
Cómo medimos el rendimiento de las GPU en la render farm: un método reproducible de costo por fotograma (2026)
Resumen
Introducción
Una puntuación de benchmark es fácil de publicar y difícil de confiar. Cualquiera puede escribir "RTX 5090: X puntos", pero el número que determina si vale la pena ejecutar un trabajo de renderizado en una tarjeta u otra no es una puntuación sintética: es el costo por fotograma. Esa cifra depende de su escena, sus ajustes de renderizado, el motor, el controlador y la forma en que se hace la aritmética, y casi nada de eso es visible en una tabla de clasificación.
Esta página es el método, no la tabla de clasificación. Documenta cómo evaluamos las GPU de la render farm en Super Renders Farm para que el resultado tenga sentido: cómo elegimos una escena de referencia, qué ajustes de renderizado bloqueamos, qué mantenemos constante en toda la matriz de hardware, cómo convertimos los tiempos brutos por fotograma en un costo por fotograma defendible y —la parte que la mayoría de los informes omite— los pasos explícitos para que un tercero pueda reproducir todo el proceso en su propio hardware. Ya hemos publicado los resultados de este método; esta es la receta que los sustenta. Cuando aparece un número a continuación, es una cifra real de uno de esos estudios, citada como ejemplo práctico en lugar de volver a derivarla aquí.
Benchmarks sintéticos frente a costo por fotograma en producción
Existen dos niveles en el benchmark de GPU, y confundirlos es el origen de la mayoría de los malentendidos.
El primero es el nivel sintético: herramientas estandarizadas que renderizan una escena fija y emiten una puntuación. Cinebench R24, el V-Ray Benchmark de Chaos y OctaneBench se ubican aquí. Son útiles para la clasificación relativa: una carga de trabajo única y repetible, la misma en cada máquina, para poder alinear tarjetas entre sí. Explicamos cómo interpretar esas puntuaciones en nuestra guía de benchmark de V-Ray y en nuestro artículo sobre puntuaciones de Cinebench para renderizado en la nube. Lo que una puntuación sintética elimina deliberadamente es todo lo que varía en producción: su geometría, su muestreo, su denoiser, su resolución de salida y el costo fijo por trabajo que una cola real tiene.
El segundo es el nivel de producción: cuánto tiempo tarda realmente un fotograma representativo y cuánto cuesta. Este es el nivel al que apunta esta metodología. Una puntuación sintética es una entrada para él —una forma de extrapolar una estimación inicial— pero no es la respuesta. El puente entre ambos es sencillo en principio: una máquina que puntúa aproximadamente el doble que otra en la misma versión de benchmark renderizará un fotograma comparable en aproximadamente la mitad del tiempo. Explicamos esa aritmética de estimación (eficiencia = tiempo de fotograma ÷ puntuación de benchmark) en la guía de V-Ray. El objetivo de un método de benchmark, a diferencia de una puntuación, es hacer que esa extrapolación sea honesta: medir en una escena cercana a la producción e informar la dispersión, no solo un punto medio.
La métrica que importa: costo por fotograma
El costo por fotograma es la unidad a la que debe resolverse una metodología, porque es la unidad en la que realmente se escribe un presupuesto de renderizado. La fórmula es sencilla:
Costo por fotograma = tiempo de pared por fotograma × costo del nodo por hora
El tiempo de pared por fotograma es el tiempo de la tarea dividido entre el número de fotogramas, medido en el planificador —no el indicador interno de "tiempo de renderizado" del motor, que excluye la carga de la escena, la construcción de la estructura de aceleración y la coordinación del dispositivo. El costo del nodo por hora es lo que cuesta ejecutar el hardware durante una hora, sea cual sea la forma en que usted lo contabilice. En nuestra render farm, el renderizado GPU se factura a $0,003 por OctaneBench-hour, y una sola RTX 5090 (32 GB) tiene una base de hardware de aproximadamente $5,2 por hora de tarjeta; nuestra guía de costo por fotograma y la guía de precios cubren el modelo orientado al cliente en su totalidad.
Combinar ambas entradas es solo aritmética de unidades: convierta el tiempo de pared por fotograma a horas y multiplique por el costo del nodo por hora, de modo que los segundos por fotograma y los dólares por hora se resuelvan en dólares por fotograma. Un fotograma corto en un nodo económico resulta bajo; uno pesado en uno costoso resulta alto. Mantenemos deliberadamente la tarifa calculada fuera de esta página de metodología —el costo real depende de la complejidad de su escena, el muestreo, el tiempo de espera en la cola y el modelo de facturación que usted use, y nuestra guía de costo por fotograma y la guía de precios son donde corresponden los números orientados al cliente. La clave aquí es que la fórmula es auditable: mantenga las unidades explícitas y cualquiera puede verificar la cifra en lugar de aceptarla con fe.
La razón por la que el costo por fotograma, y no una puntuación sintética, es la métrica fundamental: dos tarjetas pueden puntuar de manera similar en un benchmark y aun así diferir notablemente en el costo por fotograma de su escena, porque la escena determina qué fracción de cada fotograma es trabajo paralelizable frente al costo fijo que el silicio más rápido no puede eliminar.
La escena de referencia y los ajustes de renderizado
La escena es el mayor determinante de si un benchmark se traslada a la producción, por lo que ejecutamos dos tipos deliberadamente.
Escenas estándar de los fabricantes para la clasificación entre máquinas. Cuando el objetivo es una comparación limpia de igualdad a igualdad, usamos escenas de referencia publicadas: las escenas de Open Data de Blender (bmw27, classroom, junkshop), la escena Vultures de Maxon para Redshift, el V-Ray Benchmark de Chaos y OctaneBench. Son repetibles y verificables de forma independiente, que es exactamente lo que necesita una clasificación. Su debilidad es que no son su escena, por lo que los tiempos absolutos no se trasladan directamente a la producción.
Escenas representativas de producción para el costo por fotograma. Cuando el objetivo es un número con el que un operador pueda planificar, la escena debe parecerse al trabajo real: geometría real, conjuntos de texturas reales, muestreo real, resolución de salida real. En nuestro estudio de escalado multi-GPU ejecutamos Blender Cycles al 200% de resolución específicamente para que cada renderizado durara lo suficiente como para producir una relación estable y confiable —lo que también significa que esos tiempos brutos de Cycles no son comparables con las puntuaciones públicas de Open Data. Esa compensación es el método funcionando como se espera: ajuste la escena a la pregunta.
Sea cual sea la escena, los ajustes de renderizado deben estar bloqueados y registrados: número de muestras (o umbral de ruido), denoiser activado/desactivado y cuál, resolución de salida, tamaño de tile o bucket y la versión del motor. Un benchmark en el que cualquiera de estos deriva entre máquinas está midiendo la deriva, no el hardware.
La matriz de hardware
Una matriz de benchmark es una cuadrícula: las tarjetas que se están probando en un eje, los motores y las escenas en el otro. La disciplina está en lo que se mantiene constante en toda la cuadrícula.
Mantener constante: el sistema operativo, la versión y compilación del motor de renderizado, el denoiser, la escena y los ajustes. Registrar pero no siempre poder igualar: el controlador de GPU —una tarjeta de última generación a veces requiere un controlador más reciente del que puede ejecutar una más antigua, por lo que una coincidencia exacta de controlador es imposible. Cuando eso ocurre, hay que nombrarlo. En el estudio multi-GPU, el nodo RTX 5090 ejecutó el controlador 596.36 y el nodo RTX 4090 el 610.62, y señalamos que la diferencia afecta solo la comparación absoluta entre generaciones, no las relaciones de escalado dentro del nodo (que usan la misma tarjeta y controlador en ambos lados).
Nuestra flota de GPU estandariza en tarjetas NVIDIA RTX 5090 con 32 GB de VRAM, lo que hace que nuestra matriz sea internamente coherente: un inventario uniforme significa que una estimación de un nodo se traslada al siguiente. Como ejemplo práctico del eje por tarjeta, aquí está el resultado de tarjeta única del estudio multi-GPU, RTX 5090 frente a RTX 4090 en escenas idénticas:
| Motor / escena | Métrica | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | segundos (menor es mejor) | 49,45 | 77,40 |
| Cycles — classroom | segundos | 23,09 | 36,87 |
| Redshift — Vultures | segundos | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (mayor es mejor) | 15.333 | 9.608 |
| Octane | puntuación OctaneBench | 1.690,78 | 1.074,17 |
Aparecen dos tipos de métricas en esa tabla: segundos (menor es mejor) y puntuación de benchmark (mayor es mejor), que es precisamente la razón por la que los números absolutos nunca se comparan entre motores. Solo la relación dentro de un único motor es una comparación válida.
Los controles que hacen confiable un benchmark
La diferencia entre un número y un número confiable son los controles. Estos son los que nuestro método aplica.
- Una tarea por GPU. Nuestro planificador ejecuta una tarea de renderizado por tarjeta, de modo que cada cifra es un número limpio por tarjeta —el valor que usted multiplica para planificar la capacidad, no un promedio difuminado entre un dispositivo compartido.
- Pares coincidentes para cualquier comparación. Cuando comparamos generaciones de hardware en producción, una escena solo contó si la misma escena, el mismo usuario se ejecutó en ambos lados, con al menos tres tareas por lado antes de calificar. En el estudio de campo RTX 5090, 38 escenas superaron ese umbral de 1.419 tareas —38 no es el tamaño de los datos, es lo que supera un filtro deliberadamente estricto.
- Un solo controlador por ventana. Para el estudio de campo, un único controlador (581.80, CUDA 13.0) ejecutó toda la ventana de siete semanas sin ningún cambio, para que ningún intercambio a mitad de la ventana pudiera contaminar el resultado.
- Paridad del denoiser. Aproximadamente el 83% de los trabajos de Cycles ejecutaron un pase de denoising con IA tanto en el hardware nuevo como en el de la generación anterior, de modo que el denoiser fue una constante, no una variable oculta dentro de la mejora de velocidad.
- Cálido frente a frío. El costo fijo por tarea —carga de la escena, sincronización, construcción de la estructura de aceleración— representa una fracción mayor de un fotograma corto que de uno largo, razón por la cual los fotogramas cortos y dominados por costo fijo subestiman una tarjeta más rápida. El método lo tiene en cuenta informando la distribución, no asumiendo un multiplicador único.
De los tiempos brutos a un número defendible
Una vez recopilados los tiempos, las estadísticas determinan si el número titular es honesto.
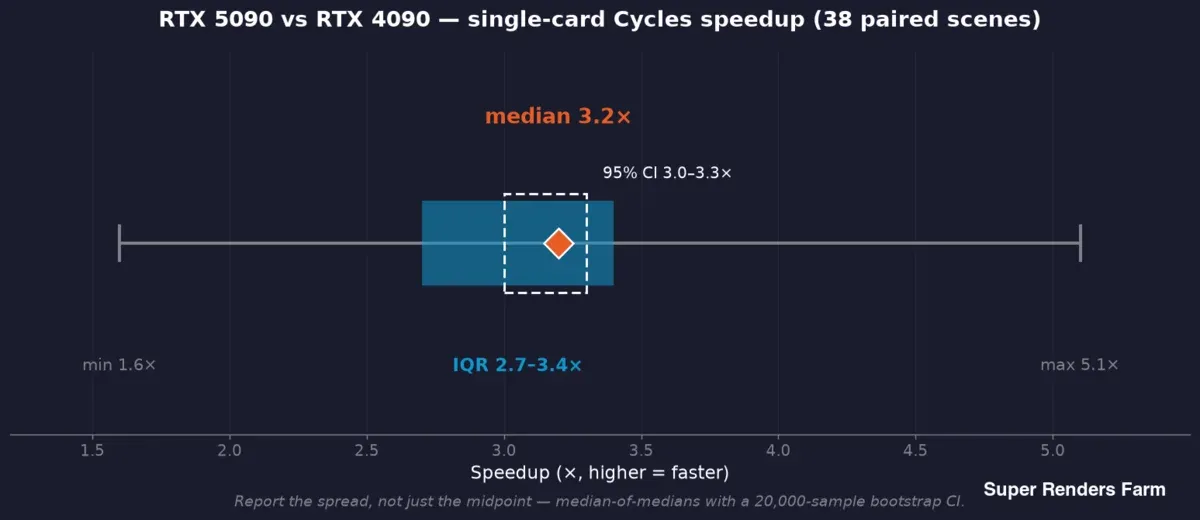
RTX 5090 frente a RTX 4090 mejora de velocidad de tarjeta única en Cycles en 38 escenas emparejadas: mediana 3,2x, intervalo de confianza del 95% de 3,0 a 3,3x, rango intercuartílico de 2,7 a 3,4x, rango completo de 1,6 a 5,1x
Usamos una mediana de medianas: cada escena aporta la mediana de sus propios tiempos por fotograma en cada lado, y el titular es la mediana de esas relaciones por escena, de modo que un fotograma lento no puede inclinar el resultado. En torno a ese punto medio informamos un intervalo de confianza bootstrap (el estudio de campo usó un bootstrap de 20.000 muestras, dando un IC del 95% de 3,0–3,3x en torno a la mediana 3,2x de mejora) y la dispersión: rango intercuartílico 2,7–3,4x, rango completo 1,6–5,1x entre esas 38 escenas.
Esa dispersión no es ruido que promediar; es el resultado. Una mejora típica de 3,2x y una escena con peor rendimiento de 1,6x son ambas verdaderas al mismo tiempo, y un benchmark que informa solo el punto medio oculta la mitad de la historia que un operador necesita. La regla que seguimos: informar la mediana y el rango, y vincular cada afirmación a la muestra que la respalda —mejora de 38 escenas emparejadas, VRAM de 57 trabajos registrados, consumo eléctrico de una ejecución de referencia controlada separada, nunca una muestra prestada para respaldar otra.
Cómo reproducir este benchmark
Esta es la parte que convierte un benchmark en una señal ganada en lugar de una afirmación de marketing: cualquiera puede ejecutarlo. Los pasos siguientes reproducen el método en cualquier cola o banco de pruebas.
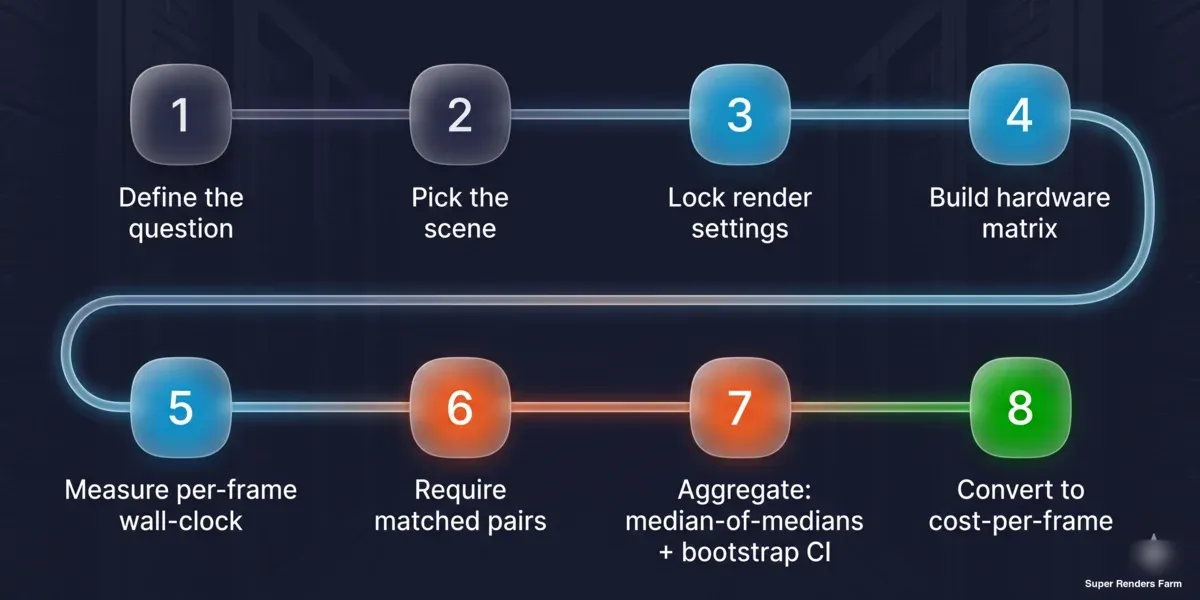
Método reproducible de costo por fotograma en ocho pasos: definir la pregunta, elegir la escena, bloquear los ajustes de renderizado, construir la matriz de hardware, medir el tiempo de pared por fotograma, requerir pares coincidentes, agregar con mediana de medianas e intervalo de confianza bootstrap, convertir a costo por fotograma
- Defina la pregunta. ¿Clasificación entre máquinas o costo por fotograma en producción? La respuesta elige el tipo de escena: estándar del fabricante para clasificación, representativa de producción para costo.
- Fije la escena y los ajustes. Bloquee el número de muestras o el umbral de ruido, la elección del denoiser, la resolución de salida, el tamaño de tile/bucket y la compilación del motor. Escríbalos; forman parte del resultado.
- Construya la matriz. Liste las tarjetas en un eje, las combinaciones de motor/escena en el otro. Decida qué se mantiene constante (SO, compilación del motor, denoiser, escena) y registre lo que no se puede igualar (controlador).
- Mida el tiempo de pared por fotograma. Use tiempo de tarea ÷ número de fotogramas del planificador o un cronómetro en el trabajo completo —no el indicador interno de tiempo de renderizado del motor, que omite la carga y el costo de construcción.
- Exija pares coincidentes y un mínimo de muestras. Para cualquier afirmación A frente a B, ejecute la misma escena en ambos lados, al menos tres tareas por lado, antes de que cuente.
- Agregue con mediana de medianas. Tome la mediana de cada escena por lado, luego la mediana de las relaciones por escena. Calcule un intervalo de confianza bootstrap e informe el rango intercuartílico y el rango completo junto a él.
- Convierta a costo por fotograma. Multiplique el tiempo de pared por fotograma medido por el costo del nodo por hora. Mantenga las unidades explícitas para que la cifra sea auditable.
- Publique las advertencias junto con el número. Indique el tamaño de la muestra detrás de cada afirmación, la situación del controlador, si los datos son observacionales o controlados y el alcance que cubre y no cubre.
Un estudio que ejecute estos ocho pasos en su propio hardware obtendrá un número que puede defender —y puede verificar el nuestro, que es el objetivo de publicar el método.
Notas de honestidad: qué puede y qué no puede afirmar un benchmark
Un método es tan confiable como las afirmaciones que se niega a hacer. Tres líneas que mantenemos:
Lo observacional no es controlado. Los datos de campo de producción —trabajos que los usuarios ejecutaron en el curso normal de sus actividades— son reales y útiles, pero los usuarios ajustan sus propias escenas entre re-renderizados, por lo que son observacionales. Una comparación directa limpia en el mismo host (por ejemplo, una RTX 5090 frente a una RTX 4090 actual en hardware idéntico) es un ejercicio controlado separado. No permitimos que uno se haga pasar por el otro.
Nodo frente a nodo incluye la configuración, no solo el silicio. Cuando un lado ejecuta bare-metal y el otro virtualizado, parte de la diferencia medida es la configuración, no el chip. Eso pertenece a la advertencia del titular, no a una nota al pie.
Ningún número que no hayamos medido. No extrapolamos cifras de consumo eléctrico o temperatura que no hayamos evaluado. Donde nuestro estudio de campo informa aproximadamente 360–375 W por tarjeta, eso proviene de una ejecución de referencia controlada bajo carga sostenida —y la cifra de energía por fotograma derivada de ella está etiquetada como una inferencia, no una medición. Si un número no fue medido, el método no lo inventa. Esa disciplina es la razón por la que un benchmark publicado puede citarse en absoluto.
Ejemplos prácticos de nuestra render farm
Este método produjo los estudios a continuación; cada uno es un conjunto de datos que puede leer junto con la receta, y es el lugar donde buscar los números reales en lugar de volver a derivarlos aquí.
| Estudio | Lo que el método produjo | Muestra |
|---|---|---|
| Escalado multi-GPU | Escalado 1x→2x por motor en escenas estándar de fabricante | 2 nodos, 4 motores, 7 combinaciones de escena/benchmark |
| Notas de campo RTX 5090 | Distribución de costo/mejora en producción, percentiles de VRAM | 38 escenas emparejadas / 1.419 tareas, 7 semanas |
| Guía de benchmark V-Ray | Estimación de tiempo de renderizado desde puntuación sintética | Tablas de referencia + estimación práctica |
| Cinebench para renderizado en la nube | Interpretación de puntuación sintética para niveles de hardware | Puntuaciones de referencia |
El mismo enfoque sustenta cómo planificamos la capacidad en nuestra render farm GPU en la nube, y los números específicos de Blender alimentan nuestro trabajo de renderizado Blender en la nube —la GPU es una minoría de nuestra mezcla general de trabajos (la mayor parte del trabajo de la farm sigue siendo renderizado CPU), por lo que limitamos estas cifras de GPU a exactamente eso, no como una afirmación sobre toda la farm.
FAQ
Q: ¿Cuál es la forma correcta de medir el rendimiento de la GPU en una render farm? A: Decida primero si desea clasificación entre máquinas o costo por fotograma en producción. Para la clasificación, use una escena estándar del fabricante repetible y una compilación de benchmark fija. Para el costo por fotograma, use una escena representativa de producción, mida el tiempo de pared por fotograma (tiempo de tarea ÷ número de fotogramas) y multiplique por el costo del nodo por hora. Bloquee los ajustes de renderizado e informe la dispersión, no solo un número único.
Q: ¿Por qué el costo por fotograma es mejor que una puntuación de benchmark? A: Una puntuación sintética elimina todo lo que varía en producción —su geometría, muestreo, denoiser y resolución— de modo que dos tarjetas pueden puntuar igual pero diferir en el costo por fotograma real de su escena. El costo por fotograma es la unidad en la que realmente se escribe un presupuesto de renderizado, razón por la que una metodología debe resolverse a esa unidad en lugar de a un punto de tabla de clasificación.
Q: ¿Cómo convierto una puntuación de benchmark en una estimación de tiempo de renderizado? A: Use la relación de puntuaciones como una relación de velocidad aproximada: una máquina que puntúa el doble que otra en la misma compilación de benchmark renderiza un fotograma comparable en aproximadamente la mitad del tiempo. Calcule la eficiencia de su máquina como tiempo de fotograma dividido entre la puntuación de benchmark y luego escale por la puntuación de la máquina objetivo. Mantenga la compilación de benchmark constante, ya que las puntuaciones de compilaciones diferentes no son comparables.
Q: ¿Qué controles hacen confiable un benchmark de GPU? A: Ejecute una sola tarea de renderizado por tarjeta para obtener números limpios por tarjeta, exija pares coincidentes (la misma escena en ambos lados, un número mínimo de tareas antes de que un resultado cuente), mantenga el controlador y la compilación del motor constantes dentro de una ventana de medición, y mantenga el ajuste del denoiser idéntico en toda la comparación. Luego agregue con una mediana de medianas e informe el intervalo de confianza y el rango.
Q: ¿Cuántas escenas de prueba necesito para un resultado confiable? A: Menos pares coincidentes de alta calidad superan a muchos poco controlados. En nuestro estudio de producción, 38 escenas superaron un filtro de inclusión estricto (la misma escena y usuario en ambos lados del hardware, al menos tres tareas por lado) de 1.419 tareas. El tamaño de muestra que importa es lo que supera su filtro, no el conteo bruto de tareas —y debe informar ambos.
Q: ¿Puedo yo mismo reproducir el benchmark de GPU de la render farm? A: Sí —ese es el objetivo. Fije una escena y sus ajustes, construya una matriz de hardware manteniendo el SO, la compilación del motor y el denoiser constantes, mida el tiempo de pared por fotograma, exija pares coincidentes, agregue con mediana de medianas más un intervalo de confianza bootstrap, convierta a costo por fotograma y publique las advertencias junto con el número. Los ocho pasos de replicación anteriores describen la secuencia completa.
Q: ¿Por qué informa un rango en lugar de un único número de mejora? A: Porque el rango es parte del resultado. El mismo hardware puede mostrar una ganancia de 1,6x en una escena corta dominada por costo fijo y más de 5x en una escena pesada dominada por cómputo, ya que el costo fijo por fotograma representa una fracción mayor de un renderizado corto. Informar solo el punto medio oculta la variación que un operador necesita para planificar la capacidad, por lo que publicamos la mediana, el rango intercuartílico y el rango completo juntos.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



