
Multi-GPU em Renderização: O Que 1 vs 2 GPUs Realmente Faz (Benchmark 2026)
Visão geral
Introdução
TL;DR: Uma segunda GPU raramente duplica a velocidade de renderização, e o quanto ajuda depende inteiramente do motor de renderização. Nos nossos benchmarks de 2026 em nós com RTX 5090 e RTX 4090 duplos, os motores de débito (V-Ray, Octane) escalaram próximo de 2,00x, enquanto os motores por tempo de renderização escalaram menos — Cycles 1,31x–1,63x, Redshift 1,68x–1,92x — porque a latência fixa por render consome parte do que a segunda placa consegue acelerar. Dois GPUs é o limite máximo prático por nó; o débito real de uma render farm vem de distribuir mais fotogramas por mais nós em paralelo, não de empilhar mais cartões numa única máquina.
Uma segunda GPU não torna o render duas vezes mais rápido. Parece óbvio quando se diz em voz alta, mas muitas decisões de hardware são tomadas com base no pressuposto de que dois cartões significam o dobro da velocidade. Em junho de 2026, retirámos dois dos nossos nós de benchmark da fila — um com dois RTX 5090, outro com dois RTX 4090 — e medimos o que acontece realmente quando se passa de uma placa para duas, em quatro motores de renderização e sete combinações de cena/benchmark.
A versão resumida: depende inteiramente do motor. Os benchmarks com base em débito (V-Ray, Octane) escalaram quase perfeitamente, perto de 2x. Os motores por tempo de renderização (Cycles, Redshift) escalaram de forma mais modesta e, na placa mais rápida, a segunda GPU ajudou menos, não mais. Percorremos os números, explicamos por que a curva se dobra desta forma e — tão importante quanto — deixamos claro onde isto para. Dois cartões é o limite máximo num único nó. Ir além disso é uma arquitetura diferente, não uma versão maior desta.
Este é um artigo de hardware/benchmark, portanto tem um peso considerável em GPU. Vale a pena dizer desde já que a GPU é a minoria do que passa pela nossa render farm — a maior parte da produção ainda é renderização em CPU (V-Ray, Corona, Arnold em CPU). Mas quando alguém pergunta "uma segunda GPU vale a pena?", merece números medidos, não um discurso de vendas. Portanto, aqui estão os números medidos.
Como Testámos (e o Que Estes Números Não São)
Ambos os nós de teste correram Windows 11 Pro com dois GPUs cada. O nó 5090 utilizou o driver 596.36; o nó 4090 utilizou o driver 610.62 — um cartão Blackwell precisa de um driver mais recente, pelo que uma correspondência exata não foi possível. Essa diferença de driver importa para uma única coisa: a comparação de velocidade entre gerações de uma 5090 e uma 4090. Os rácios de escalabilidade em que nos focamos aqui são medidos dentro de um único nó (mesmo cartão, mesmo driver, um GPU versus dois), pelo que a diferença de driver não os afeta.
Cada cena é um benchmark padrão de fornecedor — as cenas Open Data do Blender (bmw27, classroom, junkshop), a cena "Vultures" da Maxon para Redshift, o Chaos V-Ray Benchmark 6.00.02, e o OctaneBench 2025.2.1. Sem projetos de clientes, sem ativos de produção. Não publicamos minutos por fotograma, dólares por fotograma nem valores de eletricidade, porque este conjunto de dados não os contém e não os inventamos.
Uma nota de método que afeta a leitura das linhas do Cycles: executámos o Blender Cycles a 200 % de resolução, mais pesado do que o padrão do Open Data, especificamente para que cada render dure tempo suficiente para produzir um rácio de escalabilidade estável e fiável. Isso significa que os nossos tempos brutos do Cycles não são comparáveis às pontuações públicas do Open Data — estão ajustados para medir escalabilidade, não para competir em classificações. Cycles e Redshift são medidos em tempo de renderização (segundos, quanto menor melhor); V-Ray e Octane são medidos como pontuação de benchmark (vpaths ou pontos OctaneBench, quanto maior melhor). São dois tipos de métrica diferentes, pelo que os valores absolutos nunca se comparam entre motores — apenas o rácio de escalabilidade dentro de cada motor é uma comparação justa.
O Resultado Principal: Escalabilidade de 1x para 2x por Motor
Aqui estão os dados centrais — o que uma segunda placa idêntica proporciona realmente, por motor e cena:
| Motor | Cena | Escalabilidade 2x RTX 5090 | Escalabilidade 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1,54x | 1,58x |
| Cycles | classroom | 1,59x | 1,63x |
| Cycles | junkshop | 1,31x | 1,38x |
| Redshift | Vultures | 1,68x | 1,92x |
| V-Ray GPU (CUDA) | benchmark | 1,97x | 2,00x |
| V-Ray GPU (RTX) | benchmark | 2,00x | 2,00x |
| Octane | OctaneBench suite | 2,00x | 1,98x |
De cima para baixo, surge uma divisão clara. V-Ray e Octane situam-se em ou ligeiramente abaixo de 2,00x em ambos os cartões — uma segunda GPU quase duplica o desempenho. Cycles fica no intervalo 1,31x–1,63x. Redshift situa-se em 1,68x no 5090 e 1,92x no 4090.
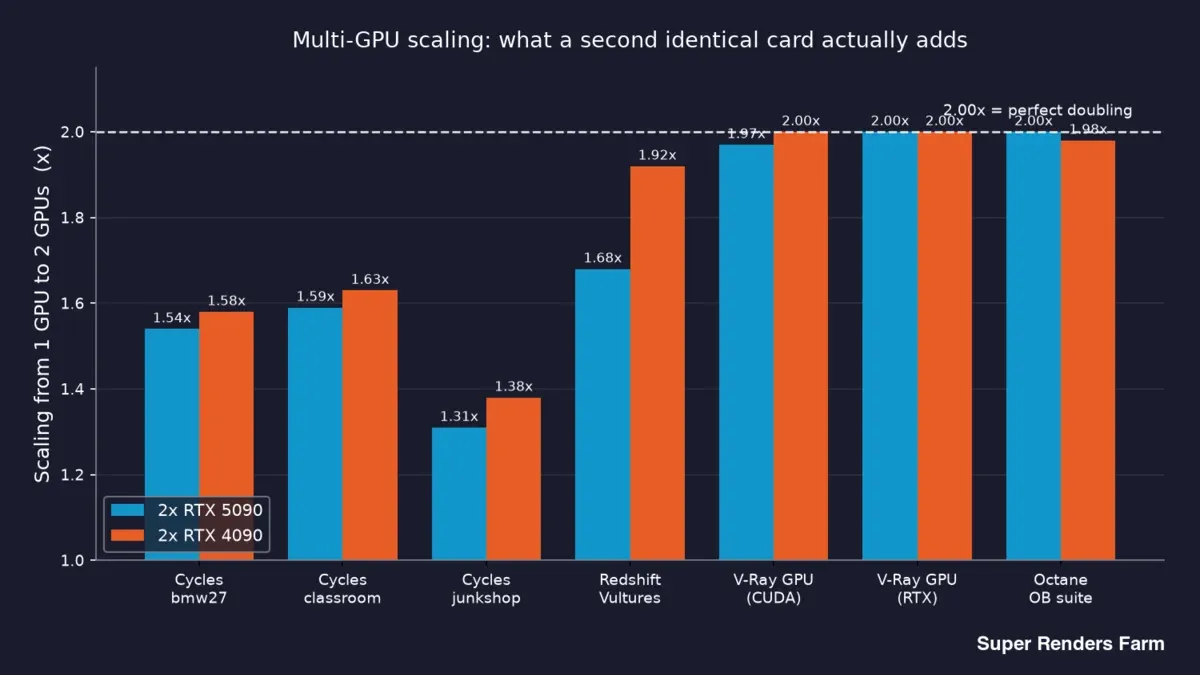
Gráfico de barras da escalabilidade de 1 para 2 GPUs por motor em nós com RTX 5090 e RTX 4090 duplos: Cycles 1,31x a 1,63x, Redshift 1,68x versus 1,92x, V-Ray e Octane próximos de 2,00x
Portanto, "adicionar uma segunda GPU duplica a minha velocidade?" tem três respostas honestas diferentes consoante o que se renderiza: basicamente sim para V-Ray e Octane, cerca de 1,5x para Cycles, e algures no meio para Redshift. Quem afirmar que um único multiplicador cobre toda a renderização não o mediu de facto.
Por Que os Motores de Débito Escalam Melhor do Que os Motores por Tempo de Renderização
O padrão não é aleatório — decorre da forma como cada benchmark passa o seu tempo. O V-Ray Benchmark e o OctaneBench são testes de débito. Lançam uma carga de trabalho sobre toda a capacidade de computação disponível e reportam uma pontuação, sendo o custo fixo de configuração (carregar a cena, construir estruturas de aceleração, inicializar o dispositivo) uma fração diminuta do tempo total. Adicionar uma segunda placa faz com que quase todo o silício extra vá diretamente para trabalho útil, ficando próximo de 2x. O resultado de V-Ray RTX a atingir um limpo 2,00x em ambos os cartões é exatamente o que se espera de uma carga de trabalho onde a latência é essencialmente ruído.
Os motores por tempo de renderização comportam-se de forma diferente. Quando se mede um render de Cycles ou Redshift em segundos de relógio de parede, está-se a cronometrar o trabalho completo — e cada trabalho carrega uma parcela fixa de latência não paralela: análise da cena, construção da BVH/estrutura de aceleração, compilação de kernels e aquecimento, coordenação de dispositivos, resolução final de pixels. Uma segunda GPU acelera a parte que é efetivamente divisível entre cartões. Não faz nada pela parte fixa. Quanto mais do tempo total de renderização for composto por latência fixa, mais abaixo de 2x ficará a escalabilidade.
É por isso que o Cycles no junkshop (1,31x–1,38x) escala pior do que o Cycles no classroom (1,59x–1,63x): o junkshop é um render mais leve e mais curto, pelo que a sua latência fixa representa uma fração maior do total, deixando menos margem para a segunda placa acelerar. A cena classroom demora mais, a parte paralela domina, e a segunda GPU tem mais espaço para ajudar. Mesmo motor, mesmo hardware — é a cena que decide o quanto a segunda placa importa.
A Parte Contraintuitiva: A Placa Mais Rápida Escalou Menos
Observe novamente a linha do Redshift. Dois RTX 5090 escalaram 1,68x. Dois RTX 4090 escalaram 1,92x. A placa mais recente e mais rápida escalou pior. Parece um erro. Não é — é o número mais instrutivo de todo o conjunto.
Eis o mecanismo. O 5090 é a placa mais rápida em termos absolutos; com um único GPU, conclui a cena Vultures em cerca de 57 segundos, contra os 100 segundos do 4090. Mas essa latência fixa por render — análise, construção, aquecimento — é aproximadamente o mesmo número de segundos independentemente da placa que a executa. No 4090, essa fatia fixa representa uma pequena fração de um render longo de 100 segundos, pelo que a segunda placa tem uma grande parte paralela para processar e a escalabilidade fica próxima de 1,92x. No 5090, o render já é curto, pelo que essa mesma fatia fixa representa uma fração maior do total, deixando uma parte paralela mais pequena para a segunda placa acelerar — e a escalabilidade fica em 1,68x.
Criticamente, isso não significa que o 5090 seja pior. É mais rápido com um cartão e mais rápido com dois cartões. Simplesmente ganha proporcionalmente menos com a segunda GPU porque havia menos render lento para acelerar desde o início. Quanto mais rápido for o render de base, mais difícil é para uma segunda placa entregar um 2x limpo — simplesmente há menos tempo a paralelizar. Esta é uma informação genuinamente útil antes de gastar dinheiro a empilhar cartões idênticos esperando retornos lineares.
Velocidade por Placa: RTX 5090 vs RTX 4090
A escalabilidade é um eixo; a velocidade bruta por placa é o outro. Com um único cartão, tendo em conta a ressalva do driver mencionada na secção de método, o 5090 saiu à frente em todos os motores testados:
| Motor | Métrica | RTX 5090 | RTX 4090 | Vantagem do 5090 |
|---|---|---|---|---|
| Cycles — bmw27 | segundos (menor é melhor) | 49,45 | 77,40 | 1,57x |
| Cycles — classroom | segundos | 23,09 | 36,87 | 1,60x |
| Cycles — junkshop | segundos | 19,71 | 34,43 | 1,75x |
| Redshift — Vultures | segundos | 57 | 100 | 1,75x |
| V-Ray GPU (CUDA) | vpaths (maior é melhor) | 11.051 | 7.419 | 1,49x |
| V-Ray GPU (RTX) | vpaths | 15.333 | 9.608 | 1,60x |
| Octane | pontuação OctaneBench | 1.690,78 | 1.074,17 | 1,57x |
Em geral, o 5090 é cerca de 1,5x a 1,75x mais rápido por placa. Dois pontos para quem planeia hardware. Primeiro, os ganhos por placa entre gerações (1,5x–1,75x aqui) são maiores e mais fiáveis do que o ganho de adicionar uma segunda placa da mesma geração num motor por tempo de renderização (muitas vezes bem abaixo de 2x). Em termos simples: uma placa mais rápida é frequentemente uma alavanca melhor do que uma segunda placa. Segundo, estes números de comparação entre gerações com um único cartão têm a ressalva da disparidade de drivers — devem ser tratados como uma comparação direcional, não como uma garantia de nível de serviço. Medimos em cenas de benchmark; a complexidade da cena, a amostragem e a resolução de saída influenciarão o valor no mundo real. Para mais informações sobre o comportamento do 5090 com um único cartão, consulte o nosso artigo sobre desempenho de renderização na nuvem com RTX 5090.
Dois GPUs É o Limite por Nó — e Por Que Isso Não É Problema
Aqui traçamos uma linha clara, porque é a parte que a maior parte do conteúdo multi-GPU ignora silenciosamente. Cada nó neste benchmark é um nó com dois GPUs. Dois cartões é o limite por nó. Não vamos mostrar uma curva de escalabilidade de 4x ou 8x num único nó, porque essa não é uma configuração que executamos, e não vamos sugerir o contrário.
Ultrapassar dois GPUs num único fotograma significa renderização distribuída multi-nó — dividir uma imagem por várias máquinas, com toda a coordenação de rede, gestão de buckets/tiles e a latência que isso implica. Esta é uma arquitetura genuinamente separada, não uma versão maior de uma caixa com dois cartões. Não é algo que oferecemos hoje para um único fotograma, pelo que não vamos apresentá-la como funcionalidade "em breve" com uma data associada.
E eis o ponto: para a esmagadora maioria da produção, o limite de dois GPUs não é a restrição que importa. A restrição que aparece primeiro é quase sempre a VRAM, não o número de cartões — uma cena que não cabe em 32 GB não renderiza independentemente de quantos GPUs se apontem a ela, o que é um problema completamente diferente (abordamos isso em limites de VRAM do RTX 5090 para cenas complexas). Quando as pessoas imaginam "escalar uma render farm", normalmente visualizam um único render enorme a ficar mais rápido com mais e mais silício. Não é assim que funciona o débito à escala de uma render farm.
Como uma Render Farm Escala de Facto: Fotogramas, Não Cartões
Esta é a distinção que vale a pena interiorizar, e é aquela para a qual os números de benchmark acima continuam a apontar. Há dois conceitos completamente diferentes por detrás da expressão "renderizar mais rápido com mais hardware":
- Dividir um fotograma por muitos GPUs ou máquinas (renderização distribuída por tile/bucket). Isto é o que os números de 1x→2x medem à escala de dois cartões, e o que a renderização distribuída multi-nó estenderia. Atinge retornos decrescentes rapidamente nos motores por tempo de renderização, como os dados mostram, devido à latência fixa por render — e o custo de coordenação só cresce à medida que se adicionam máquinas.
- Distribuir muitos fotogramas por muitas máquinas (renderização paralela por fotograma). Cada nó renderiza um fotograma completo de forma autónoma; os fotogramas de uma animação são distribuídos por toda a frota em paralelo. Não existe latência de coordenação por fotograma para combater, pelo que esta abordagem escala de forma limpa e é assim que uma animação é processada rapidamente.
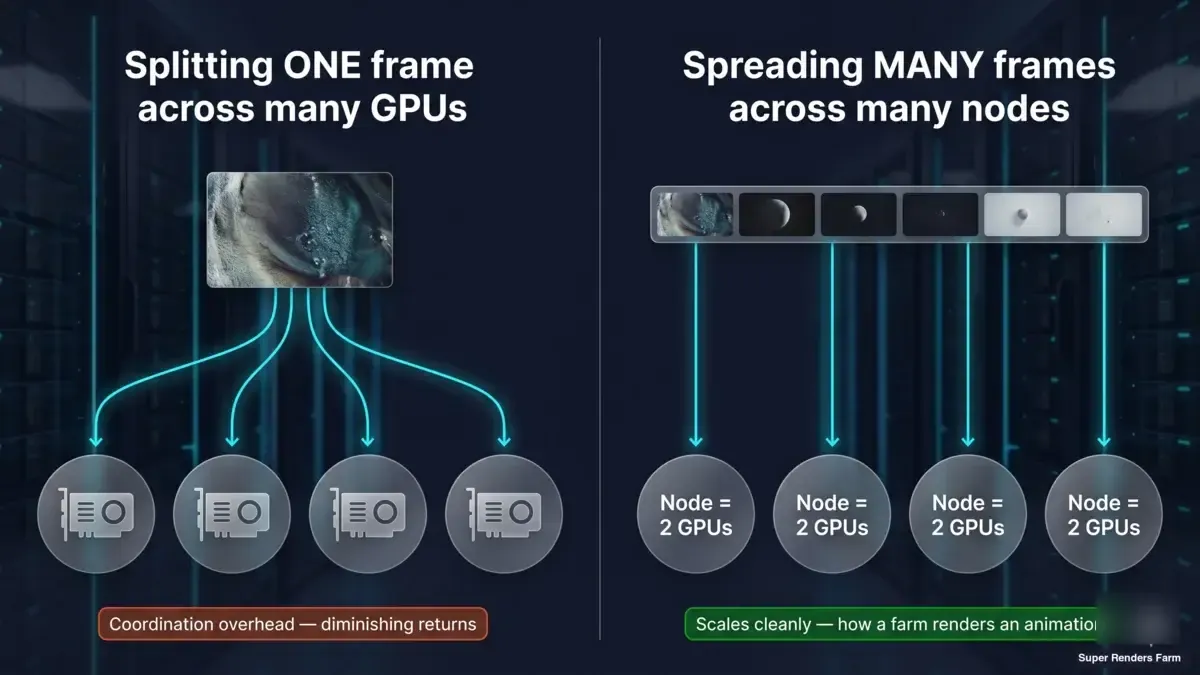
Diagrama conceptual em dois painéis: um fotograma dividido por vários GPUs gera latência de coordenação e retornos decrescentes; muitos fotogramas completos, cada um no seu próprio nó com dois GPUs em paralelo, escala de forma limpa — é assim que uma render farm escala uma animação
Uma render farm gerida obtém a sua velocidade quase inteiramente a partir do segundo modelo. A animação de 500 fotogramas não é renderizada como um único fotograma espalhado por 500 GPUs — é renderizada como 500 fotogramas distribuídos pela frota, cada um no seu próprio nó, todos ao mesmo tempo. A velocidade por nó e por fotograma é definida pelo tipo de escalabilidade de dois GPUs e desempenho por placa que aqui medimos; a velocidade ao nível da render farm vem do número de fotogramas a correr em simultâneo. São alavancas diferentes, e confundi-las é onde muita confusão do tipo "quantos GPUs preciso?" tem origem.
Portanto, a apresentação honesta do multi-GPU é mais restrita do que a versão de marketing. Dois cartões por nó dão um aumento real e mensurável — próximo de 2x no V-Ray e Octane, mais modesto no Cycles e Redshift. Para além disso, a resposta não é "empilhar mais cartões na caixa" — é "distribuir mais fotogramas por mais nós". Esta é a arquitetura, e ser direto a respeito disso tende a poupar o dinheiro que as pessoas estavam prestes a gastar em hardware que não teria o retorno que esperavam.
O Que Isto Significa na Escolha de Como Renderizar
Sintetizando em algo acionável. Se estiver a decidir entre um cartão e dois para uma estação de trabalho, o motor utilizado deve orientar a decisão: quem usa V-Ray ou Octane obtém próximo de uma duplicação total e a segunda placa é fácil de justificar; quem usa Cycles e Redshift deve esperar um aumento de 1,3x–1,9x e ponderar se uma placa individual mais rápida (o ganho geracional de 1,5x–1,75x) representa um melhor investimento. Se estiver a decidir entre renderizar localmente ou entregar o trabalho a uma render farm, lembre-se de que a vantagem da render farm é o débito paralelo por fotograma numa animação, não um multiplicador mágico por fotograma — um único fotograma importante não renderizará dramaticamente mais rápido numa render farm do que numa estação de trabalho equivalente, mas várias centenas de fotogramas absolutamente sim.
Para contexto sobre a comparação entre gestão total e solução própria — quem trata dos drivers, licenças e configuração dos nós — o nosso guia sobre render farm totalmente gerida vs DIY cobre esse tema. Na nossa render farm, o licenciamento do motor de renderização (V-Ray, Redshift, Octane) está incluído na taxa de renderização e a configuração dos nós é fixa e mantida por nós, pelo que a configuração de dois GPUs por nó e os drivers por detrás destes números não são algo que se monta ou ajusta. Para o lado específico do Redshift no Cinema 4D, onde o valor de escalabilidade de 1,68x se enquadra, consulte o nosso guia sobre render farm Redshift para Cinema 4D.
As medições aqui apresentadas são deliberadamente sem exageros. Uma segunda GPU é uma alavanca real com limites reais, a placa mais rápida escala menos porque tinha menos render lento para acelerar desde o início, e a velocidade à escala de uma render farm é uma história de distribuição de fotogramas, não de acumulação de cartões. Saber qual alavanca se aplica à carga de trabalho é a maior parte da decisão.
FAQ
Q: Adicionar uma segunda GPU duplica a velocidade de renderização? A: Geralmente não. Nos nossos benchmarks de 2026, os motores de débito como V-Ray e Octane escalaram próximo de 2,00x com uma segunda placa idêntica, mas os motores por tempo de renderização escalaram menos — Cycles ficou entre 1,31x e 1,63x e Redshift atingiu 1,68x em RTX 5090 duplos. O ganho depende inteiramente do motor e da cena, porque cada render carrega uma latência fixa que uma segunda placa não consegue acelerar.
Q: Por que o Redshift escala melhor no RTX 4090 do que no RTX 5090? A: Porque o 5090 é mais rápido, os seus renders são mais curtos, pelo que a latência fixa por render (análise da cena, construção da estrutura de aceleração, aquecimento de kernels) representa uma fração maior do total. Isso deixa uma parte paralela mais pequena para a segunda placa acelerar, daí a escalabilidade de 1,68x no 5090 contra 1,92x no 4090. O 5090 continua a ser mais rápido tanto com um como com dois cartões — simplesmente ganha proporcionalmente menos com a segunda GPU.
Q: Quanto mais rápido é o RTX 5090 face ao RTX 4090 para renderização? A: Cerca de 1,5x a 1,75x mais rápido por placa nos motores testados, incluindo Cycles, Redshift, V-Ray GPU e Octane. Estes valores de comparação entre gerações com um único cartão têm uma ressalva menor, porque os dois cartões correram drivers NVIDIA diferentes, pelo que devem ser tratados como comparação direcional e não como garantia fixa.
Q: Por que V-Ray e Octane escalam melhor do que Cycles e Redshift em dois GPUs? A: O V-Ray Benchmark e o OctaneBench são testes de débito onde o custo fixo de configuração é uma fração diminuta do tempo de execução, pelo que uma segunda placa vai quase inteiramente para trabalho útil e a escalabilidade aproxima-se de 2,00x. Cycles e Redshift são medidos como tempo total de render, que inclui latência não paralela que uma segunda placa não consegue acelerar, pelo que a sua escalabilidade fica abaixo de 2x.
Q: Uma render farm pode tornar um único fotograma mais rápido em muitas máquinas? A: Dividir um único fotograma por várias máquinas é renderização distribuída multi-nó, uma arquitetura separada com a sua própria latência de coordenação e que não oferecemos hoje para um único fotograma. Uma render farm gerida obtém a sua velocidade a partir da renderização paralela por fotograma — muitos fotogramas completos distribuídos por muitos nós ao mesmo tempo — pelo que uma animação fica pronta rapidamente enquanto um único fotograma importante renderiza aproximadamente à velocidade por nó.
Q: De quantos GPUs preciso realmente para renderização? A: Para um único nó, dois GPUs é um limite sensato e é o que os nossos nós de benchmark utilizam; para além disso, a restrição prática é geralmente a VRAM, não o número de cartões, pois uma cena que não cabe em memória não renderiza independentemente de quantas placas se adicionem. Se renderizar animações, o verdadeiro débito vem de distribuir mais fotogramas por mais nós, e não de empilhar mais cartões numa única máquina.
Q: Estes números de benchmark são comparáveis às pontuações públicas do Blender Open Data? A: Não. Corremos o Blender Cycles a 200 % de resolução, mais pesado do que o padrão do Open Data, para que cada render dure tempo suficiente para produzir um rácio de escalabilidade estável. Isso torna os nossos tempos brutos de Cycles intencionalmente incomparáveis com as classificações públicas do Open Data — as cenas foram ajustadas para medir escalabilidade, não para corresponder a pontuações padrão.
Q: É necessário gerir drivers de GPU e licenças para usar uma render farm gerida? A: Não. Numa render farm totalmente gerida, a configuração dos nós, os drivers e o licenciamento do motor de renderização (V-Ray, Redshift, Octane) são tratados internamente e incluídos na taxa de renderização, pelo que a configuração de nós com dois GPUs e os drivers por detrás destes benchmarks não são algo que se monta ou ajusta. Cycles é gratuito e de código aberto, pelo que não tem licença separada.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



