
Scaling Multi-GPU: cosa fa davvero una seconda GPU per il rendering (Benchmark 2026)
Panoramica
Introduzione
TL;DR: Una seconda GPU raramente raddoppia la velocità di rendering, e quanto aiuta dipende interamente dal motore di rendering. Nei nostri benchmark 2026 su nodi dual RTX 5090 e RTX 4090, i motori throughput (V-Ray, Octane) hanno scalato vicino a 2,00x, mentre i motori render-time hanno scalato meno — Cycles 1,31x–1,63x, Redshift 1,68x–1,92x — perché l'overhead fisso per render riduce ciò che la seconda scheda può accelerare. Due GPU è il limite pratico per nodo; il throughput reale di una render farm deriva dall'eseguire molti frame su molti nodi in parallelo, non dall'accumulare più schede in una macchina.
Una seconda GPU non rende un render il doppio più veloce. Detto così sembra ovvio, ma molte decisioni hardware si basano sull'assunto che due schede significhino velocità doppia. A giugno 2026 abbiamo sottratto dalla coda due nodi di benchmark — uno con due RTX 5090, uno con due RTX 4090 — e misurato cosa succede realmente passando da una a due schede, attraverso quattro motori di rendering e sette scene/combinazioni di benchmark.
La sintesi: dipende interamente dal motore. I benchmark di tipo throughput (V-Ray, Octane) hanno scalato quasi perfettamente, intorno a 2x. I motori render-time (Cycles, Redshift) hanno scalato meno, e sulla scheda più veloce la seconda GPU ha aiutato di meno, non di più. Di seguito vengono esaminati i numeri, spiegato perché la curva si piega in quel modo e — con altrettanta chiarezza — dove questo si ferma. Due schede è il limite per nodo singolo. Andare oltre significa un'architettura diversa, non una versione più grande di questa.
Si tratta di un articolo hardware/benchmark, quindi è orientato alle GPU. Vale la pena precisare che le GPU rappresentano una minoranza di ciò che gira sulla nostra render farm — la maggior parte della produzione è ancora CPU rendering (V-Ray, Corona, Arnold su CPU). Ma quando qualcuno chiede "vale la pena una seconda GPU?", merita numeri misurati, non un discorso commerciale. Ecco quindi i numeri misurati.
Come abbiamo testato (e cosa questi numeri non sono)
Entrambi i nodi di test giravano su Windows 11 Pro con due GPU ciascuno. Il nodo 5090 utilizzava il driver 596.36; il nodo 4090 il driver 610.62 — una scheda Blackwell richiede un driver più recente, quindi un abbinamento esatto non era possibile. Questa differenza di driver conta solo per una cosa: il confronto di velocità assoluta cross-generazionale tra una 5090 e una 4090. I rapporti di scaling su cui ci concentriamo qui sono misurati all'interno di un singolo nodo (stessa scheda, stesso driver, una GPU contro due), quindi la differenza di driver non li riguarda.
Ogni scena è un benchmark standard del produttore — le scene Open Data di Blender (bmw27, classroom, junkshop), la scena "Vultures" di Maxon per Redshift, il Chaos V-Ray Benchmark 6.00.02 e OctaneBench 2025.2.1. Nessun progetto cliente, nessun asset di produzione. Non vengono pubblicati qui i minuti per frame, il costo per frame o i consumi elettrici, perché questo dataset non li contiene e non si inventano dati.
Una nota metodologica che influisce sulla lettura delle righe di Cycles: le scene Blender Cycles sono state eseguite al 200% di risoluzione, più pesante del default Open Data, specificamente per far sì che ogni render duri abbastanza a lungo da produrre un rapporto di scaling stabile e attendibile. Ciò significa che i tempi grezzi di Cycles non sono comparabili ai punteggi pubblici Open Data — sono calibrati per misurare lo scaling, non per classificarsi in leaderboard. Cycles e Redshift sono misurati in tempo di rendering (secondi, minore è meglio); V-Ray e Octane sono misurati come punteggio benchmark (vpaths o punti OctaneBench, maggiore è meglio). Queste sono due tipologie di metrica diverse, quindi i numeri assoluti non si comparano mai tra motori — solo il rapporto di scaling all'interno di un motore è un confronto omogeneo.
Il risultato principale: scaling da 1x a 2x per motore
Ecco i dati principali — cosa porta effettivamente una seconda scheda identica, per motore e scena:
| Motore | Scena | Scaling 2x RTX 5090 | Scaling 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1,54x | 1,58x |
| Cycles | classroom | 1,59x | 1,63x |
| Cycles | junkshop | 1,31x | 1,38x |
| Redshift | Vultures | 1,68x | 1,92x |
| V-Ray GPU (CUDA) | benchmark | 1,97x | 2,00x |
| V-Ray GPU (RTX) | benchmark | 2,00x | 2,00x |
| Octane | suite OctaneBench | 2,00x | 1,98x |
Leggendo dall'alto verso il basso emerge una divisione netta. V-Ray e Octane si attestano a 2,00x o appena sotto su entrambe le schede — una seconda GPU quasi raddoppia l'output. Cycles si colloca nell'intervallo 1,31x–1,63x. Redshift arriva a 1,68x sul 5090 e 1,92x sul 4090.
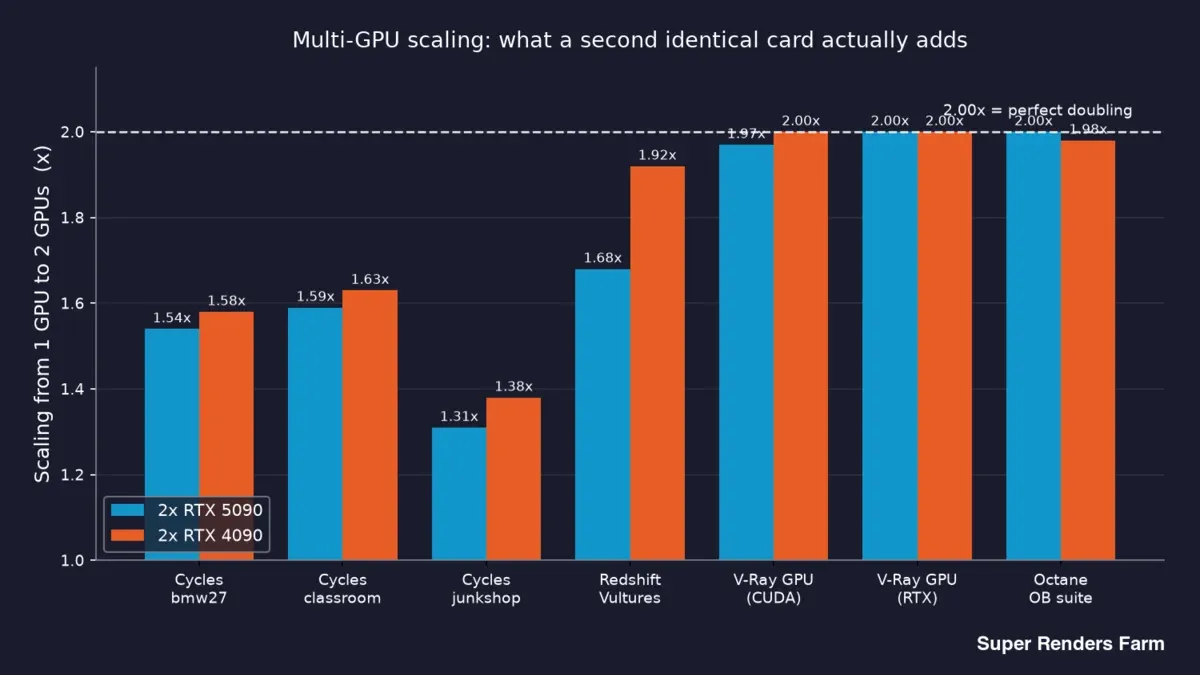
Grafico a barre dello scaling da 1 a 2 GPU per motore su nodi RTX 5090 e RTX 4090 dual-GPU: Cycles 1,31x–1,63x, Redshift 1,68x contro 1,92x, V-Ray e Octane vicini a 2,00x
Quindi alla domanda "aggiungere una seconda GPU raddoppia la velocità?" esistono tre risposte oneste diverse a seconda di cosa si renderizza: sostanzialmente sì per V-Ray e Octane, circa 1,5x in più per Cycles, e qualcosa nel mezzo per Redshift. Chi afferma che un singolo moltiplicatore copra tutto il rendering non ha misurato davvero.
Perché i motori throughput scalano meglio dei motori render-time
Il pattern non è casuale — deriva da come ogni benchmark impiega il proprio tempo. V-Ray Benchmark e OctaneBench sono test di throughput. Distribuiscono un carico di lavoro su qualsiasi unità di calcolo disponibile e riportano un punteggio, e il costo fisso di avvio (caricamento della scena, costruzione delle strutture di accelerazione, inizializzazione del dispositivo) è una frazione minima del totale. Aggiungere una seconda scheda fa sì che quasi tutta quella potenza aggiuntiva vada direttamente in lavoro utile, quindi si ottiene un valore vicino a 2x. Il risultato V-Ray RTX che tocca un netto 2,00x su entrambe le schede è esattamente quello che ci si aspetta da un carico di lavoro in cui l'overhead è essenzialmente rumore.
I motori render-time si comportano diversamente. Quando si misura un render Cycles o Redshift in secondi a parete, si sta cronometrando l'intero lavoro — e ogni lavoro porta con sé una quota fissa di overhead non parallelizzabile: parsing della scena, costruzione della struttura BVH/accelerazione, compilazione e avvio del kernel, coordinamento del dispositivo, il resolve finale dei pixel. Una seconda GPU accelera la parte realmente distribuibile tra le schede. Non fa nulla per la parte fissa. Più il tempo di rendering totale è occupato dall'overhead fisso, più lo scaling scende sotto 2x.
Ecco perché Cycles junkshop (1,31x–1,38x) scala peggio di Cycles classroom (1,59x–1,63x): junkshop è un render più leggero e breve, quindi il suo overhead fisso rappresenta una quota maggiore del totale, lasciando meno spazio alla seconda scheda. La scena classroom gira più a lungo, la porzione parallela domina e la seconda GPU ha più margine per contribuire. Stesso motore, stesso hardware — è la scena a determinare quanto conta la seconda scheda.
La parte controintuitiva: la scheda più veloce ha scalato di meno
Tornando alla riga di Redshift. Due RTX 5090 hanno scalato 1,68x. Due RTX 4090 hanno scalato 1,92x. La scheda più recente e veloce ha scalato peggio. Sembra un errore. Non lo è — è il numero più istruttivo di tutto il set.
Ecco il meccanismo. La 5090 è la scheda più veloce in termini assoluti; su una singola GPU completa la scena Vultures in circa 57 secondi, contro i 100 secondi del 4090. Ma quell'overhead fisso per render — parsing, build, avvio — è all'incirca lo stesso numero di secondi indipendentemente da quale scheda lo esegua. Sul 4090, quella quota fissa è una piccola frazione di un render lungo 100 secondi, quindi la seconda scheda ha una porzione parallela ampia da elaborare e lo scaling arriva vicino a 1,92x. Sul 5090, il render è già breve, quindi quella stessa quota fissa è una frazione maggiore del totale, lasciando una porzione parallela più ridotta alla seconda scheda — e lo scaling si attesta a 1,68x.
Aspetto fondamentale: questo non significa che la 5090 sia peggiore. È più veloce su una scheda ed è più veloce su due schede. Semplicemente guadagna proporzionalmente meno dalla seconda GPU perché aveva già meno render lento da velocizzare. Più veloce è il render di base, più difficile è per una seconda scheda consegnare un netto 2x — c'è semplicemente meno tempo rimasto da parallelizzare. È una cosa davvero utile da capire prima di investire in schede identiche aspettandosi rendimenti lineari.
Velocità per scheda: RTX 5090 vs RTX 4090
Lo scaling è un asse; la velocità grezza per scheda è l'altro. Su una singola scheda, applicando la precisazione sui driver dalla sezione metodologica, la 5090 ha superato il 4090 su ogni motore testato:
| Motore | Metrica | RTX 5090 | RTX 4090 | Vantaggio 5090 |
|---|---|---|---|---|
| Cycles — bmw27 | secondi (meno è meglio) | 49,45 | 77,40 | 1,57x |
| Cycles — classroom | secondi | 23,09 | 36,87 | 1,60x |
| Cycles — junkshop | secondi | 19,71 | 34,43 | 1,75x |
| Redshift — Vultures | secondi | 57 | 100 | 1,75x |
| V-Ray GPU (CUDA) | vpaths (più è meglio) | 11.051 | 7.419 | 1,49x |
| V-Ray GPU (RTX) | vpaths | 15.333 | 9.608 | 1,60x |
| Octane | punteggio OctaneBench | 1.690,78 | 1.074,17 | 1,57x |
Complessivamente la 5090 è circa 1,5x–1,75x più veloce per scheda. Due considerazioni per chi pianifica l'hardware. Prima: i guadagni generazionali per scheda (1,5x–1,75x qui) sono maggiori e più affidabili del guadagno derivante dall'aggiungere una seconda scheda della stessa generazione su un motore render-time (spesso ben sotto il 2x). In termini semplici: una scheda più veloce è frequentemente una leva migliore di una seconda scheda. Seconda: questi numeri cross-generazionali su singola scheda portano con sé la precisazione sulla mancata corrispondenza dei driver — andrebbero trattati come confronto direzionale, non come garanzia di prestazione. Le misurazioni sono su scene benchmark; complessità della scena, campionamento e risoluzione di output sposteranno il valore nel mondo reale. Per ulteriori dettagli sul comportamento della 5090 su singola scheda, si veda il nostro articolo sulle prestazioni di rendering cloud con RTX 5090.
Due GPU è il limite per nodo — e perché va bene così
Qui si traccia una linea netta, perché è la parte che la maggior parte dei contenuti multi-GPU tace. Ogni nodo in questo benchmark è un nodo a due GPU. Due schede è il limite per nodo. Non verranno mostrate curve di scaling 4x o 8x su nodo singolo, perché non è una configurazione che utilizziamo, e non si vuole suggerire il contrario.
Superare le due GPU su un singolo frame significa rendering distribuito multi-nodo — dividere un'immagine tra più macchine, con tutto il coordinamento di rete, la gestione dei bucket/tile e l'overhead che ne derivano. Si tratta di un'architettura genuinamente separata, non di una versione più grande di una macchina a due schede. Non è qualcosa che offriamo oggi per un singolo frame, e non lo si vuole far intendere come "prossimamente" con una data allegata.
E questo è il punto: per la stragrande maggioranza del lavoro di produzione, il limite delle due GPU non è il vincolo che conta. Il vincolo che si fa sentire per primo è quasi sempre la VRAM, non il numero di schede — una scena che non entra in 32 GB non renderizza indipendentemente da quante GPU si puntano, il che è un problema diverso (trattato in limiti VRAM di RTX 5090 per scene complesse). Quando le persone immaginano di "scalare una render farm", di solito si figurano un singolo render grande che diventa sempre più veloce su quantità crescenti di silicon. Non è così che funziona il throughput su scala di render farm.
Come scala davvero una render farm: frame, non schede
Questa è la distinzione che vale la pena interiorizzare, ed è quella a cui continuano ad alludere i numeri del benchmark sopra riportati. Ci sono due cose completamente diverse che le persone intendono con "rendere più veloce con più hardware":
- Dividere un frame tra molte GPU o macchine (rendering distribuito tile/bucket). È quello che misurano i numeri 1x→2x alla scala a due schede, e quello che il rendering distribuito multi-nodo estenderebbe. Incontra rendimenti decrescenti rapidi sui motori render-time, come mostrano i dati, a causa dell'overhead fisso per render — e il costo di coordinamento cresce al crescere delle macchine.
- Distribuire molti frame su molte macchine (rendering frame-parallelo). Ogni nodo renderizza un frame intero per conto suo; i frame di un'animazione vengono distribuiti su tutta la flotta in parallelo. Non c'è overhead di coordinamento su singolo frame da combattere, quindi scala in modo pulito ed è così che un'animazione viene completata velocemente.
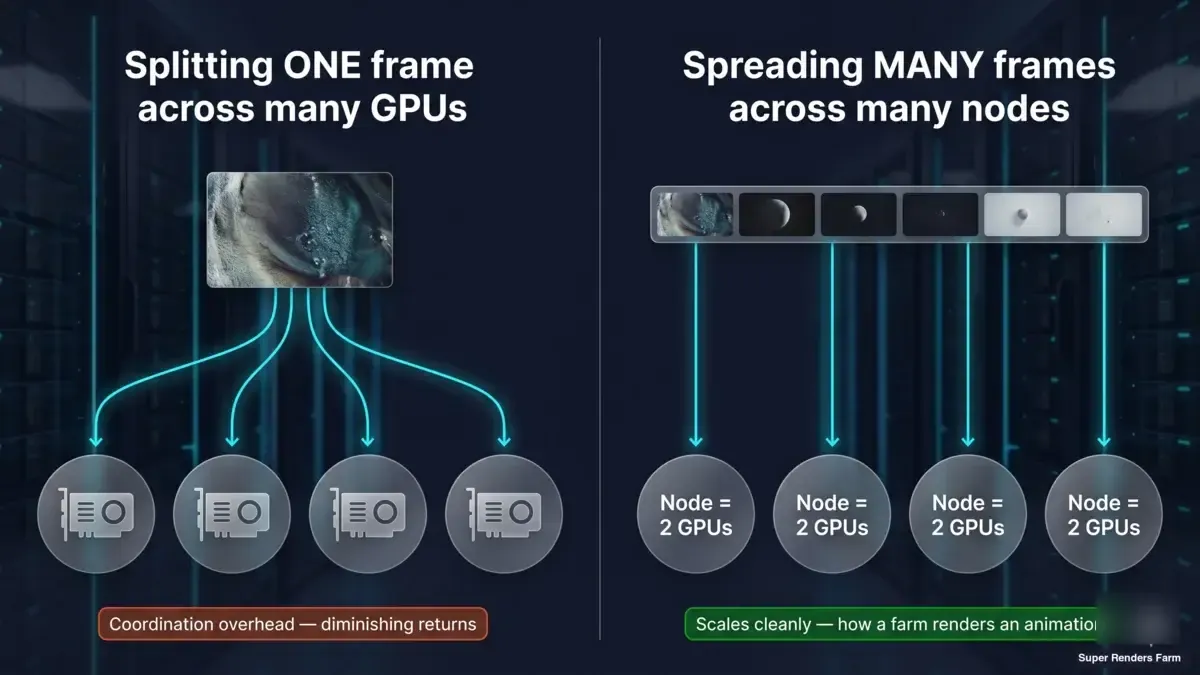
Diagramma concettuale in due pannelli: un frame diviso tra più GPU incontra overhead di coordinamento e rendimenti decrescenti; molti frame interi ciascuno sul proprio nodo a due GPU in parallelo scalano in modo pulito, ovvero come una render farm accelera un'animazione
Una render farm gestita ottiene la propria velocità quasi interamente dal secondo modello. Il tuo progetto da 500 frame non viene renderizzato come un unico frame spalmato su 500 GPU — viene renderizzato come 500 frame distribuiti su tutta la flotta, ciascuno sul proprio nodo, tutti contemporaneamente. La velocità per nodo e per frame è determinata dal tipo di scaling a due GPU e dalle prestazioni per scheda che abbiamo misurato in questo benchmark; la velocità a livello di render farm deriva dal numero di frame che girano in contemporanea. Sono leve diverse, e confonderle è la radice di molta confusione sul tema "quante GPU mi servono".
Il quadro onesto del multi-GPU è quindi più ristretto rispetto alla versione marketing. Due schede per nodo offrono un boost reale e misurabile — vicino a 2x su V-Ray e Octane, più modesto su Cycles e Redshift. Oltre, la risposta non è "aggiungi più schede al box", ma "esegui più frame su più nodi". Questa è l'architettura, e essere chiari al riguardo tende a far risparmiare alle persone denaro che stavano per spendere su hardware che non avrebbe reso quanto si aspettavano.
Cosa significa questo quando si sceglie come renderizzare
Riepilogando in qualcosa di pratico. Se si deve scegliere tra una e due schede per una workstation, il motore che si usa dovrebbe guidare la decisione: gli utenti di V-Ray o Octane ottengono quasi il raddoppio completo e la seconda scheda è facile da giustificare; gli utenti di Cycles e Redshift dovrebbero aspettarsi un incremento tra 1,3x e 1,9x e valutare se una singola scheda più veloce (il guadagno generazionale di 1,5x–1,75x) sia la spesa migliore. Se si deve decidere se renderizzare localmente o affidare il lavoro a una render farm, è importante ricordare che il vantaggio della render farm è il throughput frame-parallelo su un'animazione, non un moltiplicatore magico su singolo frame — un singolo frame hero non renderizzerà drammaticamente più veloce su una render farm rispetto a una workstation comparabile, ma qualche centinaio di frame assolutamente sì.
Per un approfondimento sul confronto tra gestione affidata e fai-da-te — chi si occupa di driver, licenze e configurazione dei nodi — il nostro articolo sulle render farm completamente gestite vs fai-da-te copre l'argomento. Sulla nostra render farm, le licenze dei motori di rendering (V-Ray, Redshift, Octane) sono incluse nella tariffa di rendering e la configurazione dei nodi è fissa e mantenuta, quindi la configurazione a due GPU per nodo e i driver che stanno dietro questi numeri non sono qualcosa che si assembla o regola autonomamente. Per il lato Redshift su Cinema 4D specificamente, dove si colloca il valore di scaling 1,68x, si veda la nostra guida alla render farm Redshift per Cinema 4D.
Le misurazioni presentate qui sono deliberatamente prive di esagerazione. Una seconda GPU è una leva reale con limiti reali, la scheda più veloce scala di meno perché aveva meno render lento da velocizzare, e la velocità su scala di render farm è una storia di distribuzione dei frame, non di accumulo di schede. Sapere quale leva si applica al proprio carico di lavoro è la maggior parte della decisione.
FAQ
Q: Aggiungere una seconda GPU raddoppia la velocità di rendering? A: Di solito no. Nei nostri benchmark 2026, i motori throughput come V-Ray e Octane hanno scalato vicino a 2,00x con una seconda scheda identica, ma i motori render-time hanno scalato meno — Cycles si è attestato tra 1,31x e 1,63x e Redshift ha raggiunto 1,68x con dual RTX 5090. Il guadagno dipende interamente dal motore e dalla scena, perché ogni render porta con sé un overhead fisso che una seconda scheda non può accelerare.
Q: Perché Redshift scala meglio su RTX 4090 che su RTX 5090? A: Perché la 5090 è più veloce, i suoi render sono più brevi, quindi l'overhead fisso per render (parsing della scena, build della struttura di accelerazione, avvio del kernel) rappresenta una frazione maggiore del totale. Questo lascia una porzione parallela più ridotta alla seconda scheda, quindi lo scaling si attesta a 1,68x sulla 5090 contro 1,92x sulla 4090. La 5090 è comunque più veloce sia su una che su due schede — guadagna semplicemente proporzionalmente meno dalla seconda GPU.
Q: Quanto è più veloce l'RTX 5090 rispetto all'RTX 4090 per il rendering? A: Circa 1,5x–1,75x più veloce per scheda sui motori testati, tra cui Cycles, Redshift, V-Ray GPU e Octane. Questi valori cross-generazionali su singola scheda portano con sé una precisazione minore perché le due schede giravano con driver NVIDIA diversi, quindi andrebbero trattati come confronto direzionale piuttosto che come garanzia fissa.
Q: Perché V-Ray e Octane scalano meglio di Cycles e Redshift con due GPU? A: V-Ray Benchmark e OctaneBench sono test di throughput in cui il costo fisso di avvio è una frazione minima del tempo, quindi una seconda scheda va quasi interamente in lavoro utile e lo scaling si avvicina a 2,00x. Cycles e Redshift sono misurati come tempo di rendering totale, che include overhead non parallelizzabile che una seconda scheda non può accelerare, quindi il loro scaling rimane sotto il 2x.
Q: Una render farm può far renderizzare più velocemente un singolo frame su più macchine? A: Dividere un frame tra più macchine è il rendering distribuito multi-nodo, che è un'architettura separata con il proprio overhead di coordinamento e non è qualcosa che offriamo oggi per un singolo frame. Una render farm gestita ottiene la propria velocità dal rendering frame-parallelo — molti frame interi distribuiti contemporaneamente su molti nodi — quindi un'animazione si completa velocemente mentre un singolo frame hero renderizza all'incirca alla velocità per nodo.
Q: Di quante GPU ho davvero bisogno per il rendering? A: Per un singolo nodo, due GPU è un limite sensato ed è quello che usano i nostri nodi di benchmark; oltre, il vincolo pratico è di solito la VRAM, non il numero di schede, poiché una scena che non entra in memoria non renderizza indipendentemente da quante schede si aggiungono. Per chi renderizza animazioni, il throughput reale deriva dall'eseguire più frame su più nodi piuttosto che dall'accumulare più schede in una macchina.
Q: Questi numeri di benchmark sono comparabili ai punteggi pubblici di Blender Open Data? A: No. Le scene Blender Cycles sono state eseguite al 200% di risoluzione, più pesante del default Open Data, in modo che ogni render durasse abbastanza a lungo da produrre un rapporto di scaling stabile. Ciò rende i tempi grezzi di Cycles intenzionalmente non comparabili alle leaderboard pubbliche Open Data — le scene erano calibrate per misurare lo scaling, non per abbinarsi ai punteggi standard.
Q: È necessario gestire driver GPU e licenze per usare una render farm gestita? A: No. Su una render farm completamente gestita, la configurazione dei nodi, i driver e le licenze dei motori di rendering (V-Ray, Redshift, Octane) vengono gestiti e sono inclusi nella tariffa di rendering, quindi la configurazione dei nodi a due GPU e i driver che stanno dietro questi benchmark non sono qualcosa che si assembla o regola. Cycles è gratuito e open-source, quindi non richiede licenze separate.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



