5090의 자체 32 GB를 초과합니다. GPU에서는 CPU 폴백이나 렌더링 불가를 의미하는 종류의 씬입니다. 로그에는 씬 메타데이터가 없으므로 어떤 종류의 씬인지는 알 수 없습니다. 다만 그 클래스는 알 수 있습니다. 37 GB 작업 집합은 무거운 지오메트리, 고해상도 텍스처 세트, 또는 볼류메트릭의 특징입니다. 32 GB 카드조차 감당하지 못하는 종류의 작업이며, 단일 GPU에서는 그냥 중단됩니다. 운영 원칙은 여전히 유효합니다. VRAM은 중앙값이 아닌 꼬리를 기준으로 크기를 결정해야 합니다. 그것이 카드에 대용량 온보드 메모리와 공유 GPU 클라우드 렌더팜 용량이 모두 존재하는 이유입니다. 작업별로 더 큰 카드를 선택할 수 있도록 말입니다.
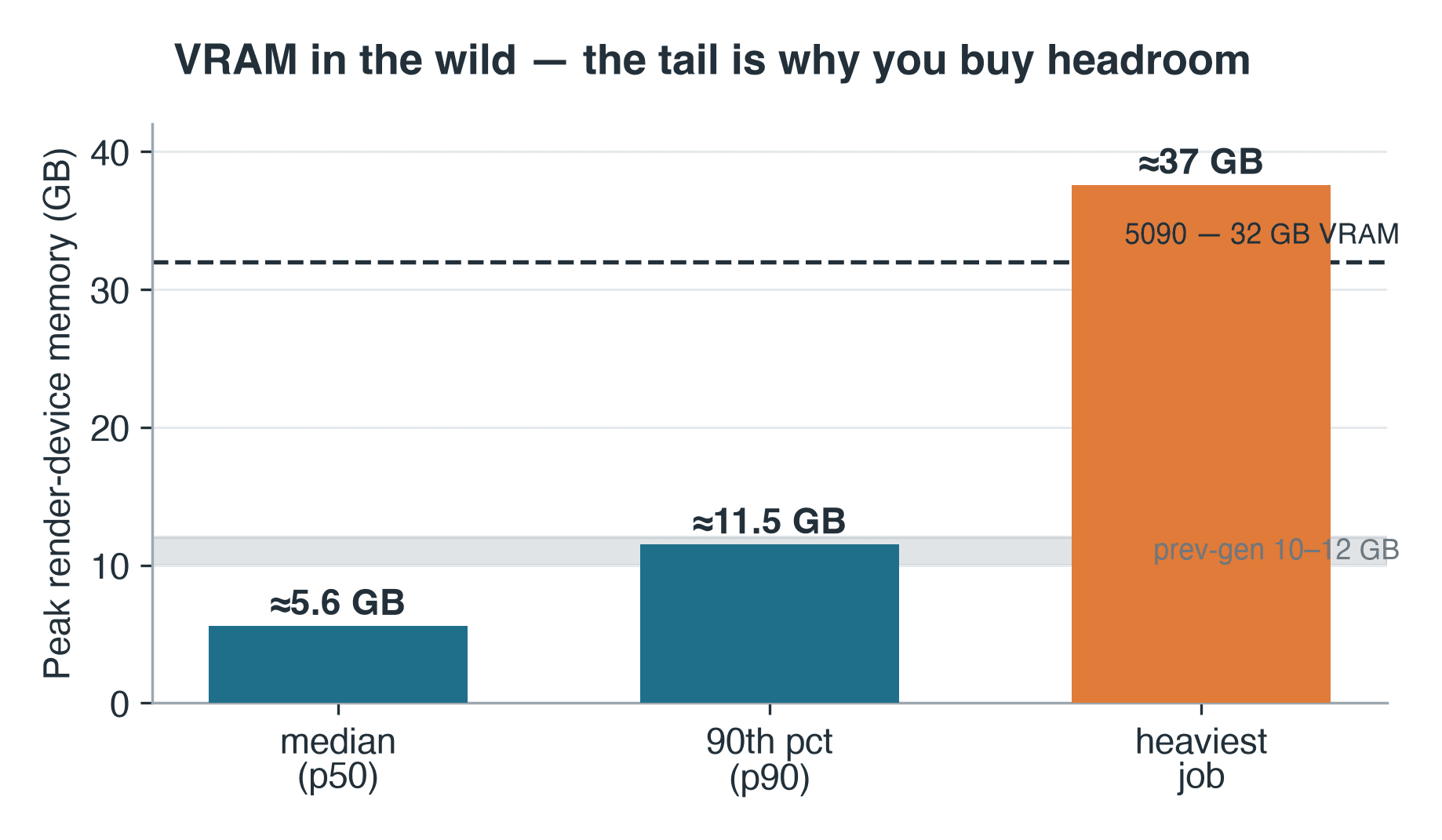
RTX 5090 노드에서의 Blender Cycles 작업 피크 렌더 디바이스 메모리: 중앙값 5.6 GB, 90번째 백분위수 11.5 GB, 최대 37 GB
57개 기록된 Cycles 작업의 피크 렌더 디바이스 메모리. 가장 무거운 작업은 5090의 자체 32 GB를 초과했습니다.
하나의 드라이버, 안정적인 전력
가장 드라마틱하지 않은 발견이 구매 전 가장 알고 싶었던 정보입니다. 드라이버 하나 — CUDA 13.0의 581.80 — 가 51일 전체 기간 동안 교체 없이 실행되었습니다. 롤백 없음, 중간 교체 없음. 프로덕션 대기열에 투입된 출시 초기 하드웨어에 있어 지루한 드라이버 로그는 최고의 칭찬입니다.
전력도 마찬가지로 안정적이었습니다. 동일한 카드를 지속 부하 하에 제어 벤치에서 실행했을 때, 각 카드는 68–83 °C에서 약 360–375 W를 소비했으며(최대 약 400 W에 근접) — 적층 쌍에서 상단 카드가 가장 뜨거웠지만 정격 등급 약 575 W보다 훨씬 낮은 수준이었습니다. 정격 최대값이 아닌 지속 소비량을 기준으로 예산을 책정하시기 바랍니다. 완성된 프레임당 에너지는 약 24초의 중앙값 Cycles 프레임 기준 대략 2.5 Wh에 해당합니다. 다만 이는 추론값으로, 벤치 소비량 기반으로 5090만을 위해 산출한 것이며 구세대 노드와의 측정 비교는 아닙니다.
이 노트가 Blender로 시작하는 이유
최근 90일 기준으로 GPU 작업은 저희 팜 전체 렌더링 작업의 약 4분의 1을 차지하며, 나머지는 CPU 작업입니다. GPU 작업 중에서 Cycles가 약 74%를 차지하고 Redshift가 약 15%로 그 뒤를 잇습니다. 이것이 렌더팜 RTX 5090 리뷰가 Blender 클라우드 렌더링을 중심으로 시작하는 이유입니다. 이 카드들이 함께 작동할 때의 동작에 대해서는 RTX 5090 클러스터 성능에 관한 동반 노트를 확인하시고, 메모리 한계에 관해서는 복잡한 씬에서 VRAM 한계가 미치는 영향을 참고하시기 바랍니다.
이 대기열에서 두 가지 결론을 도출할 수 있습니다. 첫째, 프로덕션은 벤치마크가 아닙니다. 깔끔한 실험실 수치를 기록한 카드도 가상화 오버헤드, 혼합 작업 부하, 최적화되지 않은 씬을 처리해야 하며, 결과는 하나의 점이 아닌 분포입니다. 둘째, 중앙값은 꼬리가 아닙니다. 3.2x의 일반적인 속도 향상과 단일 작업 37 GB 메모리 스파이크는 동시에 모두 사실이며, 용량 계획은 두 가지 모두를 기준으로 해야 합니다. 이 카드는 작업이 무거운 곳에서 진정으로 빠릅니다. 그렇지 않은 곳에서는 대기열이 그 이유를 알려줍니다.
방법, 간략히
여기서 제시한 모든 수치는 스테이지 테스트가 아닌 스케줄러의 자체 작업 기록에서 가져온 것입니다. 프레임당 시간은 작업 경과 시간을 프레임 수로 나눈 값이며, 헤드라인 속도 향상은 38개 대응 쌍에 걸친 씬별 중앙값의 중앙값이고, 신뢰 구간은 20,000샘플 부트스트랩입니다. 어떤 샘플이 어떤 주장을 뒷받침하는지 확인하시기 바랍니다. 속도 향상에는 38개 대응 씬, VRAM에는 57개 기록된 작업, 전력과 열에는 별도의 제어 벤치 실행 — 프로덕션 대기열이 아닙니다. 실패한 18건의 작업(약 4,900건 중)은 실패로 집계하며 제외하지 않습니다. 스케줄러는 상태를 기록하지만 원인은 기록하지 않으므로, 원인을 추측하지 않고 그대로 둡니다. 이 내용은 정신적으로 재현하기 어렵지 않습니다. 운영자라면 자신의 대기열 로그에서 똑같이 추출할 수 있으며, 특정 스튜디오와 방법론을 더 자세히 공유하는 것도 기꺼이 하겠습니다.
FAQ
Q: RTX 5090은 Blender Cycles에서 이전 세대보다 얼마나 빠릅니까? A: 38개의 대응 프로덕션 씬(두 세대 모두에서 동일한 씬과 사용자)을 기준으로, 프레임당 중앙값 시간이 약 69% 단축되었으며, 부트스트랩 95% 신뢰 구간 3.0–3.3x의 중앙값 3.2배 속도 향상을 보였습니다. 개별 씬은 1.6x에서 5.1x 범위였습니다. 이는 관찰 데이터이며 통제된 벤치마크가 아닌 노드 대 노드 데이터입니다.
Q: 씬별로 속도 향상이 왜 이렇게 차이가 납니까? A: 속도 향상은 프레임당 작업 부하와 느슨한 양의 상관관계를 보입니다(Spearman ρ ≈ 0.34). 짧고 오버헤드 지배적인 프레임은 씬 로드, 동기화, 구세대 가상화 레이어와 같은 고정 작업 비용이 지배하므로 가장 적은 이득을 얻습니다. 더 무거운 연산 집약적 프레임은 더 많은 이득을 얻습니다. 한 무거운 씬이 1.6x에 머문 것은 GPU가 아닌 스토리지 또는 CPU 단계가 병목이었기 때문입니다.
Q: 이것이 제 하드웨어와 비교할 수 있는 통제된 벤치마크입니까? A: 아닙니다. 이것은 하나의 실제 프로덕션 노드, Blender Cycles 전용의 관찰 현장 노트입니다. 사용자들이 재렌더링 사이에 씬을 조정했으며, 비교는 노드 대 노드 방식입니다. 베어메탈 5090과 가상화된 이전 세대 노드를 비교하므로, 격차의 일부는 설정 차이이지 실리콘 차이가 아닙니다. 기준선은 현재 세대 RTX 4090이 아닌 RTX 3080/2080급 하드웨어입니다.
Q: 프로덕션 씬에서 실제 VRAM 사용량은 얼마나 됩니까? A: 57개의 기록된 Cycles 작업에 걸쳐, 피크 렌더 디바이스 메모리는 중앙값 약 5.6 GB, 90번째 백분위수 약 11.5 GB였습니다. 가장 무거운 단일 작업은 약 37 GB를 기록했으며, 이는 5090의 자체 32 GB를 초과합니다. GPU에서는 CPU 폴백이나 렌더링 불가를 의미합니다. VRAM 크기는 중앙값이 아닌 꼬리를 기준으로 결정하시기 바랍니다.
Q: RTX 5090이 AI 디노이징 사용 빈도를 변화시켰습니까? A: 아닙니다. 5090 노드의 Cycles 작업 약 83%에서 AI 디노이징 패스(OptiX 또는 Intel Open Image Denoise)를 실행했으며, 이전 세대에서의 비율과 사실상 동일했습니다. AI 디노이징은 이미 표준이었으며, 새 카드는 그 주변 모든 것의 속도만 변화시켰습니다.
Q: 7주 동안 드라이버 안정성은 어떠했습니까? A: 드라이버 하나 — CUDA 13.0의 581.80 — 가 51일 전체 기간 동안 교체 없이 실행되었습니다. 롤백 없음, 중간 교체 없음. 프로덕션 대기열에 투입된 출시 초기 하드웨어에 있어 그 안정성은 그 자체로 의미 있는 결과입니다.
Q: 부하 시 전력 소비와 온도는 어떠했습니까? A: 지속 부하 하에 제어 벤치를 실행했을 때, 각 카드는 68–83 °C에서 약 360–375 W를 소비했으며 최대 약 400 W에 근접했습니다. 카드 정격 등급 약 575 W보다 여유 있게 낮은 수준입니다. 프레임당 에너지는 대략 2.5 Wh로, 이는 해당 벤치 측정값에서 5090만을 기준으로 산출한 추론값입니다.
Q: 이 수치가 다른 렌더링 엔진에도 적용됩니까? A: 아닙니다. 이 연구는 단일 노드에서의 Blender Cycles GPU 전용입니다. 다른 엔진은 디노이징, 메모리, 타이밍을 다르게 기록합니다. 이 수치는 팜 전체 또는 크로스 엔진 주장이 아닌 Cycles 특화 현장 노트로 취급하시기 바랍니다.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



