
Come eseguiamo il benchmark delle GPU per render farm: un metodo riproducibile di costo per frame (2026)
Panoramica
Introduzione
Un punteggio di benchmark è facile da pubblicare e difficile di cui fidarsi. Chiunque può scrivere "RTX 5090: X punti", ma il numero che determina se vale la pena eseguire un job di rendering su una scheda piuttosto che su un'altra non è un punteggio sintetico — è il costo per frame. Questa cifra dipende dalla scena, dalle impostazioni di rendering, dal motore, dal driver e dalla procedura di calcolo, e quasi nessuno di questi fattori è visibile in una classifica.
Questa pagina riguarda il metodo, non la classifica. Documenta come noi di Super Renders Farm eseguiamo il benchmark delle GPU per render farm in modo che il risultato abbia un significato concreto: come scegliamo una scena di benchmark, quali impostazioni di rendering blocchiamo, cosa manteniamo costante nella matrice hardware, come trasformiamo i tempi grezzi per frame in un numero di costo per frame difendibile, e — la parte che la maggior parte dei report salta — i passaggi espliciti affinché terze parti possano riprodurre l'intera procedura sul proprio hardware. Abbiamo già pubblicato i risultati di questo metodo; qui presentiamo la ricetta che li produce. Dove compare un numero nel testo, si tratta di una cifra reale proveniente da uno di quegli studi, citata come esempio pratico anziché derivata nuovamente.
Benchmark sintetici versus costo per frame in produzione
Il benchmark delle GPU presenta due livelli, e confonderli è all'origine della maggior parte delle incomprensioni.
Il primo è il livello sintetico: strumenti standardizzati che renderizzano una scena fissa e producono un punteggio. Cinebench R24, il V-Ray Benchmark di Chaos e OctaneBench appartengono a questa categoria. Sono utili per il confronto relativo — un carico di lavoro ripetibile e identico su ogni macchina, così da poter confrontare le schede tra loro. Spieghiamo come interpretare questi punteggi nella nostra guida al benchmark V-Ray e nell'articolo sui punteggi Cinebench per il cloud rendering. Quello che un punteggio sintetico elimina deliberatamente è tutto ciò che varia in produzione: la geometria, il campionamento, il denoiser, la risoluzione di output e il sovraccarico per job che una coda reale comporta.
Il secondo è il livello produttivo: quanto tempo impiega effettivamente un frame rappresentativo reale e quanto costa. Questo è il livello a cui mira questa metodologia. Un punteggio sintetico ne è un input — un modo per ricavare una stima iniziale — ma non è la risposta. Il collegamento tra i due è semplice in linea di principio: una macchina che ottiene circa il doppio del punteggio di un'altra sullo stesso build di benchmark renderizzerà un frame comparabile in circa la metà del tempo. Nella guida V-Ray illustriamo questa aritmetica di stima (efficienza = tempo per frame ÷ punteggio benchmark). L'obiettivo di un metodo di benchmark, anziché di un semplice punteggio, è rendere questa estrapolazione onesta — misurare su una scena vicina alla produzione e riportare la distribuzione, non solo un valore centrale.
La metrica che conta: costo per frame
Il costo per frame è l'unità a cui una metodologia dovrebbe giungere, perché è l'unità in cui viene effettivamente redatto un budget di rendering. La formula è semplice:
Costo per frame = tempo a orologio per frame × costo del nodo per ora
Il tempo a orologio per frame è il tempo del task diviso per il numero di frame, misurato — non il readout "tempo di rendering" interno al motore, che esclude il caricamento della scena, la costruzione della struttura di accelerazione e il coordinamento del dispositivo. Il costo del nodo per ora è il costo di esecuzione dell'hardware per un'ora, in qualsiasi modo venga contabilizzato. Sulla nostra render farm, il rendering GPU viene fatturato a $0,003 per OctaneBench-ora, e una singola RTX 5090 (32 GB) ha un costo base di circa $5,2 per scheda-ora; la nostra guida al costo per frame e la guida ai prezzi illustrano il modello rivolto al cliente nel dettaglio.
La combinazione dei due input è pura aritmetica di unità: si converte il tempo a orologio per frame in ore e si moltiplica per il costo del nodo per ora, in modo che secondi per frame e dollari per ora diano dollari per frame. Un frame breve su un nodo economico risulta basso; un frame pesante su uno costoso risulta alto. Manteniamo deliberatamente le tariffe elaborate fuori da questa pagina di metodologia — il costo effettivo dipende dalla complessità della scena, dal campionamento, dall'attesa in coda e dal modello di fatturazione utilizzato, e la nostra guida al costo per frame e la guida ai prezzi sono le sedi appropriate per i numeri rivolti ai clienti. Il punto qui è che la formula è verificabile: mantenendo le unità esplicite, chiunque può controllare il risultato invece di accettarlo per fede.
Il motivo per cui il costo per frame, e non un punteggio sintetico, è la metrica portante: due schede possono ottenere punteggi simili in un benchmark e differire notevolmente nel costo per frame sulla propria scena, perché è la scena a determinare quanto del frame è lavoro parallelizzabile rispetto al sovraccarico fisso che il silicio più veloce non può eliminare.
La scena di benchmark e le impostazioni di rendering
La scena è il singolo fattore più determinante per stabilire se un benchmark si trasferisce alla produzione, quindi utilizziamo deliberatamente due tipologie.
Scene standard del fornitore per il confronto tra macchine. Quando l'obiettivo è un confronto pulito e uniforme, utilizziamo scene di riferimento pubblicate — le scene Open Data di Blender (bmw27, classroom, junkshop), la scena Vultures di Maxon per Redshift, il V-Ray Benchmark di Chaos e OctaneBench. Sono ripetibili e verificabili indipendentemente, che è esattamente ciò di cui una classifica ha bisogno. Il loro limite è che non rappresentano la propria scena, quindi i tempi assoluti non si trasferiscono direttamente alla produzione.
Scene rappresentative della produzione per il costo per frame. Quando l'obiettivo è un numero su cui un operatore può pianificare, la scena deve assomigliare a lavoro reale — geometria reale, set di texture reali, campionamento reale, risoluzione di output reale. Nel nostro studio sulla scalabilità multi-GPU abbiamo eseguito Blender Cycles al 200% di risoluzione specificamente affinché ogni rendering durasse abbastanza a lungo da produrre un rapporto stabile e affidabile — il che significa anche che quei tempi grezzi Cycles non sono comparabili ai punteggi pubblici Open Data. Questo compromesso rappresenta il metodo che funziona come previsto: adattare la scena alla domanda.
Qualunque sia la scena, le impostazioni di rendering devono essere bloccate e registrate: numero di campioni (o soglia di rumore), denoiser attivo/disattivo e quale, risoluzione di output, dimensione del tile o del bucket e il build del motore. Un benchmark in cui uno qualsiasi di questi parametri varia tra le macchine sta misurando la variazione, non l'hardware.
La matrice hardware
Una matrice di benchmark è una griglia: le schede da testare su un asse, motori e scene sull'altro. La disciplina consiste in ciò che si mantiene costante nella griglia.
Costanti: sistema operativo, versione e build del motore di rendering, denoiser, scena e impostazioni. Registrato ma non sempre confrontabile: il driver GPU — una scheda di nuova generazione richiede talvolta un driver più recente di quello che una scheda più vecchia può eseguire, rendendo impossibile una corrispondenza esatta. Quando ciò accade, è necessario dichiararlo. Nello studio multi-GPU, il nodo RTX 5090 utilizzava il driver 596.36 e il nodo RTX 4090 il driver 610.62, e abbiamo specificato che il divario influisce solo sul confronto assoluto tra generazioni, non sui rapporti di scalabilità all'interno del nodo (che utilizzano la stessa scheda e lo stesso driver su entrambi i lati).
La nostra flotta GPU è standardizzata su schede NVIDIA RTX 5090 con 32 GB di VRAM, il che rende la nostra matrice internamente coerente — un inventario uniforme significa che una stima da un nodo si trasferisce al successivo. Come esempio pratico dell'asse per scheda, ecco il risultato con singola scheda dello studio multi-GPU, RTX 5090 versus RTX 4090 su scene identiche:
| Motore / scena | Metrica | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | secondi (minore è meglio) | 49,45 | 77,40 |
| Cycles — classroom | secondi | 23,09 | 36,87 |
| Redshift — Vultures | secondi | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (maggiore è meglio) | 15.333 | 9.608 |
| Octane | punteggio OctaneBench | 1.690,78 | 1.074,17 |
In quella tabella compaiono due tipi di metrica — secondi (minore è meglio) e punteggio benchmark (maggiore è meglio) — il che è esattamente il motivo per cui i numeri assoluti non si confrontano mai tra motori diversi. Solo il rapporto all'interno di un singolo motore è un confronto equo.
I controlli che rendono un benchmark affidabile
La differenza tra un numero e un numero affidabile sono i controlli. Questi sono quelli che il nostro metodo impone.
- Un task per GPU. Il nostro scheduler esegue un task di rendering per scheda, in modo che ogni cifra sia un numero netto per scheda — il valore da moltiplicare per pianificare la capacità, non una media sfumata su un dispositivo condiviso.
- Coppie corrispondenti per qualsiasi confronto. Quando abbiamo confrontato generazioni hardware in produzione, una scena veniva conteggiata solo se la stessa scena, lo stesso utente era presente su entrambi i lati, con almeno tre task per lato come requisito minimo. Nello studio sul campo RTX 5090, 38 scene hanno superato questo filtro su 1.419 task — 38 non è la dimensione dei dati, è quello che sopravvive a un filtro deliberatamente rigoroso.
- Un driver per finestra. Per lo studio sul campo, un singolo driver (581.80, CUDA 13.0) ha operato nell'intera finestra di sette settimane senza cambiamenti, in modo che nessuno scambio a metà finestra potesse contaminare il risultato.
- Parità del denoiser. Circa l'83% dei job Cycles ha eseguito un passaggio di AI denoising sia sull'hardware nuovo sia su quello della generazione precedente — quindi il denoiser era una costante, non una variabile nascosta all'interno dell'accelerazione.
- Warm versus cold. Il costo fisso per task — caricamento della scena, sincronizzazione, costruzione della struttura di accelerazione — rappresenta una frazione maggiore di un frame breve rispetto a uno lungo, il che spiega perché i frame brevi, dominati dal sovraccarico, sottostimano una scheda più veloce. Il metodo tiene conto di questo riportando la distribuzione anziché assumere un unico moltiplicatore.
Dai tempi grezzi a un numero difendibile
Una volta raccolti i tempi, le statistiche determinano se il numero in evidenza è onesto.
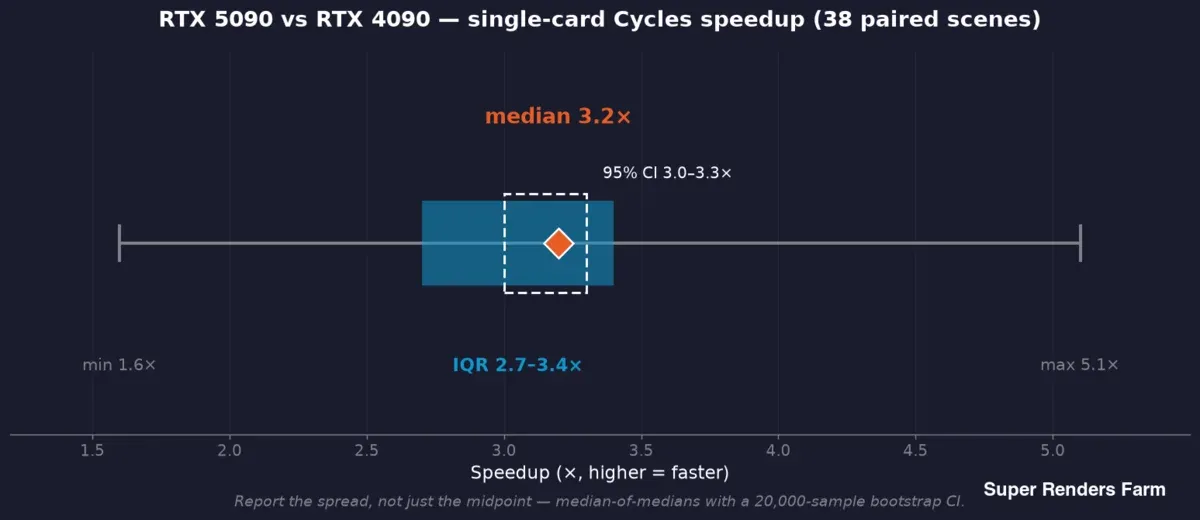
RTX 5090 versus RTX 4090 con singola scheda, velocità Cycles su 38 scene accoppiate: mediana 3,2x, intervallo di confidenza al 95% da 3,0 a 3,3x, intervallo interquartile da 2,7 a 3,4x, intervallo completo da 1,6 a 5,1x
Utilizziamo una mediana delle mediane: ogni scena contribuisce con la mediana dei propri tempi per frame su ciascun lato, e il valore in evidenza è la mediana di questi rapporti per scena — così un frame lento non può distorcere il risultato. Attorno a questo valore centrale riportiamo un intervallo di confidenza bootstrap (lo studio sul campo ha utilizzato un bootstrap da 20.000 campioni, ottenendo un CI al 95% di 3,0–3,3x attorno alla mediana 3,2x di accelerazione) e la dispersione — intervallo interquartile 2,7–3,4x, intervallo completo 1,6–5,1x tra le 38 scene.
Questa distribuzione non è rumore da mediare; è il risultato. Un'accelerazione tipica di 3,2x e un caso peggiore di 1,6x sono entrambi veri contemporaneamente, e un benchmark che riporta solo il valore centrale nasconde metà delle informazioni di cui un operatore ha bisogno. La regola che rispettiamo: riportare la mediana e l'intervallo, e collegare ogni affermazione al campione che la supporta — accelerazione da 38 scene accoppiate, VRAM da 57 job registrati, consumo energetico da un benchmark controllato separato, senza mai usare un campione per supportare un'affermazione relativa a un altro.
Come replicare questo benchmark
Questa è la parte che trasforma un benchmark in un segnale guadagnato anziché in un messaggio di marketing: chiunque può eseguirlo. I passaggi seguenti riproducono il metodo su qualsiasi coda o banco di prova.
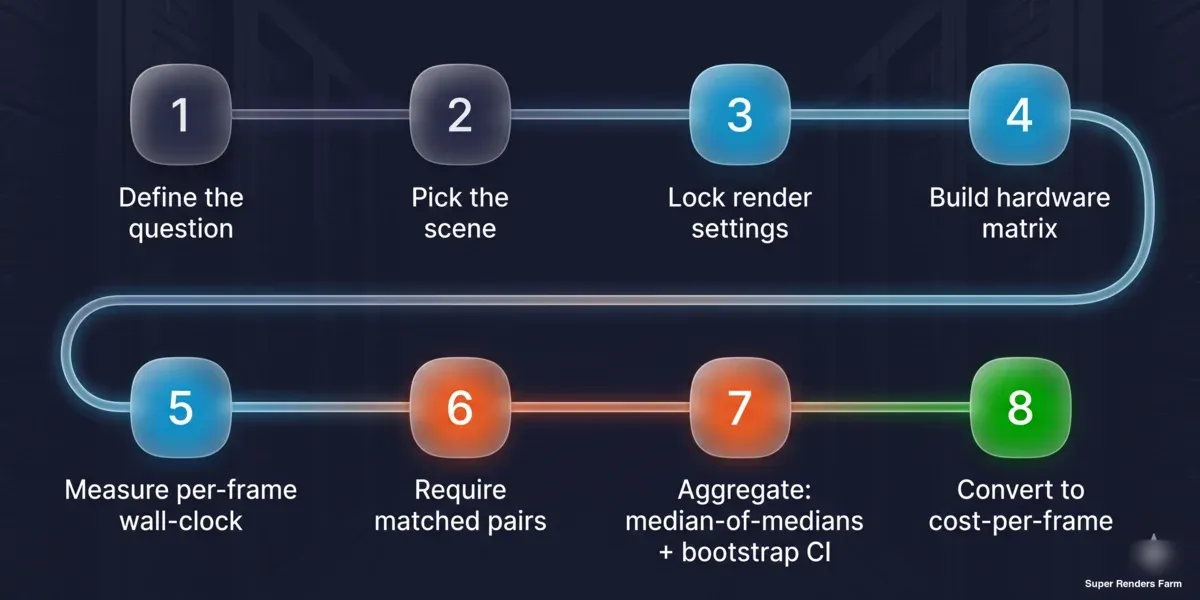
Metodo riproducibile di benchmark del costo per frame in otto passaggi: definire la domanda, scegliere la scena, bloccare le impostazioni di rendering, costruire la matrice hardware, misurare il tempo a orologio per frame, richiedere coppie corrispondenti, aggregare con mediana delle mediane e intervallo di confidenza bootstrap, convertire in costo per frame
- Definire la domanda. Confronto tra macchine o costo per frame in produzione? La risposta determina il tipo di scena — standard del fornitore per la classifica, rappresentativa della produzione per il costo.
- Fissare la scena e le impostazioni. Bloccare il numero di campioni o la soglia di rumore, la scelta del denoiser, la risoluzione di output, la dimensione del tile/bucket e il build del motore. Annotarli; fanno parte del risultato.
- Costruire la matrice. Elencare le schede su un asse, le combinazioni motore/scena sull'altro. Decidere cosa mantenere costante (OS, build del motore, denoiser, scena) e registrare ciò che non può esserlo (driver).
- Misurare il tempo a orologio per frame. Usare il tempo del task ÷ numero di frame dallo scheduler o un cronometro sull'intero job — non il readout interno del tempo di rendering del motore, che omette il caricamento e il sovraccarico di build.
- Richiedere coppie corrispondenti e un campione minimo. Per qualsiasi affermazione A-versus-B, eseguire la stessa scena su entrambi i lati, con almeno tre task per lato, prima che il risultato conti.
- Aggregare con la mediana delle mediane. Prendere la mediana di ogni scena per lato, poi la mediana dei rapporti per scena. Calcolare un intervallo di confidenza bootstrap e riportare l'intervallo interquartile e l'intervallo completo insieme ad esso.
- Convertire in costo per frame. Moltiplicare il tempo misurato per frame per il costo del nodo per ora. Mantenere le unità esplicite in modo che la cifra sia verificabile.
- Pubblicare le avvertenze insieme al numero. Indicare la dimensione del campione alla base di ogni affermazione, la situazione del driver, se i dati sono osservazionali o controllati e l'ambito che copre e non copre.
Uno studio che segue questi otto passaggi sul proprio hardware otterrà un numero che può difendere — e con cui può verificare il nostro, che è l'intero scopo della pubblicazione del metodo.
Note sull'onestà: cosa un benchmark può e non può affermare
Un metodo è affidabile solo quanto le affermazioni che rifiuta di fare. Tre linee che rispettiamo:
I dati osservazionali non sono dati controllati. I dati di produzione sul campo — job eseguiti dagli utenti nel normale corso dell'attività — sono reali e utili, ma gli utenti modificano le proprie scene tra un re-rendering e l'altro, quindi si tratta di dati osservazionali. Un confronto diretto pulito sullo stesso host (ad esempio, una RTX 5090 contro una RTX 4090 attuale su hardware identico) è un esercizio controllato separato. Non permettiamo che l'uno si spacci per l'altro.
Il confronto nodo-versus-nodo include la configurazione, non solo il silicio. Quando un lato funziona su bare-metal e l'altro in ambiente virtualizzato, parte del divario misurato dipende dalla configurazione, non dal chip. Questo appartiene alle avvertenze principali, non a una nota a piè di pagina.
Nessun numero che non abbiamo misurato. Non estrapoliamo dati sul consumo energetico o termici che non abbiamo testato. Quando il nostro studio sul campo riporta circa 360–375 W per scheda, il dato proviene da un benchmark controllato sotto carico sostenuto — e la cifra di energia per frame derivata da esso è etichettata come inferenza, non come misurazione. Se un numero non è stato misurato, il metodo non lo inventa. Questa disciplina è il motivo per cui un benchmark pubblicato può essere citato.
Esempi pratici dalla nostra render farm
Questo metodo ha prodotto gli studi seguenti; ognuno è un dataset che si può leggere insieme alla ricetta, ed è il luogo in cui trovare i numeri effettivi anziché riderivarli qui.
| Studio | Cosa ha prodotto il metodo | Campione |
|---|---|---|
| Scalabilità multi-GPU | Scalabilità 1x→2x per motore su scene standard del fornitore | 2 nodi, 4 motori, 7 combinazioni scena/benchmark |
| Note sul campo RTX 5090 | Distribuzione costo/accelerazione in produzione, percentili VRAM | 38 scene accoppiate / 1.419 task, 7 settimane |
| Guida al benchmark V-Ray | Stima punteggio sintetico-tempo di rendering | Tabelle di riferimento + stima pratica |
| Cinebench per cloud rendering | Interpretazione punteggio sintetico per livelli hardware | Punteggi di riferimento |
Lo stesso approccio è alla base della pianificazione della capacità sulla nostra GPU cloud render farm, e i numeri specifici per Blender alimentano il nostro lavoro sul cloud rendering Blender — la GPU rappresenta una minoranza del mix complessivo di job (la maggior parte del lavoro sulla render farm è ancora rendering CPU), quindi questi dati GPU sono da intendersi esattamente come tali, non come un'affermazione valida per l'intera render farm.
FAQ
Q: Qual è il modo corretto per eseguire il benchmark di una GPU per render farm? A: Occorre prima decidere se si desidera un confronto tra macchine o un costo per frame in produzione. Per il confronto, utilizzare una scena standard del fornitore ripetibile e un build fisso del benchmark. Per il costo per frame, utilizzare una scena rappresentativa della produzione, misurare il tempo a orologio per frame (tempo del task ÷ numero di frame) e moltiplicare per il costo del nodo per ora. Bloccare le impostazioni di rendering e riportare la distribuzione, non solo un singolo numero.
Q: Perché il costo per frame è migliore di un punteggio benchmark? A: Un punteggio sintetico elimina tutto ciò che varia in produzione — geometria, campionamento, denoiser e risoluzione — quindi due schede possono ottenere punteggi simili pur differendo nel costo per frame reale sulla propria scena. Il costo per frame è l'unità in cui viene effettivamente redatto un budget di rendering, ed è per questo che una metodologia dovrebbe risolversi in esso piuttosto che in un punto di classifica.
Q: Come si converte un punteggio benchmark in una stima del tempo di rendering? A: Usare il rapporto dei punteggi come rapporto approssimativo della velocità: una macchina che ottiene il doppio del punteggio di un'altra sullo stesso build di benchmark renderizza un frame comparabile in circa la metà del tempo. Calcolare l'efficienza della propria macchina come tempo per frame diviso per il punteggio benchmark, poi scalare in base al punteggio della macchina target. Mantenere il build del benchmark costante, poiché i punteggi di build diversi non sono comparabili.
Q: Quali controlli rendono un benchmark GPU affidabile? A: Eseguire un singolo task di rendering per scheda per ottenere numeri netti per scheda, richiedere coppie corrispondenti (stessa scena su entrambi i lati, un numero minimo di task prima che un risultato sia valido), mantenere il driver e il build del motore costanti all'interno di una finestra di misurazione, e mantenere identica l'impostazione del denoiser nel confronto. Quindi aggregare con una mediana delle mediane e riportare l'intervallo di confidenza e l'intervallo completo.
Q: Quante scene di test sono necessarie per un risultato affidabile? A: Poche coppie corrispondenti di alta qualità sono superiori a molte coppie scarsamente controllate. Nel nostro studio di produzione, 38 scene hanno superato un filtro di inclusione rigoroso (stessa scena e stesso utente su entrambi i lati hardware, almeno tre task per lato) su 1.419 task. La dimensione del campione che conta è quella che supera il filtro, non il conteggio grezzo dei task — ed entrambi devono essere riportati.
Q: È possibile replicare il benchmark GPU della render farm in autonomia? A: Sì — questo è l'obiettivo. Fissare una scena e le sue impostazioni, costruire una matrice hardware mantenendo OS, build del motore e denoiser costanti, misurare il tempo a orologio per frame, richiedere coppie corrispondenti, aggregare con mediana delle mediane più un intervallo di confidenza bootstrap, convertire in costo per frame e pubblicare le avvertenze insieme al numero. Gli otto passaggi di replica sopra riportati descrivono la sequenza completa.
Q: Perché viene riportato un intervallo invece di un singolo numero di accelerazione? A: Perché l'intervallo fa parte del risultato. Lo stesso hardware può mostrare un'accelerazione di 1,6x su una scena breve dominata dal sovraccarico e oltre 5x su una pesante dominata dal calcolo, poiché il sovraccarico fisso per frame rappresenta una frazione maggiore di un rendering breve. Riportare solo il valore centrale nasconde la variazione di cui un operatore ha bisogno per pianificare la capacità, quindi pubblichiamo la mediana, l'intervallo interquartile e l'intervallo completo insieme.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



