
Nuke Cloud Render Farm: Renderizado de Comps a Escala en 2026
Resumen
Renderizado de comps de Nuke en una render farm en la nube
La composición es el último tramo de un plano de efectos visuales. Cuando una secuencia llega a Nuke, los renders 3D están terminados, las placas han sido gradadas y el artista está ensamblando la imagen final: merges, keys, deep holdouts, trabajo de lente, grano. El problema es que esta "imagen final" raramente es barata de generar. Una secuencia de 200 fotogramas en 4K con una pila de entradas EXR multicanal y algunos nodos con aceleración GPU puede mantener ocupada una estación de trabajo durante horas, y el artista no puede seguir trabajando mientras se renderiza. Ese es exactamente el tipo de trabajo que una render farm en la nube existe para absorber.
En Super Renders Farm ejecutamos NukeX en toda nuestra flota de renderizado y, con los años, hemos observado que los mismos detalles de siempre determinan si un comp de Nuke se renderiza correctamente en una render farm o se detiene a mitad de una secuencia. Casi nunca es el cálculo de composición lo que falla. Es un gizmo que falta, un config de OCIO que no coincide, una ruta absoluta de Windows que no tiene ningún significado en un worker Linux, o una malinterpretación sobre qué edición de Nuke puede siquiera renderizar de forma remota. Esta guía explica cómo se distribuye el renderizado de comps de Nuke en una render farm, el panorama de ediciones y licencias que se debe comprender antes de enviar un trabajo, dónde la aceleración GPU realmente ayuda (y dónde no), y cómo empaquetar un comp para que no falte nada. El mismo enfoque operativo se aplica a flujos de trabajo más amplios de VFX y visualización de producto, pero Nuke tiene sus propias particularidades específicas, y en ellas nos centraremos aquí.
Por qué un comp de Nuke es paralelo por fotograma, no por tile
Para entender cómo Nuke se distribuye en una render farm, es útil compararlo con un renderer 3D. Un path tracer como V-Ray o Arnold puede dividir un único fotograma en buckets o tiles y asignar cada región a un hilo diferente, o, con distributed rendering, a una máquina diferente. Los píxeles de la esquina superior izquierda no dependen de los píxeles de la esquina inferior derecha, por lo que el fotograma puede dividirse espacialmente.
Un comp 2D funciona de manera diferente. El valor de cualquier píxel en el fotograma N depende únicamente de las entradas de ese fotograma ejecutadas a través del árbol de nodos. Cada fotograma es completamente autónomo, lo que hace que un comp de Nuke sea embarazosamente paralelo por fotograma: se puede renderizar el fotograma 1 en una máquina y el fotograma 200 en otra sin ninguna coordinación entre ellas. Lo que Nuke no hace es dividir un fotograma en tiles espaciales asignados a máquinas separadas: un nodo Write renderiza un fotograma completo en un único proceso. Dentro de una misma máquina, Nuke paraleliza entre hilos CPU y utiliza un motor de escaneado/región, pero entre máquinas la unidad de distribución es el fotograma.
Ese único hecho determina todo lo relacionado con el renderizado en una render farm para Nuke. El gestor de renderizado no subdivide imágenes; subdivide el rango de fotogramas. Una secuencia de 1.000 fotogramas se convierte en un conjunto de "chunks" de rango de fotogramas más pequeños, cada chunk se asigna a un worker, y cada worker lanza su propio renderizado headless de Nuke para su tramo. El diagrama a continuación muestra la estructura general.
1.000 fotogramas
(un nodo Write)
divide el rango en chunks
-F 1-50-F 51-100-F 101-150escrita en almacenamiento compartido
Dado que los fotogramas son independientes, el rendimiento escala de manera casi lineal con el número de workers que se pueden asignar al trabajo, que es precisamente la razón por la que renderizar una secuencia larga en la nube vale la pena.
El renderizado headless: cómo Nuke se ejecuta en un worker
En una render farm no hay interfaz gráfica. Cada worker ejecuta Nuke en modo terminal (batch), que renderiza todos los nodos Write activos para un rango de fotogramas determinado y luego termina. El comando base tiene este aspecto:
nuke -x -F 1-50 comp.nk
-x pone Nuke en modo execute. -F establece el rango de fotogramas y acepta fotogramas individuales (-F 7), rangos inclusivos (-F 1-50) y rangos con paso (-F 1-100x2 renderiza un fotograma de cada dos). Se pueden pasar varios argumentos -F en un mismo comando para rangos no contiguos. Algunos indicadores adicionales son relevantes cuando se pasa de un único comp a secuencias de producción:
| Indicador | Función | Relevancia en una render farm |
|---|---|---|
-x | Execute (renderizado) de todos los nodos Write activos | Opción estándar de renderizado batch |
-F a-bxc | Rango de fotogramas con paso opcional | El gestor de renderizado lo completa por chunk |
-X node | Renderiza solo el nodo Write indicado | Renderiza una salida cuando el comp tiene varios Writes |
--sro | Respeta el orden de renderizado del nodo Write | Necesario cuando un Read aguas abajo depende de la salida de un Write anterior |
--cont | Continúa tras un error de fotograma | Un fotograma corrupto no aborta un chunk completo |
-m N | Establece el número de hilos de renderizado | Ajusta la concurrencia por worker a los núcleos de la máquina |
Un renderizado iniciado de esta forma solicita una licencia de renderizado de forma predeterminada, en lugar de un asiento interactivo; se amplía en la sección siguiente. Nuke también devuelve códigos de salida útiles que un gestor de renderizado lee para marcar una tarea como correcta, fallida o que necesita reintento: 0 es éxito, 1 es un error de renderizado y 100 señala un fallo de licencia. En una render farm gestionada raramente se escriben estos comandos manualmente; las herramientas de envío los construyen. Pero conocer lo que se ejecuta bajo el capó explica la mayor parte del comportamiento que se verá en un log de renderizado.
Hay un mecanismo de distribución más que merece mencionarse para que no se confunda con el renderizado en una render farm: el Frame Server interno de Nuke. El Frame Server lanza múltiples procesos de renderizado en segundo plano para acelerar un único render, útil en una estación de trabajo ocupada o en un pequeño grupo de máquinas auxiliares. Es una herramienta diferente a la distribución de rango de fotogramas a escala de render farm, que es lo que se necesita cuando una secuencia completa debe estar lista en una noche en lugar de en un fin de semana largo.
Ediciones de Nuke y licencias para el renderizado en una render farm
Esta es la parte que genera más confusión, porque "Nuke" es una familia, no un único producto, y las ediciones no se comportan igual en una render farm.
| Edición | Descripción | ¿Puede renderizar en una render farm? |
|---|---|---|
| Nuke (Commercial) | El compositor basado en nodos base | Sí, con una licencia de renderizado |
| NukeX | Nuke más nodos avanzados (CameraTracker, denoise, deblur, distorsión de lente, PointCloudGenerator, ParticleSystem) | Sí, con una licencia de renderizado |
| Nuke Studio | Conjunto de herramientas NukeX más una línea de tiempo editorial/conform | Sí, con una licencia de renderizado |
| Nuke Indie | Edición de bajo costo para artistas en solitario | No: las render farms externas y en la nube no están admitidas |
| Nuke Assist | Un subconjunto restringido de nodos para paint, roto y tracking | No: es un asiento de asistencia interactivo, no una licencia de renderizado |
Esta tabla describe la familia Nuke en general frente a los requisitos de cualquier render farm, no específicamente nuestra flota; en nuestra propia render farm, la aplicación del lado de renderizado es NukeX, como se describe en el resto de esta guía. Hay dos aspectos que vale la pena destacar de la tabla.
En primer lugar, Nuke Indie no puede renderizar en una render farm en absoluto. La edición Indie de Foundry está diseñada para artistas en solitario con un límite de ingresos, y sus términos excluyen explícitamente las render farms externas de terceros, los servicios de renderizado en la nube y el renderizado remoto del Frame Server. Indie también guarda en sus propios formatos de script cifrados que el analizador comercial no puede leer. Por eso, si se trabaja con Indie y no se entiende por qué el envío a una render farm no funciona, no es un problema de configuración: es un límite de licencia. El renderizado en una render farm requiere las ediciones Commercial, NukeX o Nuke Studio.
En segundo lugar, en una render farm se renderiza con licencias de renderizado, no con asientos interactivos. Una licencia de renderizado es un Nuke headless sin interfaz gráfica que existe específicamente para renderizar. Cuando se lanza un renderizado de terminal, Nuke solicita una de forma predeterminada. Las licencias de renderizado son independientes de los asientos interactivos que utilizan los artistas, lo que permite a un estudio renderizar un comp en cincuenta máquinas sin comprar cincuenta asientos interactivos completos de Nuke. Un detalle útil para pipelines mixtos: una licencia de renderizado puede renderizar cualquier nodo creado en la edición NukeX o inferior, por lo que un nodo de renderizado equipado con NukeX renderizará sin problemas un script creado por un artista en el Nuke base. NukeX es un superconjunto de Nuke: añade nodos, no elimina la capacidad de leer los estándar. La restricción inversa es la única real: el Nuke base no puede evaluar nodos exclusivos de NukeX.
En cuanto al modelo de licencias, Foundry migró la familia Nuke a suscripción anual a principios de 2023, con licencias basadas en inicio de sesión que pueden funcionar en línea o sin conexión; también existen opciones perpetuas y de alquiler. Los mecanismos varían de estudio en estudio, que es el objeto de la siguiente sección.
Cómo funciona el licenciamiento en nuestra render farm
Super Renders Farm no es un partner de Foundry, y no lo afirma: nuestras alianzas verificadas con fabricantes son con los desarrolladores de motores de renderizado, no con los fabricantes de software de composición. Lo que ejecuta nuestra render farm es un modelo de utilización render-only, el mismo enfoque que usamos para las demás aplicaciones de la flota que no están vinculadas a una alianza.
En la práctica, esto significa que no es necesario aprovisionar ni gestionar un asiento de licencia de renderizado por worker. La flota de workers ejecuta NukeX, anclado a una versión compatible, y el compositor se lanza en modo headless para renderizar el script. Como SuperRenders es una render farm completamente gestionada, no es necesario conectarse mediante escritorio remoto a las máquinas, instalar Nuke ni configurar servidores de licencias manualmente: el entorno del lado de renderizado ya está operativo cuando llega el trabajo. Esa es la diferencia operativa entre una render farm gestionada y una configuración IaaS de tipo hágalo-usted-mismo, donde instalar Nuke y su licencia en cada instancia es responsabilidad del usuario.
En cuanto al costo, el renderizado de comps se factura de la misma manera que el resto del trabajo CPU: por GHz-hora de cómputo utilizado, sin alquileres mínimos de máquinas y con créditos de renderizado que no caducan. Las cuentas nuevas comienzan con un crédito de 25 USD, suficiente para renderizar una secuencia de prueba corta de extremo a extremo y confirmar que el comp se comporta igual en la render farm que en la estación de trabajo antes de comprometer un trabajo completo. Las tarifas actuales y una calculadora de costos están disponibles en la página de precios.
Distribución del rango de fotogramas en la práctica
Saber que una render farm divide el rango de fotogramas en chunks es una cosa; obtener renders limpios y predecibles es otra. En nuestro equipo de soporte, hay prácticas que aparecen una y otra vez.
El tamaño del chunk implica un equilibrio. Los chunks pequeños (unos pocos fotogramas cada uno) distribuyen el trabajo entre más máquinas y recuperan más rápidamente de una tarea fallida, pero incurren en el costo de arranque de Nuke, es decir, la carga del script, la solicitud de licencia, la inicialización de plugins, con mayor frecuencia. Los chunks grandes amortizan el arranque, pero dejan rezagados cuando una máquina lenta retiene el final de una secuencia. Para la mayoría de los comps, un chunk moderado que mantenga a cada worker ocupado varios minutos es un buen punto de partida; los comps muy pesados por fotograma (deep, 4K o más, muchos nodos GPU) tienden a chunks más pequeños.
Atención a las dependencias entre nodos Write. Si el script incluye un Read aguas abajo que depende de un archivo producido por un Write anterior, por ejemplo, un precomp horneado en disco, esos Writes deben ejecutarse en orden. Para eso sirve --sro. Sin él, un worker puede intentar el Write dependiente antes de que exista su entrada, lo que genera errores de fotogramas faltantes de aspecto aleatorio porque dependen del tiempo de ejecución de las máquinas.
Anticipar los fotogramas problemáticos ocasionales. Una entrada ilegible o un fallo de almacenamiento transitorio no debería terminar con un chunk entero. --cont permite que un render continúe tras un fotograma fallido para volver a poner en cola solo las lagunas posteriormente, en lugar de volver a renderizar todo. Combinado con el reintento automático de tareas del gestor de renderizado, esto mantiene las secuencias largas en marcha sin supervisión constante.
El beneficio de gestionar esto correctamente es directo: una secuencia que ocuparía la máquina de un artista durante un día completo regresa en el tiempo que tarda el chunk más lento en renderizarse, porque todos los demás chunks se renderizan en paralelo.
GPU vs CPU para Nuke en una render farm
Aquí hay un punto que sorprende a quienes vienen del renderizado 3D centrado en GPU: Nuke es fundamentalmente una aplicación CPU. La gran mayoría de las operaciones de composición, merges, correcciones de color, transformaciones, keys, la mayoría de los filtros, se ejecutan en la CPU. La aceleración GPU en Nuke es opcional para un subconjunto específico de nodos, expuesta a través de un control "usar GPU si está disponible"; los nodos sin ese control son solo-CPU.
| Carga de trabajo | Dónde se ejecuta | Ejemplos |
|---|---|---|
| Composición general | CPU | Merge, Grade, ColorCorrect, Transform, Keyer, la mayoría de los filtros |
| Nodos con aceleración GPU | GPU (opcional, con fallback a CPU) | Kronos y MotionBlur retimes, Denoise, VectorGenerator, Convolve, ZDefocus |
| BlinkScript / machine learning | GPU | Kernels de BlinkScript, entrenamiento de CopyCat (requiere GPU NVIDIA) |
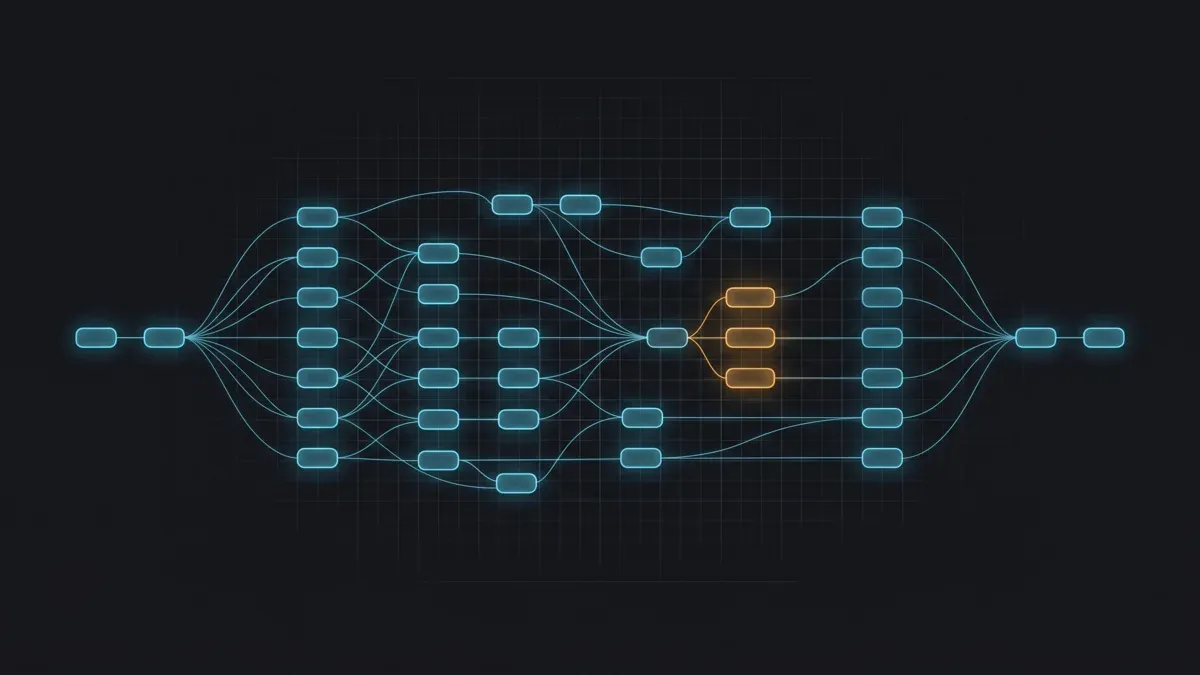
Árbol de nodos de Nuke conceptual que muestra la mayoría de los nodos de composición ejecutándose en CPU con algunos nodos con aceleración GPU resaltados
Esto significa, en cuanto al hardware, que un comp dominado por grades, merges y transformaciones apenas se beneficia de una GPU: necesita núcleos CPU y memoria. Un comp que se apoya en un Kronos retime pesado, un ZDefocus grande, Denoise o trabajo personalizado de BlinkScript puede acelerarse considerablemente con una GPU. La mayoría de los comps de producción se encuentran en un punto intermedio, por eso damos prioridad a la capacidad CPU y tratamos la GPU como un acelerador para los nodos que realmente la utilizan.
Nuestra flota refleja eso. La mayor parte del trabajo de composición se ejecuta en máquinas CPU basadas en procesadores duales Intel Xeon E5-2699 V4 con 96 a 256 GB de RAM cada una, más de 20.000 núcleos CPU en total, y esa disponibilidad de memoria es lo que más se subestima. La composición deep y las placas EXR multicanal de alta resolución consumen mucha memoria; un único fotograma deep en 4K puede contener muchas muestras por píxel, y quedarse sin RAM a mitad de un fotograma es una causa de fallos en el renderizado de la render farm mucho más habitual que la velocidad CPU bruta. Para los comps que realmente se benefician de los nodos GPU, también contamos con una GPU cloud render farm dedicada con tarjetas NVIDIA RTX 5090 con 32 GB de VRAM cada una. Si se desea ver el rendimiento de esa capa GPU en cargas de trabajo más pesadas, nuestros benchmarks de renderizado en la nube RTX 5090 lo cubren en detalle. La orientación honesta para Nuke específicamente, sin embargo, es ajustar el tamaño al comp: no conviene pagar por tiempo de GPU que un script dominado por merges nunca utilizará.
Gestión de archivos y recursos: donde realmente se producen los fallos
Si un renderizado de Nuke falla en una render farm, la probabilidad abrumadora es que sea un problema de dependencias, no de composición. Un script de comp es básicamente un conjunto de referencias, a metraje, a gizmos, a una configuración de color, y cada una de esas referencias debe resolverse de forma idéntica en un worker que no es la máquina del artista.
| Dependencia | Modo de fallo | Qué verificar |
|---|---|---|
| Metraje / nodos Read | Fotogramas faltantes, "archivo no encontrado" | Rutas accesibles por red, independientes del SO, no letras de unidad locales Z:\ que solo existen en el PC del artista |
| Gizmos / plugins OFX | El script no carga, nodo desconocido | Instalados en cada nodo de renderizado, o agrupados/horneados en el script antes del envío |
| Configuración de color OCIO | Colores incorrectos, grade desajustada | La misma configuración está desplegada y seleccionada en la render farm que usó el artista |
| Fuentes | Glifos sustituidos o incorrectos en nodos Text | Las fuentes utilizadas están presentes en los nodos de renderizado |
| LUTs / archivos .cube | Transformación de color fallida | Los archivos LUT independientes referenciados por el comp se envían junto con él |
| Versión de Nuke | Incompatibilidad de nodos | La versión del renderizado coincide con (o es más reciente que) la versión con la que se creó el comp |
Diagrama de un script de comp de Nuke y las dependencias que deben acompañarlo a una render farm: metraje, gizmos, configuración OCIO, fuentes y LUTs
Algunos de estos merecen una mirada más detenida. Las rutas son el caso clásico: un artista en Windows que referencia Z:\project\plates\ producirá un script que no significa nada para un worker Linux. Las rutas de proyecto coherentes y accesibles por red, o un gestor de renderizado que reescribe las rutas al enviar a la render farm, resuelven esto. Los gizmos y OFX personalizados deben existir en el nodo de renderizado; el hábito más seguro antes de enviar es convertir cualquier gizmo personalizado en Groups para que queden horneados en el script y no tengan ninguna dependencia externa.
La deriva del config de OCIO es la más sutil y merece atención, porque produce un render que tiene éxito pero que se ve mal. La gestión del color de Nuke se rige por un config de OpenColorIO; si la render farm resuelve un config diferente al que usó el artista, ya sea una ruta de archivo diferente, un config personalizado que nunca se desplegó, o una variable de entorno que apunta a otro lugar, las transformaciones de color divergen y el render de la render farm no coincidirá con el visor que aprobó el artista. La solución es disciplina: fijar el proyecto a un config específico y desplegado, y asegurarse de que el entorno de renderizado use exactamente ese. Una render farm gestionada mantiene los configs OCIO estándar incluidos de Nuke operativos de forma predeterminada, pero un config OCIO personalizado de un estudio debe igualmente acompañar al trabajo.
En el lado de la salida, los comps de Nuke típicamente leen y escriben EXR multicanal. Un único archivo OpenEXR puede contener muchos canales: un pase beauty más difuso, especular, AOVs de iluminación, un pase Z-depth y mattes de cryptomatte, todo leído a través de un único nodo Read y dividido con nodos Shuffle para el trabajo por pase en comp. Para la composición deep, Nuke lee y escribe deep EXR a través de DeepRead y DeepWrite, almacenando múltiples muestras de profundidad por píxel para resolver problemas de holdout y bordes sin volver a renderizar en 3D. La mayor parte de estos datos se almacena como half-float de 16 bits, el estándar para placas lineales HDR, con float completo de 32 bits reservado para pases de datos como posición en el mundo o vectores de movimiento que necesitan precisión total. Nada de esto es exótico, pero cada uno de esos canales representa más datos que mover y más memoria que mantener, lo que vuelve directamente a por qué la RAM y el rendimiento de almacenamiento importan tanto como el número de núcleos para el renderizado de comps.
Lista de verificación previa al envío para comps de Nuke
Antes de enviar un comp a cualquier render farm, ya sea la nuestra o la cola interna propia, un repaso rápido a estos puntos previene la gran mayoría de los renders fallidos:
- Rutas: todos los nodos Read y Write utilizan rutas accesibles por red e independientes del SO, no letras de unidad locales.
- Gizmos: los gizmos personalizados se convierten en Groups (horneados) o se confirma que están instalados en los nodos de renderizado.
- Color: el config de OCIO es el que resolverá la render farm; cualquier config personalizado acompaña al trabajo.
- Fuentes y LUTs: cada fuente utilizada por un nodo Text y cada archivo
.cube/LUT referenciado está presente. - Versión: la versión del renderizado coincide con la versión con la que se creó el comp.
- Edición: el script proviene de Commercial Nuke, NukeX o Nuke Studio, no de Indie, que no puede renderizar en una render farm.
- Orden de renderizado: si un Read aguas abajo depende de un Write anterior, renderizar con
--sro. - Prueba pequeña: renderizar unos pocos fotogramas primero y comparar con la salida local del artista antes de comprometer el rango completo.
Ese último punto es un seguro económico. Un renderizado de prueba de cinco fotogramas detecta una discrepancia de ruta, color o versión al costo de unos pocos minutos, mucho mejor que descubrirlo en el fotograma 800 de un trabajo nocturno.
Dónde encaja el renderizado de Nuke en un pipeline más amplio
La salida EXR de fotograma final es el destino más habitual para un comp de Nuke, pero no el único. Si el plano va hacia un motor en tiempo real en lugar de a una secuencia renderizada plana, ya sea para producción virtual o revisión en motor, las preguntas de integración son diferentes, y cubrimos ese recorrido por separado en nuestra guía del pipeline de Nuke para Unreal Engine. La distinción es clara: este artículo trata sobre el renderizado de fotogramas de comp a escala en una render farm, mientras que el recorrido de Unreal trata sobre cómo llevar el trabajo de Nuke a un contexto en tiempo real. Si aún se está trazando el mapa de cómo funciona el renderizado distribuido en general, nuestra guía sobre qué es una render farm es un buen punto de partida.
Para una referencia autorizada sobre los mecanismos descritos aquí, la documentación propia de Foundry sobre operaciones de línea de comandos y render farms y sus preguntas frecuentes sobre licencias de la familia Nuke son las fuentes canónicas, y los sitios de los proyectos OpenEXR y OpenColorIO documentan los estándares de archivo y color de los que depende un comp.
FAQ
Q: ¿Puedo renderizar Nuke en una render farm en la nube con una licencia Nuke Indie? A: No. La edición Nuke Indie de Foundry explícitamente no admite render farms externas de terceros, servicios de renderizado en la nube ni el renderizado remoto del Frame Server, y guarda en formatos de script cifrados que el analizador comercial no puede leer. El renderizado en una render farm requiere las ediciones Commercial Nuke, NukeX o Nuke Studio.
Q: ¿Necesito una licencia de renderizado de Nuke separada para utilizar una render farm en la nube? A: En una render farm, los renderizados se ejecutan en modo headless usando licencias de renderizado en lugar de asientos interactivos, así es como un estudio puede renderizar en muchas máquinas sin comprar un asiento interactivo completo para cada una. En nuestra render farm no es necesario aprovisionarlas; la flota de workers ejecuta NukeX bajo un modelo de utilización render-only, por lo que el licenciamiento del lado de renderizado se gestiona desde la propia render farm.
Q: ¿El renderizado de Nuke es más rápido en GPU o en CPU? A: Para la mayoría de los comps, en CPU. Nuke es fundamentalmente una aplicación CPU; solo un subconjunto específico de nodos, Kronos, Denoise, ZDefocus, Convolve, BlinkScript y herramientas de machine learning como CopyCat, cuentan con aceleración GPU. Un comp construido principalmente con merges, grades y transformaciones necesita núcleos CPU y RAM, mientras que un comp que se apoya en esos nodos pesados se beneficia de una GPU.
Q: ¿Cómo divide una render farm un comp de Nuke entre máquinas? A: Por rango de fotogramas, no por región de imagen. Dado que cada fotograma de un comp es independiente, el gestor de renderizado divide el rango total de fotogramas en chunks y asigna cada chunk a un worker, que renderiza su tramo en modo headless. El rendimiento escala de manera casi lineal con el número de workers en el trabajo.
Q: ¿Por qué mi comp de Nuke se renderiza con colores incorrectos en la render farm? A: La causa más habitual es la deriva del config de OCIO: la render farm resolvió un config de OpenColorIO diferente al que usó el artista, ya sea por una ruta de archivo diferente, una variable de entorno o un config personalizado que nunca se desplegó en los nodos de renderizado. Hay que fijar el proyecto a un config específico y asegurarse de que ese config exacto sea el que utiliza el entorno de renderizado.
Q: ¿Qué archivos se necesitan enviar junto con un script de Nuke para renderizar remotamente? A: El script más todo lo que referencia: metraje y secuencias de imágenes, gizmos o plugins OFX personalizados (o convertirlos a Groups), el config de color OCIO, fuentes utilizadas por nodos Text y cualquier archivo LUT independiente. La versión de renderizado también debe coincidir con la versión con la que se creó el comp.
Q: ¿NukeX renderiza un comp de Nuke estándar? A: Sí. NukeX es un superconjunto del Nuke base: añade nodos en lugar de eliminar la capacidad de leer los estándar, por lo que un nodo de renderizado NukeX renderiza sin problemas scripts creados en el Nuke base. Una licencia de renderizado puede renderizar cualquier nodo creado en la edición NukeX o inferior. La única restricción es la inversa: el Nuke base no puede evaluar nodos exclusivos de NukeX.
Q: ¿Cuánto cuesta renderizar comps de Nuke en su render farm? A: El renderizado de comps se factura por GHz-hora de cómputo CPU utilizado, sin alquileres mínimos de máquinas y con créditos de renderizado que no caducan. Las cuentas nuevas reciben un crédito de 25 USD, que cubre una secuencia de prueba corta de extremo a extremo. Las tarifas actuales y una calculadora de costos están en nuestra página de precios.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



