
RTX 5090 in produzione: 7 settimane di appunti dalla render farm (studio su 38 scene)
Panoramica
I benchmark di lancio dell'RTX 5090 hanno ormai più di un anno, e descrivono tutti la stessa cosa: una sola scheda, una scena preparata ad hoc, condizioni ideali. Quello che quasi nessuno pubblica è il seguito — il comportamento della scheda una volta immersa in una coda di produzione, mentre esegue il render delle scene altrui secondo una pianificazione che non controlla. Così abbiamo estratto i log. Quello che segue sono gli appunti a livello di coda: gli stessi dati di produzione su cui basiamo la pianificazione della capacità, esposti come numeri verificabili.
Questo copre sette settimane. Dal 1° aprile al 22 maggio 2026 — 51 giorni — abbiamo operato un nodo dual-RTX-5090 all'interno della nostra render farm live, lasciando che accettasse qualsiasi lavoro la coda gli assegnasse. Nessun test preparato, nessun frame selezionato a mano. Il breve video qui sotto illustra i numeri principali; gli appunti completi seguono.
Il nodo in sé è ordinario: due RTX 5090, 128 GiB di RAM, 32 core logici a 4.3 GHz, Windows 11. Un dettaglio influenza ogni cifra riportata — lo scheduler esegue un singolo task di render per GPU, quindi ogni scheda gestisce il proprio job e ogni numero è un numero pulito per singola scheda, il valore da moltiplicare per pianificare la capacità. Nel periodo considerato il nodo ha completato il 99.6% dei suoi task — 4,890 su circa 4,900 completati, 18 falliti. Lo scheduler registra il fallimento, non la causa, quindi non avanziamo ipotesi.
Numeri principali
- Periodo: 1° aprile – 22 maggio 2026 (51 giorni, ~7 settimane), un nodo dual-RTX-5090
- Completamento: 99.6% — 4,890 task su ~4,900 completati, 18 falliti (causa non registrata)
- Speedup: mediano 3.2x per frame su Blender Cycles rispetto ai nodi classe RTX 3080/2080 della generazione precedente (tempo mediano per frame ridotto di ~69%); IC 95% 3.0-3.3x
- Dispersione: IQR 2.7-3.4x, range completo 1.6x-5.1x su 38 scene abbinate — un solo moltiplicatore non descrive mai una coda
- Denoising AI: ~83% dei job Cycles ha eseguito un passaggio di denoising AI — la stessa percentuale sull'hardware precedente
- VRAM: mediana 5.6 GB, 90° percentile 11.5 GB, job più pesante ~37 GB
- Driver: un solo driver (581.80 / CUDA 13.0) per l'intero periodo, zero cambi
- Consumo: ~360-375 W/scheda sotto carico (bench controllato), con picco ~400 W, a 68-83 °C — ben al di sotto della classe nominale di ~575 W
Cosa mostrano 38 scene abbinate
Il confronto di cui ci fidiamo di più non è un test sintetico, ma i job che hanno girato su entrambe le generazioni nel normale corso delle attività — stessa scena, stesso utente, almeno tre task per lato prima che una scena venisse conteggiata. Il tempo per frame è il wall-clock del task diviso per il numero di frame, direttamente dalla coda. Nel periodo considerato, 38 scene hanno superato quel filtro, estratte da 1,419 task di render individuali (503 sul nodo 5090, 916 sulla generazione precedente). Trentotto non è la dimensione del nostro dataset; è ciò che sopravvive a un filtro deliberatamente rigoroso.
| Metrica | Valore |
|---|---|
| Speedup mediano per frame | 3.2x (≈69% di riduzione del tempo) |
| IC bootstrap 95% (mediana) | 3.0-3.3x |
| Range interquartile | 2.7-3.4x |
| Range completo | 1.6-5.1x |
| Scene / task | 38 scene / 1,419 task |
| Baseline | classe RTX 3080/2080 generazione precedente (10-12 GB) |
Si utilizza una mediana delle mediane: ogni scena contribuisce con la mediana dei propri tempi per frame su ciascun lato, e il 3.2x è la mediana di questi 38 rapporti, così un singolo frame lento non può distorcere il risultato. La dispersione conta quanto il punto centrale — la metà centrale delle scene si colloca tra 2.7x e 3.4x, e il range completo va da 1.6x a 5.1x.
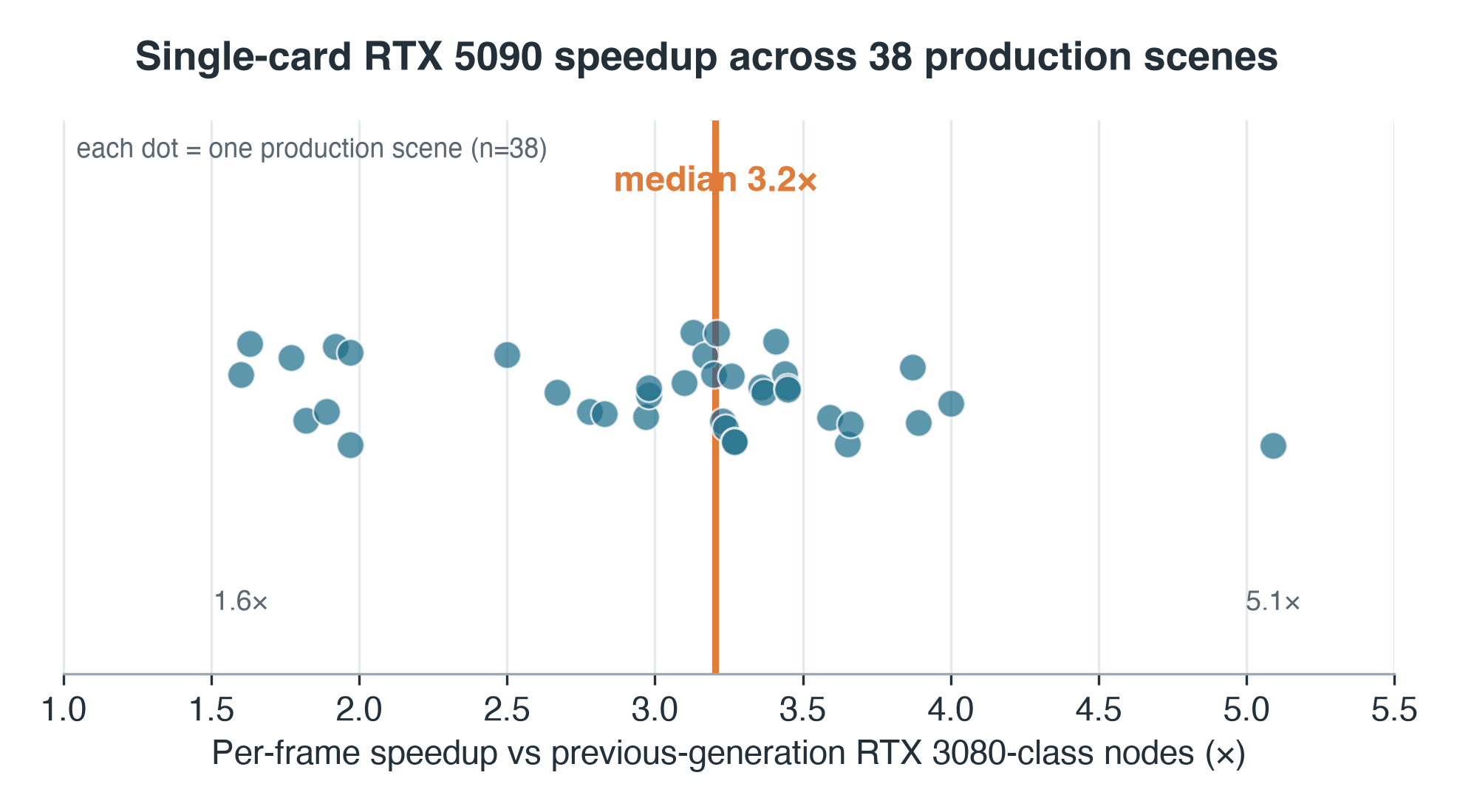
Speedup RTX 5090 per scena su 38 scene Blender Cycles in produzione, mediana 3.2x con una dispersione da 1.6 a 5.1x
Speedup per scena, RTX 5090 rispetto ai nodi della generazione precedente su cui giravano questi job — campione di produzione di 38 scene. Mediana 3.2x; range 1.6-5.1x.
Due avvertenze appartengono a questo dato, non a una nota a piè di pagina. Primo, il lato della generazione precedente era virtualizzato — GPU passthrough all'interno di una VM — quindi una quota non misurata di questo 3.2x è overhead di virtualizzazione, non silicio puro; il confronto pulito sulla stessa macchina, un RTX 5090 contro un RTX 4090 corrente, è il follow-up controllato che dobbiamo ancora eseguire. Secondo, le 38 scene non sono un campione casuale dalla coda: sono i job che un utente ha scelto di ri-renderizzare su entrambe le generazioni, il che distorce il campione verso lavori più lunghi e iterati — quindi la distribuzione va letta come quella delle coppie abbinate, non dell'intera coda.
Tre note di onestà sono fondamentali qui. Questi sono dati osservazionali — gli utenti modificano talvolta le impostazioni tra un re-render e l'altro, e non abbiamo congelato le loro scene. Il confronto è nodo contro nodo: il lato 5090 è una singola scheda bare-metal, il lato della generazione precedente gira come GPU passthrough all'interno di macchine virtuali, quindi parte del divario è dovuta alla configurazione, non al silicio. E la baseline è costituita dalle schede classe RTX 3080/2080 su cui questi job giravano effettivamente — non un RTX 4090 corrente; un confronto testa a testa con la scheda attuale è un esercizio separato e controllato che non abbiamo ancora eseguito. Questi sono numeri relativi a un singolo nodo, solo Cycles; descrivono la nostra coda e non devono essere generalizzati ad altri engine o hardware.
Ciò che separa una scena a 1.6x da una a 5.1x è in parte visibile nei dati. Tracciando lo speedup di ogni scena rispetto al tempo di esecuzione dei suoi frame sull'hardware precedente, emerge una debole tendenza positiva — Spearman ρ ≈ 0.34 (p a due code ≈ 0.04). I frame brevi e vincolati dall'overhead si trovano nella parte bassa: quando un frame termina in cinque secondi, il costo fisso per task — caricamento della scena, sincronizzazione, il vecchio livello di virtualizzazione — consuma la maggior parte del clock, e una scheda più veloce ha poco su cui agire. I frame più pesanti e vincolati dal calcolo guadagnano di più. Ma c'è dispersione reale: una scena pesante si è fermata a soli 1.6x perché il collo di bottiglia non era la GPU, ma plausibilmente lo storage o una fase vincolata dalla CPU. La mediana dice una cosa; il range dice che dipende dalla scena.
Il denoising AI era già il default
Se si chiede dove l'AI si collochi davvero in una pipeline di rendering in produzione nel 2026, i nostri log offrono una risposta poco spettacolare: nel denoiser. Circa l'83% dei job Cycles sul nodo 5090 ha eseguito un passaggio di denoising AI — OptiX o Intel Open Image Denoise — e la percentuale sui nostri nodi della generazione precedente è sostanzialmente identica. La nuova scheda non ha avviato questa abitudine; era già standard sull'hardware precedente ed è rimasta standard su quello nuovo. Per una pipeline con denoising intensivo, un salto generazionale non acquista un'"AI" che era già presente — acquista throughput di path tracing attorno a un passaggio già consolidato. Questa cifra è circoscritta a Cycles di proposito; si raccomanda di essere scettici verso qualsiasi "% AI" a livello di farm non ancorata a un singolo engine.
VRAM in condizioni reali
Cycles scrive il picco di memoria sul dispositivo nel proprio log di render — un proxy semplice ma utilizzabile per ciò che la produzione richiede davvero alla VRAM. Sui 57 job Cycles in cui quella riga era stata registrata, la memoria di render sul dispositivo al picco era di circa 5.6 GB alla mediana e 11.5 GB al 90° percentile. Le nostre schede della generazione precedente sono componenti da 10-12 GB, quindi il job mediano sarebbe rientrato — ma il job al 90° percentile sfiorava già il loro limite. E la coda si estende oltre: il job più pesante ha registrato circa 37 GB, oltre i 32 GB della stessa 5090 — il tipo di scena che su una GPU significa un fallback su CPU o nessun render. Il log non contiene metadati sulla scena, quindi non possiamo dire di che tipo di scena si trattasse — solo la sua classe: un working set da 37 GB è la firma di geometria complessa, set di texture ad alta risoluzione o volumetrici, il tipo di job che supera anche una scheda da 32 GB e, su una singola GPU, si blocca semplicemente. La regola operativa resta valida: la VRAM va dimensionata per la coda, non per la mediana. È per questo che esistono sia la memoria on-card sovradimensionata sia la capacità condivisa di GPU cloud render farm — per poter richiedere una scheda più grande per job, invece di acquistarne una.
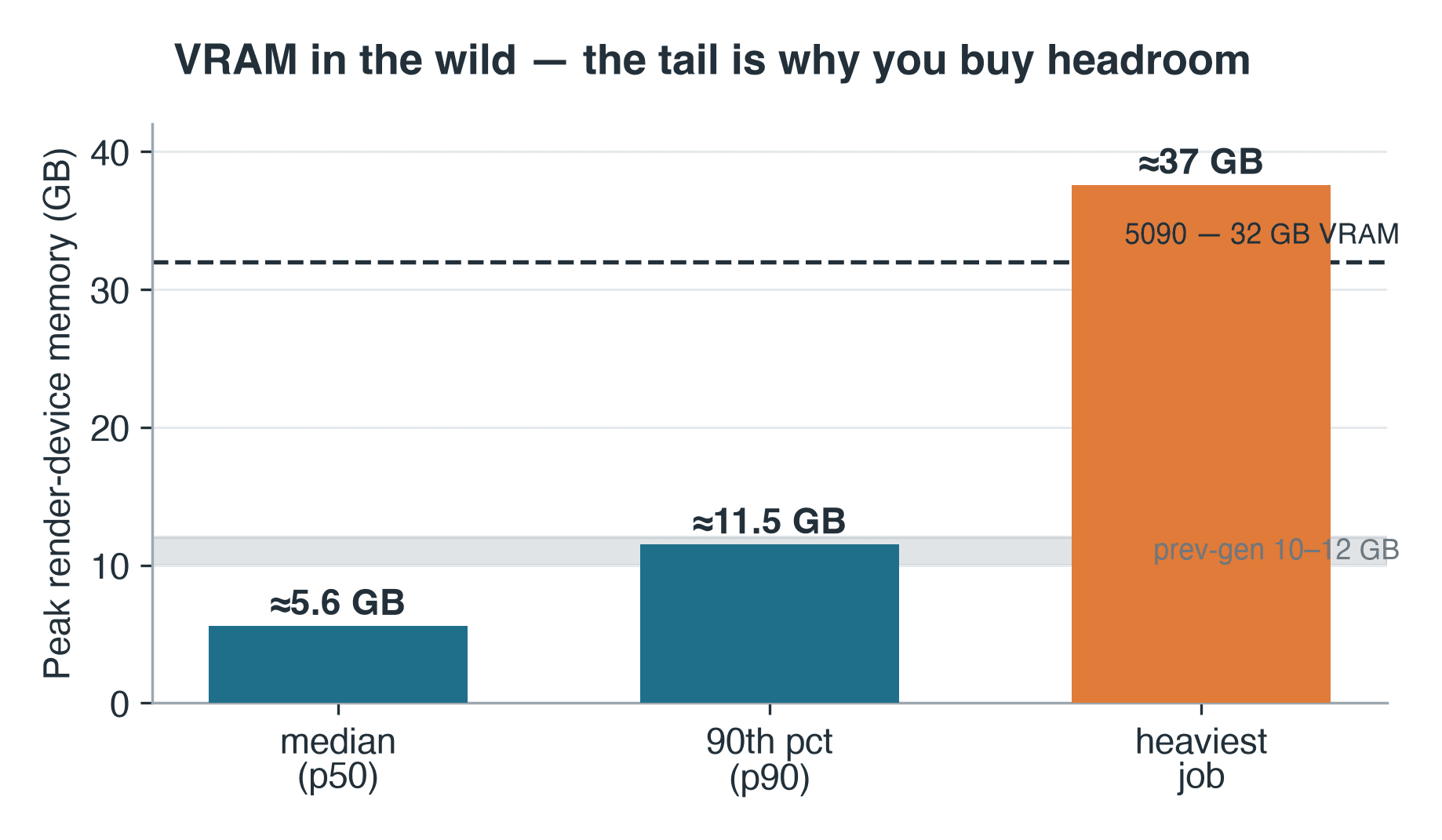
Picco di memoria di render sul dispositivo per job Blender Cycles sul nodo RTX 5090: mediana 5.6 GB, 90° percentile 11.5 GB, job più pesante 37 GB
Picco di memoria di render sul dispositivo su 57 job Cycles registrati. Il job più pesante ha superato i 32 GB della stessa 5090.
Un solo driver, e consumi contenuti
Il risultato meno spettacolare è quello che si vorrebbe conoscere prima di acquistare. Un solo driver — 581.80, su CUDA 13.0 — ha operato per l'intero periodo senza alcun cambio: nessun rollback, nessuna sostituzione nel mezzo del periodo. Per hardware di prima generazione su una coda di produzione, un log del driver noioso è il complimento migliore.
Il consumo è stato altrettanto stabile. In un bench controllato delle stesse schede sotto carico prolungato, ciascuna ha assorbito circa 360-375 W (con picco vicino a 400) a 68-83 °C — la scheda superiore in una coppia sovrapposta è la più calda, ma ben al di sotto della classe nominale di ~575 W. Il dimensionamento va fatto sul consumo prolungato, non sul picco nominale. L'energia per frame completato è di circa 2.5 Wh con un frame Cycles mediano di circa 24 secondi — ma va trattata come un'inferenza: si basa sul consumo da bench ed è stata calcolata per il solo 5090, non misurata rispetto ai nodi precedenti.
Perché questi appunti partono da Blender
Negli ultimi 90 giorni, i job GPU rappresentavano circa un quarto di tutto ciò che la nostra farm ha renderizzato — il resto è lavoro CPU. All'interno del mix GPU, Cycles costituisce circa il 74% dei job e Redshift è un chiaro secondo con circa il 15%, ed è per questo che un articolo sull'RTX 5090 su una render farm parte dal rendering cloud con Blender. Per il comportamento di più schede di questo tipo insieme, si vedano gli appunti di accompagnamento sulle performance del cluster RTX 5090, e per il limite di memoria in modo specifico, dove i limiti della VRAM incidono sulle scene complesse.
Da questa coda emergono due conclusioni. Prima: la produzione non è un benchmark — una scheda che ottiene un buon risultato in laboratorio deve comunque assorbire overhead di virtualizzazione, carichi misti e scene per cui non è stata ottimizzata, e il risultato è una distribuzione, non un punto. Seconda: la mediana non è la coda. Uno speedup tipico di 3.2x e un picco di memoria di 37 GB su un singolo job sono entrambi veri contemporaneamente, e la capacità va pianificata tenendo conto di entrambi. La scheda è davvero veloce dove il lavoro è intenso. Dove non lo è, la coda spiega il perché.
Metodo, in sintesi
Ogni cifra riportata proviene dai record dei task del nostro scheduler, non da un test preparato. Il tempo per frame è il wall-clock del task diviso per il numero di frame; lo speedup principale è una mediana delle mediane per scena sulle 38 coppie abbinate, e l'intervallo di confidenza è un bootstrap a 20,000 campioni. Si noti quale campione sostiene quale affermazione: 38 scene abbinate per lo speedup, 57 job registrati per la VRAM, e un bench controllato separato per consumo e temperature — non la coda di produzione. I 18 task falliti (su circa 4,900) vengono conteggiati come fallimenti, non esclusi; lo scheduler registra lo stato ma non la causa, quindi vengono lasciati senza indagine anziché formulare ipotesi. Nulla di questo è difficile da riprodurre nella sostanza — è ciò che qualsiasi operatore può estrarre dai propri log di coda, e siamo disponibili ad accompagnare uno studio attraverso il metodo in modo più dettagliato.
FAQ
Q: Quanto è più veloce l'RTX 5090 rispetto alla generazione precedente su Blender Cycles? A: Su 38 scene di produzione abbinate (stessa scena e stesso utente su entrambe le generazioni), il tempo mediano per frame è sceso di circa il 69% — uno speedup mediano di 3.2x, con un intervallo di confidenza bootstrap al 95% di 3.0-3.3x. Le singole scene hanno spaziato da 1.6x a 5.1x. Si tratta di dati osservazionali, da nodo a nodo, non di un benchmark controllato.
Q: Perché gli speedup variano così tanto tra le scene? A: Lo speedup segue il carico di lavoro per frame come una debole tendenza positiva (Spearman ρ ≈ 0.34). I frame brevi e vincolati dall'overhead guadagnano meno perché il costo fisso per task — caricamento della scena, sincronizzazione, il vecchio livello di virtualizzazione — è predominante; i frame più pesanti e vincolati dal calcolo guadagnano di più. Una scena pesante si è fermata a 1.6x perché il collo di bottiglia era lo storage o una fase vincolata dalla CPU, non la GPU.
Q: Si tratta di un benchmark controllato confrontabile con il proprio hardware? A: No. Questi sono appunti osservazionali da un nodo di produzione live, solo Blender Cycles. Gli utenti hanno modificato le proprie scene tra un re-render e l'altro, e il confronto è da nodo a nodo — un 5090 bare-metal contro nodi della generazione precedente virtualizzati — quindi parte del divario è dovuta alla configurazione, non al silicio. La baseline è hardware classe RTX 3080/2080, non un RTX 4090 corrente.
Q: Quanta VRAM hanno effettivamente utilizzato le scene di produzione? A: Sui 57 job Cycles registrati, la memoria di render sul dispositivo al picco era di circa 5.6 GB alla mediana e 11.5 GB al 90° percentile. Il singolo job più pesante ha registrato circa 37 GB — oltre i 32 GB della stessa 5090 — il che su una GPU significa un fallback su CPU o nessun render. La VRAM va dimensionata per la coda, non per la mediana.
Q: L'RTX 5090 ha cambiato la frequenza di utilizzo del denoising AI? A: No. Circa l'83% dei job Cycles sul nodo 5090 ha eseguito un passaggio di denoising AI (OptiX o Intel Open Image Denoise) — e la percentuale era sostanzialmente la stessa sulla generazione precedente. Il denoising AI era già standard; la nuova scheda ha solo cambiato la velocità di tutto ciò che lo circonda.
Q: Quanto è stato stabile il driver nel corso delle sette settimane? A: Un solo driver — 581.80 su CUDA 13.0 — ha operato per l'intero periodo di 51 giorni senza alcun cambio: nessun rollback, nessuna sostituzione nel mezzo del periodo. Per hardware di prima generazione su una coda di produzione, quella stabilità è di per sé un risultato significativo.
Q: Qual era il consumo e la temperatura sotto carico? A: In un bench controllato sotto carico prolungato, ciascuna scheda ha assorbito circa 360-375 W, con picco vicino a 400 W, a 68-83 °C — comodamente al di sotto della classe nominale di ~575 W della scheda. L'energia per frame è di circa 2.5 Wh, che è un'inferenza da quella misurazione da bench, calcolata per il solo 5090.
Q: Questi dati si applicano ad altri engine di rendering? A: No. Questo studio riguarda esclusivamente Blender Cycles GPU, su un singolo nodo. Altri engine registrano denoising, memoria e tempi in modo diverso. Questi vanno trattati come appunti specifici per Cycles, non come un'affermazione valida per l'intera farm o per engine diversi.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



