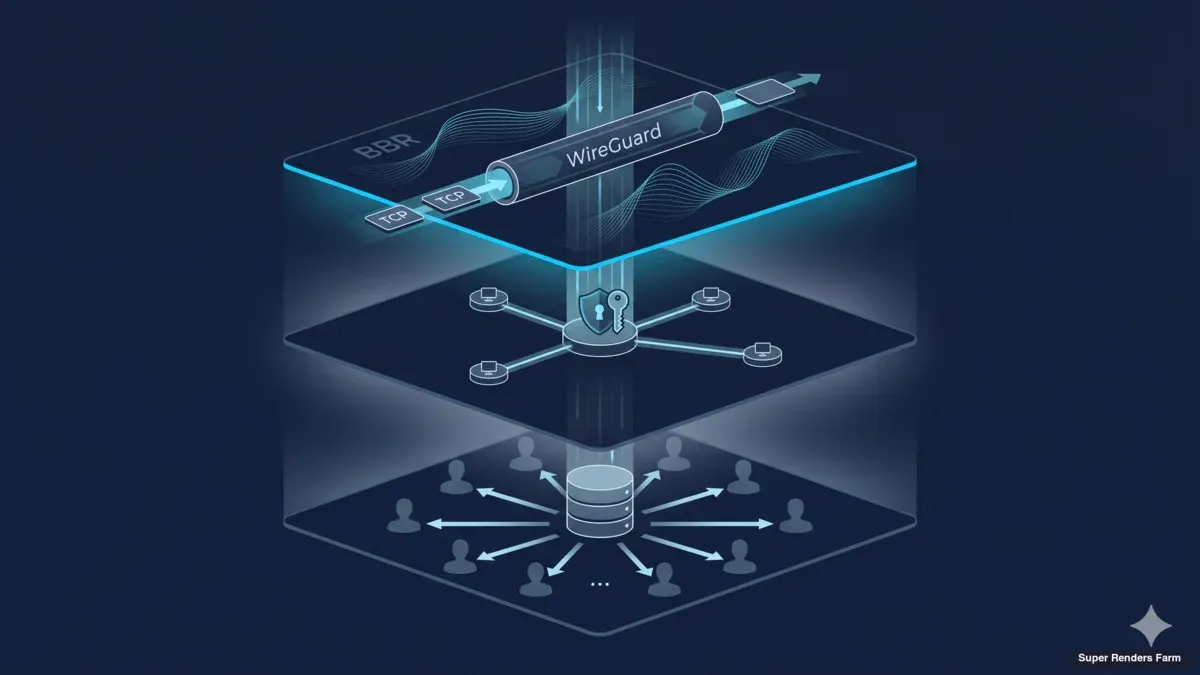
Arquitetura de render farm cross-country: WireGuard, BBR e cache SMB partilhada
Visão geral
Introdução
Construir uma render farm que vive num único rack, numa única sala, sobre um único switch, é um problema resolvido. Os comprimentos de cabo são curtos, os tempos de ida e volta medem-se em microssegundos, e a biblioteca de assets vive num NAS que cada worker lê à velocidade do porto do switch. A maioria dos guias de render farm assume silenciosamente esta topologia, porque é aquela em que tudo simplesmente funciona.
A arquitetura muda quando a render farm tem de abranger mais do que um sítio. Um cluster de 20 nós dividido entre dois locais na mesma metrópole já é um problema de rede diferente; um cluster que se estende entre países é outro problema ainda. Os tempos de ida e volta passam de submilissegundo para dezenas ou centenas de milissegundos, o jitter em rotas ISP públicas torna-se um ruído de fundo constante, a MTU entre quaisquer dois endpoints torna-se uma pergunta em vez de uma assunção, e a biblioteca de assets que vivia num único NAS tem agora de ser replicada para cada sítio ou colocada em cache a pedido. A abordagem ingénua — mesmo NAS, mesma fila de submission, mesma SMB share, apenas com cabos mais longos — aparece como modos de falha silenciosos: sessões que mantêm a ligação mas nunca transferem um frame, submissions de render que ficam a 99 por cento porque o push final de assets para um nó remoto entra em timeout, license check-outs que sucedem localmente e falham remotamente sem razão óbvia.
Este artigo descreve a arquitetura que operamos para deployments de render farm cross-country — a topologia WireGuard hub-and-spoke, o controlo de congestionamento TCP BBR, a disciplina de MSS clamping, uma camada de cache SMB3 partilhada e uma superfície de firewall endurecida. Os componentes são comuns, as decisões de configuração nem sempre são óbvias, e as lições aprendidas custaram-nos sobretudo tempo de debugging antes de custarem dinheiro a quem quer que seja. O público-alvo são arquitetos de infraestrutura e engenheiros DevOps que estão a dimensionar uma build semelhante, mais decisores de TI que querem saber em que é que a equipa se está a meter. Para um passo-a-passo operacional do mesmo stack, o nosso operational deployment guide cobre a sequência de rollout dia a dia. Para uma visão geral, a página cross-country render farm overview cobre o business case.
Topologia WireGuard hub-and-spoke

Túnel cifrado a ligar dois sítios distantes
A camada de transporte do cluster é a WireGuard. Usamo-la tanto para ligações de cliente (workstations dos artistas para a render farm) como para a ligação site-to-site entre o datacenter principal e o sítio secundário. A topologia é hub-and-spoke: um servidor WireGuard corre no gateway do datacenter principal, cada peer cliente liga-se a esse hub, e o sítio secundário liga-se como outro peer com uma sub-rede encaminhada por trás.
O apelo da WireGuard para este tipo de build é sobretudo mecânico. O protocolo usa criptografia moderna fixa (Curve25519 para troca de chaves, ChaCha20-Poly1305 para o data plane, BLAKE2s para hashing), corre no kernel Linux em vez de em userspace, e configura-se com um ficheiro chave-e-AllowedIPs que cabe num ecrã. Comparada com a OpenVPN, a superfície de configuração é cerca de uma ordem de grandeza menor, o throughput num nó Xeon típico é várias vezes superior ao mesmo custo de CPU, e o codebase é suficientemente pequeno para tornar a auditoria tratável. Comparada com IPsec, não há fase de negociação IKE que possa falhar de maneiras interessantes, não há dança de identidade de peer no rekey, e não há daemon userspace que possa fazer crash. Operámos as três em deployments passados; as configurações WireGuard são as que se aguentam sem intervenção.
A disposição hub-and-spoke significa que cada fluxo site-to-site transita pelo gateway do datacenter principal. Para um deployment cross-country de dois sítios este é o trade-off correto: concentra a superfície de ataque de IP pública numa caixa, aplica um único conjunto de regras de routing e firewall num ponto de estrangulamento, e torna o monitoring direto porque cada handshake e contador de fluxo está visível no hub. Uma full mesh pouparia um hop no tráfego site-to-site mas multiplicaria o trabalho de configuração e a superfície de ataque pública pelo quadrado do número de sítios. Para dois ou três sítios, a hub-and-spoke ganha na simplicidade operacional.
O hub escuta no porto UDP 51820 (default), e é o único porto que a interface pública aceita. Não há fallback TCP. Só-UDP é deliberado — o comportamento de congestionamento da WireGuard está construído à volta de datagramas UDP, e um túnel TCP-sobre-TCP degrada fiavelmente o throughput de longa distância. Em redes que bloqueiam UDP por completo tratamos isso como uma restrição do lado do cliente e contornamos noutra camada.
Cada peer cliente está configurado com uma única entrada AllowedIPs a cobrir a sub-rede interna do cluster. O peer site-to-site tem AllowedIPs a cobrir a sub-rede LAN remota para o kernel saber que pacotes encapsular. PersistentKeepalive é definido para 25 segundos em cada peer atrás de NAT, o que mantém viva a entrada UDP conntrack entre handshakes. Omitimos isto exatamente uma vez e passámos os dois dias seguintes a debuggar «quedas de ligação a cada 90 segundos no sítio secundário»; no terceiro sítio, PersistentKeepalive foi a primeira linha do ficheiro de config.
Controlo de congestionamento TCP BBR
Assim que o túnel WireGuard está em pé, a camada seguinte é o comportamento TCP. O Linux traz CUBIC como algoritmo de controlo de congestionamento por defeito. CUBIC escala a sua janela de congestionamento numa curva cúbica em função do tempo desde o último evento de perda, o que funciona em ligações onde a perda de pacotes é um sinal fiável de congestionamento. O senão está na palavra «fiável». Em rotas ISP de longa distância a perda de pacotes muitas vezes não é congestionamento de todo — é overflow de fila num router intermédio, uma ligação wireless a retransmitir invisível ao TCP, um rate-limiter mal configurado, ou um transitório de routing. CUBIC trata tudo isso como congestionamento e colapsa a janela mesmo quando o bottleneck tem muita capacidade livre.
BBR (Bottleneck Bandwidth and Round-trip propagation time) é a alternativa que usamos em ligações cross-country. BBR ignora a perda de pacotes como sinal primário de congestionamento e em vez disso mede diretamente a largura de banda do bottleneck e o RTT mínimo do caminho. Marca depois o ritmo do emissor à taxa do bottleneck, com uma janela dimensionada para manter um produto largura-de-banda × atraso de dados em voo. Numa long fat network — banda larga, RTT alto, perda aleatória modesta — BBR mantém a pipe cheia onde a CUBIC dividiria a janela ao meio repetidamente por perdas não congestivas.
O efeito prático numa render farm é mensurável. As transferências de assets através de um túnel cross-country, no mesmo hardware, passam de throughput aos saltos com stalls frequentes sob CUBIC para uma curva de throughput mais suave perto da capacidade real do caminho sob BBR. Os números variam com a rota ISP e a hora do dia, mas passar o lado emissor do cluster a BBR produziu de forma consistente throughput em regime mais alto e tail latencies mais curtas nas rotas que operamos.
Usamos a implementação BBR que está no kernel Linux mainline desde a versão 4.9, ativada com um sysctl de uma linha: net.core.default_qdisc=fq mais net.ipv4.tcp_congestion_control=bbr. Ambas as linhas vão para /etc/sysctl.d/99-bbr.conf e sobrevivem ao reboot. O BBR do kernel mainline é a versão que operamos em produção há anos. Existem ramos de investigação mais recentes do algoritmo mas introduzem alterações de comportamento que não tivemos tempo de validar nos nossos caminhos ISP específicos; o caminho de upgrade é um item de roadmap separado.
BBR é definido no lado emissor de qualquer fluxo grande — a caixa de cache e o render manager para as transferências de assets, o lado recetor para qualquer fluxo em sentido inverso como license callbacks e log shipping. BBR num extremo chega para ver a maior parte do benefício; BBR em ambos os extremos ajuda um pouco mais em fluxos bidirecionais.
TCP MSS clamping
De todos os problemas de rede que aparecem depois do túnel WireGuard subir, o que mais tempo de debugging nos custou: a MTU. O sintoma é consistente e confuso: os pacotes pequenos passam limpos (o ping funciona à dimensão por defeito, o SSH ecoa os caracteres, o handshake WireGuard completa), mas os pacotes grandes desaparecem no túnel e nunca saem. Os handshakes TLS ficam suspensos a meio. As sessões SMB ligam, falham no primeiro read grande. As sessões RDP estabelecem-se, mostram o ecrã de login, congelam quando o utilizador digita algo. Os servidores de licença fazem checkout de pequenos tokens e entram em timeout para os grandes.
A causa é o overhead de encapsulamento do túnel WireGuard a reduzir a MTU efetiva abaixo da MTU do caminho que os endpoints negoceiam baseando-se nas suas interfaces LAN. WireGuard acrescenta 60 bytes de overhead (20 IPv4 + 8 UDP + 32 WireGuard) a cada pacote. Uma carga útil de 1500 bytes do lado LAN torna-se um pacote de 1560 bytes do lado público, fragmentado ou descartado consoante o caminho. Path MTU Discovery (PMTUD) é suposto resolver isto enviando ICMP «Fragmentation Needed» de volta ao emissor, mas PMTUD parte na internet moderna por rotina — o ICMP é frequentemente filtrado a montante do emissor, o sinal «usa pacotes mais pequenos» nunca chega, e o túnel descarta pacotes grandes silenciosamente.
A solução é o TCP MSS (Maximum Segment Size) clamping. Configuramos a interface WireGuard do lado do router para reescrever a opção MSS em cada TCP SYN que atravessa o túnel, limitando-a à MTU efetiva do túnel menos o overhead TCP/IP. Com uma MTU de túnel de 1420 bytes (uma escolha segura que sobrevive à maioria das variações a montante), o clamp MSS é 1380. Qualquer ligação TCP que arranque depois da regra negocia um MSS de 1380 bytes, o emissor emite pacotes de 1420 bytes que passam limpos, e os drops silenciosos param.
O clamp vai na cadeia FORWARD do host WireGuard em modo router, na interface wg0, aplicado a pacotes de handshake TCP. O idioma iptables é iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (ou --set-mss 1380 para um valor fixo). nftables tem o equivalente. A regra tem de se aplicar em ambas as direções se ambos os lados iniciarem ligações TCP, o que numa render farm é o caso comum.
Não há maneira de sentir que falta o clamp MSS até que algo grande falhe — as cargas pequenas testam limpas. O clamp é uma daquelas configurações que não custam nada quando aplicadas corretamente e produzem horas de debugging confuso quando omitidas. Pusemo-lo na checklist de deployment padrão depois de um ticket de suporte às 6 da manhã sobre «transferências SMB suspensas em tamanhos aleatórios» se resolver às 8 da manhã com uma regra iptables de uma linha.
Design da cache SMB3 partilhada

Cache partilhada a servir assets localmente aos render workers
As cargas de render são pesadas em assets e dominadas por leitura. Uma cena típica vai de algumas centenas de megabytes a várias dezenas de gigabytes — geometria, texturas, simulation caches e ficheiros de projeto da DCC de rendering. Através de um cluster de 20 nós a mesma cena tem de ser legível por cada worker que pegue num frame. A abordagem ingénua é copiar a cena para cada nó antes do render arrancar. Com uma cena de 10 GB e 20 nós, isso move 200 GB pela rede para um working set de 10 GB. Multiplica por dezenas de cenas por dia por estúdio e o custo de duplicação domina a build.
A arquitetura que usamos em alternativa é uma única camada de cache partilhada por sítio, exposta aos render workers via SMB3. A cache é uma caixa Ubuntu 22.04 LTS com um único SSD (classe NVMe), formatado em ext4, com a diretoria de cache exposta pelo Samba via SMB3. Cada render worker monta a share SMB no arranque via cifs-utils e lê ficheiros de assets a partir da cache como se fossem locais. O primeiro worker que precisa de um asset desencadeia um pull do asset store cloud upstream para a cache; os workers seguintes e os frames seguintes leem da cache LAN à velocidade do porto do switch. Por sítio, a caixa de cache fica a um hop de switch de cada worker; o asset chega ao cluster uma vez e serve vinte workers.
Algumas escolhas de design merecem desempacotar. A cache é um único SSD, não um array RAID, porque a cache é por definição reconstruível a partir do asset store cloud upstream. Se o SSD falhar, o pior caso é um atraso enquanto o próximo pedido de asset puxa da cloud, mais um rebuild de qualquer render em voo que dependia de um ficheiro intermédio não cacheado. Mitigamos o risco «render em voo» fazendo rsync dos outputs de render terminados da cache para um NAS no fim de cada job, por isso uma falha de SSD não perde nenhum deliverable já entregue. Saltar o RAID poupa o custo de hardware, a complexidade do controlador e o overhead de amplificação de escrita que alguns níveis RAID impõem aos SSDs.
O file system é ext4 em vez de ZFS ou btrfs. Usámos ZFS e btrfs em builds passadas, e os feature sets que trazem (snapshots, checksumming, compressão) são benefícios reais em alguns workflows. Para uma cache de render, o padrão de leitura é sobretudo sequencial e limitado pela largura de banda em vez de transacional, e o conteúdo da cache é por design descartável. Ext4 mantém a pilha de storage simples e remove uma classe de modos de falha do conjunto de postmortems de incidentes. Operadores que já operam ZFS à escala podem certamente usá-lo aqui, mas para um deployment onde a simplicidade da camada de cache pesa mais do que ganhos de feature individuais, ext4 é a escolha.
A estratégia de pre-warm conta. Antes de um job orientado a deadline arrancar, o artista ou o TD de pipeline empurra os assets da cena para a cache via uma ferramenta de pre-staging. O primeiro frame que aterra num worker lê então de uma cache quente em vez de esperar por um cold pull. O passo de pre-warm é opcional para jobs que correm de noite (cold pull está bem) e importante para jobs que têm de terminar numa janela apertada.
A partilha de cache cross-sítio funciona através do túnel WireGuard site-to-site. O sítio secundário tem a sua própria caixa de cache e os seus próprios workers, mas a sua cache também consegue alcançar a cache do sítio primário pelo túnel para qualquer asset que esteja quente lá e ainda não quente localmente. Na prática configuramos a cache secundária para fazer fallback para a cache primária em misses antes de ir à cloud upstream — mantendo o tráfego inter-sítio no túnel cifrado e evitando taxas de egress cloud para assets que já vivem dentro da render farm. Este é um dos benefícios práticos de um clamp MSS correto: as transferências grandes de assets entre sítios movem-se a um throughput que satura o túnel em vez de bloquear no teto dos pacotes pequenos.
Serviços internos: DNS e NTP
Um cluster precisa de conhecer os seus próprios hostnames. A escolha ingénua é pôr cada host em /etc/hosts em cada nó, o que funciona com dois nós e começa a falhar com vinte. A escolha certa é DNS interno, e operamos dnsmasq na mesma caixa gateway que corre WireGuard. O cluster vive numa zona .lan — cache.lan, rn-a01.lan até rn-a20.lan, mgr.lan, nas.lan. Cada nome resolve para o IP interno correspondente na sub-rede do cluster, e o /etc/resolv.conf de cada worker aponta para o servidor dnsmasq.
O benefício é que qualquer reatribuição de IP, swap de host ou mudança de topologia requer tocar num ficheiro de configuração (o ficheiro hosts do dnsmasq) em vez de em cada nó. O benefício estende-se sobre o túnel site-to-site: um worker no sítio secundário consegue resolver cache.lan para a cache secundária via o seu dnsmasq local, e resolver mgr.lan para o render manager do sítio primário via DNS forwarding através do túnel. No passado usámos literais IP em configurações de render manager e arrependemo-nos sempre que um nó se mexia.
A armadilha do dnsmasq que nos mordeu — e que morde operadores suficientes para merecer parágrafo próprio — é a linha interface=. dnsmasq, por defeito, escuta em todas as interfaces, o que parece bem até perceberes que a caixa gateway tem pelo menos três: o WAN público, o LAN interno e o túnel WireGuard wg0. Se puseres interface=eth1 a pensar que estás a restringir o dnsmasq ao LAN, acabaste de tornar o sítio secundário ligado por WireGuard incapaz de resolver qualquer nome .lan, porque wg0 não está listado. A linha correta é interface=eth1,wg0 (ou o equivalente para os teus nomes de interface), ou uma linha except-interface= que nomeia apenas o WAN. Vimos esta má configuração produzir o sintoma «o sítio remoto consegue pingar a cache por IP mas não consegue SMB-montar por hostname» mais do que uma vez.
NTP é o outro serviço interno. Operamos chrony no gateway como servidor NTP, com o próprio gateway sincronizado a pools NTP públicos e cada nó sincronizado ao gateway. A motivação é correlação de logs do render manager: se um frame falha, a entrada de log do render manager e a do worker têm de partilhar uma linha do tempo ao milissegundo. O drift de clock num cluster de 20 nós, sobretudo quando os nós estão up há semanas, torna-se uma fonte real de confusão de debugging «esta entrada de log não bate certo». chrony mantém o drift abaixo de poucos milissegundos e remove essa classe de confusão.
Firewall: ufw com default-deny inbound
O gateway está na internet pública, e a sua postura de firewall é «default-deny inbound, default-allow outbound, default-allow forward para tráfego tunneled». No Ubuntu 22.04 LTS, a ferramenta que usamos é ufw — a Uncomplicated Firewall. ufw é um frontend sobre nftables (ou iptables em sistemas mais antigos) que expõe uma pequena superfície de comando e recusa fazer coisas surpreendentes. Para uma caixa gateway cuja config de firewall é a diferença entre «segura» e «comprometida em horas», uma pequena superfície de comando é uma feature.
A superfície pública configurada é uma regra: ufw allow 51820/udp comment 'wireguard'. Mais nada em inbound. SSH do lado público está fechado; administramos o gateway através do túnel WireGuard a partir de um IP de operador conhecido. SMB, DNS, NTP e HTTPS (para a UI do render manager) estão todos só em interfaces internas. As definições ufw default deny incoming e ufw default allow outgoing cobrem o resto da superfície.
A cadeia forward precisa de cuidado. O gateway atua como router para tráfego de cluster entre wg0 e o LAN interno, e a postura por defeito da ufw é negar forward. Pomos DEFAULT_FORWARD_POLICY="ACCEPT" em /etc/default/ufw e depois estreitamos as regras forward a pares source/destination específicos na cadeia FORWARD. A combinação — default-deny incoming, default-deny forward no boot, depois ACCEPTs forward explícitos entre sub-redes de cluster conhecidas — dá uma postura auditável que não encaminha acidentalmente tráfego entre sítios que não deviam falar.
As firewalls de host por-nó estendem esta camada Tier-1 gateway a uma camada Tier-2 host. Cada nó de render corre ufw localmente com regras que só permitem ao render manager e à caixa de cache do cluster iniciar ligações. Um worker comprometido não pode pivotar para outro worker sem primeiro vencer a firewall de host, e o gateway regista cada tentativa de forward inesperada. O modelo a dois tiers — gateway Tier 1, por-host Tier 2 — é o mesmo que qualquer cluster on-prem razoável corre; o que muda num deployment cross-country é que a superfície Tier 1 agora defende contra a internet pública. O gateway é o perímetro; as firewalls por-host são a defesa em profundidade.
Diagrama de arquitetura

Topologia hub-and-spoke de render farm, com um único túnel seguro para a internet
A descrição textual acima mapeia para o seguinte diagrama ASCII, o mesmo que desenhamos no quadro durante os kick-offs de deployment:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
O diagrama é intencionalmente genérico — sem par de cidades específico, sem ISP específico, sem numeração de sub-rede específica. Cada sítio que dispomos segue a mesma forma; os números variam.
Características de desempenho
Os números de throughput dependem da rota ISP e da hora do dia, mas a forma do desempenho é consistente nos deployments que operámos. Num túnel entre dois sítios na mesma metrópole (RTT sub-10 ms), as transferências grandes movem-se perto da taxa de linha no link bottleneck, e um render worker a ler da cache é indistinguível de um worker a ler de disco local. Num túnel entre sítios em países diferentes (50–150 ms RTT consoante a rota), as transferências grandes assentam num throughput estável marcado por BBR perto da banda do bottleneck, com o clamp MSS a manter a dimensão por segmento alinhada com a MTU do túnel.
A leitura da cache LAN local é onde a arquitetura ganha o pão. Um render worker a ler um pacote de texturas de 4 GB de cache.lan via SMB3 numa LAN gigabit switchada termina aproximadamente no tempo que o porto switch leva a empurrar os bytes — dezenas de segundos em vez dos vários minutos que um cold pull de storage cloud cross-country levaria. Para um job que toca o mesmo pacote de texturas ao longo de duzentos frames, a cache hit ratio aproxima-se de 1,0 depois da primeira leitura quente, e o túnel cross-country só é usado para o pre-warm original, a sync cross-sítio dos outputs do sítio secundário e a telemetria em regime.
Para frames de render 4K e 8K especificamente, o valor da arquitetura escala com a dimensão do frame. Uma sequência EXR 8K com múltiplas AOVs pode empurrar outputs de frame individuais para as centenas de megabytes, e 200 deles são uma escrita de dezenas de gigabytes por cena. Manter essa escrita em local-LAN e enviar apenas o output comprimido final pelo túnel é a diferença entre «termina durante a noite» e «termina quando o upload concluir, amanhã algures».
Perguntas frequentes
Q: Porquê WireGuard e não OpenVPN? A: A superfície de configuração da WireGuard é menor, o seu throughput no data plane consistentemente mais alto no mesmo hardware, a sua implementação em kernel remove um modo de falha userspace, e a sua postura de cifra fixa remove uma classe de bugs de negociação. OpenVPN é uma ferramenta sólida com vinte anos de história operacional; usamos WireGuard porque as propriedades operacionais para um túnel de cluster de longa duração são melhores nas métricas que nos interessam. Em rotas onde o UDP da WireGuard está bloqueado por completo, OpenVPN sobre TCP 443 é um fallback legítimo — mas TCP-sobre-TCP introduz as suas próprias patologias, e tratamos isso como restrição do lado do cliente.
Q: Como ajuda o BBR em rotas ISP ruidosas? A: BBR usa a banda do bottleneck e o RTT como sinal de congestionamento em vez de perda de pacotes. Em rotas onde a perda é dominada por overflow de buffer em routers intermédios, retransmissões wireless ou eventos transitórios de routing — ou seja, a maioria das rotas ISP públicas — BBR mantém o pace do emissor à banda real do caminho em vez de dividir a janela ao meio repetidamente por perdas não congestivas. O efeito é throughput em regime mais alto, tail latency mais curta em transferências grandes e menos incidentes «a transferência parou trinta segundos e depois retomou» em fluxos longos.
Q: O que é o MSS clamping e por que precisamos dele? A: O MSS clamping reescreve a opção Maximum Segment Size em pacotes TCP SYN para que a dimensão de segmento negociada passe limpa por um túnel com MTU efetiva reduzida. Sem ele, os endpoints negoceiam uma dimensão de segmento baseada nas suas interfaces LAN (tipicamente MTU 1500, MSS 1460), o túnel WireGuard não consegue transportar esses pacotes a dimensão completa, Path MTU Discovery falha porque o ICMP é filtrado algures a montante, e os pacotes grandes desaparecem silenciosamente. O sintoma é «pacotes pequenos funcionam, grandes não» — os pings passam, os handshakes TLS ficam suspensos, as transferências SMB bloqueiam a meio de ficheiro. A solução é uma regra iptables ou nftables de uma linha na interface WireGuard do lado do router.
Q: Posso fazer deploy desta arquitetura sozinho, ou preciso de um fornecedor de render farm?
A: A arquitetura é construída inteiramente a partir de componentes open source — WireGuard, a implementação BBR do Linux, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. Não há componente SRF-only. Uma equipa com competências de engenharia de infraestrutura consegue fazer deploy do mesmo stack por si, e as decisões de configuração neste artigo não são segredos; são as decisões que tomámos porque funcionaram. O que um fornecedor traz é a experiência operacional — as armadilhas como a linha interface= do dnsmasq, a história da descoberta do clamp MSS, o dimensionamento correto do SSD de cache, a tooling de pre-warm — embrulhada num playbook de deployment que não exige redescoberta a cada build. Se uma equipa absorve essa curva de experiência ou paga para a saltar é uma questão de orçamento e prazo.
Q: Qual é a cache hit ratio para workflows de render típicos? A: Para cargas paralelas por frame onde a mesma cena é renderizada ao longo de muitos frames (o padrão dominante em animação, VFX, archviz e visualização de produto), a cache hit ratio aproxima-se de 1,0 depois do primeiro pull quente de cada asset. A penalidade de cold pull é paga uma vez por asset por cache, e cada worker seguinte no mesmo sítio lê da cache quente à velocidade LAN. Para cargas que tocam um conjunto de assets diferente por frame (raras, mas acontecem em alguns workflows procedurais), a hit ratio é menor e a cache age mais como buffer de trânsito do que como store de longo prazo. O passo de pre-warm antes de jobs orientados a deadline torna efetivamente a hit ratio 1,0 para a carga planeada.
Q: Como escala esta arquitetura para além dos 20 nós? A: A topologia WireGuard hub-and-spoke escala linearmente com o número de peers — o custo de CPU do hub é crypto por peer e routing por pacote, e um gateway Xeon moderno aguenta centenas de peers antes de se tornar o bottleneck. A camada de cache escala ou crescendo a caixa de cache única (mais capacidade SSD, NIC mais rápida) ou fazendo sharding por múltiplas caixas com uma estratégia de mount consciente da carga. Para builds acima de 50 nós por sítio, tipicamente acrescentamos uma segunda caixa de cache e dividimos os workers entre elas; acima de 100 nós por sítio, a camada de cache torna-se um design read-replica distribuído, e isso é outro artigo. O túnel cross-country em si não precisa de mudança arquitetural quando o cluster cresce — o pacing BBR e o clamp MSS continuam a fazer o seu trabalho a qualquer taxa de fluxo agregada, desde que o link ISP subjacente tenha a capacidade.
Para mais detalhe prático sobre a sequência de deployment com que levantamos esta arquitetura, ver o nosso operational deployment guide. Para a postura de segurança colocada sobre este design de rede, o nosso artigo network segmentation security cobre em maior profundidade o modelo de firewall Tier-1 e Tier-2. E para os casos limite testados em campo que nem sempre acertámos à primeira, o writeup deployment lessons learned cobre os modos de falha específicos que moldaram esta arquitetura.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



