
RTX 5090 en production : 7 semaines de notes de terrain sur la render farm (étude 38 scènes)
Aperçu
Les benchmarks de lancement du RTX 5090 ont plus d'un an, et ils décrivent tous la même chose : une seule carte, une scène préparée, des conditions idéales. Ce que presque personne ne publie, c'est la suite — ce que fait la carte une fois qu'elle est enfouie dans une file d'attente de production, en rendant les scènes d'autres personnes selon un planning qu'elle ne contrôle pas. Nous avons donc extrait les logs. Ce qui suit, ce sont les notes de terrain au niveau de la file d'attente : les mêmes données de production sur lesquelles nous basons notre planification de capacité, présentées sous forme de chiffres vérifiables.
Ceci couvre sept semaines. Du 1er avril au 22 mai 2026 — 51 jours — nous avons fait fonctionner un nœud dual-RTX-5090 au sein de notre render farm en production et l'avons laissé traiter tout ce que la file d'attente lui soumettait. Aucun test mis en scène, aucune image sélectionnée. La courte vidéo ci-dessous passe en revue les chiffres clés ; les notes de terrain complètes suivent.
Le nœud lui-même n'a rien d'exceptionnel : deux RTX 5090, 128 GiB de RAM, 32 cœurs logiques à 4.3 GHz, Windows 11. Un détail conditionne chaque chiffre présenté ici — le planificateur exécute une seule tâche de rendu par GPU, de sorte que chaque carte rend son propre travail et que chaque nombre est un chiffre propre par carte, le multiplicateur que vous utilisez pour planifier la capacité. Sur l'ensemble de la fenêtre, le nœud a achevé 99.6% de ses tâches — 4,890 des quelque 4,900 tâches terminées, 18 en échec. Le planificateur enregistre l'échec, pas la cause, et nous ne nous risquerons donc pas à deviner.
Chiffres clés
- Période : 1er avril – 22 mai 2026 (51 jours, ~7 semaines), un nœud dual-RTX-5090
- Taux d'achèvement : 99.6% — 4,890 des ~4,900 tâches terminées, 18 en échec (cause non enregistrée)
- Accélération : médiane 3.2x par image sur Blender Cycles par rapport aux nœuds de génération précédente de type RTX 3080/2080 (temps médian par image réduit d'environ 69%) ; 95% CI 3.0–3.3x
- Dispersion : IQR 2.7–3.4x, plage complète 1.6x–5.1x sur 38 scènes appariées — un seul multiplicateur ne décrit jamais une file d'attente
- Débruitage IA : environ 83% des travaux Cycles ont exécuté un passage de débruitage IA — le même taux que sur l'ancien matériel
- VRAM : médiane 5.6 GB, 90e percentile 11.5 GB, travail le plus lourd ~37 GB
- Pilote : un seul pilote (581.80 / CUDA 13.0) sur toute la période, zéro changement
- Consommation électrique : ~360–375 W/carte en charge (banc de test contrôlé), pic à ~400 W, à 68–83 °C — bien en dessous de la classe nominale ~575 W
Ce que révèlent 38 scènes appariées
La comparaison en laquelle nous avons le plus confiance n'est pas un test synthétique, mais les travaux qui ont tourné sur les deux générations dans le cours normal de l'activité — même scène, même utilisateur, au moins trois tâches par côté avant qu'une scène soit prise en compte. Le temps par image est le temps d'horloge de la tâche divisé par le nombre d'images, directement extrait de la file d'attente. Sur la période considérée, 38 scènes ont franchi ce seuil, tirées de 1,419 tâches de rendu individuelles (503 sur le nœud 5090, 916 sur la génération précédente). Trente-huit n'est pas la taille de nos données ; c'est ce qui survit à un filtre délibérément strict.
| Métrique | Valeur |
|---|---|
| Accélération médiane par image | 3.2x (≈ 69% de réduction du temps) |
| IC bootstrap 95% (médiane) | 3.0–3.3x |
| Plage interquartile | 2.7–3.4x |
| Plage complète | 1.6–5.1x |
| Scènes / tâches | 38 scènes / 1,419 tâches |
| Référence | RTX 3080/2080 génération précédente (10–12 GB) |
Nous utilisons une médiane de médianes : chaque scène contribue par la médiane de ses propres temps par image sur chaque côté, et les 3.2x représentent la médiane de ces 38 ratios, de sorte qu'une image lente ne peut pas fausser le résultat. La dispersion est aussi importante que la valeur centrale — la moitié médiane des scènes se situe entre 2.7x et 3.4x, et la plage complète s'étend de 1.6x à 5.1x.
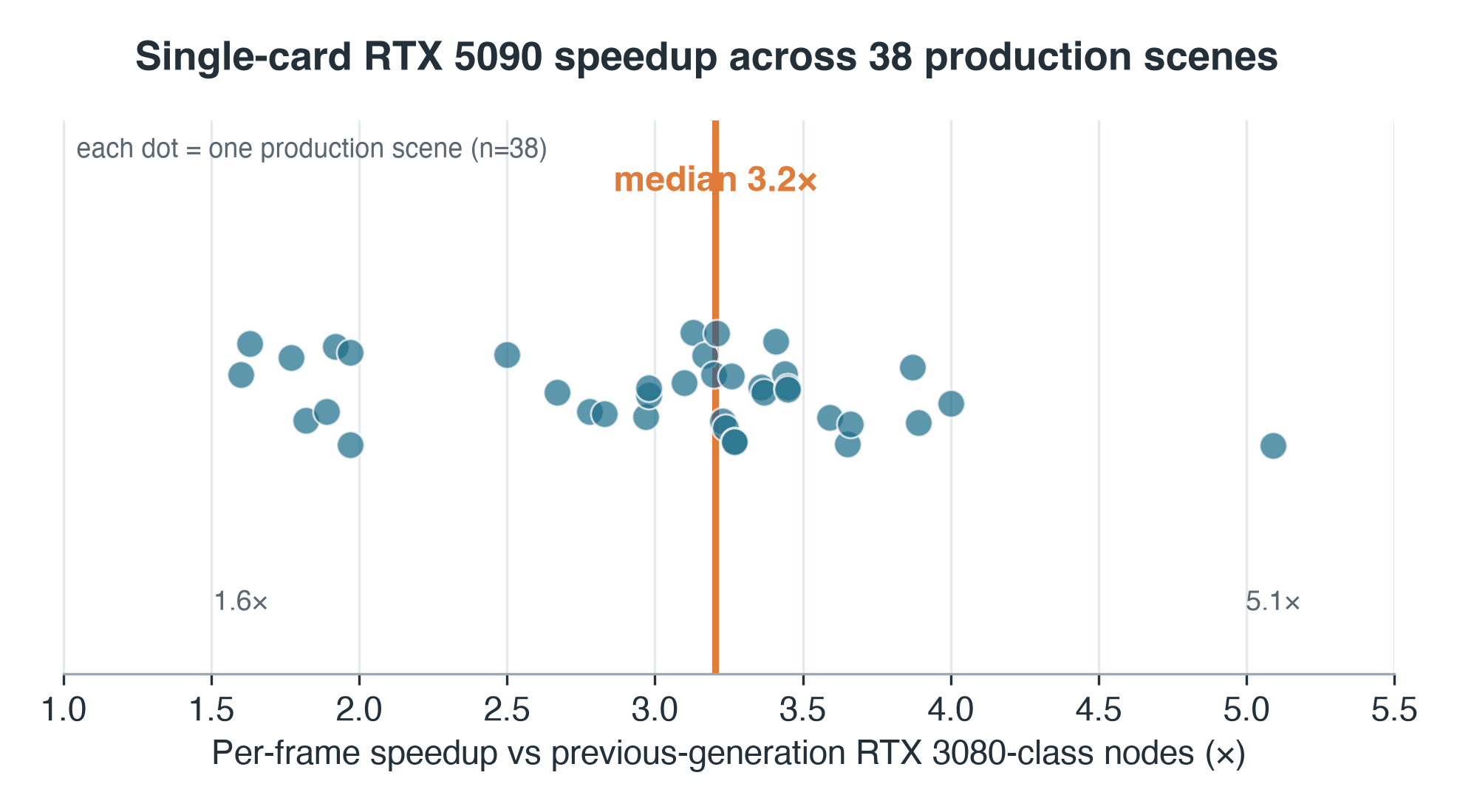
Distribution de l'accélération RTX 5090 par scène sur 38 scènes de production Blender Cycles, médiane 3.2x avec une dispersion de 1.6x à 5.1x
Accélération par scène, RTX 5090 par rapport aux nœuds de génération précédente sur lesquels ces travaux ont tourné — échantillon de production de 38 scènes. Médiane 3.2x ; plage 1.6–5.1x.
Deux mises en garde accompagnent ce chiffre, et elles méritent d'être mentionnées ici plutôt qu'en note de bas de page. Premièrement, le côté de génération précédente fonctionnait en mode virtualisé — passage GPU dans une machine virtuelle — de sorte qu'une part non mesurée de ces 3.2x correspond à une surcharge de virtualisation, et non à du silicium brut ; la comparaison directe sur le même hôte, un RTX 5090 contre un RTX 4090 actuel, est le suivi contrôlé que nous devons effectuer et que nous n'avons pas encore réalisé. Deuxièmement, les 38 scènes ne sont pas un tirage aléatoire depuis la file d'attente : ce sont les travaux qu'un utilisateur a choisi de rendre à nouveau sur les deux générations, ce qui biaise l'échantillon vers des travaux plus longs et itératifs — lisez donc la distribution comme celle des paires appariées, non comme celle de l'ensemble de la file d'attente.
Trois notes d'honnêteté sont essentielles ici. Il s'agit de données observationnelles — les utilisateurs ajustent parfois leurs paramètres entre les re-rendus, et nous n'avons pas figé leurs scènes. La comparaison est nœud contre nœud : le côté 5090 est une carte bare-metal, tandis que la génération précédente tourne en GPU passthrough dans des machines virtuelles, donc une partie de l'écart tient à la configuration, pas au silicium. Et la référence est le matériel de la classe RTX 3080/2080 sur lequel ces travaux ont réellement tourné — pas un RTX 4090 actuel ; une comparaison tête-à-tête avec la carte actuelle est un exercice séparé et contrôlé que nous n'avons pas effectué. Ce sont des chiffres issus d'un seul nœud, Cycles uniquement ; ils décrivent notre file d'attente et ne doivent pas être généralisés à d'autres moteurs ou configurations matérielles.
Ce qui distingue une scène à 1.6x d'une scène à 5.1x est en partie visible dans les données. En représentant l'accélération de chaque scène en fonction de la durée de ses images sur l'ancien matériel, une tendance positive lâche apparaît — Spearman ρ ≈ 0.34 (bilatéral p ≈ 0.04). Les images courtes, limitées par les surcharges fixes, se trouvent en bas de la distribution : quand une image se termine en cinq secondes, le coût fixe par tâche — chargement de la scène, synchronisation, l'ancienne couche de virtualisation — absorbe la majeure partie du temps d'horloge, et une carte plus rapide a peu de marge d'action. Les images plus lourdes, limitées par le calcul, bénéficient davantage. Mais il y a une réelle dispersion : une scène lourde est restée à seulement 1.6x parce que son goulot d'étranglement n'était pas le GPU mais, vraisemblablement, le stockage ou une étape limitée par le CPU. La médiane dit une chose ; la plage dit que cela dépend de la scène.
Le débruitage IA était déjà la norme
Si l'on demande où se situe réellement l'IA dans un pipeline de rendu en production en 2026, nos logs donnent une réponse peu glamour : dans le débruiteur. Environ 83% des travaux Cycles sur le nœud 5090 ont exécuté un passage de débruitage IA — OptiX ou Intel Open Image Denoise — et le taux sur nos nœuds de génération précédente est pratiquement identique. La nouvelle carte n'a pas instauré cette habitude ; elle était déjà standard sur l'ancien matériel et l'est restée sur le nouveau. Pour un pipeline à forte utilisation du débruitage, un changement de génération n'achète pas une capacité d'« IA » qui était déjà là — il achète du débit de path tracing autour d'une étape déjà routinière. Ce chiffre est intentionnellement limité à Cycles ; méfiez-vous de tout pourcentage « IA » à l'échelle d'une farm qui n'est pas associé à un seul moteur.
La VRAM dans la pratique
Cycles écrit le pic de mémoire périphérique dans le log de rendu — un proxy modeste mais utilisable de ce que la production exige réellement de la VRAM. Sur les 57 travaux Cycles pour lesquels cette ligne a été enregistrée, la mémoire de périphérique de rendu au pic était d'environ 5.6 GB à la médiane et de 11.5 GB au 90e percentile. Nos cartes de génération précédente sont des composants de 10–12 GB, de sorte que le travail médian aurait tenu — mais le travail au 90e percentile frôlait déjà leur plafond. Et la queue s'étend encore plus loin : le travail le plus lourd a consigné environ 37 GB, dépassant même les 32 GB du 5090 — le genre de scène qui, sur un GPU, implique un repli vers le CPU ou pas de rendu du tout. Le log ne contient aucune métadonnée de scène, nous ne pouvons donc pas dire de quel type de scène il s'agissait — seulement de sa classe : un jeu de travail de 37 GB est la signature d'une géométrie lourde, de textures haute résolution ou de volumes, le genre de travail qui dépasse même une carte de 32 GB et qui, sur un seul GPU, s'arrête tout simplement. La règle opérateur reste valable : vous dimensionnez la VRAM pour la queue, pas pour la médiane. C'est pourquoi la mémoire embarquée surdimensionnée et la capacité partagée de cloud render farm GPU existent toutes les deux — pour que vous puissiez accéder à une carte plus grande par travail plutôt que d'en acheter une.
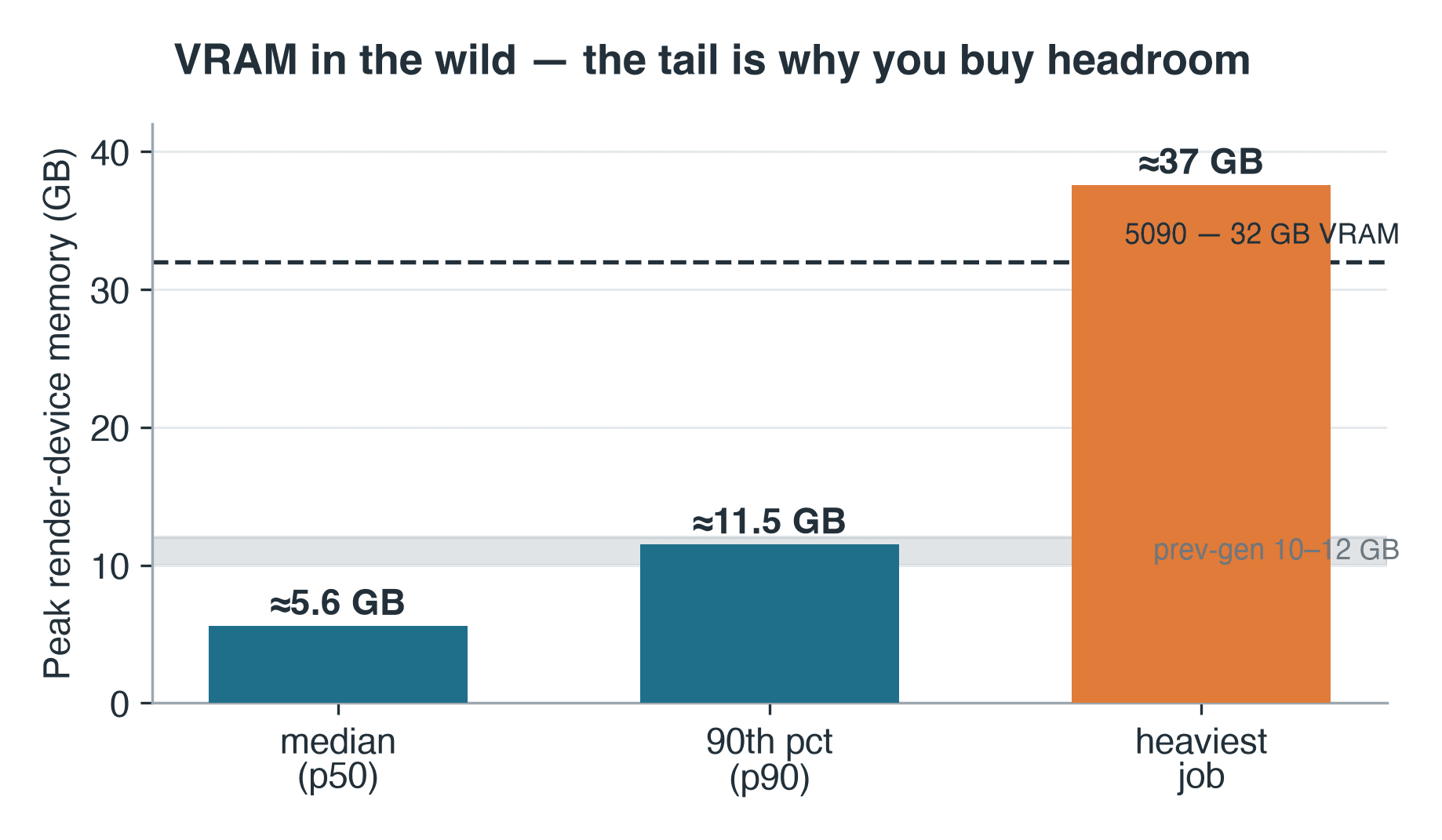
Mémoire de rendu périphérique maximale pour les travaux Blender Cycles sur le nœud RTX 5090 : médiane 5.6 GB, 90e percentile 11.5 GB, travail le plus lourd 37 GB
Pic de mémoire de rendu périphérique sur 57 travaux Cycles enregistrés. Le travail le plus lourd a dépassé les 32 GB propres au 5090.
Un seul pilote, et une consommation maîtrisée
La découverte la moins spectaculaire est celle que nous aurions le plus voulu connaître avant d'acheter. Un seul pilote — 581.80, sous CUDA 13.0 — a fonctionné pendant toute la période sans aucun changement : pas de retour arrière, pas de remplacement en cours de fenêtre. Pour du matériel en début de cycle sur une file d'attente de production, un log de pilote ennuyeux est un compliment.
La consommation électrique était tout aussi calme. Sur un banc de test contrôlé des mêmes cartes en charge soutenue, chacune consommait environ 360–375 W (pic à environ 400 W) à 68–83 °C — la carte supérieure d'une paire empilée étant la plus chaude, mais bien en dessous de la classe nominale ~575 W. Prévoyez ce tirage soutenu, pas le pic nominal. L'énergie par image rendue représente environ 2.5 Wh pour une image Cycles médiane d'environ 24 secondes — mais considérez cela comme une inférence : elle repose sur la consommation du banc de test et a été calculée pour le 5090 seul, sans mesure comparative avec les nœuds plus anciens.
Pourquoi ces notes démarrent avec Blender
Sur les 90 derniers jours, les travaux GPU représentaient environ un quart de tout ce que notre farm a rendu — le reste est du travail CPU. Au sein du mix GPU, Cycles représente environ 74% des travaux et Redshift arrive clairement en deuxième position avec environ 15%, ce qui explique pourquoi un article sur le RTX 5090 en render farm commence par le rendu cloud Blender. Pour comprendre comment plusieurs de ces cartes se comportent ensemble, consultez nos notes complémentaires sur les performances du cluster RTX 5090, et pour la question de la mémoire spécifiquement, où les limites de VRAM se font sentir sur les scènes complexes.
Deux enseignements se dégagent de cette file d'attente. Premièrement, la production n'est pas un benchmark — une carte qui affiche un bon chiffre en laboratoire doit encore absorber les surcharges de virtualisation, les charges de travail mixtes et les scènes pour lesquelles elle n'a pas été optimisée, et le résultat est une distribution, pas un point. Deuxièmement, la médiane n'est pas la queue. Une accélération typique de 3.2x et un pic de mémoire de 37 GB sur un seul travail sont tous deux vrais simultanément, et vous planifiez la capacité en tenant compte des deux. La carte est véritablement rapide là où le travail est lourd. Là où ce n'est pas le cas, la file d'attente vous explique pourquoi.
Méthode, en bref
Chaque chiffre présenté ici provient des propres enregistrements de tâches de notre planificateur, et non d'un test mis en scène. Le temps par image est le temps d'horloge de la tâche divisé par le nombre d'images ; l'accélération principale est une médiane de médianes par scène sur les 38 paires appariées, et l'intervalle de confiance est un bootstrap de 20,000 échantillons. Notez quel échantillon étaie quelle affirmation : 38 scènes appariées pour l'accélération, 57 travaux enregistrés pour la VRAM, et un banc de test contrôlé séparé pour la consommation électrique et thermique — pas la file d'attente de production. Les 18 tâches en échec (sur environ 4,900) sont comptées comme des échecs, pas ignorées ; le planificateur enregistre l'état mais pas la cause, nous les laissons donc non élucidées plutôt que de deviner. Rien de tout cela n'est difficile à reproduire dans l'esprit — c'est ce que tout opérateur peut extraire de ses propres logs de file d'attente, et nous sommes heureux d'expliquer la méthode plus en détail à un studio qui le souhaiterait.
FAQ
Q: De combien le RTX 5090 est-il plus rapide que la génération précédente pour Blender Cycles ? A: Sur 38 scènes de production appariées (même scène et même utilisateur sur les deux générations), le temps médian par image a diminué d'environ 69% — soit une accélération médiane de 3.2x, avec un intervalle de confiance bootstrap à 95% de 3.0–3.3x. Les scènes individuelles s'échelonnaient de 1.6x à 5.1x. Il s'agit de données observationnelles nœud contre nœud, pas d'un benchmark contrôlé.
Q: Pourquoi les accélérations varient-elles autant d'une scène à l'autre ? A: L'accélération suit la charge de travail par image selon une tendance positive lâche (Spearman ρ ≈ 0.34). Les images courtes, limitées par les surcharges fixes, bénéficient le moins car le coût fixe par tâche — chargement de la scène, synchronisation, l'ancienne couche de virtualisation — domine ; les images plus lourdes, limitées par le calcul, bénéficient davantage. Une scène lourde est restée à 1.6x parce que son goulot d'étranglement était le stockage ou une étape limitée par le CPU, pas le GPU.
Q: S'agit-il d'un benchmark contrôlé comparable à mon propre matériel ? A: Non. Ce sont des notes de terrain observationnelles issues d'un seul nœud de production, Blender Cycles uniquement. Les utilisateurs ont ajusté leurs propres scènes entre les re-rendus, et la comparaison est nœud contre nœud — un 5090 bare-metal contre des nœuds de génération précédente virtualisés — donc une partie de l'écart tient à la configuration, pas au silicium. La référence est le matériel de la classe RTX 3080/2080, pas un RTX 4090 actuel.
Q: Quelle quantité de VRAM les scènes de production ont-elles réellement utilisée ? A: Sur 57 travaux Cycles enregistrés, le pic de mémoire de rendu périphérique était d'environ 5.6 GB à la médiane et de 11.5 GB au 90e percentile. Le travail individuel le plus lourd a enregistré environ 37 GB — dépassant les 32 GB propres au 5090 — ce qui, sur un GPU, signifie un repli vers le CPU ou pas de rendu. Dimensionnez la VRAM pour la queue, pas pour la médiane.
Q: Le RTX 5090 a-t-il modifié la fréquence d'utilisation du débruitage IA ? A: Non. Environ 83% des travaux Cycles sur le nœud 5090 ont exécuté un passage de débruitage IA (OptiX ou Intel Open Image Denoise) — et le taux était pratiquement identique sur la génération précédente. Le débruitage IA était déjà standard ; la nouvelle carte n'a modifié que la vitesse de tout ce qui l'entoure.
Q: Quelle était la stabilité du pilote pendant les sept semaines ? A: Un seul pilote — 581.80 sous CUDA 13.0 — a fonctionné pendant toute la fenêtre de 51 jours sans aucun changement : pas de retour arrière, pas de remplacement en cours de fenêtre. Pour du matériel en début de cycle sur une file d'attente de production, cette stabilité est en elle-même un résultat significatif.
Q: Quelle était la consommation électrique et la température en charge ? A: Sur un banc de test contrôlé en charge soutenue, chaque carte consommait environ 360–375 W, avec un pic à environ 400 W, à 68–83 °C — largement en dessous de la classe nominale ~575 W de la carte. L'énergie par image représente environ 2.5 Wh, ce qui est une inférence à partir de cette mesure sur banc de test, calculée pour le 5090 uniquement.
Q: Ces chiffres s'appliquent-ils à d'autres moteurs de rendu ? A: Non. Cette étude est limitée à Blender Cycles GPU, sur un seul nœud. Les autres moteurs enregistrent le débruitage, la mémoire et les temps différemment. Considérez ces chiffres comme des notes de terrain spécifiques à Cycles, pas comme une affirmation valide pour l'ensemble d'une farm ou pour tous les moteurs.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



