
RTX 5090 en producción: 7 semanas de notas de campo en render farm (estudio de 38 escenas)
Resumen
Los benchmarks de lanzamiento de la RTX 5090 tienen más de un año, y todos describen lo mismo: una sola tarjeta, una escena preparada para la ocasión, condiciones ideales. Lo que casi nadie publica es la secuela — qué hace la tarjeta una vez que está enterrada en una cola de producción, renderizando las escenas de otras personas según un calendario que no controla. Así que revisamos los registros. Lo que sigue son las notas de campo a nivel de cola: los mismos datos de producción con los que planificamos la capacidad, presentados como números que usted puede verificar.
Esto son siete semanas de eso. Del 1 de abril al 22 de mayo de 2026 — 51 días — pusimos un nodo dual-RTX-5090 dentro de nuestra render farm activa y lo dejamos aceptar lo que la cola le asignara. Sin pruebas preparadas, sin fotogramas seleccionados a mano. El breve video a continuación repasa los números principales; las notas de campo completas vienen a continuación.
El nodo en sí no tiene nada de extraordinario: dos RTX 5090, 128 GiB de RAM, 32 núcleos lógicos a 4.3 GHz, Windows 11. Un detalle condiciona todas las cifras aquí — el planificador ejecuta una sola tarea de render por GPU, de modo que cada tarjeta renderiza su propio trabajo y cada número es un número limpio por tarjeta, la cifra que se multiplica para planificar capacidad. A lo largo del periodo, el nodo completó el 99.6% de sus tareas — 4,890 de aproximadamente 4,900 completadas, 18 fallidas. El planificador registra el fallo, no la causa, así que no especularemos sobre ella.
Cifras clave
- Periodo: 1 de abril – 22 de mayo de 2026 (51 días, ~7 semanas), un nodo dual-RTX-5090
- Finalización: 99.6% — 4,890 de ~4,900 tareas completadas, 18 fallidas (causa no registrada)
- Aceleración: mediana 3.2x por fotograma en Blender Cycles frente a nodos de generación anterior clase RTX 3080/2080 (tiempo medio por fotograma reducido ~69%); IC 95% 3.0–3.3x
- Dispersión: IQR 2.7–3.4x, rango completo 1.6x–5.1x en 38 escenas pareadas — ningún multiplicador único describe una cola
- Denoising con IA: ~83% de los trabajos de Cycles ejecutaron un paso de denoising con IA — la misma tasa que en el hardware anterior
- VRAM: mediana 5.6 GB, percentil 90 11.5 GB, trabajo más pesado ~37 GB
- Driver: un solo driver (581.80 / CUDA 13.0) durante todo el periodo, cero cambios
- Consumo: ~360–375 W/tarjeta bajo carga (banco controlado), con picos de ~400 W, a 68–83 °C — muy por debajo de la clase nominal de ~575 W
Lo que muestran 38 escenas pareadas
La comparación en la que más confiamos no es una prueba sintética, sino los trabajos que se ejecutaron en ambas generaciones en el curso normal del negocio — misma escena, mismo usuario, al menos tres tareas por lado antes de que una escena contara. El tiempo por fotograma es el tiempo de reloj de la tarea dividido por el número de fotogramas, directamente de la cola. En el periodo, 38 escenas superaron ese filtro, extraídas de 1,419 tareas de render individuales (503 en el nodo 5090, 916 en la generación anterior). Treinta y ocho no es el tamaño de nuestros datos; es lo que sobrevive a un filtro deliberadamente estricto.
| Métrica | Valor |
|---|---|
| Aceleración media por fotograma | 3.2x (≈69% de reducción de tiempo) |
| IC 95% bootstrap (mediana) | 3.0–3.3x |
| Rango intercuartílico | 2.7–3.4x |
| Rango completo | 1.6–5.1x |
| Escenas / tareas | 38 escenas / 1,419 tareas |
| Línea de base | clase RTX 3080/2080 de generación anterior (10–12 GB) |
Utilizamos una mediana de medianas: cada escena aporta la mediana de sus propios tiempos por fotograma en cada lado, y el 3.2x es la mediana de esas 38 ratios, de modo que un fotograma lento no puede sesgar el resultado. La dispersión importa tanto como el punto medio — la mitad central de las escenas se sitúa entre 2.7x y 3.4x, y el rango completo va de 1.6x a 5.1x.
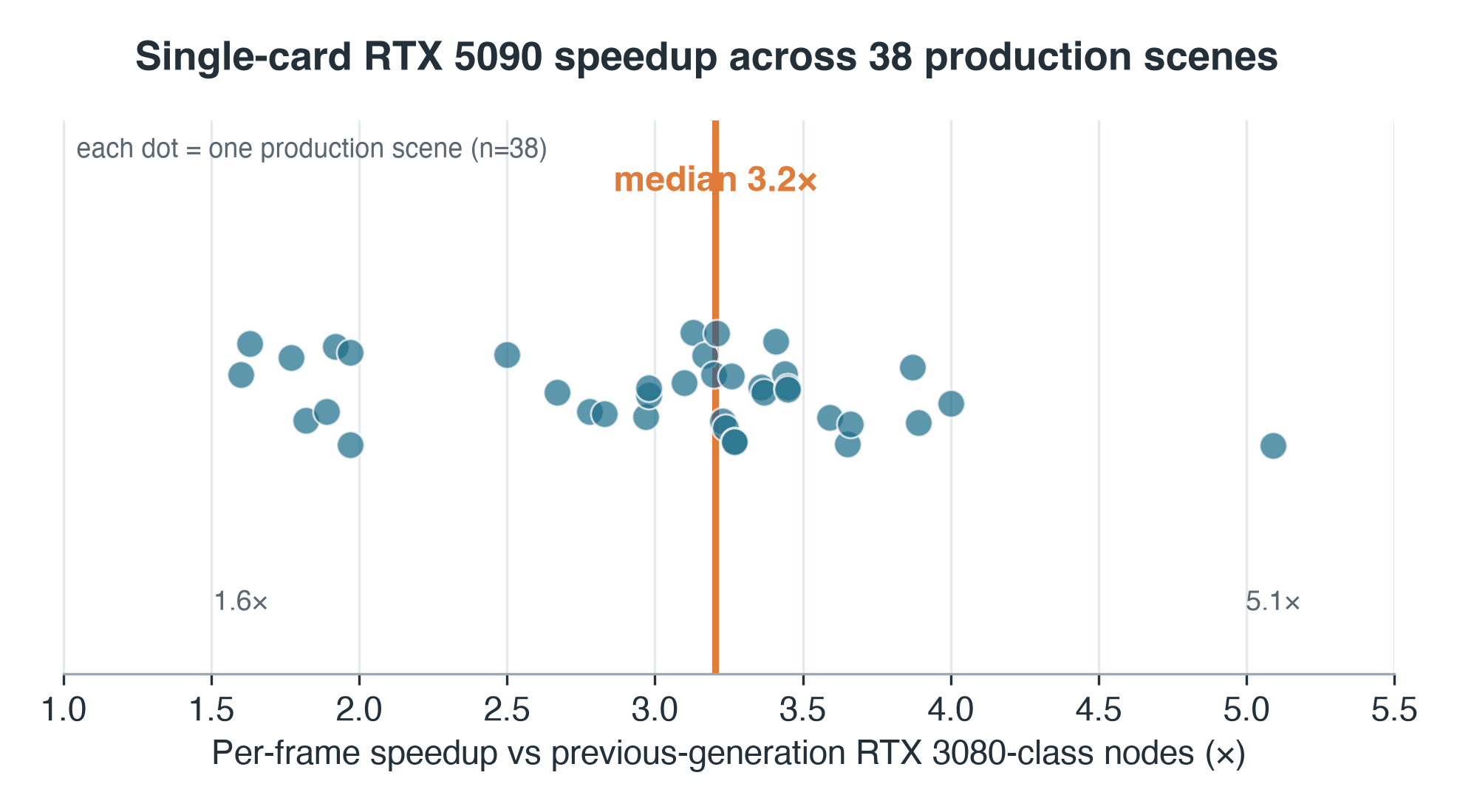
Aceleración por escena de la RTX 5090 en 38 escenas de producción de Blender Cycles, mediana 3.2x con una dispersión de 1.6 a 5.1x
Aceleración por escena, RTX 5090 frente a los nodos de generación anterior en los que se ejecutaron estos trabajos — muestra de producción de 38 escenas. Mediana 3.2x; rango 1.6–5.1x.
Dos advertencias pertenecen a ese número, no a una nota al pie. Primero, el lado de la generación anterior se ejecutó virtualizado — GPU passthrough dentro de una máquina virtual — de modo que una proporción no medida de este 3.2x corresponde a la sobrecarga de virtualización, no al silicio puro; la comparación limpia en el mismo host, una RTX 5090 frente a una RTX 4090 actual, es el experimento controlado que debemos hacer y aún no hemos realizado. Segundo, las 38 escenas no son una muestra aleatoria de la cola: son los trabajos que un usuario decidió volver a renderizar en ambas generaciones, lo que sesga la muestra hacia trabajos más largos e iterados — así que lea la distribución como la de los pares coincidentes, no la de toda la cola.
Tres notas de honestidad son fundamentales aquí. Estos son datos observacionales — los usuarios a veces ajustan sus configuraciones entre rerenderizados, y no congelamos sus escenas. La comparación es nodo contra nodo: el lado de la 5090 es una tarjeta bare-metal, el lado de la generación anterior se ejecuta como GPU passthrough dentro de máquinas virtuales, por lo que parte de la diferencia es de configuración, no de silicio. Y la línea de base son las tarjetas clase RTX 3080/2080 con las que estos trabajos se ejecutaron realmente — no una RTX 4090 actual; un enfrentamiento limpio con la tarjeta actual es un ejercicio controlado y separado que no hemos realizado. Estos son números de un solo nodo, solo Cycles; describen nuestra cola y no deben generalizarse a otros motores o hardware.
Lo que separa una escena de 1.6x de una de 5.1x es en parte visible en los datos. Si se representa la aceleración de cada escena frente al tiempo que tardaban sus fotogramas en el hardware antiguo, aparece una tendencia positiva suave — Spearman ρ ≈ 0.34 (p bilateral ≈ 0.04). Los fotogramas cortos, limitados por la sobrecarga, se sitúan en la parte inferior: cuando un fotograma tarda cinco segundos, el coste fijo por tarea — carga de escena, sincronización, la antigua capa de virtualización — consume la mayor parte del tiempo, y una tarjeta más rápida tiene poco margen de actuación. Los fotogramas más pesados, limitados por cómputo, ganan más. Pero hay dispersión real: una escena pesada se mantuvo en solo 1.6x porque su cuello de botella no era la GPU sino, posiblemente, el almacenamiento o una etapa limitada por CPU. La mediana dice una cosa; el rango dice que depende de la escena.
El denoising con IA ya era el estándar
Si se pregunta dónde encaja la IA en un pipeline de renderizado en producción en 2026, nuestros registros dan una respuesta nada glamurosa: en el denoiser. Aproximadamente el 83% de los trabajos de Cycles en el nodo 5090 ejecutaron un paso de denoising con IA — OptiX o Intel Open Image Denoise — y la tasa en nuestros nodos de generación anterior es esencialmente idéntica. La nueva tarjeta no inició el hábito; ya era estándar en el hardware antiguo y siguió siéndolo en el nuevo. Para un pipeline con mucho denoising, un salto de generación no le compra una «IA» que ya estaba ahí — le compra rendimiento de path-tracing alrededor de un paso que ya era rutinario. Esta cifra es intencional solo para Cycles; sea escéptico ante cualquier «% de IA» en una render farm que no esté vinculado a un motor específico.
VRAM en condiciones reales
Cycles escribe el pico de memoria del dispositivo en el registro de render — un dato modesto pero utilizable como aproximación de lo que la producción realmente exige a la VRAM. En los 57 trabajos de Cycles donde se registró esa línea, la memoria pico del dispositivo de render fue de aproximadamente 5.6 GB en la mediana y 11.5 GB en el percentil 90. Nuestras tarjetas de generación anterior son de 10–12 GB, por lo que el trabajo mediano habría cabido — pero el trabajo en el percentil 90 ya rozaba su límite. Y la cola se extiende más allá: el trabajo más pesado registró aproximadamente 37 GB, por encima incluso de los 32 GB propios de la 5090 — el tipo de escena que en una GPU significa recurrir a la CPU o no poder renderizar en absoluto. El registro no lleva metadatos de escena, así que no podemos decirle qué tipo de escena era — solo su clase: un conjunto de trabajo de 37 GB es la firma de geometría pesada, texturas de alta resolución o volumétricas, el tipo de trabajo que supera incluso una tarjeta de 32 GB y, en una sola GPU, simplemente se detiene. La regla del operador sigue vigente: se dimensiona la VRAM para la cola, no para la mediana. Por eso existen tanto la memoria oversized en la tarjeta como la capacidad compartida de render farm en la nube con GPU — para poder elegir una tarjeta mayor por trabajo en lugar de comprar una.
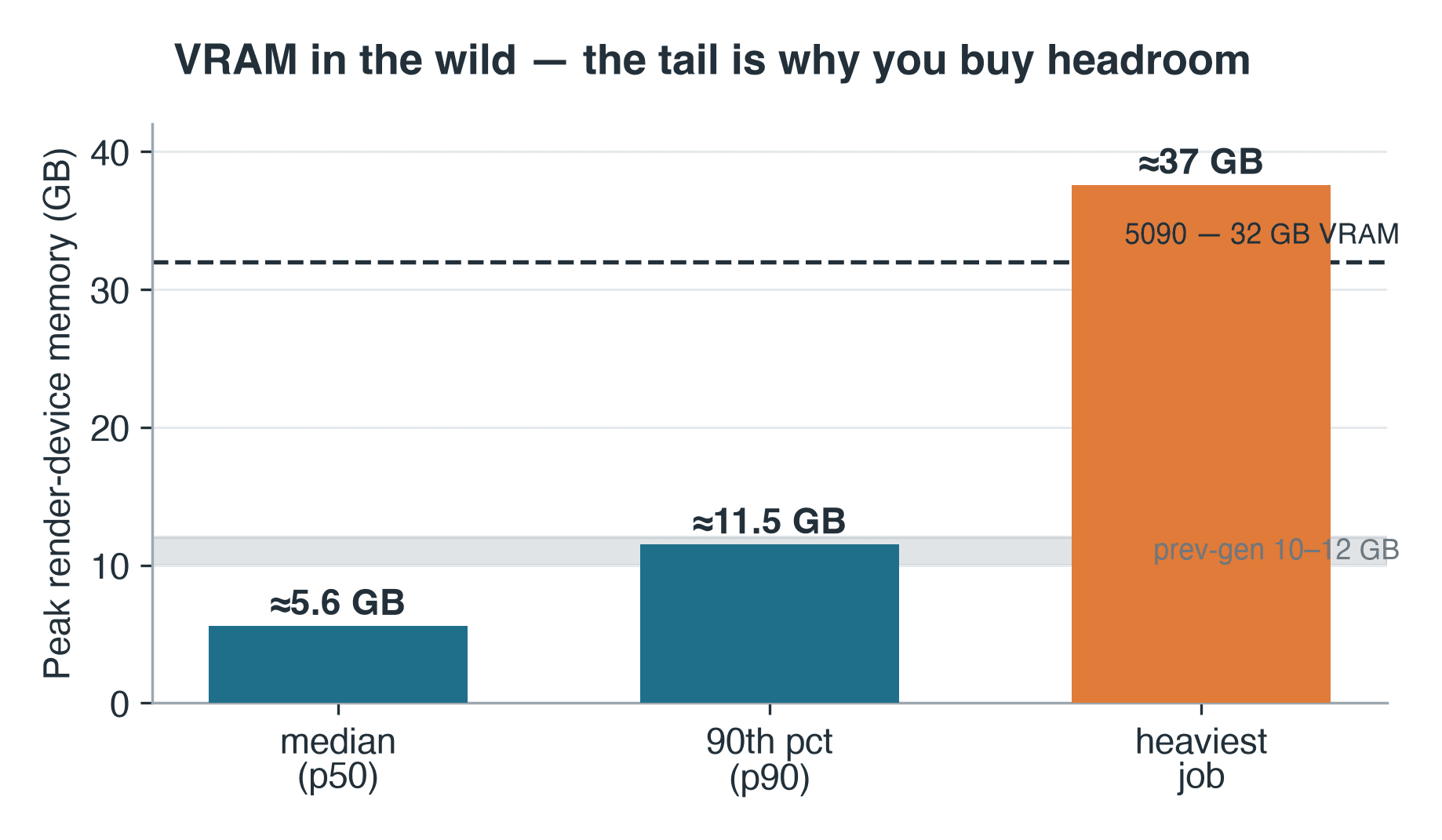
Memoria pico del dispositivo de render para trabajos de Blender Cycles en el nodo RTX 5090: mediana 5.6 GB, percentil 90 11.5 GB, trabajo más pesado 37 GB
Memoria pico del dispositivo de render en 57 trabajos de Cycles registrados. El trabajo más pesado superó incluso los 32 GB propios de la 5090.
Un solo driver y consumo acotado
El hallazgo menos dramático es el que más querríamos conocer antes de comprar. Un solo driver — 581.80, en CUDA 13.0 — ejecutó todo el periodo con cero cambios: sin reversiones, sin intercambios a mitad de periodo. Para hardware de ciclo temprano en una cola de producción, un registro de driver aburrido es el mejor cumplido.
El consumo fue igualmente tranquilo. En un banco controlado del mismo hardware bajo carga sostenida, cada tarjeta consumió aproximadamente 360–375 W (con picos cercanos a 400) a 68–83 °C — la tarjeta superior en un par apilado siendo la más caliente, pero muy por debajo de la clase nominal de ~575 W. Calcule el presupuesto para ese consumo sostenido, no para el pico nominal. La energía por fotograma terminado resulta en aproximadamente 2.5 Wh con un fotograma medio de Cycles de unos 24 segundos — pero trátelo como una inferencia: se apoya en el consumo del banco y se calculó solo para la 5090, no medido frente a los nodos más antiguos.
Por qué estas notas comienzan con Blender
En los últimos 90 días, los trabajos de GPU representaron aproximadamente una cuarta parte de todo lo que renderizó nuestra render farm — el resto es trabajo de CPU. Dentro de la mezcla de GPU, Cycles representa aproximadamente el 74% de los trabajos y Redshift es un claro segundo con aproximadamente el 15%, que es por qué un informe sobre RTX 5090 en render farm comienza con renderizado en la nube con Blender. Para ver cómo se comportan varias de estas tarjetas juntas, consulte nuestras notas complementarias sobre rendimiento del clúster RTX 5090, y para el límite de memoria específicamente, dónde los límites de VRAM afectan en escenas complejas.
Dos conclusiones emergen de esta cola. Primero, la producción no es un benchmark — una tarjeta que publica un número limpio en laboratorio todavía tiene que absorber la sobrecarga de virtualización, cargas de trabajo mixtas y escenas para las que nunca se ajustó, y el resultado es una distribución, no un punto. Segundo, la mediana no es la cola. Una aceleración típica de 3.2x y un pico de memoria de 37 GB en un solo trabajo son ambos ciertos a la vez, y se planifica la capacidad teniendo en cuenta ambos. La tarjeta es genuinamente rápida donde el trabajo es pesado. Donde no lo es, la cola explica por qué.
Método, en resumen
Cada cifra aquí proviene de los propios registros de tareas de nuestro planificador, no de una prueba preparada. El tiempo por fotograma es el tiempo de reloj de la tarea dividido por el número de fotogramas; la aceleración principal es una mediana de medianas por escena en los 38 pares coincidentes, y el intervalo de confianza es un bootstrap de 20,000 muestras. Tenga en cuenta qué muestra respalda cada afirmación: 38 escenas pareadas para la aceleración, 57 trabajos registrados para la VRAM, y un banco controlado separado para consumo y temperatura — no la cola de producción. Las 18 tareas que fallaron (de aproximadamente 4,900) se cuentan como fallos, no se descartan; el planificador registra el estado pero no la causa, así que las dejamos sin investigar en lugar de especular. Nada de esto es difícil de reproducir en esencia — es lo que cualquier operador puede extraer de sus propios registros de cola, y estamos encantados de explicar el método con más detalle a cualquier estudio que lo solicite.
FAQ
Q: ¿Cuánto más rápida es la RTX 5090 que la generación anterior para Blender Cycles? A: En 38 escenas de producción pareadas (misma escena y usuario en ambas generaciones), el tiempo medio por fotograma se redujo aproximadamente un 69% — una aceleración media de 3.2x, con un intervalo de confianza bootstrap del 95% de 3.0–3.3x. Las escenas individuales oscilaron entre 1.6x y 5.1x. Se trata de datos observacionales nodo contra nodo, no de un benchmark controlado.
Q: ¿Por qué varían tanto las aceleraciones entre escenas? A: La aceleración sigue la carga de trabajo por fotograma con una tendencia positiva suave (Spearman ρ ≈ 0.34). Los fotogramas cortos, limitados por la sobrecarga, ganan menos porque el coste fijo por tarea — carga de escena, sincronización, la antigua capa de virtualización — domina; los fotogramas más pesados, limitados por cómputo, ganan más. Una escena pesada se mantuvo en 1.6x porque su cuello de botella era el almacenamiento o una etapa limitada por CPU, no la GPU.
Q: ¿Es este un benchmark controlado que puedo comparar con mi propio hardware? A: No. Estas son notas de campo observacionales de un nodo de producción activo, solo Blender Cycles. Los usuarios ajustaron sus propias escenas entre rerenderizados, y la comparación es nodo contra nodo — una 5090 bare-metal frente a nodos de generación anterior virtualizados — por lo que parte de la diferencia es de configuración, no de silicio. La línea de base es hardware clase RTX 3080/2080, no una RTX 4090 actual.
Q: ¿Cuánta VRAM usaron realmente las escenas de producción? A: En 57 trabajos de Cycles registrados, la memoria pico del dispositivo de render fue de aproximadamente 5.6 GB en la mediana y 11.5 GB en el percentil 90. El trabajo individual más pesado registró aproximadamente 37 GB — por encima de los 32 GB propios de la 5090 — lo que en una GPU significa recurrir a la CPU o no poder renderizar. Dimensione la VRAM para la cola, no para la mediana.
Q: ¿Cambió la RTX 5090 la frecuencia con que se usó el denoising con IA? A: No. Aproximadamente el 83% de los trabajos de Cycles en el nodo 5090 ejecutaron un paso de denoising con IA (OptiX o Intel Open Image Denoise) — y la tasa era esencialmente la misma en la generación anterior. El denoising con IA ya era estándar; la nueva tarjeta solo cambió la velocidad de todo lo que lo rodea.
Q: ¿Qué tan estable fue el driver durante las siete semanas? A: Un solo driver — 581.80 en CUDA 13.0 — ejecutó todo el periodo de 51 días con cero cambios: sin reversiones, sin intercambios a mitad de periodo. Para hardware de ciclo temprano en una cola de producción, esa estabilidad es un resultado significativo por sí mismo.
Q: ¿Cuál fue el consumo y la temperatura bajo carga? A: En un banco controlado bajo carga sostenida, cada tarjeta consumió aproximadamente 360–375 W, con picos cercanos a 400 W, a 68–83 °C — cómodamente por debajo de la clase nominal de ~575 W de la tarjeta. La energía por fotograma resulta en aproximadamente 2.5 Wh, que es una inferencia a partir de esa medición en banco, calculada solo para la 5090.
Q: ¿Se aplican estos números a otros motores de renderizado? A: No. Este estudio es solo GPU de Blender Cycles, en un único nodo. Otros motores registran el denoising, la memoria y el tiempo de manera diferente. Trate estas como notas de campo específicas de Cycles, no como una afirmación válida para toda la render farm o para todos los motores.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



