
RTX 5090 trong Thực Chiến: 7 Tuần Ghi Chép Thực Tế từ Render Farm (Nghiên Cứu 38 Scene)
Tổng quan
Các bài benchmark RTX 5090 lúc ra mắt đã hơn một năm tuổi, và tất cả đều mô tả cùng một thứ: một card, một scene dàn dựng sẵn, điều kiện lý tưởng. Điều hầu như không ai công bố là phần tiếp theo — card đó hoạt động ra sao khi bị nhúng vào hàng đợi render thực tế, xử lý scene của người khác theo một lịch trình mà nó không kiểm soát. Vì vậy chúng tôi đã kéo log ra. Bài viết này là ghi chép cấp hàng đợi: cùng dữ liệu production mà chúng tôi dùng để lập kế hoạch công suất, được trình bày dưới dạng các con số bạn có thể tự kiểm tra.
Đây là bảy tuần dữ liệu đó. Từ ngày 1 tháng 4 đến 22 tháng 5 năm 2026 — 51 ngày — chúng tôi chạy một node dual-RTX-5090 trong live Render Farm (hệ thống máy tính kết xuất) và để nó nhận bất cứ thứ gì hàng đợi giao cho. Không có test dàn dựng, không cherry-pick frame. Video ngắn dưới đây tóm tắt các con số chính; toàn bộ ghi chép thực tế theo sau đó.
Bản thân node không có gì đặc biệt: hai RTX 5090, 128 GiB RAM, 32 logical core ở 4.3 GHz, Windows 11. Một chi tiết định hình mọi con số ở đây — scheduler chạy một tác vụ render cho mỗi GPU, nên mỗi card render job riêng của nó và mọi con số đều là số sạch per-card, con số bạn nhân lên để lập kế hoạch công suất. Trong suốt khoảng thời gian này, node hoàn thành 99.6% tác vụ của nó — 4,890 trong số khoảng 4,900 hoàn thành, 18 thất bại. Scheduler ghi lại sự thất bại, không ghi nguyên nhân, vì vậy chúng tôi sẽ không đoán.
Các con số chính
- Khoảng thời gian: 1 tháng 4 – 22 tháng 5, 2026 (51 ngày, ~7 tuần), một node dual-RTX-5090
- Hoàn thành: 99.6% — 4,890 trong ~4,900 tác vụ hoàn thành, 18 thất bại (nguyên nhân không được ghi)
- Tốc độ tăng: trung vị 3.2x per-frame trên Blender Cycles so với các node thế hệ trước RTX 3080/2080-class (thời gian per-frame trung vị giảm ~69%); 95% CI 3.0–3.3x
- Mức phân tán: IQR 2.7–3.4x, phạm vi đầy đủ 1.6x–5.1x trên 38 scene theo cặp — một hệ số nhân không bao giờ mô tả đủ cả hàng đợi
- AI denoise: ~83% job Cycles chạy một lượt AI denoise — cùng tỷ lệ trên phần cứng cũ
- VRAM: trung vị 5.6 GB, phân vị thứ 90 là 11.5 GB, job nặng nhất ~37 GB
- Driver: một driver duy nhất (581.80 / CUDA 13.0) trong toàn bộ thời gian, zero thay đổi
- Điện năng: ~360–375 W/card dưới tải (bench kiểm soát), đỉnh ~400 W, ở 68–83 °C — thấp hơn nhiều so với mức rated ~575 W
38 scene theo cặp cho thấy gì
Phép so sánh mà chúng tôi tin tưởng nhất không phải là test tổng hợp mà là các job đã chạy trên cả hai thế hệ trong quá trình kinh doanh thông thường — cùng scene, cùng người dùng, ít nhất ba tác vụ mỗi bên trước khi một scene được tính. Thời gian per-frame là wall-clock của tác vụ chia cho số frame, lấy thẳng từ hàng đợi. Trong khoảng thời gian này, 38 scene vượt qua tiêu chí đó, được rút ra từ 1,419 tác vụ render riêng lẻ (503 trên node 5090, 916 trên thế hệ trước). Ba mươi tám không phải là kích thước dữ liệu của chúng tôi; đó là những gì còn lại sau một bộ lọc cố ý nghiêm ngặt.
| Chỉ số | Giá trị |
|---|---|
| Tốc độ tăng per-frame trung vị | 3.2x (≈69% giảm thời gian) |
| Bootstrap 95% CI (trung vị) | 3.0–3.3x |
| Khoảng tứ phân vị | 2.7–3.4x |
| Phạm vi đầy đủ | 1.6–5.1x |
| Scene / tác vụ | 38 scene / 1,419 tác vụ |
| Baseline | RTX 3080/2080-class thế hệ trước (10–12 GB) |
Chúng tôi dùng trung vị của các trung vị: mỗi scene đóng góp trung vị của các thời gian per-frame của nó ở mỗi bên, và 3.2x là trung vị của 38 tỷ lệ đó, nên một frame chậm không thể làm lệch kết quả. Mức phân tán quan trọng không kém điểm giữa — nửa giữa của các scene nằm trong khoảng 2.7x đến 3.4x, và phạm vi đầy đủ chạy từ 1.6x đến 5.1x.
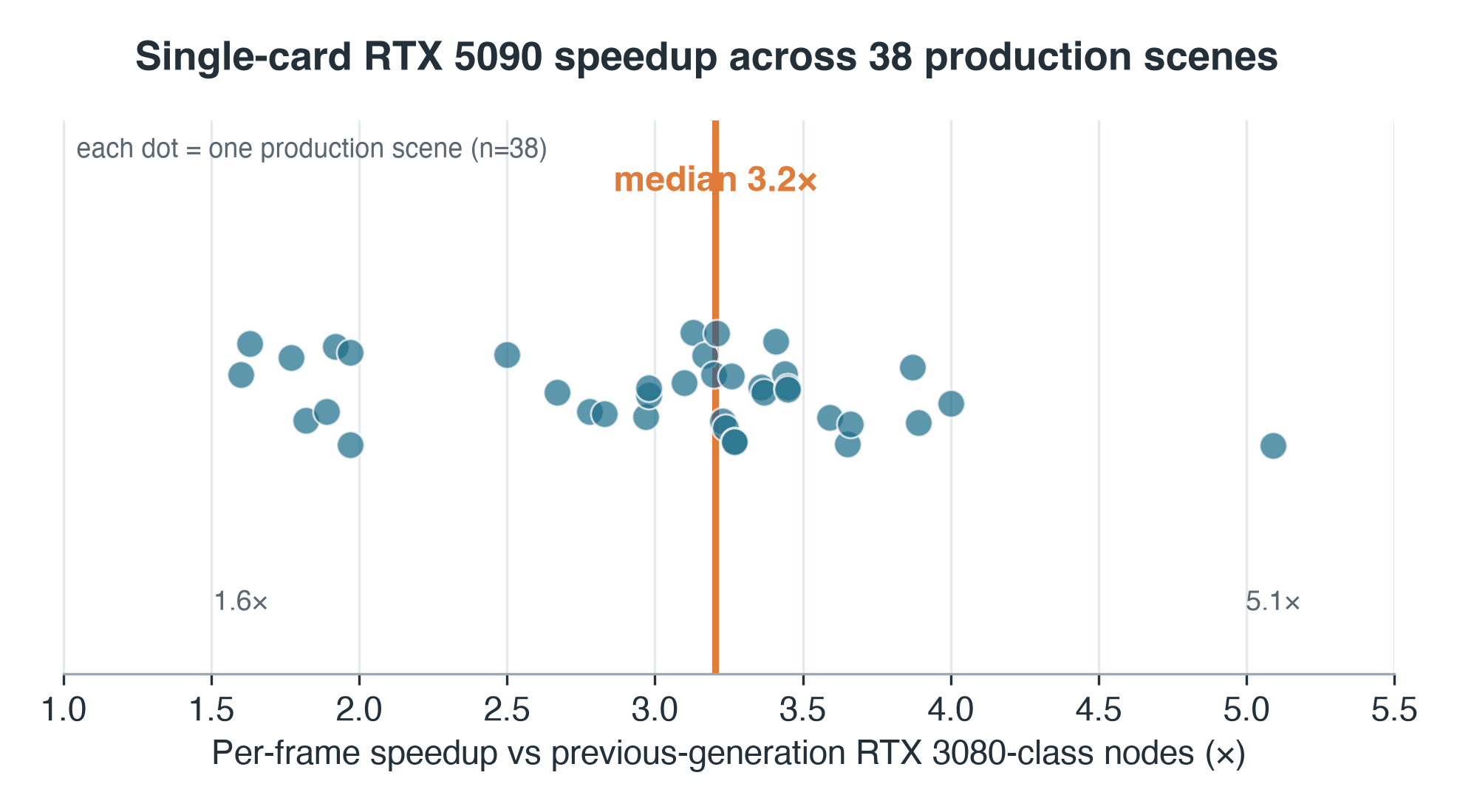
Tốc độ tăng per-scene của RTX 5090 trên 38 scene Blender Cycles production, trung vị 3.2x với mức phân tán 1.6 đến 5.1x
Tốc độ tăng per-scene, RTX 5090 so với các node thế hệ trước mà những job này từng chạy — mẫu production 38 scene. Trung vị 3.2x; phạm vi 1.6–5.1x.
Hai lưu ý thuộc về con số đó, không phải chú thích cuối trang. Thứ nhất, phía thế hệ trước chạy ảo hóa — GPU passthrough trong VM — nên một phần không đo được của 3.2x này là overhead ảo hóa, không phải silicon thuần túy; phép so sánh cùng host sạch, một RTX 5090 đối một RTX 4090 hiện tại, là bài follow-up có kiểm soát mà chúng tôi cần làm và chưa chạy. Thứ hai, 38 scene không phải là mẫu ngẫu nhiên từ hàng đợi: đây là các job mà người dùng tình cờ render lại trên cả hai thế hệ, điều này làm lệch mẫu về phía các công việc dài hơi, lặp đi lặp lại — vì vậy hãy đọc phân phối như của các cặp phù hợp, không phải toàn bộ hàng đợi.
Ba lưu ý trung thực là trọng tải ở đây. Đây là dữ liệu quan sát — người dùng đôi khi điều chỉnh cài đặt giữa các lần render lại, và chúng tôi không khóa scene của họ. Phép so sánh là node-vs-node: phía 5090 là một card bare-metal, phía thế hệ trước chạy dưới dạng GPU passthrough trong máy ảo, nên một phần khoảng cách đó là do setup, không phải silicon. Và baseline là card RTX 3080/2080-class mà những job này thực sự đã chạy — không phải RTX 4090 hiện tại; một bài so sánh head-to-head sạch với card hiện tại là một bài tập riêng biệt có kiểm soát mà chúng tôi chưa chạy. Đây là các con số single-node, chỉ Cycles; chúng mô tả hàng đợi của chúng tôi và không nên được khái quát hóa cho các engine hoặc phần cứng khác.
Điều phân biệt một scene 1.6x với một scene 5.1x một phần hiện ra trong dữ liệu. Vẽ tốc độ tăng của mỗi scene theo thời gian frame trên phần cứng cũ và một xu hướng dương lỏng lẻo xuất hiện — Spearman ρ ≈ 0.34 (hai chiều p ≈ 0.04). Các frame ngắn, bị ràng buộc bởi overhead, nằm ở dưới cùng: khi một frame hoàn thành trong năm giây, chi phí cố định per-tác vụ — tải scene, đồng bộ, lớp ảo hóa cũ — chiếm hầu hết đồng hồ, và một card nhanh hơn có ít thứ để tận dụng. Các frame nặng hơn, bị ràng buộc bởi tính toán, được lợi nhiều hơn. Nhưng có sự phân tán thực sự: một scene nặng chỉ đạt 1.6x vì điểm nghẽn của nó không phải GPU mà có thể là storage hoặc một giai đoạn bị ràng buộc bởi CPU. Trung vị nói một điều; phạm vi nói rằng điều đó phụ thuộc vào scene.
AI denoising đã là mặc định từ trước
Hỏi AI thực sự đứng ở đâu trong pipeline render production năm 2026, và log của chúng tôi đưa ra câu trả lời không hào nhoáng: trong denoiser. Khoảng 83% job Cycles trên node 5090 chạy một lượt AI denoise — OptiX hoặc Intel Open Image Denoise — và tỷ lệ trên các node thế hệ trước của chúng tôi về cơ bản là giống hệt. Card mới không bắt đầu thói quen đó; nó đã là tiêu chuẩn trên phần cứng cũ và vẫn là tiêu chuẩn trên phần cứng mới. Đối với một pipeline nặng denoising, một bước nhảy thế hệ không mua cho bạn "AI" vốn đã có sẵn ở đó — nó mua throughput path-tracing xung quanh một bước đã là thông lệ. Con số này được giới hạn trong phạm vi Cycles theo chủ đích; hãy hoài nghi với bất kỳ "% AI" toàn farm nào không gắn với một engine cụ thể.
VRAM trong thực tế
Cycles ghi số liệu bộ nhớ thiết bị đỉnh vào log render — một proxy khiêm tốn nhưng có thể dùng được cho những gì production thực sự đòi hỏi từ VRAM. Trên 57 job Cycles mà dòng đó được ghi lại, bộ nhớ render-device đỉnh khoảng 5.6 GB ở trung vị và 11.5 GB ở phân vị thứ 90. Các card thế hệ trước của chúng tôi là các phần 10–12 GB, vì vậy job trung vị sẽ vừa — nhưng job phân vị thứ 90 đã chạm sát trần của chúng. Và đuôi còn xa hơn: job nặng nhất ghi lại khoảng 37 GB, vượt qua cả 32 GB của chính 5090 — loại scene mà trên GPU nghĩa là CPU fallback hoặc không render được. Log không có metadata scene, vì vậy chúng tôi không thể cho bạn biết loại scene đó là gì — chỉ biết class của nó: working set 37 GB là dấu hiệu của geometry nặng, bộ texture độ phân giải cao, hoặc volumetrics, loại job vượt quá ngay cả card 32 GB và, trên một GPU đơn, đơn giản là dừng lại. Nguyên tắc của operator vẫn đúng: bạn sizing VRAM cho đuôi, không phải trung vị. Đó là lý do tại sao cả bộ nhớ trên card oversized lẫn công suất cloud render farm GPU dùng chung đều tồn tại — để bạn có thể tiếp cận một card lớn hơn cho mỗi job thay vì mua một card.
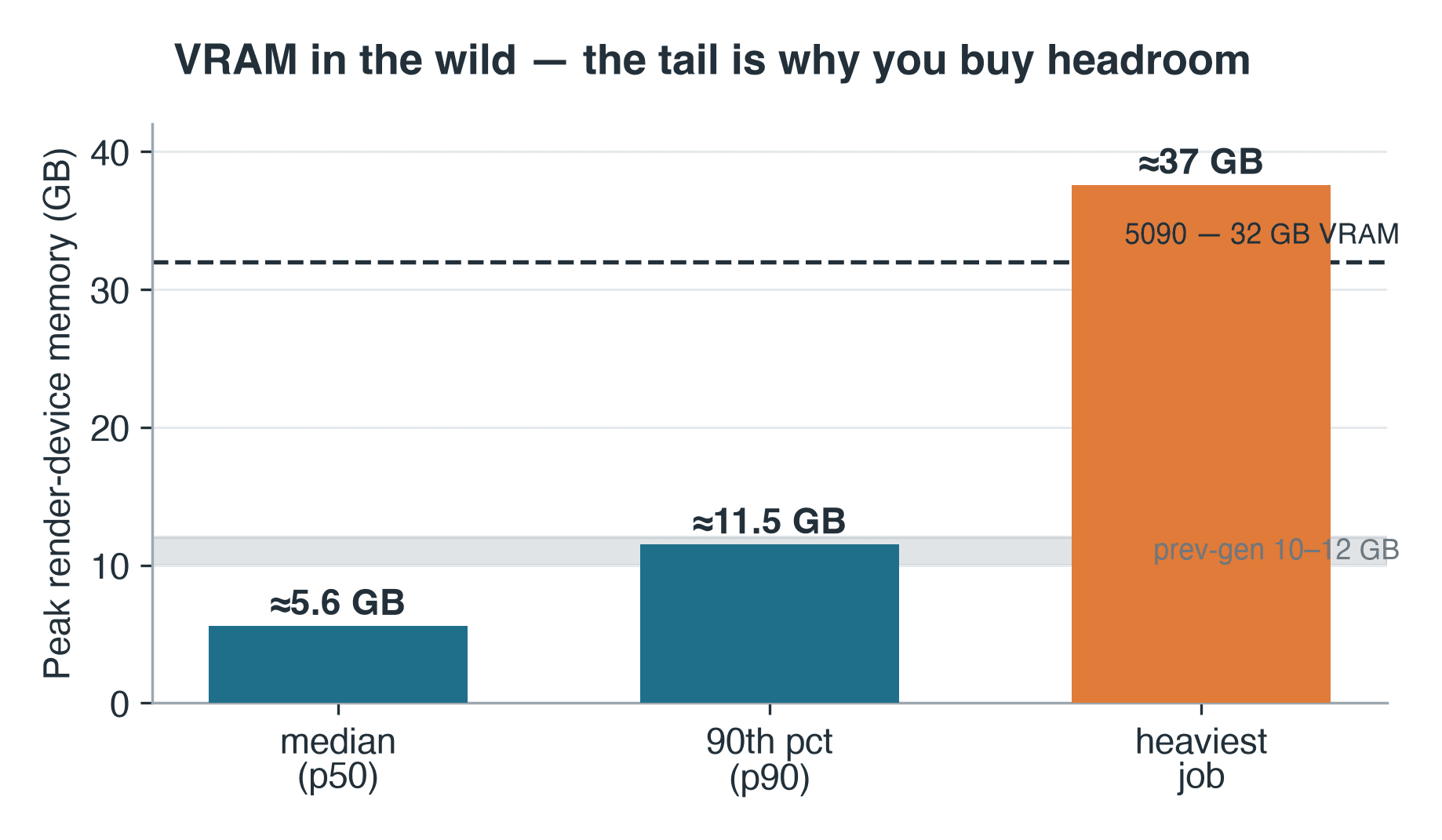
Bộ nhớ render-device đỉnh cho các job Blender Cycles trên node RTX 5090: trung vị 5.6 GB, phân vị thứ 90 là 11.5 GB, job nặng nhất 37 GB
Bộ nhớ render-device đỉnh trên 57 job Cycles đã được ghi log. Job nặng nhất vượt qua cả 32 GB của chính 5090.
Một driver duy nhất và điện năng ổn định
Phát hiện ít kịch tính nhất là điều chúng tôi muốn biết nhất trước khi mua. Một driver — 581.80, trên CUDA 13.0 — chạy toàn bộ khoảng thời gian với zero thay đổi: không rollback, không swap giữa chừng. Đối với phần cứng chu kỳ sớm trên hàng đợi production, một log driver nhàm chán là lời khen ngợi.
Điện năng cũng bình thản tương tự. Trên một bench run kiểm soát của cùng các card dưới tải duy trì, mỗi card tiêu thụ khoảng 360–375 W (đỉnh gần 400) ở 68–83 °C — card phía trên trong cặp xếp chồng chạy nóng nhất, nhưng thấp hơn nhiều so với mức rated ~575 W. Hãy lập ngân sách cho mức tiêu thụ duy trì đó, không phải đỉnh rated. Năng lượng per-frame hoàn thành khoảng 2.5 Wh ở frame Cycles trung vị khoảng 24 giây — nhưng hãy coi đó là suy luận: nó dựa trên mức tiêu thụ bench và được tính cho riêng 5090, không được đo so với các node cũ.
Tại sao ghi chép này bắt đầu với Blender
Trong 90 ngày gần nhất, các job GPU chiếm khoảng một phần tư tổng số render của farm chúng tôi — phần còn lại là công việc CPU. Trong hỗn hợp GPU, Cycles chiếm khoảng 74% job và Redshift là thứ hai rõ ràng ở khoảng 15%, đó là lý do tại sao một bài viết RTX 5090 về render farm bắt đầu với Blender cloud rendering. Để biết cách nhiều card như vậy hoạt động cùng nhau, xem ghi chép đồng hành của chúng tôi về hiệu suất cluster RTX 5090, và để biết cụ thể về cạnh VRAM, nơi giới hạn VRAM ảnh hưởng đến các scene phức tạp.
Hai điều được rút ra từ hàng đợi này. Thứ nhất, production không phải benchmark — một card đạt con số clean trong lab vẫn phải hấp thụ overhead ảo hóa, workload hỗn hợp, và các scene mà nó chưa từng được tune cho, và kết quả là một phân phối, không phải một điểm. Thứ hai, trung vị không phải đuôi. Tốc độ tăng điển hình 3.2x và đỉnh bộ nhớ 37 GB của một job đều đúng cùng lúc, và bạn lập kế hoạch công suất xung quanh cả hai. Card thực sự nhanh ở nơi công việc nặng. Ở những nơi không như vậy, hàng đợi cho bạn biết lý do tại sao.
Phương pháp, tóm tắt
Mọi con số ở đây đều đến từ các bản ghi tác vụ của scheduler của chúng tôi, không phải test dàn dựng. Thời gian per-frame là wall-clock của tác vụ chia cho số frame; tốc độ tăng headline là trung vị của các trung vị per-scene trên 38 cặp phù hợp, và khoảng tin cậy là bootstrap 20,000 mẫu. Lưu ý mẫu nào hỗ trợ tuyên bố nào: 38 scene theo cặp cho tốc độ tăng, 57 job đã ghi log cho VRAM, và một bench run kiểm soát riêng biệt cho điện năng và nhiệt độ — không phải hàng đợi production. 18 tác vụ thất bại (trong khoảng 4,900) được tính là thất bại, không bị loại bỏ; scheduler ghi trạng thái nhưng không ghi nguyên nhân, vì vậy chúng tôi để chúng không điều tra thay vì đoán. Không có gì ở đây khó tái tạo về mặt tinh thần — đó là những gì bất kỳ operator nào cũng có thể kéo ra từ log hàng đợi của họ, và chúng tôi sẵn sàng hướng dẫn một studio qua phương pháp này chi tiết hơn.
FAQ
Q: RTX 5090 nhanh hơn bao nhiêu so với thế hệ trước cho Blender Cycles? A: Trên 38 scene production theo cặp (cùng scene và người dùng trên cả hai thế hệ), thời gian per-frame trung vị giảm khoảng 69% — tốc độ tăng trung vị 3.2x, với bootstrap 95% confidence interval là 3.0–3.3x. Các scene riêng lẻ dao động từ 1.6x đến 5.1x. Đây là dữ liệu quan sát, node-vs-node, không phải benchmark có kiểm soát.
Q: Tại sao tốc độ tăng lại biến thiên nhiều giữa các scene? A: Tốc độ tăng theo dõi workload per-frame theo một xu hướng dương lỏng lẻo (Spearman ρ ≈ 0.34). Các frame ngắn, bị ràng buộc bởi overhead, được lợi ít nhất vì chi phí cố định per-tác vụ — tải scene, đồng bộ, lớp ảo hóa cũ — chiếm ưu thế; các frame nặng hơn, bị ràng buộc bởi tính toán, được lợi nhiều hơn. Một scene nặng chỉ đạt 1.6x vì điểm nghẽn là storage hoặc một giai đoạn bị ràng buộc CPU, không phải GPU.
Q: Đây có phải là benchmark có kiểm soát mà tôi có thể so sánh với phần cứng của mình không? A: Không. Đây là ghi chép thực tế quan sát từ một node production trực tiếp, chỉ Blender Cycles. Người dùng đã điều chỉnh scene của họ giữa các lần render lại, và phép so sánh là node-vs-node — một 5090 bare-metal đối với các node thế hệ trước ảo hóa — nên một phần khoảng cách là do setup, không phải silicon. Baseline là phần cứng RTX 3080/2080-class, không phải RTX 4090 hiện tại.
Q: Các scene production thực sự dùng bao nhiêu VRAM? A: Trên 57 job Cycles đã được ghi log, bộ nhớ render-device đỉnh khoảng 5.6 GB ở trung vị và 11.5 GB ở phân vị thứ 90. Job đơn nặng nhất ghi khoảng 37 GB — vượt qua 32 GB của chính 5090 — điều này trên GPU nghĩa là CPU fallback hoặc không render được. Hãy sizing VRAM cho đuôi, không phải trung vị.
Q: RTX 5090 có thay đổi tần suất sử dụng AI denoising không? A: Không. Khoảng 83% job Cycles trên node 5090 chạy một lượt AI denoise (OptiX hoặc Intel Open Image Denoise) — và tỷ lệ về cơ bản giống hệt trên thế hệ trước. AI denoising đã là tiêu chuẩn từ trước; card mới chỉ thay đổi tốc độ của mọi thứ xung quanh nó.
Q: Driver ổn định như thế nào trong bảy tuần? A: Một driver — 581.80 trên CUDA 13.0 — chạy toàn bộ cửa sổ 51 ngày với zero thay đổi: không rollback, không swap giữa chừng. Đối với phần cứng chu kỳ sớm trên hàng đợi production, sự ổn định đó là một kết quả có ý nghĩa riêng của nó.
Q: Mức tiêu thụ điện và nhiệt độ dưới tải là bao nhiêu? A: Trên một bench run kiểm soát dưới tải duy trì, mỗi card tiêu thụ khoảng 360–375 W, đỉnh gần 400 W, ở 68–83 °C — thoải mái dưới mức rated ~575 W của card. Năng lượng per-frame khoảng 2.5 Wh, đây là suy luận từ phép đo bench đó, được tính cho riêng 5090.
Q: Các con số này có áp dụng cho các render engine khác không? A: Không. Nghiên cứu này chỉ dành cho Blender Cycles GPU, trên một node đơn. Các engine khác ghi log denoising, bộ nhớ và timing theo cách khác. Hãy coi đây là ghi chép thực tế dành riêng cho Cycles, không phải tuyên bố toàn farm hoặc cross-engine.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



