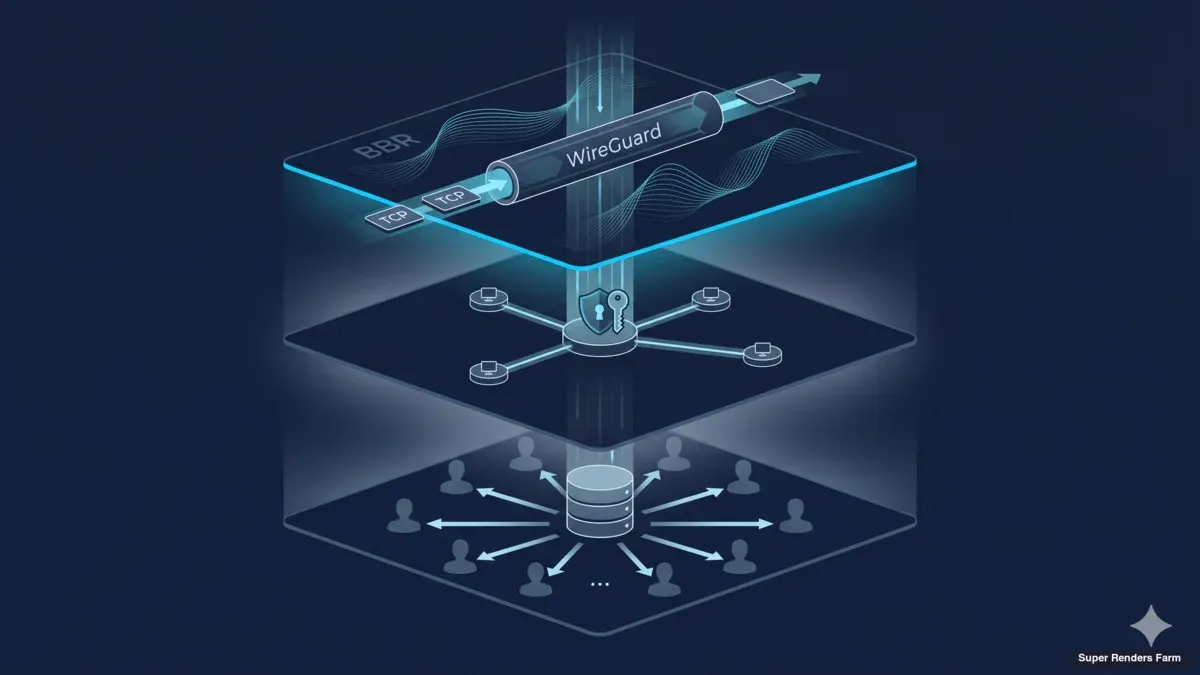
Arquitectura de render farm cross-country: WireGuard, BBR y caché SMB compartida
Resumen
Introducción
Construir una render farm que vive en un solo rack, en una sola sala, sobre un solo switch, es un problema resuelto. Las tiradas de cable son cortas, los tiempos de ida y vuelta se miden en microsegundos, y la biblioteca de assets vive en un NAS desde el que cada worker lee a la velocidad del puerto del switch. La mayoría de las guías de render farm asumen silenciosamente esta topología, porque es aquella en la que todo simplemente funciona.
La arquitectura cambia cuando la granja tiene que abarcar más de un sitio. ¿Un cluster de 20 nodos dividido entre dos ubicaciones en la misma metrópoli ya es un problema de red diferente; un cluster que se extiende entre países es otro problema más. Los tiempos de ida y vuelta pasan de submilisegundo a decenas o cientos de milisegundos, el jitter en rutas ISP públicas se convierte en un ruido de fondo constante, la MTU entre dos endpoints cualesquiera se vuelve una pregunta en lugar de una suposición, y la biblioteca de assets que vivía en un solo NAS ahora tiene que o bien replicarse a cada sitio o bien cachearse bajo demanda. El enfoque ingenuo — mismo NAS, misma cola de submission, mismo SMB share, solo cables más largos — aparece como modos de fallo silenciosos: sesiones que se conectan y mantienen conexión pero nunca transfieren un frame, submissions de render que se quedan al 99 por ciento porque el push final de assets a un nodo remoto agota el timeout, license check-outs que tienen éxito localmente y fallan remotamente sin razón obvia.
Este artículo describe la arquitectura que operamos para deployments de render farm cross-country — la topología WireGuard hub-and-spoke, el control de congestión TCP BBR, la disciplina de MSS clamping, una capa de caché SMB3 compartida y una superficie de firewall endurecida. Los componentes son comunes, las decisiones de configuración no siempre son obvias, y las lecciones aprendidas nos han costado sobre todo tiempo de debugging antes de costarle dinero a nadie. La audiencia es arquitectos de infraestructura e ingenieros DevOps que están dimensionando un build similar, más decisores de TI que quieren saber en qué se está metiendo su equipo. Para un walkthrough operativo paso a paso del mismo stack, nuestra operational deployment guide cubre la secuencia de rollout día a día. Para una visión general, la página cross-country render farm overview cubre el caso de negocio.
Topología WireGuard hub-and-spoke

Túnel cifrado que conecta dos sitios distantes
La capa de transporte del cluster es WireGuard. Lo usamos tanto para conexiones de clientes (estaciones de trabajo de los artistas hacia la granja) como para el enlace site-to-site entre el datacenter principal y el sitio secundario. La topología es hub-and-spoke: un servidor WireGuard corre en el gateway del datacenter principal, cada peer cliente conecta a ese hub, y el sitio secundario conecta como otro peer con una subred enrutada detrás.
El atractivo de WireGuard para este tipo de build es sobre todo mecánico. El protocolo usa criptografía moderna fija (Curve25519 para intercambio de claves, ChaCha20-Poly1305 para el data plane, BLAKE2s para hashing), corre en el kernel de Linux en lugar de en userspace, y se configura con un archivo clave-y-AllowedIPs que cabe en una pantalla. Comparado con OpenVPN, la superficie de configuración es alrededor de un orden de magnitud menor, el throughput en un nodo Xeon típico es varias veces mayor al mismo coste de CPU, y el codebase es lo bastante pequeño como para que la auditoría sea tratable. Comparado con IPsec, no hay fase de negociación IKE que pueda fallar de maneras interesantes, no hay danza de identidad de peer en el rekey, y no hay daemon de userspace que pueda crashear. Hemos operado los tres en deployments pasados; las configuraciones WireGuard son las que se mantienen sin intervención.
La disposición hub-and-spoke significa que cada flujo site-to-site transita por el gateway del datacenter principal. Para un deployment cross-country de dos sitios este es el tradeoff correcto: concentra la superficie de ataque de IP pública en una sola box, aplica un único conjunto de reglas de enrutamiento y firewall en un único punto de estrangulamiento, y hace el monitoring directo porque cada handshake y contador de flujo es visible en el hub. Un full mesh ahorraría un hop en el tráfico site-to-site pero multiplicaría el trabajo de configuración y la superficie de ataque pública por el cuadrado del número de sitios. Para dos o tres sitios, hub-and-spoke gana en simplicidad operativa.
El hub escucha en el puerto UDP 51820 (por defecto), y ese es el único puerto que la interfaz pública acepta. No hay fallback TCP. Solo-UDP es deliberado — el comportamiento de congestión de WireGuard está construido alrededor de datagramas UDP, y un túnel TCP-sobre-TCP degrada fiablemente el throughput a larga distancia. En redes que bloquean UDP por completo lo tratamos como una restricción del lado cliente y enrutamos alrededor en otra capa.
Cada peer cliente está configurado con una sola entrada AllowedIPs que cubre la subred interna del cluster. El peer site-to-site tiene AllowedIPs cubriendo la subred LAN remota para que el kernel sepa qué paquetes encapsular. PersistentKeepalive se fija a 25 segundos en cada peer detrás de NAT, lo que mantiene viva la entrada UDP conntrack entre handshakes. Lo hemos omitido exactamente una vez y pasamos los siguientes dos días debuggeando «caídas de conexión cada 90 segundos en el sitio secundario»; en el tercer sitio, PersistentKeepalive fue la primera línea del archivo de config.
Control de congestión TCP BBR
Una vez que el túnel WireGuard está arriba, la siguiente capa es el comportamiento TCP. Linux trae CUBIC como algoritmo de control de congestión por defecto. CUBIC escala su ventana de congestión en una curva cúbica como función del tiempo desde el último evento de pérdida, lo que funciona en enlaces donde la pérdida de paquetes es una señal fiable de congestión. La trampa está en la palabra «fiable». En rutas ISP de larga distancia, la pérdida de paquetes a menudo no es congestión en absoluto — es desbordamiento de cola en un router intermedio, un enlace inalámbrico retransmitiendo de manera invisible a TCP, un rate-limiter mal configurado, o un transitorio de enrutamiento. CUBIC trata todo eso como congestión y colapsa la ventana incluso cuando el bottleneck tiene mucha capacidad libre.
BBR (Bottleneck Bandwidth and Round-trip propagation time) es la alternativa que usamos en enlaces cross-country. BBR ignora la pérdida de paquetes como señal primaria de congestión y en su lugar mide directamente el ancho de banda del bottleneck y el RTT mínimo de la ruta. Luego marca el ritmo del emisor a la tasa del bottleneck, con una ventana dimensionada para mantener un producto ancho-de-banda-por-retardo en vuelo. En un long fat network — gran ancho de banda, RTT alto, pérdida aleatoria modesta — BBR mantiene la tubería llena donde CUBIC dividiría su ventana a la mitad repetidamente por pérdidas no congestivas.
El efecto práctico en una render farm es medible. Las transferencias de assets a través de un túnel cross-country, en el mismo hardware, pasan de throughput a saltos con stalls frecuentes bajo CUBIC a una curva de throughput más suave cerca de la capacidad real de la ruta bajo BBR. Los números varían con la ruta ISP y la hora del día, pero pasar el lado emisor del cluster a BBR ha producido de forma constante mayor throughput en régimen estacionario y tail latencies más cortas en las rutas que operamos.
Usamos la implementación BBR que está en el kernel mainline de Linux desde la versión 4.9, activada con un sysctl de una línea: net.core.default_qdisc=fq más net.ipv4.tcp_congestion_control=bbr. Ambas líneas van en /etc/sysctl.d/99-bbr.conf y sobreviven al reboot. El BBR del kernel mainline es la versión que operamos en producción desde hace años. Existen ramas de investigación más nuevas del algoritmo pero introducen cambios de comportamiento que no hemos tenido tiempo de validar en nuestras rutas ISP específicas; el camino de upgrade es un ítem de roadmap separado.
BBR se fija en el lado emisor de cualquier flujo grande — la box de caché y el render manager para transferencias de assets, el lado receptor para cualquier flujo en sentido inverso como license callbacks y log shipping. BBR en un extremo basta para ver la mayor parte del beneficio; BBR en ambos extremos ayuda un poco más en flujos bidireccionales.
TCP MSS clamping
De todos los problemas de red que aparecen después de que el túnel WireGuard sube, el que más tiempo de debugging nos ha costado: la MTU. El síntoma es consistente y confuso: los paquetes pequeños pasan limpios (el ping funciona al tamaño por defecto, SSH eco los caracteres, el handshake WireGuard completa), pero los paquetes grandes desaparecen en el túnel y nunca salen. Los handshakes TLS cuelgan a la mitad. Las sesiones SMB conectan, fallan en el primer read grande. Las sesiones RDP se establecen, muestran la pantalla de login, se congelan cuando el usuario teclea algo. Los servidores de licencias hacen checkout de tokens pequeños y agotan timeout en los grandes.
La causa es el overhead de encapsulación del túnel WireGuard reduciendo la MTU efectiva por debajo de la MTU del camino que los endpoints negocian basándose en sus interfaces LAN. WireGuard añade 60 bytes de overhead (20 IPv4 + 8 UDP + 32 WireGuard) a cada paquete. Una carga útil de 1500 bytes en el lado LAN se convierte en un paquete de 1560 bytes en el lado público, fragmentado o descartado según el camino. Path MTU Discovery (PMTUD) se supone que arregla esto enviando ICMP «Fragmentation Needed» de vuelta al emisor, pero PMTUD se rompe en la internet moderna rutinariamente — ICMP a menudo se filtra upstream del emisor, la señal «usa paquetes más pequeños» nunca llega, y el túnel descarta paquetes grandes silenciosamente.
La solución es TCP MSS (Maximum Segment Size) clamping. Configuramos la interfaz WireGuard del lado del router para reescribir la opción MSS en cada TCP SYN que cruza el túnel, capándola a la MTU efectiva del túnel menos el overhead TCP/IP. Con una MTU de túnel de 1420 bytes (una elección segura que sobrevive a la mayoría de variaciones upstream), el MSS clamp es 1380. Cualquier conexión TCP que arranca tras la regla negocia un MSS de 1380 bytes, el emisor emite paquetes de 1420 bytes que pasan limpios, y los drops silenciosos se detienen.
El clamp va en la cadena FORWARD del host WireGuard en modo router, en la interfaz wg0, aplicado a paquetes de handshake TCP. El idiom iptables es iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (o --set-mss 1380 para un valor fijo). nftables tiene el equivalente. La regla debe aplicar en ambas direcciones si ambos lados inician conexiones TCP, lo que en una render farm es el caso común.
No hay manera de sentir que falta el MSS clamp hasta que algo grande falla — las cargas pequeñas testean bien. El clamp es una de esas configuraciones que no cuestan nada cuando se aplican correctamente y producen horas de debugging confuso cuando se omiten. Lo metimos en la checklist de deployment estándar después de que un ticket de soporte de las 6 a. m. sobre «las transferencias SMB se cuelgan en tamaños aleatorios» se resolviera a las 8 a. m. con una regla iptables de una línea.
Diseño de caché SMB3 compartida

Caché compartida que sirve assets localmente a los workers de render
Las cargas de render son pesadas en assets y dominadas por lectura. Una escena típica va desde unos cientos de megabytes hasta varias decenas de gigabytes — geometría, texturas, simulation caches y archivos de proyecto de la DCC de rendering. A través de un cluster de 20 nodos la misma escena debe ser legible por cada worker que tome un frame. El enfoque ingenuo es copiar la escena a cada nodo antes de que arranque el render. Con una escena de 10 GB y 20 nodos, eso mueve 200 GB a través de la red para lo que es un working set de 10 GB. Multiplica por decenas de escenas al día por estudio y el coste de duplicación domina el build.
La arquitectura que usamos en su lugar es una única capa de caché compartida por sitio, expuesta a los workers de render mediante SMB3. La caché es una box Ubuntu 22.04 LTS con un solo SSD (clase NVMe), formateada ext4, con el directorio de caché expuesto por Samba vía SMB3. Cada worker de render monta el share SMB en el boot mediante cifs-utils y lee archivos de assets desde la caché como si fueran locales. El primer worker que necesita un asset determinado dispara un pull desde el asset store cloud upstream a la caché; los workers siguientes y frames siguientes leen desde la caché LAN a velocidad de puerto de switch. Por sitio, la box de caché está a un hop de switch de cada worker; el asset llega al cluster una vez y sirve a veinte workers.
Algunas decisiones de diseño merecen desempaquetarse. La caché es un solo SSD, no un array RAID, porque la caché es por definición reconstruible desde el asset store cloud upstream. Si el SSD falla, el peor caso es un retraso mientras la siguiente petición de asset pull desde la nube, más un rebuild de cualquier render en vuelo que dependiera de un archivo intermedio no cacheado. Mitigamos el riesgo «render en vuelo» rsynceando los outputs de render terminados desde la caché a un NAS al final de cada job, así un fallo de SSD no pierde ningún entregable ya enviado. Saltarse RAID ahorra el coste de hardware, la complejidad del controlador y el overhead de amplificación de escritura que algunos niveles RAID imponen a los SSD.
El sistema de archivos es ext4 en lugar de ZFS o btrfs. Hemos usado ZFS y btrfs en builds pasados, y los feature sets que aportan (snapshots, checksumming, compresión) son beneficios reales en algunos workflows. Para una caché de render, el patrón de lectura es sobre todo secuencial y limitado por ancho de banda en lugar de transaccional, y el contenido de la caché es por diseño descartable. Ext4 mantiene la pila de almacenamiento simple y retira una clase de modos de fallo del set de postmortems de incidentes. Operadores que ya operan ZFS a escala pueden usarlo aquí sin problema, pero para un deployment donde la simplicidad de la capa de caché pesa más que ganancias de feature individuales, ext4 es la elección.
La estrategia de pre-warm importa. Antes de que un job dirigido por deadline arranque, el artista o el TD de pipeline empuja los assets de la escena a la caché mediante una herramienta de pre-staging. El primer frame que aterriza en un worker lee entonces desde una caché caliente en lugar de esperar un cold pull. El paso pre-warm es opcional para jobs que corren de noche (cold pull va bien) e importante para jobs que deben terminar en una ventana ajustada.
El share de caché cross-site funciona a través del túnel WireGuard site-to-site. El sitio secundario tiene su propia box de caché y workers, pero su caché también puede alcanzar la caché del sitio primario por el túnel para cualquier asset que esté caliente allí y no aún localmente. En la práctica configuramos la caché secundaria para que haga fallback a la caché primaria en misses antes de ir al cloud upstream — manteniendo el tráfico inter-sitio en el túnel cifrado y evitando cargos de egress cloud por assets que ya viven dentro de la granja. Este es uno de los beneficios prácticos de un MSS clamp correcto: las transferencias grandes de assets entre sitios se mueven a un throughput que satura el túnel en lugar de stallar en el techo de paquetes pequeños.
Servicios internos: DNS y NTP
Un cluster necesita conocer sus propios hostnames. La elección ingenua es poner cada host en /etc/hosts en cada nodo, lo que funciona con dos nodos y empieza a fallar con veinte. La elección correcta es DNS interno, y operamos dnsmasq en la misma box gateway que corre WireGuard. El cluster vive en una zona .lan — cache.lan, rn-a01.lan hasta rn-a20.lan, mgr.lan, nas.lan. Cada nombre resuelve a la IP interna correspondiente en la subred del cluster, y el /etc/resolv.conf de cada worker apunta al servidor dnsmasq.
El beneficio es que cualquier reasignación de IP, swap de host o cambio de topología requiere tocar un archivo de configuración (el archivo de hosts de dnsmasq) en lugar de cada nodo. El beneficio se extiende al túnel site-to-site: un worker en el sitio secundario puede resolver cache.lan hacia la caché secundaria mediante su dnsmasq local, y resolver mgr.lan hacia el render manager del sitio primario mediante DNS forwarding a través del túnel. Hemos, en el pasado, usado literales IP en configuraciones de render manager y lo hemos lamentado cada vez que un nodo se movía.
La trampa de dnsmasq que nos ha mordido — y muerde a suficientes operadores como para merecer su propio párrafo — es la línea interface=. dnsmasq, por defecto, escucha en todas las interfaces, lo cual parece bien hasta que te das cuenta de que la box gateway tiene al menos tres: el WAN público, el LAN interno y el túnel WireGuard wg0. Si pones interface=eth1 pensando que estás restringiendo dnsmasq al LAN, acabas de dejar el sitio secundario conectado por WireGuard incapaz de resolver cualquier nombre .lan, porque wg0 no está listada. La línea correcta es interface=eth1,wg0 (o el equivalente para tus nombres de interfaz), o una línea except-interface= que nombre solo el WAN. Hemos visto esta mala configuración producir el síntoma «el sitio remoto puede pingar la caché por IP pero no puede SMB-montarla por hostname» más de una vez.
NTP es el otro servicio interno. Operamos chrony en el gateway como servidor NTP, con el propio gateway sincronizado a pools NTP públicos y cada nodo sincronizado al gateway. La motivación es la correlación de logs del render manager: si un frame falla, la entrada de log del render manager y la del worker deben compartir una línea de tiempo a la milisegundo. La deriva de reloj en un cluster de 20 nodos, sobre todo cuando los nodos llevan semanas up, se vuelve una fuente real de confusión de debugging «esta entrada de log no encaja». chrony mantiene la deriva por debajo de unos pocos milisegundos y retira esa clase de confusión.
Firewall: ufw con default-deny inbound
El gateway está en la internet pública, y su postura de firewall es «default-deny inbound, default-allow outbound, default-allow forward para tráfico tunelado». En Ubuntu 22.04 LTS, la herramienta que usamos es ufw — el Uncomplicated Firewall. ufw es un frontend sobre nftables (o iptables en sistemas más antiguos) que expone una pequeña superficie de comando y se niega a hacer cosas sorprendentes. Para una box gateway donde la config de firewall es la diferencia entre «segura» y «comprometida en horas», una superficie de comando pequeña es una feature.
La superficie pública configurada es una regla: ufw allow 51820/udp comment 'wireguard'. Nada más en inbound. SSH desde el lado público está cerrado; administramos el gateway a través del túnel WireGuard desde una IP de operador conocida. SMB, DNS, NTP y HTTPS (para la UI del render manager) están todos en interfaces internas solamente. Los ajustes ufw default deny incoming y ufw default allow outgoing cubren el resto de la superficie.
La cadena forward requiere cuidado. El gateway actúa como router para tráfico de cluster entre wg0 y el LAN interno, y la postura por defecto de ufw es denegar forward. Ponemos DEFAULT_FORWARD_POLICY="ACCEPT" en /etc/default/ufw y luego acotamos las reglas forward a pares source/destination específicos en la cadena FORWARD. La combinación — default-deny incoming, default-deny forward en boot, luego ACCEPTs forward explícitos entre subredes de cluster conocidas — da una postura auditable que no enruta accidentalmente tráfico entre sitios que no deberían hablar.
Los firewalls de host por-nodo extienden esta capa Tier-1 gateway a una capa Tier-2 host. Cada nodo de render corre ufw localmente con reglas que solo permiten al render manager y la box de caché del cluster iniciar conexiones. Un worker comprometido no puede pivotar a otro worker sin antes vencer el firewall de host, y el gateway loguea cada intento de forward inesperado. El modelo dos-tiers — gateway Tier 1, por-host Tier 2 — es el mismo que cualquier cluster on-prem razonable opera; lo que cambia en un deployment cross-country es que la superficie Tier 1 ahora defiende contra la internet pública. El gateway es el perímetro; los firewalls por-host son defensa en profundidad.
Diagrama de arquitectura

Topología de render farm hub-and-spoke, un único túnel seguro hacia internet
La descripción textual anterior se mapea al siguiente diagrama ASCII, el mismo que dibujamos en pizarra durante los kick-offs de deployment:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
El diagrama es intencionalmente genérico — sin par de ciudades específico, sin ISP específico, sin numeración de subred específica. Cada sitio que desplegamos sigue la misma forma; los números varían.
Características de rendimiento
Los números de throughput dependen de la ruta ISP y la hora del día, pero la forma del rendimiento es consistente a través de los deployments que hemos operado. En un túnel entre dos sitios de la misma metrópoli (RTT sub-10 ms), las transferencias grandes se mueven cerca de la tasa de línea en el enlace bottleneck, y un worker de render leyendo desde caché se siente indistinguible de un worker leyendo desde disco local. En un túnel entre sitios en países diferentes (50–150 ms RTT según la ruta), las transferencias grandes se asientan en un throughput estable marcado por BBR cerca del ancho de banda del bottleneck, con el MSS clamp manteniendo el tamaño por segmento alineado con la MTU del túnel.
La lectura desde la caché LAN local es donde la arquitectura se gana el sustento. Un worker de render leyendo un paquete de texturas de 4 GB desde cache.lan mediante SMB3 en una LAN gigabit conmutada termina aproximadamente en el tiempo que el puerto switch tarda en empujar los bytes — decenas de segundos en lugar de los plazos de varios minutos que tomaría un cold pull desde almacenamiento cloud cross-country. Para un job que toca el mismo paquete de texturas a lo largo de doscientos frames, la cache hit ratio se aproxima a 1,0 tras la primera lectura caliente, y el túnel cross-country se usa solo para el pre-warm original, la sync cross-site de outputs del sitio secundario y la telemetría en régimen estacionario.
Para frames de render 4K y 8K específicamente, el valor de la arquitectura escala con el tamaño de frame. Una secuencia EXR 8K con múltiples AOVs puede empujar outputs de frame individuales a los cientos de megabytes, y 200 de ellos son una escritura de decenas de gigabytes por escena. Mantener esa escritura en local-LAN y enviar solo el output comprimido final por el túnel es la diferencia entre «termina por la noche» y «termina cuando el upload acaba, mañana en algún momento».
Preguntas frecuentes
Q: ¿Por qué WireGuard y no OpenVPN? A: La superficie de configuración de WireGuard es menor, su throughput en data plane consistentemente más alto en el mismo hardware, su implementación en kernel retira un modo de fallo userspace, y su postura de cifrado fijo retira una clase de bugs de negociación. OpenVPN es una herramienta sólida con veinte años de historial operativo; usamos WireGuard porque las propiedades operativas para un túnel de cluster de larga duración son mejores en las métricas que nos importan. En rutas donde el UDP de WireGuard está bloqueado completamente, OpenVPN sobre TCP 443 es un fallback legítimo — pero TCP-sobre-TCP introduce sus propias patologías, y lo tratamos como una restricción del lado cliente.
Q: ¿Cómo ayuda BBR en rutas ISP ruidosas? A: BBR usa el ancho de banda del bottleneck y el RTT como señal de congestión en lugar de pérdida de paquetes. En rutas donde la pérdida está dominada por desbordamiento de buffer en routers intermedios, retransmisiones inalámbricas o eventos transitorios de enrutamiento — es decir, la mayoría de rutas ISP públicas — BBR mantiene el pace del emisor al ancho de banda real de la ruta en lugar de dividir la ventana a la mitad repetidamente por pérdidas no congestivas. El efecto es mayor throughput en régimen estacionario, tail latency más corta en transferencias grandes y menos incidentes «la transferencia se detuvo treinta segundos y luego retomó» en flujos largos.
Q: ¿Qué es el MSS clamping y por qué lo necesito? A: El MSS clamping reescribe la opción Maximum Segment Size en paquetes TCP SYN para que el tamaño de segmento negociado encaje limpiamente a través de un túnel con MTU efectiva reducida. Sin él, los endpoints negocian un tamaño de segmento basado en sus interfaces LAN (típicamente MTU 1500, MSS 1460), el túnel WireGuard no puede llevar esos paquetes a tamaño completo, Path MTU Discovery falla porque ICMP se filtra en algún punto upstream, y los paquetes grandes desaparecen silenciosamente. El síntoma es «paquetes pequeños funcionan, grandes no» — los pings pasan, los handshakes TLS cuelgan, las transferencias SMB se stallan a mitad de archivo. La solución es una regla iptables o nftables de una línea en la interfaz WireGuard del lado del router.
Q: ¿Puedo desplegar esta arquitectura yo mismo, o necesito un vendedor de render farm?
A: La arquitectura está construida enteramente con componentes open source — WireGuard, la implementación BBR de Linux, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. No hay componente SRF-only. Un equipo con habilidades de ingeniero de infraestructura puede desplegar el mismo stack por su cuenta, y las decisiones de configuración en este artículo no son secretos; son las decisiones que hicimos porque funcionaban. Lo que un vendedor aporta es la experiencia operativa — las trampas como la línea interface= de dnsmasq, la historia del descubrimiento del MSS clamp, el dimensionado correcto del SSD de caché, la herramienta de pre-warm — empaquetada en un playbook de deployment que no requiere redescubrimiento en cada build. Si un equipo absorbe esa curva de experiencia o paga para saltársela es una cuestión de presupuesto y plazo.
Q: ¿Cuál es la cache hit ratio para workflows de render típicos? A: Para cargas paralelas por frame donde la misma escena se renderiza a lo largo de muchos frames (el patrón dominante en animación, VFX, archviz y visualización de producto), la cache hit ratio se aproxima a 1,0 tras el primer pull caliente de cada asset. La penalización de cold pull se paga una vez por asset por caché, y cada worker siguiente en el mismo sitio lee desde la caché caliente a velocidad LAN. Para cargas que tocan un set de assets diferente por frame (raras, pero ocurren en algunos workflows procedurales), la hit ratio es menor y la caché actúa más como buffer de tránsito que como store de largo plazo. El paso pre-warm antes de jobs dirigidos por deadline hace efectivamente que la hit ratio sea 1,0 para la carga planificada.
Q: ¿Cómo escala esta arquitectura más allá de 20 nodos? A: La topología WireGuard hub-and-spoke escala linealmente con el número de peers — el coste CPU del hub es crypto por peer y enrutamiento por paquete, y un gateway Xeon moderno puede manejar cientos de peers antes de convertirse en el bottleneck. La capa de caché escala bien creciendo la box de caché única (más capacidad SSD, NIC más rápida) o haciendo sharding entre múltiples boxes con una estrategia de mount consciente del workload. Para builds más allá de 50 nodos por sitio, normalmente añadimos una segunda box de caché y dividimos workers entre ellas; más allá de 100 nodos por sitio, la capa de caché se convierte en un diseño de read-replica distribuido, y eso es otro artículo. El túnel cross-country en sí no necesita cambio arquitectural a medida que el cluster crece — el pacing BBR y el MSS clamp siguen haciendo su trabajo a cualquier tasa de flujo agregada, mientras el enlace ISP subyacente tenga la capacidad.
Para más detalle práctico sobre la secuencia de deployment con la que levantamos esta arquitectura, ver nuestra operational deployment guide. Para la postura de seguridad superpuesta sobre este diseño de red, nuestro artículo network segmentation security cubre con más profundidad el modelo de firewall Tier-1 y Tier-2. Y para los casos límite probados en campo que no siempre hicimos bien a la primera, el writeup deployment lessons learned cubre los modos de fallo específicos que dieron forma a esta arquitectura.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



