
멀티 GPU 스케일링: GPU 1개와 2개가 렌더링에 미치는 실제 영향 (2026년 벤치마크)
개요
소개
TL;DR: 두 번째 GPU를 추가한다고 해서 렌더 속도가 두 배로 빨라지는 경우는 드물며, 그 효과는 전적으로 렌더링 엔진에 달려 있습니다. 저희의 2026년 듀얼 RTX 5090 및 RTX 4090 노드 벤치마크에서, 처리량 엔진(V-Ray, Octane)은 2.00x에 가깝게 스케일링된 반면, 렌더 시간 엔진은 더 낮게 스케일링되었습니다 — Cycles 1.31x1.63x, Redshift 1.68x1.92x — 이는 고정된 렌더당 오버헤드가 두 번째 카드로 가속할 수 있는 부분을 잠식하기 때문입니다. GPU 두 장이 노드당 실질적인 상한선이며, 렌더팜의 실제 처리량은 한 머신에 카드를 더 쌓는 것이 아니라 많은 노드에 걸쳐 많은 프레임을 병렬로 실행하는 데서 나옵니다.
두 번째 GPU를 추가한다고 해서 렌더 속도가 두 배로 빨라지지는 않습니다. 말로 하면 당연하게 들리지만, 실제로는 카드 두 장이면 속도도 두 배라는 가정 아래 많은 하드웨어 구매 결정이 이루어지고 있습니다. 저희는 2026년 6월에 RTX 5090 듀얼 장착 노드와 RTX 4090 듀얼 장착 노드 두 대를 대기열에서 꺼내, 4종의 렌더링 엔진과 7가지 씬·벤치마크 조합에서 GPU 1개에서 2개로 늘렸을 때 실제로 어떤 일이 벌어지는지 측정했습니다.
결론부터 말씀드리면, 엔진에 따라 결과가 크게 달라집니다. 처리량 중심 벤치마크(V-Ray, Octane)는 거의 2x에 가까운 스케일링을 보였습니다. 렌더 시간 기반 엔진(Cycles, Redshift)은 그보다 낮았으며, 더 빠른 카드에서는 두 번째 GPU의 기여가 더 작아졌습니다. 이 글에서는 수치를 하나씩 살펴보고, 그래프가 그런 형태를 띠는 이유를 설명하며, 동등하게 중요한 한 가지를 명확히 짚겠습니다. 단일 노드에서의 한계는 카드 두 장입니다. 그 이상은 단순히 더 큰 버전이 아니라 완전히 다른 아키텍처입니다.
이 글은 하드웨어 및 벤치마크 중심의 내용이므로 GPU에 초점이 맞춰져 있습니다. 저희 렌더팜에서 실행되는 작업의 대다수는 여전히 CPU 렌더링(CPU 기반 V-Ray, Corona, Arnold)이라는 점을 먼저 말씀드립니다. 하지만 "두 번째 GPU가 의미 있는가?"라는 질문을 받는다면, 마케팅 멘트가 아닌 실제 측정값을 제공해야 합니다. 아래에 그 측정값을 정리했습니다.
테스트 방법 (그리고 이 수치가 아닌 것)
두 테스트 노드는 모두 GPU 두 장을 장착한 Windows 11 Pro 환경에서 실행되었습니다. 5090 노드는 드라이버 596.36을, 4090 노드는 드라이버 610.62를 사용했습니다. Blackwell 카드에는 최신 드라이버가 필요하기 때문에 동일한 버전을 맞추는 것이 불가능했습니다. 이 드라이버 차이가 영향을 미치는 것은 딱 한 가지, 5090과 4090 사이의 절대적인 세대 간 속도 비교뿐입니다. 저희가 중점적으로 분석하는 스케일링 비율은 단일 노드 내(동일 카드, 동일 드라이버, GPU 1개 대 2개)에서 측정되었으므로, 드라이버 차이는 영향을 주지 않습니다.
모든 씬은 벤더 표준 벤치마크를 사용했습니다. Blender의 Open Data 씬(bmw27, classroom, junkshop), Redshift용 Maxon의 "Vultures" 씬, Chaos V-Ray Benchmark 6.00.02, 그리고 OctaneBench 2025.2.1입니다. 실제 고객 프로젝트나 프로덕션 에셋은 사용하지 않았습니다. 이 데이터셋에는 프레임당 소요 시간, 프레임당 비용, 전기 요금 관련 데이터가 포함되지 않으므로, 해당 수치는 공개하지 않습니다.
Cycles 행을 해석할 때 알아두어야 할 방법론적 사항이 하나 있습니다. Blender Cycles는 200% 해상도로 실행했습니다. Open Data 기본값보다 높게 설정한 이유는, 렌더가 충분히 오래 지속되어 신뢰할 수 있는 안정적인 스케일링 비율을 측정하기 위해서입니다. 따라서 저희의 Cycles 원시 시간은 공개 Open Data 점수와 비교할 수 없습니다. 리더보드 경쟁이 아닌 스케일링 측정을 위해 조정된 값입니다. Cycles와 Redshift는 렌더 시간(초, 낮을수록 좋음)으로 측정되고, V-Ray와 Octane은 벤치마크 점수(vpaths 또는 OctaneBench 포인트, 높을수록 좋음)로 측정됩니다. 두 가지 지표 유형이 서로 다르므로, 절대 수치는 엔진 간에 비교할 수 없으며, 동일 엔진 내 스케일링 비율만이 사과와 사과를 비교하는 의미 있는 수치입니다.
핵심 결과: 엔진별 1x~2x 스케일링
아래는 엔진과 씬별로 두 번째 동일 카드를 추가했을 때의 실제 효과를 정리한 핵심 데이터입니다.
| 엔진 | 씬 | 듀얼 RTX 5090 스케일링 | 듀얼 RTX 4090 스케일링 |
|---|---|---|---|
| Cycles | bmw27 | 1.54x | 1.58x |
| Cycles | classroom | 1.59x | 1.63x |
| Cycles | junkshop | 1.31x | 1.38x |
| Redshift | Vultures | 1.68x | 1.92x |
| V-Ray GPU (CUDA) | 벤치마크 | 1.97x | 2.00x |
| V-Ray GPU (RTX) | 벤치마크 | 2.00x | 2.00x |
| Octane | OctaneBench 스위트 | 2.00x | 1.98x |
위에서 아래로 읽으면 뚜렷한 구분이 보입니다. V-Ray와 Octane은 두 카드 모두에서 2.00x에 근접하거나 약간 낮은 값으로, 두 번째 GPU가 출력을 거의 두 배로 높입니다. Cycles는 1.31x~1.63x 범위에 분포합니다. Redshift는 5090에서 1.68x, 4090에서 1.92x를 기록했습니다.
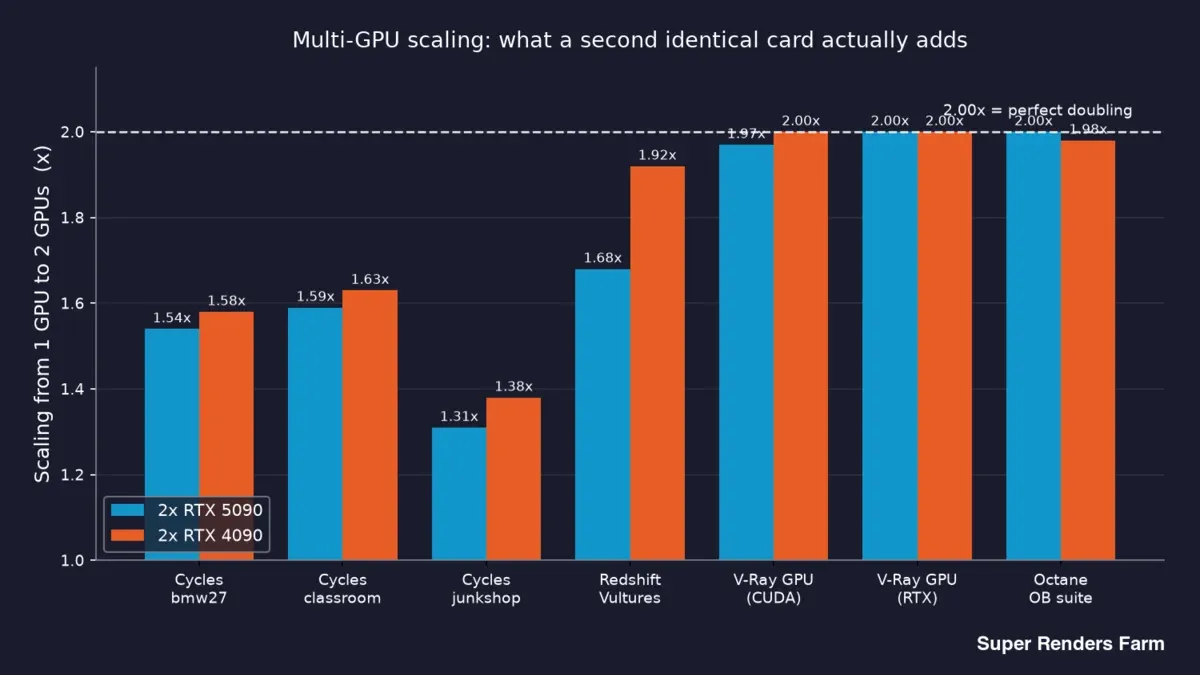
엔진별 GPU 1개→2개 스케일링 막대 그래프: 듀얼 RTX 5090 및 듀얼 RTX 4090 노드 기준. Cycles 1.31x~1.63x, Redshift 1.68x 대 1.92x, V-Ray 및 Octane 약 2.00x
"두 번째 GPU를 추가하면 속도가 두 배가 되나요?"라는 질문에는 렌더링하는 대상에 따라 세 가지 솔직한 답변이 있습니다. V-Ray와 Octane에서는 사실상 그렇습니다. Cycles에서는 대략 1.5x 향상입니다. Redshift에서는 그 중간 어딘가입니다. 단일 배율로 모든 렌더링을 설명할 수 있다고 말하는 사람은 실제로 측정해보지 않은 것입니다.
처리량 엔진이 렌더 시간 엔진보다 스케일링이 좋은 이유
이 패턴은 무작위가 아닙니다. 각 벤치마크가 시간을 어떻게 사용하는지에서 비롯됩니다. V-Ray Benchmark와 OctaneBench는 처리량 테스트입니다. 사용 가능한 컴퓨팅 자원 전체에 작업을 쏟아붓고 점수를 보고하는 방식이며, 씬 로딩, 가속 구조 빌드, 장치 초기화 등의 고정 설정 비용은 전체 실행 시간의 극히 작은 부분을 차지합니다. 두 번째 카드를 추가하면 추가된 실리콘 거의 전부가 유효한 작업에 투입되어 2x에 근접한 결과가 나옵니다. V-Ray RTX 결과가 두 카드 모두에서 정확히 2.00x를 기록한 것은, 오버헤드가 사실상 노이즈 수준인 작업에서 예상할 수 있는 정확한 결과입니다.
렌더 시간 엔진은 다르게 작동합니다. Cycles나 Redshift 렌더를 벽시계 시간(초)으로 측정하면 전체 작업을 타이밍하는 셈입니다. 모든 작업에는 병렬화되지 않는 고정 오버헤드가 있습니다. 씬 파싱, BVH/가속 구조 빌드, 커널 컴파일 및 워밍업, 장치 조율, 최종 픽셀 병합 등이 여기에 해당합니다. 두 번째 GPU는 카드 간에 실제로 분할 가능한 부분의 속도를 높입니다. 고정된 부분에는 아무런 영향을 주지 않습니다. 전체 렌더 시간에서 고정 오버헤드가 차지하는 비율이 클수록 스케일링은 2x에서 더 멀어집니다.
Cycles junkshop(1.31x1.38x)이 Cycles classroom(1.59x1.63x)보다 스케일링이 낮은 것도 이 때문입니다. junkshop은 렌더가 더 가볍고 짧기 때문에 고정 오버헤드가 전체에서 더 큰 비율을 차지하며, 두 번째 카드가 가속할 수 있는 여지가 줄어듭니다. classroom 씬은 더 오래 실행되므로 병렬 처리 부분이 지배적이고, 두 번째 GPU가 기여할 공간이 더 많습니다. 동일한 엔진, 동일한 하드웨어에서 씬이 두 번째 카드의 효과를 결정합니다.
직관에 반하는 결과: 더 빠른 카드에서 스케일링이 더 낮았습니다
Redshift 행을 다시 보십시오. 듀얼 RTX 5090은 1.68x 스케일링을 보였고, 듀얼 RTX 4090은 1.92x를 보였습니다. 더 새롭고 빠른 카드에서 스케일링이 더 낮았습니다. 오류처럼 보이지만 그렇지 않습니다. 이것이 전체 데이터 세트에서 가장 시사점이 큰 수치입니다.
메커니즘은 다음과 같습니다. 5090은 절대 수치 기준으로 더 빠른 카드입니다. GPU 1개 기준으로 Vultures 씬을 약 57초에 마치는 반면 4090은 약 100초가 걸립니다. 그런데 렌더당 고정 오버헤드인 파싱, 빌드, 워밍업은 어떤 카드가 실행하든 초 단위로 대략 동일합니다. 4090에서는 이 고정 부분이 100초짜리 긴 렌더의 작은 분수에 불과하므로, 두 번째 카드가 처리할 큰 병렬 부분이 남아 스케일링이 1.92x에 가깝게 나옵니다. 5090에서는 렌더가 이미 짧기 때문에 동일한 고정 부분이 전체의 더 큰 비율을 차지하여, 두 번째 카드가 가속할 수 있는 병렬 부분이 줄어들고 스케일링이 1.68x로 나옵니다.
중요한 것은, 이것이 5090이 더 나쁘다는 의미가 아니라는 점입니다. 5090은 카드 1개에서도 2개에서도 더 빠릅니다. 다만 처음부터 렌더가 빠르기 때문에 두 번째 GPU로부터 비례적으로 얻는 것이 적을 뿐입니다. 기본 렌더가 빠를수록 두 번째 카드가 깔끔한 2x를 달성하기는 더 어렵습니다. 병렬화할 수 있는 시간 자체가 줄어들기 때문입니다. 동일한 카드를 쌓으면 선형적인 수익을 기대할 수 있다고 생각하며 비용을 투자하기 전에 반드시 이해해야 할 사실입니다.
카드당 속도: RTX 5090 대 RTX 4090
스케일링이 한 축이라면, 카드당 원시 속도는 또 다른 축입니다. 방법론 섹션의 드라이버 주의사항을 전제로, GPU 1개 기준에서 5090은 테스트한 모든 엔진에서 앞섰습니다.
| 엔진 | 지표 | RTX 5090 | RTX 4090 | 5090 우위 |
|---|---|---|---|---|
| Cycles — bmw27 | 초 (낮을수록 좋음) | 49.45 | 77.40 | 1.57x |
| Cycles — classroom | 초 | 23.09 | 36.87 | 1.60x |
| Cycles — junkshop | 초 | 19.71 | 34.43 | 1.75x |
| Redshift — Vultures | 초 | 57 | 100 | 1.75x |
| V-Ray GPU (CUDA) | vpaths (높을수록 좋음) | 11,051 | 7,419 | 1.49x |
| V-Ray GPU (RTX) | vpaths | 15,333 | 9,608 | 1.60x |
| Octane | OctaneBench 점수 | 1,690.78 | 1,074.17 | 1.57x |
전반적으로 5090은 카드당 약 1.5x1.75x 빠릅니다. 하드웨어 계획을 세우는 분들을 위한 두 가지 시사점이 있습니다. 첫째, 세대 간 카드당 성능 향상(여기서는 1.5x1.75x)은 같은 세대 카드를 추가하는 것보다 크고 안정적입니다. 렌더 시간 엔진에서 두 번째 카드를 추가하면 종종 2x에 훨씬 미치지 못합니다. 쉽게 말해, 더 빠른 카드가 두 번째 카드보다 효과적인 레버인 경우가 많습니다. 둘째, 이 단일 카드 세대 간 비교 수치에는 드라이버 불일치 주의사항이 있습니다. 방향성 비교 지표로 활용하되, 고정된 보장 수치로 받아들이지 마십시오. 저희는 벤치마크 씬에서 측정하며, 실제 씬의 복잡도, 샘플링, 출력 해상도에 따라 실제 수치가 달라집니다. 단일 카드 5090의 동작에 대한 자세한 내용은 저희의 RTX 5090 GPU 클라우드 렌더링 성능 글을 참고하십시오.
노드당 상한선은 GPU 2개 — 그리고 그것으로 충분한 이유
여기서 명확한 선을 그어야 합니다. 대부분의 멀티 GPU 콘텐츠가 조용히 넘어가는 부분이기 때문입니다. 이 벤치마크의 모든 노드는 GPU 2개짜리 노드입니다. 카드 두 장이 노드당 상한선입니다. 4x나 8x 단일 노드 스케일링 곡선은 보여드리지 않겠습니다. 저희가 운용하지 않는 구성이며, 그런 것처럼 암시하지도 않겠습니다.
단일 프레임에서 GPU 두 장 이상을 사용하려면 멀티 노드 분산 렌더링이 필요합니다. 하나의 이미지를 여러 머신에 나누어 처리하는 방식으로, 그에 따른 네트워크 조율, 버킷/타일 관리, 오버헤드가 수반됩니다. 이것은 카드 두 장짜리 박스의 더 큰 버전이 아니라 완전히 별개의 아키텍처입니다. 현재 단일 프레임에 대해서는 제공하지 않으며, "출시 예정" 기능으로 날짜를 달아 언급하지도 않겠습니다.
그리고 한 가지 더. 프로덕션 작업의 압도적 다수에서 GPU 두 장 상한선이 실제 제약이 되는 경우는 드뭅니다. 가장 먼저 걸리는 제약은 거의 언제나 카드 수가 아닌 VRAM입니다. 32GB에 맞지 않는 씬은 GPU를 몇 장 투입해도 렌더되지 않으며, 이것은 완전히 다른 문제입니다(복잡한 씬을 위한 RTX 5090 VRAM 한계 글에서 다룹니다). "렌더팜을 스케일업한다"고 상상할 때 사람들은 보통 하나의 거대한 렌더가 점점 더 많은 실리콘 위에서 빨라지는 그림을 떠올립니다. 하지만 렌더팜 규모에서의 실제 처리량은 그런 방식으로 작동하지 않습니다.
렌더팜이 실제로 스케일링하는 방법: 카드가 아닌 프레임
이것이 내면화할 가치가 있는 핵심 구분이며, 위의 벤치마크 수치가 계속 가리키는 지점이기도 합니다. "더 많은 하드웨어에서 더 빠르게 렌더한다"는 말에는 완전히 다른 두 가지 의미가 있습니다.
- 하나의 프레임을 여러 GPU 또는 머신에 분할 (타일/버킷 분산 렌더링). 이것이 두 장 규모에서 1x→2x 수치가 측정하는 것이며, 멀티 노드 분산 렌더링이 확장하는 방식입니다. 데이터에서 보듯이 렌더 시간 엔진에서는 빠르게 수익 체감이 나타납니다. 고정된 렌더당 오버헤드 때문이며, 머신을 추가할수록 조율 비용만 늘어납니다.
- 많은 프레임을 여러 머신에 분산 (프레임 병렬 렌더링). 각 노드가 전체 프레임 하나씩을 독립적으로 렌더합니다. 애니메이션의 프레임들이 전체 렌더팜에 병렬로 분배됩니다. 단일 프레임 조율 오버헤드가 없으므로 깔끔하게 스케일링됩니다. 이 방식이 렌더팜에서 애니메이션이 빠르게 완성되는 원리입니다.
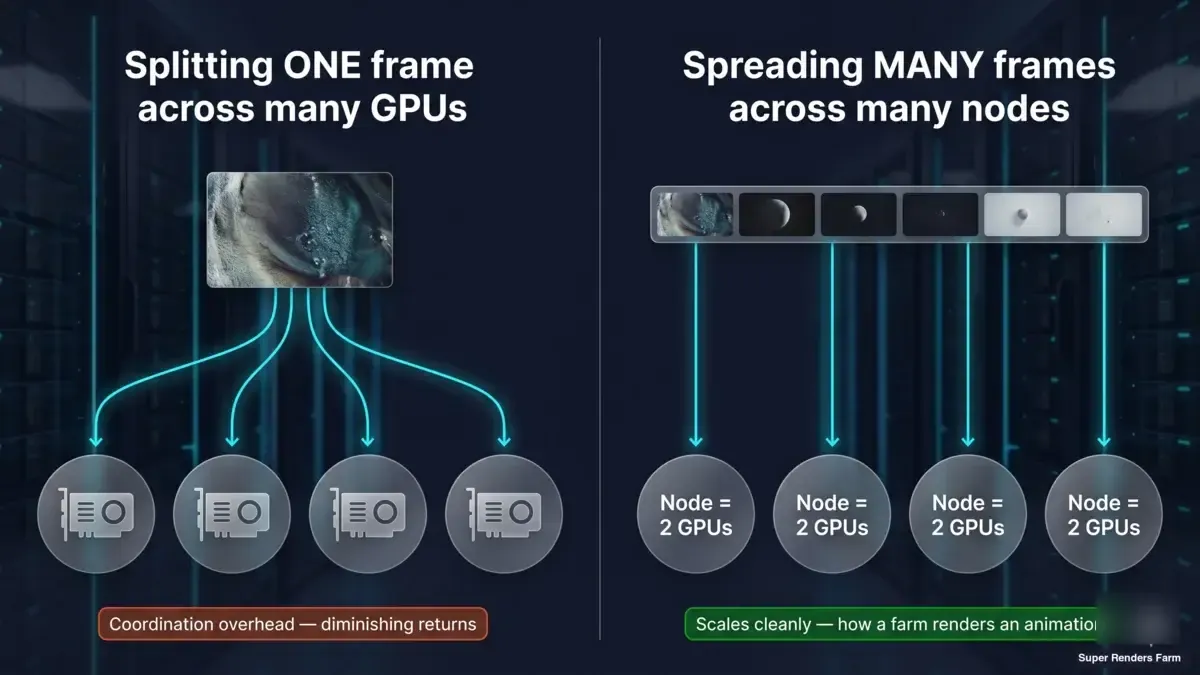
개념 다이어그램 2패널: 하나의 프레임을 여러 GPU에 분할하면 조율 오버헤드와 수익 체감이 발생하는 반면, 각각의 듀얼 GPU 노드에서 독립적으로 전체 프레임을 처리하는 방식은 애니메이션 스케일링에서 깔끔하게 작동함
풀 매니지드 렌더팜은 두 번째 모델에서 속도의 거의 전부를 얻습니다. 500프레임 애니메이션이 500개의 GPU에 한 프레임씩 나뉘어 렌더되는 것이 아니라, 렌더팜 전체에 500개의 프레임이 분배되어 각각 자체 노드에서 동시에 렌더됩니다. 노드당·프레임당 속도는 여기서 벤치마크한 GPU 2개 스케일링과 카드당 성능이 결정하고, 렌더팜 수준의 속도는 동시에 실행되는 프레임 수에서 나옵니다. 이 두 가지는 서로 다른 레버이며, 이를 혼동하는 것이 "GPU가 몇 개나 필요한가"에 대한 혼란의 주된 원인입니다.
따라서 멀티 GPU에 대한 솔직한 이야기는 마케팅 버전보다 좁습니다. 노드당 카드 두 장은 실제로 측정 가능한 향상을 제공합니다. V-Ray와 Octane에서는 2x에 가깝고, Cycles와 Redshift에서는 더 완만합니다. 그 이상은 "박스에 카드를 더 쌓는" 방식이 아니라 "더 많은 노드에 더 많은 프레임을 실행하는" 방식입니다. 이것이 아키텍처이며, 이를 솔직하게 이야기하는 것이 실제로는 그렇게 작동하지 않았을 하드웨어에 비용을 쏟아붓는 것을 막아줍니다.
렌더링 방식을 선택할 때 이것이 의미하는 바
실제로 활용할 수 있는 내용으로 정리하겠습니다. 워크스테이션에서 카드 1개와 2개 중 어느 것을 선택할지 결정할 때는 주로 사용하는 엔진이 기준이 되어야 합니다. V-Ray나 Octane 사용자는 거의 완전한 두 배의 효과를 얻으므로 두 번째 카드는 정당화하기 쉽습니다. Cycles나 Redshift 사용자는 1.3x1.9x 향상을 기대해야 하며, 더 빠른 단일 카드(1.5x1.75x 세대 간 향상)가 더 나은 선택인지 고민해 볼 필요가 있습니다. 로컬에서 렌더할지 렌더팜에 맡길지 결정할 때는, 렌더팜의 장점이 애니메이션에서의 프레임 병렬 처리량이지 마법 같은 단일 프레임 배수가 아님을 기억하십시오. 단일 히어로 스틸 프레임은 비슷한 워크스테이션보다 렌더팜에서 극적으로 빨라지지 않지만, 수백 개의 프레임은 확실히 달라집니다.
풀 매니지드와 DIY의 트레이드오프 — 드라이버, 라이선스, 노드 구성을 누가 처리하는지 — 에 대한 맥락은 저희의 풀 매니지드 렌더팜 대 DIY 렌더팜 비교 가이드를 참고하십시오. 저희 렌더팜에서는 렌더링 엔진 라이선스(V-Ray, Redshift, Octane)가 렌더링 요금에 포함되어 있으며, 노드 구성도 고정·유지되므로 이 벤치마크 수치의 배경이 되는 GPU 2개 노드 설정과 드라이버를 직접 조립하거나 조정할 필요가 없습니다. Redshift가 Cinema 4D에서 1.68x 스케일링을 보이는 경우에 대해서는 Cinema 4D용 Redshift 렌더팜 가이드를 참고하십시오.
이 글의 측정값은 의도적으로 과장 없이 제시했습니다. 두 번째 GPU는 실제 효과가 있지만 명확한 한계도 있습니다. 더 빠른 카드에서 스케일링이 낮은 것은 처음부터 느린 렌더를 가속할 여지가 적기 때문이며, 렌더팜 규모의 속도는 카드를 쌓는 이야기가 아닌 프레임 분배 이야기입니다. 자신의 작업 흐름에 어떤 레버가 적용되는지를 아는 것이 결정의 대부분입니다.
FAQ
Q: 두 번째 GPU를 추가하면 렌더 속도가 두 배가 됩니까? A: 대체로 그렇지 않습니다. 저희의 2026년 벤치마크에서 V-Ray와 Octane 같은 처리량 엔진은 두 번째 동일 카드로 2.00x에 근접한 스케일링을 보였지만, 렌더 시간 엔진은 더 낮게 나타났습니다. Cycles는 1.31x~1.63x, Redshift는 듀얼 RTX 5090에서 1.68x를 기록했습니다. 향상 폭은 엔진과 씬에 따라 완전히 달라집니다. 모든 렌더에는 두 번째 카드로 가속할 수 없는 고정 오버헤드가 있기 때문입니다.
Q: RTX 4090보다 RTX 5090에서 Redshift의 스케일링이 더 낮은 이유는 무엇입니까? A: 5090이 더 빠르기 때문에 렌더가 짧아지고, 그 결과 씬 파싱·가속 구조 빌드·커널 워밍업 등 고정된 렌더당 오버헤드가 전체에서 더 큰 비율을 차지합니다. 그만큼 두 번째 카드가 가속할 수 있는 병렬 부분이 줄어들어 5090에서는 1.68x, 4090에서는 1.92x가 됩니다. 5090은 카드 1개와 2개 모두에서 여전히 더 빠르며, 단지 두 번째 GPU로부터 비례적으로 얻는 것이 적을 뿐입니다.
Q: RTX 5090은 렌더링에서 RTX 4090보다 얼마나 빠릅니까? A: 저희가 테스트한 Cycles, Redshift, V-Ray GPU, Octane 전반에서 카드당 약 1.5x~1.75x 더 빠릅니다. 두 카드가 서로 다른 NVIDIA 드라이버로 실행되었으므로 이 단일 카드 세대 간 수치에는 사소한 주의사항이 있습니다. 고정된 보장 수치가 아닌 방향성 비교 지표로 활용하십시오.
Q: V-Ray와 Octane이 GPU 두 장에서 Cycles나 Redshift보다 스케일링이 좋은 이유는 무엇입니까? A: V-Ray Benchmark와 OctaneBench는 처리량 테스트로, 고정 설정 비용이 전체 실행 시간의 극히 일부에 불과합니다. 따라서 두 번째 카드가 거의 전부 유효한 작업에 투입되어 스케일링이 2.00x에 근접합니다. Cycles와 Redshift는 총 렌더 시간으로 측정되는데, 여기에는 두 번째 카드로 가속할 수 없는 비병렬 오버헤드가 포함되어 2x 미만으로 스케일링됩니다.
Q: 렌더팜에서 여러 머신에 단일 프레임을 더 빠르게 렌더할 수 있습니까? A: 하나의 프레임을 여러 머신에 분할하는 것은 멀티 노드 분산 렌더링으로, 고유의 조율 오버헤드가 있는 별개의 아키텍처이며 현재 단일 프레임에 대해서는 제공하지 않습니다. 풀 매니지드 렌더팜은 대신 프레임 병렬 렌더링으로 속도를 얻습니다. 다수의 전체 프레임이 동시에 다수의 노드에 분산되어 처리되므로, 애니메이션은 빠르게 완성되지만 단일 히어로 프레임은 노드당 속도로 렌더됩니다.
Q: 렌더링에 실제로 GPU가 몇 개나 필요합니까? A: 단일 노드 기준으로 GPU 두 장이 합리적인 상한선이며, 저희 벤치마크 노드도 그렇게 구성되어 있습니다. 그 이상에서는 실질적인 제약이 보통 카드 수가 아닌 VRAM입니다. 메모리에 맞지 않는 씬은 카드를 몇 장 추가해도 렌더되지 않습니다. 애니메이션을 렌더링하는 경우, 실질적인 처리량 향상은 한 머신에 카드를 더 쌓는 것이 아니라 더 많은 노드에 더 많은 프레임을 분산시키는 방법에서 나옵니다.
Q: 이 벤치마크 수치는 공개된 Blender Open Data 점수와 비교할 수 있습니까? A: 아닙니다. 저희는 Blender Cycles를 200% 해상도로 실행했으며, 이는 Open Data 기본값보다 높게 설정한 것입니다. 각 렌더가 충분히 오래 지속되어 안정적인 스케일링 비율을 측정할 수 있도록 조정된 값입니다. 따라서 저희의 원시 Cycles 시간은 의도적으로 공개 Open Data 리더보드와 비교할 수 없습니다. 씬은 표준 점수 매칭이 아닌 스케일링 측정을 위해 조정되었습니다.
Q: 풀 매니지드 렌더팜을 사용하려면 GPU 드라이버와 라이선스를 직접 관리해야 합니까? A: 아닙니다. 풀 매니지드 렌더팜에서는 노드 구성, 드라이버, 렌더링 엔진 라이선스(V-Ray, Redshift, Octane)가 모두 관리되며 렌더링 요금에 포함되어 있습니다. 이 벤치마크의 배경이 되는 GPU 2개 노드 설정과 드라이버는 직접 조립하거나 조정할 필요가 없습니다. Cycles는 무료 오픈소스이므로 별도의 라이선스가 필요하지 않습니다.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



