
Como Avaliamos GPUs de Render Farm: Um Método Reproduzível de Custo por Frame (2026)
Visão geral
Introdução
Uma pontuação de benchmark é fácil de publicar e difícil de confiar. Qualquer pessoa pode publicar "RTX 5090: X pontos", mas o número que decide se vale a pena executar um trabalho de renderização numa placa ou noutra não é uma pontuação sintética — é o custo por frame concluído. Esse valor depende da cena, das definições de renderização, do motor, do driver e da forma como se faz a aritmética, e quase nenhum desses elementos é visível numa entrada de tabela classificativa.
Esta página descreve o método, não a tabela classificativa. Documenta como avaliamos GPUs de render farm na Super Renders Farm de modo a que o resultado seja significativo: como escolhemos uma cena de benchmark, quais as definições de renderização que bloqueamos, o que mantemos constante em toda a matriz de hardware, como convertemos tempos brutos por frame num número de custo por frame defensável e — a parte que a maioria dos artigos omite — os passos explícitos para que uma terceira parte possa reproduzir tudo no seu próprio hardware. Já publicámos os resultados deste método; esta é a receita por detrás deles. Quando um número aparece abaixo, trata-se de um valor real de um desses estudos, citado como exemplo de aplicação e não rederivado aqui.
Benchmarks sintéticos versus custo por frame de produção
Existem duas camadas na avaliação de GPU, e confundi-las é a origem de grande parte da confusão.
A primeira é a camada sintética: ferramentas padronizadas que renderizam uma cena fixa e emitem uma pontuação. O Cinebench R24, o V-Ray Benchmark da Chaos e o OctaneBench situam-se aqui. São úteis para classificação relativa — uma carga de trabalho repetível, igual em todas as máquinas, permitindo alinhar placas umas contra as outras. Explicamos como interpretar essas pontuações no nosso guia de benchmark V-Ray e no artigo sobre pontuações Cinebench para renderização na nuvem. O que uma pontuação sintética elimina deliberadamente é tudo o que varia em produção: a geometria, o sampling, o denoiser, a resolução de saída e a sobrecarga por trabalho que uma fila real comporta.
A segunda é a camada de produção: quanto tempo demora realmente um frame representativo e quanto custa. Esta é a camada visada por esta metodologia. Uma pontuação sintética é um dado de entrada — uma forma de extrapolar uma estimativa inicial — mas não é a resposta. A ligação entre ambas é simples em princípio: uma máquina que pontua aproximadamente o dobro de outra no mesmo build de benchmark renderizará um frame comparável em cerca de metade do tempo. Detalhamos essa aritmética de estimativa (eficiência = tempo de frame ÷ pontuação de benchmark) no guia de V-Ray. O objetivo de um método de benchmark, por oposição a uma pontuação, é tornar essa extrapolação honesta — medir numa cena próxima da produção e reportar a distribuição, não apenas um ponto médio.
A métrica que importa: custo por frame
O custo por frame é a unidade a que uma metodologia deve chegar, porque é a unidade em que um orçamento de renderização é efetivamente escrito. A fórmula é simples:
Custo por frame = tempo de relógio de parede por frame × custo do nó por hora
O tempo de relógio de parede por frame é o tempo da tarefa dividido pelo número de frames, medido — não a leitura interna de "tempo de renderização" do motor, que exclui o carregamento da cena, a construção da estrutura de aceleração e a coordenação de dispositivos. O custo do nó por hora é o custo de funcionamento do hardware durante uma hora, independentemente da forma de contabilização. Na nossa render farm, a renderização GPU é faturada a $0,003 por OctaneBench-hora, e uma única RTX 5090 (32 GB) tem uma base de hardware de aproximadamente $5,2 por hora de placa; o nosso guia de custo por frame e o guia de preços abordam o modelo orientado ao cliente em detalhe.
A combinação dos dois dados é apenas aritmética de unidades: converte-se o tempo de relógio de parede por frame em horas e multiplica-se pelo custo do nó por hora, de modo a que segundos por frame e dólares por hora resultem em dólares por frame. Um frame curto num nó económico resulta num valor baixo; um frame pesado num nó dispendioso resulta num valor elevado. Mantemos deliberadamente a taxa calculada fora desta página de metodologia — o custo real depende da complexidade da cena, do sampling, do tempo de espera na fila e do modelo de faturação utilizado, sendo o nosso guia de custo por frame e o guia de preços os locais adequados para os números orientados ao cliente. O ponto importante é que a fórmula é auditável: mantendo as unidades explícitas, qualquer pessoa pode verificar o valor em vez de o aceitar por fé.
A razão pela qual o custo por frame, e não uma pontuação sintética, é a métrica fundamental: duas placas podem pontuar de forma semelhante num benchmark e ainda assim diferir significativamente no custo por frame da cena em questão, porque a cena determina quanto de cada frame é trabalho paralelizável versus sobrecarga fixa que o silício mais rápido não consegue eliminar.
A cena de benchmark e as definições de renderização
A cena é o maior fator determinante para que um benchmark seja transferível para a produção, pelo que executamos deliberadamente dois tipos.
Cenas padrão de fornecedor para classificação entre máquinas. Quando o objetivo é uma comparação limpa e equitativa, utilizamos cenas de referência publicadas — as cenas Open Data do Blender (bmw27, classroom, junkshop), a cena Vultures da Maxon para Redshift, o V-Ray Benchmark da Chaos e o OctaneBench. Estas são repetíveis e verificáveis de forma independente, o que é exatamente o que uma classificação necessita. A sua fraqueza é que não correspondem à cena do utilizador, pelo que os tempos absolutos não se transferem diretamente para a produção.
Cenas representativas de produção para o custo por frame. Quando o objetivo é um número com base no qual um operador pode planear, a cena tem de se assemelhar a trabalho real — geometria real, conjuntos de texturas reais, sampling real, resolução de saída real. No nosso estudo de escalonamento multi-GPU, executámos o Blender Cycles a 200 % de resolução especificamente para que cada renderização durasse tempo suficiente para produzir um rácio estável e fiável — o que também significa que esses tempos brutos de Cycles não são comparáveis às pontuações públicas do Open Data. Essa troca é o método a funcionar como previsto: ajustar a cena à questão.
Independentemente da cena, as definições de renderização devem ser bloqueadas e registadas: contagem de amostras (ou limiar de ruído), denoiser ativo/inativo e qual, resolução de saída, tamanho do tile ou bucket e o build do motor. Um benchmark em que qualquer um destes elementos varie entre máquinas está a medir a variação, não o hardware.
A matriz de hardware
Uma matriz de benchmark é uma grelha: as placas em teste num eixo, os motores e cenas no outro. A disciplina está no que se mantém constante em toda a grelha.
Mantém-se constante: sistema operativo, versão e build do motor de renderização, denoiser, cena e definições. Regista-se mas nem sempre se consegue igualar: o driver de GPU — uma placa de geração atual por vezes requer um driver mais recente do que uma placa mais antiga consegue executar, pelo que uma correspondência exata de drivers é impossível. Quando isso acontece, deve ser identificado. No estudo multi-GPU, o nó RTX 5090 executou o driver 596.36 e o nó RTX 4090 o driver 610.62, tendo sido assinalado que a diferença afeta apenas a comparação absoluta entre gerações, não os rácios de escalonamento dentro do nó (que utilizam a mesma placa e driver em ambos os lados).
A nossa frota de GPU está padronizada com placas NVIDIA RTX 5090 com 32 GB de VRAM, o que torna a nossa matriz internamente consistente — um inventário uniforme significa que uma estimativa de um nó é transferível para o seguinte. Como exemplo de aplicação do eixo por placa, apresenta-se o resultado de placa única do estudo multi-GPU, RTX 5090 versus RTX 4090 em cenas idênticas:
| Motor / cena | Métrica | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | segundos (menor é melhor) | 49,45 | 77,40 |
| Cycles — classroom | segundos | 23,09 | 36,87 |
| Redshift — Vultures | segundos | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (maior é melhor) | 15.333 | 9.608 |
| Octane | pontuação OctaneBench | 1.690,78 | 1.074,17 |
Dois tipos de métricas aparecem nessa tabela — segundos (menor é melhor) e pontuação de benchmark (maior é melhor) — o que explica precisamente por que os números absolutos nunca são comparáveis entre motores. Apenas o rácio dentro de um único motor é uma comparação equitativa.
Controlos que tornam um benchmark fiável
A diferença entre um número e um número fiável são os controlos. Estes são os que o nosso método aplica.
- Uma tarefa por GPU. O nosso agendador executa uma tarefa de renderização por placa, pelo que cada valor é um número limpo por placa — o valor que se multiplica para planear a capacidade, não uma média distorcida num dispositivo partilhado.
- Pares correspondentes para qualquer comparação. Ao comparar gerações de hardware em produção, uma cena só era contabilizada se a mesma cena e o mesmo utilizador tivessem sido executados em ambos os lados, com pelo menos três tarefas por lado antes de ser qualificada. No estudo de campo RTX 5090, 38 cenas superaram esse critério de um total de 1.419 tarefas — 38 não é o tamanho dos dados, é o que sobrevive a um filtro deliberadamente rigoroso.
- Um driver por janela. Para o estudo de campo, um único driver (581.80, CUDA 13.0) executou toda a janela de sete semanas sem qualquer alteração, de modo a que nenhuma substituição a meio do período pudesse contaminar o resultado.
- Paridade de denoiser. Cerca de 83 % dos trabalhos Cycles executaram um passo de denoising com IA tanto no hardware novo como no de geração anterior — pelo que o denoiser foi uma constante, não uma variável escondida dentro do fator de aceleração.
- Quente versus frio. O custo fixo por tarefa — carregamento da cena, sincronização, construção da estrutura de aceleração — representa uma fração maior de um frame curto do que de um longo, razão pela qual frames curtos limitados por sobrecarga subestimam uma placa mais rápida. O método tem isso em conta ao reportar a distribuição, em vez de assumir um único multiplicador.
De tempos brutos a um número defensável
Depois de os tempos serem recolhidos, a estatística determina se o número principal é honesto.
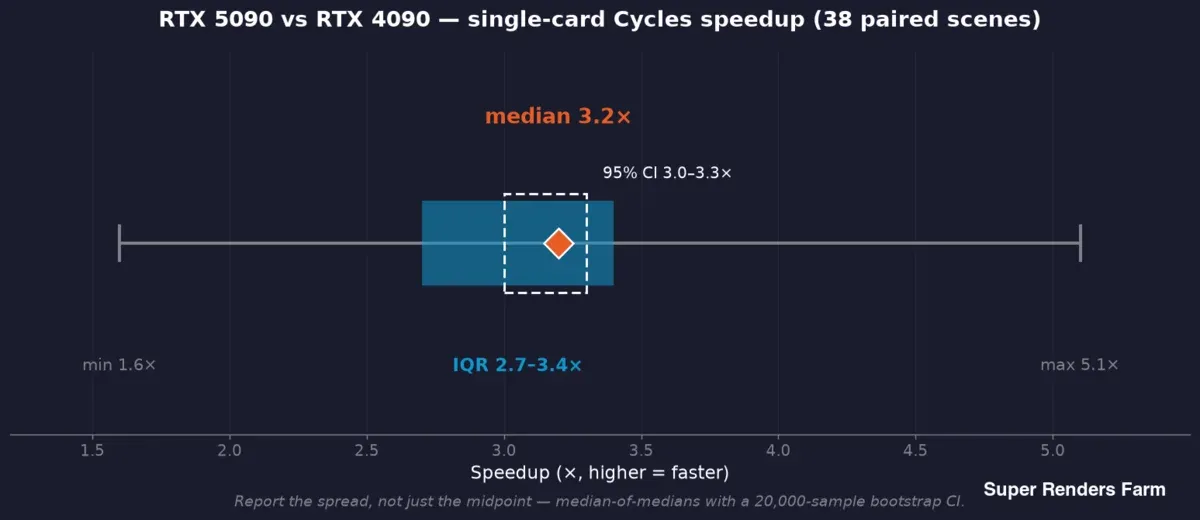
RTX 5090 versus RTX 4090 aceleração de Cycles com placa única em 38 cenas pareadas: mediana 3,2x, intervalo de confiança 95 % de 3,0 a 3,3x, intervalo interquartil de 2,7 a 3,4x, intervalo total de 1,6 a 5,1x
Utilizamos uma mediana de medianas: cada cena contribui com a mediana dos seus próprios tempos por frame em cada lado, e o valor principal é a mediana desses rácios por cena — de modo a que um frame lento não possa distorcer o resultado. Em torno desse ponto médio, reportamos um intervalo de confiança bootstrap (o estudo de campo utilizou um bootstrap de 20.000 amostras, dando um IC de 95 % de 3,0–3,3x em torno da mediana de 3,2x de aceleração) e a dispersão — intervalo interquartil de 2,7–3,4x, intervalo total de 1,6–5,1x nessas 38 cenas.
Essa distribuição não é ruído a eliminar por média; é o resultado. Uma aceleração típica de 3,2x e um pior caso de 1,6x numa cena são ambos verdadeiros em simultâneo, e um benchmark que reporta apenas o ponto médio oculta metade da informação de que um operador necessita. A regra que seguimos: reportar a mediana e o intervalo, e associar cada afirmação à amostra que a sustenta — aceleração de 38 cenas pareadas, VRAM de 57 trabalhos registados, consumo energético de um ensaio controlado separado, nunca uma amostra emprestada para suportar outra.
Como replicar este benchmark
Esta é a parte que transforma um benchmark num sinal merecido em vez de uma linha de marketing: qualquer pessoa o pode executar. Os passos abaixo reproduzem o método em qualquer fila ou bancada de teste.
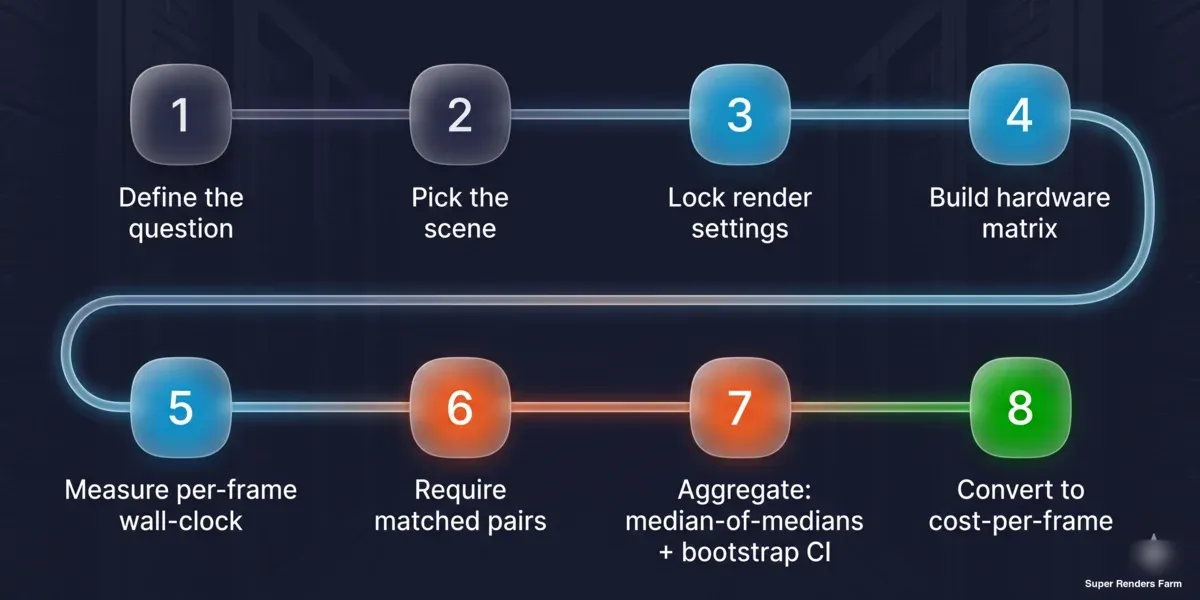
Método reproduzível de custo por frame em oito passos: definir a questão, escolher a cena, bloquear as definições de renderização, construir a matriz de hardware, medir o tempo de relógio de parede por frame, exigir pares correspondentes, agregar com mediana de medianas e intervalo de confiança bootstrap, converter para custo por frame
- Definir a questão. Classificação entre máquinas ou custo por frame de produção? A resposta escolhe o tipo de cena — padrão de fornecedor para classificação, representativa de produção para custo.
- Fixar a cena e as definições. Bloquear a contagem de amostras ou o limiar de ruído, a escolha do denoiser, a resolução de saída, o tamanho do tile/bucket e o build do motor. Registar tudo; faz parte do resultado.
- Construir a matriz. Listar as placas num eixo, as combinações de motor/cena no outro. Decidir o que se mantém constante (SO, build do motor, denoiser, cena) e registar o que não pode ser (driver).
- Medir o tempo de relógio de parede por frame. Utilizar o tempo da tarefa ÷ número de frames a partir do agendador ou de um cronómetro sobre o trabalho completo — não a leitura interna de tempo de renderização do motor, que omite a sobrecarga de carregamento e construção.
- Exigir pares correspondentes e uma amostra mínima. Para qualquer afirmação A versus B, executar a mesma cena em ambos os lados, com pelo menos três tarefas por lado, antes de ser contabilizada.
- Agregar com mediana de medianas. Tomar a mediana de cada cena por lado, depois a mediana dos rácios por cena. Calcular um intervalo de confiança bootstrap e reportar o intervalo interquartil e o intervalo total a par dele.
- Converter para custo por frame. Multiplicar o tempo medido por frame pelo custo do nó por hora. Manter as unidades explícitas para que o valor seja auditável.
- Publicar as ressalvas com o número. Indicar o tamanho da amostra por detrás de cada afirmação, a situação do driver, se os dados são observacionais ou controlados, e o âmbito que abrangem e o que não abrangem.
Um estúdio que execute estes oito passos no seu próprio hardware obterá um número que pode defender — e com o qual pode verificar o nosso, que é precisamente o objetivo de publicar o método.
Notas de honestidade: o que um benchmark pode e não pode afirmar
Um método só é tão fiável quanto as afirmações que recusa fazer. Três linhas que mantemos:
Observacional não é controlado. Os dados de campo de produção — trabalhos que os utilizadores executaram no decurso normal das suas atividades — são reais e úteis, mas os utilizadores ajustam as suas próprias cenas entre re-renderizações, pelo que são observacionais. Um confronto direto controlado e limpo entre anfitriões (por exemplo, uma RTX 5090 contra uma RTX 4090 atual em hardware idêntico) é um exercício controlado separado. Não permitimos que um se faça passar pelo outro.
Nó versus nó implica configuração, não apenas silício. Quando um lado corre em bare-metal e o outro em virtualizado, parte da diferença medida deve-se à configuração, não ao chip. Isso pertence à ressalva principal, não a uma nota de rodapé.
Nenhum número que não tenhamos medido. Não extrapolamos valores de consumo energético ou térmicos que não tenhamos avaliado. Onde o nosso estudo de campo reporta aproximadamente 360–375 W por placa, esse valor provém de um ensaio controlado sob carga sustentada — e o valor de energia por frame derivado dele é identificado como inferência, não como medição. Se um número não foi medido, o método não o inventa. Essa disciplina é a razão pela qual um benchmark publicado pode ser citado.
Exemplos de aplicação da nossa render farm
Este método produziu os estudos abaixo; cada um é um conjunto de dados que pode ser lido a par da receita, sendo o local indicado para consultar os números reais em vez de os rederivir aqui.
| Estudo | O que o método produziu | Amostra |
|---|---|---|
| Escalonamento multi-GPU | Escalonamento 1x→2x por motor em cenas padrão de fornecedor | 2 nós, 4 motores, 7 combinações de cena/benchmark |
| Notas de campo RTX 5090 | Distribuição de custo/aceleração em produção, percentis de VRAM | 38 cenas pareadas / 1.419 tarefas, 7 semanas |
| Guia de benchmark V-Ray | Estimativa de pontuação sintética para tempo de renderização | Tabelas de referência + estimativa de aplicação |
| Cinebench para renderização na nuvem | Interpretação de pontuação sintética para níveis de hardware | Pontuações de referência |
A mesma abordagem sustenta o planeamento de capacidade na nossa render farm GPU na nuvem, e os números específicos do Blender alimentam o nosso trabalho de renderização Blender na nuvem — o GPU representa uma minoria do total de trabalhos da render farm (a maior parte continua a ser renderização CPU), pelo que delimitamos estes valores de GPU exatamente como tal, e não como uma afirmação abrangente de toda a render farm.
FAQ
Q: Qual é a forma correta de avaliar uma GPU de render farm? A: Decidir primeiro se se pretende classificação entre máquinas ou custo por frame de produção. Para classificação, utilizar uma cena padrão de fornecedor repetível e um build de benchmark fixo. Para custo por frame, utilizar uma cena representativa de produção, medir o tempo de relógio de parede por frame (tempo da tarefa ÷ número de frames) e multiplicar pelo custo do nó por hora. Bloquear as definições de renderização e reportar a distribuição, não apenas um único número.
Q: Por que razão o custo por frame é melhor do que uma pontuação de benchmark? A: Uma pontuação sintética elimina tudo o que varia em produção — geometria, sampling, denoiser e resolução — pelo que duas placas podem pontuar de forma semelhante e ainda assim diferir no custo por frame real da cena em questão. O custo por frame é a unidade em que um orçamento de renderização é efetivamente escrito, razão pela qual uma metodologia deve chegar a esse valor em vez de a um ponto de tabela classificativa.
Q: Como se converte uma pontuação de benchmark numa estimativa de tempo de renderização? A: Utilizar o rácio de pontuações como rácio de velocidade aproximado: uma máquina com o dobro da pontuação de outra no mesmo build de benchmark renderiza um frame comparável em aproximadamente metade do tempo. Calcular a eficiência da máquina como tempo de frame dividido pela pontuação de benchmark, depois escalar pela pontuação da máquina alvo. Manter o build de benchmark constante, uma vez que pontuações de builds diferentes não são comparáveis.
Q: Que controlos tornam um benchmark de GPU fiável? A: Executar uma única tarefa de renderização por placa para obter números limpos por placa, exigir pares correspondentes (a mesma cena em ambos os lados, um número mínimo de tarefas antes de um resultado ser contabilizado), manter o driver e o build do motor constantes dentro de uma janela de medição, e manter a definição do denoiser idêntica em toda a comparação. Depois, agregar com mediana de medianas e reportar o intervalo de confiança e o intervalo.
Q: Quantas cenas de teste são necessárias para um resultado fiável? A: Um menor número de pares correspondentes de alta qualidade supera muitos pouco controlados. No nosso estudo de produção, 38 cenas superaram um filtro de inclusão rigoroso (mesma cena e utilizador em ambos os lados de hardware, com pelo menos três tarefas por lado) de um total de 1.419 tarefas. O tamanho da amostra que importa é o que supera o filtro, não o número bruto de tarefas — e ambos devem ser reportados.
Q: É possível reproduzir o benchmark de GPU da render farm de forma independente? A: Sim — esse é o objetivo. Fixar uma cena e as suas definições, construir uma matriz de hardware mantendo o SO, o build do motor e o denoiser constantes, medir o tempo de relógio de parede por frame, exigir pares correspondentes, agregar com mediana de medianas mais um intervalo de confiança bootstrap, converter para custo por frame, e publicar as ressalvas com o número. Os oito passos de replicação acima descrevem a sequência completa.
Q: Por que razão se reporta um intervalo em vez de um único número de aceleração? A: Porque o intervalo faz parte do resultado. O mesmo hardware pode mostrar um ganho de 1,6x numa cena curta limitada por sobrecarga e mais de 5x numa cena pesada limitada por computação, uma vez que a sobrecarga fixa por frame representa uma fração maior de uma renderização curta. Reportar apenas o ponto médio oculta a variação de que um operador necessita para planear a capacidade, pelo que publicamos a mediana, o intervalo interquartil e o intervalo total em conjunto.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



