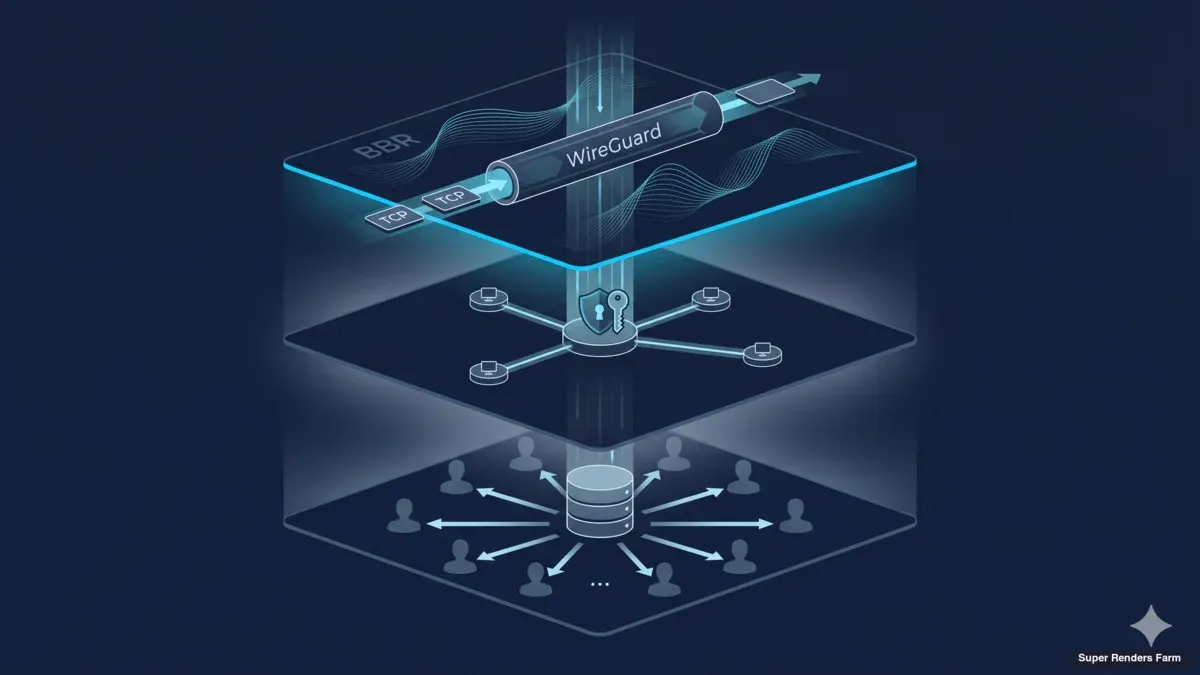
Cross-Country render farm Architektur: WireGuard, BBR und Shared-SMB-Cache-Design
Überblick
Einführung
Eine render farm zu bauen, die in einem Rack, in einem Raum, an einem Switch lebt, ist ein gelöstes Problem. Kabelwege sind kurz, Round-Trip-Zeiten werden in Mikrosekunden gemessen, und die Asset-Bibliothek liegt auf einem NAS, von dem jeder Worker mit Switch-Port-Geschwindigkeit liest. Die meisten Anleitungen für render farms setzen diese Topologie stillschweigend voraus, denn es ist diejenige, bei der einfach alles funktioniert.
Die Architektur ändert sich, sobald die Farm mehr als einen Standort umspannen muss. Ein 20-Knoten-Cluster, der auf zwei Standorte in derselben Metropolregion verteilt ist, stellt bereits ein anderes Netzwerkproblem dar; ein Cluster, der sich über Länder erstreckt, ist erneut ein anderes Problem. Round-Trip-Zeiten dehnen sich von unter einer Millisekunde auf Dutzende oder Hunderte von Millisekunden, Jitter auf öffentlichen ISP-Routen wird zum konstanten Hintergrundrauschen, die MTU zwischen je zwei Endpunkten wird zur Frage statt zur Annahme, und die Asset-Bibliothek, die früher auf einem einzigen NAS lag, muss nun entweder an jeden Standort repliziert oder bei Bedarf gecacht werden. Der naive Ansatz — gleicher NAS, gleiche Submission-Queue, gleicher SMB Share, nur längere Kabel — äußert sich als stille Fehlermodi: Sitzungen, die Verbindung halten, aber niemals ein Frame übertragen; Render-Submissions, die bei 99 Prozent hängen, weil der finale Asset-Push an einen entfernten Knoten timeout läuft; License-Check-outs, die lokal funktionieren und remote ohne erkennbaren Grund scheitern.
Dieser Artikel beschreibt die Architektur, die wir für Cross-Country-render-farm-Deployments betreiben — WireGuard-Hub-and-Spoke-Topologie, TCP-BBR-Congestion-Control, MSS-Clamping-Disziplin, eine Shared-SMB3-Cache-Schicht und eine gehärtete Firewall-Oberfläche. Die Komponenten sind verbreitet, die Konfigurationsentscheidungen nicht immer offensichtlich, und die Lessons Learned haben uns zumeist Debugging-Zeit gekostet, bevor sie irgendwem Geld gekostet haben. Die Zielgruppe sind Infrastruktur-Architekten und DevOps-Engineers, die einen ähnlichen Build dimensionieren, plus IT-Entscheider, die wissen wollen, worauf sich ihr Team einlässt. Für eine schrittweise operative Anleitung zum selben Stack siehe unseren operational deployment guide. Für den höheren Überblick deckt die Seite Cross-Country-render-farm Übersicht den Business Case ab.
WireGuard Hub-and-Spoke Topologie

Verschlüsselter Tunnel verbindet zwei weit entfernte Standorte
Die Transportschicht des Clusters ist WireGuard. Wir nutzen es sowohl für Client-Verbindungen (Workstations der Artists, die zur Farm verbinden) als auch für die Site-to-Site-Verbindung zwischen dem primären Datacenter und dem Sekundärstandort. Die Topologie ist Hub-and-Spoke: ein WireGuard-Server läuft am Hauptdatacenter-Gateway, jeder Client-Peer verbindet zu diesem Hub, und der Sekundärstandort verbindet als weiterer Peer mit einem geroutetem Subnetz dahinter.
Der Reiz von WireGuard für diesen Build ist überwiegend mechanisch. Das Protokoll nutzt feste, moderne Kryptographie (Curve25519 für Key Exchange, ChaCha20-Poly1305 für die Datenebene, BLAKE2s für Hashing), läuft im Linux-Kernel statt im Userspace und konfiguriert sich über eine Schlüssel-und-AllowedIPs-Datei, die auf einen Bildschirm passt. Gegenüber OpenVPN ist die Konfigurationsoberfläche etwa eine Größenordnung kleiner, der Durchsatz auf einem typischen Xeon-Knoten mehrfach höher bei gleichen CPU-Kosten, und der Codebase klein genug, dass Audit machbar wird. Gegenüber IPsec gibt es keine IKE-Verhandlungsphase, die auf interessante Weise scheitern könnte, kein Peer-Identity-Tanz beim Rekey und keinen Userspace-Daemon, der abstürzen kann. Wir haben alle drei in vergangenen Deployments betrieben; die WireGuard-Konfigurationen sind diejenigen, die ohne Eingriff stabil laufen.
Das Hub-and-Spoke-Layout bedeutet, dass jeder Site-to-Site-Flow das Hauptdatacenter-Gateway durchläuft. Für ein Zwei-Standort-Cross-Country-Deployment ist das der richtige Tradeoff: Es konzentriert die öffentliche IP-Angriffsfläche auf eine Box, wendet ein einziges Set von Routing- und Firewall-Regeln an einer Engstelle an, und macht Monitoring einfach, weil jeder Handshake und Flow-Counter am Hub sichtbar ist. Ein Full Mesh würde einen Hop beim Site-to-Site-Verkehr sparen, aber die Konfigurationsarbeit und die öffentliche Angriffsfläche im Quadrat der Site-Anzahl vervielfachen. Für zwei oder drei Standorte gewinnt Hub-and-Spoke bei operativer Einfachheit.
Der Hub lauscht auf UDP-Port 51820 (Default), und das ist der einzige Port, den das öffentliche Interface akzeptiert. Es gibt keinen TCP-Fallback. Nur-UDP ist beabsichtigt — WireGuards Congestion-Verhalten ist um UDP-Datagramme herum gebaut, und ein TCP-über-TCP-Tunnel degradiert zuverlässig den Long-Distance-Durchsatz. In Netzen, die UDP komplett blockieren, behandeln wir das als kundenseitige Einschränkung und routen auf einer anderen Ebene drumherum.
Jeder Client-Peer ist mit einem einzigen AllowedIPs-Eintrag konfiguriert, der das interne Cluster-Subnetz abdeckt. Der Site-to-Site-Peer hat AllowedIPs für das Remote-LAN-Subnetz, damit der Kernel weiß, welche Pakete er encapsuliert. PersistentKeepalive wird auf 25 Sekunden gesetzt für jeden Peer hinter NAT, was den UDP-Conntrack-Eintrag zwischen Handshakes lebendig hält. Wir haben das genau einmal weggelassen und die nächsten zwei Tage "Verbindungsabbrüche alle 90 Sekunden am Sekundärstandort" debuggt; beim dritten Standort war PersistentKeepalive die erste Zeile der Config-Datei.
TCP BBR Congestion Control
Sobald der WireGuard-Tunnel steht, ist die nächste Schicht das TCP-Verhalten. Linux liefert CUBIC als Default-Congestion-Control-Algorithmus. CUBIC skaliert sein Congestion-Window auf einer kubischen Kurve als Funktion der Zeit seit dem letzten Loss-Ereignis, was auf Verbindungen funktioniert, bei denen Paketverlust ein verlässliches Congestion-Signal ist. Der Haken steckt im Wort "verlässlich". Auf Long-Distance-ISP-Routen ist Paketverlust oft gar keine Congestion — es ist Queue-Overflow an einem Zwischenrouter, ein Wireless-Link mit unsichtbaren Retransmits, ein falsch konfigurierter Rate-Limiter oder ein Routing-Transient. CUBIC behandelt all das als Congestion und kollabiert das Window, selbst wenn der Bottleneck noch Kapazität hat.
BBR (Bottleneck Bandwidth and Round-trip propagation time) ist die Alternative, die wir auf Cross-Country-Links nutzen. BBR ignoriert Paketverlust als primäres Congestion-Signal und misst stattdessen direkt die Bottleneck-Bandbreite und die minimale Round-Trip-Time. Es pact dann den Sender mit der Bottleneck-Rate, mit einem Window, das ein Bandwidth-Delay-Product an Daten im Flug hält. Auf einem Long Fat Network — hohe Bandbreite, hohe RTT, moderater zufälliger Loss — hält BBR die Pipe voll, wo CUBIC sein Window für nicht-congestive Losses wiederholt halbieren würde.
Der praktische Effekt auf einer render farm ist messbar. Asset-Transfers über einen Cross-Country-Tunnel, auf derselben Hardware, gehen von sprunghaftem Durchsatz mit häufigen Stalls unter CUBIC zu einer glatteren Durchsatzkurve näher an der tatsächlichen Pfadkapazität unter BBR. Die Headline-Zahlen variieren mit ISP-Route und Tageszeit, aber das Umstellen der Cluster-Senderseite auf BBR hat auf unseren Routen konsistent höheren Steady-State-Durchsatz und kürzere Tail-Latenzen produziert.
Wir nutzen die BBR-Implementierung, die seit Linux-Kernel-Version 4.9 im Mainline ist, aktiviert über einen Einzeiler-sysctl: net.core.default_qdisc=fq plus net.ipv4.tcp_congestion_control=bbr. Beide Zeilen gehen in /etc/sysctl.d/99-bbr.conf und überleben Reboots. Der Mainline-Kernel-BBR ist die Version, die wir seit Jahren in Produktion fahren. Neuere Forschungszweige des Algorithmus existieren, bringen aber Verhaltensänderungen mit, die wir auf unseren spezifischen ISP-Pfaden nicht validiert haben; der Upgrade-Pfad ist ein separater Roadmap-Punkt.
BBR wird auf der Senderseite jedes großen Flows gesetzt — Cache-Box und Render-Manager für Asset-Transfers, die Empfängerseite für jeden Reverse-Direction-Flow wie License-Callbacks und Log-Shipping. BBR an einem Ende reicht, um den Großteil des Vorteils zu sehen; BBR an beiden Enden hilft auf bidirektionalen Flows etwas mehr.
TCP MSS Clamping
Von allen Netzwerkproblemen, die nach dem WireGuard-Tunnel-Aufbau auftauchen, hat uns dasjenige am meisten Debugging-Zeit gekostet: MTU. Das Symptom ist konsistent und verwirrend: kleine Pakete kommen sauber durch (Ping funktioniert bei Default-Größe, SSH echot Zeichen, der WireGuard-Handshake schließt ab), aber große Pakete verschwinden im Tunnel und kommen nie heraus. TLS-Handshakes hängen mittendrin. SMB-Sitzungen verbinden, scheitern beim ersten großen Read. RDP-Sitzungen bauen auf, zeigen den Login-Screen, frieren ein, sobald der Nutzer etwas tippt. License-Server checken kleine Tokens aus und laufen bei großen in den Timeout.
Die Ursache ist der Encapsulation-Overhead des WireGuard-Tunnels, der die effektive MTU unter die Path-MTU senkt, welche die Endpunkte anhand ihrer LAN-Interfaces aushandeln. WireGuard fügt 60 Byte Overhead (20 IPv4 + 8 UDP + 32 WireGuard) zu jedem Paket hinzu. Eine 1500-Byte-Nutzlast auf der LAN-Seite wird zu einem 1560-Byte-Paket auf der öffentlichen Seite, das je nach Pfad fragmentiert oder verworfen wird. Path MTU Discovery (PMTUD) soll das per ICMP "Fragmentation Needed"-Antworten beheben, aber PMTUD scheitert im modernen Internet routinemäßig — ICMP wird oft upstream des Senders gefiltert, das "kleinere Pakete nutzen"-Signal kommt nie an, und der Tunnel verwirft große Pakete still.
Die Lösung ist TCP-MSS (Maximum Segment Size)-Clamping. Wir konfigurieren das router-seitige WireGuard-Interface so, dass es die MSS-Option in jedem TCP-SYN, das den Tunnel durchquert, umschreibt und auf die effektive Tunnel-MTU minus TCP/IP-Overhead deckelt. Bei einer Tunnel-MTU von 1420 Byte (eine sichere Wahl, die die meisten Upstream-Variationen überlebt) ist das MSS-Clamp 1380. Jede TCP-Verbindung, die nach der Regel startet, verhandelt eine 1380-Byte-MSS, der Sender emittiert 1420-Byte-Pakete, die sauber durchpassen, und die stillen Drops hören auf.
Das Clamp gehört auf die FORWARD-Chain des router-mode-WireGuard-Hosts, am wg0-Interface, angewendet auf TCP-Handshake-Pakete. Das iptables-Idiom lautet iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (oder --set-mss 1380 für einen festen Wert). nftables hat das Äquivalent. Die Regel muss in beide Richtungen wirken, wenn beide Seiten TCP-Verbindungen initiieren, was auf einer render farm der Normalfall ist.
Es gibt keinen Weg zu spüren, dass das MSS-Clamp fehlt, bevor etwas Großes scheitert — kleine Workloads testen sauber. Das Clamp ist eine dieser Konfigurationen, die nichts kosten, wenn korrekt angewendet, und stundenlanges verwirrtes Debugging erzeugen, wenn weggelassen. Wir haben es in die Standard-Deployment-Checkliste aufgenommen, nachdem ein 6-Uhr-Support-Ticket über "SMB-Transfers hängen bei zufälligen Größen" um 8 Uhr mit einer Einzeiler-iptables-Regel gelöst war.
Shared SMB3 Cache Design

Gemeinsamer Cache stellt Render-Workern Assets lokal bereit
Render-Workloads sind asset-lastig und lese-dominiert. Eine typische Szene reicht von einigen hundert Megabyte bis mehreren zehn Gigabyte — Geometrie, Texturen, Simulation Caches und die Projektdateien der Rendering-DCC. Über einen 20-Knoten-Cluster muss die gleiche Szene von jedem Worker lesbar sein, der ein Frame aufnimmt. Der naive Ansatz ist, die Szene vor dem Render auf jeden Knoten zu kopieren. Mit einer 10-GB-Szene und 20 Knoten bewegt das 200 GB über das Netzwerk für einen 10-GB-Working-Set. Multipliziert mit Dutzenden Szenen pro Tag dominieren die Duplikationskosten den Build.
Die Architektur, die wir stattdessen nutzen, ist eine einzige Shared-Cache-Schicht pro Standort, den Render-Workern über SMB3 exponiert. Der Cache ist eine Ubuntu-22.04-LTS-Box mit einer einzelnen SSD (NVMe-Klasse), ext4-formatiert, mit dem Cache-Verzeichnis per Samba via SMB3 exponiert. Jeder Render-Worker mountet den SMB-Share beim Boot über cifs-utils und liest Asset-Dateien aus dem Cache, als wären sie lokal. Der erste Worker, der ein bestimmtes Asset braucht, triggert einen Pull aus dem Upstream-Cloud-Asset-Store in den Cache; nachfolgende Worker und nachfolgende Frames lesen aus dem LAN-Cache mit Switch-Port-Geschwindigkeit. Pro Standort sitzt die Cache-Box einen Switch-Hop von jedem Worker entfernt; das Asset erreicht den Cluster einmal und bedient zwanzig Worker.
Ein paar Designentscheidungen verdienen Auspacken. Der Cache ist eine einzelne SSD, kein RAID, weil der Cache per Definition aus dem Upstream-Cloud-Asset-Store rebuildbar ist. Wenn die SSD ausfällt, ist der Worst Case eine Verzögerung, während der nächste Asset-Request aus der Cloud zieht, plus ein Rebuild jedes In-Flight-Renders, der von einer nicht-gecachten Zwischendatei abhing. Wir mitigieren das "In-Flight-Render"-Risiko durch rsync der fertigen Render-Outputs vom Cache auf ein NAS am Job-Ende, sodass ein SSD-Ausfall kein bereits geliefertes Deliverable verliert. RAID auszulassen spart Hardwarekosten, Controller-Komplexität und den Write-Amplification-Overhead, den manche RAID-Level auf SSDs auferlegen.
Das Filesystem ist ext4 statt ZFS oder btrfs. Wir haben beide ZFS und btrfs in vergangenen Builds genutzt, und die Feature-Sets, die sie bringen (Snapshots, Checksumming, Compression), sind in manchen Workflows echte Vorteile. Für einen Render-Cache ist das Lesemuster überwiegend sequenziell und bandbreiten-bound statt transaktionsschwer, und die Cache-Inhalte sind per Design verwerfbar. Ext4 hält den Storage-Stack einfach und entfernt eine Klasse von Failure-Modes aus dem Incident-Postmortem-Set. Operatoren, die ZFS bereits at scale fahren, können es hier absolut nutzen, aber für ein Deployment, in dem Cache-Layer-Einfachheit über einzelne Feature-Gewinne wiegt, ist ext4 die Wahl.
Die Pre-Warm-Strategie zählt. Vor einem deadline-getriebenen Job pusht der Artist oder Pipeline TD die Assets der Szene über ein Pre-Staging-Tool in den Cache. Das erste Frame, das auf einem Worker landet, liest dann aus einem warmen Cache, statt auf einen Cold Pull zu warten. Der Pre-Warm-Schritt ist optional für Jobs, die über Nacht laufen (Cold Pull ist okay), und wichtig für Jobs, die in einem engen Fenster fertig werden müssen.
Cross-Site-Cache-Sharing funktioniert über den WireGuard-Site-to-Site-Tunnel. Der Sekundärstandort hat seine eigene Cache-Box und Worker, aber sein Cache kann auch über den Tunnel den Cache des Primärstandorts erreichen für jedes Asset, das dort warm und lokal noch nicht warm ist. In der Praxis konfigurieren wir den Sekundär-Cache so, dass er für Misses auf den Primär-Cache zurückfällt, bevor er Upstream Cloud trifft — was Inter-Site-Verkehr auf dem verschlüsselten Tunnel hält und Cloud-Egress-Charges für bereits in der Farm liegende Assets vermeidet. Das ist einer der praktischen Vorteile eines korrekten MSS-Clamps: große Asset-Transfers zwischen Standorten laufen mit tunnel-sättigendem Durchsatz statt am Small-Packet-Ceiling zu stallen.
Interne Dienste: DNS und NTP
Ein Cluster muss seine eigenen Hostnamen kennen. Die naive Wahl ist, jeden Host in /etc/hosts auf jedem Knoten zu listen, was bei zwei Knoten funktioniert und bei zwanzig zu scheitern beginnt. Die richtige Wahl ist internes DNS, und wir betreiben dnsmasq auf derselben Gateway-Box, die WireGuard fährt. Der Cluster lebt in einer .lan-Zone — cache.lan, rn-a01.lan bis rn-a20.lan, mgr.lan, nas.lan. Jeder Name löst auf die entsprechende interne IP im Cluster-Subnetz auf, und /etc/resolv.conf jedes Workers zeigt auf den dnsmasq-Server.
Der Vorteil ist, dass jede IP-Neuvergabe, jeder Host-Tausch oder jede Topologieänderung das Anfassen einer Konfigurationsdatei verlangt (das dnsmasq-Hosts-File) statt jedes Knotens. Der Vorteil reicht über den Site-to-Site-Tunnel: ein Worker am Sekundärstandort kann cache.lan zum Sekundär-Cache über sein lokales dnsmasq auflösen und mgr.lan zum Render-Manager des Primärstandorts über DNS-Forwarding über den Tunnel. Wir haben in der Vergangenheit IP-Literale in Render-Manager-Konfigurationen genutzt und es jedes Mal bereut, wenn ein Knoten umzog.
Die dnsmasq-Falle, die uns gebissen hat — und genug Operatoren beißt, dass sie einen eigenen Absatz verdient — ist die interface=-Zeile. dnsmasq lauscht per Default auf jedem Interface, was okay scheint, bis du realisierst, dass die Gateway-Box mindestens drei hat: das öffentliche WAN, das interne LAN und den WireGuard-Tunnel wg0. Wenn du interface=eth1 setzt in der Annahme, du beschränkst dnsmasq auf LAN, hast du gerade den WireGuard-verbundenen Sekundärstandort unfähig gemacht, irgendeinen .lan-Namen aufzulösen, weil wg0 nicht gelistet ist. Die korrekte Zeile ist interface=eth1,wg0 (oder das Äquivalent für deine Interface-Namen), oder eine except-interface=-Zeile, die nur das WAN nennt. Wir haben diese Fehlkonfiguration das Symptom "Remote-Standort kann den Cache per IP pingen, aber nicht per Hostname SMB-mounten" mehr als einmal erzeugen sehen.
NTP ist der andere interne Dienst. Wir fahren chrony am Gateway als NTP-Server, mit dem Gateway selbst zu öffentlichen NTP-Pools synchronisiert und jedem Knoten zum Gateway. Die Motivation ist Log-Korrelation des Render-Managers: scheitert ein Frame, müssen Render-Manager-Log-Eintrag und Worker-Log-Eintrag sich auf einer Zeitlinie innerhalb von Millisekunden treffen. Clock-Drift auf einem 20-Knoten-Cluster, besonders wenn Knoten wochenlang up sind, wird zu einer realen Quelle von "dieser Log-Eintrag passt nicht ganz"-Debugging-Verwirrung. chrony hält den Drift unter wenigen Millisekunden und entfernt diese Verwirrungsklasse.
Firewall: ufw mit Default-Deny Inbound
Das Gateway sitzt am öffentlichen Internet, und seine Firewall-Posture ist "Default-Deny Inbound, Default-Allow Outbound, Default-Allow Forward für tunneled Traffic." Auf Ubuntu 22.04 LTS ist das Tool, das wir nutzen, ufw — die Uncomplicated Firewall. ufw ist ein Frontend über nftables (oder iptables auf älteren Systemen), das eine kleine Command-Oberfläche exponiert und sich weigert, Überraschendes zu tun. Für eine Gateway-Box, deren Firewall-Config den Unterschied zwischen "sicher" und "innerhalb von Stunden kompromittiert" ausmacht, ist eine kleine Command-Oberfläche ein Feature.
Die konfigurierte öffentliche Oberfläche ist eine Regel: ufw allow 51820/udp comment 'wireguard'. Sonst nichts Inbound. SSH von der öffentlichen Seite ist zu; wir administrieren das Gateway durch den WireGuard-Tunnel von einer bekannten Operator-IP. SMB, DNS, NTP und HTTPS (für die Render-Manager-UI) sind alle nur auf internen Interfaces. Die ufw default deny incoming- und ufw default allow outgoing-Einstellungen decken den Rest der Oberfläche ab.
Die Forward-Chain braucht Sorgfalt. Das Gateway agiert als Router für Cluster-Traffic zwischen wg0 und dem internen LAN, und die ufw-Default-Posture ist Deny Forward. Wir setzen DEFAULT_FORWARD_POLICY="ACCEPT" in /etc/default/ufw und engen die Forward-Regeln dann auf spezifische Source/Destination-Paare in der FORWARD-Chain ein. Die Kombination — Default-Deny Incoming, Default-Deny Forward beim Boot, dann explizite Forward-ACCEPTs zwischen bekannten Cluster-Subnetzen — gibt eine auditierbare Posture, die nicht versehentlich Traffic zwischen Standorten routet, die nicht miteinander sprechen sollten.
Per-Knoten-Host-Firewalls erweitern diese Tier-1-Gateway-Schicht zu einer Tier-2-Host-Schicht. Jeder Render-Knoten fährt ufw lokal mit Regeln, die nur dem Render-Manager und der Cache-Box des Clusters erlauben, Verbindungen zu initiieren. Ein kompromittierter Worker kann nicht zu einem anderen Worker pivoten, ohne erst die Host-Firewall zu besiegen, und das Gateway loggt jeden unerwarteten Forward-Versuch. Das Zwei-Tier-Modell — Gateway Tier 1, Per-Host Tier 2 — ist dasselbe, das jeder vernünftige On-Prem-Cluster fährt; was sich auf einem Cross-Country-Deployment ändert, ist, dass die Tier-1-Oberfläche jetzt gegen das öffentliche Internet verteidigt. Das Gateway ist der Perimeter; Per-Host-Firewalls sind Defense-in-Depth.
Architektur-Diagramm

Hub-and-Spoke-render-farm-Topologie mit einem einzigen sicheren Tunnel zum Internet
Die obige Textbeschreibung mappt auf das folgende ASCII-Diagramm, das wir bei Deployment-Kick-offs aufs Whiteboard malen:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
Das Diagramm ist bewusst generisch — kein spezifisches Städtepaar, kein spezifischer ISP, keine spezifische Subnetz-Nummerierung. Jeder Standort, den wir deployen, folgt derselben Form; die Zahlen variieren.
Performance-Charakteristiken
Die Durchsatzzahlen hängen von ISP-Route und Tageszeit ab, aber die Form der Performance ist über die von uns gefahrenen Deployments konsistent. Auf einem Tunnel zwischen zwei Standorten in derselben Metropolregion (Sub-10-ms-RTT) bewegen sich große Transfers nahe Line-Rate auf dem Bottleneck-Link, und ein Render-Worker, der vom Cache liest, fühlt sich nicht von einem unterscheidbar, der von lokaler Platte liest. Auf einem Tunnel zwischen Standorten in verschiedenen Ländern (50–150 ms RTT je nach Route) setzen sich große Transfers auf einen stabilen BBR-pace nahe der Bottleneck-Bandbreite, mit dem MSS-Clamp, das die Per-Segment-Größe an die Tunnel-MTU anpasst.
Der lokale LAN-Cache-Read ist, wo die Architektur ihr Geld verdient. Ein Render-Worker, der ein 4-GB-Texture-Pack von cache.lan über SMB3 auf einem geswitchten Gigabit-LAN liest, ist in etwa der Zeit fertig, die der Switch-Port braucht, um die Bytes zu pushen — Sekunden bis Zehn-Sekunden-Bereich statt der Mehr-Minuten-Spanne, die ein Cold Pull aus Cross-Country-Cloud-Storage bräuchte. Für einen Job, der dasselbe Texture-Pack über zweihundert Frames anfasst, nähert sich die Cache-Hit-Ratio 1,0 nach dem ersten warmen Read, und der Cross-Country-Tunnel wird nur für den ursprünglichen Pre-Warm, den Cross-Site-Sync von Sekundärstandort-Outputs und Steady-State-Telemetrie genutzt.
Speziell für 4K- und 8K-Render-Frames skaliert der Wert der Architektur mit der Frame-Größe. Eine 8K-EXR-Sequenz mit mehreren AOVs kann einzelne Frame-Outputs in den dreistelligen Megabyte-Bereich pushen, und 200 davon sind ein Schreib im mehrstelligen Gigabyte-Bereich pro Szene. Diesen Schreib lokal-LAN zu halten und nur den finalen komprimierten Output über den Tunnel zu shippen, ist der Unterschied zwischen "über Nacht fertig" und "fertig, wenn der Upload morgen irgendwann durch ist".
Häufig gestellte Fragen
Q: Warum WireGuard und nicht OpenVPN? A: WireGuards Konfigurationsoberfläche ist kleiner, sein Data-Plane-Durchsatz konsistent höher auf gleicher Hardware, seine Kernel-Implementierung entfernt einen Userspace-Failure-Mode, und seine Fixed-Cipher-Posture entfernt eine Klasse von Negotiation-Bugs. OpenVPN ist ein solides Tool mit zwanzig Jahren operativer Historie; wir nutzen WireGuard, weil die operativen Eigenschaften für einen langlaufenden Cluster-Tunnel auf den Metriken, die uns wichtig sind, besser sind. Auf Routen, wo WireGuards UDP komplett blockiert ist, ist OpenVPN über TCP 443 ein legitimer Fallback — aber TCP-über-TCP bringt seine eigenen Pathologien, und wir behandeln das als kundenseitige Einschränkung.
Q: Wie hilft BBR auf unruhigen ISP-Routen? A: BBR nutzt Bottleneck-Bandbreite und RTT als Congestion-Signal statt Paketverlust. Auf Routen, wo Loss von Buffer-Overflow an Zwischenroutern, Wireless-Retransmits oder transienten Routing-Events dominiert wird — also den meisten öffentlichen ISP-Routen — hält BBR den Sender-Pace an der tatsächlichen Pfad-Bandbreite, statt das Window für nicht-congestive Losses wiederholt zu halbieren. Der Effekt ist höherer Steady-State-Durchsatz, kürzere Tail-Latenz auf großen Transfers und weniger "Transfer stalled dreißig Sekunden und resumed dann"-Vorfälle auf langen Flows.
Q: Was ist MSS-Clamping und warum brauche ich es? A: MSS-Clamping schreibt die Maximum-Segment-Size-Option in TCP-SYN-Paketen so um, dass die verhandelte Segmentgröße sauber durch einen Tunnel mit reduzierter effektiver MTU passt. Ohne es verhandeln Endpunkte eine Segmentgröße basierend auf ihren LAN-Interfaces (typisch 1500-Byte-MTU, 1460-Byte-MSS), der WireGuard-Tunnel kann diese Pakete nicht in voller Größe tragen, Path MTU Discovery scheitert, weil ICMP irgendwo upstream gefiltert wird, und große Pakete verschwinden still. Das Symptom ist "kleine Pakete funktionieren, große nicht" — Pings kommen durch, TLS-Handshakes hängen, SMB-Transfers stallen mid-file. Die Lösung ist eine Einzeiler-iptables- oder nftables-Regel am router-seitigen WireGuard-Interface.
Q: Kann ich diese Architektur selbst deployen, oder brauche ich einen render-farm-Vendor?
A: Die Architektur ist komplett aus Open-Source-Komponenten gebaut — WireGuard, Linuxes BBR-Implementierung, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. Es gibt keine SRF-only-Komponente. Ein Team mit Infrastruktur-Engineer-Skills kann denselben Stack selbst deployen, und die Konfigurationsentscheidungen in diesem Artikel sind keine Geheimnisse; es sind die Entscheidungen, die wir gemacht haben, weil sie funktioniert haben. Was ein Vendor bringt, ist die operative Erfahrung — die Fallen wie die dnsmasq-interface=-Zeile, die MSS-Clamp-Entdeckungsgeschichte, das Right-Sizing der Cache-SSD, das Pre-Warm-Tooling — gebündelt in ein Deployment-Playbook, das auf jedem Build keine Wiederentdeckung verlangt. Ob ein Team diese Erfahrungskurve absorbieren oder daran vorbei kaufen will, ist eine Budget- und Timeline-Frage.
Q: Wie hoch ist die Cache-Hit-Ratio für typische Render-Workflows? A: Für Frame-Parallel-Workloads, wo dieselbe Szene über viele Frames gerendert wird (das dominierende Pattern in Animation, VFX, Archviz und Produktvisualisierung), nähert sich die Cache-Hit-Ratio 1,0 nach dem ersten warmen Pull jedes Assets. Der Cold-Pull-Penalty wird einmal pro Asset pro Cache gezahlt, und jeder nachfolgende Worker am selben Standort liest vom warmen Cache mit LAN-Geschwindigkeit. Für Workloads, die pro Frame einen anderen Asset-Set anfassen (selten, kommt aber in manchen prozeduralen Workflows vor), ist die Hit-Ratio niedriger und der Cache verhält sich eher wie ein Transit-Buffer. Der Pre-Warm-Schritt vor deadline-getriebenen Jobs macht die Hit-Ratio für die geplante Workload effektiv 1,0.
Q: Wie skaliert diese Architektur über 20 Knoten hinaus? A: Die Hub-and-Spoke-WireGuard-Topologie skaliert linear mit der Peer-Anzahl — die Hub-CPU-Kosten sind Per-Peer-Crypto und Per-Paket-Routing, und ein modernes Xeon-Gateway kann Hunderte von Peers handhaben, bevor es zum Bottleneck wird. Die Cache-Schicht skaliert entweder durch Wachstum der einzelnen Cache-Box (mehr SSD-Kapazität, schnellere NIC) oder Sharding über mehrere Boxes mit einer workload-bewussten Mount-Strategie. Für Builds über 50 Knoten pro Standort fügen wir typisch eine zweite Cache-Box hinzu und splitten Worker zwischen ihnen; über 100 Knoten pro Standort wird die Cache-Schicht ein verteiltes Read-Replica-Design, und das ist ein anderer Artikel. Der Cross-Country-Tunnel selbst braucht keine Architekturänderung beim Cluster-Wachstum — BBR-Pacing und MSS-Clamp tun ihren Job bei jeder aggregierten Flow-Rate, solange der ISP-Link die Kapazität hat.
Für mehr praktische Details zur Deployment-Sequenz, mit der wir diese Architektur hochfahren, siehe unseren operational deployment guide. Für die über dieses Netzdesign gelegte Sicherheits-Posture deckt unser Artikel network segmentation security das Tier-1- und Tier-2-Firewall-Modell tiefer ab. Und für die felderprobten Edge-Cases, die wir nicht immer beim ersten Mal richtig hatten, deckt der Writeup deployment lessons learned die spezifischen Failure-Modes, die diese Architektur geformt haben.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



