Se lo studio lavora su un filespace condiviso, ogni job di render inviato a una render farm di solo upload obbliga a riesportare, riempacchettare e spingere centinaia di gigabyte attraverso la rete pubblica prima che il rendering possa iniziare. È il lato dati a diventare il collo di bottiglia, non il lato render.
Esempio concreto: una scena da 800 GB impacchettata per un progetto archviz Cinema 4D + Redshift impiega gran parte di una giornata lavorativa a 100 Mbit/s — prima che venga renderizzato un singolo frame. Moltiplicato per tre o cinque job settimanali, la finestra di upload occupa il calendario, non la flotta GPU. Le versioni peggiorano il problema — un cambio di asset da 20 GB a metà progetto significa un'altra riesportazione e un'altra finestra di upload.
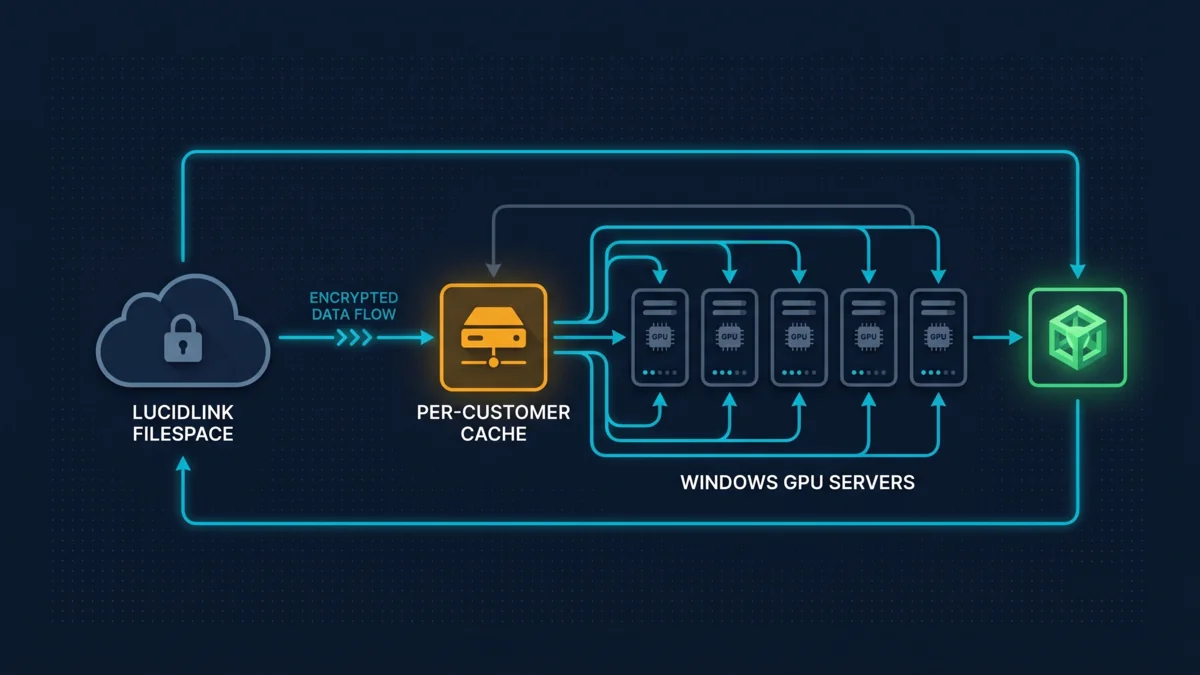
LucidLink risolve pulitamente il lato dati: streaming per intervallo di byte su object storage, cifrato end-to-end, montato come un drive locale su ogni postazione della pipeline. Il team artistico smette di pensare a dove vivono i file.
Ma le flotte di render degli hyperscaler come AWS Deadline Cloud e gli equivalenti su GCP richiedono che sia il cliente a gestire la flotta — credenziali di service account, topologia VPC, template AMI, ciclo di vita degli event-script, policy di autoscaling, e tutto il vocabolario operativo che le accompagna. La maggior parte degli studi non vuole fare il sysadmin cloud oltre al lavoro artistico.
Super Renders Farm colma il divario: porta il tuo filespace LucidLink, noi operiamo la flotta di render gestita. Il flusso di lavoro dei dati che già hai, collegato a hardware di render che non devi gestire.