
Multi-GPU-Skalierung: Was 1 vs. 2 GPUs beim Rendering wirklich bewirken (Benchmark 2026)
Überblick
Einleitung
TL;DR: Eine zweite GPU verdoppelt die Rendergeschwindigkeit selten, und wie stark sie hilft, hängt vollständig von der Render-Engine ab. In unseren 2026-Benchmarks auf Dual-RTX-5090- und Dual-RTX-4090-Nodes skalierten Durchsatz-Engines (V-Ray, Octane) nahe 2,00x, während Renderzeit-Engines niedriger skalierten — Cycles 1,31x–1,63x, Redshift 1,68x–1,92x —, weil ein fixer Overhead pro Rendering das begrenzt, was die zweite Karte beschleunigen kann. Zwei GPUs sind die praktische Obergrenze pro Node; der reale Durchsatz einer render farm entsteht durch viele Frames parallel über viele Nodes, nicht durch das Stapeln weiterer Karten in einer Maschine.
Eine zweite GPU macht ein Rendering nicht doppelt so schnell. Das klingt selbstverständlich, sobald man es ausspricht, aber viele Hardware-Entscheidungen basieren auf der Annahme, dass zwei Karten doppelte Geschwindigkeit bedeuten. Wir haben im Juni 2026 zwei unserer Benchmark-Nodes aus der Warteschlange genommen – einen mit zwei RTX 5090 und einen mit zwei RTX 4090 – und gemessen, was tatsächlich passiert, wenn man von einer auf zwei Karten wechselt, und zwar über vier Render-Engines und sieben Szenen- bzw. Benchmark-Kombinationen hinweg.
Die Kurzfassung: Es kommt vollständig auf die Engine an. Durchsatz-orientierte Benchmarks (V-Ray, Octane) skalieren fast perfekt, etwa 2x. Renderzeit-Engines (Cycles, Redshift) skalieren niedriger, und bei der schnelleren Karte half die zweite GPU weniger, nicht mehr. Wir gehen die Zahlen durch, erklären, warum die Kurve so verläuft wie sie verläuft, und – ebenso wichtig – erläutern klar, wo diese Betrachtung endet. Zwei Karten sind die Obergrenze auf einem einzelnen Node. Darüber hinaus zu gehen ist eine andere Architektur, keine größere Version dieser.
Dies ist ein Hardware- und Benchmark-Beitrag mit GPU-Schwerpunkt. Es sei vorweg gesagt, dass GPU nur einen kleinen Teil der Aufträge auf unserer render farm ausmacht – der Großteil der Produktionsarbeit läuft nach wie vor als CPU-Rendering (V-Ray, Corona, Arnold auf CPU). Wenn jemand aber fragt, „Lohnt sich eine zweite GPU?", verdient er gemessene Zahlen und keinen Verkaufspitch. Also: hier sind die gemessenen Zahlen.
Testmethodik (und was diese Zahlen nicht sind)
Beide Test-Nodes liefen unter Windows 11 Pro mit je zwei GPUs. Der 5090-Node verwendete Treiber 596.36; der 4090-Node verwendete Treiber 610.62 – eine Blackwell-Karte benötigt einen neueren Treiber, weshalb ein exakter Treiber-Abgleich nicht möglich war. Dieser Treiberunterschied ist nur für einen Aspekt relevant: den absoluten generationsübergreifenden Geschwindigkeitsvergleich zwischen einer 5090 und einer 4090. Die Skalierungsverhältnisse, auf die wir uns hier konzentrieren, sind innerhalb eines einzelnen Nodes gemessen (gleiche Karte, gleicher Treiber, eine GPU vs. zwei), sodass der Treiberunterschied keine Auswirkung hat.
Jede Szene ist ein herstellerkonformer Benchmark – Blenders Open-Data-Szenen (bmw27, classroom, junkshop), Maxons „Vultures"-Szene für Redshift, der Chaos V-Ray Benchmark 6.00.02 und OctaneBench 2025.2.1. Keine Kundenprojekte, keine Produktionsdaten. Wir veröffentlichen hier keine Minutenangaben pro Frame, Dollar-pro-Frame-Werte oder Stromverbrauchszahlen, weil dieses Datensatz diese nicht enthält und wir sie nicht erfinden.
Ein Methodikhinweis, der die Lesart der Cycles-Zeilen beeinflusst: Wir haben Blender Cycles mit 200 % Auflösung betrieben, schwerer als der Open-Data-Standard, damit jedes Rendering lang genug dauert, um ein stabiles und verlässliches Skalierungsverhältnis zu liefern. Das bedeutet, dass unsere Cycles-Rohzeiten nicht mit öffentlichen Open-Data-Wertungen vergleichbar sind – sie sind auf die Messung der Skalierung ausgelegt, nicht auf Bestenlisten-Einträge. Cycles und Redshift werden in Renderzeit (Sekunden, niedriger ist besser) gemessen; V-Ray und Octane als Benchmark-Score (vpaths bzw. OctaneBench-Punkte, höher ist besser). Das sind zwei verschiedene Metrik-Typen, sodass absolute Zahlen niemals Engine-übergreifend verglichen werden können – nur das Skalierungsverhältnis innerhalb einer Engine ist ein fairer Vergleich.
Das Kernergebnis: 1x-bis-2x-Skalierung je Engine
Hier sind die wesentlichen Daten – was eine zweite identische Karte tatsächlich bringt, nach Engine und Szene:
| Engine | Szene | Skalierung 2x RTX 5090 | Skalierung 2x RTX 4090 |
|---|---|---|---|
| Cycles | bmw27 | 1,54x | 1,58x |
| Cycles | classroom | 1,59x | 1,63x |
| Cycles | junkshop | 1,31x | 1,38x |
| Redshift | Vultures | 1,68x | 1,92x |
| V-Ray GPU (CUDA) | Benchmark | 1,97x | 2,00x |
| V-Ray GPU (RTX) | Benchmark | 2,00x | 2,00x |
| Octane | OctaneBench-Suite | 2,00x | 1,98x |
Liest man dies von oben nach unten, ergibt sich eine klare Zweiteilung. V-Ray und Octane landen bei oder knapp unter 2,00x auf beiden Karten – eine zweite GPU verdoppelt den Durchsatz nahezu. Cycles liegt im Bereich 1,31x–1,63x. Redshift kommt auf 1,68x beim 5090 und 1,92x beim 4090.
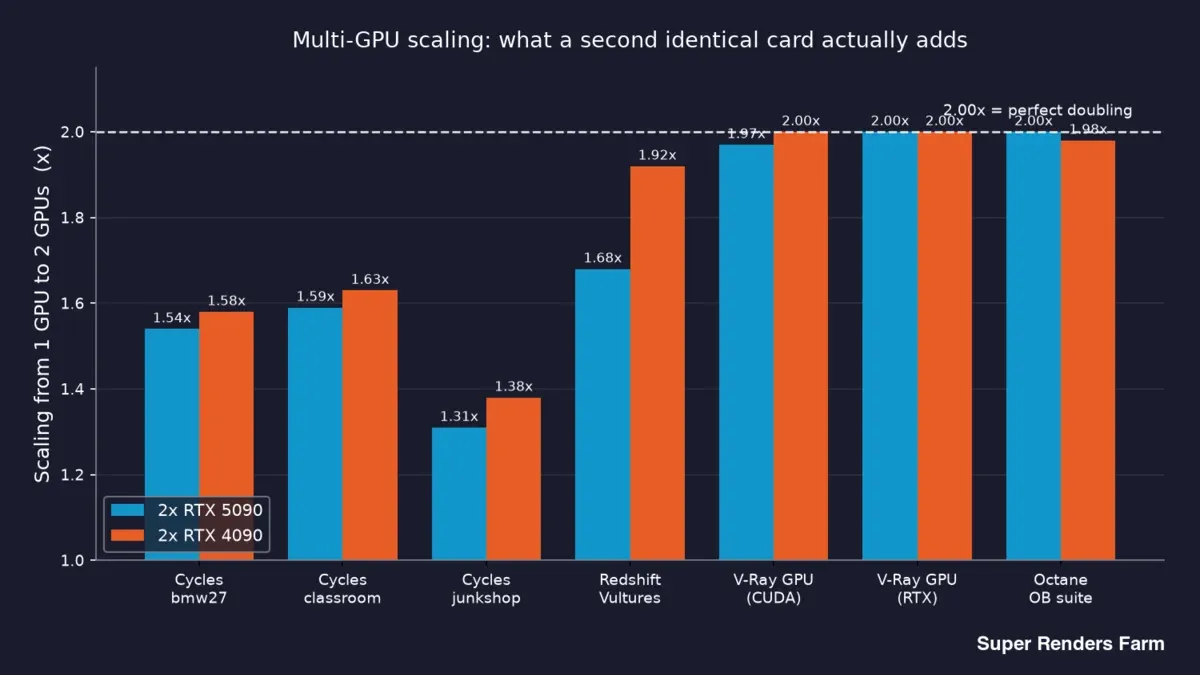
Balkendiagramm der 1-GPU-auf-2-GPU-Skalierung je Engine auf Dual-RTX-5090- und Dual-RTX-4090-Nodes: Cycles 1,31x bis 1,63x, Redshift 1,68x vs. 1,92x, V-Ray und Octane nahe 2,00x
Die Frage „Verdoppelt eine zweite GPU meine Geschwindigkeit?" hat also drei ehrliche Antworten, je nach Render-Engine: grundsätzlich ja für V-Ray und Octane, grob 1,5x für Cycles und irgendwo dazwischen für Redshift. Wer behauptet, ein einziger Multiplikator gilt für das gesamte Rendering, hat es schlicht nicht gemessen.
Warum Durchsatz-Engines besser skalieren als Renderzeit-Engines
Das Muster ist nicht zufällig – es ergibt sich daraus, wie jeder Benchmark seine Zeit verbringt. V-Ray Benchmark und OctaneBench sind Durchsatz-Tests. Sie belasten die gesamte verfügbare Rechenleistung und geben einen Score aus; der fixe Einrichtungsaufwand (Szene laden, Beschleunigungsstrukturen aufbauen, Gerät initialisieren) macht nur einen winzigen Bruchteil der Gesamtlaufzeit aus. Eine zweite Karte bedeutet, dass fast die gesamte zusätzliche Rechenleistung direkt in sinnvolle Arbeit fließt – daher kommt man nahe an 2x heran. Das saubere 2,00x-Ergebnis von V-Ray RTX auf beiden Karten ist genau das, was man von einer Arbeitslast erwartet, bei der der Overhead praktisch vernachlässigbar ist.
Renderzeit-Engines verhalten sich anders. Wenn man ein Cycles- oder Redshift-Rendering in Wanduhr-Sekunden misst, misst man den gesamten Auftrag – und jeder Auftrag trägt einen fixen Block nicht-paralleler Overhead-Arbeit: Szene-Parsing, BVH/Beschleunigungsstruktur-Aufbau, Kernel-Kompilierung und Warm-up, Gerätekoordination, das abschließende Pixel-Zusammenführen. Eine zweite GPU beschleunigt nur den Teil, der tatsächlich auf Karten aufteilbar ist. Sie tut nichts für den fixen Teil. Je größer der fixe Overhead-Anteil an der Gesamtrenderzeit, desto weiter sinkt die Skalierung unter 2x.
Das ist der Grund, warum Cycles junkshop (1,31x–1,38x) schlechter skaliert als Cycles classroom (1,59x–1,63x): junkshop ist ein leichteres, kürzeres Rendering, sodass sein fixer Overhead einen größeren Anteil am Gesamten ausmacht und der zweiten Karte weniger zur Beschleunigung übrig lässt. Die classroom-Szene läuft länger, der parallele Anteil dominiert, und die zweite GPU hat mehr Raum. Gleiche Engine, gleiche Hardware – die Szene bestimmt, wie sehr die zweite Karte hilft.
Das Kontraintuitive: Die schnellere Karte skalierte schlechter
Blickt man zurück auf die Redshift-Zeile: Zwei RTX 5090 skalieren 1,68x. Zwei RTX 4090 skalieren 1,92x. Die neuere, schnellere Karte skalierte schlechter. Das sieht wie ein Fehler aus. Ist es nicht – es ist die aufschlussreichste Zahl des gesamten Datensatzes.
Hier ist der Mechanismus. Die 5090 ist die schnellere Karte in absoluten Zahlen; mit einer einzelnen GPU rendert sie die Vultures-Szene in etwa 57 Sekunden gegenüber 100 Sekunden der 4090. Aber der fixe Overhead pro Rendering – Parsing, Aufbau, Warm-up – beläuft sich auf ungefähr die gleiche Anzahl Sekunden, unabhängig davon, welche Karte läuft. Bei der 4090 ist dieser fixe Anteil ein kleiner Bruchteil eines langen 100-Sekunden-Renderings, sodass die zweite Karte einen großen parallelen Anteil zu bewältigen hat und die Skalierung nahe 1,92x landet. Bei der 5090 ist das Rendering bereits kurz, weshalb der gleiche fixe Anteil einen größeren Bruchteil des Gesamten ausmacht und ein kleinerer paralleler Anteil für die zweite Karte übrig bleibt – daher kommt die Skalierung auf 1,68x.
Entscheidend ist: Das bedeutet nicht, dass die 5090 schlechter ist. Sie ist mit einer Karte schneller und mit zwei Karten schneller. Sie profitiert von der zweiten GPU proportional weniger, weil es weniger langsames Rendering zum Beschleunigen gab. Je schneller Ihr Basis-Rendering, desto schwieriger ist es für eine zweite Karte, ein sauberes 2x zu liefern – es bleibt schlicht weniger Zeit zum Parallelisieren. Das ist ein wirklich nützliches Wissen, bevor man Geld für das Stapeln identischer Karten in Erwartung linearer Renditen ausgibt.
Geschwindigkeit je Karte: RTX 5090 vs. RTX 4090
Skalierung ist eine Achse; rohe Geschwindigkeit je Karte ist die andere. Mit einer einzelnen Karte und dem angewendeten Treibervorbehalt aus dem Methodikabschnitt war die 5090 bei allen getesteten Engines vorn:
| Engine | Metrik | RTX 5090 | RTX 4090 | 5090-Vorteil |
|---|---|---|---|---|
| Cycles — bmw27 | Sekunden (niedriger besser) | 49,45 | 77,40 | 1,57x |
| Cycles — classroom | Sekunden | 23,09 | 36,87 | 1,60x |
| Cycles — junkshop | Sekunden | 19,71 | 34,43 | 1,75x |
| Redshift — Vultures | Sekunden | 57 | 100 | 1,75x |
| V-Ray GPU (CUDA) | vpaths (höher besser) | 11.051 | 7.419 | 1,49x |
| V-Ray GPU (RTX) | vpaths | 15.333 | 9.608 | 1,60x |
| Octane | OctaneBench-Score | 1.690,78 | 1.074,17 | 1,57x |
Insgesamt ist die 5090 je Karte rund 1,5x bis 1,75x schneller. Zwei Erkenntnisse für alle, die Hardware planen. Erstens: Generationsbedingte Zuwächse je Karte (hier 1,5x–1,75x) sind größer und verlässlicher als der Gewinn durch Hinzufügen einer gleichgenerationellen zweiten Karte bei einer Renderzeit-Engine (oft deutlich unter 2x). Einfach gesagt: Eine schnellere Karte ist häufig der bessere Hebel als eine zweite Karte. Zweitens: Diese einzelkartenbasierten, generationsübergreifenden Zahlen tragen den Treiberunterschied-Vorbehalt – sie sind als Richtungsvergleich zu werten, nicht als Servicegarantie. Wir messen auf Benchmark-Szenen; Ihre Szenenkomplexität, Ihr Sampling und Ihre Ausgabeauflösung werden die realen Werte beeinflussen. Weitere Informationen zum Verhalten einzelner RTX-5090-Karten finden Sie in unserem Artikel zu RTX 5090 GPU Cloud Rendering Performance.
Zwei GPUs sind die Node-Obergrenze – und warum das in Ordnung ist
Hier ziehen wir eine klare Linie, weil dies der Teil ist, den die meisten Multi-GPU-Inhalte stillschweigend übergehen. Jeder Node in diesem Benchmark ist ein Zwei-GPU-Node. Zwei Karten sind die Node-Obergrenze. Wir werden Ihnen keine 4x- oder 8x-Skalierungskurve für einen einzelnen Node zeigen, weil das keine Konfiguration ist, die wir betreiben, und wir werden das auch nicht implizieren.
Mehr als zwei GPUs auf einem einzelnen Frame bedeutet verteiltes Multi-Node-Rendering – das Aufteilen eines Bildes auf mehrere Maschinen mit dem gesamten Netzwerk-Koordinationsaufwand, Bucket-/Kachel-Management und Overhead, den das impliziert. Das ist eine grundlegend andere Architektur, keine größere Version eines Zwei-Karten-Servers. Wir bieten das heute für einen einzelnen Frame nicht an, weshalb wir es auch nicht als „demnächst verfügbar"-Funktion mit Datum ankündigen werden.
Und hier ist der Punkt: Für die überwiegende Mehrheit der Produktionsarbeit ist die Zwei-GPU-Obergrenze nicht die entscheidende Einschränkung. Die Einschränkung, die zuerst zuschlägt, ist fast immer VRAM, nicht die Kartenanzahl – eine Szene, die nicht in 32 GB passt, wird unabhängig von der Anzahl der GPUs nicht rendern, was ein völlig anderes Problem ist (wir behandeln es in RTX 5090 VRAM-Grenzen für komplexe Szenen). Wenn Menschen sich „Skalierung einer render farm" vorstellen, stellen sie sich meist ein einzelnes riesiges Rendering vor, das auf immer mehr Rechenleistung schneller wird. So funktioniert Durchsatz auf Farm-Ebene jedoch nicht.
Wie eine render farm tatsächlich skaliert: Frames, nicht Karten
Dies ist die Unterscheidung, die es wert ist, verinnerlicht zu werden, und sie ist diejenige, auf die die obigen Benchmark-Zahlen immer wieder hinweisen. Es gibt zwei völlig verschiedene Dinge, die Menschen mit „schneller rendern auf mehr Hardware" meinen:
- Einen Frame über viele GPUs oder Maschinen verteilen (Kachel-/Bucket-verteiltes Rendering). Das ist das, was die 1x→2x-Zahlen im Zwei-Karten-Maßstab messen, und was verteiltes Multi-Node-Rendering erweitern würde. Es trifft bei Renderzeit-Engines schnell auf abnehmende Renditen, wie die Daten zeigen, wegen des fixen Overhead-Aufwands pro Rendering – und der Koordinationsaufwand wächst nur, wenn man weitere Maschinen hinzufügt.
- Viele Frames über viele Maschinen verteilen (frame-paralleles Rendering). Jeder Node rendert einen vollständigen Frame für sich; die Frames einer Animation werden parallel über die gesamte Farm verteilt. Es gibt keinen Einzelframe-Koordinationsaufwand zu bekämpfen, sodass dies sauber skaliert und der Weg ist, wie eine Animation schnell abgewickelt wird.
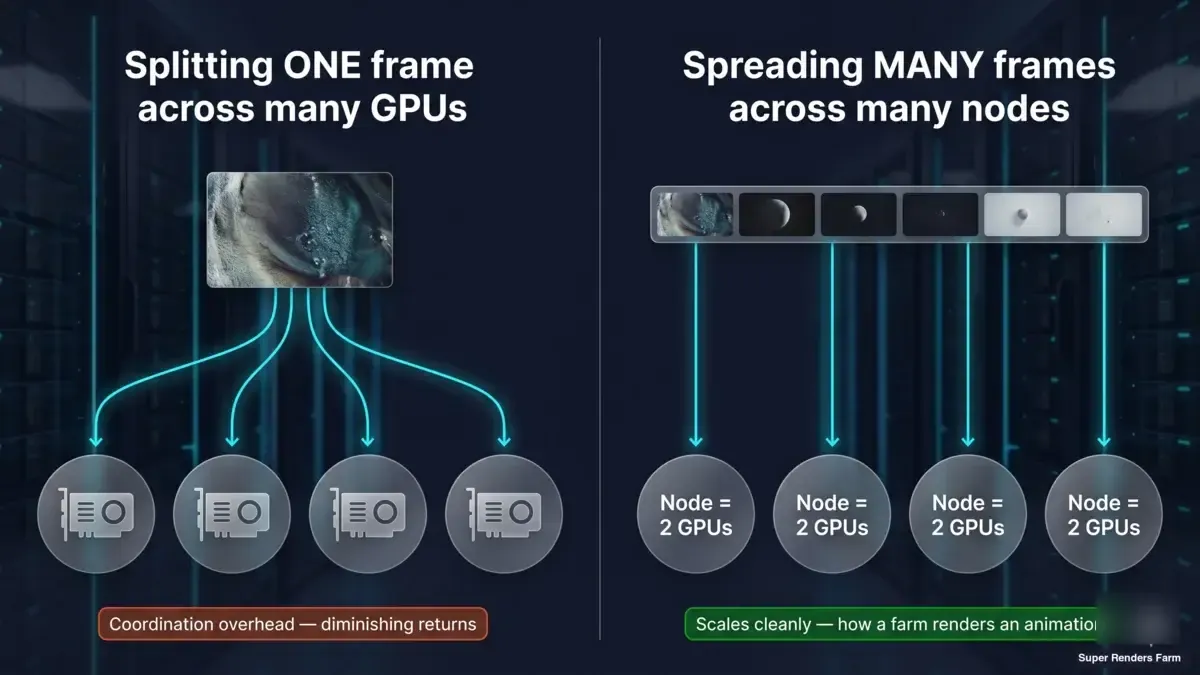
Zweipanel-Konzeptdiagramm: Ein Frame aufgeteilt über mehrere GPUs trifft auf Koordinationsaufwand und abnehmende Renditen; viele vollständige Frames je auf einem eigenen Zwei-GPU-Node parallel skalieren sauber – so skaliert eine render farm eine Animation
Eine vollständig verwaltete render farm erhält ihre Geschwindigkeit fast ausschließlich durch das zweite Modell. Ihre 500-Frame-Animation wird nicht als ein Frame auf 500 GPUs verteilt gerendert – sie wird als 500 Frames verteilt über die gesamte Farm gerendert, jeder auf seinem eigenen Node, alles gleichzeitig. Die Geschwindigkeit pro Node und Frame wird durch die Art der Zwei-GPU-Skalierung und der Einzelkarten-Performance bestimmt, die wir hier gemessen haben; die Geschwindigkeit auf Farm-Ebene ergibt sich aus der Anzahl gleichzeitig laufender Frames. Das sind verschiedene Hebel, und ihre Verwechslung ist der Ursprung vieler „Wie viele GPUs brauche ich?"-Verwirrungen.
Die ehrliche Einschätzung von Multi-GPU ist daher enger als die Marketing-Version. Zwei Karten pro Node geben Ihnen einen realen, messbaren Schub – nahe 2x bei V-Ray und Octane, bescheidener bei Cycles und Redshift. Darüber hinaus lautet die Antwort nicht „mehr Karten in den Server stecken", sondern „mehr Frames über mehr Nodes laufen lassen". Das ist die Architektur, und eine klare Kommunikation darüber erspart in der Regel Ausgaben für Hardware, die sich nicht so ausgezahlt hätte wie erwartet.
Was das für Ihre Render-Entscheidung bedeutet
Zusammenfassend lässt sich folgendes ableiten. Wenn Sie zwischen einer und zwei Karten für eine Workstation entscheiden, sollte die Engine, mit der Sie arbeiten, die Entscheidung leiten: V-Ray- und Octane-Nutzer erhalten nahezu eine vollständige Verdoppelung, und die zweite Karte ist leicht zu rechtfertigen; Cycles- und Redshift-Nutzer sollten einen Zuwachs von 1,3x–1,9x erwarten und abwägen, ob eine schnellere Einzelkarte (der generationsbedingte 1,5x–1,75x-Gewinn) die bessere Investition ist. Wenn Sie entscheiden, ob Sie lokal oder auf einer Farm rendern, denken Sie daran: Der Farm-Vorteil liegt im frame-parallelen Durchsatz für Animationen, nicht in einem magischen Einzelframe-Multiplikator – ein einzelner Hero-Still-Frame wird auf einer Farm nicht wesentlich schneller rendern als auf einer vergleichbaren Workstation, aber einige hundert Frames absolut schon.
Für den Kontext zum vollständig-verwalteten-vs-DIY-Kompromiss – wer sich um Treiber, Lizenzen und Node-Konfiguration kümmert – behandelt unser Beitrag vollständig verwaltete vs. selbst betriebene render farm dies ausführlich. Auf unserer render farm ist die Render-Engine-Lizenzierung (V-Ray, Redshift, Octane) im Rendering-Tarif enthalten, und die Node-Konfiguration ist festgelegt und wird für Sie gepflegt, sodass die Zwei-GPU-pro-Node-Einrichtung und die Treiber hinter diesen Zahlen nicht etwas sind, das Sie selbst zusammenstellen oder anpassen müssen. Speziell für Redshift unter Cinema 4D, wo der 1,68x-Skalierungswert relevant ist, lesen Sie unseren Redshift render farm für Cinema 4D-Leitfaden.
Die hier vorgestellten Messungen sind bewusst frei von Übertreibungen. Eine zweite GPU ist ein realer Hebel mit realen Grenzen, die schnellere Karte skaliert weniger, weil sie weniger langsames Rendering zu beschleunigen hatte, und Geschwindigkeit auf Farm-Ebene ist eine Geschichte der Frame-Verteilung, keine Geschichte des Karten-Stapelns. Zu wissen, welcher Hebel für Ihre Arbeitslast gilt, macht den Großteil der Entscheidung aus.
FAQ
Q: Verdoppelt eine zweite GPU die Rendergeschwindigkeit? A: Normalerweise nicht. In unseren 2026-Benchmarks skalieren Durchsatz-Engines wie V-Ray und Octane mit einer zweiten identischen Karte nahe an 2,00x, aber Renderzeit-Engines skalieren niedriger – Cycles kam auf 1,31x bis 1,63x, Redshift auf 1,68x bei Dual-RTX-5090. Der Gewinn hängt vollständig von Engine und Szene ab, weil jedes Rendering fixen Overhead trägt, den eine zweite Karte nicht beschleunigen kann.
Q: Warum skaliert Redshift auf der RTX 4090 besser als auf der RTX 5090? A: Weil die 5090 schneller ist, sind ihre Renderings kürzer, weshalb der fixe Overhead pro Rendering (Szene-Parsing, Beschleunigungsstruktur-Aufbau, Kernel-Warm-up) einen größeren Anteil des Gesamten ausmacht. Das lässt einen kleineren parallelen Anteil für die zweite Karte übrig, sodass die Skalierung bei der 5090 auf 1,68x gegenüber 1,92x bei der 4090 kommt. Die 5090 ist mit einer und zwei Karten nach wie vor schneller – sie gewinnt proportional schlicht weniger aus der zweiten GPU.
Q: Wie viel schneller ist die RTX 5090 gegenüber der RTX 4090 beim Rendering? A: Rund 1,5x bis 1,75x schneller je Karte über alle getesteten Engines hinweg, darunter Cycles, Redshift, V-Ray GPU und Octane. Diese einzelkartenbasierten, generationsübergreifenden Zahlen tragen einen kleinen Vorbehalt, weil die beiden Karten verschiedene NVIDIA-Treiber verwendeten – sie sind daher als Richtungsvergleich zu verstehen, nicht als feste Garantie.
Q: Warum skalieren V-Ray und Octane über zwei GPUs besser als Cycles und Redshift? A: V-Ray Benchmark und OctaneBench sind Durchsatz-Tests, bei denen der fixe Einrichtungsaufwand einen winzigen Bruchteil der Laufzeit ausmacht, sodass eine zweite Karte fast vollständig in sinnvolle Arbeit fließt und die Skalierung sich 2,00x annähert. Cycles und Redshift werden als Gesamt-Renderzeit gemessen, die nicht-parallelen Overhead einschließt, den eine zweite Karte nicht beschleunigen kann, weshalb ihre Skalierung unter 2x bleibt.
Q: Kann eine render farm einen einzelnen Frame auf vielen Maschinen schneller rendern? A: Das Aufteilen eines Frames auf mehrere Maschinen ist verteiltes Multi-Node-Rendering, eine separate Architektur mit eigenem Koordinationsaufwand, die wir heute für einen einzelnen Frame nicht anbieten. Eine vollständig verwaltete render farm erhält ihre Geschwindigkeit stattdessen aus frame-parallelem Rendering – viele vollständige Frames gleichzeitig auf vielen Nodes verteilt –, sodass eine Animation schnell fertig wird, während ein einzelner Hero-Frame mit etwa Node-Geschwindigkeit rendert.
Q: Wie viele GPUs brauche ich wirklich für das Rendering? A: Für einen einzelnen Node sind zwei GPUs eine sinnvolle Obergrenze und das, was unsere Benchmark-Nodes verwenden; darüber hinaus ist die praktische Einschränkung meist VRAM, nicht die Kartenanzahl, da eine Szene, die nicht in den Speicher passt, unabhängig von der Kartenanzahl nicht rendert. Wenn Sie Animationen rendern, kommt der echte Durchsatz davon, mehr Frames über mehr Nodes zu verteilen, statt mehr Karten in eine Maschine zu stecken.
Q: Sind diese Benchmark-Zahlen mit öffentlichen Blender-Open-Data-Wertungen vergleichbar? A: Nein. Wir haben Blender Cycles mit 200 % Auflösung betrieben, schwerer als der Open-Data-Standard, damit jedes Rendering lange genug dauert, um ein stabiles Skalierungsverhältnis zu erzeugen. Das macht unsere Cycles-Rohzeiten absichtlich unvergleichbar mit öffentlichen Open-Data-Bestenlisten – die Szenen wurden für die Skalierungsmessung angepasst, nicht für Standard-Scores.
Q: Muss ich GPU-Treiber und Lizenzen selbst verwalten, wenn ich eine vollständig verwaltete render farm nutze? A: Nein. Auf einer vollständig verwalteten Farm werden Node-Konfiguration, Treiber und Render-Engine-Lizenzen (V-Ray, Redshift, Octane) für Sie übernommen und sind im Rendering-Tarif enthalten, sodass das Zwei-GPU-Node-Setup und die Treiber hinter diesen Benchmarks nichts sind, das Sie selbst zusammenstellen oder anpassen müssen. Cycles ist kostenlos und Open-Source, weshalb es keine separate Lizenz erfordert.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



