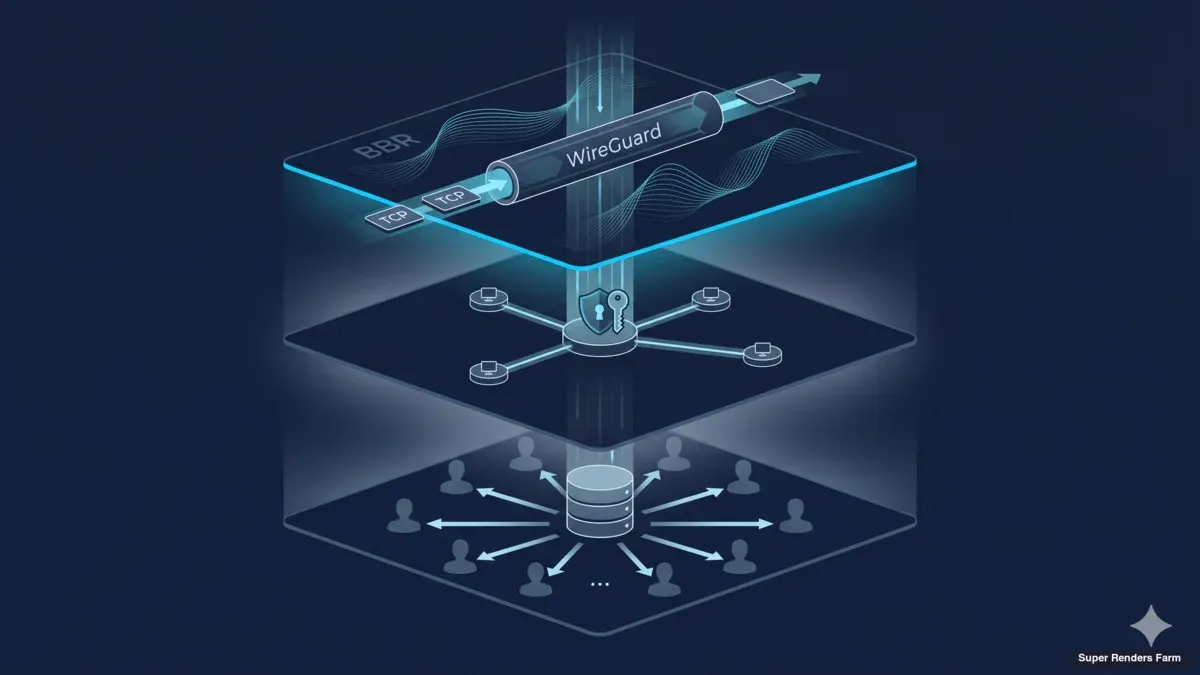
크로스컨트리 렌더팜 아키텍처: WireGuard, BBR, 공유 SMB 캐시 설계
개요
들어가며
하나의 랙, 하나의 방, 하나의 스위치 안에 있는 렌더팜을 구축하는 것은 이미 해결된 문제예요. 케이블은 짧고, 왕복 시간은 마이크로초 단위로 측정되며, 에셋 라이브러리는 모든 워커가 스위치 포트 속도로 읽을 수 있는 NAS 위에 자리해요. 대부분의 렌더팜 가이드는 이 토폴로지를 조용히 전제로 삼아요. 모든 것이 그냥 잘 돌아가는 형태이기 때문이에요.
팜이 둘 이상의 사이트에 걸쳐야 할 때 아키텍처는 달라져요. 같은 메트로폴리탄 지역의 두 위치에 분할된 20노드 클러스터는 이미 다른 네트워크 문제이고, 국가를 가로지르는 클러스터는 또 다른 문제예요. 왕복 시간은 1ms 이하에서 수십에서 수백 ms로 늘어나고, 공용 ISP 경로의 지터는 끊임없는 배경 잡음이 되며, 임의의 두 엔드포인트 사이의 MTU는 가정이 아니라 질문이 되고, 하나의 NAS에 있던 에셋 라이브러리는 이제 각 사이트로 복제되거나 요청 시 캐시되어야 해요. 단순한 접근 방식 — 같은 NAS, 같은 서브미션 큐, 같은 SMB 공유, 단지 더 긴 케이블 — 은 조용한 실패 모드로 나타나요. 연결은 유지되지만 프레임을 전송하지 않는 세션, 원격 노드로의 최종 에셋 푸시가 타임아웃되어 99%에서 멈춘 렌더 서브미션, 로컬에서는 성공하지만 원격에서는 명확한 이유 없이 실패하는 라이선스 체크아웃 등이에요.
이 글은 크로스컨트리 렌더팜 배포를 위해 우리가 운영하는 아키텍처를 설명해요 — WireGuard 허브앤스포크 토폴로지, TCP BBR 혼잡 제어, MSS 클램핑 원칙, 공유 SMB3 캐시 계층, 하드닝된 방화벽 표면. 구성 요소는 일반적이고, 구성 선택은 항상 자명하지 않으며, 배운 교훈은 대부분 누군가에게 돈을 잃게 하기 전에 디버깅 시간을 비용으로 치렀어요. 대상 독자는 비슷한 빌드의 규모를 산정하는 인프라 아키텍트와 DevOps 엔지니어, 그리고 자기 팀이 무엇에 발을 들이는지 알고 싶은 IT 의사결정자예요. 같은 스택의 단계별 운영 가이드는 저희 operational deployment guide가 일별 롤아웃 순서를 다뤄요. 상위 개요는 cross-country render farm overview 페이지가 비즈니스 케이스를 다뤄요.
WireGuard 허브앤스포크 토폴로지

두 원거리 사이트를 연결하는 암호화된 터널
클러스터의 전송 계층은 WireGuard예요. 클라이언트 연결(아티스트의 워크스테이션에서 팜으로)과 메인 데이터센터와 보조 사이트 간 사이트 대 사이트 연결 양쪽 모두에 사용해요. 토폴로지는 허브앤스포크예요. 하나의 WireGuard 서버가 메인 데이터센터 게이트웨이에서 동작하고, 모든 클라이언트 피어는 이 허브에 연결되며, 보조 사이트는 라우팅된 서브넷을 뒤에 둔 또 다른 피어로 연결돼요.
이런 종류의 빌드에서 WireGuard의 매력은 대체로 기계적이에요. 프로토콜은 고정된 모던 암호화(키 교환에 Curve25519, 데이터 평면에 ChaCha20-Poly1305, 해싱에 BLAKE2s)를 사용하고, 유저스페이스가 아닌 Linux 커널에서 동작하며, 한 화면에 들어가는 키와 AllowedIPs 파일로 구성돼요. OpenVPN에 비하면 구성 표면은 약 한 자릿수 작고, 같은 CPU 비용에서 일반적인 Xeon 노드의 처리량은 몇 배 높으며, 코드베이스는 감사가 가능할 만큼 작아요. IPsec에 비하면 흥미로운 방식으로 실패할 수 있는 IKE 협상 단계가 없고, 리키 시 피어 신원 춤이 없고, 크래시할 수 있는 유저스페이스 데몬이 없어요. 과거 배포에서 세 가지 모두 운영해 본 적이 있는데, 개입 없이 유지되는 구성은 WireGuard 것들이에요.
허브앤스포크 배치는 모든 사이트 간 흐름이 메인 데이터센터 게이트웨이를 통과한다는 뜻이에요. 두 사이트의 크로스컨트리 배포에서는 올바른 트레이드오프예요. 공용 IP 공격 표면을 한 박스에 집중시키고, 단일 라우팅과 방화벽 규칙 세트를 한 병목 지점에 적용하며, 모든 핸드셰이크와 플로우 카운터가 허브에서 보이기 때문에 모니터링을 단순하게 만들어요. 풀 메시는 사이트 간 트래픽에서 한 홉을 절약하지만 구성 작업과 공용 공격 표면을 사이트 수의 제곱으로 곱해요. 두 개 또는 세 개의 사이트에서는 허브앤스포크가 운영적 단순함에서 이겨요.
허브는 UDP 51820 포트(기본값)에서 수신하고, 이것이 공용 인터페이스가 받아들이는 유일한 포트예요. TCP 폴백은 없어요. UDP 전용은 의도적인 선택이에요 — WireGuard의 혼잡 동작은 UDP 데이터그램을 중심으로 구축되어 있고, TCP-위-TCP 터널은 장거리 처리량을 신뢰성 있게 떨어뜨려요. UDP를 완전히 차단하는 네트워크에서는 이를 고객 측 제약으로 다루고 다른 계층에서 우회해요.
각 클라이언트 피어는 클러스터의 내부 서브넷을 포괄하는 단일 AllowedIPs 항목으로 구성돼요. 사이트 대 사이트 피어는 커널이 어떤 패킷을 캡슐화해야 하는지 알 수 있도록 원격 LAN 서브넷을 포괄하는 AllowedIPs를 가져요. PersistentKeepalive는 NAT 뒤의 모든 피어에서 25초로 설정되며, 이는 핸드셰이크 사이 UDP conntrack 항목을 살아 있게 유지해요. 정확히 한 번 이를 생략했고, 그 후 이틀을 "보조 사이트에서 90초마다 연결이 끊깁니다" 디버깅으로 보냈어요. 세 번째 사이트에서는 PersistentKeepalive가 구성 파일의 첫 번째 줄이었어요.
TCP BBR 혼잡 제어
WireGuard 터널이 올라가면 다음 계층은 TCP 동작이에요. Linux는 기본 혼잡 제어 알고리즘으로 CUBIC을 제공해요. CUBIC은 마지막 손실 이벤트 이후 시간의 함수로 혼잡 윈도를 3차 곡선으로 스케일링하는데, 패킷 손실이 혼잡의 신뢰할 수 있는 신호인 링크에서 잘 작동해요. 함정은 "신뢰할 수 있는"이라는 말에 있어요. 장거리 ISP 경로에서 패킷 손실은 종종 혼잡이 전혀 아니에요 — 중간 라우터의 큐 오버플로우, TCP에 보이지 않게 재전송하는 무선 링크, 잘못 구성된 레이트 리미터, 또는 짧은 라우팅 트랜지언트예요. CUBIC은 이 모든 것을 혼잡으로 다루고 병목에 용량이 많이 남아 있어도 윈도를 붕괴시켜요.
BBR(Bottleneck Bandwidth and Round-trip propagation time)은 크로스컨트리 링크에서 우리가 사용하는 대안이에요. BBR은 패킷 손실을 주요 혼잡 신호로 무시하고 대신 경로의 병목 대역폭과 최소 왕복 시간을 직접 측정해요. 그런 다음 발신자를 병목 속도로 페이싱하며, 윈도 크기는 정확히 하나의 대역폭-지연 곱의 데이터가 비행 중이 되도록 해요. 롱 팻 네트워크 — 높은 대역폭, 높은 RTT, 적당한 임의 손실 — 에서 BBR은 파이프를 가득 유지하지만, CUBIC은 혼잡이 아닌 손실에 대해 윈도를 반복적으로 절반으로 줄여요.
렌더팜에서의 실제 효과는 측정 가능해요. 동일한 하드웨어에서 크로스컨트리 터널을 통한 에셋 전송은 CUBIC에서 잦은 정체와 들쭉날쭉한 처리량에서 BBR에서 경로의 실제 용량에 가까운 더 부드러운 처리량 곡선으로 바뀌어요. 헤드라인 숫자는 ISP 경로와 시간대에 따라 달라지지만, 클러스터 발신 측을 BBR로 전환하면 우리가 운영하는 경로에서 일관되게 더 높은 안정 상태 처리량과 더 짧은 테일 레이턴시를 보여줬어요.
Linux 커널 메인라인 4.9 버전부터 들어있는 BBR 구현을 사용해요. 한 줄의 sysctl로 활성화돼요. net.core.default_qdisc=fq 더하기 net.ipv4.tcp_congestion_control=bbr. 두 줄 모두 /etc/sysctl.d/99-bbr.conf에 들어가고 재부팅 후에도 유지돼요. 메인라인 커널 BBR이 수년간 프로덕션에서 운영해 온 버전이에요. 알고리즘의 더 새로운 연구 분기가 존재하지만 우리의 특정 ISP 경로에서 검증할 시간이 없었던 동작 변경을 도입해요. 업그레이드 경로는 별도의 로드맵 항목이에요.
BBR은 큰 흐름의 발신 측에 설정해요 — 에셋 전송을 위한 캐시 박스와 렌더 매니저, 라이선스 콜백과 로그 시핑 같은 역방향 흐름을 위한 수신 측. 한쪽 끝의 BBR로도 대부분의 이점을 볼 수 있고, 양쪽 끝의 BBR은 양방향 흐름에서 조금 더 도움이 돼요.
TCP MSS 클램핑
WireGuard 터널이 올라온 후 나타나는 모든 네트워크 문제 중 가장 많은 디버깅 시간을 잡아먹은 것이 MTU예요. 증상은 일관되고 혼란스러워요. 작은 패킷은 깨끗하게 통과하고(기본 크기에서 ping 작동, SSH 문자 에코, WireGuard 핸드셰이크 완료), 큰 패킷은 터널 안으로 사라지고 결코 나오지 않아요. TLS 핸드셰이크는 중간에 멈춰요. SMB 세션은 연결되지만 첫 번째 큰 read에서 실패해요. RDP 세션은 설정되고 로그인 화면을 표시한 다음 사용자가 무언가를 입력하는 순간 얼어버려요. 라이선스 서버는 작은 토큰은 체크아웃하지만 큰 것에서는 타임아웃돼요.
원인은 WireGuard 터널의 캡슐화 오버헤드가 엔드포인트가 LAN 인터페이스를 기반으로 협상하는 경로 MTU 아래로 유효 MTU를 줄이는 거예요. WireGuard는 모든 패킷에 60바이트 오버헤드(20 IPv4 + 8 UDP + 32 WireGuard)를 더해요. LAN 측의 1500바이트 페이로드는 공용 측에서 1560바이트 패킷이 되고, 경로에 따라 단편화되거나 폐기돼요. Path MTU Discovery(PMTUD)는 발신자에게 ICMP "Fragmentation Needed"를 돌려보내 이를 수정해야 하지만, PMTUD는 현대 인터넷에서 일상적으로 깨져요 — ICMP는 종종 발신자의 상류에서 필터링되어 "더 작은 패킷을 사용하라"는 신호가 결코 도착하지 않고, 터널은 큰 패킷을 조용히 폐기해요.
해결책은 TCP MSS(Maximum Segment Size) 클램핑이에요. 라우터 측 WireGuard 인터페이스를 구성하여 터널을 가로지르는 모든 TCP SYN의 MSS 옵션을 다시 쓰고, 터널의 유효 MTU에서 TCP/IP 오버헤드를 뺀 값으로 제한해요. 1420바이트 터널 MTU(대부분의 상류 변동을 견디는 안전한 선택)에서 MSS 클램프는 1380이에요. 규칙이 들어간 후 시작하는 모든 TCP 연결은 1380바이트 MSS를 협상하고, 발신자는 깨끗하게 통과하는 1420바이트 패킷을 보내며, 조용한 폐기는 멈춰요.
클램프는 라우터 모드 WireGuard 호스트의 FORWARD 체인에서 wg0 인터페이스에 TCP 핸드셰이크 패킷에 적용돼요. iptables 관용구는 iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu(또는 고정 값에 --set-mss 1380)예요. nftables에 동등한 것이 있어요. 양쪽 모두 TCP 연결을 시작하면 규칙은 양방향으로 적용되어야 하는데, 렌더팜에서는 흔한 경우예요.
큰 무언가가 실패할 때까지 MSS 클램프가 빠졌다는 것을 느낄 방법이 없어요 — 작은 워크로드는 깨끗하게 테스트돼요. 클램프는 올바르게 적용하면 비용이 들지 않고 생략하면 혼란스러운 디버깅 시간을 만들어내는 구성 중 하나예요. 새벽 6시 "SMB 전송이 임의의 크기에서 멈춤" 지원 티켓이 오전 8시에 한 줄의 iptables 규칙으로 해결된 후 표준 배포 체크리스트에 넣었어요.
공유 SMB3 캐시 설계

렌더 워커에 에셋을 로컬로 제공하는 공유 캐시
렌더 워크로드는 에셋이 무겁고 읽기 우세예요. 일반적인 씬은 수백 메가바이트에서 수십 기가바이트까지 — 지오메트리, 텍스처, 시뮬레이션 캐시, 렌더링 DCC의 프로젝트 파일이에요. 20노드 클러스터 전체에서 같은 씬은 프레임을 가져가는 모든 워커가 읽을 수 있어야 해요. 순진한 접근은 렌더가 시작되기 전에 씬을 모든 노드에 복사하는 거예요. 10GB 씬과 20노드의 경우, 이는 10GB 워킹 셋을 위해 네트워크를 통해 200GB를 이동해요. 스튜디오당 하루 수십 개 씬을 곱하면 중복 비용이 빌드를 지배해요.
대신 사용하는 아키텍처는 사이트당 단일 공유 캐시 계층으로, 렌더 워커에 SMB3로 노출돼요. 캐시는 ext4 형식의 단일 SSD(NVMe 클래스)를 가진 Ubuntu 22.04 LTS 박스 하나이고, 캐시 디렉토리는 Samba를 통해 SMB3로 노출돼요. 각 렌더 워커는 부팅 시 cifs-utils를 통해 SMB 공유를 마운트하고 캐시에서 에셋 파일을 로컬인 것처럼 읽어요. 특정 에셋이 필요한 첫 번째 워커는 상류 클라우드 에셋 스토어에서 캐시로의 풀을 트리거하고, 후속 워커와 후속 프레임은 스위치 포트 속도로 LAN 캐시에서 읽어요. 사이트당 캐시 박스는 모든 워커에서 한 스위치 홉 거리에 있어요. 에셋은 클러스터에 한 번 도달하고 스무 명의 워커를 서비스해요.
몇 가지 설계 선택을 풀어볼 가치가 있어요. 캐시는 RAID 어레이가 아닌 단일 SSD인데, 캐시가 정의상 상류 클라우드 에셋 스토어로부터 재구축 가능하기 때문이에요. SSD가 고장 나면 최악의 경우는 다음 에셋 요청이 클라우드에서 풀하는 동안의 지연과 캐시되지 않은 중간 파일에 의존하던 진행 중인 렌더의 재구축이에요. 각 작업 종료 시 캐시에서 NAS로 완료된 렌더 출력을 rsync하여 "진행 중인 렌더" 위험을 완화하므로, SSD 고장이 이미 전달된 어떤 deliverable도 잃지 않아요. RAID를 건너뛰면 하드웨어 비용, 컨트롤러 복잡성, 일부 RAID 레벨이 SSD에 부과하는 쓰기 증폭 오버헤드를 절약해요.
파일 시스템은 ZFS나 btrfs가 아닌 ext4예요. 과거 빌드에서 ZFS와 btrfs를 모두 사용했고, 그것들이 가져오는 기능 세트(스냅샷, 체크섬, 압축)는 일부 워크플로에서 실제 이점이에요. 렌더 캐시의 경우 읽기 패턴은 트랜잭션 중심이 아니라 주로 순차적이고 대역폭 제한적이며, 캐시 내용은 설계상 폐기 가능해요. ext4는 스토리지 스택을 단순하게 유지하고 사고 사후 검토 세트에서 한 부류의 실패 모드를 제거해요. 이미 ZFS를 대규모로 운영하는 운영자는 여기서도 절대 사용할 수 있지만, 캐시 계층 단순성이 개별 기능 이점보다 더 중요한 배포에는 ext4가 선택이에요.
프리워밍 전략이 중요해요. 마감 기한이 있는 작업이 시작되기 전에 아티스트나 파이프라인 TD는 프리스테이징 도구를 통해 씬의 에셋을 캐시로 푸시해요. 그러면 워커에 떨어지는 첫 번째 프레임은 콜드 풀을 기다리는 대신 따뜻한 캐시에서 읽어요. 프리워밍 단계는 밤새 실행되는 작업에는 선택 사항이고(콜드 풀이 괜찮음) 제한된 창에서 완료해야 하는 작업에는 중요해요.
크로스사이트 캐시 공유는 WireGuard 사이트 대 사이트 터널을 통해 작동해요. 보조 사이트는 자체 캐시 박스와 워커를 가지지만, 캐시는 거기서 따뜻하고 로컬에서 아직 따뜻하지 않은 모든 에셋에 대해 터널을 통해 기본 사이트의 캐시에도 도달할 수 있어요. 실제로 미스 시 상류 클라우드에 가기 전에 기본 캐시로 폴백하도록 보조 캐시를 구성해요 — 이는 사이트 간 트래픽을 암호화된 터널에 유지하고 이미 팜 안에 있는 에셋에 대한 클라우드 이그레스 비용을 피해요. 이것이 올바른 MSS 클램프의 실제 이점 중 하나예요. 사이트 간 큰 에셋 전송은 작은 패킷 천장에서 정체되는 대신 터널을 포화시키는 처리량으로 이동해요.
내부 서비스: DNS와 NTP
클러스터는 자체 호스트네임을 알아야 해요. 순진한 선택은 모든 노드의 /etc/hosts에 모든 호스트를 넣는 것인데, 두 노드에서는 작동하고 스무 노드에서는 실패하기 시작해요. 올바른 선택은 내부 DNS이고, WireGuard를 실행하는 같은 게이트웨이 박스에서 dnsmasq를 운영해요. 클러스터는 .lan 존에 있어요 — cache.lan, rn-a01.lan에서 rn-a20.lan, mgr.lan, nas.lan. 각 이름은 클러스터 서브넷의 해당 내부 IP로 해석되고, 각 워커의 /etc/resolv.conf는 dnsmasq 서버를 가리켜요.
이점은 모든 IP 재할당, 호스트 교체, 토폴로지 변경이 모든 노드를 만지는 대신 하나의 구성 파일(dnsmasq 호스트 파일)을 만지는 것이 필요하다는 거예요. 이점은 사이트 대 사이트 터널 너머로 확장돼요. 보조 사이트의 워커는 로컬 dnsmasq를 통해 cache.lan을 보조 캐시로 해석할 수 있고, 터널을 통한 DNS 포워딩으로 mgr.lan을 기본 사이트의 렌더 매니저로 해석할 수 있어요. 과거에 렌더 매니저 구성에 IP 리터럴을 사용했고 노드가 이동할 때마다 후회했어요.
저희를 물고 — 자체 단락을 받을 만큼 충분한 운영자를 물고 — 있는 dnsmasq 함정은 interface= 줄이에요. dnsmasq는 기본적으로 모든 인터페이스에서 수신하는데, 이는 게이트웨이 박스에 최소 세 개가 있다는 것을 깨달을 때까지는 괜찮아 보여요. 공용 WAN, 내부 LAN, WireGuard 터널 wg0. dnsmasq를 LAN으로 제한한다고 생각하며 interface=eth1을 설정하면, wg0가 나열되지 않았기 때문에 WireGuard로 연결된 보조 사이트가 어떤 .lan 이름도 해석할 수 없게 만든 거예요. 올바른 줄은 interface=eth1,wg0(또는 인터페이스 이름의 등가물) 또는 WAN만 명명하는 except-interface= 줄이에요. 이 잘못된 구성이 "원격 사이트가 IP로 캐시를 핑할 수 있지만 호스트네임으로 SMB 마운트할 수 없음" 증상을 한 번 이상 만들어내는 것을 봤어요.
NTP는 다른 내부 서비스예요. 게이트웨이에서 NTP 서버로 chrony를 운영해요. 게이트웨이 자체는 공용 NTP 풀에 동기화되고 모든 노드는 게이트웨이에 동기화돼요. 동기는 렌더 매니저 로그 상관관계예요. 프레임이 실패하면 렌더 매니저의 로그 항목과 워커의 로그 항목은 밀리초 이내의 타임라인을 공유해야 해요. 특히 노드가 몇 주 동안 켜져 있을 때 20노드 클러스터의 클록 드리프트는 "이 로그 항목이 잘 맞지 않는다" 디버깅 혼란의 실제 원인이 돼요. chrony는 드리프트를 몇 밀리초 이하로 유지하고 그 부류의 혼란을 제거해요.
방화벽: default-deny inbound인 ufw
게이트웨이는 공용 인터넷에 있고, 방화벽 자세는 "default-deny inbound, default-allow outbound, 터널 트래픽에 대한 default-allow forward"예요. Ubuntu 22.04 LTS에서 사용하는 도구는 ufw — Uncomplicated Firewall이에요. ufw는 작은 명령 표면을 노출하고 놀라운 일을 하기를 거부하는 nftables(또는 이전 시스템의 iptables) 위의 프론트엔드예요. 방화벽 구성이 "안전한"과 "시간 내에 손상된" 사이의 차이인 게이트웨이 박스에 대해 작은 명령 표면은 기능이에요.
구성된 공용 표면은 하나의 규칙이에요. ufw allow 51820/udp comment 'wireguard'. 인바운드의 다른 어떤 것도 없어요. 공용 측의 SSH는 닫혀 있어요. WireGuard 터널을 통해 알려진 운영자 IP에서 게이트웨이를 관리해요. SMB, DNS, NTP, HTTPS(렌더 매니저 UI용)는 모두 내부 인터페이스에만 있어요. ufw default deny incoming과 ufw default allow outgoing 설정이 나머지 표면을 다뤄요.
포워드 체인은 주의가 필요해요. 게이트웨이는 wg0와 내부 LAN 사이의 클러스터 트래픽을 위한 라우터로 작동하고, ufw의 기본 자세는 포워드를 거부하는 거예요. /etc/default/ufw에 DEFAULT_FORWARD_POLICY="ACCEPT"를 설정한 다음 FORWARD 체인의 특정 source/destination 쌍에 포워드 규칙을 좁혀요. 조합 — default-deny incoming, 부팅 시 default-deny forward, 그런 다음 알려진 클러스터 서브넷 간 명시적 포워드 ACCEPT — 는 감사 가능한 자세를 제공하고 대화해서는 안 되는 사이트 간에 우발적으로 트래픽을 라우팅하지 않아요.
노드별 호스트 방화벽은 이 Tier-1 게이트웨이 계층을 Tier-2 호스트 계층으로 확장해요. 각 렌더 노드는 클러스터의 렌더 매니저와 캐시 박스만 연결을 시작할 수 있는 규칙으로 로컬에서 ufw를 실행해요. 손상된 워커는 호스트 방화벽을 먼저 물리치지 않고는 다른 워커로 피벗할 수 없고, 게이트웨이는 모든 예기치 않은 포워드 시도를 기록해요. 2계층 모델 — 게이트웨이 Tier 1, 호스트별 Tier 2 — 은 어떤 합리적인 온프레미스 클러스터도 운영하는 것과 동일해요. 크로스컨트리 배포에서 변경되는 것은 Tier 1 표면이 이제 공용 인터넷에 대해 방어해야 한다는 거예요. 게이트웨이는 경계, 호스트별 방화벽은 심층 방어예요.
아키텍처 다이어그램

허브앤스포크 렌더팜 토폴로지, 인터넷으로의 단일 보안 터널
위의 텍스트 설명은 배포 킥오프 동안 화이트보드에 그리는 것과 같은 다음 ASCII 다이어그램에 매핑돼요.
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
다이어그램은 의도적으로 일반적이에요 — 특정 도시 쌍, 특정 ISP, 특정 서브넷 번호 없음. 배포하는 모든 사이트는 동일한 형태를 따르고, 숫자가 달라요.
성능 특성
처리량 숫자는 ISP 경로와 시간대에 따라 달라지지만, 성능의 형태는 우리가 운영한 배포에서 일관돼요. 같은 메트로의 두 사이트 간 터널(10ms 미만 RTT)에서 큰 전송은 병목 링크의 라인 속도에 가깝게 이동하고, 캐시에서 읽는 렌더 워커는 로컬 디스크에서 읽는 워커와 구별되지 않게 느껴져요. 서로 다른 국가의 사이트 간 터널(경로에 따라 50–150ms RTT)에서 큰 전송은 MSS 클램프가 세그먼트당 크기를 터널 MTU에 맞춰 유지하면서 병목 대역폭에 가까운 BBR 페이스 안정 처리량에 정착해요.
로컬 LAN 캐시 읽기가 아키텍처가 밥값을 하는 곳이에요. 스위치된 기가비트 LAN의 SMB3를 통해 cache.lan에서 4GB 텍스처 팩을 읽는 렌더 워커는 스위치 포트가 바이트를 푸시하는 데 걸리는 시간 — 크로스컨트리 클라우드 스토리지에서 콜드 풀이 걸리는 다분 단위 시간 대신 수십 초 — 에 대략 완료돼요. 200프레임에 걸쳐 동일한 텍스처 팩을 만지는 작업의 경우 캐시 적중률은 첫 번째 따뜻한 읽기 후 1.0에 접근하고, 크로스컨트리 터널은 원래 프리워밍, 보조 사이트 출력의 크로스사이트 동기화, 안정 상태 텔레메트리에만 사용돼요.
특히 4K 및 8K 렌더 프레임의 경우 아키텍처의 가치는 프레임 크기와 함께 확장돼요. 여러 AOV가 있는 8K EXR 시퀀스는 개별 프레임 출력을 수백 메가바이트로 밀어 올릴 수 있고, 200개는 씬당 수십 기가바이트 쓰기예요. 그 쓰기를 로컬 LAN에 유지하고 최종 압축된 출력만 터널을 통해 보내는 것이 "밤새 완료"와 "내일 언젠가 업로드가 완료되면 완료"의 차이예요.
자주 묻는 질문
Q: OpenVPN이 아닌 WireGuard인 이유는 무엇인가요? A: WireGuard의 구성 표면은 더 작고, 동일한 하드웨어에서 데이터 평면 처리량이 일관되게 더 높으며, 커널 구현이 유저스페이스 실패 모드를 제거하고, 고정 암호 자세가 한 부류의 협상 버그를 제거해요. OpenVPN은 20년의 운영 역사를 가진 견고한 도구예요. 우리에게 중요한 메트릭에서 장기 실행 클러스터 터널의 운영 특성이 더 좋기 때문에 WireGuard를 사용해요. WireGuard의 UDP가 완전히 차단된 경로에서는 TCP 443 위의 OpenVPN이 합당한 폴백이지만, TCP-위-TCP는 자체 병리를 도입하므로 이를 고객 측 제약으로 다뤄요.
Q: BBR이 잡음 많은 ISP 경로에서 어떻게 도움이 되나요? A: BBR은 혼잡 신호로 패킷 손실 대신 병목 대역폭과 RTT를 사용해요. 손실이 중간 라우터의 버퍼 오버플로우, 무선 재전송 또는 일시적인 라우팅 이벤트에 의해 지배되는 경로 — 즉, 대부분의 공용 ISP 경로 — 에서 BBR은 혼잡이 아닌 손실에 대해 윈도를 반복적으로 절반으로 줄이는 대신 발신자 페이스를 경로의 실제 대역폭에 유지해요. 효과는 더 높은 안정 상태 처리량, 큰 전송에서 더 짧은 테일 레이턴시, 긴 흐름에서 "전송이 30초 동안 정지했다가 재개됨" 사건이 적어지는 거예요.
Q: MSS 클램핑이 무엇이고 왜 필요한가요? A: MSS 클램핑은 TCP SYN 패킷의 Maximum Segment Size 옵션을 다시 써서 협상된 세그먼트 크기가 유효 MTU가 감소된 터널을 통해 깨끗하게 맞도록 해요. 그것이 없으면 엔드포인트는 LAN 인터페이스를 기반으로 세그먼트 크기를 협상해요(일반적으로 MTU 1500, MSS 1460). WireGuard 터널은 그러한 패킷을 전체 크기로 운반할 수 없고, Path MTU Discovery는 ICMP가 상류 어딘가에서 필터링되기 때문에 실패하며, 큰 패킷은 조용히 사라져요. 증상은 "작은 패킷은 작동하지만 큰 것은 작동하지 않음" — ping은 통과하고, TLS 핸드셰이크는 멈추며, SMB 전송은 파일 중간에서 정체돼요. 해결책은 라우터 측 WireGuard 인터페이스의 한 줄 iptables 또는 nftables 규칙이에요.
Q: 이 아키텍처를 직접 배포할 수 있나요, 아니면 렌더팜 공급업체가 필요한가요?
A: 아키텍처는 전적으로 오픈 소스 구성 요소 — WireGuard, Linux의 BBR 구현, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4 — 로 구축돼요. SRF 전용 구성 요소는 없어요. 인프라 엔지니어 기술을 가진 팀은 동일한 스택을 스스로 배포할 수 있고, 이 글의 구성 선택은 비밀이 아니에요. 잘 작동했기 때문에 우리가 한 선택이에요. 공급업체가 가져오는 것은 운영 경험이에요 — dnsmasq의 interface= 줄과 같은 함정, MSS 클램프 발견 이야기, 캐시 SSD의 적정 사이징, 프리워밍 도구 — 모든 빌드에서 재발견을 요구하지 않는 배포 플레이북에 묶여 있어요. 팀이 그 경험 곡선을 흡수할지 아니면 비용을 지불해서 건너뛸지는 예산과 일정의 문제예요.
Q: 일반적인 렌더 워크플로의 캐시 적중률은 얼마인가요? A: 같은 씬이 많은 프레임에 걸쳐 렌더링되는 프레임 병렬 워크로드(애니메이션, VFX, 아크비즈, 제품 시각화의 지배적 패턴)의 경우, 캐시 적중률은 각 에셋의 첫 번째 따뜻한 풀 후 1.0에 접근해요. 콜드 풀 페널티는 캐시당 에셋당 한 번 지불되고, 동일한 사이트의 후속 워커는 LAN 속도로 따뜻한 캐시에서 읽어요. 프레임당 다른 에셋 세트를 만지는 워크로드(드물지만 일부 절차적 워크플로에서 발생)의 경우 적중률은 더 낮고 캐시는 장기 저장소보다는 전송 버퍼처럼 작동해요. 마감 기한이 있는 작업 전의 프리워밍 단계는 계획된 워크로드에 대해 적중률을 사실상 1.0으로 만들어요.
Q: 이 아키텍처는 20노드 이상으로 어떻게 확장되나요? A: 허브앤스포크 WireGuard 토폴로지는 피어 수에 따라 선형적으로 확장돼요 — 허브의 CPU 비용은 피어당 암호화와 패킷당 라우팅이고, 현대 Xeon 게이트웨이는 병목이 되기 전에 수백 명의 피어를 편안하게 처리할 수 있어요. 캐시 계층은 단일 캐시 박스를 키우거나(더 많은 SSD 용량, 더 빠른 NIC) 워크로드 인식 마운트 전략으로 여러 박스에 샤딩하여 확장돼요. 사이트당 50노드를 넘는 빌드의 경우 일반적으로 두 번째 캐시 박스를 추가하고 워커를 그 사이에 분할해요. 사이트당 100노드를 넘으면 캐시 계층이 단일 박스가 아닌 분산 읽기 복제본 디자인이 되는데, 그것은 다른 글이에요. 크로스컨트리 터널 자체는 클러스터가 성장함에 따라 아키텍처 변경이 필요하지 않아요 — 기본 ISP 링크가 용량을 가지고 있는 한 BBR 페이싱과 MSS 클램프는 어떤 집계 흐름 속도에서도 계속 작동해요.
이 아키텍처를 가동하는 배포 시퀀스에 대한 더 실용적인 세부 사항은 저희 operational deployment guide를 보세요. 이 네트워크 디자인 위에 놓인 보안 자세는 저희 network segmentation security 글이 Tier-1과 Tier-2 방화벽 모델을 더 깊이 다뤄요. 그리고 우리가 항상 처음에 옳게 하지는 못한 현장 테스트된 엣지 케이스의 경우, deployment lessons learned 글이 이 아키텍처를 형성한 특정 실패 모드를 다뤄요.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



