
Multi-GPU Scaling: 1 vs 2 GPU Thực Sự Làm Gì Cho Việc Render (Benchmark 2026)
Tổng quan
Giới thiệu
TL;DR: GPU thứ hai hiếm khi tăng gấp đôi tốc độ render, và mức độ hữu ích phụ thuộc hoàn toàn vào render engine. Trong các benchmark năm 2026 của chúng tôi trên các node dual RTX 5090 và RTX 4090, các engine throughput (V-Ray, Octane) scale gần 2.00x, trong khi các engine render-time scale thấp hơn — Cycles 1.31x-1.63x, Redshift 1.68x-1.92x — vì overhead cố định mỗi lần render lấy đi phần mà GPU thứ hai có thể tăng tốc. Hai GPU là mức trần thực tế mỗi node; throughput thực sự của một render farm đến từ việc chạy nhiều khung hình trên nhiều node song song, không phải chồng thêm card vào một máy.
GPU thứ hai không làm cho việc render nhanh gấp đôi. Điều đó nghe có vẻ hiển nhiên khi đã nói ra, nhưng nhiều quyết định phần cứng được đưa ra dựa trên giả định rằng hai card đồng nghĩa với tốc độ gấp đôi. Chúng tôi đã tháo hai node benchmark ra khỏi hàng đợi vào tháng 6 năm 2026 — một node với hai RTX 5090, một node với hai RTX 4090 — và đo lường điều thực sự xảy ra khi bạn chuyển từ một card lên hai card, trên bốn render engine và bảy tổ hợp scene/benchmark.
Tóm gọn: kết quả phụ thuộc hoàn toàn vào engine. Các benchmark theo hướng throughput (V-Ray, Octane) scale gần như hoàn hảo, khoảng 2x. Các engine theo thời gian render (Cycles, Redshift) scale thấp hơn, và trên card nhanh hơn, GPU thứ hai giúp ích ít hơn, không nhiều hơn. Chúng tôi sẽ đi qua các con số, giải thích tại sao đường cong uốn theo cách đó, và — quan trọng không kém — làm rõ giới hạn ở đây. Hai card là mức trần trên một node đơn. Vượt qua đó là một kiến trúc khác, không phải phiên bản lớn hơn của thiết lập này.
Đây là bài viết về phần cứng/benchmark, vì vậy nó thiên về GPU nhiều. Đáng nói trước rằng GPU chiếm thiểu số trong những gì chạy trên render farm của chúng tôi — phần lớn công việc sản xuất ở đây vẫn là CPU rendering (V-Ray, Corona, Arnold trên CPU). Nhưng khi ai đó hỏi "GPU thứ hai có đáng không," họ xứng đáng được nhận các con số đo lường, không phải một bài chào hàng. Vì vậy, đây là các con số đo lường.
Cách chúng tôi kiểm thử (và những gì các con số này không phải)
Cả hai node test đều chạy Windows 11 Pro với hai GPU mỗi node. Node 5090 sử dụng driver 596.36; node 4090 sử dụng driver 610.62 — card Blackwell cần driver mới hơn, vì vậy không thể khớp chính xác. Sự chênh lệch driver đó chỉ quan trọng với một điều: so sánh tốc độ xuyên thế hệ tuyệt đối giữa 5090 và 4090. Các tỷ lệ scaling mà chúng tôi tập trung vào ở đây được đo trong một node đơn (cùng card, cùng driver, một GPU so với hai GPU), vì vậy sự khác biệt driver không ảnh hưởng đến chúng.
Mọi scene đều là benchmark chuẩn của nhà cung cấp — các scene Open Data của Blender (bmw27, classroom, junkshop), scene "Vultures" của Maxon cho Redshift, Chaos V-Ray Benchmark 6.00.02, và OctaneBench 2025.2.1. Không có dự án khách hàng, không có asset sản xuất. Chúng tôi không công bố thời gian render từng khung hình theo phút, chi phí mỗi khung hình, hay số liệu điện năng ở đây, vì bộ dữ liệu này không chứa chúng và chúng tôi không tự bịa ra.
Một lưu ý về phương pháp ảnh hưởng đến cách bạn đọc các hàng Cycles: chúng tôi chạy Blender Cycles ở độ phân giải 200%, nặng hơn mặc định của Open Data, cụ thể để mỗi lần render kéo dài đủ lâu để tạo ra tỷ lệ scaling ổn định, đáng tin cậy. Điều đó có nghĩa là thời gian Cycles thô của chúng tôi không thể so sánh với điểm số Open Data công khai — chúng được điều chỉnh để đo lường scaling, không phải để khoe khoang trên bảng xếp hạng. Cycles và Redshift được đo bằng thời gian render (giây, thấp hơn là tốt hơn); V-Ray và Octane được đo bằng điểm số benchmark (vpaths hoặc điểm OctaneBench, cao hơn là tốt hơn). Đó là hai loại chỉ số khác nhau, vì vậy các con số tuyệt đối không bao giờ so sánh xuyên engine — chỉ tỷ lệ scaling trong cùng engine mới là so sánh công bằng.
Kết quả cốt lõi: Scaling từ 1x lên 2x, theo từng engine
Đây là dữ liệu tiêu đề — GPU thứ hai giống hệt thực sự mang lại gì cho bạn, theo engine và scene:
| Engine | Scene | Scaling 2x RTX 5090 | Scaling 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1.54x | 1.58x |
| Cycles | classroom | 1.59x | 1.63x |
| Cycles | junkshop | 1.31x | 1.38x |
| Redshift | Vultures | 1.68x | 1.92x |
| V-Ray GPU (CUDA) | benchmark | 1.97x | 2.00x |
| V-Ray GPU (RTX) | benchmark | 2.00x | 2.00x |
| Octane | OctaneBench suite | 2.00x | 1.98x |
Đọc từ trên xuống dưới và một sự phân chia rõ ràng xuất hiện. V-Ray và Octane đạt ở mức hoặc ngay dưới 2.00x trên cả hai card — GPU thứ hai gần như tăng gấp đôi sản lượng. Cycles nằm trong khoảng 1.31x–1.63x. Redshift đạt 1.68x trên 5090 và 1.92x trên 4090.
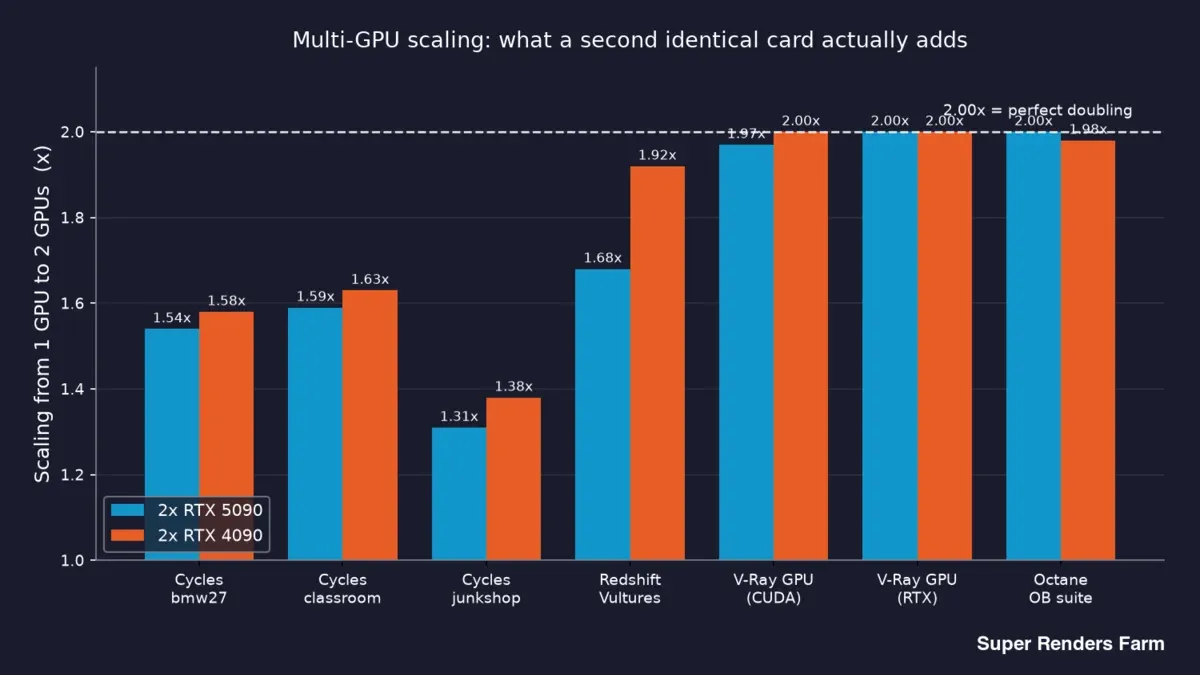
Biểu đồ thanh về scaling từ 1 GPU lên 2 GPU theo engine trên node dual RTX 5090 và dual RTX 4090: Cycles 1.31x đến 1.63x, Redshift 1.68x so với 1.92x, V-Ray và Octane gần 2.00x
Vì vậy, "việc thêm GPU thứ hai có tăng gấp đôi tốc độ không?" có ba câu trả lời trung thực khác nhau tùy thuộc vào những gì bạn render: về cơ bản là có với V-Ray và Octane, khoảng 1.5x với Cycles, và ở đâu đó ở giữa với Redshift. Bất kỳ ai nói với bạn rằng một hệ số nhân đơn lẻ bao gồm tất cả việc render đều chưa thực sự đo lường nó.
Tại sao các engine throughput scale tốt hơn các engine render-time
Mô hình này không phải ngẫu nhiên — nó xuất phát từ cách mỗi benchmark sử dụng thời gian. V-Ray Benchmark và OctaneBench là các bài test throughput. Chúng tung một khối lượng công việc lên bất cứ bao nhiêu tài nguyên tính toán có sẵn và báo cáo điểm số, và chi phí thiết lập cố định (tải scene, xây dựng cấu trúc tăng tốc, khởi tạo thiết bị) chỉ là một phần nhỏ trong tổng thời gian chạy. Thêm card thứ hai và hầu hết silicon bổ sung đó đi thẳng vào công việc hữu ích, vì vậy bạn đạt gần 2x. Kết quả V-Ray RTX đạt đúng 2.00x trên cả hai card là chính xác những gì bạn sẽ mong đợi từ một khối lượng công việc mà chi phí overhead về cơ bản là nhiễu.
Các engine render-time hoạt động khác nhau. Khi bạn đo lường một lần render Cycles hoặc Redshift bằng giây thực tế, bạn đang tính giờ toàn bộ công việc — và mỗi công việc đều mang theo một phần overhead cố định không song song được: phân tích scene, xây dựng BVH/cấu trúc tăng tốc, biên dịch kernel và khởi động, phối hợp thiết bị, giải quyết pixel cuối cùng. GPU thứ hai tăng tốc phần thực sự có thể phân chia giữa các card. Nó không làm gì cho phần cố định. Càng nhiều tổng thời gian render là overhead cố định, scaling càng xa dưới 2x.
Đó là lý do tại sao Cycles junkshop (1.31x–1.38x) scale kém hơn Cycles classroom (1.59x–1.63x): junkshop là render nhẹ hơn, ngắn hơn, vì vậy overhead cố định của nó chiếm tỷ lệ lớn hơn của tổng thể, để lại ít hơn cho GPU thứ hai tăng tốc. Scene classroom chạy lâu hơn, phần song song chiếm ưu thế, và GPU thứ hai có nhiều chỗ để giúp đỡ hơn. Cùng engine, cùng phần cứng — scene quyết định GPU thứ hai quan trọng như thế nào.
Phần trái với trực giác: Card nhanh hơn scale kém hơn
Nhìn lại hàng Redshift. Hai RTX 5090 scale 1.68x. Hai RTX 4090 scale 1.92x. Card mới hơn, nhanh hơn scale tệ hơn. Điều đó trông giống như một lỗi. Nhưng không phải — đây là con số hướng dẫn nhiều nhất trong toàn bộ bộ dữ liệu.
Đây là cơ chế. 5090 là card nhanh hơn về tuyệt đối; trên một GPU đơn, nó hoàn thành scene Vultures trong khoảng 57 giây so với 100 giây của 4090. Nhưng overhead cố định mỗi lần render — phân tích, xây dựng, khởi động — là khoảng cùng số giây bất kể card nào chạy nó. Trên 4090, phần cố định đó là một phần nhỏ của render dài 100 giây, vì vậy GPU thứ hai có phần song song lớn để xử lý và scaling đạt gần 1.92x. Trên 5090, render đã ngắn, vì vậy cùng phần cố định đó chiếm tỷ lệ lớn hơn của tổng thể, để lại phần song song nhỏ hơn cho GPU thứ hai tăng tốc — và scaling chỉ đạt 1.68x.
Điều quan trọng, điều này không có nghĩa là 5090 tệ hơn. Nó nhanh hơn với một card và nhanh hơn với hai card. Nó chỉ đơn giản là nhận được tỷ lệ ít hơn từ GPU thứ hai vì nó có ít render chậm để tăng tốc từ đầu. Card nền tảng càng nhanh, GPU thứ hai càng khó đạt được 2x sạch — đơn giản là còn ít thời gian hơn để song song hóa. Đây là điều thực sự hữu ích cần hiểu trước khi bạn chi tiền chồng các card giống nhau mong đợi lợi nhuận tuyến tính.
Tốc độ mỗi card: RTX 5090 vs RTX 4090
Scaling là một trục; tốc độ thô mỗi card là trục kia. Trên một card đơn, với lưu ý về driver từ phần phương pháp được áp dụng, 5090 vượt trội trên mọi engine chúng tôi kiểm thử:
| Engine | Chỉ số | RTX 5090 | RTX 4090 | Lợi thế 5090 |
|---|---|---|---|---|
| Cycles — bmw27 | giây (thấp hơn là tốt hơn) | 49.45 | 77.40 | 1.57x |
| Cycles — classroom | giây | 23.09 | 36.87 | 1.60x |
| Cycles — junkshop | giây | 19.71 | 34.43 | 1.75x |
| Redshift — Vultures | giây | 57 | 100 | 1.75x |
| V-Ray GPU (CUDA) | vpaths (cao hơn là tốt hơn) | 11.051 | 7.419 | 1.49x |
| V-Ray GPU (RTX) | vpaths | 15.333 | 9.608 | 1.60x |
| Octane | Điểm OctaneBench | 1.690,78 | 1.074,17 | 1.57x |
Nhìn chung, 5090 nhanh hơn khoảng 1.5x đến 1.75x mỗi card. Hai điểm rút ra cho bất kỳ ai lên kế hoạch phần cứng. Thứ nhất, lợi nhuận mỗi card theo thế hệ (1.5x–1.75x ở đây) lớn hơn và đáng tin cậy hơn so với lợi ích từ việc thêm card thứ hai cùng thế hệ trên engine render-time (thường dưới 2x). Nói đơn giản: card nhanh hơn thường là đòn bẩy tốt hơn so với card thứ hai. Thứ hai, các con số xuyên thế hệ đơn card này mang lưu ý về sự không khớp driver — hãy coi chúng là so sánh định hướng, không phải đảm bảo cấp độ dịch vụ. Chúng tôi đo lường trên các scene benchmark; độ phức tạp scene, lấy mẫu và độ phân giải đầu ra của bạn sẽ làm thay đổi con số thực tế. Để biết thêm về hành vi 5090 đơn card, hãy xem bài viết hiệu suất cloud rendering GPU RTX 5090 của chúng tôi.
Hai GPU là mức trần mỗi node — và tại sao điều đó ổn
Đây là nơi chúng tôi vẽ một ranh giới cứng, vì đây là phần mà hầu hết nội dung multi-GPU bỏ qua. Mọi node trong benchmark này đều là node hai GPU. Hai card là mức trần mỗi node. Chúng tôi sẽ không hiển thị cho bạn đường cong scaling 4x hoặc 8x đơn node, vì đó không phải là cấu hình chúng tôi chạy, và chúng tôi sẽ không ngụ ý điều khác.
Vượt quá hai GPU trên một khung hình đơn có nghĩa là kết xuất phân tán đa node — chia một hình ảnh trên nhiều máy, với tất cả sự phối hợp mạng, quản lý bucket/tile, và overhead mà điều đó ngụ ý. Đó là một kiến trúc thực sự riêng biệt, không phải phiên bản lớn hơn của hộp hai card. Đây không phải là điều chúng tôi cung cấp ngày nay cho một khung hình đơn, vì vậy chúng tôi sẽ không treo nó như một tính năng "sắp có" với ngày cụ thể.
Và đây là điều: đối với phần lớn công việc sản xuất, mức trần hai GPU không phải là hạn chế quan trọng nhất. Hạn chế xuất hiện đầu tiên hầu như luôn là VRAM, không phải số lượng card — một scene không vừa trong 32 GB sẽ không render bất kể bạn chỉ bao nhiêu GPU vào nó, đó là một vấn đề hoàn toàn khác (chúng tôi đề cập đến nó trong giới hạn VRAM RTX 5090 cho các scene phức tạp). Khi mọi người hình dung "mở rộng quy mô render farm," họ thường tưởng tượng một render khổng lồ trở nên nhanh hơn trên ngày càng nhiều silicon. Đó không phải là cách throughput ở quy mô render farm thực sự hoạt động.
Cách render farm thực sự mở rộng quy mô: Khung hình, không phải card
Đây là sự phân biệt đáng nội tâm hóa, và đó là điều mà các con số benchmark ở trên luôn chỉ ra. Có hai điều hoàn toàn khác nhau mà mọi người có nghĩa là "render nhanh hơn trên nhiều phần cứng hơn":
- Chia một khung hình trên nhiều GPU hoặc máy (kết xuất phân tán tile/bucket). Đây là những gì các con số 1x→2x đo lường ở quy mô hai card, và kết xuất phân tán đa node sẽ mở rộng. Nó đạt lợi nhuận giảm dần nhanh chóng trên các engine render-time, như dữ liệu cho thấy, vì overhead cố định mỗi render — và chi phí phối hợp chỉ tăng khi bạn thêm máy.
- Phân phối nhiều khung hình trên nhiều máy (kết xuất song song theo khung hình). Mỗi node render một khung hình đầy đủ trên máy của riêng nó; các khung hình của một hoạt hình được phân phối ra toàn bộ hạm đội song song. Không có overhead phối hợp khung hình đơn để chiến đấu, vì vậy điều này mở rộng gọn gàng và là cách một hoạt hình được hoàn thành nhanh chóng.
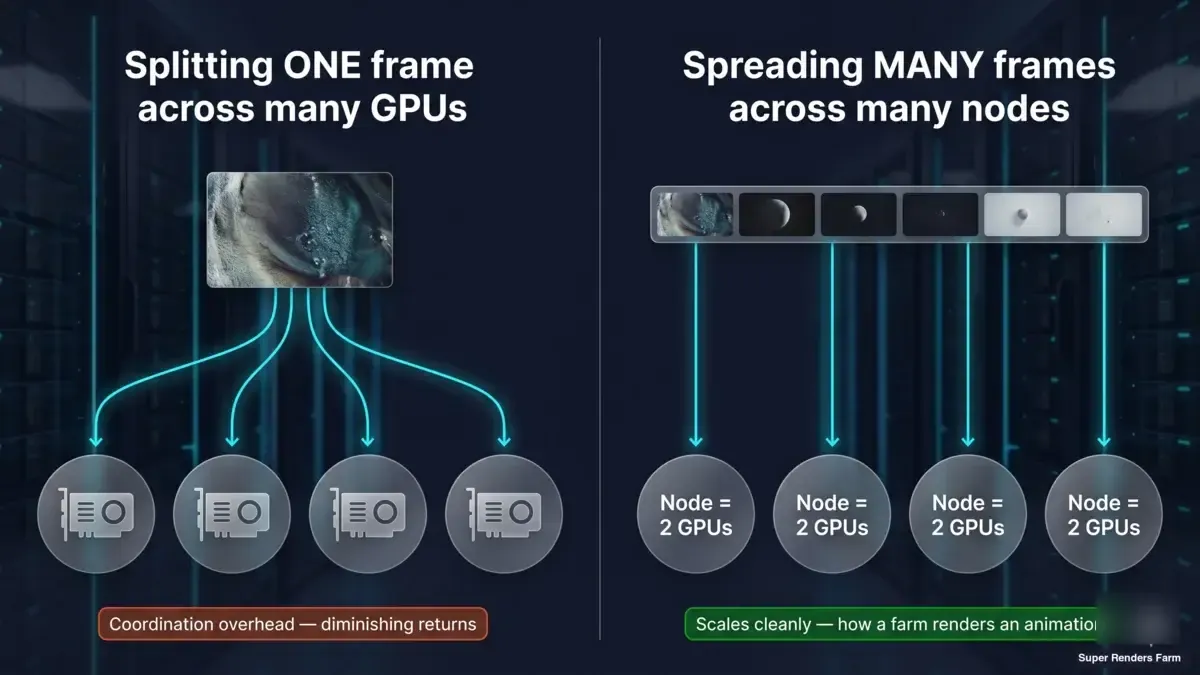
Sơ đồ khái niệm hai bảng: một khung hình chia trên nhiều GPU gặp overhead phối hợp và lợi nhuận giảm dần; nhiều khung hình đầy đủ mỗi khung trên node hai GPU riêng của mình song song mở rộng gọn gàng, đó là cách render farm mở rộng quy mô hoạt hình
Một render farm được quản lý có tốc độ của nó hầu như hoàn toàn từ mô hình thứ hai. Hoạt hình 500 khung hình của bạn không được render như một khung hình trải rộng trên 500 GPU — nó được render như 500 khung hình phân phối khắp hạm đội, mỗi khung trên node riêng của nó, tất cả cùng một lúc. Tốc độ mỗi node, mỗi khung hình được thiết lập bởi loại scaling hai GPU và hiệu suất mỗi card mà chúng tôi đã benchmark ở đây; tốc độ ở mức render farm đến từ bao nhiêu khung hình chạy đồng thời. Chúng là các đòn bẩy khác nhau, và việc nhầm lẫn chúng là nơi bắt đầu rất nhiều sự nhầm lẫn "tôi cần bao nhiêu GPU."
Vì vậy, framing trung thực về multi-GPU hẹp hơn phiên bản marketing. Hai card mỗi node mang lại cho bạn sự tăng cường thực sự, có thể đo lường được — gần 2x trên V-Ray và Octane, khiêm tốn hơn trên Cycles và Redshift. Ngoài đó, câu trả lời không phải là "chồng thêm card vào hộp," mà là "chạy thêm khung hình trên nhiều node hơn." Đó là kiến trúc, và nói thẳng về nó có xu hướng tiết kiệm tiền cho mọi người mà họ sắp chi vào phần cứng không mang lại kết quả theo cách họ giả định.
Điều này có nghĩa gì khi bạn chọn cách render
Tổng hợp lại thành điều gì đó bạn có thể hành động. Nếu bạn đang quyết định giữa một card và hai card cho workstation, engine bạn sử dụng nên thúc đẩy quyết định: người dùng V-Ray hoặc Octane nhận được gần như tăng gấp đôi hoàn toàn và card thứ hai dễ biện minh; người dùng Cycles và Redshift nên mong đợi tăng 1.3x–1.9x và cân nhắc liệu card đơn nhanh hơn (lợi nhuận thế hệ 1.5x–1.75x) có phải là chi tiêu tốt hơn không. Nếu bạn đang quyết định có nên render cục bộ hay giao công việc cho render farm, hãy nhớ lợi thế của render farm là throughput song song theo khung hình trên hoạt hình, không phải hệ số nhân khung hình đơn thần kỳ — một hero still-frame đơn sẽ không render nhanh hơn đáng kể trên render farm so với workstation tương đương, nhưng vài trăm khung hình thì chắc chắn sẽ.
Để biết bối cảnh về sự đánh đổi quản lý-vs-tự-làm — ai xử lý driver, giấy phép và cấu hình node — bài phân tích render farm quản lý toàn diện vs DIY của chúng tôi đề cập đến nó. Trên render farm của chúng tôi, giấy phép render engine (V-Ray, Redshift, Octane) được bao gồm trong giá render và cấu hình node được cố định và duy trì cho bạn, vì vậy thiết lập hai GPU mỗi node và các driver đằng sau những con số này không phải là thứ bạn tự lắp ráp hay điều chỉnh. Cụ thể cho phía Redshift trên Cinema 4D, nơi con số scaling 1.68x rơi vào, hãy xem hướng dẫn render farm Redshift cho Cinema 4D của chúng tôi.
Các phép đo ở đây được cố ý tránh khoa trương. GPU thứ hai là đòn bẩy thực sự với giới hạn thực sự, card nhanh hơn scale kém hơn vì nó có ít render chậm để tăng tốc từ đầu, và tốc độ ở mức render farm là câu chuyện phân phối khung hình, không phải chồng card. Biết đòn bẩy nào áp dụng cho khối lượng công việc của bạn là phần lớn của quyết định.
FAQ
Q: Việc thêm GPU thứ hai có tăng gấp đôi tốc độ render không? A: Thường thì không. Trong các benchmark 2026 của chúng tôi, các engine throughput như V-Ray và Octane scale gần 2.00x với card thứ hai giống hệt, nhưng các engine render-time scale thấp hơn — Cycles đạt từ 1.31x đến 1.63x và Redshift đạt 1.68x trên dual RTX 5090. Mức tăng phụ thuộc hoàn toàn vào engine và scene, vì mỗi lần render đều mang overhead cố định mà GPU thứ hai không thể tăng tốc.
Q: Tại sao Redshift scale tốt hơn trên RTX 4090 so với RTX 5090? A: Vì 5090 nhanh hơn, các lần render của nó ngắn hơn, vì vậy overhead cố định mỗi render (phân tích scene, xây dựng cấu trúc tăng tốc, khởi động kernel) chiếm tỷ lệ lớn hơn của tổng thể. Điều đó để lại phần song song nhỏ hơn cho GPU thứ hai tăng tốc, vì vậy scaling chỉ đạt 1.68x trên 5090 so với 1.92x trên 4090. 5090 vẫn nhanh hơn trên cả một và hai card — nó chỉ đơn giản là nhận được tỷ lệ ít hơn từ GPU thứ hai.
Q: RTX 5090 nhanh hơn RTX 4090 bao nhiêu để render? A: Khoảng 1.5x đến 1.75x nhanh hơn mỗi card trên các engine chúng tôi kiểm thử, bao gồm Cycles, Redshift, V-Ray GPU và Octane. Các con số xuyên thế hệ đơn card này mang một lưu ý nhỏ vì hai card chạy các driver NVIDIA khác nhau, vì vậy hãy coi chúng là so sánh định hướng thay vì đảm bảo cố định.
Q: Tại sao V-Ray và Octane scale tốt hơn Cycles và Redshift trên hai GPU? A: V-Ray Benchmark và OctaneBench là các bài test throughput mà chi phí thiết lập cố định chỉ là một phần nhỏ trong tổng thời gian chạy, vì vậy card thứ hai đi gần như hoàn toàn vào công việc hữu ích và scaling tiếp cận 2.00x. Cycles và Redshift được đo bằng tổng thời gian render, bao gồm overhead không song song được mà GPU thứ hai không thể tăng tốc, vì vậy scaling của chúng nằm dưới 2x.
Q: Render farm có thể làm cho một khung hình render nhanh hơn trên nhiều máy không? A: Việc chia một khung hình trên nhiều máy là kết xuất phân tán đa node, đây là một kiến trúc riêng biệt với overhead phối hợp riêng của nó và không phải là điều chúng tôi cung cấp ngày nay cho một khung hình đơn. Render farm được quản lý có được tốc độ từ kết xuất song song theo khung hình thay thế — nhiều khung hình đầy đủ được phân phối trên nhiều node cùng một lúc — vì vậy hoạt hình hoàn thành nhanh trong khi một hero frame đơn render ở khoảng tốc độ mỗi node.
Q: Tôi thực sự cần bao nhiêu GPU để render? A: Đối với một node đơn, hai GPU là mức trần hợp lý và là những gì các node benchmark của chúng tôi sử dụng; ngoài đó, hạn chế thực tế thường là VRAM, không phải số lượng card, vì scene không vừa trong bộ nhớ sẽ không render bất kể bạn thêm bao nhiêu card. Nếu bạn render hoạt hình, throughput thực sự đến từ việc chạy nhiều khung hình trên nhiều node hơn thay vì chồng thêm card vào một máy.
Q: Các con số benchmark này có thể so sánh với điểm số Blender Open Data công khai không? A: Không. Chúng tôi chạy Blender Cycles ở độ phân giải 200%, nặng hơn mặc định của Open Data, để mỗi lần render kéo dài đủ lâu để tạo ra tỷ lệ scaling ổn định. Điều đó khiến thời gian Cycles thô của chúng tôi cố ý không thể so sánh với bảng xếp hạng Open Data công khai — các scene được điều chỉnh để đo lường scaling, không phải để khớp với điểm số chuẩn.
Q: Tôi có cần quản lý driver GPU và giấy phép để sử dụng render farm được quản lý không? A: Không. Trên render farm quản lý toàn diện, cấu hình node, driver và giấy phép render engine (V-Ray, Redshift, Octane) đều được xử lý cho bạn và bao gồm trong giá render, vì vậy thiết lập node hai GPU và các driver đằng sau các benchmark này không phải là thứ bạn tự lắp ráp hay điều chỉnh. Cycles là miễn phí và mã nguồn mở, vì vậy nó không cần giấy phép riêng.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



