
Escalado Multi-GPU: Lo que 1 vs 2 GPUs Hace Realmente en el Renderizado (Benchmark 2026)
Resumen
Introducción
TL;DR: Una segunda GPU rara vez duplica la velocidad de renderizado, y cuánto ayuda depende por completo del motor de renderizado. En nuestros benchmarks de 2026 en nodos duales RTX 5090 y RTX 4090, los motores de tipo rendimiento (V-Ray, Octane) escalaron cerca de 2,00x, mientras que los motores de tiempo de renderizado escalaron menos — Cycles entre 1,31x y 1,63x, Redshift entre 1,68x y 1,92x — porque la sobrecarga fija por renderizado reduce lo que la segunda tarjeta puede acelerar. Dos GPUs es el límite práctico por nodo; el rendimiento real de una render farm proviene de ejecutar muchos fotogramas en muchos nodos en paralelo, no de apilar más tarjetas en una sola máquina.
Una segunda GPU no hace que el renderizado sea el doble de rápido. Eso suena obvio una vez que se dice en voz alta, pero muchas decisiones de hardware se toman bajo el supuesto de que dos tarjetas significan el doble de velocidad. En junio de 2026 retiramos dos de nuestros nodos de benchmark de la cola — uno con dos RTX 5090, otro con dos RTX 4090 — y medimos lo que realmente ocurre al pasar de una tarjeta a dos, en cuatro motores de renderizado y siete combinaciones de escenas/benchmarks.
La versión corta: depende completamente del motor. Los benchmarks de tipo rendimiento (V-Ray, Octane) escalaron casi perfectamente, en torno a 2x. Los motores de tiempo de renderizado (Cycles, Redshift) escalaron menos, y en la tarjeta más rápida la segunda GPU ayudó menos, no más. Aquí presentamos los datos, explicamos por qué la curva se dobla de esa manera y — igual de importante — dejamos claro dónde termina esto. Dos tarjetas es el límite en un único nodo. Ir más allá es una arquitectura distinta, no una versión ampliada de este caso.
Este es un artículo de hardware y benchmarks, por lo que está orientado a las GPU. Vale la pena decir desde el principio que las GPU son la minoría de lo que circula por nuestra render farm — la mayor parte del trabajo de producción aquí es todavía renderizado CPU (V-Ray, Corona, Arnold en CPU). Pero cuando alguien pregunta "¿vale la pena una segunda GPU?", merece números medidos, no un argumento de venta. Aquí están los números medidos.
Cómo Realizamos las Pruebas (y lo que Estos Números No Son)
Ambos nodos de prueba ejecutaron Windows 11 Pro con dos GPUs cada uno. El nodo 5090 usó el driver 596.36; el nodo 4090 usó el driver 610.62 — una tarjeta Blackwell requiere un driver más nuevo, por lo que no fue posible una coincidencia exacta. Esa diferencia de driver importa solo para una cosa: la comparación de velocidad absoluta entre generaciones del 5090 y el 4090. Los ratios de escalado en los que nos centramos aquí se miden dentro de un único nodo (misma tarjeta, mismo driver, una GPU frente a dos), por lo que la diferencia de driver no los afecta.
Cada escena es un benchmark estándar del fabricante — las escenas Open Data de Blender (bmw27, classroom, junkshop), la escena "Vultures" de Maxon para Redshift, el Chaos V-Ray Benchmark 6.00.02 y OctaneBench 2025.2.1. Ningún proyecto de cliente, ningún asset de producción. Aquí no publicamos minutos por fotograma, dólares por fotograma ni cifras de consumo eléctrico, porque este conjunto de datos no los contiene y no los inventamos.
Una nota metodológica que afecta a la lectura de las filas de Cycles: ejecutamos Blender Cycles al 200% de resolución, más pesado que el estándar de Open Data, específicamente para que cada renderizado dure suficiente y produzca un ratio de escalado estable y fiable. Eso significa que nuestros tiempos brutos de Cycles no son comparables con las puntuaciones públicas de Open Data — están ajustados para medir el escalado, no para competir en clasificaciones. Cycles y Redshift se miden en tiempo de renderizado (segundos, cuanto menor mejor); V-Ray y Octane se miden como puntuación de benchmark (vpaths o puntos de OctaneBench, cuanto mayor mejor). Estos son dos tipos de métricas distintos, por lo que los números absolutos nunca se comparan entre motores — solo el ratio de escalado dentro de un mismo motor es una comparación justa.
El Resultado Central: Escalado de 1x a 2x por Motor
Aquí están los datos principales — lo que realmente aporta una segunda tarjeta idéntica, por motor y escena:
| Motor | Escena | Escalado 2x RTX 5090 | Escalado 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1,54x | 1,58x |
| Cycles | classroom | 1,59x | 1,63x |
| Cycles | junkshop | 1,31x | 1,38x |
| Redshift | Vultures | 1,68x | 1,92x |
| V-Ray GPU (CUDA) | benchmark | 1,97x | 2,00x |
| V-Ray GPU (RTX) | benchmark | 2,00x | 2,00x |
| Octane | OctaneBench suite | 2,00x | 1,98x |
Leyendo de arriba a abajo, aparece una división clara. V-Ray y Octane se sitúan en 2,00x o justo por debajo en ambas tarjetas — una segunda GPU casi duplica el rendimiento. Cycles queda entre 1,31x y 1,63x. Redshift queda en 1,68x con el 5090 y en 1,92x con el 4090.
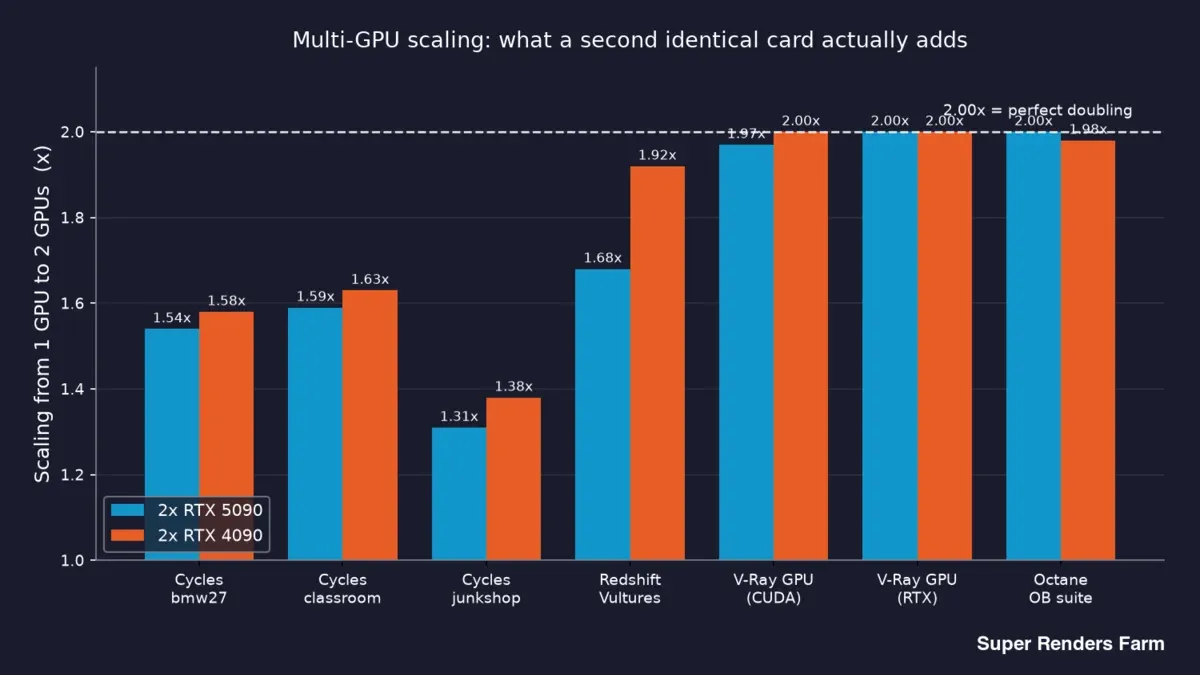
Gráfico de barras del escalado de 1 a 2 GPUs por motor en nodos duales RTX 5090 y RTX 4090: Cycles de 1,31x a 1,63x, Redshift 1,68x frente a 1,92x, V-Ray y Octane cerca de 2,00x
Así que "¿añadir una segunda GPU duplica mi velocidad?" tiene tres respuestas honestas distintas según lo que renderice: básicamente sí para V-Ray y Octane, aproximadamente 1,5x para Cycles, y en algún punto intermedio para Redshift. Quien le diga que un único multiplicador cubre todo el renderizado es que no lo ha medido realmente.
Por qué los Motores de Rendimiento Escalan Mejor que los Motores de Tiempo de Renderizado
El patrón no es aleatorio — proviene de cómo cada benchmark emplea su tiempo. V-Ray Benchmark y OctaneBench son pruebas de rendimiento. Lanzan una carga de trabajo sobre la capacidad de cómputo disponible y reportan una puntuación, y el coste fijo de configuración (cargar la escena, construir estructuras de aceleración, inicializar el dispositivo) es una fracción mínima del tiempo total. Añada una segunda tarjeta y casi todo ese silicio extra va directo al trabajo útil, por lo que se obtiene cerca de 2x. El resultado de V-Ray RTX alcanzando un 2,00x limpio en ambas tarjetas es exactamente lo que cabría esperar de una carga de trabajo donde la sobrecarga es prácticamente ruido.
Los motores de tiempo de renderizado se comportan de forma diferente. Cuando se mide un renderizado de Cycles o Redshift en segundos de reloj de pared, se cronometra el trabajo completo — y cada trabajo lleva consigo una porción fija de sobrecarga no paralelizable: análisis de la escena, construcción de la estructura BVH/de aceleración, compilación y calentamiento del kernel, coordinación del dispositivo, la resolución final de los píxeles. Una segunda GPU acelera la parte que realmente se puede dividir entre tarjetas. No hace nada por la parte fija. Cuanto mayor sea la fracción del tiempo total de renderizado que corresponde a la sobrecarga fija, más por debajo de 2x quedará el escalado.
Por eso Cycles junkshop (1,31x–1,38x) escala peor que Cycles classroom (1,59x–1,63x): junkshop es un renderizado más ligero y corto, por lo que su sobrecarga fija representa una fracción mayor del total, dejando menos para que la segunda tarjeta acelere. La escena classroom se ejecuta durante más tiempo, la porción paralela domina y la segunda GPU tiene más margen para ayudar. Mismo motor, mismo hardware — la escena decide cuánto importa la segunda tarjeta.
La Parte Contraintuitiva: La Tarjeta Más Rápida Escaló Menos
Mire de nuevo la fila de Redshift. Dos RTX 5090 escalaron 1,68x. Dos RTX 4090 escalaron 1,92x. La tarjeta más nueva y rápida escaló peor. Parece un error. No lo es — es el dato más instructivo de todo el conjunto.
Este es el mecanismo. El 5090 es la tarjeta más rápida en términos absolutos; con una sola GPU termina la escena Vultures en unos 57 segundos frente a los 100 segundos del 4090. Pero esa sobrecarga fija por renderizado — análisis, construcción, calentamiento — ocupa aproximadamente el mismo número de segundos independientemente de qué tarjeta lo ejecute. Con el 4090, esa porción fija es una fracción pequeña de un largo renderizado de 100 segundos, por lo que la segunda tarjeta tiene una gran porción paralela que procesar y el escalado queda cerca de 1,92x. Con el 5090, el renderizado ya es corto, por lo que esa misma porción fija es una fracción mayor del total, dejando una porción paralela más pequeña para que la segunda tarjeta acelere — y el escalado queda en 1,68x.
Fundamental: esto no significa que el 5090 sea peor. Es más rápido con una tarjeta y más rápido con dos. Simplemente gana proporcionalmente menos de la segunda GPU porque tenía menos renderizado lento que acelerar. Cuanto más rápido sea el renderizado base, más difícil es para una segunda tarjeta conseguir un 2x limpio — hay simplemente menos tiempo para paralelizar. Eso es algo genuinamente útil que comprender antes de gastar dinero apilando tarjetas idénticas esperando retornos lineales.
Velocidad por Tarjeta: RTX 5090 vs RTX 4090
El escalado es un eje; la velocidad bruta por tarjeta es el otro. Con una sola tarjeta, aplicada la advertencia del driver de la sección de metodología, el 5090 quedó por delante en todos los motores que probamos:
| Motor | Métrica | RTX 5090 | RTX 4090 | Ventaja del 5090 |
|---|---|---|---|---|
| Cycles — bmw27 | segundos (menor es mejor) | 49,45 | 77,40 | 1,57x |
| Cycles — classroom | segundos | 23,09 | 36,87 | 1,60x |
| Cycles — junkshop | segundos | 19,71 | 34,43 | 1,75x |
| Redshift — Vultures | segundos | 57 | 100 | 1,75x |
| V-Ray GPU (CUDA) | vpaths (mayor es mejor) | 11.051 | 7.419 | 1,49x |
| V-Ray GPU (RTX) | vpaths | 15.333 | 9.608 | 1,60x |
| Octane | Puntuación OctaneBench | 1.690,78 | 1.074,17 | 1,57x |
En conjunto, el 5090 es aproximadamente 1,5x a 1,75x más rápido por tarjeta. Dos conclusiones para quienes planifiquen hardware. Primero, las ganancias generacionales por tarjeta (1,5x–1,75x aquí) son mayores y más fiables que la ganancia de añadir una segunda tarjeta de la misma generación en un motor de tiempo de renderizado (a menudo bien por debajo de 2x). En términos simples: una tarjeta más rápida es con frecuencia una mejor palanca que una segunda tarjeta. Segundo, estos números de una sola tarjeta entre generaciones llevan la advertencia del driver incompatible — trátelos como una comparación orientativa, no como una garantía de nivel de servicio. Medimos en escenas de benchmark; la complejidad de su escena, el muestreo y la resolución de salida moverán el valor real. Para más información sobre el comportamiento del 5090 con una sola tarjeta, consulte nuestro análisis de rendimiento del RTX 5090 en cloud rendering de GPU.
Dos GPUs es el Límite por Nodo — y Por qué Eso Está Bien
Aquí es donde trazamos una línea firme, porque es la parte que la mayoría del contenido multi-GPU omite discretamente. Cada nodo de este benchmark es un nodo de dos GPUs. Dos tarjetas es el límite por nodo. No mostraremos una curva de escalado de 4x u 8x en un único nodo, porque esa no es una configuración que utilizamos, y no vamos a insinuar lo contrario.
Superar las dos GPUs en un único fotograma implica renderizado distribuido multi-nodo — dividir una imagen entre varias máquinas, con toda la coordinación de red, gestión de bloques/tiles y la sobrecarga que eso implica. Es una arquitectura genuinamente diferente, no una versión ampliada de una caja de dos tarjetas. No es algo que ofrezcamos hoy para un único fotograma, por lo que no vamos a presentarlo como una función "próximamente" con una fecha adjunta.
Y he aquí la clave: para la abrumadora mayoría del trabajo de producción, el límite de dos GPUs no es la restricción que importa. La restricción que aparece primero es casi siempre la VRAM, no el número de tarjetas — una escena que no cabe en 32 GB no se renderizará independientemente de cuántas GPUs se apunten a ella, lo cual es un problema completamente distinto (lo tratamos en límites de VRAM del RTX 5090 para escenas complejas). Cuando la gente imagina "escalar una render farm", normalmente piensa en un renderizado gigante que se vuelve cada vez más rápido con más y más silicio. Así no es como funciona realmente el rendimiento a escala de render farm.
Cómo Escala Realmente una Render Farm: Fotogramas, no Tarjetas
Esta es la distinción que vale la pena interiorizar, y es la que los números del benchmark señalan constantemente. Hay dos cosas completamente distintas que la gente quiere decir con "renderizar más rápido con más hardware":
- Dividir un fotograma entre muchas GPUs o máquinas (renderizado distribuido por tiles/bloques). Esto es lo que los números 1x→2x miden a escala de dos tarjetas, y lo que el renderizado distribuido multi-nodo extendería. Alcanza rápidamente rendimientos decrecientes en los motores de tiempo de renderizado, como muestran los datos, debido a la sobrecarga fija por renderizado — y el coste de coordinación solo crece al añadir máquinas.
- Distribuir muchos fotogramas entre muchas máquinas (renderizado paralelo por fotogramas). Cada nodo renderiza un fotograma completo por su cuenta; los fotogramas de una animación se distribuyen por toda la flota en paralelo. No hay sobrecarga de coordinación de un único fotograma que combatir, por lo que esto escala limpiamente y es cómo una animación se termina rápidamente.
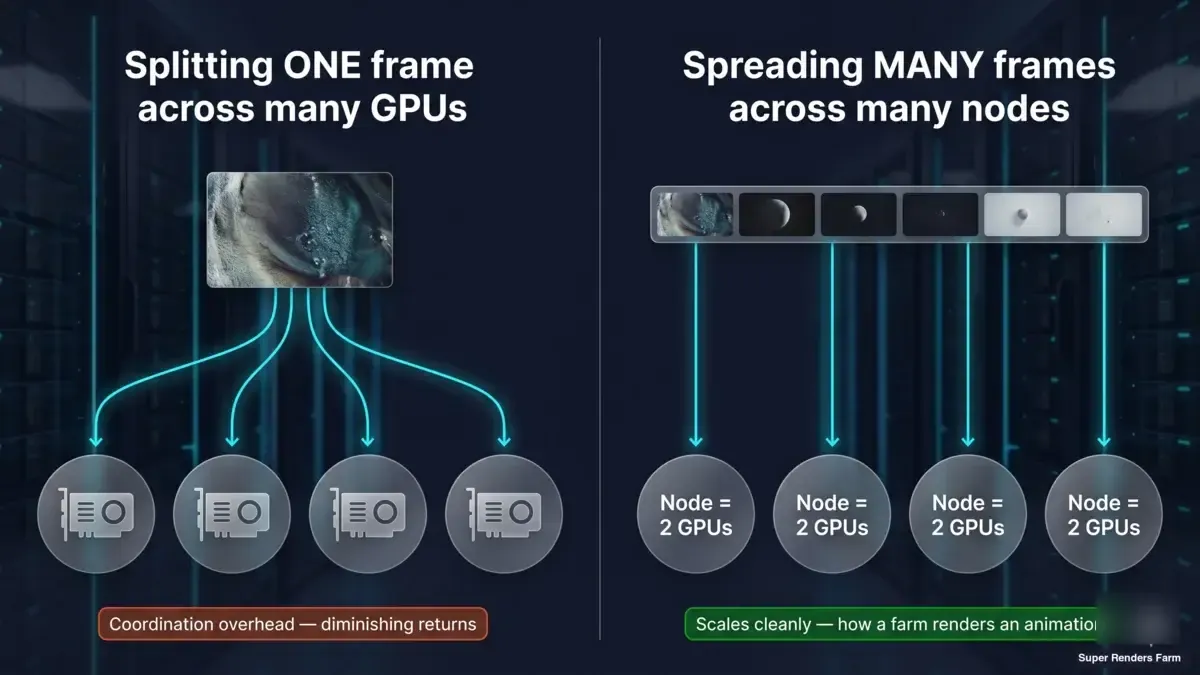
Diagrama conceptual en dos paneles: un fotograma dividido entre varias GPUs choca con la sobrecarga de coordinación y los rendimientos decrecientes; muchos fotogramas completos cada uno en su propio nodo de dos GPUs en paralelo escala limpiamente, así es como una render farm escala una animación
Una render farm gestionada obtiene su velocidad casi en su totalidad del segundo modelo. Su animación de 500 fotogramas no se renderiza como un fotograma extendido sobre 500 GPUs — se renderiza como 500 fotogramas distribuidos por la flota, cada uno en su propio nodo, todos al mismo tiempo. La velocidad por nodo y por fotograma está determinada por el tipo de escalado de dos GPUs y el rendimiento por tarjeta que hemos medido aquí; la velocidad a nivel de la render farm proviene de cuántos fotogramas se ejecutan de forma concurrente. Son palancas distintas, y confundirlas es donde comienza mucha de la confusión sobre "cuántas GPUs necesito".
Así que el encuadre honesto del multi-GPU es más estrecho que la versión de marketing. Dos tarjetas por nodo le dan un impulso real y medible — cerca de 2x en V-Ray y Octane, más moderado en Cycles y Redshift. Más allá de eso, la respuesta no es "apilar más tarjetas en la caja", sino "ejecutar más fotogramas en más nodos". Esa es la arquitectura, y ser claro al respecto tiende a ahorrar a la gente el dinero que estaban a punto de gastar en hardware que no habría rendido como esperaban.
Lo que Esto Significa al Elegir Cómo Renderizar
Reuniendo todo en algo con lo que pueda actuar. Si está decidiendo entre una tarjeta y dos para una estación de trabajo, el motor que utiliza habitualmente debería guiar la decisión: los usuarios de V-Ray u Octane obtienen cerca de un doblaje completo y la segunda tarjeta es fácil de justificar; los usuarios de Cycles y Redshift deben esperar un aumento de 1,3x–1,9x y sopesar si una única tarjeta más rápida (la ganancia generacional de 1,5x–1,75x) es el mejor gasto. Si está decidiendo entre renderizar localmente o encargarlo a una render farm, recuerde que la ventaja de la render farm es el rendimiento paralelo por fotogramas en una animación, no un multiplicador mágico de un único fotograma — un fotograma estático protagonista no se renderizará dramáticamente más rápido en una render farm que en una estación de trabajo comparable, pero unos pocos cientos de fotogramas absolutamente sí.
Para contexto sobre la compensación entre gestionado y hágalo usted mismo — quién se encarga de los drivers, las licencias y la configuración de los nodos — consulte nuestro análisis de render farm completamente gestionada vs DIY. En nuestra render farm, las licencias del motor de renderizado (V-Ray, Redshift, Octane) están incluidas en la tarifa de renderizado y la configuración del nodo es fija y mantenida para usted, por lo que la configuración de dos GPUs por nodo y los drivers detrás de estos números no son algo que deba ensamblar ni ajustar. Para el lado de Redshift en Cinema 4D específicamente, donde queda el escalado de 1,68x, consulte nuestra guía de render farm Redshift para Cinema 4D.
Las mediciones aquí son deliberadamente sin exageración. Una segunda GPU es una palanca real con límites reales, la tarjeta más rápida escala menos porque tenía menos renderizado lento que acelerar, y la velocidad a escala de render farm es una historia de distribución de fotogramas, no de apilamiento de tarjetas. Saber qué palanca aplica a su carga de trabajo es la mayor parte de la decisión.
FAQ
Q: ¿Añadir una segunda GPU duplica la velocidad de renderizado? A: Por lo general, no. En nuestros benchmarks de 2026, los motores de rendimiento como V-Ray y Octane escalaron cerca de 2,00x con una segunda tarjeta idéntica, pero los motores de tiempo de renderizado escalaron menos — Cycles quedó entre 1,31x y 1,63x y Redshift alcanzó 1,68x en RTX 5090 duales. La ganancia depende completamente del motor y la escena, porque cada renderizado lleva una sobrecarga fija que una segunda tarjeta no puede acelerar. Q: ¿Por qué Redshift escala mejor en el RTX 4090 que en el RTX 5090? A: Porque el 5090 es más rápido, sus renderizados son más cortos, por lo que la sobrecarga fija por renderizado (análisis de escena, construcción de la estructura de aceleración, calentamiento del kernel) representa una fracción mayor del total. Eso deja una porción paralela más pequeña para que la segunda tarjeta acelere, por lo que el escalado queda en 1,68x con el 5090 frente a 1,92x con el 4090. El 5090 sigue siendo más rápido tanto con una como con dos tarjetas — simplemente gana proporcionalmente menos de la segunda GPU. Q: ¿Cuánto más rápido es el RTX 5090 que el RTX 4090 para renderizar? A: Aproximadamente 1,5x a 1,75x más rápido por tarjeta en los motores que probamos, incluyendo Cycles, Redshift, V-Ray GPU y Octane. Estas cifras de una sola tarjeta entre generaciones llevan una advertencia menor porque las dos tarjetas ejecutaron diferentes drivers de NVIDIA, por lo que deben tratarse como una comparación orientativa más que como una garantía fija. Q: ¿Por qué V-Ray y Octane escalan mejor que Cycles y Redshift con dos GPUs? A: V-Ray Benchmark y OctaneBench son pruebas de rendimiento donde el coste fijo de configuración es una fracción mínima de la ejecución, por lo que una segunda tarjeta va casi en su totalidad al trabajo útil y el escalado se aproxima a 2,00x. Cycles y Redshift se miden como tiempo total de renderizado, que incluye sobrecarga no paralela que una segunda tarjeta no puede acelerar, por lo que su escalado queda por debajo de 2x. Q: ¿Puede una render farm hacer que un único fotograma se renderice más rápido en muchas máquinas? A: Dividir un fotograma entre múltiples máquinas es renderizado distribuido multi-nodo, que es una arquitectura distinta con su propia sobrecarga de coordinación y no es algo que ofrezcamos hoy para un único fotograma. Una render farm gestionada obtiene su velocidad del renderizado paralelo por fotogramas en su lugar — muchos fotogramas completos distribuidos entre muchos nodos al mismo tiempo — por lo que una animación termina rápidamente mientras que un fotograma estático protagonista se renderiza aproximadamente a la velocidad por nodo. Q: ¿Cuántas GPUs necesito realmente para renderizar? A: Para un único nodo, dos GPUs es un límite sensato y es lo que usan nuestros nodos de benchmark; más allá de eso, la restricción práctica suele ser la VRAM, no el número de tarjetas, ya que una escena que no cabe en memoria no se renderizará sin importar cuántas tarjetas añada. Si renderiza animaciones, el verdadero rendimiento proviene de ejecutar más fotogramas en más nodos en lugar de apilar más tarjetas en una máquina. Q: ¿Son estos números de benchmark comparables con las puntuaciones públicas de Blender Open Data? A: No. Ejecutamos Blender Cycles al 200% de resolución, más pesado que el estándar de Open Data, para que cada renderizado dure suficiente y produzca un ratio de escalado estable. Eso hace que nuestros tiempos brutos de Cycles sean intencionalmente no comparables con las clasificaciones públicas de Open Data — las escenas fueron ajustadas para medir el escalado, no para coincidir con las puntuaciones estándar. Q: ¿Necesito gestionar los drivers y las licencias de GPU para usar una render farm gestionada? A: No. En una render farm completamente gestionada, la configuración de los nodos, los drivers y las licencias del motor de renderizado (V-Ray, Redshift, Octane) se gestionan por usted e incluyen en la tarifa de renderizado, por lo que la configuración del nodo de dos GPUs y los drivers detrás de estos benchmarks no son algo que deba ensamblar ni ajustar. Cycles es gratuito y de código abierto, por lo que no lleva licencia separada.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



