
Karma XPU de Houdini en una Cloud Render Farm: Guía Técnica 2026
Resumen
Introducción
Karma XPU es el motor de renderizado con el que cada vez más estudios de Houdini están estandarizando su trabajo, y con razón: es el motor de producción propio de SideFX, reside de forma nativa dentro de Solaris y USD, y su ejecución híbrida de CPU más GPU hace que el look-dev se sienta casi interactivo. En una única estación de trabajo, es un placer de utilizar. El problema comienza cuando se toma una escena de Karma XPU de la estación de trabajo y se intenta ejecutar cientos de fotogramas en una render farm.
A escala de render farm, Karma XPU deja de comportarse como una versión más rápida de Karma CPU y empieza a comportarse como una bestia diferente. La VRAM se convierte en un techo rígido en lugar de una sugerencia. Las simulaciones que funcionaban bien de forma interactiva no pueden distribuirse en absoluto hasta que se almacenen en caché. El motor puede volver silenciosamente a la CPU en un fotograma pesado y dejarle preguntándose por qué un plano tardó seis veces más que el contiguo. Nada de esto son errores — es la arquitectura que se muestra bajo carga.
Llevamos años ejecutando renderizado distribuido para trabajos de Houdini, y Karma XPU es uno de los motores disponibles en nuestra render farm cloud para Houdini junto con Redshift, Mantra, Arnold, V-Ray for Houdini y Octane. Esta guía es el análisis técnico en profundidad: qué es realmente Karma XPU, cómo difiere de Karma CPU y Mantra, qué cambia cuando se renderiza sin interfaz en una render farm, cómo debe funcionar primero el almacenamiento en caché de simulaciones y cómo decidir entre Karma XPU y Redshift para un plano determinado. Si prefiere una lista de verificación de preparación de escenas paso a paso, nuestra guía de configuración de Houdini cubre ese terreno; este artículo asume que ya conoce Solaris.
Por qué Karma XPU es más difícil de escalar de lo que parece
Lo que hay que entender sobre Karma XPU es que "XPU" no es un motor de renderizado — es un modo de ejecución. Karma es un único delegado de renderizado USD, y XPU es la ruta que distribuye el trabajo entre los núcleos de CPU y la GPU de NVIDIA al mismo tiempo, con ambos dispositivos contribuyendo muestras a la misma imagen. Karma CPU es el mismo delegado con la GPU desactivada. Este diseño es elegante en una estación de trabajo y complicado en una render farm, por cuatro razones.
En primer lugar, la ruta de GPU se ejecuta sobre OptiX, lo que significa que carga geometría, texturas y estructuras de aceleración en la VRAM de la GPU. Cuando una escena cabe en la VRAM, se obtiene toda la aceleración híbrida. Cuando no cabe, Karma XPU tiende a volver hacia la ejecución en CPU en lugar de transmitir datos como hacen algunos motores GPU. El renderizado termina igualmente, pero a una fracción de la velocidad esperada — y nada en un registro de trabajo normal lo señala.
En segundo lugar, XPU es más joven que los motores con los que compite. Houdini 20.0 fue su primer hito de estabilidad en producción y la versión 20.5 amplió considerablemente la cobertura de funciones, pero un puñado de funciones todavía favorece a Karma CPU. Si un plano utiliza alguna de ellas, parte del renderizado puede caer silenciosamente a la ruta de CPU.
En tercer lugar, la fijación de versiones importa más de lo que la gente espera. Una escena creada en una versión puntual de Houdini debería renderizarse en nodos de render farm que ejecuten esa misma versión; la superficie de Karma ha cambiado lo suficiente entre las versiones 20.0, 20.5 y la línea 21 como para no asumir que los renderizados entre versiones serán correctos.
En cuarto lugar — y este es el que atrapa a todos la primera vez — las simulaciones no son fotogramas. No puede simplemente enviar una configuración de Pyro o FLIP a una render farm y esperar que se distribuya. Eso merece su propia sección, y la tiene más adelante.
Karma XPU vs Karma CPU vs Mantra
Con Houdini se incluyen tres motores de renderizado, y elegir entre ellos es la primera decisión real para cualquier trabajo en render farm. No son intercambiables.
Mantra es el motor heredado. Es anterior al USD, funciona sobre la canalización de descripción de escenas propia de Houdini y utiliza shaders basados en VEX (CVEX) en lugar de MaterialX. SideFX no lo ha eliminado y sigue siendo completamente funcional, pero no recibe nuevas funciones — la dirección futura es claramente Karma. Mantra sigue siendo útil en dos casos: pipelines con amplias bibliotecas de shaders VEX que serían costosas de reconstruir, y el comportamiento ocasional de micropolígonos o desplazamiento que aún no tiene un equivalente limpio en Karma. Si sus shaders son CVEX, no se traducen a Karma, y eso solo puede mantener un plano en Mantra.
Karma CPU es la ruta de referencia. Es nativo de USD, implementa el conjunto completo de funciones de Karma y es la referencia cuando se necesita saber cómo debería verse un fotograma. Se ejecuta en paralelo a través de núcleos de CPU sin implicación de la GPU. En una render farm con una gran flota de CPU es genuinamente práctico — elude completamente el techo de VRAM, lo que lo convierte en la opción sensata para escenas demasiado pesadas para caber cómodamente en la memoria de la GPU.
Karma XPU es la ruta acelerada híbrida: CPU más GPU de NVIDIA, ambas trazando en el mismo fotograma, utilizando sombreado MaterialX y la misma base nativa USD que Karma CPU. Al combinar la GPU con la CPU, renderiza el look-dev interactivo y los fotogramas finales dentro de la VRAM más rápido que cualquiera de las rutas solo de CPU, y es el valor predeterminado natural para los nuevos pipelines de Solaris. Su limitación es que es un subconjunto de funciones de Karma CPU — la mayoría de las brechas restantes se refieren a volumen exótico, sombreado o casos extremos de AOV, y SideFX las está cerrando versión tras versión. La regla honesta de producción es renderizar un fotograma de comparación tanto en XPU como en CPU antes de comprometer una secuencia a XPU, porque cuando XPU y CPU difieren, CPU es el correcto.
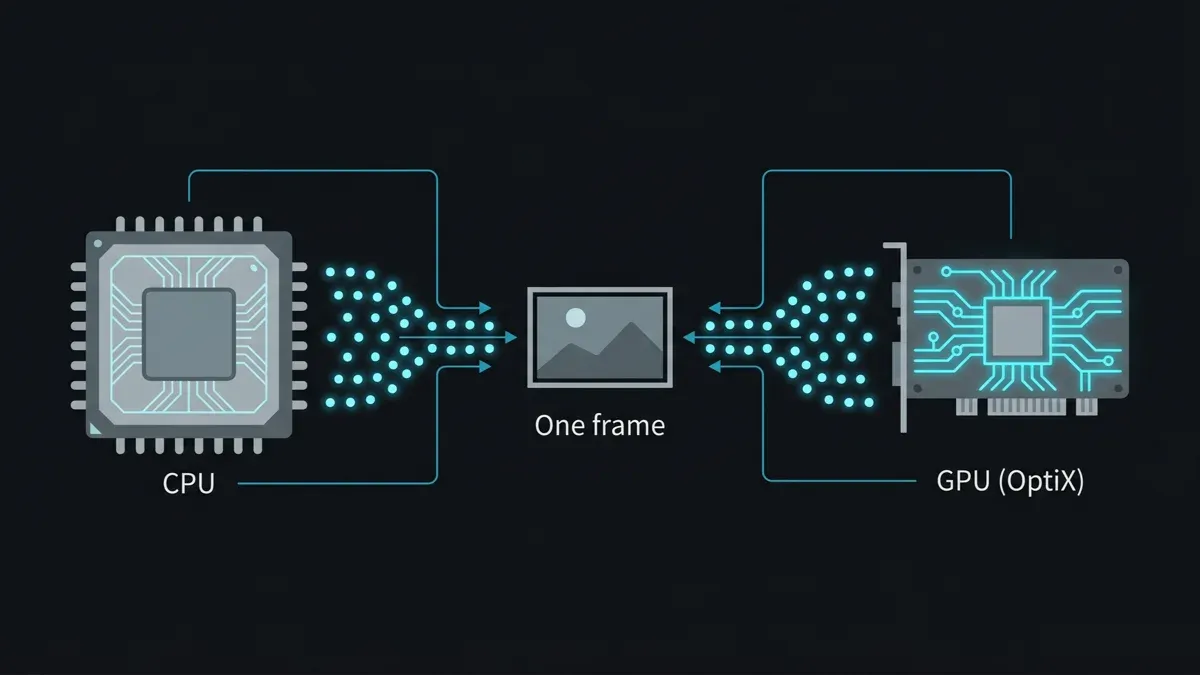
Diagrama de Karma XPU de Houdini dividiendo el trabajo de renderizado entre CPU y GPU simultáneamente, contribuyendo ambos muestras a un único fotograma.
| Aspecto | Mantra | Karma CPU | Karma XPU |
|---|---|---|---|
| Base de escena | Pre-USD (pipeline nativo) | USD / Solaris | USD / Solaris |
| Cómputo | CPU | CPU | CPU + GPU NVIDIA |
| Sombreado | VEX / CVEX | MaterialX | MaterialX |
| Completitud de funciones | Congelado (sin nuevas funciones) | Referencia (completo) | Subconjunto de CPU, madurando |
| Techo de VRAM | Ninguno | Ninguno | Sí — limitado por memoria de GPU |
| Indicado para | Pipelines VEX heredados | Escenas pesadas, referencia | Look-dev nativo USD + fotogramas finales en VRAM |
Ejecutar Karma XPU sin interfaz en una cloud render farm
De forma interactiva, se renderiza pulsando el botón en el visor de Solaris. En una render farm, ese botón es un programa de línea de comandos llamado husk. Es el motor de renderizado USD independiente de SideFX — un proceso ligero que carga una etapa USD compuesta y la renderiza sin iniciar una sesión completa e interactiva de Houdini. Se incluye con Houdini y es la forma canónica de renderizar Karma a escala. Un envío tiene, en esencia, este aspecto:
husk --renderer Karma \
--frame 1001 --frame-count 50 \
--output /project/render/shot_010.$F4.exr \
/project/usd/shot_010.usd
Cada nodo de render farm ejecuta husk contra la misma etapa USD pero para un rango de fotogramas diferente, que es lo que hace que funcione la distribución a nivel de fotograma. La etapa en sí es un archivo .usd/.usdc completamente compuesto que referencia toda la geometría, luces, cámaras y materiales. Sus AOV no son parámetros de línea de comandos — son prims de Render Var de USD integrados en la etapa desde los Render Settings y Render Var LOPs, por lo que husk los lee sin necesitar una red Houdini activa. Beauty, alpha, normales, albedo y el resto viajan dentro del USD.
Conviene conocer algunos mecanismos específicos de render farm. Karma admite checkpointing, escribiendo el estado intermedio del renderizado a intervalos de muestra para que un fotograma héroe largo pueda reanudarse en lugar de reiniciarse si un nodo tiene problemas — valioso para fotogramas individuales con miles de muestras, menos relevante para animaciones con muestras moderadas donde cada fotograma es barato de repetir. El denoising se ejecuta a través del denoiser OptiX en la GPU o Intel OIDN en la CPU; en una render farm nos inclinamos hacia OIDN cuando la estabilidad temporal a través de muchos nodos importa, porque produce resultados idénticos independientemente de qué máquina procesó el fotograma.
Sobre el licenciamiento, seremos directos, porque es una pregunta frecuente. Karma no es un plugin con licencia separada como Redshift, Arnold, V-Ray u Octane — viene incluido con Houdini. Ejecutamos Houdini y Karma bajo utilización solo de renderizado para procesar sus trabajos; no somos un partner de SideFX y no revendemos licencias de Houdini. Dado que nuestra render farm es completamente gestionada, usted no accede remotamente a un nodo, no instala Houdini por su cuenta ni nos entrega una licencia — usted carga su escena y los datos en caché, y el licenciamiento del lado del renderizado en nuestros nodos se gestiona como parte de la operación del servicio. Para los motores comerciales del stack de Houdini, las licencias de Redshift, Arnold, V-Ray y Octane están incluidas en la tarifa de renderizado.
El stack de Houdini de Super Renders Farm
Una render farm que solo ejecuta un motor fuerza a todos los planos a través de un mismo conjunto de compromisos. El trabajo de Houdini raramente coopera con eso, por lo que nuestra render farm cloud para Houdini ejecuta el conjunto completo: Karma (en modos XPU y CPU), Mantra, Redshift, Arnold, V-Ray for Houdini y Octane. El propósito de esta variedad es que usted elija el motor adecuado por plano en lugar de por estudio — Karma XPU para el pase de look-dev nativo USD, Karma CPU para el fotograma héroe con muchos volúmenes que no cabe en la VRAM, Redshift para la secuencia crítica en velocidad, Mantra para la configuración de shaders heredada.
El hardware subyacente se divide a lo largo de la misma línea CPU/GPU que hace el trabajo de Houdini. Nuestra flota de CPU aporta más de 20.000 núcleos de CPU, que es donde ocurre la mayor parte del renderizado de producción — en toda la industria y en nuestra render farm, el renderizado CPU sigue siendo la mayor parte de los trabajos. Esa capacidad de CPU es lo que hace que Karma CPU y Mantra sean prácticos a escala de secuencia y lo que atrapa a Karma XPU cuando un fotograma es demasiado pesado para la GPU. Para los trabajos de GPU, nuestras máquinas GPU dedicadas ejecutan tarjetas NVIDIA RTX 5090 con 32 GB de VRAM cada una. Para Karma XPU específicamente, esos 32 GB son el número que más importa: la VRAM es el techo efectivo sobre qué tan compleja puede ser una escena antes de que XPU deje de acelerar en la GPU. Un conjunto de texturas UDIM 4K, un entorno instanciado denso o un VDB de alta resolución pueden consumir rápidamente ese presupuesto, y cuanto más grande sea la tarjeta, más lejos llega antes de que el renderizado caiga silenciosamente a la CPU. Si está evaluando trabajos limitados por GPU en general, nuestras notas de renderizado con RTX 5090 profundizan en la tarjeta, y la página general de render farm GPU cubre la flota.

Diagrama de Karma XPU y VRAM de GPU: una escena que cabe en 32 GB de VRAM se renderiza a velocidad híbrida CPU+GPU, mientras que una escena que supera la VRAM vuelve a la CPU.
La facturación sigue el hardware: el renderizado CPU se mide por GHz-hora y el renderizado GPU por OctaneBench-hora, por lo que una secuencia de Karma CPU y una secuencia de Redshift se pagan en las unidades que realmente describen el trabajo realizado. Dado que Karma XPU puede utilizar ambos dispositivos, el modelo mental más claro es que se factura como tiempo de GPU cuando se ejecuta en un nodo de GPU y permanece en la VRAM, con la contribución de la CPU yendo de la mano — otra razón por la que conviene respetar el techo de VRAM.
Caché de simulaciones: el paso que no puede omitir
Este es el concepto más importante para renderizar Houdini en cualquier render farm, y el que con mayor probabilidad hará perder un día si se malentiende: los fotogramas son paralelamente independientes, pero las simulaciones no lo son.
El fotograma 1042 de una animación renderizada no necesita que exista primero el fotograma 1041 — ambos pueden renderizarse en máquinas separadas al mismo tiempo. Esa independencia es la razón por la que las render farms funcionan. Una simulación es lo contrario. El fotograma 1042 de una simulación de Pyro se calcula a partir del estado del humo en el fotograma 1041, que vino del 1040, todo el camino de vuelta al primer fotograma. No se puede calcular el medio de una simulación sin calcular todo lo anterior, en orden, en una sola máquina. Entregue una simulación sin procesar a una render farm y no habrá nada que distribuir.
La solución es determinista e innegociable: simule primero, almacene en caché en disco, luego renderice la caché en la render farm. La simulación se ejecuta secuencialmente en una máquina (o una máquina de simulación dedicada) y escribe el resultado de cada fotograma en disco. Esos archivos de caché — ahora datos estáticos e independientes de fotograma — son los que renderiza la render farm. Los nodos de renderizado nunca vuelven a simular; leen geometría y volúmenes precomputados y rastrean fotogramas en paralelo como cualquier otra animación.
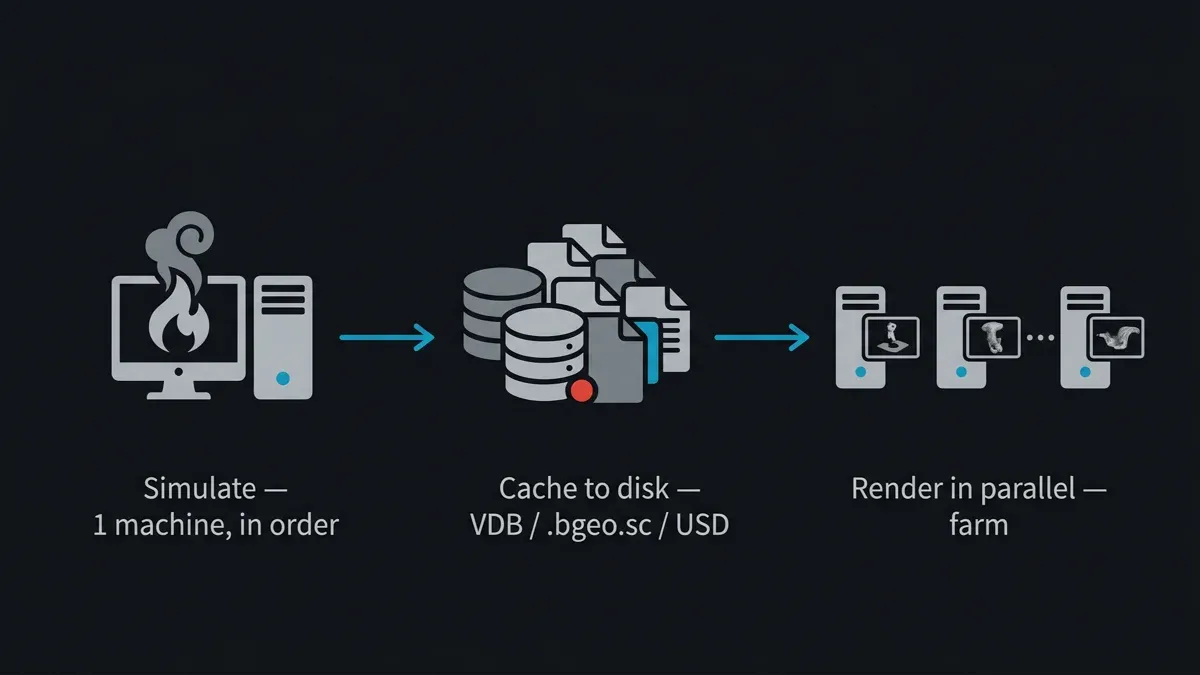
Diagrama de pipeline: una simulación se resuelve secuencialmente en una máquina, se almacena en caché en disco como VDB o bgeo, y luego se renderiza fotograma a fotograma en paralelo a través de una render farm.
Lo que se almacena en caché depende del solver:
| Simulación | Solver | Formato de caché | Notas |
|---|---|---|---|
| Humo / fuego | Sparse Pyro | .vdb | Volúmenes dispersos estándar del sector; se leen directamente en la etapa de renderizado |
| Líquidos | FLIP | Partículas .bgeo.sc → superficie mallada | El mallado desde partículas en caché es independiente por fotograma, por lo que puede enviarse a la render farm por separado |
| Tela / grano / cuerpos blandos | Vellum | .bgeo.sc | Las cachés de tela héroe crecen rápido — vigile el rendimiento de almacenamiento |
| Cuerpos rígidos, crowds, instancias | RBD / Agents | .bgeo.sc o USD | USD (PointInstancer) es la entrega más limpia a Karma |
Un detalle que vale la pena señalar: existe una diferencia real entre la simulación en sí y el trabajo posterior a ella. El mallado de superficies FLIP — convertir partículas en caché en una malla de renderizado — depende solo de las partículas de cada fotograma, no del fotograma anterior, por lo que ese paso es paralelizable y puede enviarse a la render farm como su propio pase aunque la simulación subyacente no pudiera serlo. El patrón cada vez más común en los pipelines de Houdini 20 en adelante es almacenar en caché la geometría directamente en USD, de modo que husk la lea de forma nativa en el momento del renderizado sin ningún paso de traducción de SOP a USD en el nodo.
Aquí es también donde PDG/TOPs gana su lugar. PDG es el grafo de tareas consciente de dependencias de Houdini, y modela exactamente la relación que el renderizado en render farm necesita: "almacena en caché esta simulación, y solo una vez que la caché exista, renderiza estos fotogramas desde ella." Un File Cache TOP produce la caché de simulación como dependencia de salida; una tarea de renderizado posterior espera a que exista y luego se expande por fotograma. PDG puede dirigir tanto el almacenamiento en caché como el renderizado con husk a través de sus nodos de planificación, razón por la cual se ha convertido en la columna vertebral de los pipelines serios de render farm de Houdini.
Una nota práctica de la experiencia: las cachés de tela y líquido de alta resolución pueden llegar a gigabytes por fotograma, y cuando docenas de nodos extraen la misma secuencia desde el almacenamiento compartido al mismo tiempo, el rendimiento de lectura — no el cómputo — se convierte en el cuello de botella. Admitimos cargas sin límite de tamaño rígido (sugerimos mantenerse por debajo de 300 GB por carga, y usar SFTP o la aplicación cliente por encima de eso), y aceptamos archivos .tar, .tar.gz y .7z — pero no .zip. Reempaquete las secuencias de caché pesadas como .tar.gz antes de subirlas. El resultado renderizado permanece disponible durante 45 días después de completarse un trabajo, tiempo más que suficiente para descargar una secuencia completa.
Envío de un trabajo de Karma XPU, de principio a fin
Uniendo las piezas, un trabajo limpio de Karma XPU en render farm se ejecuta en un orden predecible:

Flujo de trabajo de seis pasos para enviar un trabajo de Karma XPU a una cloud render farm: almacenar simulaciones en caché, exportar la etapa USD, cargar, elegir el motor, distribuir fotogramas, denoisear y descargar.
- Almacene en caché todas las simulaciones. Pyro a VDB, FLIP y Vellum a
.bgeo.sco USD. Confirme que las cachés están completas y son contiguas por fotograma — un fotograma central que falta aparece como un hueco en el renderizado, no como un error. - Exporte una etapa USD compuesta con los prims de Render Settings y Render Var integrados, con todas las rutas de assets resueltas para que sean accesibles desde un nodo de renderizado y no solo desde las unidades locales de su estación de trabajo.
- Empaquete el proyecto — escena, cachés, texturas y cualquier configuración OCIO — y cárguelo. Dado que la render farm es completamente gestionada, no hay ningún nodo al que acceder remotamente ni ninguna instalación de Houdini que supervisar.
- Elija el motor. Karma XPU para el look-dev dentro de la VRAM y los pases finales; cambie a Karma CPU para los fotogramas que sabe que son demasiado pesados para 32 GB; recurra a Redshift cuando la velocidad sea la prioridad.
- Distribuya los fotogramas. La render farm distribuye el rango de fotogramas entre los nodos, cada uno ejecutando
huskpara su fragmento. Usted supervisa el progreso en lugar de gestionarlo. - Denoise y descargue. Descargue los EXR (con OIDN aplicado si lo configuró) dentro del plazo de 45 días.
El modo de fallo recurrente en todo esto es la resolución de assets. USD resuelve las rutas relativas a la capa que las referencia o como rutas absolutas, y una ruta absoluta que apunta a la unidad de su estación de trabajo local simplemente producirá texturas o geometría faltantes en un nodo de renderizado — a menudo sin un error explícito, solo negro donde debería haber un asset. Resuelva las rutas contra una raíz de proyecto compartida, mantenga su configuración OCIO coherente en todo el trabajo para que el color no derive, y aplane las dependencias de HDA personalizadas en el USD antes de exportarlo para que un nodo no necesite un plugin que nunca se le proporcionó. Para los fundamentos más amplios de cómo el renderizado en la nube distribuye este tipo de trabajo, nuestra descripción general de cloud render farm establece el contexto.
Cuándo elegir Karma XPU vs Redshift
Tanto Karma XPU como Redshift pueden renderizar Houdini en una render farm GPU, y la elección no es sobre cuál es "mejor" — es sobre lo que el plano y el pipeline necesitan. Provienen de filosofías diferentes. Karma XPU es físicamente basado, nativo de USD, con sombreado MaterialX y creado por el mismo proveedor que Houdini. Redshift es un motor GPU maduro y predominantemente sesgado con más de una década de historial de producción, un plugin para Houdini y — este es su rasgo destacado en render farm — un robusto sistema out-of-core que se desborda con gracia de la VRAM a la RAM del sistema y NVMe cuando una escena se vuelve demasiado grande. Donde Karma XPU tiende a volver a la CPU cuando hay desbordamiento de VRAM, Redshift sigue renderizando en la GPU con una penalización de rendimiento predecible, razón por la cual una tarjeta de 32 GB puede manejar escenas con mucho más de 32 GB de texturas en Redshift.
Esa diferencia impulsa la mayor parte de la decisión:
| Elija Karma XPU cuando... | Elija Redshift cuando... |
|---|---|
| El pipeline es nativo de USD / Solaris | La velocidad bruta de GPU es la prioridad |
| Los shaders son MaterialX | La escena es intensiva en VRAM (VDB grandes, conjuntos de texturas enormes) |
| Desea transporte de luz físicamente basado, sin parpadeo de caché de GI | Necesita estabilidad out-of-core por encima del techo de VRAM |
| Está estandarizando en el stack completo de SideFX | El equipo ya tiene shaders de Redshift y look-dev |
| El factor de costo del motor importa (Karma viene con Houdini) | Trabaja en C4D / Maya / Houdini y quiere un look unificado |
Los otros motores cubren los casos límite. Arnold es la elección para VFX pesados con subsuperficie compleja, cabello y volúmenes, o cuando un pipeline ya depende de shaders específicos de Arnold — simplemente fije la versión de HtoA a los nodos de render farm y preconvierta las texturas a .tx. V-Ray for Houdini tiene sentido para estudios ya estandarizados en V-Ray en 3ds Max y Maya que quieren un look coherente entre DCCs; puede leer más en nuestra página de Redshift sobre el lado GPU de esa comparación. Octane es adecuado para equipos que ya están en su ecosistema espectral basado en nodos y se factura limpiamente por OctaneBench-hora. Si desea una comparación más amplia proveedor por proveedor en lugar de por motor, nuestra comparación de render farms para Houdini cubre esa decisión.
Una advertencia específica para Karma XPU en una render farm: dado que una secuencia puede contener tanto fotogramas ligeros (acelerados por GPU) como fotogramas pesados (silenciosamente limitados por CPU), los tiempos de renderizado pueden variar ampliamente a través de lo que parece un trabajo uniforme. La solución es una verificación de memoria antes del vuelo en el fotograma más pesado antes de comprometer todo el rango — si va a superar los 32 GB de VRAM, decida deliberadamente entre Karma CPU en la flota de CPU y la ruta out-of-core de Redshift en lugar de dejar que el motor decida por usted a mitad de la secuencia. Más allá del motor en sí, las trampas estándar de render farm siguen aplicando: fije la versión de Houdini, mantenga la configuración del denoiser explícita en lugar de depender de los valores predeterminados por nodo, y verifique que cada ruta de asset se resuelva desde un nodo y no solo desde su máquina.
Para los detalles oficiales del motor, SideFX mantiene documentación exhaustiva tanto para Karma como para el motor de renderizado de línea de comandos husk — vale la pena leerlos antes de su primer envío grande.
FAQ
Q: ¿Cuál es la diferencia entre Karma XPU y Karma CPU?
A: Son el mismo motor Karma nativo de USD en dos modos de ejecución. Karma CPU se ejecuta solo en núcleos de CPU e implementa el conjunto completo de funciones de calidad de referencia. Karma XPU añade su GPU de NVIDIA y renderiza en CPU y GPU juntos para mayor velocidad, pero actualmente admite un subconjunto de las funciones de Karma CPU y está limitado por la VRAM de la GPU. El hábito práctico es confirmar un fotograma en Karma CPU cuando el resultado de XPU parece incorrecto, porque CPU es la referencia.
Q: ¿Necesito una licencia de SideFX o Houdini para renderizar Karma en una cloud render farm?
A: No por su parte, en una render farm completamente gestionada. Karma se incluye con Houdini en lugar de licenciarse por separado como Redshift u Octane, y ejecutamos Houdini bajo utilización solo de renderizado para procesar sus trabajos — no somos un partner de SideFX y no revendemos licencias de Houdini. Usted carga su escena y sus cachés; el licenciamiento del lado del renderizado en nuestros nodos se gestiona como parte del servicio gestionado.
Q: ¿Por qué las simulaciones deben almacenarse en caché antes de renderizarlas en una render farm?
A: Porque las simulaciones son secuenciales y los fotogramas no lo son. Cada fotograma de simulación depende del estado del fotograma anterior, por lo que una simulación debe resolverse en orden en una sola máquina. Los fotogramas de renderizado, en cambio, son independientes y pueden ejecutarse en cientos de nodos al mismo tiempo. Almacenar la simulación finalizada en disco (VDB para Pyro, .bgeo.sc o USD para FLIP y Vellum) la convierte en datos estáticos que la render farm puede renderizar en paralelo sin volver a simular.
Q: ¿Cómo gestiona Karma XPU una escena que supera la VRAM de la GPU?
A: A diferencia de Redshift, que transmite out-of-core desde la memoria del sistema, Karma XPU tiende a volver hacia la ejecución en CPU cuando una escena no cabe en la VRAM. El renderizado termina igualmente, pero la aceleración por GPU se pierde y el fotograma puede tardar mucho más — sin nada obvio en el registro. Para escenas que sabe que son pesadas, es mejor elegir deliberadamente Karma CPU en la flota de CPU o la ruta out-of-core de Redshift que dejar que el retroceso ocurra a mitad de la secuencia.
Q: ¿Es Karma XPU más rápido que Redshift?
A: Depende del plano. Redshift es un motor GPU altamente optimizado y predominantemente sesgado, y a menudo es más rápido en escenas de producción típicas, especialmente las intensivas en VRAM donde su sistema out-of-core mantiene el trabajo en la GPU. Karma XPU es físicamente basado y completamente nativo de USD, lo que es una mejor opción para los pipelines de Solaris y el sombreado MaterialX incluso si necesita más muestras para ruido equivalente. La velocidad por sí sola no lo decide — la compatibilidad con el pipeline y el margen de VRAM generalmente sí lo hacen.
Q: ¿Qué es husk y necesito usarlo directamente?
A: husk es el motor de renderizado USD de línea de comandos independiente de SideFX, y es lo que realmente renderiza Karma en un nodo de render farm — un proceso ligero que carga una etapa USD compuesta sin una sesión completa de Houdini. En una render farm gestionada no lo invoca manualmente; usted envía su escena y la render farm ejecuta husk por fotograma en los nodos por usted. Saber que existe le ayuda a entender por qué una exportación USD limpia y completamente resuelta importa tanto.
Q: ¿Puede PDG/TOPs dirigir un renderizado de Karma en la render farm?
A: Sí. PDG modela la dependencia entre almacenar en caché una simulación y renderizar desde ella, y sus nodos de planificación pueden distribuir tanto el paso de File Cache como el renderizado husk posterior a través de una render farm. Es la forma estándar en que los pipelines serios de Houdini expresan "primero almacena en caché, luego distribuye el renderizado por fotograma", y mantiene las partes secuenciales y paralelas del trabajo en el orden correcto automáticamente.
Q: ¿Qué otros motores de Houdini puedo usar además de Karma XPU?
A: Nuestro stack de Houdini ejecuta Karma en modos XPU y CPU, además de Mantra, Redshift, Arnold, V-Ray for Houdini y Octane. Ese rango le permite combinar el motor con el plano — Karma XPU para el look-dev nativo de USD, Karma CPU para los fotogramas héroe intensivos en VRAM, Redshift para la velocidad y out-of-core, Mantra para los shaders VEX heredados, y Arnold, V-Ray u Octane donde un pipeline ya depende de ellos.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



