
Comment nous benchmarkons les GPU de render farm : une méthode reproductible de coût par image (2026)
Aperçu
Introduction
Un score de benchmark est facile à publier et difficile à vérifier. Tout le monde peut afficher « RTX 5090 : X points », mais le chiffre qui détermine si un travail de rendu vaut la peine d'être exécuté sur une carte plutôt qu'une autre n'est pas un score synthétique — c'est le coût par image finale. Cette valeur dépend de votre scène, de vos paramètres de rendu, du moteur de rendu, du pilote, et de la façon dont vous faites le calcul, et presque aucun de ces éléments n'est visible dans un classement.
Cette page présente la méthode, pas le classement. Elle documente comment nous benchmarkons les GPU de render farm chez Super Renders Farm afin que le résultat ait une signification réelle : comment nous choisissons une scène de benchmark, quels paramètres de rendu nous verrouillons, ce que nous maintenons constant à travers la matrice matérielle, comment nous transformons les temps bruts par image en un coût par image défendable, et — la partie que la plupart des articles omettent — les étapes explicites pour qu'un tiers puisse reproduire l'ensemble sur son propre matériel. Nous avons déjà publié les résultats de cette méthode ; voici la recette qui les sous-tend. Lorsqu'un chiffre apparaît ci-dessous, il s'agit d'un vrai résultat issu de l'une de ces études, cité comme exemple illustratif plutôt que recalculé ici.
Benchmarks synthétiques versus coût par image en production
Il existe deux niveaux dans le benchmarking GPU, et les confondre est la source de la plupart des malentendus.
Le premier est la couche synthétique : des outils standardisés qui effectuent le rendu d'une scène fixe et émettent un score. Cinebench R24, le V-Ray Benchmark de Chaos, et OctaneBench en font partie. Ils sont utiles pour le classement relatif — une charge de travail unique et reproductible, identique sur chaque machine, permettant de comparer les cartes entre elles. Nous expliquons comment interpréter ces scores dans notre guide du benchmark V-Ray et dans notre article sur les scores Cinebench pour le rendu cloud. Ce qu'un score synthétique exclut délibérément, c'est tout ce qui varie en production : votre géométrie, votre échantillonnage, votre débruitage, votre résolution de sortie, et la charge par tâche qu'une vraie file d'attente implique.
Le second est la couche production : combien de temps prend réellement une image représentative, et ce que cela coûte. C'est la couche que cette méthodologie cible. Un score synthétique en est une entrée — un moyen d'extrapoler une estimation de départ — mais ce n'est pas la réponse. Le lien entre les deux est simple en principe : une machine qui obtient environ deux fois le score d'une autre sur le même build de benchmark produira, très approximativement, une image comparable en environ deux fois moins de temps. Nous détaillons cet calcul d'estimation (efficacité = temps par image ÷ score de benchmark) dans le guide V-Ray. L'objectif d'une méthode de benchmark, par opposition à un score, est de rendre cette extrapolation honnête — de mesurer sur une scène proche de la production et de rapporter la dispersion, pas seulement une valeur centrale.
La métrique qui compte : le coût par image
Le coût par image est l'unité vers laquelle une méthodologie doit converger, car c'est l'unité dans laquelle un budget de rendu est réellement rédigé. La formule est simple :
Coût par image = temps horloge par image × coût du nœud par heure
Le temps horloge par image correspond au temps de tâche divisé par le nombre d'images, mesuré — pas l'affichage « temps de rendu » interne du moteur de rendu, qui exclut le chargement de la scène, la construction de la structure d'accélération et la coordination des périphériques. Le coût du nœud par heure est ce que le matériel coûte à faire fonctionner pendant une heure, quelle que soit votre méthode de comptabilisation. Sur notre render farm, le rendu GPU est facturé à 0,003 $ par OctaneBench-hour, et une seule RTX 5090 (32 Go) a un coût matériel de base d'environ 5,2 $ par carte-heure ; notre guide du coût par image et le guide des tarifs couvrent le modèle côté client dans son intégralité.
Combiner ces deux entrées relève simplement d'une arithmétique d'unités : convertissez le temps horloge par image en heures et multipliez par le coût du nœud par heure, de sorte que les secondes par image et les dollars par heure donnent des dollars par image. Une image courte sur un nœud peu coûteux atterrit bas ; une image lourde sur un nœud onéreux atterrit haut. Nous gardons délibérément le tarif calculé en dehors de cette page de méthodologie — le coût réel dépend de la complexité de votre scène, de l'échantillonnage, de l'attente en file d'attente et du modèle de facturation que vous utilisez, et notre guide du coût par image et notre guide des tarifs sont l'endroit où appartiennent les chiffres côté client. L'essentiel ici est que la formule est vérifiable : en gardant les unités explicites, n'importe qui peut contrôler le chiffre plutôt que de le prendre pour acquis.
La raison pour laquelle le coût par image, et non un score synthétique, est la métrique de référence : deux cartes peuvent obtenir des scores similaires sur un benchmark et pourtant différer sensiblement en termes de coût par image sur votre scène, car la scène détermine quelle fraction de chaque image est un travail parallélisable par opposition aux charges fixes que le silicium plus rapide ne peut pas toucher.
La scène de benchmark et les paramètres de rendu
La scène est le levier le plus important pour déterminer si un benchmark est transférable à la production, c'est pourquoi nous en utilisons délibérément deux types.
Scènes standard fournisseurs pour le classement inter-machines. Lorsque l'objectif est une comparaison propre, nous utilisons des scènes de référence publiées — les scènes Open Data de Blender (bmw27, classroom, junkshop), la scène Vultures de Maxon pour Redshift, le V-Ray Benchmark de Chaos, et OctaneBench. Elles sont reproductibles et vérifiables indépendamment, ce qui est précisément ce que nécessite un classement. Leur faiblesse est qu'elles ne sont pas votre scène, donc les temps absolus ne se transfèrent pas directement à la production.
Scènes représentatives de la production pour le coût par image. Lorsque l'objectif est un chiffre sur lequel un opérateur peut planifier, la scène doit ressembler à un vrai travail — une vraie géométrie, de vrais jeux de textures, un vrai échantillonnage, une vraie résolution de sortie. Dans notre étude de mise à l'échelle multi-GPU, nous avons exécuté Blender Cycles à 200 % de résolution précisément pour que chaque rendu dure suffisamment longtemps pour produire un ratio stable et fiable — ce qui signifie également que ces temps bruts Cycles ne sont pas comparables aux scores Open Data publics. Ce compromis est la méthode qui fonctionne comme prévu : adapter la scène à la question.
Quelle que soit la scène, les paramètres de rendu doivent être verrouillés et enregistrés : le nombre d'échantillons (ou le seuil de bruit), le débruitage activé/désactivé et lequel, la résolution de sortie, la taille des tuiles ou des buckets, et le build du moteur de rendu. Un benchmark où l'un de ces éléments dérive entre les machines mesure la dérive, pas le matériel.
La matrice matérielle
Une matrice de benchmark est une grille : les cartes testées sur un axe, les moteurs de rendu et les scènes sur l'autre. La discipline réside dans ce que vous maintenez constant à travers la grille.
Maintenez constants : le système d'exploitation, la version et le build du moteur de rendu, le débruitage, la scène et les paramètres. Enregistrez mais ne pouvez pas toujours faire correspondre : le pilote GPU — une carte de génération actuelle nécessite parfois un pilote plus récent qu'une ancienne carte ne peut pas utiliser, donc une correspondance exacte de pilote est impossible. Lorsque cela se produit, nommez-le. Dans l'étude multi-GPU, le nœud RTX 5090 utilisait le pilote 596.36 et le nœud RTX 4090 le pilote 610.62, et nous avons signalé que l'écart n'affecte que la comparaison absolue inter-générations, pas les ratios de mise à l'échelle intra-nœud (qui utilisent la même carte et le même pilote des deux côtés).
Notre flotte GPU se standardise sur des cartes NVIDIA RTX 5090 avec 32 Go de VRAM, ce qui rend notre matrice cohérente en interne — un inventaire uniforme signifie qu'une estimation d'un nœud se transfère au suivant. À titre d'exemple illustratif de l'axe par carte, voici le résultat en carte unique de l'étude multi-GPU, RTX 5090 versus RTX 4090 sur des scènes identiques :
| Moteur de rendu / scène | Métrique | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | secondes (moins c'est mieux) | 49,45 | 77,40 |
| Cycles — classroom | secondes | 23,09 | 36,87 |
| Redshift — Vultures | secondes | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (plus c'est mieux) | 15 333 | 9 608 |
| Octane | score OctaneBench | 1 690,78 | 1 074,17 |
Deux types de métriques apparaissent dans ce tableau — les secondes (moins c'est mieux) et le score de benchmark (plus c'est mieux) — ce qui explique pourquoi les chiffres absolus ne se comparent jamais entre moteurs de rendu. Seul le ratio à l'intérieur d'un même moteur de rendu est une comparaison équitable.
Les contrôles qui rendent un benchmark fiable
La différence entre un chiffre et un chiffre fiable, ce sont les contrôles. Voici ceux que notre méthode applique.
- Une tâche par GPU. Notre planificateur exécute une tâche de rendu par carte, de sorte que chaque chiffre est un nombre propre par carte — la valeur que vous multipliez pour planifier la capacité, et non une moyenne floue sur un périphérique partagé.
- Paires appariées pour toute comparaison. Lorsque nous avons comparé des générations de matériel en production, une scène n'était comptabilisée que si la même scène, le même utilisateur avait été utilisé des deux côtés, avec au moins trois tâches par côté avant d'être qualifiée. Dans l'étude terrain RTX 5090, 38 scènes ont passé ce filtre sur 1 419 tâches — 38 n'est pas la taille des données, c'est ce qui survit à un filtre délibérément strict.
- Un seul pilote par fenêtre temporelle. Pour l'étude terrain, un seul pilote (581.80, CUDA 13.0) a fonctionné pendant toute la fenêtre de sept semaines sans aucun changement, de sorte qu'aucun remplacement en cours de fenêtre ne puisse contaminer le résultat.
- Parité du débruitage. Environ 83 % des tâches Cycles ont exécuté un débruitage par IA sur le matériel nouveau et celui de la génération précédente — le débruitage était donc une constante, pas une variable cachée dans l'accélération.
- Chaud versus froid. Le coût fixe par tâche — chargement de scène, synchronisation, construction de la structure d'accélération — représente une fraction plus importante d'une image courte que d'une image longue, ce qui explique pourquoi les images courtes limitées par les charges fixes sous-estiment une carte plus rapide. La méthode prend cela en compte en rapportant la distribution, sans supposer un multiplicateur unique.
Des temps bruts à un chiffre défendable
Une fois les temps collectés, les statistiques déterminent si le chiffre principal est honnête.
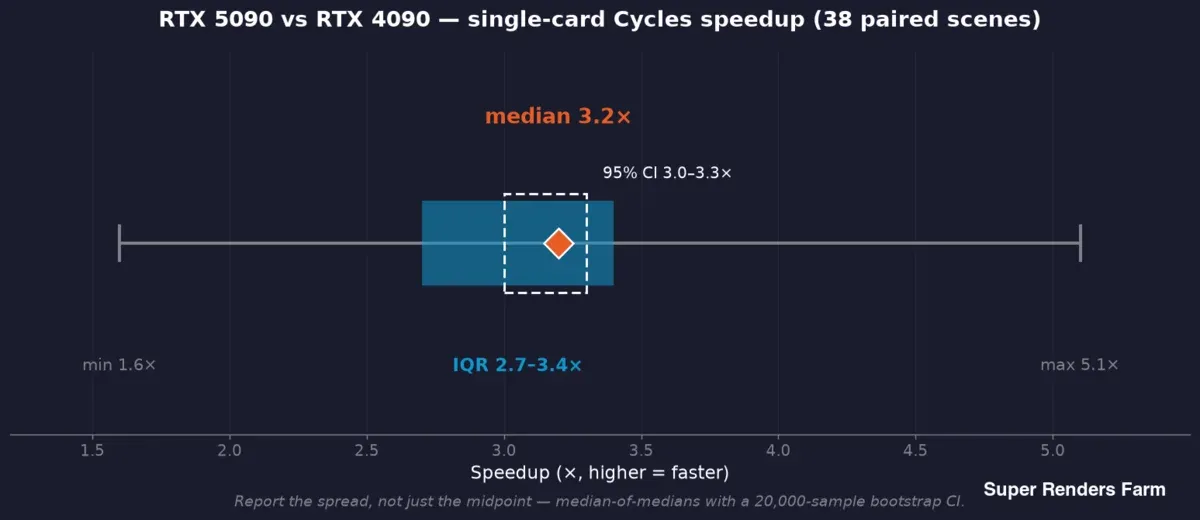
RTX 5090 versus RTX 4090 en carte unique : accélération Cycles sur 38 scènes appariées, médiane 3,2x, intervalle de confiance 95 % de 3,0 à 3,3x, écart interquartile de 2,7 à 3,4x, plage complète de 1,6 à 5,1x
Nous utilisons une médiane des médianes : chaque scène contribue la médiane de ses propres temps par image de chaque côté, et le chiffre principal est la médiane de ces ratios par scène — ainsi, une image lente ne peut pas fausser le résultat. Autour de cette valeur centrale, nous rapportons un intervalle de confiance bootstrap (l'étude terrain a utilisé un bootstrap de 20 000 échantillons, donnant un IC à 95 % de 3,0–3,3x autour de la médiane de 3,2x d'accélération) et la dispersion — écart interquartile de 2,7–3,4x, plage complète de 1,6–5,1x sur ces 38 scènes.
Cette dispersion n'est pas un bruit à moyenner ; c'est le résultat. Une accélération typique de 3,2x et un pire cas de 1,6x sur une scène sont tous deux vrais simultanément, et un benchmark qui ne rapporte que la valeur centrale cache la moitié de l'histoire dont un opérateur a besoin. La règle que nous suivons : rapporter la médiane et la plage, et relier chaque affirmation à l'échantillon qui la soutient — accélération provenant de 38 scènes appariées, VRAM de 57 tâches enregistrées, puissance d'un banc d'essai contrôlé séparé, jamais un échantillon emprunté pour soutenir un autre.
Comment reproduire ce benchmark
C'est la partie qui fait d'un benchmark un signal méritoire plutôt qu'un argument marketing : n'importe qui peut l'exécuter. Les étapes ci-dessous reproduisent la méthode sur n'importe quelle file d'attente ou banc d'essai.
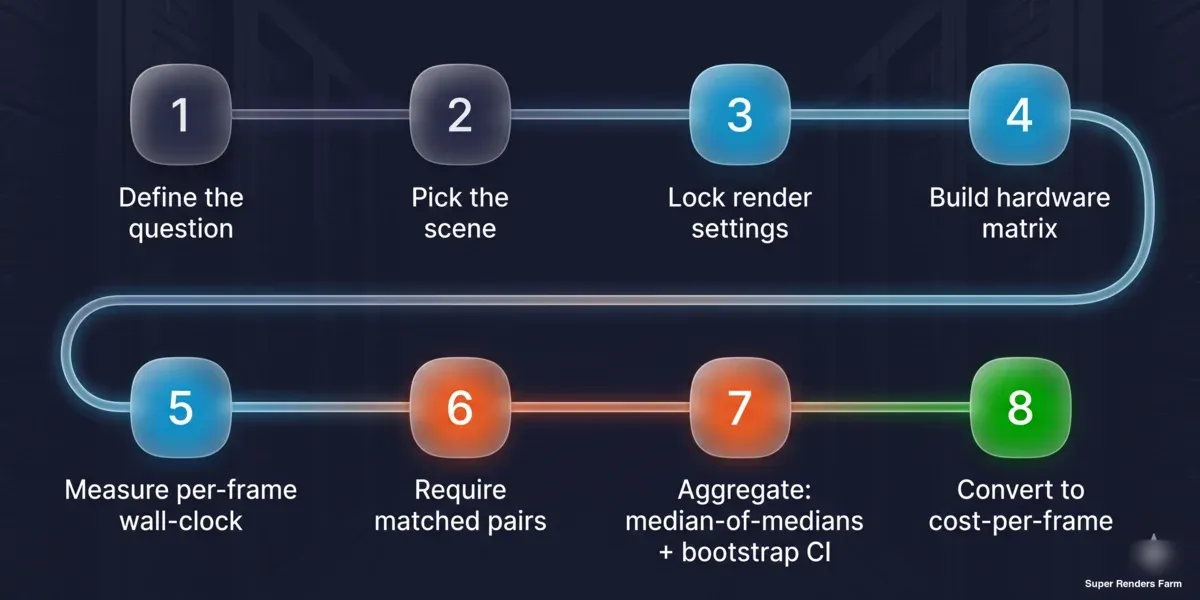
Méthode de benchmark reproductible de coût par image en huit étapes : définir la question, choisir la scène, verrouiller les paramètres de rendu, construire la matrice matérielle, mesurer le temps horloge par image, exiger des paires appariées, agréger avec la médiane des médianes et l'intervalle de confiance bootstrap, convertir en coût par image
- Définir la question. Classement inter-machines, ou coût par image en production ? La réponse détermine le type de scène — standard fournisseur pour le classement, représentative de la production pour le coût.
- Fixer la scène et les paramètres. Verrouiller le nombre d'échantillons ou le seuil de bruit, le choix du débruitage, la résolution de sortie, la taille des tuiles/buckets et le build du moteur de rendu. Les noter ; ils font partie du résultat.
- Construire la matrice. Lister les cartes sur un axe, les combinaisons moteur de rendu/scène sur l'autre. Décider ce qui est maintenu constant (OS, build du moteur de rendu, débruitage, scène) et enregistrer ce qui ne peut pas l'être (pilote).
- Mesurer le temps horloge par image. Utiliser le temps de tâche ÷ le nombre d'images depuis le planificateur ou un chronomètre sur l'ensemble du travail — pas l'affichage du temps de rendu interne du moteur de rendu, qui omet la charge et la construction des structures d'accélération.
- Exiger des paires appariées et un échantillon minimum. Pour toute affirmation A-versus-B, exécuter la même scène des deux côtés, au moins trois tâches par côté, avant qu'elle soit comptabilisée.
- Agréger avec la médiane des médianes. Prendre la médiane de chaque scène par côté, puis la médiane des ratios par scène. Calculer un intervalle de confiance bootstrap et rapporter l'écart interquartile et la plage complète en parallèle.
- Convertir en coût par image. Multiplier le temps mesuré par image par le coût du nœud par heure. Garder les unités explicites pour que le chiffre soit vérifiable.
- Publier les mises en garde avec le chiffre. Indiquer la taille de l'échantillon derrière chaque affirmation, la situation du pilote, si les données sont observationnelles ou contrôlées, et la portée couverte ou non.
Un studio qui suit ces huit étapes sur son propre matériel obtiendra un chiffre qu'il peut défendre — et pourra vérifier le nôtre, ce qui est tout l'intérêt de publier la méthode.
Notes d'honnêteté : ce qu'un benchmark peut et ne peut pas affirmer
Une méthode n'est fiable qu'autant que les affirmations qu'elle refuse de faire. Trois lignes que nous tenons :
L'observationnel n'est pas du contrôlé. Les données terrain de production — les tâches que les utilisateurs ont exécutées dans le cours normal de leurs activités — sont réelles et utiles, mais les utilisateurs ajustent leurs propres scènes entre les re-rendus, c'est donc de l'observationnel. Un comparatif tête-à-tête propre sur le même hôte (par exemple, une RTX 5090 contre une RTX 4090 actuelle sur un matériel identique) est un exercice contrôlé distinct. Nous ne laissons pas l'un se faire passer pour l'autre.
Le nœud contre nœud inclut la configuration, pas seulement le silicium. Lorsqu'un côté fonctionne en bare-metal et l'autre en virtualisé, une partie de l'écart mesuré est la configuration, pas la puce. Cela appartient à la mise en garde principale, pas à une note de bas de page.
Aucun chiffre que nous n'avons pas mesuré. Nous n'extrapolons pas les chiffres de puissance ou thermiques que nous n'avons pas testés. Là où notre étude terrain rapporte environ 360–375 W par carte, cela provient d'un banc d'essai contrôlé sous charge soutenue — et la figure d'énergie par image qui en est dérivée est étiquetée comme une inférence, pas une mesure. Si un chiffre n'a pas été mesuré, la méthode ne l'invente pas. Cette discipline est la raison pour laquelle un benchmark publié peut être cité du tout.
Exemples illustratifs de notre render farm
Cette méthode a produit les études ci-dessous ; chacune est un jeu de données que vous pouvez lire en parallèle avec la recette, et l'endroit où chercher les chiffres réels plutôt que de les recalculer ici.
| Étude | Ce que la méthode a produit | Échantillon |
|---|---|---|
| Mise à l'échelle multi-GPU | Mise à l'échelle 1x→2x par moteur de rendu sur des scènes standard fournisseurs | 2 nœuds, 4 moteurs de rendu, 7 combinaisons scène/benchmark |
| Notes terrain RTX 5090 | Distribution du coût/accélération en production, percentiles VRAM | 38 scènes appariées / 1 419 tâches, 7 semaines |
| Guide du benchmark V-Ray | Estimation du temps de rendu à partir du score synthétique | Tables de référence + estimation illustrative |
| Cinebench pour le rendu cloud | Interprétation du score synthétique pour les niveaux matériels | Scores de référence |
La même approche sous-tend notre planification de capacité sur notre render farm GPU cloud, et les chiffres spécifiques à Blender alimentent notre travail de rendu cloud Blender — le GPU représente une minorité de notre mix global de tâches (la plupart du travail de render farm reste du rendu CPU), donc nous présentons ces chiffres GPU comme tels, et non comme une affirmation couvrant l'ensemble de la render farm.
FAQ
Q: Quelle est la bonne façon de benchmarker un GPU de render farm ? A: Décidez d'abord si vous souhaitez un classement inter-machines ou un coût par image en production. Pour le classement, utilisez une scène standard fournisseur reproductible et un build de benchmark fixe. Pour le coût par image, utilisez une scène représentative de la production, mesurez le temps horloge par image (temps de tâche ÷ nombre d'images), et multipliez par le coût du nœud par heure. Verrouillez les paramètres de rendu et rapportez la dispersion, pas seulement un seul chiffre.
Q: Pourquoi le coût par image est-il meilleur qu'un score de benchmark ? A: Un score synthétique exclut tout ce qui varie en production — votre géométrie, votre échantillonnage, votre débruitage et votre résolution — de sorte que deux cartes peuvent obtenir des scores similaires mais différer en termes de coût par image réel sur votre scène. Le coût par image est l'unité dans laquelle un budget de rendu est réellement rédigé, c'est pourquoi une méthodologie devrait y converger plutôt que vers un point de classement.
Q: Comment convertir un score de benchmark en estimation de temps de rendu ? A: Utilisez le ratio de scores comme ratio de vitesse approximatif : une machine obtenant deux fois le score d'une autre sur le même build de benchmark produira une image comparable en environ deux fois moins de temps. Calculez l'efficacité de votre machine comme le temps par image divisé par le score de benchmark, puis mettez à l'échelle avec le score de la machine cible. Gardez le build du benchmark constant, car les scores de builds différents ne sont pas comparables.
Q: Quels contrôles rendent un benchmark GPU fiable ? A: Exécutez une seule tâche de rendu par carte pour des chiffres propres par carte, exigez des paires appariées (la même scène des deux côtés, un nombre minimum de tâches avant qu'un résultat soit comptabilisé), maintenez le pilote et le build du moteur de rendu constants dans une fenêtre de mesure, et gardez le paramètre de débruitage identique sur toute la comparaison. Ensuite, agrégez avec la médiane des médianes et rapportez l'intervalle de confiance et la plage.
Q: De combien de scènes de test ai-je besoin pour un résultat fiable ? A: Moins de paires appariées de haute qualité valent mieux que beaucoup de paires peu contrôlées. Dans notre étude de production, 38 scènes ont survécu à un filtre d'inclusion strict (même scène et utilisateur sur les deux côtés matériels, au moins trois tâches par côté) sur 1 419 tâches. La taille d'échantillon qui compte est ce qui passe votre filtre, pas le nombre brut de tâches — et vous devriez rapporter les deux.
Q: Puis-je reproduire votre benchmark GPU de render farm moi-même ? A: Oui — c'est l'intention. Fixez une scène et ses paramètres, construisez une matrice matérielle en maintenant constants le système d'exploitation, le build du moteur de rendu et le débruitage, mesurez le temps horloge par image, exigez des paires appariées, agrégez avec la médiane des médianes plus un intervalle de confiance bootstrap, convertissez en coût par image, et publiez les mises en garde avec le chiffre. Les huit étapes de réplication ci-dessus décrivent la séquence complète.
Q: Pourquoi rapportez-vous une plage plutôt qu'un seul chiffre d'accélération ? A: Parce que la plage fait partie du résultat. Le même matériel peut afficher un gain de 1,6x sur une scène courte limitée par les charges fixes et plus de 5x sur une scène intensive liée au calcul, puisque la charge fixe par image représente une fraction plus importante d'un rendu court. Rapporter uniquement la valeur centrale cache la variation dont un opérateur a besoin pour planifier la capacité, c'est pourquoi nous publions la médiane, l'écart interquartile et la plage complète ensemble.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



