
Cách Chúng Tôi Benchmark GPU Render Farm: Phương Pháp Chi Phí Mỗi Khung Hình Có Thể Tái Tạo (2026)
Tổng quan
Giới thiệu
Điểm benchmark dễ công bố nhưng khó tin tưởng. Ai cũng có thể đăng "RTX 5090: X điểm", nhưng con số quyết định liệu một render job có đáng chạy trên card này hay card khác không phải là điểm tổng hợp — đó là chi phí mỗi khung hình hoàn chỉnh. Con số đó phụ thuộc vào scene của bạn, cài đặt render, engine, driver, và cách bạn tính toán, và hầu như không có gì trong số đó hiển thị trong bảng xếp hạng.
Trang này là phương pháp, không phải bảng xếp hạng. Nó ghi lại cách chúng tôi tại Super Renders Farm benchmark GPU render farm để kết quả có ý nghĩa: cách chọn scene benchmark, cài đặt render nào chúng tôi khóa, những gì chúng tôi giữ cố định trên ma trận phần cứng, cách chuyển đổi thời gian mỗi khung hình thô thành con số chi phí mỗi khung hình có thể bảo vệ, và — phần mà hầu hết các bài viết bỏ qua — các bước cụ thể để bên thứ ba có thể tái tạo toàn bộ trên phần cứng của họ. Chúng tôi đã công bố kết quả của phương pháp này; đây là công thức đằng sau chúng. Khi một con số xuất hiện dưới đây, đó là số liệu thực từ một trong những nghiên cứu đó, được trích dẫn làm ví dụ minh họa thay vì được tính lại ở đây.
Benchmark tổng hợp so với chi phí mỗi khung hình trong thực tế
Có hai lớp trong benchmark GPU, và việc nhầm lẫn chúng là nơi mà hầu hết sự nhầm lẫn bắt đầu.
Lớp đầu tiên là lớp tổng hợp: các công cụ được chuẩn hóa render một scene cố định và xuất ra điểm số. Cinebench R24, V-Ray Benchmark của Chaos, và OctaneBench đều thuộc đây. Chúng hữu ích cho việc xếp hạng tương đối — một khối lượng công việc lặp lại duy nhất, giống nhau trên mọi máy, để bạn có thể xếp hàng các card cạnh nhau. Chúng tôi giải thích cách đọc những điểm số đó trong hướng dẫn benchmark V-Ray và bài viết điểm Cinebench cho cloud rendering của chúng tôi. Điểm tổng hợp cố tình loại bỏ mọi thứ thay đổi trong thực tế: geometry của bạn, sampling, denoiser, độ phân giải đầu ra, và chi phí mỗi job mà một hàng đợi thực sự mang theo.
Lớp thứ hai là lớp thực tế: một khung hình đại diện thực sự mất bao lâu và điều đó tốn bao nhiêu. Đây là lớp mà phương pháp này nhắm tới. Điểm tổng hợp là đầu vào của nó — một cách để ngoại suy ước tính ban đầu — nhưng không phải câu trả lời. Cầu nối giữa hai lớp đơn giản về nguyên tắc: một máy đạt điểm gấp đôi máy kia trên cùng một phiên bản benchmark sẽ, rất gần đúng, render một khung hình tương đương trong khoảng một nửa thời gian. Chúng tôi trình bày phép tính ước tính đó (hiệu suất = thời gian khung hình ÷ điểm benchmark) trong hướng dẫn V-Ray. Mục đích của một phương pháp benchmark, khác với điểm số, là làm cho sự ngoại suy đó trung thực — đo trên một scene gần với thực tế và báo cáo độ phân tán, không chỉ một điểm giữa.
Chỉ số quan trọng: chi phí mỗi khung hình
Chi phí mỗi khung hình là đơn vị mà một phương pháp nên giải quyết, vì đó là đơn vị mà ngân sách render thực sự được viết bằng. Công thức đơn giản:
Chi phí mỗi khung hình = thời gian đồng hồ treo tường mỗi khung hình × chi phí node mỗi giờ
Thời gian đồng hồ treo tường mỗi khung hình là thời gian task chia cho số khung hình, được đo — không phải chỉ số "thời gian render" nội bộ của engine, vốn loại trừ tải scene, xây dựng cấu trúc tăng tốc, và phối hợp thiết bị. Chi phí node mỗi giờ là bất kỳ chi phí phần cứng nào để chạy trong một giờ, tùy cách bạn tính. Trên render farm của chúng tôi, GPU rendering được tính theo $0,003 mỗi OctaneBench-giờ, và một RTX 5090 đơn lẻ (32 GB) có cơ sở phần cứng khoảng $5,2 mỗi card-giờ; hướng dẫn chi phí mỗi khung hình và hướng dẫn bảng giá của chúng tôi đề cập mô hình hướng đến khách hàng đầy đủ.
Kết hợp hai đầu vào chỉ là tính toán đơn vị: chuyển đổi thời gian đồng hồ treo tường mỗi khung hình thành giờ và nhân với chi phí node mỗi giờ, sao cho giây-mỗi-khung-hình và đô-la-mỗi-giờ ra đô-la-mỗi-khung-hình. Một khung hình ngắn trên node rẻ tiền sẽ thấp; một khung hình nặng trên node đắt tiền sẽ cao. Chúng tôi cố ý không đưa tỷ lệ đã tính sẵn vào trang phương pháp này — chi phí thực tế phụ thuộc vào độ phức tạp của scene, sampling, thời gian chờ hàng đợi, và mô hình thanh toán bạn đang chạy, và hướng dẫn chi phí mỗi khung hình và hướng dẫn bảng giá của chúng tôi là nơi các con số hướng đến khách hàng thuộc về. Điểm mấu chốt ở đây là công thức có thể kiểm toán: giữ các đơn vị rõ ràng và bất kỳ ai cũng có thể kiểm tra con số thay vì tin vào đức tin.
Lý do tại sao chi phí mỗi khung hình, chứ không phải điểm tổng hợp, là chỉ số quan trọng: hai card có thể đạt điểm tương tự trên benchmark nhưng vẫn khác nhau rõ rệt về chi phí mỗi khung hình trên scene của bạn, vì scene quyết định bao nhiêu phần của mỗi khung hình là công việc có thể song song hóa so với chi phí cố định mà silicon nhanh hơn không thể chạm tới.
Scene benchmark và cài đặt render
Scene là đòn bẩy lớn nhất về việc liệu benchmark có chuyển giao được vào thực tế hay không, vì vậy chúng tôi cố ý chạy hai loại.
Scene chuẩn của nhà cung cấp để xếp hạng đa máy. Khi mục tiêu là so sánh công bằng, chúng tôi sử dụng các scene tham chiếu đã công bố — các scene Open Data của Blender (bmw27, classroom, junkshop), scene Vultures của Maxon cho Redshift, Chaos V-Ray Benchmark, và OctaneBench. Chúng có thể lặp lại và kiểm chứng độc lập, đó chính xác là những gì một bảng xếp hạng cần. Điểm yếu của chúng là không phải scene của bạn, vì vậy thời gian tuyệt đối không chuyển trực tiếp vào thực tế.
Scene đại diện cho thực tế để tính chi phí mỗi khung hình. Khi mục tiêu là một con số mà nhà vận hành có thể lên kế hoạch, scene phải trông giống công việc thực — geometry thực, bộ texture thực, sampling thực, độ phân giải đầu ra thực. Trong nghiên cứu mở rộng đa GPU của chúng tôi, chúng tôi chạy Blender Cycles ở độ phân giải 200% đặc biệt để mỗi lần render đủ dài để tạo ra tỷ lệ ổn định, đáng tin cậy — điều đó cũng có nghĩa là thời gian Cycles thô đó không thể so sánh với điểm Open Data công khai. Sự đánh đổi đó là phương pháp đang hoạt động như dự định: điều chỉnh scene theo câu hỏi.
Dù là scene nào, cài đặt render phải được khóa và ghi lại: số lượng mẫu (hoặc ngưỡng nhiễu), denoiser bật/tắt và loại nào, độ phân giải đầu ra, kích thước tile hoặc bucket, và phiên bản engine. Một benchmark mà bất kỳ điều nào trong số này thay đổi giữa các máy đang đo sự thay đổi đó, không phải phần cứng.
Ma trận phần cứng
Ma trận benchmark là một lưới: các card bạn đang kiểm tra trên một trục, các engine và scene trên trục kia. Kỷ luật nằm ở những gì bạn giữ cố định trên toàn bộ lưới.
Giữ cố định: hệ điều hành, phiên bản và bản dựng render-engine, denoiser, scene, và cài đặt. Ghi nhận nhưng không thể luôn khớp: driver GPU — một card thế hệ hiện tại đôi khi yêu cầu driver mới hơn so với card cũ có thể chạy, vì vậy khớp driver chính xác là không thể. Khi điều đó xảy ra, hãy nêu rõ. Trong nghiên cứu đa GPU, node RTX 5090 chạy driver 596.36 và node RTX 4090 chạy 610.62, và chúng tôi đã ghi chú rằng khoảng cách đó chỉ ảnh hưởng đến so sánh tuyệt đối giữa các thế hệ, không ảnh hưởng đến tỷ lệ mở rộng trong cùng node (sử dụng cùng card và driver ở cả hai phía).
Đội GPU của chúng tôi được chuẩn hóa trên các card NVIDIA RTX 5090 với 32 GB VRAM, điều đó làm cho ma trận của chúng tôi nhất quán nội bộ — một kho hàng đồng nhất có nghĩa là ước tính từ một node chuyển sang node tiếp theo. Làm ví dụ minh họa cho trục mỗi card, đây là kết quả một card từ nghiên cứu đa GPU, RTX 5090 so với RTX 4090 trên các scene giống hệt nhau:
| Engine / scene | Chỉ số | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | giây (thấp hơn tốt hơn) | 49,45 | 77,40 |
| Cycles — classroom | giây | 23,09 | 36,87 |
| Redshift — Vultures | giây | 57 | 100 |
| V-Ray GPU (RTX) | vpaths (cao hơn tốt hơn) | 15.333 | 9.608 |
| Octane | điểm OctaneBench | 1.690,78 | 1.074,17 |
Hai loại chỉ số xuất hiện trong bảng đó — giây (thấp hơn tốt hơn) và điểm benchmark (cao hơn tốt hơn) — đó là lý do tại sao các con số tuyệt đối không bao giờ so sánh giữa các engine. Chỉ tỷ lệ trong một engine duy nhất mới là so sánh công bằng.
Các biện pháp kiểm soát làm cho benchmark đáng tin cậy
Sự khác biệt giữa một con số và một con số đáng tin cậy là các biện pháp kiểm soát. Đây là những gì phương pháp của chúng tôi thực thi.
- Một task duy nhất mỗi GPU. Bộ lập lịch của chúng tôi chạy một render task mỗi card, vì vậy mỗi con số là số mỗi card rõ ràng — giá trị bạn nhân để lên kế hoạch công suất, không phải trung bình bị làm mờ trên một thiết bị dùng chung.
- Các cặp khớp cho bất kỳ so sánh nào. Khi chúng tôi so sánh các thế hệ phần cứng trong thực tế, một scene chỉ được tính nếu cùng scene, cùng người dùng chạy ở cả hai phía, với ít nhất ba task mỗi phía trước khi đủ điều kiện. Trong nghiên cứu thực địa RTX 5090, 38 scene vượt qua tiêu chí đó trong số 1.419 task — 38 không phải là kích thước dữ liệu, mà là những gì tồn tại qua một bộ lọc nghiêm ngặt có chủ đích.
- Một driver mỗi cửa sổ đo. Đối với nghiên cứu thực địa, một driver duy nhất (581.80, CUDA 13.0) chạy toàn bộ cửa sổ bảy tuần với không thay đổi, vì vậy không có sự thay đổi giữa chừng nào có thể làm ô nhiễm kết quả.
- Ngang bằng denoiser. Khoảng 83% job Cycles chạy một lần AI denoiser trên cả phần cứng mới và thế hệ trước — vì vậy denoiser là hằng số, không phải biến ẩn bên trong tốc độ tăng.
- Ấm so với nguội. Chi phí cố định mỗi task — tải scene, đồng bộ, xây dựng cấu trúc tăng tốc — chiếm tỷ lệ lớn hơn trong một khung hình ngắn so với một khung hình dài, đó là lý do tại sao các khung hình ngắn bị giới hạn bởi chi phí cố định đánh giá thấp một card nhanh hơn. Phương pháp tính đến điều này bằng cách báo cáo phân phối, không giả định một hệ số nhân duy nhất.
Từ thời gian thô đến con số có thể bảo vệ
Khi thời gian đã được thu thập, thống kê quyết định liệu con số tiêu đề có trung thực hay không.
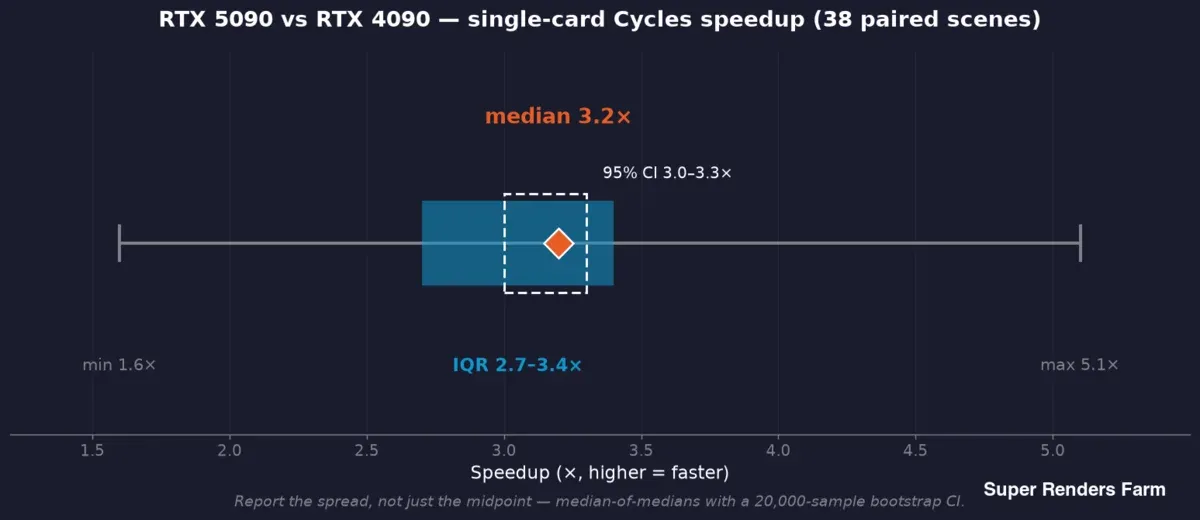
RTX 5090 so với RTX 4090 tốc độ tăng Cycles một card trên 38 scene ghép cặp: trung vị 3,2x, khoảng tin cậy 95% từ 3,0 đến 3,3x, phạm vi tứ phân vị 2,7 đến 3,4x, phạm vi đầy đủ 1,6 đến 5,1x
Chúng tôi sử dụng trung vị của các trung vị: mỗi scene đóng góp trung vị của thời gian mỗi khung hình riêng của nó ở mỗi phía, và tiêu đề là trung vị của các tỷ lệ mỗi scene — vì vậy một khung hình chậm không thể làm nghiêng kết quả. Xung quanh điểm giữa đó, chúng tôi báo cáo khoảng tin cậy bootstrap (nghiên cứu thực địa sử dụng 20.000 mẫu bootstrap, cho khoảng tin cậy 95% 3,0–3,3x xung quanh trung vị 3,2x tốc độ tăng) và độ phân tán — phạm vi tứ phân vị 2,7–3,4x, phạm vi đầy đủ 1,6–5,1x trên 38 scene đó.
Độ phân tán đó không phải là nhiễu để làm trung bình đi; đó là kết quả. Tốc độ tăng điển hình 3,2x và trường hợp xấu nhất 1,6x đều đúng cùng một lúc, và một benchmark chỉ báo cáo điểm giữa che giấu một nửa câu chuyện mà nhà vận hành cần. Quy tắc chúng tôi tuân theo: báo cáo trung vị và phạm vi, và gắn mỗi khẳng định với mẫu hỗ trợ nó — tốc độ tăng từ 38 scene ghép cặp, VRAM từ 57 job được ghi lại, điện năng từ một lần chạy bench kiểm soát riêng biệt, không bao giờ một mẫu được mượn để hỗ trợ mẫu khác.
Cách tái tạo benchmark này
Đây là phần làm cho một benchmark trở thành tín hiệu có thể kiếm được thay vì một câu marketing: bất kỳ ai cũng có thể chạy nó. Các bước dưới đây tái tạo phương pháp trên bất kỳ hàng đợi hoặc bench test nào.
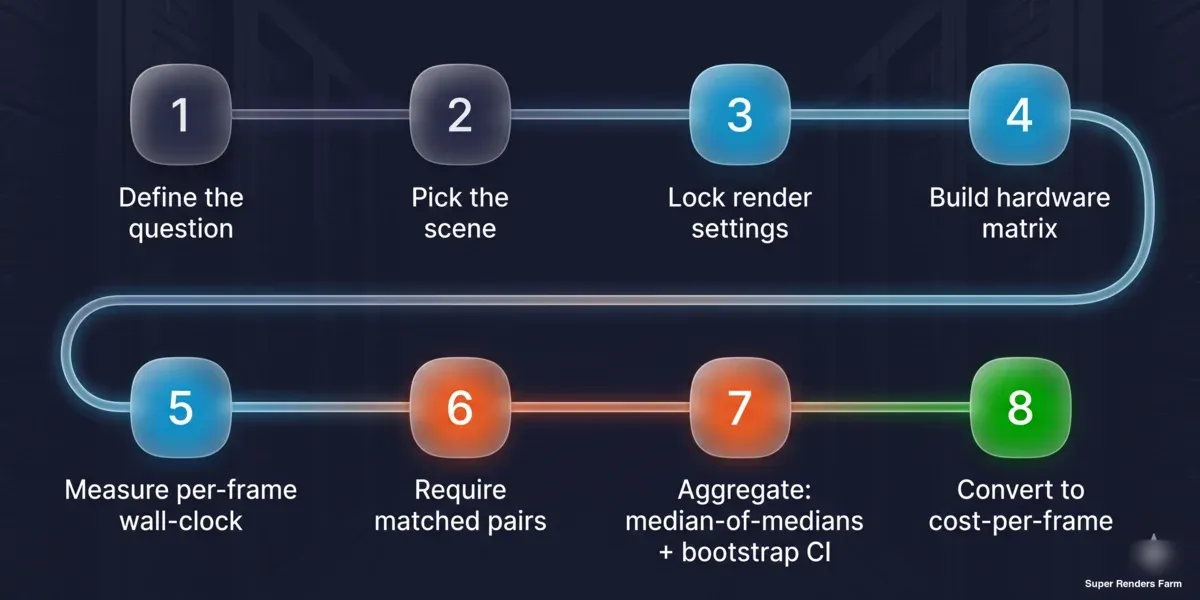
Phương pháp benchmark chi phí mỗi khung hình có thể tái tạo tám bước: xác định câu hỏi, chọn scene, khóa cài đặt render, xây dựng ma trận phần cứng, đo thời gian đồng hồ treo tường mỗi khung hình, yêu cầu cặp khớp, tổng hợp với trung vị của các trung vị và khoảng tin cậy bootstrap, chuyển đổi sang chi phí mỗi khung hình
- Xác định câu hỏi. Xếp hạng đa máy, hay chi phí mỗi khung hình trong thực tế? Câu trả lời chọn loại scene của bạn — chuẩn của nhà cung cấp để xếp hạng, đại diện thực tế để tính chi phí.
- Cố định scene và cài đặt. Khóa số lượng mẫu hoặc ngưỡng nhiễu, lựa chọn denoiser, độ phân giải đầu ra, kích thước tile/bucket, và phiên bản engine. Ghi chép lại; chúng là một phần của kết quả.
- Xây dựng ma trận. Liệt kê các card trên một trục, kết hợp engine/scene trên trục kia. Quyết định những gì được giữ cố định (OS, phiên bản engine, denoiser, scene) và ghi lại những gì không thể (driver).
- Đo thời gian đồng hồ treo tường mỗi khung hình. Sử dụng thời gian task ÷ số khung hình từ bộ lập lịch hoặc đồng hồ bấm giờ trên toàn bộ job — không phải chỉ số thời gian render nội bộ của engine, vốn bỏ qua chi phí tải và xây dựng.
- Yêu cầu cặp khớp và mẫu tối thiểu. Đối với bất kỳ khẳng định A-so-với-B nào, hãy chạy cùng scene ở cả hai phía, ít nhất ba task mỗi phía, trước khi tính.
- Tổng hợp với trung vị của các trung vị. Lấy trung vị của mỗi scene ở mỗi phía, sau đó trung vị của các tỷ lệ mỗi scene. Tính khoảng tin cậy bootstrap và báo cáo phạm vi tứ phân vị và phạm vi đầy đủ cùng với nó.
- Chuyển đổi sang chi phí mỗi khung hình. Nhân thời gian mỗi khung hình đã đo với chi phí node mỗi giờ. Giữ các đơn vị rõ ràng để con số có thể kiểm toán.
- Công bố các cảnh báo cùng với con số. Nêu kích thước mẫu đằng sau mỗi khẳng định, tình trạng driver, liệu dữ liệu có phải là quan sát hay kiểm soát, và phạm vi áp dụng cũng như không áp dụng.
Một studio chạy tám bước này trên phần cứng của mình sẽ có được một con số có thể bảo vệ — và có thể kiểm tra con số của chúng tôi, đó là toàn bộ lý do công bố phương pháp.
Ghi chú về tính trung thực: benchmark có thể và không thể khẳng định gì
Một phương pháp chỉ đáng tin cậy bằng những khẳng định nó từ chối đưa ra. Ba ranh giới chúng tôi giữ:
Quan sát không phải kiểm soát. Dữ liệu thực địa sản xuất — các job mà người dùng chạy trong quá trình kinh doanh bình thường — là thực và hữu ích, nhưng người dùng điều chỉnh scene của họ giữa các lần render lại, vì vậy đó là quan sát. Một so sánh trực tiếp cùng host sạch (ví dụ, một RTX 5090 so với RTX 4090 hiện tại trên phần cứng giống hệt) là một bài tập kiểm soát riêng biệt. Chúng tôi không để một cái giả vờ là cái kia.
Node-so-với-node mang theo cài đặt, không chỉ silicon. Khi một bên chạy bare-metal và bên kia chạy ảo hóa, một phần khoảng cách đo được là do cài đặt, không phải chip. Điều đó thuộc về cảnh báo tiêu đề, không phải chú thích cuối trang.
Không có con số nào chúng tôi không đo. Chúng tôi không ngoại suy các con số điện năng hoặc nhiệt độ mà chúng tôi không bench. Khi nghiên cứu thực địa của chúng tôi báo cáo khoảng 360–375 W mỗi card, điều đó đến từ một lần chạy bench kiểm soát dưới tải liên tục — và con số năng lượng mỗi khung hình được suy ra từ đó được gắn nhãn là suy luận, không phải đo lường. Nếu một con số không được đo, phương pháp không phát minh ra nó. Kỷ luật đó là lý do tại sao một benchmark đã công bố có thể được trích dẫn.
Các ví dụ minh họa từ render farm của chúng tôi
Phương pháp này tạo ra các nghiên cứu dưới đây; mỗi nghiên cứu là một tập dữ liệu bạn có thể đọc cùng với công thức, và là nơi để tìm các con số thực tế thay vì tính lại ở đây.
| Nghiên cứu | Kết quả phương pháp tạo ra | Mẫu |
|---|---|---|
| Mở rộng đa GPU | Mở rộng 1x→2x mỗi engine trên scene chuẩn nhà cung cấp | 2 node, 4 engine, 7 kết hợp scene/benchmark |
| Ghi chú thực địa RTX 5090 | Phân phối chi phí/tốc độ tăng thực tế, phân vị VRAM | 38 scene ghép cặp / 1.419 task, 7 tuần |
| Hướng dẫn benchmark V-Ray | Ước tính điểm tổng hợp sang thời gian render | Bảng tham chiếu + ước tính minh họa |
| Cinebench cho cloud rendering | Giải thích điểm tổng hợp cho các bậc phần cứng | Điểm tham chiếu |
Cách tiếp cận tương tự làm nền tảng cho việc lên kế hoạch công suất trên GPU cloud render farm của chúng tôi, và các con số dành riêng cho Blender đưa vào công việc Blender cloud rendering của chúng tôi — GPU là thiểu số trong tổng hỗn hợp job của chúng tôi (hầu hết công việc render farm vẫn là CPU rendering), vì vậy chúng tôi xác định phạm vi các con số GPU này là chính xác như vậy, không phải là một khẳng định toàn farm.
FAQ
Q: Cách đúng để benchmark GPU render farm là gì? A: Trước tiên hãy quyết định xem bạn muốn xếp hạng đa máy hay chi phí mỗi khung hình trong thực tế. Để xếp hạng, hãy sử dụng scene chuẩn nhà cung cấp có thể lặp lại và phiên bản benchmark cố định. Để tính chi phí mỗi khung hình, hãy sử dụng scene đại diện thực tế, đo thời gian đồng hồ treo tường mỗi khung hình (thời gian task ÷ số khung hình), và nhân với chi phí node mỗi giờ. Khóa cài đặt render và báo cáo độ phân tán, không chỉ một con số đơn lẻ.
Q: Tại sao chi phí mỗi khung hình tốt hơn điểm benchmark? A: Điểm tổng hợp loại bỏ mọi thứ thay đổi trong thực tế — geometry, sampling, denoiser, và độ phân giải của bạn — vì vậy hai card có thể đạt điểm tương tự nhưng vẫn khác nhau về chi phí mỗi khung hình thực tế trên scene của bạn. Chi phí mỗi khung hình là đơn vị mà ngân sách render thực sự được viết bằng, đó là lý do tại sao một phương pháp nên giải quyết nó thay vì điểm bảng xếp hạng.
Q: Làm thế nào để chuyển đổi điểm benchmark thành ước tính thời gian render? A: Sử dụng tỷ lệ điểm như một tỷ lệ tốc độ gần đúng: một máy đạt điểm gấp đôi máy kia trên cùng phiên bản benchmark sẽ render một khung hình tương đương trong khoảng một nửa thời gian. Tính hiệu suất máy của bạn là thời gian khung hình chia cho điểm benchmark, sau đó mở rộng theo điểm của máy mục tiêu. Giữ phiên bản benchmark cố định, vì điểm từ các phiên bản khác nhau không thể so sánh được.
Q: Các biện pháp kiểm soát nào làm cho benchmark GPU đáng tin cậy? A: Chạy một render task duy nhất mỗi card để có số mỗi card rõ ràng, yêu cầu các cặp khớp (cùng scene ở cả hai phía, số lượng task tối thiểu trước khi kết quả có giá trị), giữ driver và phiên bản engine cố định trong một cửa sổ đo, và giữ cài đặt denoiser giống hệt nhau trên toàn bộ so sánh. Sau đó tổng hợp với trung vị của các trung vị và báo cáo khoảng tin cậy và phạm vi.
Q: Tôi cần bao nhiêu scene test để có kết quả đáng tin cậy? A: Ít cặp khớp chất lượng cao còn hơn nhiều cặp được kiểm soát lỏng lẻo. Trong nghiên cứu thực tế của chúng tôi, 38 scene tồn tại qua bộ lọc đưa vào nghiêm ngặt (cùng scene và người dùng trên cả hai phía phần cứng, ít nhất ba task mỗi phía) trong số 1.419 task. Kích thước mẫu quan trọng là những gì vượt qua bộ lọc của bạn, không phải số lượng task thô — và bạn nên báo cáo cả hai.
Q: Tôi có thể tự tái tạo benchmark GPU render farm của các bạn không? A: Có — đó là mục đích. Cố định một scene và cài đặt của nó, xây dựng ma trận phần cứng giữ OS, phiên bản engine, và denoiser cố định, đo thời gian đồng hồ treo tường mỗi khung hình, yêu cầu các cặp khớp, tổng hợp với trung vị của các trung vị cộng với khoảng tin cậy bootstrap, chuyển đổi sang chi phí mỗi khung hình, và công bố các cảnh báo cùng với con số. Tám bước tái tạo ở trên trình bày đầy đủ trình tự.
Q: Tại sao các bạn báo cáo phạm vi thay vì một con số tốc độ tăng? A: Vì phạm vi là một phần của kết quả. Cùng một phần cứng có thể cho thấy mức tăng 1,6x trên một scene ngắn bị giới hạn bởi chi phí cố định và hơn 5x trên một scene nặng bị giới hạn bởi tính toán, vì chi phí cố định mỗi khung hình chiếm tỷ lệ lớn hơn trong một lần render ngắn. Chỉ báo cáo điểm giữa che giấu sự biến đổi mà nhà vận hành cần để lên kế hoạch công suất, vì vậy chúng tôi công bố trung vị, phạm vi tứ phân vị, và phạm vi đầy đủ cùng nhau.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



