20-Node Dedicated GPU-render-farm grenzüberschreitend bereitstellen (2026)
Überblick
Einleitung
Wenn ein Kreativteam nach einer dedizierten render farm fragt, die mehrere Länder überspannt, arbeitet es in der Regel um eine Einschränkung herum, die eine SaaS render farm nicht lösen kann. Es kann sich um ein Studio handeln, das vertraglich keinem Dritten erlauben darf, seine Anmeldedaten zu halten, um ein verteiltes Team, dessen Artists in einem Land Knoten in einem anderen steuern, oder um ein Produktionshaus, dessen mehrmonatiger Auftrag Per-Frame-Abrechnung wirtschaftlich falsch macht.
In unserer Erfahrung besteht die eigentliche Herausforderung selten darin, „mehr GPUs zu buchen". Es geht darum, die richtigen Teile zu verbinden: kundeneigenen Cloud-Speicher, eine private GPU-Flotte in passender Größe, verschlüsselten grenzüberschreitenden Transport, der Jitter standhält, und eine Remote-Desktop-Schicht, die bei einem schweren 3D-Viewport nicht zusammenbricht. Stimmt ein Element nicht, läuft der Cluster — aber die Artists bemerken es, und der Auftrag erodiert leise.
Wir betreiben Super Renders Farm, eine Cloud-render-farm mit einer substanziellen CPU- und GPU-Flotte, und richten außerdem dedizierte GPU-Cluster für Teams ein, deren Workflows nicht auf unseren Managed Service passen. Dieser Artikel ist ein Praxisleitfaden aus diesen Bereitstellungen — wie wir eine dedizierte 20-Node GPU-render-farm architektonisch aufbauen, die ein verteiltes Kreativteam über Grenzen hinweg aus einer einzigen dedizierten Einrichtung bedient, mit ehrlichen Anmerkungen zu den Entscheidungen, die wir getroffen haben, den Entscheidungen, von denen wir abgerückt sind, und den Lektionen, die wir nun standardmäßig anwenden. Wenn Sie dedizierte Infrastruktur gegen unser Managed-render-farm-Angebot abwägen, hilft Ihnen dieser Leitfaden zu entscheiden, ob der dedizierte Weg den architektonischen Mehraufwand rechtfertigt.
Dedicated vs. SaaS — Entscheidungskriterien
Die meisten Rendering-Workloads benötigen keinen dedizierten Cluster. Eine Managed-Cloud-render-farm nimmt eine Szene entgegen, plant die Frames ein und rechnet pro Minute ab. Es gibt keine Infrastruktur zu besitzen, keine Firewall zu pflegen und kein Operations-Team kundenseitig einzuplanen. Für projektbasierte Arbeit — einen einzelnen Kurzfilm, einen 30-Sekunden-Spot, einen Stapel Stills — gewinnt dieses Modell auf jeder relevanten Achse.
Ein dedizierter Cluster rechtfertigt seine Komplexität nur, wenn eines oder mehrere der folgenden Kriterien zutreffen:
- IP-Kontrolle ist vertraglich vorgegeben, nicht nur bevorzugt. Der Rahmenvertrag des Kunden oder der Vertrag mit dem Endkunden verbietet Dritten, Szenedateien oder Render-Anmeldedaten zu halten. SaaS-Pipelines, die den Szenen-Upload vermitteln, verletzen diese Einschränkung selbst dann, wenn die zugrunde liegende Rechenleistung identisch ist.
- Der Auftrag läuft Monate, nicht Tage. Arbeit mit fester Struktur — eine langlaufende Animationsserie, eine mehrquartalige Architekturvisualisierungs-Pipeline, eine laufende Virtual-Production-Bühne — amortisiert die Vorab-Architekturkosten. Per-Frame-Abrechnung hingegen skaliert linear mit der Laufzeit und wird ab einem bestimmten Zeithorizont unwirtschaftlich.
- Der Workflow ist so individuell, dass eine Managed-Pipeline ihn nicht hosten kann. Eigene DCC-Plugin-Stacks, hauseigene Render-Manager, simulationsintensive Pipelines, die in einen Shared Cache vorberechnen, oder proprietäre Toolchains drängen zu dedizierten Knoten, die der Kunde direkt konfigurieren kann.
- Bring-your-own-Cloud ist eine harte Anforderung. Wenn die Projekt-Assets in einer Cloud-File-Streaming-Plattform unter dem Kunden-Konto liegen, muss sich der Cluster als der Kunde anmelden, nicht als Infrastrukturanbieter. Dies ist das unten beschriebene „Model B"-Muster.
- Netzwerksegmentierung muss über ein Tenant-VLAN hinausgehen. Manche Workflows verlangen, dass der Cluster für das breitere Netzwerk des Anbieters nicht nur logisch, sondern auch per Routing unsichtbar ist.
Trifft keines dieser Kriterien zu, ist eine Managed render farm die richtige Wahl. Treffen zwei oder mehr zu, verschiebt sich die Diskussion in Richtung dedizierter Infrastruktur. Die verbleibende Frage ist geografisch: Sitzen die Artists, die die Arbeit ausführen, in der Nähe der Einrichtung, oder muss der Cluster sie über ein öffentliches ISP-Backbone bedienen, das nationale Grenzen überquert?
Architekturüberblick
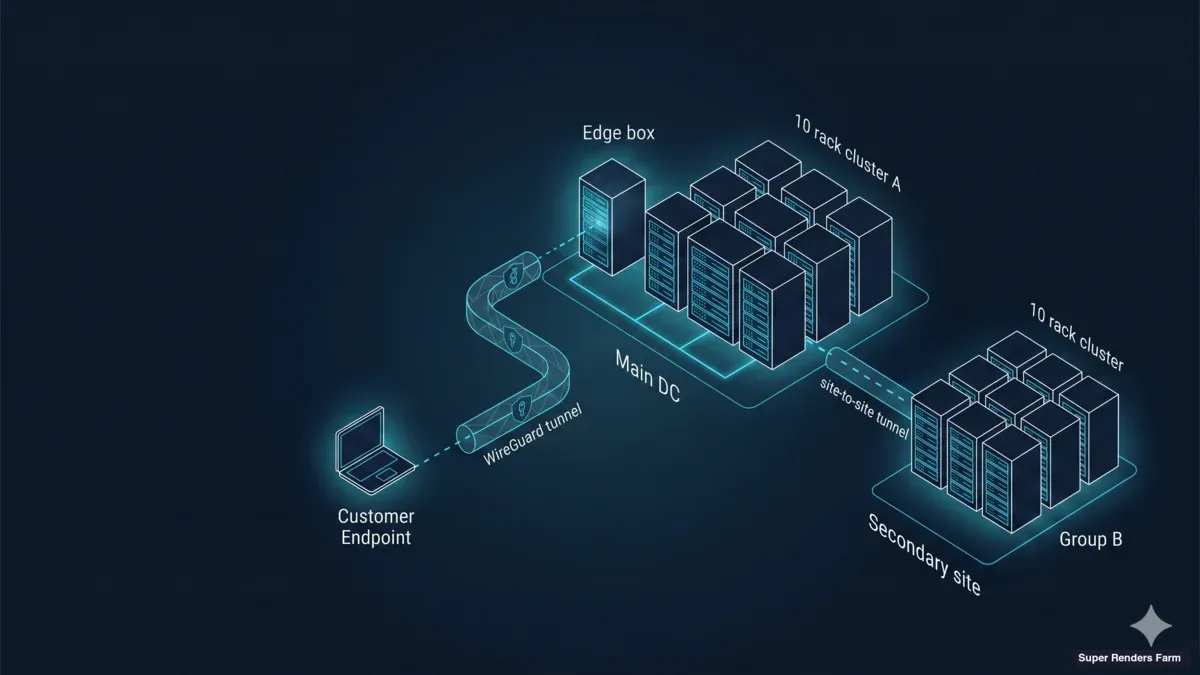
Die Architektur, die wir für grenzüberschreitende dedizierte Cluster einsetzen, besteht aus drei Ebenen: einer Transportebene, einer Compute-Ebene und einer Storage-Acceleration-Ebene. Jede hat einen einzelnen Ausfallmodus, der in unserer Erfahrung den Großteil der betrieblichen Probleme verursacht, wenn er auftritt.
[ Remote-Artists — verteilt über Länder ]
│
│ WireGuard Hub-and-Spoke
│ (UDP 51820, Ende-zu-Ende verschlüsselt,
│ BBR + MSS-geclampter Transport)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — dedizierte Cluster-Einrichtung│
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (einzelner Ubuntu-Host) │ │
│ │ • WireGuard Hub (NAT/MASQUERADE) │ │
│ │ • Samba SMB3 Cache (Single SSD, ext4) │ │
│ │ • dnsmasq (.lan-Zone) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + TCP MSS Clamp │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × RTX 5090 Render-Nodes │ │
│ │ (Windows 11 Pro, Sunshine, Cloud-File- │ │
│ │ Stream-Client, Cache-Mount — einheitliches │ │
│ │ Image für die gesamte Flotte) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Cloud-File-Streaming-Plattform des Kunden —
Kunde meldet sich auf jedem Knoten an; Super Renders
Farm hält keine Anmeldedaten (Model B) ]
Die Transportebene ist WireGuard in einem Hub-and-Spoke-Muster. Die Workstation jedes Artists verbindet sich über einen verschlüsselten UDP-Tunnel mit dem Hub an der Cluster-Einrichtung; der gesamte Artist-zu-Cluster-Verkehr, unabhängig davon, in welchem Land der Artist sitzt, durchläuft dieselbe Tunnel-Topologie. Die Compute-Ebene besteht aus zwanzig Windows 11 Pro-Knoten, jeder mit einer einzelnen NVIDIA RTX 5090 mit 32 GB VRAM, als eine einzige einheitliche Flotte in einer Einrichtung bereitgestellt. Die Storage-Acceleration-Ebene ist eine einzelne Edge-and-Cache-Box an der Einrichtung, die eine Samba SMB3-Freigabe auf einer einzelnen SSD mit ext4 hostet — zusammen mit den Netzwerkdiensten, auf die der Cluster angewiesen ist (DNS, NTP, Firewall).
Eine zentrale Design-Entscheidung: Edge-Box und Cache-Box sind dasselbe System. In einer früheren Version dieser Architektur lag das Edge-Gateway auf einem separaten Gerät und der Cache auf einem NAS — was Race Conditions beim Kaltstart und zwei separate Oberflächen zum Patchen erzeugte. Die Konsolidierung auf einen einzigen Ubuntu 22.04 LTS-Host beseitigte beide Probleme. Die Box wird zu einer kritischen Ressource — aber die Projekt-Daten des Kunden verbleiben auf der Cloud-File-Streaming-Plattform, sodass sich der Cache nach einem lokalen Ausfall vom Upstream neu aufwärmt.
20-Node-GPU-Cluster-Aufbau
Die Standardgröße für die hier beschriebenen Bereitstellungen sind zwanzig RTX 5090-Knoten, als eine einzige einheitliche Flotte innerhalb einer Einrichtung bereitgestellt. Diese Größe passt konsistent zu einem Kreativteam in der Bandbreite von zehn bis zwanzig Artists — dem Bereich, in dem dedizierte Cluster für IP-sensible Workflows ihren Wert erzielen.
Jeder Knoten hat dieselbe Hardware-Form: eine einzelne RTX 5090 mit 32 GB VRAM, eine moderne Mehrkern-CPU, 64 GB oder 128 GB System-RAM und ein lokales NVMe-Laufwerk, das nur für Betriebssystem und Scratch dimensioniert ist. Persistente Projektdaten liegen auf dem Shared Cache oder auf der vorgelagerten Cloud-File-Streaming-Plattform — niemals auf dem Knoten selbst.
Das Betriebssystem auf jedem Knoten ist Windows 11 Pro, bereitgestellt von einem sauberen Image. Wir laden DCC-Plugin-Stacks absichtlich nicht auf das Node-Image vor. Der Kunde übernimmt die Installation seiner eigenen DCC-Tools — Cinema 4D, Redshift, Houdini, After Effects, Blender und andere — damit das Node-Image minimal und reproduzierbar bleibt. Endet der Auftrag, löschen wir es und spielen das gleiche saubere Basis-Image neu auf.
Wir haben 32 GB VRAM pro Knoten bewusst gewählt. Moderne GPU-Render-Engines — Redshift, Octane, Arnold GPU, Cycles — laden zunehmend stark texturierte Szenen, die in 24-GB-Karten schlicht nicht passen. RTX 5090 mit 32 GB ist der aktuelle Sweet Spot für Produktions-Renderer; sie verarbeitet die meisten Architekturvisualisierungs-, Motion-Design- und Animationsarbeiten ohne Paging in den System-RAM — was der Punkt ist, an dem gemischte GPU-Flotten leise langsam werden.
Die zwanzig Knoten sind identisch konfiguriert — gleiches Image, gleicher DCC-Installationssatz, gleiches Cache-Mount, gleiche WireGuard-Route — und präsentieren sich dem Render-Manager des Kunden als ein einziger Pool. Deadline, Royal Render oder der eigene Scheduler des Kunden behandelt die Flotte als eine Ressource ohne gruppenspezifisches Routing oder manuelles Neuausbalancieren. Frames werden an den jeweils freien Knoten übergeben; der Render-Manager des Kunden übernimmt die Lastverteilung auf Job-Queue-Ebene.
Die Flotte ist Layer-3-routebar — der Kunde installiert seinen eigenen Render-Manager und reicht Aufträge von einer Remote-Workstation ein, anstatt jeden Knoten über Remote Desktop zu steuern. Das ist wichtiger, als es den Anschein hat: Es ist der Unterschied zwischen einem Cluster, mit dem Artists kämpfen, und einem, den Artists vergessen.
Kundeneigene Anmeldedaten (Model B)
Die einzelne architektonische Entscheidung, die eine dedizierte render farm am häufigsten zur richtigen Antwort für IP-sensible Workflows macht, ist das, was wir Model B nennen: kundeneigene Anmeldedaten. In Model A — dem Standard für Managed render farms, einschließlich unseres eigenen SaaS-Services — hält der Infrastrukturanbieter Anmeldedaten für die Rendering-Pipeline. Der Kunde lädt Szenedateien hoch; die Pipeline des Anbieters vermittelt das Rendering. Dieses Modell funktioniert für die überwiegende Mehrheit der Workloads und steht hinter fast jeder kommerziellen Cloud-render-farm.
In Model B liefert der Infrastrukturanbieter Hardware, Betriebssystem, Netzwerk und Cache-Schicht, hält aber niemals das Authentifizierungsmaterial des Kunden für die Cloud-File-Streaming-Plattform oder für die Quell-Daten des Projekts. Der Kunde meldet sich auf jedem Knoten bei der Cloud-Plattform an, genau wie an seiner eigenen Workstation. Projektdateien werden vom Cloud-Speicher des Kunden gestreamt. Render-Ergebnisse werden zurück auf den Cloud-Speicher des Kunden geschrieben. Die Rolle des Anbieters ist auf die Hardware-und-Pipeline-Ebene begrenzt.
Das ist aus drei Gründen relevant:
- Vertragliche Anforderungen: Wenn der Endkunde des Kunden eine NDA oder einen Rahmenvertrag hat, der einschränkt, wo Anmeldedaten und Quelldateien liegen dürfen, hält Model B den Anbieter außerhalb des Geltungsbereichs dieser Einschränkungen. Der Kunde muss den Rendering-Anbieter nicht in eine Vertragskette verhandeln, die nicht für ihn ausgelegt war.
- Audit-Fähigkeit: Wenn der Kunde einem Sicherheitsprüfer nachweisen muss, dass seine Rendering-Pipeline keine Anmeldedaten an Dritte weitergibt, liefert Model B eine klare Antwort. Der Anbieter dokumentiert Hardware, Netzwerk und Betrieb; der Kunde dokumentiert die Anmeldedaten-Kette.
- Auftragsabschluss: Da der Anbieter niemals Anmeldedaten hielt, ist der Auftragsabschluss einfacher. Der Kunde widerruft seine eigenen Cloud-Sessions; der Anbieter löscht den Cache, spielt die Knoten neu auf und stellt eine schriftliche Bestätigung aus, dass Cache und Node-Images vernichtet wurden. Es gibt keinen Anmeldedaten-Rotationsschritt für den Anbieter, da niemals Anmeldedaten gehalten wurden.
Model B ist nicht für jeden geeignet. Es verpflichtet das Operations-Team des Kunden zum Anmeldedaten-Lifecycle auf jedem Knoten — zwanzig Rotationen zu koordinieren, wenn Secrets monatlich rotiert werden. Teams, die diese Praxis bereits etabliert haben, empfinden den Kompromiss als akzeptabel. Teams ohne diese Praxis neigen dazu, bei Managed-Rendering auf Model A zu bleiben.
Cloud-File-Streaming-Integration
In den hier beschriebenen Konfigurationen liegen die Projekt-Assets des Kunden auf einer Cloud-File-Streaming-Plattform — einem Dienst, der den Cloud-gesicherten Projektbaum des Kunden als virtuelles Dateisystem auf jedem Knoten zugänglich macht. Der Artist mountet das Projekt; der Knoten liest Dateien bei Bedarf; die Plattform übernimmt Backing-Storage, Versionierung und regionsübergreifende Replikation.
Wir integrieren mit einer generischen Cloud-File-Streaming-Plattform nach Wahl des Kunden. Die Plattform sieht ein Anmeldeereignis von jedem Knoten mit dem Kunden-Konto; der auf dem Knoten laufende Plattform-Client mountet den Projektbaum unter einem bekannten Pfad; die DCC-Anwendung des Kunden öffnet Dateien von diesem Pfad, genau wie von einer lokalen Workstation. Die Cloud-Plattform muss nicht wissen, dass der Knoten Teil eines Render-Clusters ist.
Was sich ändert, wenn dies in einen 20-Knoten-Cluster integriert wird, ist das Zugriffsmuster. Ein einzelner Artist auf einer einzelnen Workstation zieht eine Projektdatei nach der anderen bei Bedarf, während er arbeitet. Zwanzig Render-Nodes, die dieselbe Szene gleichzeitig für einen Frame-Bereich öffnen, erzeugen einen synchronisierten Burst von Cloud-Lesezugriffen auf dieselben Assets. Ohne Cache zieht jeder Knoten jede Textur, jede zwischengespeicherte Simulation, jede Abhängigkeit parallel — was sowohl internationale Bandbreite verschwendet als auch auf dem ersten Frame jedes Bereichs langsam ist.
Deshalb existiert der Shared Cache. Wir beschreiben ihn im Detail im nächsten Abschnitt, aber die Integration mit Cloud-File-Streaming ist der Grund, warum er existieren muss. Asset-Pulls aus der Cloud werden einmal durch die Cache-Box konzentriert und dann über das LAN an alle zwanzig Knoten verteilt. Die Cloud-Plattform sieht niemals zwanzig gleichzeitige Abrufe derselben Textur — sie sieht einen einzigen Abruf, plus warme SMB-Lesezugriffe innerhalb unseres Netzwerks.
Das andere praktische Detail ist Write-Back. Wenn ein Render-Frame fertiggestellt ist, schreibt der Knoten die Ausgabe zurück auf die Cloud-File-Streaming-Plattform — über das Kunden-Konto. Das Team des Kunden im Remote-Büro sieht die Frames in Echtzeit im Projektbaum erscheinen. Es gibt keinen manuellen Upload-Schritt, keine anbietervermittelte Übertragung; die Cloud-Plattform übernimmt den gesamten Kreislauf.
Shared-Cache-Architektur
Der Shared Cache ist eine von zwei oder drei architektonischen Entscheidungen, die, wenn sie falsch getroffen werden, den Wert eines Clusters leise untergraben. Wir haben diese Entscheidung in früheren Bereitstellungen falsch getroffen. Das Muster, das sich über mehrere Builds bewährt hat, ist bewusst konservativ.
Ein einzelner Edge-and-Cache-Host läuft unter Ubuntu 22.04 LTS, mit einer einzelnen 8-TB-SATA-SSD, formatiert als ext4 und über Samba SMB3 dem Cluster zugänglich gemacht. Der Cache-Mount erscheint auf jedem Render-Node unter einem festen Pfad (z. B. \\cache.lan\proj). Wenn ein Knoten eine Projektdatei über den Cloud-File-Streaming-Client öffnet, wird die Datei durch den lokalen Cache gestreamt; nachfolgende Lesezugriffe auf dieselbe Datei auf jedem Knoten treffen direkt auf die SSD über das LAN.
In diesem Absatz stecken drei bewusste Entscheidungen.
Erstens: ein einziger Cache, keine knotenspezifischen Caches. Eine frühere Version dieser Architektur speicherte Cache-Material pro Knoten. Bei zwanzig RTX 5090-Knoten bedeutete das bis zu 200 TB redundanten Speicher zu verwalten und zwanzig separate Cache-Zustände zu debuggen, wenn etwas auseinanderlief. Die Konsolidierung auf einen einzigen Shared Cache reduziert den Speicherbedarf um den Faktor zwanzig und macht den Cache-Zustand zu einem einzigen Artefakt, das das Operations-Team einsehen kann.
Zweitens: eine einzelne SSD auf ext4, kein RAID 10 mit LUKS auf XFS. Der frühere Plan sah vor, dass der Cache auf einem RAID-10-Array mit LUKS-Verschlüsselung im Ruhezustand auf XFS liegen sollte. Dieser Plan war für die tatsächlich eingesetzte Hardware überentwickelt — eine SSD, ein Dateisystem, ein Mount. Wir haben die RAID-Schicht entfernt, LUKS entfernt und ext4 verwendet, weil der Cache nicht die Quelle der Wahrheit für Projektdaten ist. Die Cloud des Kunden ist die Quelle der Wahrheit. Fällt das Cache-Laufwerk aus, ersetzen wir es und wärmen es vom Upstream neu auf; Redundanz auf der Cache-Ebene ist nicht nötig, weil Redundanz auf der Cloud-Ebene vorhanden ist. (Verschlüsselung im Ruhezustand lag außerhalb des Umfangs dieses Auftrags, ist aber als separate Beauftragung verfügbar, wenn ein Endkunde dies vorschreibt.)
Drittens: den Cache vor dem ersten Produktionstag vorwärmen. Das ist die Lektion, die wir auf die harte Tour gelernt haben. Am ersten Tag ist jeder Cache-Miss der teuerste Lesezugriff im Cluster — er durchquert den internationalen Link, zieht aus dem Cloud-Speicher des Kunden und schreibt auf die lokale SSD, bevor der Renderer die Datei verwenden kann. Vorwärmen — ein strukturierter Durchlauf durch den Asset-Baum des Projekts am Vortag — wandelt die Lesezugriffe des ersten Tages von kalten Cloud-Pulls in warme SMB-Lesezugriffe um. Wir planen jetzt ein Vorwärm-Fenster in jeden dedizierten Cluster-Auftrag ein.
Innerhalb der Einrichtung mountet jeder Knoten den Cache unter demselben festen Pfad (\\cache.lan\proj) über SMB3 auf dem lokalen LAN. Da der interne Verkehr nicht den WireGuard-Tunnel durchquert, gilt MSS-Clamping hier nicht, und der Link läuft durchgehend mit Gigabit-Ethernet-Geschwindigkeit. Der Cache-Mount-Pfad ist auf jedem Knoten identisch, was die Render-Manager-Konfiguration des Kunden vereinfacht — derselbe Szenedatei-Pfad löst sich auf jedem Mitglied des Pools gleich auf.
Netzwerk-Optimierung für grenzüberschreitenden Betrieb
Die Transportebene entscheidet darüber, ob sich ein grenzüberschreitender Cluster nahtlos oder gebrochen anfühlt. Die Standardverhalten von TCP/IP, IP-Fragmentierung und DNS-over-VPN sind für langdistanzige verschlüsselte Tunnel, die SMB und Remote Desktop transportieren, subtil falsch. Kernel und Netzwerkkonfiguration zu optimieren ist keine Option; es ist der Unterschied zwischen einem funktionierenden Cluster und einem, der mysteriöserweise große Pakete verliert.
WireGuard, Hub-and-Spoke. Jeder Artist verbindet sich von seiner Workstation über einen WireGuard-Client mit dem Hub an der Cluster-Einrichtung. Der gesamte Verkehr zwischen Artist und Cluster ist Ende-zu-Ende verschlüsselt. Wir verwenden bewusst eine einzige VPN-Technologie, anstatt Protokolle zu mischen; IPSec für eine Rolle und ein anderes VPN für eine andere zu kombinieren erzeugt operativen Mehraufwand ohne Sicherheitsgewinn.
TCP BBR. Linuxs Standard-Staukontrolle (CUBIC) wurde für Verbindungen mit geringer Latenz und wenig Paketverlust entwickelt. Langdistanz-ISP-Verbindungen, die verschlüsselten Verkehr transportieren, sehen sehr anders aus — moderate Latenz, gelegentliches Jitter und asymmetrische Verlustmuster. BBR liefert auf diesen Verbindungen konsistent mehr nutzbaren Durchsatz als CUBIC, besonders wenn die Verbindung mit dem übrigen Internet-Verkehr des Kunden geteilt wird. Wir verwenden Kernels Standard-BBR (BBR v1); das neuere BBRv3 wurde in diesem Build nicht eingesetzt, und die Standardversion war für uns stabil.
TCP MSS Clamping. Dies ist die häufigste Ursache für „Der Cluster funktioniert meistens, außer bei großen Dateien"-Beschwerden. Wenn Verkehr einen Tunnel durchquert, der die effektive MTU reduziert, werden große Pakete entweder fragmentiert (langsam) oder lautlos verworfen (schlimmer). Kleine Pakete und Ping funktionieren einwandfrei, was das Problem schwer zu diagnostizieren macht. Die Lösung ist, TCP MSS am WireGuard-Router zu clampen, sodass TCP eine Paketgröße aushandelt, die in den Tunnel passt. Danach hören TLS-Handshakes, RDP-Sessions und SMB-Lesezugriffe großer Dateien auf zu hängen.
dnsmasq mit dem VPN-Interface aufgelistet. Ein subtiler Fallstrick: dnsmasq muss das WireGuard-Interface (z. B. wg0) explizit in seiner Konfiguration aufführen, auch wenn der Client eine private .lan-Adresse abfragt. Ohne diese Konfiguration laufen DNS-Lookups über den Tunnel aus, aber Ping funktioniert noch, weil Ping nicht über DNS läuft. Das erzeugt einige der verwirrendsten Diagnosesitzungen, die wir erlebt haben, weil jeder andere Test einwandfrei aussieht.
chrony für NTP. Zeitsynchronisation klingt trivial, ist aber für Render-Manager (Deadline stempelt Jobs), Log-Korrelation über den Cluster und Auth-Token mit Zeitkomponente wichtig. chrony verarbeitet Uhrabweichungen über einen Hochlatenz-Link besser als das ältere ntpd; wir betreiben es auf der Edge-Box und lassen jeden Knoten damit synchronisieren.
Die kombinierte Wirkung dieser Entscheidungen ist ein Tunnel, der sich für die meisten Workloads wie ein LAN anfühlt und sich sauber degradiert, wenn der öffentliche Pfad ungewöhnlich überlastet ist. Der nächste Abschnitt beschreibt, wie der Betrieb von 3D-Arbeit über diesen Tunnel in der Praxis aussieht.
Moonlight und Sunshine für Remote Desktop
Remote Desktop ist die Schicht, die Artists am direktesten erleben. Wenn sich die Remote-Desktop-Schicht träge oder ruckelig anfühlt, spielt es keine Rolle, wie schnell der Renderer ist — die Hände der Artists sind langsam, und der Auftrag leidet.
Wir verwenden Moonlight (Client) und Sunshine (Host auf jedem Knoten) für Remote Desktop. Die Kombination nutzt NVIDIAs NVENC Hardware-Encoder auf der RTX 5090, um den Frame-Buffer in Echtzeit zu kodieren und dann an die Workstation des Artists zu streamen. Da das Kodieren auf der GPU stattfindet, die bereits im Knoten ist, gibt es keine Konkurrenz mit dem Renderer, und die durch Remote Desktop hinzugefügte Latenz wird durch die Netzwerk-Roundtrip-Zeit dominiert — nicht durch die Kodierungsphase.
Für 3D-Viewport-Arbeit ist das auf eine Art und Weise relevant, die es bei traditionellem Remote Desktop nicht ist. Ältere Protokolle — RDP, VNC, der Standard-Microsoft-Remote-Desktop — wurden für Büro-Workloads entwickelt. Sie verarbeiten Text, Dialoge und sich langsam ändernde Fenster gut, aber bei einem Vollbild-3D-Viewport während einer Turntable-Vorschau versagen sie. Moonlight + Sunshine behandelt den Frame-Buffer als Video, was genau das richtige Modell für 3D-Arbeit ist.
Wir haben einen Qualitäts-Gate-Test — intern „Test 8" genannt — den wir ausführen, bevor wir einen Knoten an einen Artist übergeben. Dieser Test führt eine definierte Sequenz von Viewport-Operationen unter Last aus und bestätigt, dass die Remote-Desktop-Erfahrung eine Basislinie erfüllt. Besteht ein Knoten den Test nicht, debuggen wir entweder die Kodierpipeline oder nehmen den Knoten aus dem Betrieb, bis das Problem gelöst ist. Wir führen diesen Test zu Beginn jedes Auftrags und nach jedem Knoten-Reimage durch.
Parsec ist ein praktikabler Ausweich-Kandidat, wenn Sunshine ein host-spezifisches Problem hat. Wir haben eine kleine Anzahl von Knoten mit Parsec ausgeliefert, wenn Sunshine nicht zuverlässig konfiguriert werden konnte; die Artist-Erfahrung ist ähnlich. Wir standardisieren darauf nicht, weil das kontobasierte, cloud-koordinierte Modell nicht so sauber zu Model-B-Anmeldedaten-Handling passt wie selbstgehostetes Sunshine.
Wir haben in der frühen Planung andere Remote-Desktop-Optionen in Betracht gezogen und verworfen — generische Remote-Desktop-Tools ohne GPU-Kodierung und eine Open-Source-Alternative, die unseren Qualitäts-Gate auf einem Vollbild-3D-Viewport nicht bestand. Das Prinzip, das zählt: Für GPU-Cluster-Knoten ist hardware-kodiertes Streaming das einzige Modell, das im Maßstab standhält.
Kapazitätsplanung und reservierter Slot
Die 20-Knoten-Konfiguration in diesem Leitfaden ist ein reservierter dedizierter Slice der breiteren Flotte von Super Renders Farm, der für die Dauer des Auftrags herausgeschnitten wird. Reserviert bedeutet: Die Knoten werden nicht mit dem Managed-Service-Pool geteilt, nicht mit anderen Tenants co-geplant und nicht per Frame abgerechnet — der Kunde zahlt für den Slice als pauschale Betriebsausgabe und hat exklusive Kontrolle über diese Knoten vom Kickoff bis zum Teardown.
Die Größe des Slice auf zwanzig Knoten ist eine bewusste Entscheidung. Unter zehn Knoten rechtfertigt ein Cluster den architektonischen Mehraufwand gegenüber einer Managed render farm nicht — der SaaS-Weg ist einfacher und wirtschaftlicher. Über dreißig hinaus braucht die Cache-Schicht eine Neuarchitektur (mehrere Cache-Boxen, regionale Caches), und das Betriebsmodell ändert seine Form. Zwanzig ist der Bereich, in dem eine einzelne Edge-and-Cache-Box, ein einzelner WireGuard-Hub und ein einheitliches Windows-Image sauber funktionieren — und in dem ein Kreativteam von zehn bis zwanzig Artists genug Knoten hat, damit Frames während Crunch-Phasen fließen, ohne Leerlaufzeit im Normalbetrieb.
Da Super Renders Farm eine substanzielle Flotte über diesen dedizierten Slice hinaus betreibt, besteht Spielraum für Scale-up, wenn der Auftrag es erfordert. Das Hinzufügen weiterer reservierter Knoten innerhalb derselben Einrichtung ist eine Konfigurationsänderung, kein Beschaffungszyklus. Kunden mit mehrmonatigen Aufträgen legen die Slice-Größe typischerweise beim Kickoff fest und überarbeiten sie an Quartalsgrenzen auf Basis des tatsächlichen Bedarfs gegenüber dem ursprünglichen Plan.
Netzwerksegmentierung
Netzwerksegmentierung in einem solchen Cluster ist keine Option. Der Kunde operiert auf der Infrastruktur des Anbieters, darf aber niemals das breitere Netzwerk des Anbieters sehen — nicht das NAS des Anbieters, nicht die Router-Admin-Interfaces des Anbieters, nicht andere Tenants. Ebenso dürfen die internen Systeme des Anbieters niemals den Workloads des Kunden ausgesetzt sein.
Wir implementieren Segmentierung in zwei Stufen.
Stufe 1 — Edge-Firewall. Die Edge-and-Cache-Box führt ufw (Uncomplicated Firewall) in einer Standard-Deny-Inbound-Haltung aus. Nur der WireGuard-UDP-Port (51820) ist dem öffentlichen Internet zugänglich. SSH, SMB, DNS, NTP und alle anderen auf der Edge laufenden Dienste sind an interne Interfaces gebunden und von außerhalb des Clusters nicht erreichbar. Weiterleitungsregeln erlauben Pakete zwischen dem WireGuard-Interface und dem Cluster-LAN, aber nicht zwischen einem dieser Netzwerke und den anderen internen Netzwerken des Anbieters. Die Standard-Forward-Haltung ist Verwerfen, sofern nicht explizit erlaubt.
Stufe 2 — Host-Firewall auf jedem Knoten. Jeder Render-Node hat seine eigene Windows-Firewall-Konfiguration, die die Edge-Haltung spiegelt — eingehende Verbindungen aus Cluster-IPs für die benötigten Dienste (SMB, Remote Desktop, Render-Manager) akzeptieren und alles andere verwerfen. Das ist keine Redundanz; es ist Defense in Depth. Wenn ein Knoten falsch konfiguriert oder kompromittiert wird, bleibt die Host-Firewall eine Barriere.
Das Prinzip hinter beiden Stufen ist Least Privilege: Der Kunde und die Knoten sollen die Knotengruppe sehen und nichts sonst. Wir geben dem Kunden keine allgemeinen Routen in das interne Netzwerk des Anbieters. Der Tunnel des Kunden endet an der Edge-Box; die Edge-Box leitet nur in das Cluster-LAN; das Cluster-LAN leitet nur zwischen Cluster-Mitgliedern.
In der Praxis kann der Kunde die anderen Systeme des Anbieters nicht anpingen oder scannen, selbst wenn er es wollte. Keine gemeinsame Management-Ebene, kein gemeinsamer Monitoring-Pfad, der andere Tenants exponiert.
Gelernte Lektionen
Diese fünf operativen Lektionen haben uns bei jeder dedizierten Cluster-Bereitstellung entweder Stunden des Debuggings erspart — oder, wenn wir sie vergessen haben anzuwenden, Stunden des Debuggings gekostet.
1. Dual-Home-Gateway-Routing-Falle. Wenn die Edge-Box zwei Netzwerk-Interfaces hat (eines öffentlich, eines LAN), kommt es auf die Reihenfolge an. Die LAN-Route muss konfiguriert werden, bevor die Standard-Route geändert wird. Wenn Sie zuerst die Standard-Route ändern und dann versuchen, die LAN-Route hinzuzufügen, kann die SSH-Session, mit der Sie eingeloggt sind, in dem Moment abbrechen, in dem sich die Standard-Route ändert — und Sie sich selbst aussperren. Die Lösung ist verfahrenstechnisch, nicht technisch: immer zuerst interne Routen konfigurieren, validieren, und dann erst die Standard-Route ändern.
2. WireGuard und DNS. dnsmasq muss explizit jedes Interface aufführen, auf dem es lauschen soll, einschließlich des WireGuard-Interface. Führen Sie nur das LAN-Interface auf, laufen DNS-Lookups von VPN-Clients aus — aber Ping funktioniert noch, weil Ping nicht über DNS läuft. Das ist einer der diagnostisch irreführendsten Ausfallmodi, den wir erlebt haben. Die Lösung ist eine Zeile in der dnsmasq-Konfiguration, aber Sie müssen wissen, wo Sie suchen müssen.
3. TCP MSS Clamping ist durch einen Tunnel nicht optional. TLS-Handshakes, RDP-Sessions, SMB-Lesezugriffe großer Dateien — alles, was große Pakete senden möchte — wird lautlos verworfen, wenn MSS nicht geclampt ist. Das erste Symptom ist meist „Moonlight funktioniert zehn Sekunden, dann friert es ein" oder „SMB listet Verzeichnisse auf, kann aber Dateien größer als 1 MB nicht lesen". Die Lösung ist eine iptables-Regel auf dem WireGuard-Host. Vor der Übergabe des Clusters anwenden.
4. Speicher richtig dimensionieren, nicht überentwickeln. Die frühere Version dieser Architektur spezifizierte RAID 10 mit LUKS-Verschlüsselung auf XFS. Die tatsächlich eingesetzte Cache-Hardware war eine einzelne SSD. Wir haben die RAID-Schicht entfernt, die LUKS-Schicht entfernt und ext4 verwendet — weil der Cache nicht die Quelle der Wahrheit ist, das Cloud-Speicher-System ist es. Redundanz auf der Cache-Ebene gegen echte Redundanz auf der Cloud-Ebene einzutauschen war die richtige Entscheidung. Die Lektion: Speicher nach dem ausrichten, was die Daten tatsächlich erfordern, nicht nach dem, was in einem Planungsdokument sicher wirkt.
5. Den Cache vorwärmen. Am ersten Tag kostet jeder Cache-Miss den internationalen Link und die Cloud-Plattform einen Roundtrip. Die erste Produktionsstunde auf einem kalten Cache fühlt sich langsam an, selbst wenn alles andere korrekt konfiguriert ist. Wir planen jetzt ein Vorwärm-Fenster in jeden Auftrag ein — normalerweise einen oder zwei Tage vor Produktionsbeginn. Der Artist sieht das Vorwärmen nicht; er erlebt einen Cluster, der sich bereits auf dem ersten Frame schnell anfühlt.
Das sind operative Lektionen, keine architektonischen. Sie leben in der Deployment-Checkliste, nicht im Architekturdokument. Aber sie trennen einen Cluster, der in der Theorie funktioniert, von einem, der unter realer Produktionslast standhält. Kleinere Muster werden auftrags-spezifisch angewendet — die fünf oben genannten tauchen bei jeder Bereitstellung auf.
Fazit
Eine dedizierte 20-Knoten-grenzüberschreitende GPU-render-farm ist die richtige Architektur, wenn IP-Kontrolle vertraglich vorgegeben ist, der Auftrag mehrere Monate läuft, der Workflow individuelle Konfiguration erfordert und Bring-your-own-Cloud-Authentifizierung nicht verhandelbar ist. Außerhalb dieser Bedingungen ist eine Managed render farm fast immer die bessere Antwort — die architektonische Komplexität hier rechtfertigt sich nicht für projektbasierte Arbeit oder für Teams ohne eine dedizierte Operations-Funktion.
Wenn die Bedingungen zutreffen, sind die hier beschriebenen Muster — Model-B-Anmeldedaten, Shared Cache auf ext4, WireGuard-Hub-and-Spoke-Transport, BBR mit MSS Clamping, Moonlight + Sunshine für Remote Desktop, zweistufiges Firewalling — das, was wir standardmäßig einsetzen. Es sind nicht die einzigen gültigen Muster, aber die, die sich über Bereitstellungen hinweg bewährt haben.
Das Team hinter Super Renders Farm betreibt sowohl Managed-render-farm-Angebot als auch dedizierte Cluster-Bereitstellungen — einschließlich der dedizierten GPU-Cluster-Konfigurationen und grenzüberschreitenden Topologien, die in diesem Leitfaden beschrieben werden.
FAQ
Q: Wie lange dauert eine typische 20-Knoten-Cluster-Bereitstellung? A: Je nach Umfang, Hardware-Bereitschaft an der Einrichtung und Cloud-File-Streaming-Setup des Kunden dauert ein typischer Auftrag von einigen Wochen Vorlaufzeit für Hardware und Netzwerk-Bereitstellung bis zu einem Vorwärm-Fenster von ein bis zwei Tagen vor Produktionsbeginn. Wir dimensionieren den Zeitplan nach dem Produktionskalender des Kunden, nicht nach einer festen Vorlage.
Q: Was, wenn mein Team über drei Kontinente verteilt ist? A: Die WireGuard-Hub-and-Spoke-Topologie skaliert auf zusätzliche Client-Standorte, ohne die Cluster-Architektur zu ändern. Jeder Remote-Artist führt einen WireGuard-Client aus und verbindet sich mit demselben Hub an der Cluster-Einrichtung. Die Latenz aus jeder Region wird durch den öffentlichen Internet-Pfad zwischen dieser Region und dem Hub bestimmt; in unserer Erfahrung machen BBR und MSS Clamping den Unterschied zwischen nutzbarer und nicht nutzbarer Verbindung auf diesen Pfaden.
Q: Kann ich den Cluster sehen, bevor ich mich zu einem mehrmonatigen Auftrag verpflichte? A: Wir arrangieren in der Regel ein Proof-of-Concept-Fenster während des Scoping-Gesprächs. Die genaue Form hängt vom Projekt des Kunden ab — manchmal ist es eine Remote-Desktop-Session auf einem einzelnen Knoten, um die Artist-Erfahrung zu testen, manchmal ein kleiner Render-Test, um die Cache- und Cloud-File-Streaming-Integration zu validieren. Konkrete Bedingungen sind ein geschäftliches Gespräch; kontaktieren Sie unser Sales-Team, um zu besprechen, was für Ihren Zeitplan passt.
Q: Wie wird Datensicherheit am Ende des Auftrags gehandhabt? A: Da Model B Kunden-Anmeldedaten aus unseren Händen hält, konzentriert sich der Auftragsabschluss auf Hardware- und Cache-Bereinigung. Wir löschen den SMB-Cache, spielen jeden Knoten von der sauberen Basislinie neu auf und stellen eine schriftliche Bestätigung aus, dass Cache und Node-Images vernichtet wurden. Der Kunde widerruft seine eigenen Cloud-File-Streaming-Sessions, was außerhalb unseres Systems liegt. Konkrete Vertragssprache (NDA, SLA, Wortlaut des Bestätigungsschreibens) wird durch unser Sales-Team abgewickelt.
Q: Was, wenn ich mehr als 20 Knoten benötige? A: Die 20-Knoten-Konfiguration ist die häufigste Form, die wir bereitstellen, aber die Architektur skaliert darüber hinaus. Größere Flotten werden innerhalb derselben Einrichtung hinzugefügt — zusätzliche reservierte Knoten speisen sich in denselben WireGuard-Hub, denselben SMB3-Cache und dasselbe einheitliche Windows-Image ein. Die praktische Grenze ist in der Regel die Cache-Bandbreite: Eine einzelne Edge-and-Cache-Box hat eine endliche SMB-Lese-Obergrenze, und bei sehr großen Flotten muss die Cache-Architektur selbst neu gedacht werden (mehrere Cache-Boxen, regionale Caches). Wir besprechen diese Design-Entscheidungen auftrags-spezifisch.
Q: Kann ich meine eigene Lizenz für Cinema 4D, Redshift oder andere DCC-Tools mitbringen? A: Das Lizenzmodell — Bring-your-own-License gegenüber anbieterseitig bereitgestellten Lizenzen — ist eine geschäftliche Entscheidung, die vom spezifischen DCC und dem bestehenden Lizenzbestand des Kunden abhängt. Manche Konfigurationen funktionieren sauber mit Kunden-Lizenzen; andere sind mit anbieterseitig bereitgestellten einfacher. Wir klären das im Scoping-Gespräch. Kontaktieren Sie unser Sales-Team für Details.
Q: Wie gehen Sie mit Cloud-Speicher von EU- gegenüber US-Anbietern um? A: Die Cloud-File-Streaming-Plattform ist die Wahl des Kunden. Unser Cluster integriert mit jeder Plattform, die einen Sign-in-Client auf Windows ausführen und den Projektbaum des Kunden als gemountetes Dateisystem zugänglich machen kann. Der geografische Standort des vorgelagerten Cloud-Speichers beeinflusst die internationale Latenz des Kunden-zu-Cluster-Pfads — weshalb wir den WireGuard-Hub-and-Spoke-Transport und die BBR-optimierte Konfiguration für grenzüberschreitende Setups empfehlen. Wir hosten die Cloud-Plattform nicht selbst; sie verbleibt unter dem Kunden-Konto.
Q: Was passiert, wenn der WireGuard-Tunnel abbricht? A: WireGuard stellt die Session automatisch wieder her, wenn das zugrunde liegende Netzwerk sich erholt; die Remote-Desktop-Session des Kunden kann während des Re-Handshakes kurz pausieren. Bricht der Tunnel ab, während ein Render läuft, läuft das Rendering selbst weiter auf dem Knoten (es ist nicht vom Tunnel für laufende Arbeit abhängig), aber Write-Back in die Cloud steht in der Warteschlange, bis der Tunnel wiederhergestellt ist. Wir überwachen den Tunnel-Zustand von der Edge-Box und alarmieren bei anhaltenden Ausfällen.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



