
マルチGPUスケーリング:1枚vs2枚のGPUがレンダリングに与える実際の影響(2026年ベンチマーク)
概要
はじめに
TL;DR: 2枚目のGPUがレンダリング速度を倍にすることはほとんどなく、どれだけ効果があるかはレンダーエンジンによって完全に異なります。2026年にデュアルRTX 5090ノードとデュアルRTX 4090ノードで実施した弊社のベンチマークでは、スループット型エンジン(V-Ray、Octane)は2.00倍近くにスケールした一方、レンダリング時間計測型エンジンはそれを下回りました――Cyclesは1.31〜1.63倍、Redshiftは1.68〜1.92倍です。これは、固定の1レンダリングあたりのオーバーヘッドが、2枚目のカードが加速できる部分を食いつぶすためです。1ノードあたり2枚が現実的な上限であり、レンダーファームの実際のスループットは、1台のマシンにカードを重ねることではなく、多数のノードにわたって多数のフレームを並列処理することから生まれます。
2枚目のGPUを追加しても、レンダリング速度は2倍になりません。口に出してみれば当たり前に聞こえますが、「2枚のカード=2倍の速度」という前提でハードウェアの意思決定が行われるケースは少なくありません。2026年6月、弊社のベンチマーク用ノードのうち2台――RTX 5090を2枚搭載したノードとRTX 4090を2枚搭載したノード――をキューから取り出し、4種類のレンダリングエンジンと7つのシーン/ベンチマークの組み合わせで、1枚から2枚に増やした際に実際に何が起きるかを計測しました。
結論を先に述べると、結果はエンジンによって大きく異なります。スループット型のベンチマーク(V-Ray、Octane)はほぼ完全に2倍にスケールしました。レンダリング時間計測型のエンジン(Cycles、Redshift)はそれを下回り、しかも高速なカードほど2枚目の恩恵は小さくなりました。以下で数値を順に確認し、なぜそのような曲線を描くのかを説明します。そしてもう一点、同じく重要なこととして――この検証の範囲の限界についても明確にします。1ノードあたり2枚がシングルノードの上限です。それ以上に拡張するのは、別のアーキテクチャの話であり、2枚構成の延長ではありません。
本記事はハードウェア/ベンチマークに特化した内容であり、GPUの比重が高くなっています。弊社のファームを流れる処理の大半は依然としてCPUレンダリング(CPU上のV-Ray、Corona、Arnold)であることをあらかじめお伝えします。ただ、「2枚目のGPUは費用対効果があるか」という問いに対しては、セールストークではなく実測値で答えるべきです。以下がその実測値です。
テスト方法(および本データが示さないもの)
両テストノードはWindows 11 Proで動作し、それぞれ2枚のGPUを搭載しています。5090ノードはドライバー596.36、4090ノードはドライバー610.62を使用しました――Blackwellカードには新しいドライバーが必要なため、まったく同じバージョンでの統一はできませんでした。このドライバーの差が影響するのは一点のみです。それは5090と4090の世代間の絶対的な速度比較です。本記事で重点を置くスケーリング比率は、シングルノード内で計測したもの(同一カード、同一ドライバー、1枚vs2枚)であるため、ドライバーの差異は影響しません。
各シーンはすべてベンダー標準のベンチマークです――BlenderのOpen Dataシーン(bmw27、classroom、junkshop)、MaxonのRedshift用「Vultures」シーン、Chaos V-Ray Benchmark 6.00.02、OctaneBench 2025.2.1。顧客のプロジェクトや本番アセットは使用していません。フレームあたりの所要時間、フレームあたりのコスト、電力消費量はこのデータセットには含まれておらず、架空の数値を作成することはしないため、ここでは公開しません。
Cyclesの行の読み方に影響する手法上の注意点を一つ挙げます。BlenderのCyclesは、Open Dataのデフォルトより重い200%解像度で実行しました。これは各レンダリングを十分な長さにして、安定した信頼性の高いスケーリング比率を得るためです。そのため、本記事のCycles生データはOpen Dataの公式スコアとは比較できません――スケーリングの計測に最適化されており、リーダーボード用ではありません。CyclesとRedshiftはレンダリング時間(秒、低いほど良い)で計測し、V-RayとOctaneはベンチマークスコア(vpath数またはOctaneBenchポイント、高いほど良い)で計測しています。この2つは異なる指標であるため、エンジン間の絶対値は比較できず、エンジン内のスケーリング比率のみが公正な比較対象です。
核心的な結果:エンジン別の1→2倍スケーリング
以下が主要データです。エンジンおよびシーン別に、同一カードを2枚にすることで実際に得られる効果を示しています。
| エンジン | シーン | RTX 5090×2のスケーリング | RTX 4090×2のスケーリング |
|---|---|---|---|
| Cycles | bmw27 | 1.54倍 | 1.58倍 |
| Cycles | classroom | 1.59倍 | 1.63倍 |
| Cycles | junkshop | 1.31倍 | 1.38倍 |
| Redshift | Vultures | 1.68倍 | 1.92倍 |
| V-Ray GPU (CUDA) | ベンチマーク | 1.97倍 | 2.00倍 |
| V-Ray GPU (RTX) | ベンチマーク | 2.00倍 | 2.00倍 |
| Octane | OctaneBenchスイート | 2.00倍 | 1.98倍 |
上から下へ読むと、明確な分かれ目が見えます。V-RayとOctaneは両カードで2.00倍以下ながら非常に近い値――2枚目のGPUが出力をほぼ倍増させています。Cyclesは1.31倍から1.63倍の範囲。Redshiftは5090で1.68倍、4090で1.92倍に収まっています。
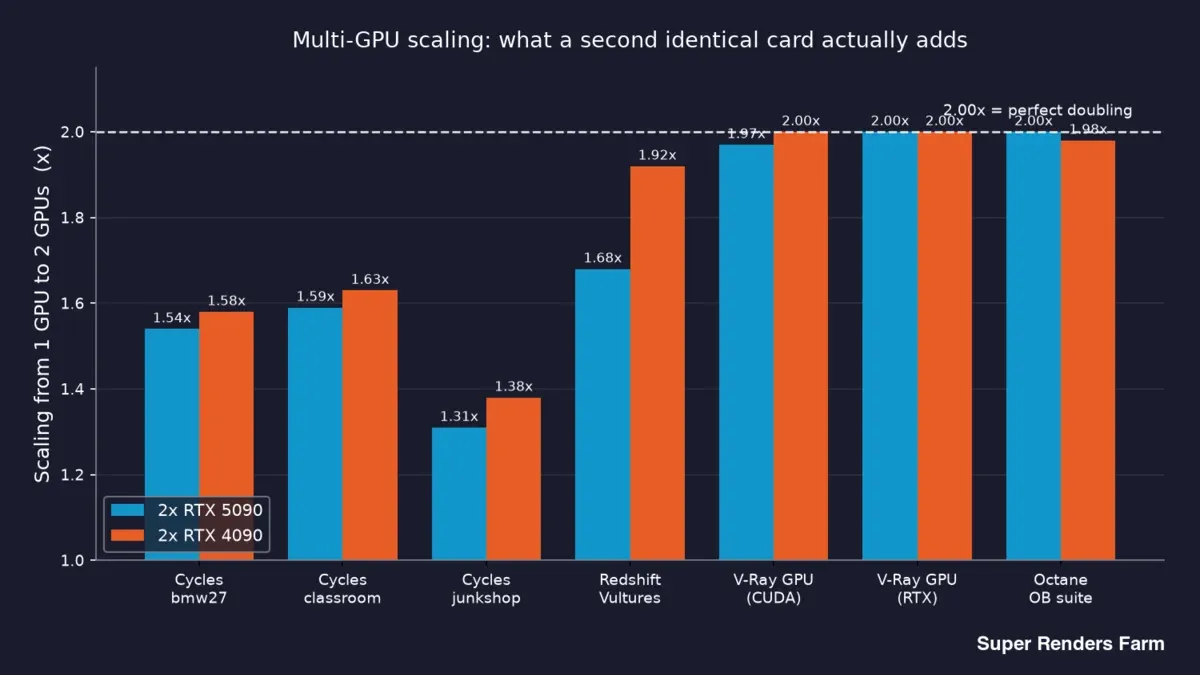
RTX 5090×2およびRTX 4090×2ノードのエンジン別1GPU→2GPUスケーリングの棒グラフ:Cycles 1.31〜1.63倍、Redshift 1.68倍 対 1.92倍、V-RayとOctaneは約2.00倍
つまり「2枚目のGPUで速度は倍になるか?」という問いに対する正直な答えは、レンダリング対象によって三通りあります。V-RayとOctaneではほぼYes、Cyclesではおよそ1.5倍の向上、Redshiftはその中間。単一の倍率がレンダリング全体に当てはまるかのように語る人は、実際には計測していないということです。
スループット型エンジンがレンダリング時間計測型エンジンより高くスケールする理由
このパターンはランダムではありません。各ベンチマークがどこに時間を費やしているかに起因しています。V-Ray BenchmarkとOctaneBenchはスループットテストです。利用可能なコンピューティングリソース全体に負荷を均等に分散してスコアを報告し、固定のセットアップコスト(シーンの読み込み、アクセラレーション構造のビルド、デバイスの初期化)は全体のほんのわずかに過ぎません。2枚目のカードを追加すると、追加されたシリコンのほぼすべてが有効な処理に直接投入されるため、2倍に近いスケーリングが得られます。V-Ray RTXが両カードで2.00倍という理想値を達成したことは、オーバーヘッドが実質的にノイズに過ぎないワークロードから期待される結果そのものです。
レンダリング時間計測型エンジンは異なる動作をします。CyclesやRedshiftのレンダリングをウォールクロック秒で計測する場合、ジョブ全体の時間を計っています。そしてすべてのジョブには、並列化できない固定のオーバーヘッドの塊が含まれています。シーンの解析、BVH/アクセラレーション構造のビルド、カーネルのコンパイルとウォームアップ、デバイス間の協調処理、最終的なピクセル解決などがそれです。2枚目のGPUはカード間で実際に分割できる部分のみを高速化します。固定部分には何の効果もありません。レンダリング時間全体に占める固定オーバーヘッドの割合が大きいほど、スケーリングは2倍を下回ります。
Cycles junkshop(1.31〜1.38倍)がCycles classroom(1.59〜1.63倍)よりスケールが低い理由もここにあります。junkshopは軽量で短いレンダリングであるため、固定オーバーヘッドが全体に占める割合が大きく、2枚目のカードが加速できる余地が少ないのです。classroomシーンはより長く、並列部分が支配的になり、2枚目のGPUが活躍できる余地が増えます。同じエンジン、同じハードウェアでも、シーンが2枚目のカードの有効性を決定します。
直感に反する結果:高速なカードほどスケールが低い
Redshiftの行を見直してください。RTX 5090×2のスケーリングは1.68倍。RTX 4090×2は1.92倍。新しく高速なカードの方がスケールが低い。これは誤りのように見えますが、そうではありません――このデータセット全体で最も示唆に富む数値です。
メカニズムを説明します。5090は絶対的な性能では高速なカードです。シングルGPUでVulturesシーンを約57秒で完了するのに対し、4090では約100秒かかります。しかし、レンダリングごとの固定オーバーヘッド――解析、ビルド、ウォームアップ――は、どちらのカードを使っても同じ秒数です。4090では、この固定の割合は長い100秒のレンダリングに対してわずかであるため、2枚目のカードが処理できる大きな並列部分が残り、スケーリングは1.92倍近くになります。5090では、レンダリング自体が既に短いため、同じ固定の割合が全体に占める割合が大きくなり、2枚目のカードが加速できる並列部分が小さくなって、スケーリングは1.68倍に収まります。
重要なのは、これは5090が劣ることを意味しないということです。1枚でも2枚でも5090の方が高速です。ただ、2枚目のGPUから得られる比例的な恩恵が少ない。なぜなら、そもそも速度を上げる余地が少ないためです。ベースのレンダリングが速ければ速いほど、2枚目のカードがきれいな2倍を実現するのは難しくなります――並列化できる時間が少ないからです。同一カードを重ねて直線的なリターンを期待して費用を投じる前に、これを理解しておくことは非常に有益です。
カード別の速度:RTX 5090 vs RTX 4090
スケーリングは一つの軸に過ぎません。もう一つの軸は1枚あたりの生速度です。シングルカードで(手法のセクションのドライバー注意書きを踏まえたうえで)、5090は検証したすべてのエンジンで優位でした。
| エンジン | 指標 | RTX 5090 | RTX 4090 | 5090の優位性 |
|---|---|---|---|---|
| Cycles — bmw27 | 秒(低いほど良い) | 49.45 | 77.40 | 1.57倍 |
| Cycles — classroom | 秒 | 23.09 | 36.87 | 1.60倍 |
| Cycles — junkshop | 秒 | 19.71 | 34.43 | 1.75倍 |
| Redshift — Vultures | 秒 | 57 | 100 | 1.75倍 |
| V-Ray GPU (CUDA) | vpaths(高いほど良い) | 11,051 | 7,419 | 1.49倍 |
| V-Ray GPU (RTX) | vpaths | 15,333 | 9,608 | 1.60倍 |
| Octane | OctaneBenchスコア | 1,690.78 | 1,074.17 | 1.57倍 |
全体を通じて、5090は1枚あたりおよそ1.5〜1.75倍高速です。ハードウェアを計画している方へ、二つの示唆があります。第一に、世代間の1枚あたりの性能向上(ここでは1.5〜1.75倍)は、同世代の2枚目のカードを追加した場合のレンダリング時間計測型エンジンにおける向上(しばしば2倍を大きく下回る)より大きく、信頼性が高いということです。平易に言えば、高速なカード1枚の方が2枚目のカードより有効なレバーとなることが多いです。第二に、シングルカードでの世代間比較にはドライバー差異の注意書きがあるため、方向性の参考として扱い、サービスレベルの確約とは見なさないでください。弊社はベンチマークシーンで計測しています。実際のシーンの複雑度、サンプリング数、出力解像度によってリアルワールドの値は変化します。シングルカードにおける5090の動作については、RTX 5090 GPUクラウドレンダリングパフォーマンスの記事もご参照ください。
1ノードあたり2枚が上限――そしてそれで十分な理由
ここで明確な線を引きます。マルチGPUコンテンツの多くが静かに省略している部分だからです。本ベンチマークのすべてのノードは2GPUノードです。2枚が1ノードあたりの上限です。4倍や8倍のシングルノードスケーリング曲線は示しません。そのような構成を弊社では運用しておらず、そのような示唆を与えるつもりもないためです。
シングルフレームで2枚を超えるGPUを使う場合は、マルチノード分散レンダリング――1枚の画像を複数のマシンに分割し、ネットワーク協調処理、バケット/タイル管理、それに伴うオーバーヘッドを伴う――が必要になります。これは全く別のアーキテクチャであり、2枚構成の拡大版ではありません。現在、シングルフレームに対してこの機能は提供しておらず、「近日公開予定」として日付付きで予告するつもりもありません。
そして実際のところ、大多数の本番作業において、2枚という上限は主要な制約ではありません。先に当たる制約はほとんどの場合、カード枚数ではなくVRAMです――32 GBに収まらないシーンは、GPUを何枚向けても処理できません。これはまったく別の問題です(RTX 5090の複雑なシーンにおけるVRAM制限で取り上げています)。「レンダーファームをスケールアップする」というイメージの多くは、より多くのシリコンで1枚の巨大なレンダリングが次第に速くなるというものです。しかしそれは、ファームスケールにおけるスループットの実際の仕組みではありません。
レンダーファームが実際にスケールする方法:カードではなくフレーム
ここで内面化する価値があるのが、先のベンチマーク数値が繰り返し示唆している区別です。「より多くのハードウェアでより速くレンダリングする」という表現には、まったく異なる二つの意味があります。
- 1フレームを多数のGPUまたはマシンに分割する(タイル/バケット分散レンダリング)。これは1→2枚の数値が2枚スケールで計測しているもの、そしてマルチノード分散レンダリングがさらに拡張するものです。データが示すように、レンダリング時間計測型エンジンでは固定の1レンダリングあたりのオーバーヘッドのために急速に逓減し、マシンを追加するほど協調コストは増加します。
- 多数のフレームを多数のマシンに分散する(フレーム並列レンダリング)。各ノードが完全なフレームを独立してレンダリングし、アニメーションのフレームが並行して複数のノードに配分されます。シングルフレームの協調オーバーヘッドがないため、クリーンにスケールし、これがアニメーションを高速に仕上げる方法です。
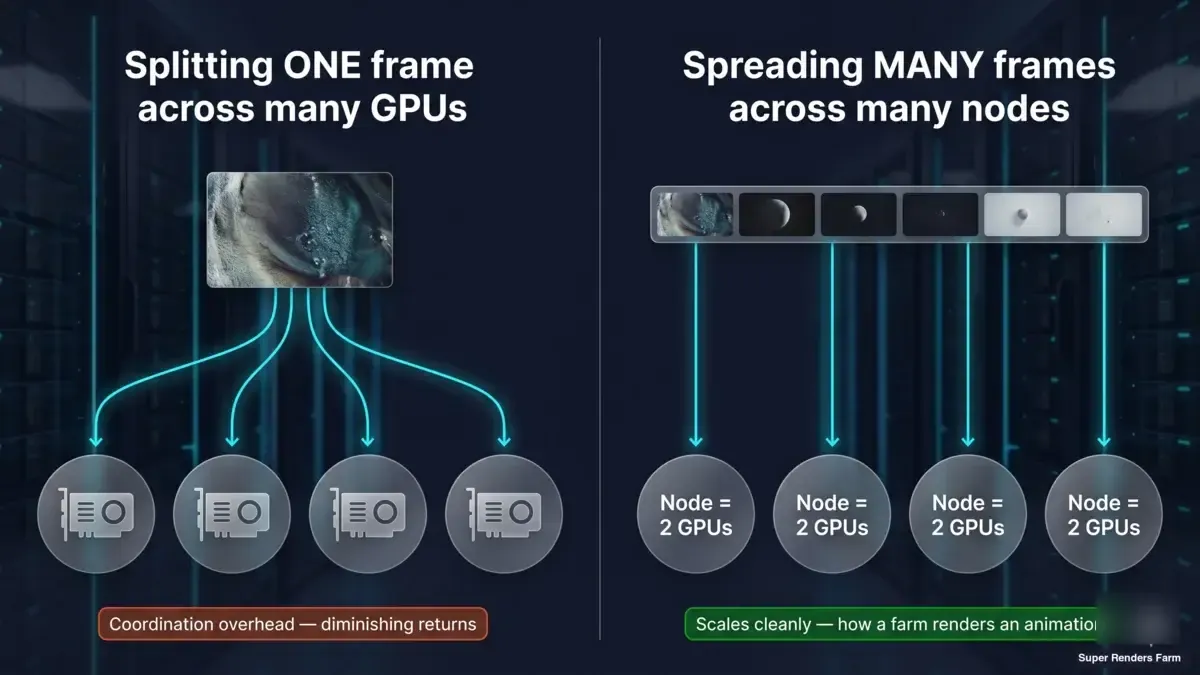
2パネルのコンセプト図:1つのフレームを複数のGPUに分割すると協調オーバーヘッドと収穫逓減が発生する;多数の完全フレームをそれぞれ独自の2GPUノードで並列処理するとクリーンにスケールし、レンダーファームがアニメーションをスケールさせる方法となる
マネージドレンダーファームは、そのスピードのほぼすべてを第二のモデルから得ています。500フレームのアニメーションは、500台のGPUに1フレームを分散させてレンダリングするのではなく、500フレームをフリート全体に分配し、各フレームを自ノードで並列に同時処理します。1ノードあたり・1フレームあたりの速度は、ここでベンチマークした2GPUスケーリングと1枚あたりのパフォーマンスによって決まります。ファームレベルのスピードは、同時に処理されるフレーム数から生まれます。この二つは異なるレバーであり、混同することが「GPUは何枚必要か」という混乱の多くを招いています。
そのため、マルチGPUについての正直な評価は、マーケティング版より狭い範囲に収まります。1ノードあたり2枚は現実的で計測可能な向上をもたらします――V-RayとOctaneでは2倍近く、CyclesとRedshiftではより控えめです。それ以上になると、答えは「1台の筐体にカードを重ねる」ではなく、「より多くのノードにより多くのフレームを分散させる」です。これがそのアーキテクチャです。このことを率直に伝えることで、期待通りの効果を得られなかったであろうハードウェアへの無駄な出費を防げます。
レンダリング方法を選ぶ際の実践的示唆
実際に活かせる形にまとめます。ワークステーションで1枚と2枚のどちらを選ぶかを検討している場合、使用するエンジンが判断を左右するはずです。V-RayまたはOctaneのユーザーはほぼ完全な倍増が得られるため、2枚目のカードは正当化しやすいです。CyclesとRedshiftのユーザーは1.3〜1.9倍の向上を見込み、高速なシングルカード(1.5〜1.75倍の世代間向上)の方が良い投資かどうかを検討すべきです。ローカルレンダリングとファームへの委託のどちらを選ぶかを検討している場合、ファームの強みはアニメーションのフレーム並列スループットであることを覚えておいてください。単一のヒーロースティルフレームは、同等のワークステーションと比べてファームでも劇的に速くなることはありませんが、数百フレームは確実に速くなります。
マネージド型とDIY型のトレードオフ――ドライバー、ライセンス、ノード設定を誰が管理するか――については、フルマネージドvs DIIYレンダーファームの記事で解説しています。弊社のファームでは、レンダリングエンジンのライセンス(V-Ray、Redshift、Octane)はレンダリング料金に含まれており、ノードの構成は固定でメンテナンスされています。そのため、本データの背景にある2GPUノードのセットアップやドライバーを自分でアセンブルしたり調整したりする必要はありません。1.68倍のスケーリング値が該当するCinema 4D上のRedshiftについては、Cinema 4D向けRedshiftレンダーファームのガイドをご覧ください。
本記事の計測値は意図的に誇張を排除しています。2枚目のGPUは実際の効果と明確な限界を持ち、高速なカードほどスケールが低いのは速度向上の余地が少ないからであり、ファームスケールのスピードはフレーム分散の話であり、カードを重ねる話ではありません。どのレバーが自分のワークロードに当てはまるかを理解することが、意思決定の大半を占めます。
FAQ
Q: 2枚目のGPUを追加するとレンダリング速度は倍になりますか? A: 通常はなりません。2026年のベンチマークでは、V-RayやOctaneのようなスループット型エンジンは同一カード2枚で2.00倍近くにスケールしましたが、レンダリング時間計測型エンジンはそれを下回りました――Cyclesは1.31〜1.63倍、RedshiftはデュアルRTX 5090で1.68倍でした。向上幅はエンジンとシーンによって完全に異なります。すべてのレンダリングには2枚目のカードが速度向上に貢献できない固定オーバーヘッドが含まれるためです。
Q: RedshiftはなぜRTX 5090よりRTX 4090の方がスケールが高いのですか? A: 5090は高速なため、レンダリング自体が短くなります。その結果、レンダリングごとの固定オーバーヘッド(シーン解析、アクセラレーション構造のビルド、カーネルウォームアップ)が全体に占める割合が大きくなります。2枚目のカードが加速できる並列部分が小さくなるため、5090では1.68倍、4090では1.92倍にスケーリングが収まります。5090は1枚でも2枚でも高速です――ただ、2枚目のGPUから得られる比例的な恩恵が少ないのです。
Q: RTX 5090はRTX 4090と比べてレンダリングでどのくらい高速ですか? A: Cycles、Redshift、V-Ray GPU、Octaneを含む検証したエンジン全体で1枚あたりおよそ1.5〜1.75倍高速でした。これらのシングルカード世代間比較には、2枚のカードが異なるNVIDIAドライバーで動作していたという軽微な注意書きがあるため、固定的な保証としてではなく方向性の参考として扱ってください。
Q: なぜV-RayとOctaneは2枚のGPUでCyclesやRedshiftよりスケールが高いのですか? A: V-Ray BenchmarkとOctaneBenchは、固定のセットアップコストが全体のごく一部を占めるスループットテストであるため、2枚目のカードはほぼすべて有効な処理に投入でき、スケーリングが2.00倍近くになります。CyclesとRedshiftは2枚目のカードが加速できない非並列オーバーヘッドを含む総レンダリング時間で計測されるため、スケーリングが2倍を下回ります。
Q: レンダーファームは1つのフレームを多数のマシンで速くレンダリングできますか? A: 1つのフレームを複数のマシンに分割するのはマルチノード分散レンダリングであり、独自の協調オーバーヘッドを持つ別のアーキテクチャです。現在、シングルフレームに対してこの機能は提供していません。マネージドファームはその代わりにフレーム並列レンダリングからスピードを得ています――多数の完全フレームを多数のノードに同時に分散させる方式です。そのためアニメーションは高速に完了しますが、シングルヒーローフレームはおおよそ1ノードの速度でレンダリングされます。
Q: レンダリングに実際に何枚のGPUが必要ですか? A: シングルノードでは2枚が妥当な上限であり、弊社のベンチマークノードもそれを使用しています。それ以上になると、現実的な制約はカード枚数ではなく通常VRAMです。メモリに収まらないシーンは、カードを何枚追加してもレンダリングできません。アニメーションをレンダリングするなら、1台のマシンにカードを重ねるより、より多くのノードにより多くのフレームを分散させることで真のスループットが得られます。
Q: これらのベンチマーク数値はBlender Open Dataの公式スコアと比較できますか? A: いいえ。Blender CyclesをOpen Dataのデフォルトより重い200%解像度で実行しました。各レンダリングを安定したスケーリング比率を得るのに十分な長さにするためです。そのため、本記事のCycles生データはOpen Dataのリーダーボードと意図的に比較できません――シーンはスケーリング計測に最適化されており、標準スコアへの適合を目的としていません。
Q: マネージドレンダーファームを使うにはGPUドライバーとライセンスを自分で管理する必要がありますか? A: いいえ。フルマネージドファームでは、ノードの設定、ドライバー、レンダリングエンジンのライセンス(V-Ray、Redshift、Octane)はすべて管理されており、レンダリング料金に含まれています。そのため、本ベンチマークの背景にある2GPUノードのセットアップとドライバーをアセンブルしたり調整したりする必要はありません。Cyclesは無料のオープンソースソフトウェアであるため、別途ライセンスは必要ありません。
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



