
RTX 5090 em Produção: 7 Semanas de Notas de Campo de uma Render Farm (Estudo com 38 Cenas)
Visão geral
Os benchmarks de lançamento do RTX 5090 têm mais de um ano, e descrevem todos a mesma coisa: uma placa, uma cena preparada, condições ideais. O que quase ninguém publica é a continuação — o que a placa faz quando está enterrada numa fila de produção, a renderizar as cenas de outras pessoas num calendário que não controla. Por isso analisámos os registos. O que se segue são as notas de campo ao nível da fila: os mesmos dados de produção a partir dos quais planeamos a capacidade, apresentados como números que podem ser verificados.
São sete semanas disso. De 1 de abril a 22 de maio de 2026 — 51 dias — operámos um nó dual-RTX-5090 dentro da nossa render farm em produção e deixámos que tratasse do que a fila lhe entregasse. Sem testes preparados, sem frames escolhidas a dedo. O vídeo curto abaixo percorre os números principais; as notas de campo completas seguem-se.
O nó em si é vulgar: dois RTX 5090, 128 GiB de RAM, 32 núcleos lógicos a 4.3 GHz, Windows 11. Um detalhe condiciona todos os valores aqui apresentados — o escalonador executa uma única tarefa de render por GPU, pelo que cada placa renderiza o seu próprio trabalho e cada número é um número limpo por placa, a figura pela qual se multiplica para planear a capacidade. Ao longo do período, o nó concluiu 99.6% das suas tarefas — 4,890 de aproximadamente 4,900 concluídas, 18 falhadas. O escalonador regista a falha, não a causa, pelo que não especularemos.
Números-chave
- Período: 1 de abril – 22 de maio de 2026 (51 dias, ~7 semanas), um nó dual-RTX-5090
- Conclusão: 99.6% — 4,890 de ~4,900 tarefas concluídas, 18 falhadas (causa não registada)
- Aceleração: mediana de 3.2x por frame no Blender Cycles vs. nós de geração anterior da classe RTX 3080/2080 (tempo mediano por frame reduzido ~69%); IC 95% 3.0–3.3x
- Dispersão: IQR 2.7–3.4x, intervalo completo de 1.6x–5.1x em 38 cenas emparelhadas — um único multiplicador nunca descreve uma fila
- Denoising com IA: ~83% dos trabalhos Cycles executaram uma passagem de denoising com IA — a mesma taxa no hardware anterior
- VRAM: mediana de 5.6 GB, percentil 90 de 11.5 GB, trabalho mais pesado ~37 GB
- Driver: um único driver (581.80 / CUDA 13.0) em todo o período, zero substituições
- Energia: ~360–375 W/placa sob carga (benchmark controlado), com picos de ~400 W, a 68–83 °C — bem abaixo da classe nominal de ~575 W
O que 38 cenas emparelhadas mostram
A comparação em que mais confiamos não é um teste sintético, mas os trabalhos que correram em ambas as gerações no decorrer normal da atividade — mesma cena, mesmo utilizador, pelo menos três tarefas por lado antes de uma cena ser contabilizada. O tempo por frame é o tempo de relógio da tarefa dividido pelo número de frames, diretamente da fila. Do período em análise, 38 cenas superaram esse critério, provenientes de 1,419 tarefas de render individuais (503 no nó 5090, 916 na geração anterior). Trinta e oito não é o tamanho dos nossos dados; é o que sobrevive a um filtro deliberadamente rigoroso.
| Métrica | Valor |
|---|---|
| Aceleração mediana por frame | 3.2x (≈69% de redução no tempo) |
| IC bootstrap 95% (mediana) | 3.0–3.3x |
| Intervalo interquartil | 2.7–3.4x |
| Intervalo completo | 1.6–5.1x |
| Cenas / tarefas | 38 cenas / 1,419 tarefas |
| Referência | RTX 3080/2080 de geração anterior (10–12 GB) |
Usamos uma mediana de medianas: cada cena contribui com a mediana dos seus próprios tempos por frame em cada lado, e o valor 3.2x é a mediana dessas 38 razões, pelo que uma frame lenta não pode distorcer o resultado. A dispersão importa tanto quanto o ponto central — a metade central das cenas situa-se entre 2.7x e 3.4x, e o intervalo completo vai de 1.6x a 5.1x.
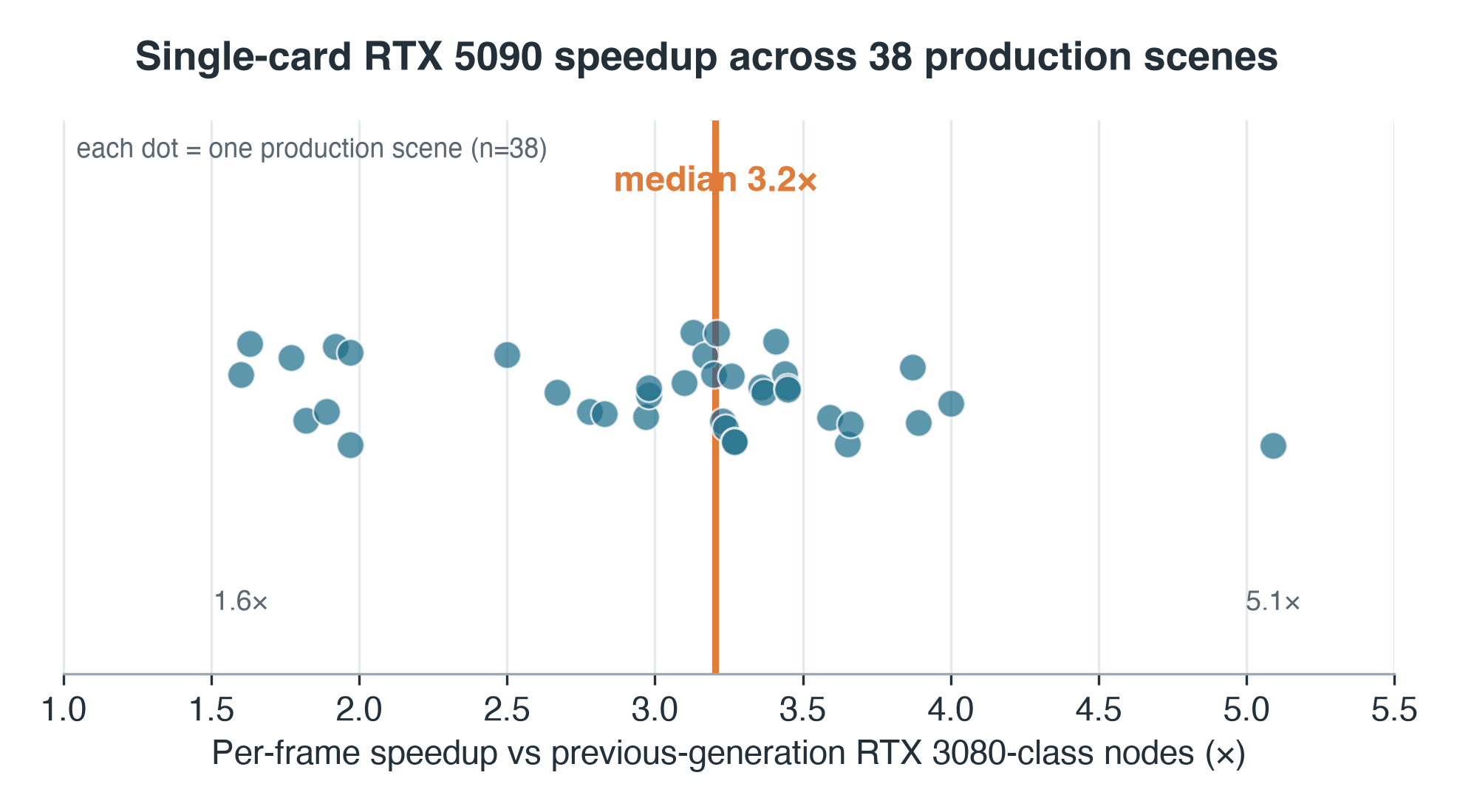
Aceleração do RTX 5090 por cena em 38 cenas de produção do Blender Cycles, mediana de 3.2x com uma dispersão de 1.6 a 5.1x
Aceleração por cena, RTX 5090 vs. os nós de geração anterior em que estes trabalhos correram — amostra de 38 cenas de produção. Mediana 3.2x; intervalo 1.6–5.1x.
Duas ressalvas pertencem a este número, não a uma nota de rodapé. Em primeiro lugar, o lado da geração anterior correu virtualizado — passagem de GPU dentro de uma VM — pelo que uma parte não mensurável deste 3.2x é overhead de virtualização, não silício puro; a comparação limpa no mesmo hardware, um RTX 5090 contra um RTX 4090 atual, é o acompanhamento controlado que ficamos a dever e ainda não realizámos. Em segundo lugar, as 38 cenas não são uma amostra aleatória da fila: são os trabalhos que um utilizador teve a oportunidade de re-renderizar em ambas as gerações, o que enviesou a amostra para trabalhos mais longos e iterados — por isso, leia a distribuição como a das cenas emparelhadas, não a de toda a fila.
Três notas de honestidade são aqui fundamentais. Estes são dados observacionais — os utilizadores ajustam por vezes as definições entre re-renderizações, e não congelámos as suas cenas. A comparação é nó versus nó: o lado do 5090 é uma placa bare-metal, o lado da geração anterior corre com passagem de GPU dentro de máquinas virtuais, pelo que parte da diferença é de configuração, não de silício. E a referência são as placas da classe RTX 3080/2080 em que estes trabalhos correram de facto — não um RTX 4090 atual; um confronto direto com a placa atual é um exercício separado e controlado que ainda não realizámos. Estes são valores de nó único, apenas Cycles; descrevem a nossa fila e não devem ser generalizados a outros motores ou hardware.
O que separa uma cena de 1.6x de uma de 5.1x é em parte visível nos dados. Ao representar graficamente a aceleração de cada cena em função do tempo que os seus frames demoravam no hardware antigo, surge uma tendência positiva ténue — Spearman ρ ≈ 0.34 (p bilateral ≈ 0.04). Os frames curtos, limitados pelo overhead, ficam na base: quando um frame termina em cinco segundos, o custo fixo por tarefa — carregamento da cena, sincronização, a antiga camada de virtualização — consome a maior parte do tempo, e uma placa mais rápida tem pouco espaço para atuar. Os frames mais pesados, limitados pelo processamento, ganham mais. Mas há dispersão real: uma cena pesada ficou em apenas 1.6x porque o seu bottleneck não era a GPU, mas provavelmente o armazenamento ou uma fase limitada pela CPU. A mediana diz uma coisa; o intervalo diz que depende da cena.
O denoising com IA já era o padrão
A pergunta sobre onde a IA se situa realmente num pipeline de rendering em produção em 2026 tem uma resposta pouco glamorosa nos nossos registos: no denoiser. Cerca de 83% dos trabalhos Cycles no nó 5090 executaram uma passagem de denoising com IA — OptiX ou Intel Open Image Denoise — e a taxa nos nossos nós de geração anterior é essencialmente idêntica. A nova placa não iniciou o hábito; já era padrão no hardware antigo e manteve-se padrão no novo. Para um pipeline intensivo em denoising, uma mudança de geração não está a comprar "IA" que já lá estava — está a comprar débito de path-tracing em torno de um passo já rotineiro. Este valor está propositadamente limitado ao Cycles; seja cético em relação a qualquer "% de IA" em toda a render farm que não esteja vinculado a um único motor.
VRAM em condições reais
O Cycles escreve a sua figura de memória de dispositivo de pico no registo de render — um proxy simples mas utilizável para o que a produção exige realmente da VRAM. Nas 57 tarefas Cycles em que essa linha foi registada, a memória de dispositivo de pico de render foi de cerca de 5.6 GB na mediana e 11.5 GB no percentil 90. As nossas placas de geração anterior têm 10–12 GB, pelo que a tarefa mediana caberia — mas a tarefa no percentil 90 já estava a roçar o seu limite. E o limite vai mais longe: a tarefa mais pesada registou cerca de 37 GB, acima mesmo dos 32 GB do 5090 — o tipo de cena que numa GPU significa um fallback para CPU ou nenhuma renderização. O registo não contém metadados da cena, pelo que não podemos dizer que tipo de cena era — apenas a sua classe: um conjunto de trabalho de 37 GB é a assinatura de geometria pesada, conjuntos de texturas de alta resolução ou volumetria, o tipo de trabalho que ultrapassa mesmo uma placa de 32 GB e, numa GPU única, simplesmente para. A regra do operador mantém-se: dimensiona-se a VRAM para o limite, não para a mediana. É por isso que existem tanto memória na placa sobredimensionada como capacidade partilhada de render farm na nuvem com GPU — para poder usar uma placa maior por trabalho em vez de comprar uma.
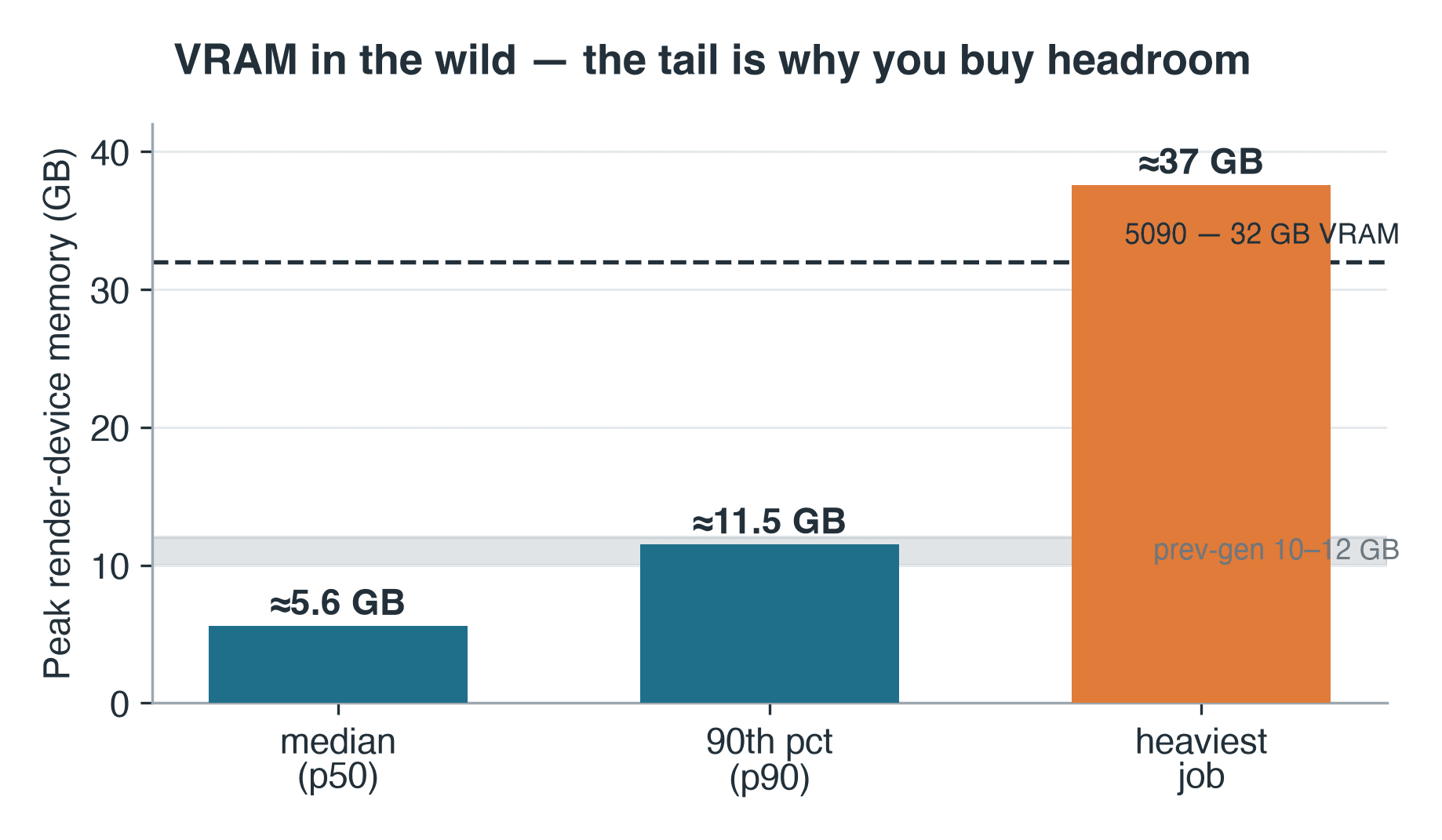
Memória de dispositivo de pico de render para trabalhos Blender Cycles no nó RTX 5090: mediana de 5.6 GB, percentil 90 de 11.5 GB, trabalho mais pesado com 37 GB
Memória de dispositivo de pico de render em 57 trabalhos Cycles registados. O trabalho mais pesado ultrapassou os próprios 32 GB do 5090.
Um único driver e energia controlada
A descoberta menos dramática é a que mais quereríamos saber antes de comprar. Um único driver — 581.80, em CUDA 13.0 — correu em todo o período de 51 dias com zero substituições: sem rollbacks, sem trocas a meio do período. Para hardware de ciclo inicial numa fila de produção, um registo de driver enfadonho é o elogio.
A energia foi igualmente tranquila. Num benchmark controlado das mesmas placas sob carga sustentada, cada uma consumiu cerca de 360–375 W (com picos próximos de 400) a 68–83 °C — a placa do topo num par empilhado é a que aquece mais, mas bem abaixo da classe nominal de ~575 W. Planeie para esse consumo sustentado, não para o pico nominal. A energia por frame concluído resulta em cerca de 2.5 Wh para um frame Cycles mediano de cerca de 24 segundos — mas trate isso como uma inferência: baseia-se no consumo do benchmark e foi calculado apenas para o 5090, não medido em comparação com os nós mais antigos.
Por que estas notas começam pelo Blender
Nos últimos 90 dias, os trabalhos de GPU representaram cerca de um quarto de tudo o que a nossa render farm renderizou — o resto é trabalho de CPU. Dentro da mistura de GPU, o Cycles representa cerca de 74% dos trabalhos e o Redshift um segundo lugar claro com cerca de 15%, que é por isso que um artigo sobre o RTX 5090 numa render farm começa com renderização na nuvem com Blender. Para saber como várias destas placas se comportam em conjunto, consulte as nossas notas complementares sobre desempenho de cluster RTX 5090 e, especificamente sobre o limite de memória, onde os limites de VRAM se fazem sentir em cenas complexas.
Duas conclusões saem desta fila. Em primeiro lugar, a produção não é um benchmark — uma placa que apresenta um resultado limpo em laboratório ainda tem de absorver overhead de virtualização, cargas de trabalho mistas e cenas para as quais nunca foi otimizada, e o resultado é uma distribuição, não um ponto. Em segundo lugar, a mediana não é o limite. Uma aceleração típica de 3.2x e um pico de memória de 37 GB num único trabalho são ambos verdadeiros ao mesmo tempo, e o planeamento de capacidade considera os dois. A placa é genuinamente rápida onde o trabalho é pesado. Onde não é, a fila diz porquê.
Método, em resumo
Todos os valores aqui apresentados provêm dos registos de tarefas do nosso próprio escalonador, não de um teste preparado. O tempo por frame é o tempo de relógio da tarefa dividido pelo número de frames; a aceleração principal é uma mediana de medianas por cena nos 38 pares correspondentes, e o intervalo de confiança é um bootstrap de 20,000 amostras. Atenção à amostra que fundamenta cada afirmação: 38 cenas emparelhadas para a aceleração, 57 trabalhos registados para a VRAM, e um benchmark controlado separado para energia e temperaturas — não a fila de produção. As 18 tarefas que falharam (de aproximadamente 4,900) são contadas como falhas, não descartadas; o escalonador regista o estado mas não a causa, pelo que ficam por investigar em vez de especularmos. Nada disto é difícil de reproduzir no espírito — é o que qualquer operador pode extrair dos seus próprios registos de fila, e estamos disponíveis para acompanhar um estúdio pelo método com mais detalhe.
FAQ
Q: Quanto mais rápido é o RTX 5090 face à geração anterior para o Blender Cycles? A: Em 38 cenas de produção emparelhadas (mesma cena e utilizador em ambas as gerações), o tempo mediano por frame reduziu cerca de 69% — uma aceleração mediana de 3.2x, com um intervalo de confiança bootstrap de 95% de 3.0–3.3x. As cenas individuais variaram entre 1.6x e 5.1x. Trata-se de dados observacionais, nó versus nó, não de um benchmark controlado.
Q: Por que variam tanto as acelerações entre cenas? A: A aceleração acompanha a carga de trabalho por frame como uma tendência positiva ténue (Spearman ρ ≈ 0.34). Os frames curtos, limitados pelo overhead, ganham menos porque o custo fixo por tarefa — carregamento da cena, sincronização, a antiga camada de virtualização — domina; os frames mais pesados, limitados pelo processamento, ganham mais. Uma cena pesada ficou em 1.6x porque o seu bottleneck era o armazenamento ou uma fase limitada pela CPU, não a GPU.
Q: Este estudo é um benchmark controlado comparável com o meu próprio hardware? A: Não. Estas são notas de campo observacionais de um único nó de produção em funcionamento, apenas Blender Cycles. Os utilizadores ajustaram as suas próprias cenas entre re-renderizações, e a comparação é nó versus nó — um 5090 bare-metal contra nós de geração anterior virtualizados — pelo que parte da diferença é de configuração, não de silício. A referência é o hardware da classe RTX 3080/2080, não um RTX 4090 atual.
Q: Quanta VRAM usaram realmente as cenas de produção? A: Em 57 trabalhos Cycles registados, a memória de dispositivo de pico de render foi de cerca de 5.6 GB na mediana e 11.5 GB no percentil 90. O trabalho individual mais pesado registou cerca de 37 GB — acima dos próprios 32 GB do 5090 — o que numa GPU significa um fallback para CPU ou nenhuma renderização. Dimensione a VRAM para o limite, não para a mediana.
Q: O RTX 5090 alterou a frequência com que o denoising com IA foi utilizado? A: Não. Cerca de 83% dos trabalhos Cycles no nó 5090 executaram uma passagem de denoising com IA (OptiX ou Intel Open Image Denoise) — e a taxa era essencialmente a mesma na geração anterior. O denoising com IA já era padrão; a nova placa apenas alterou a velocidade de tudo o que o rodeia.
Q: Qual foi a estabilidade do driver durante as sete semanas? A: Um único driver — 581.80 em CUDA 13.0 — correu em todo o período de 51 dias com zero substituições: sem rollbacks, sem trocas a meio do período. Para hardware de ciclo inicial numa fila de produção, essa estabilidade é por si só um resultado significativo.
Q: Qual foi o consumo de energia e a temperatura sob carga? A: Num benchmark controlado sob carga sustentada, cada placa consumiu cerca de 360–375 W, com picos próximos de 400 W, a 68–83 °C — confortavelmente abaixo da classe nominal de ~575 W da placa. A energia por frame resulta em cerca de 2.5 Wh, o que é uma inferência a partir dessa medição de benchmark, calculada apenas para o 5090.
Q: Estes valores aplicam-se a outros motores de renderização? A: Não. Este estudo é exclusivamente de GPU Blender Cycles, num único nó. Outros motores registam denoising, memória e temporização de forma diferente. Trate estes valores como notas de campo específicas do Cycles, não como uma afirmação abrangente à render farm ou transversal a motores.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



