
Multi-GPU Scaling: What 1 vs 2 GPUs Actually Does for Rendering (2026 Benchmark)
Overview
Introduction
TL;DR: A second GPU rarely doubles render speed, and how much it helps depends entirely on the render engine. Across our 2026 benchmarks on dual RTX 5090 and RTX 4090 nodes, throughput engines (V-Ray, Octane) scaled close to 2.00x, while render-time engines scaled lower — Cycles 1.31x-1.63x, Redshift 1.68x-1.92x — because fixed per-render overhead eats into what the second card can speed up. Two GPUs is the practical per-node ceiling; a render farm's real throughput comes from running many frames across many nodes in parallel, not stacking more cards into one machine.
A second GPU does not make a render twice as fast. That sounds obvious once you say it out loud, but a lot of hardware decisions get made on the assumption that two cards mean double the speed. We pulled two of our benchmark nodes off the queue in June 2026 — one with two RTX 5090s, one with two RTX 4090s — and measured what actually happens when you go from one card to two, across four render engines and seven scene/benchmark combinations.
The short version: it depends entirely on the engine. Throughput-style benchmarks (V-Ray, Octane) scaled almost perfectly, around 2x. Render-time engines (Cycles, Redshift) scaled lower, and on the faster card the second GPU helped less, not more. We will walk through the numbers, explain why the curve bends the way it does, and — just as importantly — be clear about where this stops. Two cards is the ceiling on a single node. Going beyond that is a different architecture, not a bigger version of this one.
This is a hardware/benchmark piece, so it leans GPU-heavy. Worth saying up front that GPU is the minority of what runs across our farm — most production work here is still CPU rendering (V-Ray, Corona, Arnold on CPU). But when someone asks "is a second GPU worth it," they deserve measured numbers, not a sales pitch. So here are the measured numbers.
How We Tested (and What These Numbers Are Not)
Both test nodes ran Windows 11 Pro with two GPUs each. The 5090 node used driver 596.36; the 4090 node used driver 610.62 — a Blackwell card needs a newer driver, so an exact match was not possible. That driver gap matters for one thing only: the absolute cross-generation speed comparison between a 5090 and a 4090. The scaling ratios we focus on here are measured within a single node (same card, same driver, one GPU vs two), so the driver difference does not touch them.
Every scene is a vendor-standard benchmark — Blender's Open Data scenes (bmw27, classroom, junkshop), Maxon's "Vultures" scene for Redshift, the Chaos V-Ray Benchmark 6.00.02, and OctaneBench 2025.2.1. No customer projects, no production assets. We are not publishing per-frame minutes, dollars-per-frame, or electricity figures here, because this dataset does not contain them and we do not invent them.
One method note that affects how you read the Cycles rows: we ran Blender Cycles at 200% resolution, heavier than the Open Data default, specifically so each render lasts long enough to produce a stable, trustworthy scaling ratio. That means our raw Cycles times are not comparable to public Open Data scores — they are tuned for measuring scaling, not for leaderboard bragging. Cycles and Redshift are measured in render time (seconds, lower is better); V-Ray and Octane are measured as a benchmark score (vpaths or OctaneBench points, higher is better). Those are two different metric types, so absolute numbers never compare across engines — only the scaling ratio within an engine is apples-to-apples.
The Core Result: 1x to 2x Scaling, Per Engine
Here is the headline data — what a second identical card actually buys you, by engine and scene:
| Engine | Scene | 2x RTX 5090 scaling | 2x RTX 4090 scaling |
|---|---|---|---|
| Cycles | bmw27 | 1.54x | 1.58x |
| Cycles | classroom | 1.59x | 1.63x |
| Cycles | junkshop | 1.31x | 1.38x |
| Redshift | Vultures | 1.68x | 1.92x |
| V-Ray GPU (CUDA) | benchmark | 1.97x | 2.00x |
| V-Ray GPU (RTX) | benchmark | 2.00x | 2.00x |
| Octane | OctaneBench suite | 2.00x | 1.98x |
Read that top to bottom and a clear split appears. V-Ray and Octane land at or just under 2.00x on both cards — a second GPU very nearly doubles output. Cycles sits in the 1.31x–1.63x range. Redshift lands at 1.68x on the 5090 and 1.92x on the 4090.
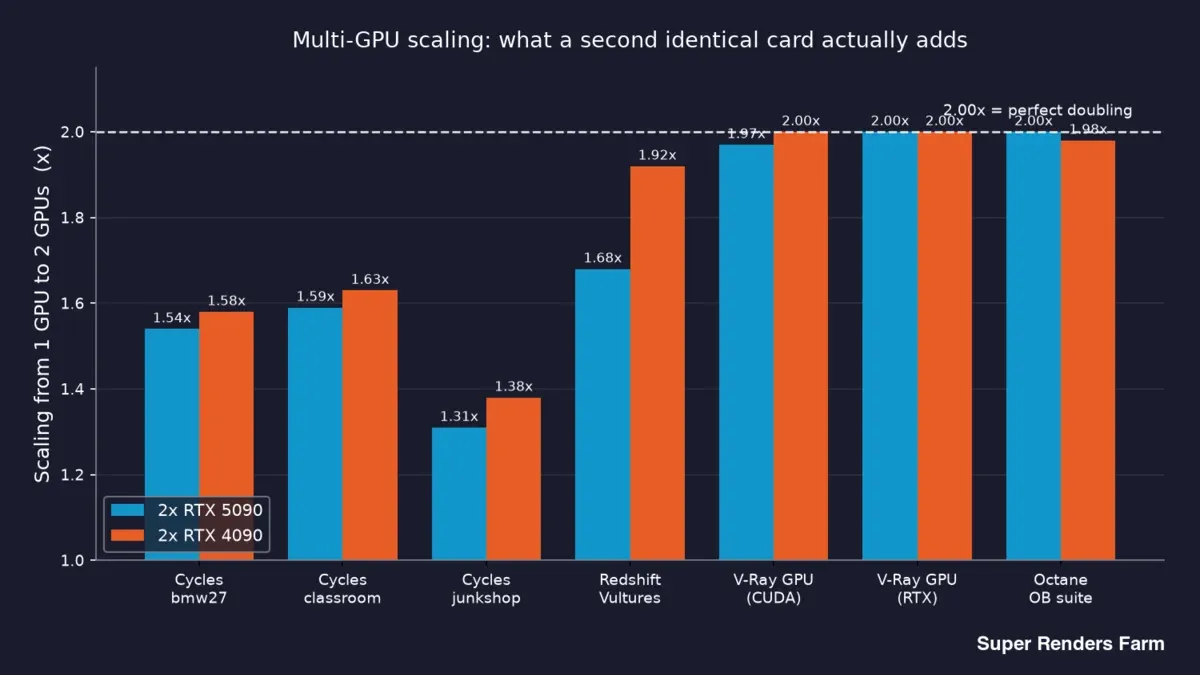
Bar chart of 1-GPU-to-2-GPU scaling by engine on dual RTX 5090 and dual RTX 4090 nodes: Cycles 1.31x to 1.63x, Redshift 1.68x versus 1.92x, V-Ray and Octane near 2.00x
So "does adding a second GPU double my speed?" has three different honest answers depending on what you render: basically yes for V-Ray and Octane, roughly a 1.5x bump for Cycles, and somewhere in between for Redshift. Anyone who tells you a single multiplier covers all of rendering has not actually measured it.
Why Throughput Engines Scale Better Than Render-Time Engines
The pattern is not random — it comes from how each benchmark spends its time. V-Ray Benchmark and OctaneBench are throughput tests. They blast a workload across whatever compute is available and report a score, and the fixed setup cost (loading the scene, building acceleration structures, initializing the device) is a tiny sliver of the total run. Add a second card and almost all of that extra silicon goes straight into useful work, so you get close to 2x. The V-Ray RTX result hitting a clean 2.00x on both cards is exactly what you would expect from a workload where overhead is essentially noise.
Render-time engines behave differently. When you measure a Cycles or Redshift render as wall-clock seconds, you are timing the whole job — and every job carries a fixed chunk of non-parallel overhead: scene parse, BVH/acceleration-structure build, kernel compilation and warm-up, device coordination, the final pixel resolve. A second GPU speeds up the part that is actually splittable across cards. It does nothing for the fixed part. The more of your total render time is fixed overhead, the further below 2x your scaling lands.
That is why Cycles junkshop (1.31x–1.38x) scales worse than Cycles classroom (1.59x–1.63x): junkshop is a lighter, shorter render, so its fixed overhead is a bigger fraction of the whole, leaving less for the second card to accelerate. The classroom scene runs longer, the parallel portion dominates, and the second GPU gets more room to help. Same engine, same hardware — the scene decides how much the second card matters.
The Counter-Intuitive Part: The Faster Card Scaled Less
Look back at the Redshift row. Two RTX 5090s scaled 1.68x. Two RTX 4090s scaled 1.92x. The newer, faster card scaled worse. That looks like an error. It is not — it is the most instructive number in the whole set.
Here is the mechanism. The 5090 is the faster card in absolute terms; on a single GPU it finishes the Vultures scene in about 57 seconds versus the 4090's 100 seconds. But that fixed per-render overhead — parse, build, warm-up — is roughly the same number of seconds regardless of which card runs it. On the 4090, that fixed slice is a small fraction of a long 100-second render, so the second card has a big parallel portion to chew through and scaling lands near 1.92x. On the 5090, the render is already short, so that same fixed slice is a larger fraction of the total, leaving a smaller parallel portion for the second card to accelerate — and scaling comes in at 1.68x.
Critically, this does not mean the 5090 is worse. It is faster on one card and faster on two cards. It simply gains proportionally less from the second GPU because it had less slow-render to speed up in the first place. The faster your base render, the harder it is for a second card to deliver a clean 2x — there is just less time left to parallelize. That is a genuinely useful thing to understand before you spend money stacking identical cards expecting linear returns.
Per-Card Speed: RTX 5090 vs RTX 4090
Scaling is one axis; raw per-card speed is the other. On a single card, with the driver caveat from the method section applied, the 5090 came out ahead across every engine we tested:
| Engine | Metric | RTX 5090 | RTX 4090 | 5090 advantage |
|---|---|---|---|---|
| Cycles — bmw27 | seconds (lower better) | 49.45 | 77.40 | 1.57x |
| Cycles — classroom | seconds | 23.09 | 36.87 | 1.60x |
| Cycles — junkshop | seconds | 19.71 | 34.43 | 1.75x |
| Redshift — Vultures | seconds | 57 | 100 | 1.75x |
| V-Ray GPU (CUDA) | vpaths (higher better) | 11,051 | 7,419 | 1.49x |
| V-Ray GPU (RTX) | vpaths | 15,333 | 9,608 | 1.60x |
| Octane | OctaneBench score | 1,690.78 | 1,074.17 | 1.57x |
Across the board the 5090 lands roughly 1.5x to 1.75x faster per card. Two takeaways for anyone planning hardware. First, generational per-card gains (1.5x–1.75x here) are larger and more reliable than the gain from adding a same-generation second card on a render-time engine (often well under 2x). In plain terms: a faster card is frequently a better lever than a second card. Second, these single-card cross-generation numbers carry the driver-mismatch caveat — treat them as a directional comparison, not a service-level guarantee. We measure on benchmark scenes; your scene complexity, sampling, and output resolution will move the real-world figure. For more on single-card 5090 behavior, see our RTX 5090 GPU cloud rendering performance write-up.
Two GPUs Is the Per-Node Ceiling — and Why That Is Fine
Here is where we draw a hard line, because it is the part most multi-GPU content quietly skips. Every node in this benchmark is a two-GPU node. Two cards is the per-node ceiling. We are not going to show you a 4x or 8x single-node scaling curve, because that is not a configuration we run, and we are not going to imply otherwise.
Pushing past two GPUs on a single frame means multi-node distributed rendering — splitting one image across several machines, with all the network coordination, bucket/tile management, and overhead that implies. That is a genuinely separate architecture, not a bigger version of a two-card box. It is not something we offer today for a single frame, so we are not going to dangle it as a "coming soon" feature with a date attached.
And here is the thing: for the overwhelming majority of production work, the two-GPU ceiling is not the constraint that matters. The constraint that bites first is almost always VRAM, not card count — a scene that does not fit in 32 GB will not render regardless of how many GPUs you point at it, which is a different problem entirely (we cover it in RTX 5090 VRAM limits for complex scenes). When people picture "scaling up a render farm," they usually imagine one giant render getting faster on more and more silicon. That is not how throughput at farm scale actually works.
How a Render Farm Actually Scales: Frames, Not Cards
This is the distinction worth internalizing, and it is the one the benchmark numbers above keep gesturing at. There are two completely different things people mean by "render faster on more hardware":
- Splitting one frame across many GPUs or machines (tile/bucket distributed rendering). This is what the 1x→2x numbers measure at the two-card scale, and what multi-node distributed rendering would extend. It hits diminishing returns fast on render-time engines, as the data shows, because of fixed per-render overhead — and the coordination cost only grows as you add machines.
- Spreading many frames across many machines (frame-parallel rendering). Each node renders a whole frame on its own; an animation's frames are handed out across the fleet in parallel. There is no single-frame coordination overhead to fight, so this scales cleanly and is how an animation gets turned around fast.
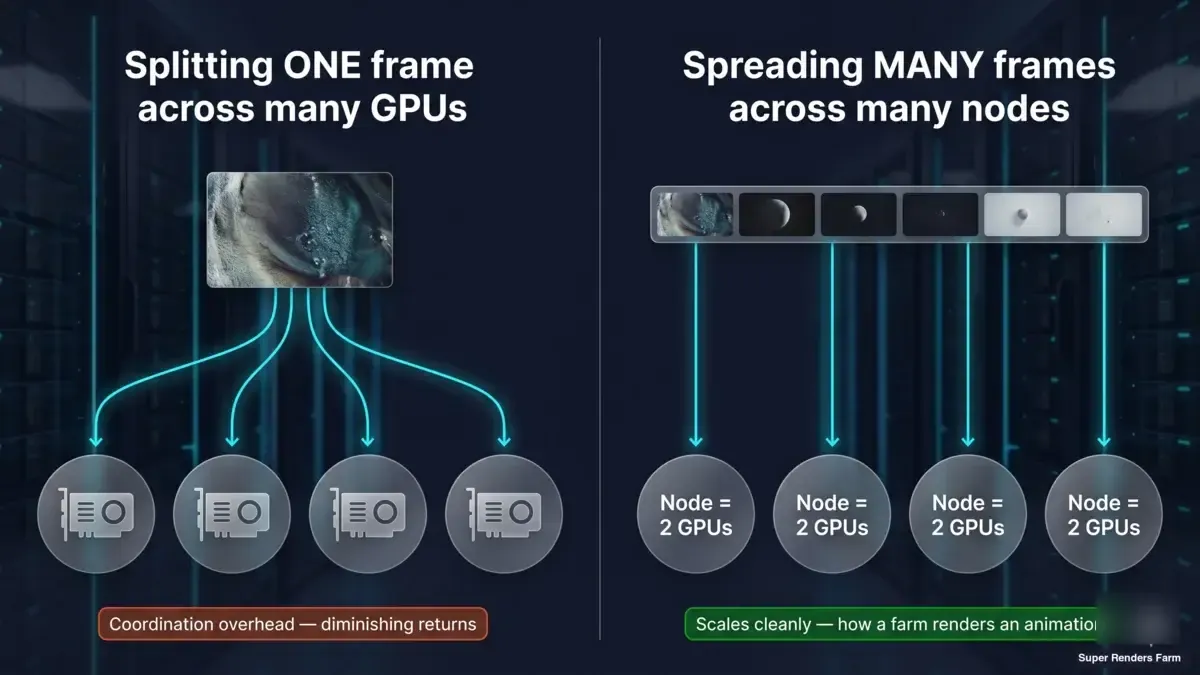
Two-panel concept diagram: one frame split across several GPUs hits coordination overhead and diminishing returns; many whole frames each on their own two-GPU node in parallel scales cleanly, how a render farm scales an animation
A managed render farm gets its speed almost entirely from the second model. Your 500-frame animation does not get rendered as one frame smeared across 500 GPUs — it gets rendered as 500 frames distributed across the fleet, each on its own node, all at once. The per-node, per-frame speed is set by the kind of two-GPU scaling and per-card performance we benchmarked here; the farm-level speed comes from how many frames run concurrently. They are different levers, and conflating them is where a lot of "how many GPUs do I need" confusion starts.
So the honest framing of multi-GPU is narrower than the marketing version. Two cards per node gives you a real, measurable boost — close to 2x on V-Ray and Octane, more modest on Cycles and Redshift. Beyond that, the answer is not "stack more cards in the box," it is "run more frames across more nodes." That is the architecture, and being straight about it tends to save people money they were about to spend on hardware that would not have paid off the way they assumed.
What This Means When You Choose How to Render
Pulling it together into something you can act on. If you are deciding between one card and two for a workstation, the engine you live in should drive the call: V-Ray or Octane users get close to a full doubling and the second card is easy to justify; Cycles and Redshift users should expect a 1.3x–1.9x bump and weigh whether a faster single card (the 1.5x–1.75x generational gain) is the better spend. If you are deciding whether to render locally or hand work to a farm, remember the farm advantage is frame-parallel throughput on an animation, not a magic single-frame multiplier — a single hero still-frame will not render dramatically faster on a farm than on a comparable workstation, but a few hundred frames absolutely will.
For context on the managed-vs-do-it-yourself tradeoff — who handles drivers, licensing, and node configuration — our fully managed vs DIY render farm breakdown covers it. On our farm, render-engine licensing (V-Ray, Redshift, Octane) is included in the rendering rate and the node configuration is fixed and maintained for you, so the two-GPU-per-node setup and the drivers behind these numbers are not something you assemble or tune yourself. For the Redshift-on-Cinema-4D side specifically, where the 1.68x scaling figure lands, see our Redshift render farm for Cinema 4D guide.
The measurements here are deliberately un-hyped. A second GPU is a real lever with real limits, the faster card scales less because it had less slow-render to speed up, and farm-scale speed is a frame-distribution story, not a card-stacking one. Knowing which lever applies to your workload is most of the decision.
If you're pricing out a job from these multipliers, check current render farm pricing or read the cost-per-frame benchmarking methodology behind these numbers. For the CPU side of hardware comparison, see our Cinebench scores for cloud rendering or the V-Ray Benchmark guide.
FAQ
Q: Does adding a second GPU double rendering speed? A: Not usually. In our 2026 benchmarks, throughput engines like V-Ray and Octane scaled close to 2.00x with a second identical card, but render-time engines scaled lower — Cycles landed between 1.31x and 1.63x and Redshift hit 1.68x on dual RTX 5090s. The gain depends entirely on the engine and the scene, because every render carries fixed overhead that a second card cannot speed up.
Q: Why does Redshift scale better on the RTX 4090 than the RTX 5090? A: Because the 5090 is faster, its renders are shorter, so the fixed per-render overhead (scene parse, acceleration-structure build, kernel warm-up) is a larger fraction of the total. That leaves a smaller parallel portion for the second card to accelerate, so scaling comes in at 1.68x on the 5090 versus 1.92x on the 4090. The 5090 is still faster on both one and two cards — it simply gains proportionally less from the second GPU.
Q: How much faster is the RTX 5090 than the RTX 4090 for rendering? A: Roughly 1.5x to 1.75x faster per card across the engines we tested, including Cycles, Redshift, V-Ray GPU, and Octane. These single-card cross-generation figures carry a minor caveat because the two cards ran different NVIDIA drivers, so treat them as a directional comparison rather than a fixed guarantee.
Q: Why do V-Ray and Octane scale better than Cycles and Redshift across two GPUs? A: V-Ray Benchmark and OctaneBench are throughput tests where the fixed setup cost is a tiny fraction of the run, so a second card goes almost entirely into useful work and scaling approaches 2.00x. Cycles and Redshift are measured as total render time, which includes non-parallel overhead a second card cannot accelerate, so their scaling lands below 2x.
Q: Can a render farm make a single frame render faster on many machines? A: Splitting one frame across multiple machines is multi-node distributed rendering, which is a separate architecture with its own coordination overhead and is not something we offer today for a single frame. A managed farm gets its speed from frame-parallel rendering instead — many whole frames distributed across many nodes at once — so an animation finishes fast while a single hero frame renders at roughly per-node speed.
Q: How many GPUs do I actually need for rendering? A: For a single node, two GPUs is a sensible ceiling and is what our benchmark nodes use; beyond that the practical constraint is usually VRAM, not card count, since a scene that does not fit in memory will not render no matter how many cards you add. If you render animations, real throughput comes from running more frames across more nodes rather than stacking more cards into one machine.
Q: Are these benchmark numbers comparable to public Blender Open Data scores? A: No. We ran Blender Cycles at 200% resolution, heavier than the Open Data default, so each render lasts long enough to produce a stable scaling ratio. That makes our raw Cycles times intentionally non-comparable to public Open Data leaderboards — the scenes were tuned for measuring scaling, not for matching standard scores.
Q: Do I need to manage GPU drivers and licenses to use a managed render farm? A: No. On a fully managed farm, node configuration, drivers, and render-engine licensing (V-Ray, Redshift, Octane) are handled for you and included in the rendering rate, so the two-GPU node setup and the drivers behind these benchmarks are not something you assemble or tune. Cycles is free and open-source, so it carries no separate license.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



