
Multi-GPU Scaling : ce qu'un deuxième GPU apporte vraiment au rendu (benchmark 2026)
Aperçu
Introduction
TL;DR: Un deuxième GPU double rarement la vitesse de rendu, et l'ampleur du gain dépend entièrement du moteur de rendu. Sur nos benchmarks 2026 réalisés sur des nœuds dual RTX 5090 et RTX 4090, les moteurs en mode débit (V-Ray, Octane) ont scalé à près de 2,00x, tandis que les moteurs à temps de rendu ont scalé moins bien — Cycles 1,31x-1,63x, Redshift 1,68x-1,92x — parce que la surcharge opérationnelle fixe par rendu réduit ce que la deuxième carte peut accélérer. Deux GPU constituent le plafond pratique par nœud ; le débit réel d'une render farm provient de l'exécution de nombreuses images sur de nombreux nœuds en parallèle, pas de l'empilement de cartes supplémentaires dans une seule machine.
Un deuxième GPU ne rend pas un projet deux fois plus vite. Cela paraît évident une fois dit, mais de nombreuses décisions d'achat matériel reposent sur l'hypothèse que deux cartes égalent deux fois la vitesse. En juin 2026, nous avons sorti deux nœuds de benchmark de notre file d'attente — l'un équipé de deux RTX 5090, l'autre de deux RTX 4090 — et mesuré ce qui se passe réellement lorsque l'on passe d'une carte à deux, sur quatre moteurs de rendu et sept combinaisons scène/benchmark.
La version courte : tout dépend du moteur. Les benchmarks en mode débit (V-Ray, Octane) ont scalé quasi parfaitement, autour de 2x. Les moteurs à temps de rendu (Cycles, Redshift) ont scalé moins bien, et sur la carte la plus rapide, le deuxième GPU a aidé moins, pas plus. Nous allons parcourir les chiffres, expliquer pourquoi la courbe se plie ainsi et — tout aussi important — préciser clairement où cela s'arrête. Deux cartes constituent le plafond sur un nœud unique. Aller au-delà constitue une architecture différente, pas une version plus grande de celle-ci.
Il s'agit d'un article axé matériel/benchmark, donc orienté GPU. Il convient de préciser d'emblée que le GPU représente une minorité de ce qui tourne sur notre render farm — la plupart des productions utilisent encore le rendu CPU (V-Ray, Corona, Arnold sur CPU). Mais lorsque quelqu'un demande « est-ce qu'un deuxième GPU en vaut la peine », il mérite des chiffres mesurés, pas un argumentaire commercial. Voici donc les chiffres mesurés.
Comment nous avons testé (et ce que ces chiffres ne sont pas)
Les deux nœuds de test tournaient sous Windows 11 Pro avec deux GPU chacun. Le nœud 5090 utilisait le pilote 596.36 ; le nœud 4090 utilisait le pilote 610.62 — une carte Blackwell nécessite un pilote plus récent, une correspondance exacte n'était donc pas possible. Cet écart de pilote n'a d'importance que sur un seul point : la comparaison de vitesse absolue inter-générations entre un 5090 et un 4090. Les ratios de scaling sur lesquels nous nous concentrons sont mesurés au sein d'un nœud unique (même carte, même pilote, un GPU versus deux), donc la différence de pilote ne les affecte pas.
Chaque scène est un benchmark standard fournisseur : les scènes Open Data de Blender (bmw27, classroom, junkshop), la scène « Vultures » de Maxon pour Redshift, le Chaos V-Ray Benchmark 6.00.02 et OctaneBench 2025.2.1. Aucun projet client, aucun asset de production. Nous ne publions pas de minutes par image, de coût par image, ni de données électriques, car ce jeu de données ne les contient pas et nous ne les inventons pas.
Une note méthodologique importante pour la lecture des lignes Cycles : nous avons fait tourner Blender Cycles à 200 % de résolution, plus lourd que le réglage par défaut Open Data, précisément pour que chaque rendu dure assez longtemps pour produire un ratio de scaling stable et fiable. Cela signifie que nos temps bruts Cycles ne sont pas comparables aux scores publics Open Data — ils sont calibrés pour mesurer le scaling, pas pour figurer dans des classements. Cycles et Redshift sont mesurés en temps de rendu (secondes, moins c'est mieux) ; V-Ray et Octane sont mesurés en score de benchmark (vpaths ou points OctaneBench, plus c'est mieux). Ce sont deux types de métriques différents, donc les chiffres absolus ne se comparent jamais entre moteurs — seul le ratio de scaling au sein d'un moteur est comparable.
Le résultat central : scaling 1x→2x, par moteur
Voici les données phares — ce qu'une deuxième carte identique apporte réellement, par moteur et par scène :
| Moteur | Scène | Scaling 2x RTX 5090 | Scaling 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1,54x | 1,58x |
| Cycles | classroom | 1,59x | 1,63x |
| Cycles | junkshop | 1,31x | 1,38x |
| Redshift | Vultures | 1,68x | 1,92x |
| V-Ray GPU (CUDA) | benchmark | 1,97x | 2,00x |
| V-Ray GPU (RTX) | benchmark | 2,00x | 2,00x |
| Octane | suite OctaneBench | 2,00x | 1,98x |
Lire ce tableau de haut en bas fait apparaître une nette séparation. V-Ray et Octane arrivent à 2,00x ou juste en dessous sur les deux cartes — un deuxième GPU double quasi la production. Cycles se situe entre 1,31x et 1,63x. Redshift atteint 1,68x sur le 5090 et 1,92x sur le 4090.
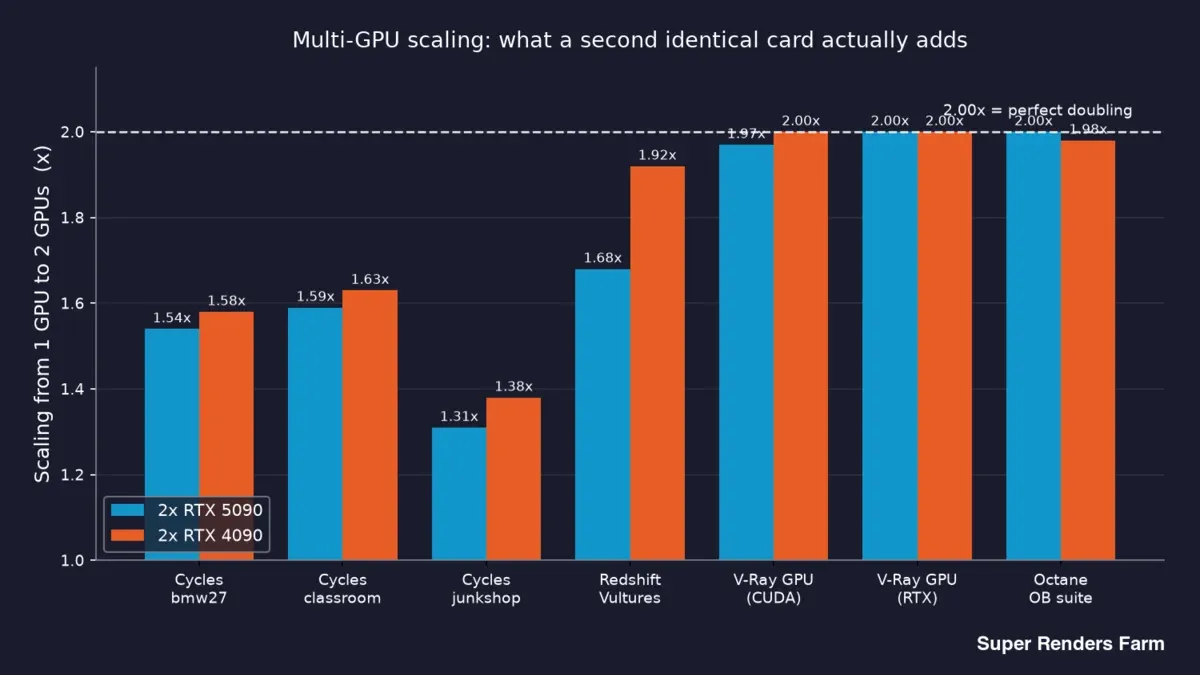
Graphique à barres du scaling 1-GPU vers 2-GPU par moteur sur des nœuds dual RTX 5090 et dual RTX 4090 : Cycles de 1,31x à 1,63x, Redshift 1,68x contre 1,92x, V-Ray et Octane proches de 2,00x
Ainsi, « est-ce qu'ajouter un deuxième GPU double ma vitesse ? » a trois réponses honnêtes différentes selon ce que vous rendez : essentiellement oui pour V-Ray et Octane, environ 1,5x pour Cycles, et quelque part entre les deux pour Redshift. Quiconque vous affirme qu'un seul multiplicateur s'applique à tout le rendu n'a tout simplement pas mesuré.
Pourquoi les moteurs de débit scalent mieux que les moteurs à temps de rendu
Le schéma n'est pas aléatoire — il découle de la façon dont chaque benchmark utilise son temps. V-Ray Benchmark et OctaneBench sont des tests de débit. Ils déversent une charge de travail sur tout le calcul disponible et rapportent un score, et la charge de configuration fixe (chargement de la scène, construction des structures d'accélération, initialisation du périphérique) représente une infime portion du temps total. Ajoutez une deuxième carte et la quasi-totalité de ce silicium supplémentaire va directement en travail utile, ce qui vous donne un scaling proche de 2x. Le résultat V-Ray RTX atteignant un net 2,00x sur les deux cartes est exactement ce que l'on attendrait d'une charge de travail où la surcharge opérationnelle est essentiellement du bruit.
Les moteurs à temps de rendu se comportent différemment. Lorsque vous mesurez un rendu Cycles ou Redshift en secondes au mur, vous chronométrez le travail complet — et chaque travail comporte une portion fixe de surcharge non parallélisable : analyse de la scène, construction BVH/structure d'accélération, compilation du noyau et préchauffage, coordination des périphériques, résolution finale des pixels. Un deuxième GPU accélère la partie qui est réellement divisible entre les cartes. Il ne fait rien pour la partie fixe. Plus votre temps de rendu total est constitué de surcharge opérationnelle fixe, plus votre scaling descend en dessous de 2x.
C'est pourquoi Cycles junkshop (1,31x–1,38x) scale moins bien que Cycles classroom (1,59x–1,63x) : junkshop est un rendu plus léger et plus court, donc sa surcharge opérationnelle fixe représente une plus grande fraction de l'ensemble, laissant moins à accélérer pour la deuxième carte. La scène classroom tourne plus longtemps, la portion parallèle domine, et le deuxième GPU a plus de place pour aider. Même moteur, même matériel — c'est la scène qui décide de l'importance de la deuxième carte.
La partie contre-intuitive : la carte plus rapide a moins bien scalé
Regardez à nouveau la ligne Redshift. Deux RTX 5090 ont scalé à 1,68x. Deux RTX 4090 ont scalé à 1,92x. La nouvelle carte, plus rapide, a moins bien scalé. Cela ressemble à une erreur. Ce n'en est pas une — c'est le chiffre le plus instructif de tout l'ensemble.
Voici le mécanisme. Le 5090 est la carte la plus rapide en termes absolus ; sur un GPU unique, il termine la scène Vultures en environ 57 secondes contre 100 secondes pour le 4090. Mais cette surcharge opérationnelle fixe par rendu — analyse, construction, préchauffage — représente à peu près le même nombre de secondes quelle que soit la carte utilisée. Sur le 4090, cette portion fixe représente une petite fraction d'un long rendu de 100 secondes, donc la deuxième carte dispose d'une grande portion parallèle à traiter et le scaling atteint 1,92x. Sur le 5090, le rendu est déjà court, donc cette même portion fixe représente une plus grande fraction du total, laissant une plus petite portion parallèle pour la deuxième carte — et le scaling arrive à 1,68x.
Fondamentalement, cela ne signifie pas que le 5090 est moins bon. Il est plus rapide sur une carte et plus rapide sur deux cartes. Il gagne simplement proportionnellement moins du deuxième GPU parce qu'il avait moins de rendu lent à accélérer. Plus votre rendu de base est rapide, plus il est difficile pour une deuxième carte de délivrer un 2x net — il reste tout simplement moins de temps à paralléliser. C'est une chose vraiment utile à comprendre avant de dépenser de l'argent à empiler des cartes identiques en espérant des rendements linéaires.
Vitesse par carte : RTX 5090 vs RTX 4090
Le scaling est un axe ; la vitesse brute par carte en est un autre. Sur une seule carte, avec la mise en garde de pilote de la section méthode appliquée, le 5090 est arrivé en tête sur tous les moteurs testés :
| Moteur | Métrique | RTX 5090 | RTX 4090 | Avantage 5090 |
|---|---|---|---|---|
| Cycles — bmw27 | secondes (moins c'est mieux) | 49,45 | 77,40 | 1,57x |
| Cycles — classroom | secondes | 23,09 | 36,87 | 1,60x |
| Cycles — junkshop | secondes | 19,71 | 34,43 | 1,75x |
| Redshift — Vultures | secondes | 57 | 100 | 1,75x |
| V-Ray GPU (CUDA) | vpaths (plus c'est mieux) | 11 051 | 7 419 | 1,49x |
| V-Ray GPU (RTX) | vpaths | 15 333 | 9 608 | 1,60x |
| Octane | score OctaneBench | 1 690,78 | 1 074,17 | 1,57x |
Dans l'ensemble, le 5090 est environ 1,5x à 1,75x plus rapide par carte. Deux conclusions pour quiconque planifie du matériel. Premièrement, les gains générationnels par carte (1,5x–1,75x ici) sont plus importants et plus fiables que le gain lié à l'ajout d'une deuxième carte de même génération sur un moteur à temps de rendu (souvent bien en dessous de 2x). En termes simples : une carte plus rapide est souvent un meilleur levier qu'une deuxième carte. Deuxièmement, ces chiffres inter-générations sur une seule carte comportent la mise en garde de désaccord de pilote — considérez-les comme une comparaison directionnelle, pas comme une garantie de niveau de service. Nous mesurons sur des scènes de benchmark ; la complexité de votre scène, l'échantillonnage et la résolution de sortie déplaceront le chiffre réel. Pour plus d'informations sur le comportement du 5090 sur une seule carte, consultez notre article sur les performances de rendu cloud GPU RTX 5090.
Deux GPU constituent le plafond par nœud — et pourquoi c'est bien
Voici où nous traçons une ligne claire, car c'est la partie que la plupart des contenus multi-GPU passent discrètement sous silence. Chaque nœud de ce benchmark est un nœud à deux GPU. Deux cartes constituent le plafond par nœud. Nous n'allons pas vous montrer une courbe de scaling 4x ou 8x sur un nœud unique, car ce n'est pas une configuration que nous utilisons, et nous n'allons pas sous-entendre le contraire.
Dépasser deux GPU sur une seule image signifie recourir au rendu distribué multi-nœuds — diviser une image sur plusieurs machines, avec toute la coordination réseau, la gestion des buckets/tuiles et la surcharge opérationnelle que cela implique. C'est une architecture véritablement distincte, pas une version plus grande d'un boîtier à deux cartes. Ce n'est pas quelque chose que nous proposons aujourd'hui pour une seule image, donc nous n'allons pas l'agiter comme une fonctionnalité « bientôt disponible » avec une date associée.
Et voici la réalité : pour l'écrasante majorité des productions, le plafond à deux GPU n'est pas la contrainte qui importe. La contrainte qui se manifeste en premier est presque toujours la VRAM, pas le nombre de cartes — une scène qui ne tient pas dans 32 Go ne se rendra pas quel que soit le nombre de GPU pointés dessus, ce qui est un problème entièrement différent (nous l'abordons dans les limites VRAM du RTX 5090 pour les scènes complexes). Quand les gens imaginent « scaler une render farm », ils imaginent généralement un rendu gigantesque devenant plus rapide sur de plus en plus de silicium. Ce n'est pas ainsi que le débit à l'échelle d'une render farm fonctionne réellement.
Comment une render farm scale réellement : les images, pas les cartes
C'est la distinction qui mérite d'être intégrée, et c'est celle à laquelle les chiffres du benchmark ci-dessus renvoient sans cesse. Il y a deux choses complètement différentes que les gens entendent par « rendre plus vite sur plus de matériel » :
- Diviser une image sur plusieurs GPU ou machines (rendu distribué en tuiles/buckets). C'est ce que les chiffres 1x→2x mesurent à l'échelle de deux cartes, et ce que le rendu distribué multi-nœuds étendrait. Cela atteint rapidement des rendements décroissants sur les moteurs à temps de rendu, comme le montrent les données, en raison de la surcharge opérationnelle fixe par rendu — et la charge de coordination ne fait que croître à mesure qu'on ajoute des machines.
- Répartir de nombreuses images sur de nombreuses machines (rendu parallèle par image). Chaque nœud rend une image entière par lui-même ; les images d'une animation sont distribuées sur l'ensemble du parc en parallèle. Il n'y a pas de surcharge de coordination sur une seule image à combattre, donc cela scale proprement et c'est ainsi qu'une animation est rendue rapidement.
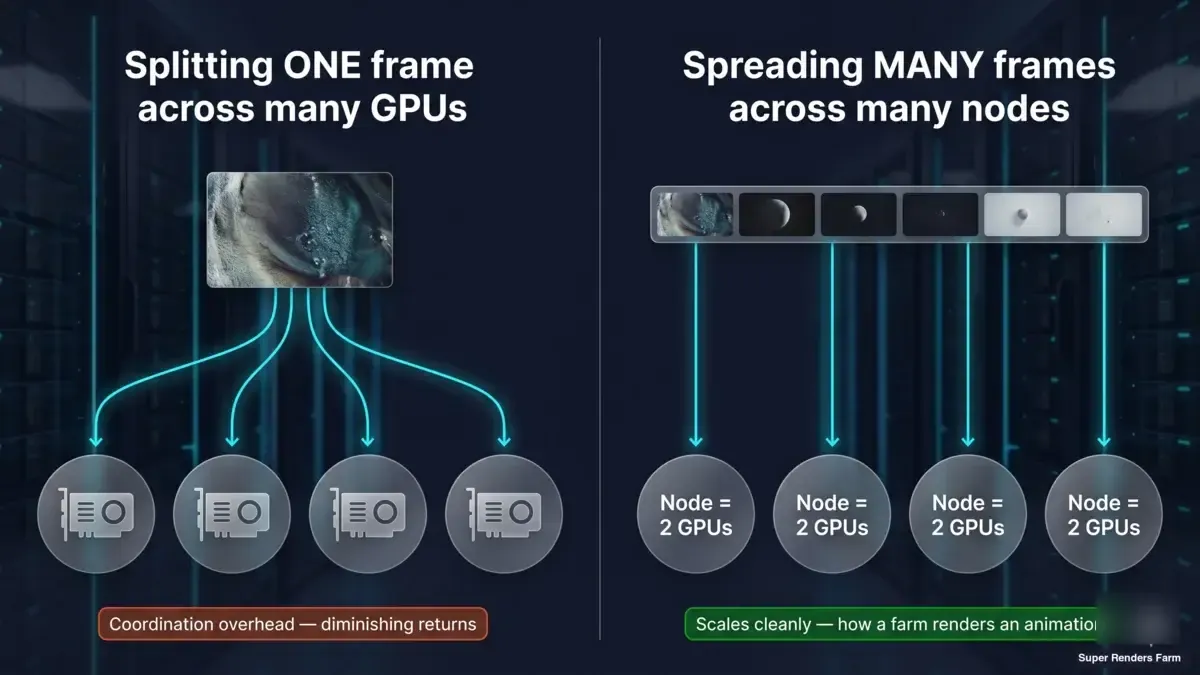
Diagramme conceptuel en deux panneaux : une image divisée sur plusieurs GPU rencontre une surcharge de coordination et des rendements décroissants ; de nombreuses images entières chacune sur leur propre nœud à deux GPU en parallèle scale proprement, c'est ainsi qu'une render farm scale une animation
Une render farm gérée tire sa vitesse presque entièrement du second modèle. Votre animation de 500 images n'est pas rendue comme une seule image étalée sur 500 GPU — elle est rendue comme 500 images distribuées sur l'ensemble du parc, chacune sur son propre nœud, toutes en même temps. La vitesse par nœud et par image est définie par le type de scaling à deux GPU et de performance par carte que nous avons benchmarké ici ; la vitesse au niveau de la render farm provient du nombre d'images rendues simultanément. Ce sont des leviers différents, et les confondre est à l'origine de beaucoup de confusion autour de la question « combien de GPU me faut-il ? ».
Le cadrage honnête du multi-GPU est donc plus étroit que la version marketing. Deux cartes par nœud vous apportent un gain réel et mesurable — proche de 2x sur V-Ray et Octane, plus modeste sur Cycles et Redshift. Au-delà, la réponse n'est pas « empiler plus de cartes dans le boîtier », c'est « faire tourner plus d'images sur plus de nœuds ». C'est l'architecture, et être franc à ce sujet tend à économiser aux gens de l'argent qu'ils étaient sur le point de dépenser sur du matériel qui n'aurait pas rentabilisé leurs attentes.
Ce que cela signifie pour choisir votre mode de rendu
Pour synthétiser en quelque chose d'actionnable. Si vous choisissez entre une carte et deux pour une station de travail, le moteur que vous utilisez doit guider la décision : les utilisateurs de V-Ray ou Octane obtiennent un doublement quasi complet et la deuxième carte est facile à justifier ; les utilisateurs de Cycles et Redshift doivent s'attendre à un gain de 1,3x–1,9x et peser si une carte unique plus rapide (le gain générationnel de 1,5x–1,75x) est la meilleure dépense. Si vous choisissez de rendre localement ou de confier le travail à une render farm, gardez à l'esprit que l'avantage de la render farm est le débit parallèle par image sur une animation, pas un multiplicateur magique sur une seule image — une seule image « hero » ne sera pas rendue de façon dramatiquement plus rapide sur une render farm que sur une station de travail comparable, mais quelques centaines d'images, si.
Pour le contexte sur le compromis entre géré et DIY — qui gère les pilotes, les licences et la configuration des nœuds — notre comparaison render farm entièrement gérée vs DIY le couvre. Sur notre render farm, les licences des moteurs de rendu (V-Ray, Redshift, Octane) sont incluses dans le tarif de rendu et la configuration des nœuds est fixe et maintenue pour vous, donc le setup à deux GPU par nœud et les pilotes derrière ces chiffres ne sont pas quelque chose que vous assemblez ou ajustez vous-même. Pour le côté Redshift sur Cinema 4D spécifiquement, où le chiffre de scaling de 1,68x s'applique, consultez notre guide Redshift render farm pour Cinema 4D.
Les mesures ici sont délibérément sans fioritures. Un deuxième GPU est un vrai levier avec de vraies limites, la carte plus rapide scale moins parce qu'elle avait moins de rendu lent à accélérer, et la vitesse à l'échelle d'une render farm est une question de distribution d'images, pas d'empilement de cartes. Savoir quel levier s'applique à votre charge de travail constitue l'essentiel de la décision.
FAQ
Q: Est-ce qu'ajouter un deuxième GPU double la vitesse de rendu ? A: Pas généralement. Dans nos benchmarks 2026, les moteurs de débit comme V-Ray et Octane ont scalé à près de 2,00x avec une deuxième carte identique, mais les moteurs à temps de rendu ont scalé moins — Cycles s'est situé entre 1,31x et 1,63x et Redshift a atteint 1,68x sur des dual RTX 5090. Le gain dépend entièrement du moteur et de la scène, car chaque rendu comporte une surcharge opérationnelle fixe qu'une deuxième carte ne peut pas accélérer.
Q: Pourquoi Redshift scale mieux sur le RTX 4090 que sur le RTX 5090 ? A: Parce que le 5090 est plus rapide, ses rendus sont plus courts, donc la surcharge opérationnelle fixe par rendu (analyse de la scène, construction de la structure d'accélération, préchauffage du noyau) représente une plus grande fraction du total. Cela laisse une portion parallèle plus petite pour la deuxième carte à accélérer, ce qui donne un scaling de 1,68x sur le 5090 contre 1,92x sur le 4090. Le 5090 est toujours plus rapide sur une et deux cartes — il gagne simplement proportionnellement moins du deuxième GPU.
Q: Dans quelle mesure le RTX 5090 est-il plus rapide que le RTX 4090 pour le rendu ? A: Environ 1,5x à 1,75x plus rapide par carte sur les moteurs que nous avons testés, dont Cycles, Redshift, V-Ray GPU et Octane. Ces chiffres inter-générations sur une seule carte comportent une légère mise en garde car les deux cartes tournaient avec des pilotes NVIDIA différents, donc considérez-les comme une comparaison directionnelle plutôt qu'une garantie fixe.
Q: Pourquoi V-Ray et Octane scalent-ils mieux que Cycles et Redshift sur deux GPU ? A: V-Ray Benchmark et OctaneBench sont des tests de débit où la charge de configuration fixe représente une infime fraction du temps de run, donc une deuxième carte va presque entièrement en travail utile et le scaling approche 2,00x. Cycles et Redshift sont mesurés en temps de rendu total, qui inclut une surcharge opérationnelle non parallèle qu'une deuxième carte ne peut pas accélérer, donc leur scaling reste en dessous de 2x.
Q: Une render farm peut-elle rendre une seule image plus rapidement sur plusieurs machines ? A: Diviser une image sur plusieurs machines est du rendu distribué multi-nœuds, qui est une architecture distincte avec sa propre surcharge de coordination et que nous ne proposons pas aujourd'hui pour une seule image. Une render farm gérée tire sa vitesse du rendu parallèle par image à la place — de nombreuses images entières distribuées sur de nombreux nœuds en même temps — donc une animation se termine vite tandis qu'une seule image hero se rend à la vitesse approximative d'un nœud.
Q: De combien de GPU ai-je réellement besoin pour le rendu ? A: Pour un nœud unique, deux GPU constituent un plafond sensé et c'est ce qu'utilisent nos nœuds de benchmark ; au-delà, la contrainte pratique est habituellement la VRAM, pas le nombre de cartes, puisqu'une scène qui ne tient pas en mémoire ne se rendra pas quel que soit le nombre de cartes ajoutées. Si vous rendez des animations, le vrai débit vient de faire tourner plus d'images sur plus de nœuds plutôt que d'empiler plus de cartes dans une machine.
Q: Ces chiffres de benchmark sont-ils comparables aux scores publics Blender Open Data ? A: Non. Nous avons fait tourner Blender Cycles à 200 % de résolution, plus lourd que le réglage par défaut Open Data, pour que chaque rendu dure assez longtemps pour produire un ratio de scaling stable. Cela rend nos temps bruts Cycles intentionnellement non comparables aux classements publics Open Data — les scènes étaient calibrées pour mesurer le scaling, pas pour correspondre aux scores standard.
Q: Faut-il gérer les pilotes GPU et les licences pour utiliser une render farm gérée ? A: Non. Sur une render farm entièrement gérée, la configuration des nœuds, les pilotes et les licences des moteurs de rendu (V-Ray, Redshift, Octane) sont pris en charge pour vous et inclus dans le tarif de rendu, donc le setup à deux GPU par nœud et les pilotes derrière ces benchmarks ne sont pas quelque chose que vous assemblez ou ajustez. Cycles est gratuit et open-source, il ne nécessite donc pas de licence séparée.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



