
Render Farm Network Segmentation and WireGuard Security: A Tier-1 + Tier-2 Architecture
Overview
Introduction
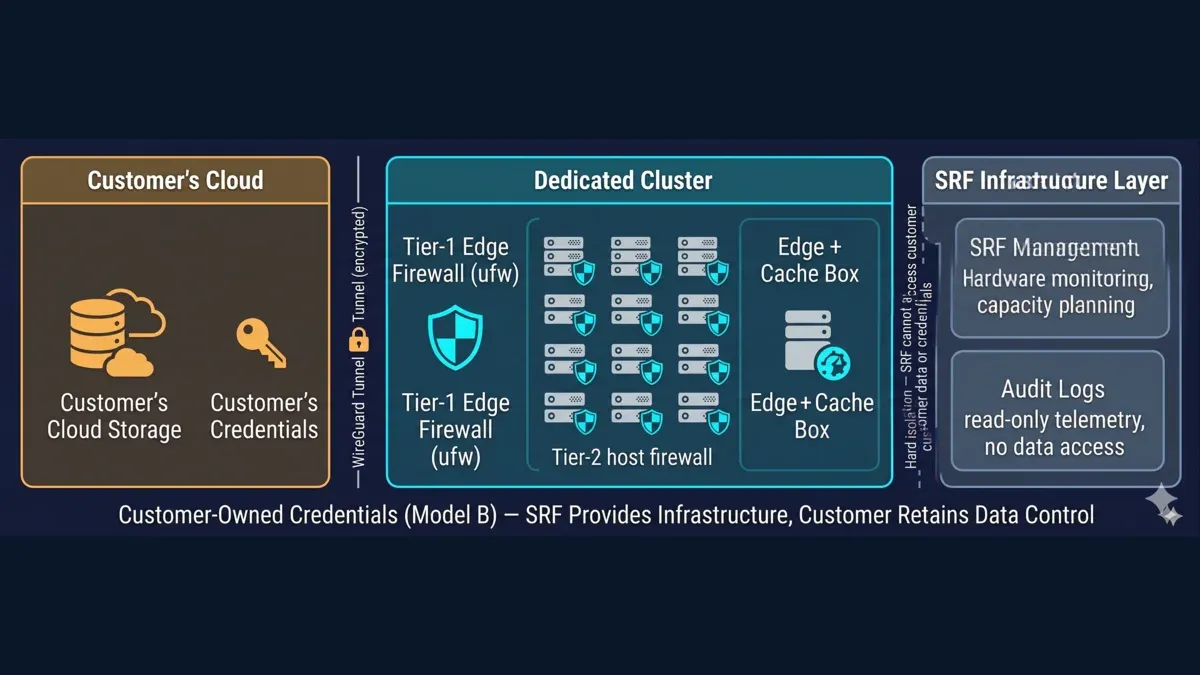
The end-to-end security boundary — customer cloud storage and credentials reaching a dedicated cluster across an encrypted WireGuard tunnel, with a Tier-1 edge firewall and Tier-2 host firewalls inside, and an SRF infrastructure layer hard-isolated from customer data under the customer-owned-credentials Model B pattern.
A render farm is a network problem before it is a rendering problem. Frames flow between a submission machine, a manager, a fleet of workers, an asset cache, and an output store; credentials flow between artists and license servers; remote sessions flow between artists and the workstation surface they are driving. When the network is one switch in one room, the security model is mostly perimeter. When the farm spans datacenters or continents, the perimeter is no longer a useful unit of analysis: every link that crosses a building boundary is a public-internet link until proven otherwise, every credential that touches a remote system can be intercepted, and every worker that can reach every other worker is a worker that can pivot if it is ever compromised.
This article describes the security architecture we run for cross-site and cross-country render farm deployments — a two-tier firewall model with a default-deny edge, per-node host firewalls behind it, WireGuard end-to-end encryption for every link that crosses a building boundary, least-privilege access patterns for every operator role, and customer isolation primitives that scale from shared multi-tenant infrastructure to dedicated single-customer clusters. The audience is IT security teams evaluating cloud-rendering vendors, compliance officers asking whether their auditor will find a render-farm vendor acceptable, and pipeline architects designing the network shape of a new build. A separate writeup on the network architecture — WireGuard hub-and-spoke, BBR, MSS clamping, and the shared SMB cache layer — covers the transport side; this article covers what happens above the wire.
Network Segmentation Principles for Render Farm

Concentric segmentation tiers wrapping the render cluster's core nodes — a default-deny Tier-1 edge on the outside and per-node Tier-2 host firewalls within, so traffic crosses only at controlled gates.
Segmentation in this context means three separate things. First, no node can reach any other node it does not need to reach for its job. A render worker needs to read assets from the cache, pull jobs from the manager, write outputs back to a known location, and send heartbeat telemetry — and nothing else. A compromised worker that cannot pivot to other workers, cannot reach operator SSH, and cannot reach the management plane is a contained failure rather than a cluster-wide failure. Lateral movement is the single most consequential thing a segmentation policy prevents.
Second, no customer can reach any other customer. On multi-tenant infrastructure, this means processes, user accounts, file system paths, and license check-outs are isolated per customer at the operating-system level. On dedicated cluster infrastructure, this means physical hardware boundaries, separate WireGuard hubs, separate credential stores, and separate operational management surfaces. The strength of the isolation should match the sensitivity of the workload — a freelancer rendering product visualization and a studio rendering pre-release entertainment work do not need the same isolation level, but they should be able to choose the level that fits their threat model.
Third, no customer can reach the operator's internal systems beyond the surface a job actually needs. A render submission writes to the manager's job queue and reads its own outputs; it does not need to enumerate other customers, read the operator's billing database, or reach the operator's source control. This is the privilege boundary that protects every customer from every other customer through the operator's own systems.
The tier model we run reflects these three principles. Tier 1 is the perimeter — the edge gateway facing the public internet that decides what traffic enters at all. Tier 2 is the per-node host firewall — every machine inside the perimeter independently decides which peers it accepts connections from. Above both tiers, application-layer access controls enforce role separation, customer isolation, and the audit boundary compliance reviews care about. Each tier is independently auditable; a failure at one does not collapse the others.
Tier-1 Edge with ufw and Default-Deny
The edge of the cluster is a single Linux gateway running ufw, the canonical front end for nftables on Ubuntu LTS. The configured posture is default deny incoming and default allow outgoing. The only inbound rule on the public interface is allow 51820/udp for WireGuard. Nothing else accepts traffic from the public side — not SSH, not HTTPS, not SMB, not the render manager API, not monitoring agents. Those services bind to internal interfaces only; reaching them from outside the cluster requires terminating a WireGuard tunnel first.
The reasoning is mechanical. Every open port on the public internet is scanned within minutes and probed continuously thereafter. Reducing the count of public ports to exactly one, and making that port speak a protocol that does not respond to unauthenticated probes (WireGuard answers nothing to a peer it does not know), reduces the attack surface to the smallest meaningful unit. SSH behind a WireGuard tunnel is a target the attacker cannot reach without first defeating WireGuard.
The forward chain needs explicit attention. The gateway acts as a router between the WireGuard interface and the internal cluster subnet, and ufw's default forward posture is deny. We set DEFAULT_FORWARD_POLICY="ACCEPT" in /etc/default/ufw, then narrow the forwarded flows with explicit FORWARD chain rules that allow traffic between known cluster subnets and deny everything else. The result is a perimeter that is auditable and does not accidentally route a packet to a destination no one intended.
Outbound rules deserve similar discipline. Workers pull from a small set of upstream asset stores, the manager talks to a small set of license servers, telemetry ships to a small set of monitoring endpoints, and OS package updates pull from a known mirror. Locking outbound destinations to that small set blocks an entire class of post-compromise behaviors: a compromised worker that wants to exfiltrate data to an attacker-controlled host cannot reach it because the host is not on the egress allowlist. Egress filtering turns invisible exfiltration into a noisy attempt monitoring can flag.
Logging on the Tier-1 edge records every dropped inbound packet and every forwarded flow on the router chain, shipped to a central log host behind the same WireGuard tunnel reachable only from authenticated operator workstations. Logs are the primary source of audit evidence for compliance reviews.
Tier-2 Host Firewall on Every Node
The Tier-1 edge is necessary and not sufficient. A worker reachable from every other worker on the internal subnet is one compromise away from a cluster-wide pivot, regardless of how strong the edge is. Tier 2 is the answer: every machine inside the perimeter runs its own host firewall with its own ruleset, independently deciding which peers it accepts connections from.
On Linux nodes the host firewall is ufw, configured with the same default-deny inbound posture as the edge but with internal rules allowing only what the node's role requires. A render worker accepts SMB from the cache box, render-manager job protocol from the manager, monitoring telemetry from the monitoring host, and SSH from the operator bastion subnet. Everything else, including connections from other workers, is denied. A compromised worker cannot probe its neighbor because the neighbor will not accept the connection — the Tier-1 edge has been defeated in this hypothetical, and the Tier-2 host firewall is the second line that has not been.
On Windows nodes the host firewall is Windows Defender Firewall with advanced security, configured with equivalent rules. Inbound RDP is restricted to a narrow operator subnet for emergency support; the customer's remote-desktop protocol (a dedicated streaming port for Moonlight or equivalent) is allowed from the customer's WireGuard peer address only; everything else is denied. For the use case — enforce a small ruleset on a fleet of identically-configured machines — Windows Defender Firewall is fully adequate, and the management surface integrates with Group Policy.
Group membership is the unit of policy. Nodes are grouped by role and customer: customer-A workers are one group, customer-B workers another, operator-management nodes a third, cache and storage a fourth. Cross-group connections require an explicit rule and are denied by default. A customer-A worker cannot SMB-mount customer-B's cache, cannot RDP to customer-B's workstation, and cannot pull a job from a customer-B manager — not because the application layer is enforcing this, but because the host firewall does not allow the TCP handshake to complete.
Host firewall rules are managed via configuration management so they are version-controlled, reviewable, and consistent across every node. A misconfigured firewall on one node out of twenty is hard to detect by inspection and easy to catch with drift detection.
WireGuard End-to-End Encryption
Every link that crosses a building boundary is encrypted with WireGuard. Artist workstations tunnel WireGuard to the cluster gateway. Site-to-site links tunnel WireGuard between gateways. Operator SSH sessions tunnel WireGuard from the operator's laptop to the cluster bastion. The internal cluster LAN inside one building is not WireGuard-encrypted — that traffic is on a switch in a room we control — but anything that leaves the building is.
WireGuard's appeal here is a property that has nothing to do with cryptography per se: there is no plaintext fallback. WireGuard does not negotiate cipher suites, does not select algorithms at runtime, and does not have a "this peer asked for an older cipher so we are going to oblige" code path. Every tunnel uses Curve25519 for key exchange, ChaCha20-Poly1305 for the data plane, BLAKE2s for hashing, and Poly1305 for message authentication. The cipher choices are fixed at the protocol level. A meaningful class of attacks on TLS-style negotiated protocols — downgrade attacks, weak-cipher selection, broken-cipher legacy fallback — does not apply because the protocol does not have the negotiation step those attacks target.
Per-peer keys are the second property. Every peer has its own public key, and the hub explicitly allows or denies each peer based on its key and AllowedIPs. There is no shared secret. If one workstation's private key leaks, the fix is to remove that peer and reissue a new keypair for that one workstation; every other peer continues undisturbed. Forward secrecy is the third property: WireGuard rotates session keys regularly, and long-term keys are used only for the initial handshake. An attacker who records traffic and later compromises a long-term key cannot decrypt the recorded traffic, because the session key derived from the ephemeral exchange no longer exists.
The kernel-level implementation is the fourth property, and it determines whether the architecture is operationally tolerable at scale. WireGuard has shipped in the mainline Linux kernel since 5.6. On a typical Xeon gateway, kernel WireGuard sustains gigabit-class throughput per peer at single-digit CPU cost. For a gateway also doing routing, firewall, and DNS, kernel vs userspace crypto is the difference between a comfortable box and a saturated one.
Least-Privilege Access Patterns
A least-privilege access map where only the specific node-to-node routes each role needs are open — a worker reaches the cache, manager, and monitoring host and nothing else — while every other path stays closed.
Every account inside the cluster has the minimum privileges required to do its job, and operator roles are separated so no single role can do everything. Four account classes matter on the deployments we run.
Customer remote-desktop accounts log in to the customer's workstation surface with access to the customer's own data and DCC environment. They do not have shell access to the underlying operating system. The customer drives the DCC through the remote-desktop protocol, submits renders, downloads outputs, and never touches the OS administration layer.
Which remote-desktop protocol carries that session — and how Moonlight, Parsec, and RDP compare on latency and security — is covered in our GPU remote-desktop protocol comparison. A compromised customer account cannot reach OS-level credentials, license-server passwords, or shared cluster infrastructure.
Operator DevOps accounts have SSH access to Linux nodes through the bastion. Bastion access requires the operator to authenticate over WireGuard first, then to the bastion with a hardware-backed key, then to the destination node with a per-account key. Two-factor authentication is enforced at the bastion. Every SSH session is logged to a central audit log the operator's own account cannot modify or delete — start time, source address, destination node, duration, and command history.
Monitoring agents on each node have a dedicated service account with read-only access to the metrics they collect. They cannot execute arbitrary commands, cannot read application data, and cannot write to any persistent location other than their own log file. The principle is that observation should not require modification rights. Storage access is enforced by SMB ACLs at the cache and NAS layer: a customer-A worker mounting the cache sees only customer-A's directory tree; the SMB server enforces this at the file system layer rather than relying on the worker.
The role separation that matters most is the separation between operator and customer. The operator does not have remote-desktop access to customer workstations except through an audited support session the customer must explicitly authorize. The customer does not have OS-level access to the operator's infrastructure. This boundary — enforced at the WireGuard layer (separate peer configurations), the host firewall layer (separate access rules), and the application layer (separate auth realms) — is the boundary that lets a customer trust their workload is theirs alone.
Customer Isolation: Multi-Tenant vs Dedicated Cluster
Customer isolation has two practical implementations. Multi-tenant SaaS infrastructure runs many customers' jobs on a shared fleet, isolating them at the OS level — separate user accounts, file system paths, process groups, and license check-out scopes. Dedicated cluster infrastructure runs one customer's jobs on hardware allocated to that one customer for the duration of the engagement, with no other customer's processes, accounts, or data touching the same machines.
Multi-tenant isolation is the default, and for most workloads it is the correct choice — economics are better, and process-level isolation combined with file system ACLs and the host firewall rules above prevents the cross-customer access patterns that matter in practice. Dedicated cluster isolation is the right choice when the workload's value, regulatory environment, or contractual obligations require a stronger boundary. The motivating threat model is: what if OS-level isolation has a vulnerability we do not yet know about, or what if the operator's own internal access is itself the attack vector? On dedicated hardware, the answers are bounded by physics — the customer's data lives on the customer's drives, processes run on the customer's CPUs and GPUs, the customer's WireGuard hub serves only the customer's peers, and operator access can be configured to require explicit per-session authorization. A class of risks moves from "trust the operator's multi-tenant implementation" to "trust the customer's own hardware boundary."
The customer-owned-credentials model — BYOC, where the customer's DCC licenses and asset-store credentials are entered by the customer and never seen by the operator — is the natural pairing with dedicated cluster; see the customer-owned credentials writeup for the full model. Dedicated hardware plus customer-owned credentials means the operator runs the infrastructure but does not see authentication material, source files, or project data. The operator's role becomes "keep the infrastructure healthy" rather than "have access to the customer's data and choose not to use it."
When to choose dedicated over multi-tenant is workload-specific. We see customers choose dedicated when one of three conditions is present: an IP-sensitivity threshold set in writing by the customer's legal or compliance team; a regulatory framework that requires demonstrable per-customer data isolation; or a scale threshold where the cost difference becomes small enough that the isolation upside dominates. A separate article covers the SaaS vs dedicated cluster decision framework in more depth.
Compliance Readiness (Without Certification Claims)
The honest disclosure first: Super Renders Farm is not currently SOC 2 certified, is not currently ISO 27001 certified, and does not hold any other formal information-security certification we would represent to a compliance reviewer as "we have the certificate, you can take it as evidence." Any customer whose own compliance program requires their vendors to be certified should know this before signing a contract.
What we provide is a set of technical building blocks an auditor reviewing a customer's compliance program can examine — the components of the architecture in this article, viewed through the control families SOC 2 and ISO 27001 share at the technical layer.
Encryption at-rest and in-transit. Data in transit between the customer and the cluster, and between cluster nodes that span buildings, is encrypted by WireGuard (Curve25519 + ChaCha20-Poly1305). Data at rest on the cache and storage layer uses native OS encryption-at-rest features where the customer requests them; this is configurable per engagement because the tradeoffs vary by workload. SMB3 is configured to require in-transit encryption on cross-site traffic.
Audit trail capability. SSH session logs are recorded with source, destination, duration, and command history on a log host operator accounts cannot modify. WireGuard handshake logs record every peer connection attempt. Render job logs record submission time, parameters, completion status, and resource usage per customer. These logs can be exported for the customer's auditor on request.
Access control and segregation. The Tier-1 + Tier-2 firewall model is the segregation control. Operator-vs-customer role separation is the role-based access control. Per-customer firewall group memberships in the dedicated cluster model are the customer-isolation control. Each is auditable independently as text. Data destruction at end-of-engagement follows a documented procedure — file-level deletion, free-space overwrite, and an attestation letter signed by the operator recording what was destroyed, when, and by whom. The attestation is the artifact the customer's compliance program files as evidence.
Network monitoring. The cluster runs flow logging on the gateway and host-level monitoring on each node. Continuous network intrusion detection at the level a SOC 2 "continuous monitoring" objective would require is on the internal roadmap but not currently deployed.
The framing that matters: the operator's infrastructure is one component of the customer's compliance program, not the program itself. A customer pursuing SOC 2 or ISO 27001 certification is evaluated on the totality of their controls, of which the rendering vendor is one input. Our job is to provide building blocks the customer's program can rely on, and to be honest about which controls are mature, which are partial, and which are not yet in scope.
Threat Model

The threat model — external probes and lateral-movement attempts striking the cluster's layered defenses from every side, with the core render assets contained behind the segmentation and encryption boundary.
Architecture documents that do not include a threat model tend to imply the architecture defends against everything, which is never true. The scope of what this architecture addresses is bounded; the failures it does not address are real and worth naming explicitly.
What the architecture defends against. External attacker scanning and probing: the Tier-1 default-deny posture and WireGuard's authenticate-before-accept behavior mean the cluster's only response to an unauthenticated scan is silence — no banner to fingerprint, no version string to attack, no auth prompt to brute-force. Lateral movement after a single-node compromise: the Tier-2 host firewall means a compromised worker cannot scan or pivot to its neighbors, cannot reach the management plane, and cannot reach the operator's bastion. Blast radius is one node plus whatever it had legitimate access to — meaningful, but not cluster-wide. Credential theft of operator credentials used against the customer: on the dedicated cluster with customer-owned credentials, the operator does not hold the customer's licenses, asset-store credentials, or project decryption keys, so a compromise of the operator's credential store does not expose customer auth material. Data exfiltration through operator staff, meaningfully but not absolutely: operator SSH access requires audited bastion sessions, hardware-backed keys, and per-session authorization, raising the cost of a malicious-insider scenario substantially though not to zero.
What the architecture does not fully defend against. Supply-chain attacks: operating systems, DCCs, plugins, render engines, and the kernel itself are software written by parties other than the operator; we can mitigate (patch management, host hardening, segmentation that limits what a compromised binary can reach) but cannot eliminate. Supply-chain risk is a category we share with everyone in the industry rather than one we have solved. Insider threats with admin access: an operator with bastion access, audit-log access, and sustained intent to misuse those privileges is constrained by audit logs, two-factor authentication, role separation, and the per-customer dedicated cluster boundary — but is not eliminated. Operator hiring, background checks, and audit-trail visibility customers can themselves review are the controls that address this. Customer credential hygiene: if a customer's WireGuard private key leaks because the workstation is compromised, the attacker has the same access the customer had; the operator can detect anomalous patterns and disable the peer, but cannot prevent the leak.
The architecture removes large categories of risk and reduces others to manageable levels; it does not remove every category, and any vendor representation that suggests otherwise should be examined skeptically.
Frequently Asked Questions
Q: Is WireGuard production-grade for enterprise render farm use? A: WireGuard has been in the mainline Linux kernel since version 5.6 (March 2020), is used in production by major infrastructure operators, and has had its protocol formally verified with the Tamarin prover. The cryptographic primitives (Curve25519, ChaCha20-Poly1305, BLAKE2s, Poly1305) are modern, peer-reviewed choices used across many security-sensitive systems. For render farm transport — long-running tunnels, large flows, small operational surface — it is the production choice we have run for years without protocol-layer incidents.
Q: If our render farm vendor gets compromised, is my data exposed? A: On a multi-tenant model, a compromise of the operator's infrastructure could expose data the operator's systems have access to, scoped by the customer-isolation controls above. On the dedicated cluster model with customer-owned credentials, the operator does not hold the customer's authentication material and the customer's data lives on hardware allocated to the customer — a compromise of the operator's shared infrastructure does not automatically expose dedicated-cluster customer data because the dedicated cluster is a separate boundary. Dedicated-plus-BYOC is the strongest practical answer for high-IP-sensitivity workloads.
Q: Can you provide audit logs for a compliance review? A: Yes. SSH session logs, WireGuard handshake logs, render job logs, and firewall flow logs can be exported for the customer's auditor on request, subject to the retention period defined in the engagement contract. Export format is the one the auditor needs (most commonly CSV or JSON). We do not provide read-write access to the log host itself; the export model preserves audit-trail integrity while giving the customer the evidence they need.
Q: How is end-of-engagement data destruction verified? A: File-level deletion is followed by a free-space overwrite on the relevant storage devices, then an attestation letter signed by the operator recording the devices in scope, the date and time, the procedure, and the personnel involved. For engagements that require it, destruction can be witnessed by the customer's representative. The attestation is the artifact the customer's compliance program files as evidence.
Q: What about insider threats from your own staff? A: Insider threat is mitigated by role separation, two-factor authentication at the bastion, audit logs operator accounts cannot modify, and the per-customer dedicated cluster boundary. It is not reduced to zero, and we are honest about that. The customer's own review of audit logs, on request, is one of the most effective controls against insider misuse — it puts the customer in the loop on what operator staff has actually done.
Q: Do you support SAML or single sign-on integration? A: Customer-side SSO is on the internal roadmap and is not a generally-available feature today. Customers who need SSO for their own compliance reasons should raise it during engagement scoping; some integrations have been done per-engagement where the customer's identity provider can be bridged to the cluster's auth layer through a documented path.
Q: Can my SOC 2 or ISO 27001 auditor review your architecture? A: Yes. We are not certified ourselves, as disclosed above, but we are responsive to vendor-review questionnaires and to architecture review requests from customer auditors. The technical building blocks described in this article are the same ones the auditor will see in our written responses; the configurations are auditable as text. What we cannot provide is a certification document of our own, because we do not currently hold one.
Q: What is your intrusion detection coverage? A: Network flow logging on the Tier-1 edge and host-level monitoring on each node are deployed today. Continuous network IDS at the level a SOC 2 "continuous monitoring" objective would require is on the internal roadmap but not currently in production. Customers whose own compliance program requires a continuous-IDS control should evaluate the gap against their own risk tolerance.
For the network architecture this security model sits on top of, see our cross-country render farm architecture deep-dive. For the customer-owned-credentials model that pairs with dedicated cluster, see the BYOC writeup. For the operational deployment, see our 20-node dedicated GPU render farm guide. For the buying-decision framework, see the SaaS vs dedicated cluster comparison and the dedicated GPU cluster rental landing.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



