
レンダーファームGPUのベンチマーク手法:再現可能なフレームあたりコスト計測法(2026年)
概要
はじめに
ベンチマークスコアは公開しやすいですが、信頼しにくいものです。「RTX 5090:Xポイント」と掲載することは誰でもできますが、あるカードで実際にレンダリングジョブを実行すべきか否かを判断する数値は、合成スコアではありません。それはフレームあたりコストです。この数値は、シーン、レンダー設定、エンジン、ドライバー、そして計算方法に依存しており、そのほとんどはリーダーボードのエントリには表示されません。
このページはリーダーボードではなく、手法を解説するものです。Super Renders FarmがレンダーファームのGPUをどのようにベンチマークするかを文書化しています。具体的には、ベンチマークシーンの選び方、ロックするレンダー設定、ハードウェアマトリクス全体で一定に保つ要素、生のフレーム時間を説得力のあるフレームあたりコストに変換する方法、そして多くの解説が省略している部分、つまりサードパーティが自分のハードウェアで全体を再現できる明示的な手順を説明します。この手法の出力はすでに公開済みです。これはその背後にあるレシピです。以下に数値が登場する場合は、それらの研究のいずれかから得た実際の値であり、再導出するのではなく実例として引用しています。
合成ベンチマークと実制作フレームあたりコスト
GPUベンチマークには2つの層があり、それらを混同することがほとんどの混乱の原因です。
1つ目は合成層です。標準化されたツールが1つの固定されたシーンをレンダリングしてスコアを出力するものです。Cinebench R24、ChaosのV-Rayベンチマーク、OctaneBenchはすべてここに含まれます。これらは相対的なランキングに役立ちます。すべてのマシンで同じ繰り返し可能なワークロードを使用するため、カードを並べて比較できます。それらのスコアの読み方は、V-Rayベンチマークガイドとクラウドレンダリング向けCinebenchスコアの記事で説明しています。合成スコアが意図的に除外しているのは、実制作で変動するすべての要素です。ジオメトリ、サンプリング、デノイザー、出力解像度、そして実際のキューが持つジョブごとのオーバーヘッドが含まれます。
2つ目は実制作層です。代表的な実際のフレームが実際にどれくらい時間がかかり、それがいくらかかるかということです。この手法が対象とするのはこの層です。合成スコアはその入力の1つであり、初期推定値を外挿する方法ですが、答えそのものではありません。2つの橋渡しは原理的には単純です。同じベンチマークビルドで別のマシンのほぼ2倍のスコアを出すマシンは、おおよそ半分の時間で同等のフレームをレンダリングします。その推定の計算(効率 = フレーム時間 ÷ ベンチマークスコア)はV-Rayガイドで説明しています。スコアではなくベンチマーク手法の目的は、その外挿を誠実にすること、つまり実制作に近いシーンで計測し、中央値だけでなく分布を報告することです。
重要な指標:フレームあたりコスト
フレームあたりコストは手法が収束すべき単位です。なぜなら、それがレンダリング予算が実際に記述される単位だからです。計算式はシンプルです:
フレームあたりコスト = フレームあたりウォールクロック時間 × ノードのコスト/時間
フレームあたりウォールクロックは、タスク時間をフレーム数で割ったもので、計測値であり、エンジンの内部「レンダリング時間」表示ではありません(シーンロード、アクセラレーション構造のビルド、デバイス調整を除外します)。ノードのコスト/時間は、そのハードウェアを1時間実行するコストです。当ファームでは、GPU レンダリングはOctaneBench-hourあたり0.003ドルで請求され、RTX 5090(32 GB)1枚あたりのハードウェア基盤はおおよそカード時間あたり5.2ドルです。顧客向けのモデルについては、フレームあたりコストガイドと料金ガイドで詳しく説明しています。
2つの入力を組み合わせるのは単純な単位計算です。フレームあたりウォールクロック時間を時間に変換し、ノードのコスト/時間を掛けることで、秒/フレームとドル/時間がドル/フレームに解決します。安価なノードでの短いフレームは低くなり、高価なノードでの重いフレームは高くなります。実際のコストはシーンの複雑さ、サンプリング、キュー待ち時間、および使用する課金モデルによって異なるため、実際の数値はこの手法ページには意図的に記載しておらず、フレームあたりコストガイドと料金ガイドがその場所です。重要なのは、この計算式が監査可能であることです。単位を明示すれば、誰でも信頼だけでなく数値を確認できます。
フレームあたりコストが合成スコアではなく主要な指標である理由:2枚のカードがベンチマークで同様のスコアを出しても、シーンでのフレームあたりコストは大きく異なる可能性があります。なぜなら、シーンが各フレームの並列化可能な作業と、高速なシリコンが手を付けられない固定オーバーヘッドの比率を決定するからです。
ベンチマークシーンとレンダー設定
シーンは、ベンチマークが実制作に転用できるかどうかに影響する最大のレバーであるため、意図的に2種類を実施しています。
クロスマシンランキング用のベンダー標準シーン。 純粋なリンゴ対リンゴの比較が目標の場合、公開されているリファレンスシーンを使用します。BlenderのOpen Dataシーン(bmw27、classroom、junkshop)、RedshiftのためのMaxon Vulturesシーン、Chaos V-Rayベンチマーク、OctaneBenchなどです。これらは繰り返し可能で独立して検証可能であり、まさにランキングに必要なものです。欠点は、それらがあなたのシーンではないため、絶対的な時間は直接実制作に転用できないことです。
フレームあたりコスト用の実制作代表シーン。 オペレーターが計画に使える数値が目標の場合、シーンは実際の作業に近いものでなければなりません。実際のジオメトリ、実際のテクスチャセット、実際のサンプリング、実際の出力解像度が含まれます。マルチGPUスケーリング研究では、各レンダリングが安定した信頼できる比率を生成するのに十分な長さになるよう、Blender Cyclesを200%解像度で実行しました。これはまた、それらの生のCycles時間が公開のOpen Dataスコアと比較できないことを意味します。このトレードオフは、手法が意図通りに機能している証拠です。シーンを問いに合わせて調整するということです。
どのシーンであっても、レンダー設定はロックして記録する必要があります。サンプル数(またはノイズしきい値)、デノイザーのオン/オフとその種類、出力解像度、タイルまたはバケットサイズ、エンジンビルドが含まれます。マシン間でこれらのいずれかが変動するベンチマークは、ハードウェアではなく変動を計測していることになります。
ハードウェアマトリクス
ベンチマークマトリクスはグリッドです。一方の軸にテストするカード、もう一方の軸にエンジンとシーンを配置します。規律はグリッド全体で一定に保つものにあります。
一定に保つもの:オペレーティングシステム、レンダリングエンジンのバージョンとビルド、デノイザー、シーン、設定。記録するが常に一致させられないもの:GPUドライバー。最新世代のカードは古いカードが使用できないドライバーを必要とする場合があるため、ドライバーの完全一致は不可能です。その場合は明示します。マルチGPU研究では、RTX 5090ノードはドライバー596.36、RTX 4090ノードは610.62で実行し、このギャップが世代間の絶対的な比較にのみ影響し、ノード内のスケーリング比率(両側で同じカードとドライバーを使用)には影響しないことを明示しました。
当ファームのGPUフリートは32 GBのVRAMを搭載したNVIDIA RTX 5090カードで標準化されており、これがマトリクスの内部一貫性を確保しています。統一されたインベントリは、あるノードからの推定値が次のノードにも転用できることを意味します。カード軸の実例として、マルチGPU研究からの単カード結果、RTX 5090対RTX 4090の同一シーンでの比較を以下に示します:
| エンジン/シーン | 指標 | RTX 5090 | RTX 4090 |
|---|---|---|---|
| Cycles — bmw27 | 秒(低い方が良い) | 49.45 | 77.40 |
| Cycles — classroom | 秒 | 23.09 | 36.87 |
| Redshift — Vultures | 秒 | 57 | 100 |
| V-Ray GPU(RTX) | vpaths(高い方が良い) | 15,333 | 9,608 |
| Octane | OctaneBenchスコア | 1,690.78 | 1,074.17 |
この表には2種類の指標が含まれています。秒(低い方が良い)とベンチマークスコア(高い方が良い)です。これが絶対的な数値がエンジン間で比較できない理由です。リンゴ対リンゴの比較は、単一エンジン内の比率のみです。
ベンチマークを信頼できるものにするコントロール
数値と信頼できる数値の違いはコントロールにあります。当手法が実施するコントロールは以下の通りです。
- GPUごとに1つのタスク。 スケジューラーはカードごとに1つのレンダータスクを実行するため、すべての数値はクリーンなカードごとの数値です。これは容量を計画するために掛ける値であり、共有デバイスの曖昧な平均ではありません。
- 比較のための対応ペア。 実制作でハードウェア世代を比較した際、シーンは同じシーン、同じユーザーが両側で実行し、カウントされる前に各側で少なくとも3つのタスクを実行した場合のみカウントしました。RTX 5090フィールドスタディでは、1,419タスクのうち38シーンがその基準をクリアしました。38は意図的に厳格なフィルターを生き延びた数であり、データのサイズではありません。
- ウィンドウごとに1つのドライバー。 フィールドスタディでは、単一のドライバー(581.80、CUDA 13.0)が7週間全体を通じて変更なしで実行され、ウィンドウ途中の変更が結果を汚染することはありませんでした。
- デノイザーの同等性。 Cyclesジョブの約83%が新旧世代のハードウェア両方でAIデノイズパスを実行しました。デノイザーは変数ではなく定数でした。
- ウォームとコールド。 タスクごとの固定コスト(シーンロード、同期、アクセラレーション構造のビルド)は、長いフレームよりも短いフレームのほうが大きな割合を占めます。これが短いオーバーヘッドバウンドのフレームが高速なカードを過小評価する理由です。この手法は、1つの乗数を想定するのではなく、分布を報告することでこれに対処しています。
生の時間から信頼できる数値へ
時間が収集されたら、統計によってヘッドラインの数値が誠実かどうかが決まります。
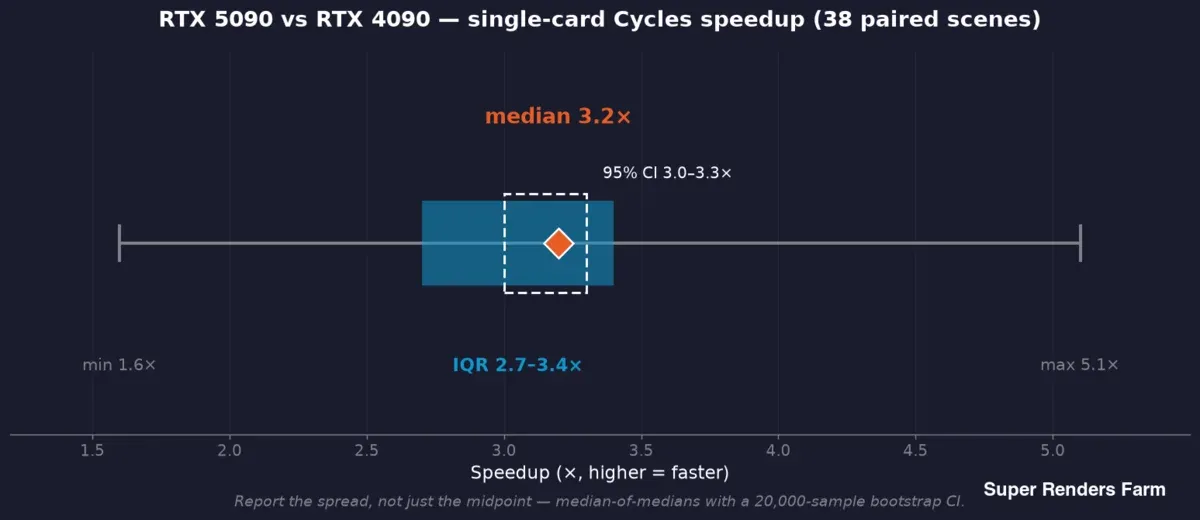
RTX 5090対RTX 4090の単カードCyclesスピードアップ(38対応シーン):中央値3.2x、95%信頼区間3.0〜3.3x、四分位範囲2.7〜3.4x、全範囲1.6〜5.1x
当手法ではメディアンのメディアンを使用します。各シーンは各側のフレームごとの時間の中央値を提供し、ヘッドラインはそのシーンごとの比率の中央値です。これにより、1つの遅いフレームが結果を歪めることができません。その中央値の周りにブートストラップ信頼区間(フィールドスタディでは20,000サンプルのブートストラップを使用し、中央値3.2xスピードアップ周辺に95% CI 3.0〜3.3xを提供)と分散(四分位範囲2.7〜3.4x、38シーン全体の全範囲1.6〜5.1x)を報告します。
この分散は平均化すべきノイズではなく、結果そのものです。3.2xの典型的なスピードアップと1.6xの最悪ケースのシーンは同時に真実であり、中央値のみを報告するベンチマークはオペレーターが必要とするストーリーの半分を隠しています。当手法のルール:中央値と範囲を報告し、各主張をそれを裏付けるサンプルに結び付けること。スピードアップは38の対応シーンから、VRAMは57のログされたジョブから、電力は別の制御されたベンチ実行から。あるサンプルを別の主張を支持するために借用することはありません。
このベンチマークを再現する方法
これがベンチマークをマーケティング文句ではなく獲得可能なシグナルにする部分です。誰でも実行できます。以下の手順は、任意のキューまたはテストベンチで手法を再現します。
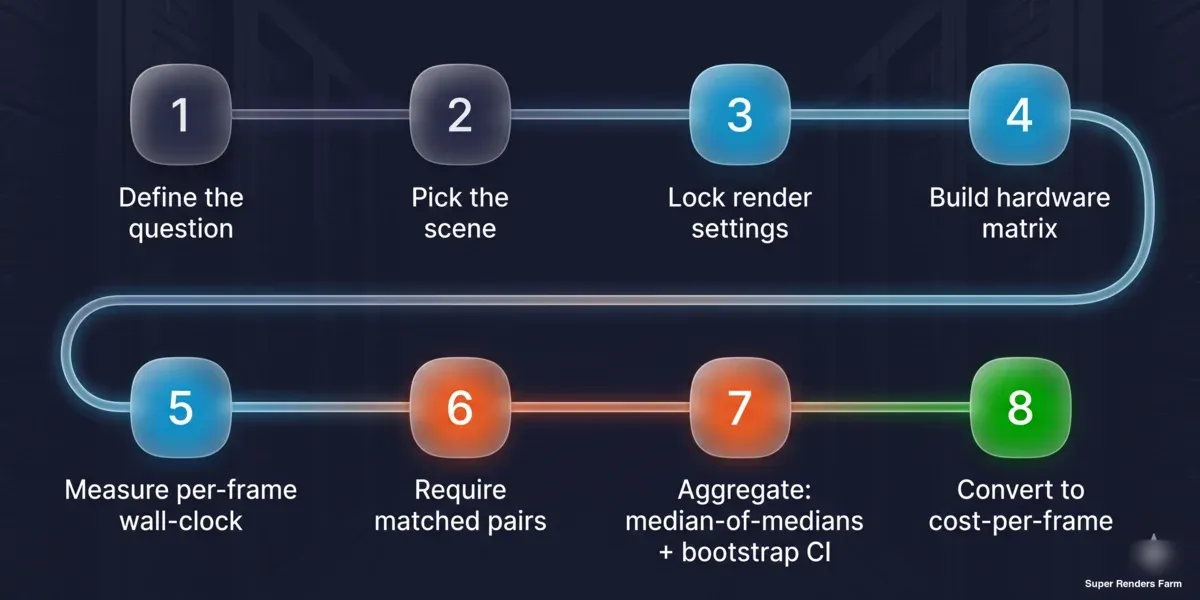
8ステップの再現可能なフレームあたりコストベンチマーク手法:質問の定義、シーンの選択、レンダー設定のロック、ハードウェアマトリクスの構築、フレームあたりウォールクロックの計測、対応ペアの要求、メディアンのメディアンとブートストラップ信頼区間での集計、フレームあたりコストへの変換
- 質問を定義します。 クロスマシンランキングか、実制作フレームあたりコストか?答えがシーンの種類を決定します。ランキングにはベンダー標準、コストには実制作代表を使用します。
- シーンと設定を固定します。 サンプル数またはノイズしきい値、デノイザーの選択、出力解像度、タイル/バケットサイズ、エンジンビルドをロックします。書き留めておきましょう。それらは結果の一部です。
- マトリクスを構築します。 一方の軸にカード、もう一方の軸にエンジン/シーンの組み合わせをリストします。一定に保つもの(OS、エンジンビルド、デノイザー、シーン)と保持できないもの(ドライバー)を記録します。
- フレームあたりウォールクロックを計測します。 スケジューラーまたはジョブ全体のストップウォッチからのタスク時間 ÷ フレーム数を使用します。シーンロードとビルドのオーバーヘッドを省略するエンジンの内部レンダリング時間表示は使用しません。
- 対応ペアと最小サンプルを要求します。 A対Bの主張には、同じシーンを両側で実行し、カウントされる前に各側で少なくとも3つのタスクを実行します。
- メディアンのメディアンで集計します。 各側の各シーンの中央値を取得し、次にシーンごとの比率の中央値を取ります。ブートストラップ信頼区間を計算し、四分位範囲と全範囲も一緒に報告します。
- フレームあたりコストに変換します。 計測されたフレームあたり時間にノードコスト/時間を掛けます。数値が監査可能になるよう単位を明示します。
- 数値と共に注意事項を公開します。 各主張の背後にあるサンプルサイズ、ドライバーの状況、データが観察的か制御的か、およびカバーする範囲と外れる範囲を明記します。
これらの8ステップを自分のハードウェアで実行するスタジオは、説明できる数値を得られます。そして当手法に対して検証することもできます。手法を公開する目的はそこにあります。
誠実さに関する注記:ベンチマークが主張できることとできないこと
手法は、主張を拒否することによってのみ信頼できます。当手法が守る3つのラインがあります:
観察的なものは制御的ではありません。 実制作フィールドデータ(ユーザーが通常の業務で実行したジョブ)は現実的で有用ですが、ユーザーは再レンダリング間に自分のシーンを調整するため、それは観察的です。クリーンな同一ホストでの直接対決(例えば、同一ハードウェアでのRTX 5090対現行RTX 4090)は、別の制御された演習です。一方をもう一方に見せかけることはしません。
ノード対ノードにはシリコンだけでなくセットアップも含まれます。 一方がベアメタルで実行し、もう一方が仮想化で実行する場合、計測されたギャップの一部はセットアップであり、チップではありません。それは脚注ではなくヘッドラインの注意事項に記載する必要があります。
計測していない数値は含みません。 計測していない電力や熱の数値は外挿しません。フィールドスタディがカードあたり約360〜375 Wを報告する場合、それは持続的な負荷下での制御されたベンチ実行から得られており、そこから導出されたフレームあたりエネルギーの数値は測定値ではなく推論としてラベル付けされています。数値が計測されていない場合、手法はそれを作り出しません。この規律が公開されたベンチマークを引用できる理由です。
当ファームの実例
この手法は以下の研究を生み出しました。各研究はレシピと一緒に読めるデータセットであり、実際の数値を探す場所です。ここで再導出するのではありません。
| 研究 | 手法が生み出したもの | サンプル |
|---|---|---|
| マルチGPUスケーリング | ベンダー標準シーンでのエンジンごとの1x→2xスケーリング | 2ノード、4エンジン、7シーン/ベンチマーク組み合わせ |
| RTX 5090フィールドノート | 実制作コスト/スピードアップ分布、VRAMパーセンタイル | 38対応シーン / 1,419タスク、7週間 |
| V-Rayベンチマークガイド | 合成スコアからレンダリング時間の推定 | リファレンステーブル + 実例推定 |
| クラウドレンダリング向けCinebench | ハードウェア階層向けの合成スコア解釈 | リファレンススコア |
同じアプローチが当ファームのGPUクラウドレンダーファームの容量計画の基盤となっており、Blender固有の数値はBlenderクラウドレンダリングの作業にも活用しています。GPUはジョブ全体のマイナーな部分です(ファーム作業のほとんどはまだCPUレンダリングです)。そのため、これらのGPU数値はファーム全体の主張としてではなく、GPU固有のものとして限定しています。
FAQ
Q: レンダーファームのGPUをベンチマークする正しい方法は何ですか? A: まずクロスマシンランキングが必要か、実制作フレームあたりコストが必要かを決定します。ランキングには、繰り返し可能なベンダー標準シーンと固定されたベンチマークビルドを使用します。フレームあたりコストには、実制作代表シーンを使用し、フレームあたりウォールクロック(タスク時間 ÷ フレーム数)を計測し、ノードコスト/時間を掛けます。レンダー設定をロックし、単一の数値ではなく分布を報告します。
Q: なぜフレームあたりコストはベンチマークスコアより優れているのですか? A: 合成スコアは実制作で変動するすべての要素(ジオメトリ、サンプリング、デノイザー、解像度)を除外するため、2枚のカードが同様のスコアを出しても、あなたのシーンでの実際のフレームあたりコストは異なる可能性があります。フレームあたりコストはレンダリング予算が実際に記述される単位であるため、手法はリーダーボードポイントではなくこれに収束すべきです。
Q: ベンチマークスコアをレンダリング時間の推定に変換するにはどうすればよいですか? A: スコアの比率をおおよその速度比率として使用します。同じベンチマークビルドで別のマシンの2倍のスコアを出すマシンは、同等のフレームをほぼ半分の時間でレンダリングします。マシンの効率をフレーム時間をベンチマークスコアで割って計算し、ターゲットマシンのスコアでスケーリングします。異なるビルドのスコアは比較できないため、ベンチマークビルドを一定に保ちます。
Q: GPUベンチマークを信頼できるものにするコントロールは何ですか? A: クリーンなカードごとの数値のためにカードごとに1つのレンダータスクを実行し、対応ペアを要求し(両側で同じシーン、結果がカウントされる前に最小タスク数)、計測ウィンドウ内でドライバーとエンジンビルドを一定に保ち、比較全体でデノイザー設定を同一に保ちます。次にメディアンのメディアンで集計し、信頼区間と範囲を報告します。
Q: 信頼できる結果を得るために何個のテストシーンが必要ですか? A: 厳密に制御された少ない対応ペアの方が、緩く制御された多くのペアよりも優れています。当ファームの実制作研究では、1,419タスクのうち38シーンが厳格な包含フィルター(両ハードウェア側で同じシーンとユーザー、各側で少なくとも3タスク)を通過しました。重要なサンプルサイズはフィルターをクリアしたものであり、生のタスク数ではありません。両方を報告する必要があります。
Q: レンダーファームのGPUベンチマークを自分で再現できますか? A: はい。それが目的です。シーンとその設定を固定し、OS、エンジンビルド、デノイザーを一定に保つハードウェアマトリクスを構築し、フレームあたりウォールクロックを計測し、対応ペアを要求し、メディアンのメディアンとブートストラップ信頼区間で集計し、フレームあたりコストに変換し、数値と共に注意事項を公開します。上記の8つの再現手順が完全なシーケンスを示しています。
Q: なぜ1つのスピードアップ数値ではなく範囲を報告するのですか? A: 範囲が結果の一部だからです。同じハードウェアが、短いオーバーヘッドバウンドのシーンでは1.6xのゲインを示し、重いコンピュートバウンドのシーンでは5x以上を示す可能性があります。フレームごとの固定オーバーヘッドは短いレンダーの大きな割合を占めるためです。中央値のみを報告すると、オペレーターが容量を計画するために必要な変動が隠れます。そのため、中央値、四分位範囲、全範囲を一緒に公開しています。
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



