
RTX 5090の本番稼働:レンダーファームの7週間フィールドノート(38シーン調査)
概要
RTX 5090のローンチベンチマークはすでに1年以上前のものであり、いずれも同じ状況を描写しています:1枚のカード、1つのステージングシーン、理想的な条件。ほとんど誰も公開していないのは、その続き——カードが実際に本番キューに投入され、自分では制御できないスケジュールで他のユーザーのシーンをレンダリングし続けるとどうなるか、という話です。そこで私たちはログを引き出しました。以下は、私たちが実際にキャパシティ計画の根拠としている本番データを、検証可能な数値として整理したキューレベルのフィールドノートです。
これは7週間分のデータです。2026年4月1日から5月22日まで——51日間——私たちはデュアルRTX 5090ノード1台をライブレンダーファームの中で稼働させ、キューから割り当てられた仕事をそのまま処理させました。ステージングテストなし、フレームの選り好みなし。以下の短い動画でヘッドライン数値を解説し、その後に詳細なフィールドノートを続けます。
ノード自体は特筆すべきものではありません:RTX 5090が2基、RAMは128 GiB、論理コアは4.3 GHzで32個、OSはWindows 11です。ここに掲載されているすべての数値を形づくる重要な仕様が1つあります——スケジューラーはGPU1基につき1つのレンダータスクを割り当てるため、各カードは個別のジョブをレンダリングし、すべての数値はカード単位のクリーンな値となっています。これはキャパシティ計画の際に乗算する数字です。期間中、このノードはタスクの99.6%を完了させました——約4,900件中4,890件が完了し、18件が失敗しています。スケジューラーは失敗を記録しますが原因は記録しないため、推測は行いません。
主要な数値
- 期間: 2026年4月1日〜5月22日(51日間、約7週間)、デュアルRTX 5090ノード1台
- 完了率: 99.6%——約4,900件中4,890件が完了、18件が失敗(原因は記録なし)
- 高速化: Blender Cyclesのフレーム単位で中央値 3.2倍(旧世代RTX 3080/2080クラスノードとの比較。フレーム単位の中央値時間は約69%短縮);95% CI 3.0〜3.3倍
- 分布: IQR 2.7〜3.4倍、38組のシーン全体での全範囲 1.6倍〜5.1倍——1つの倍率数値でキューを表現することはできません
- AIデノイズ: Cyclesジョブの約83%がAIデノイズパスを実行——旧ハードウェアと同じ比率
- VRAM: 中央値5.6 GB、90パーセンタイル11.5 GB、最大ジョブ 約37 GB
- ドライバー: 期間全体で1つのドライバー(581.80 / CUDA 13.0)のみ使用、変更ゼロ
- 消費電力: 負荷時に各カード約360〜375 W(制御ベンチ、ピーク約400 W)、温度68〜83 °C——定格クラスの約575 Wを大幅に下回る
38組のシーンが示すもの
最も信頼できる比較は合成テストではなく、通常の業務の中で両世代のハードウェアで実行されたジョブです——同じシーン、同じユーザー、シーンとしてカウントするには両側で少なくとも3タスクが必要です。フレーム単位の時間はタスクの実時間をフレーム数で割ったもので、キューから直接取得しています。この期間中、38シーンがその基準をクリアし、1,419件の個別レンダータスク(RTX 5090ノードで503件、旧世代で916件)から抽出されています。38という数は私たちのデータの総量ではなく、意図的に厳格なフィルターを通過したものの数です。
| 指標 | 値 |
|---|---|
| フレーム単位の高速化(中央値) | 3.2倍(約69%の時間短縮) |
| ブートストラップ95% CI(中央値) | 3.0〜3.3倍 |
| 四分位範囲 | 2.7〜3.4倍 |
| 全範囲 | 1.6〜5.1倍 |
| シーン数 / タスク数 | 38シーン / 1,419タスク |
| ベースライン | 旧世代RTX 3080/2080クラス(10〜12 GB) |
私たちが使用しているのは中央値の中央値です:各シーンは両側でそれぞれのフレーム単位時間の中央値を提供し、3.2倍はその38の比率の中央値であるため、1つの遅いフレームが結果を歪めることはありません。ばらつきは中央値と同様に重要です——シーンの中間半分は2.7倍から3.4倍の間に収まり、全範囲は1.6倍から5.1倍に及びます。
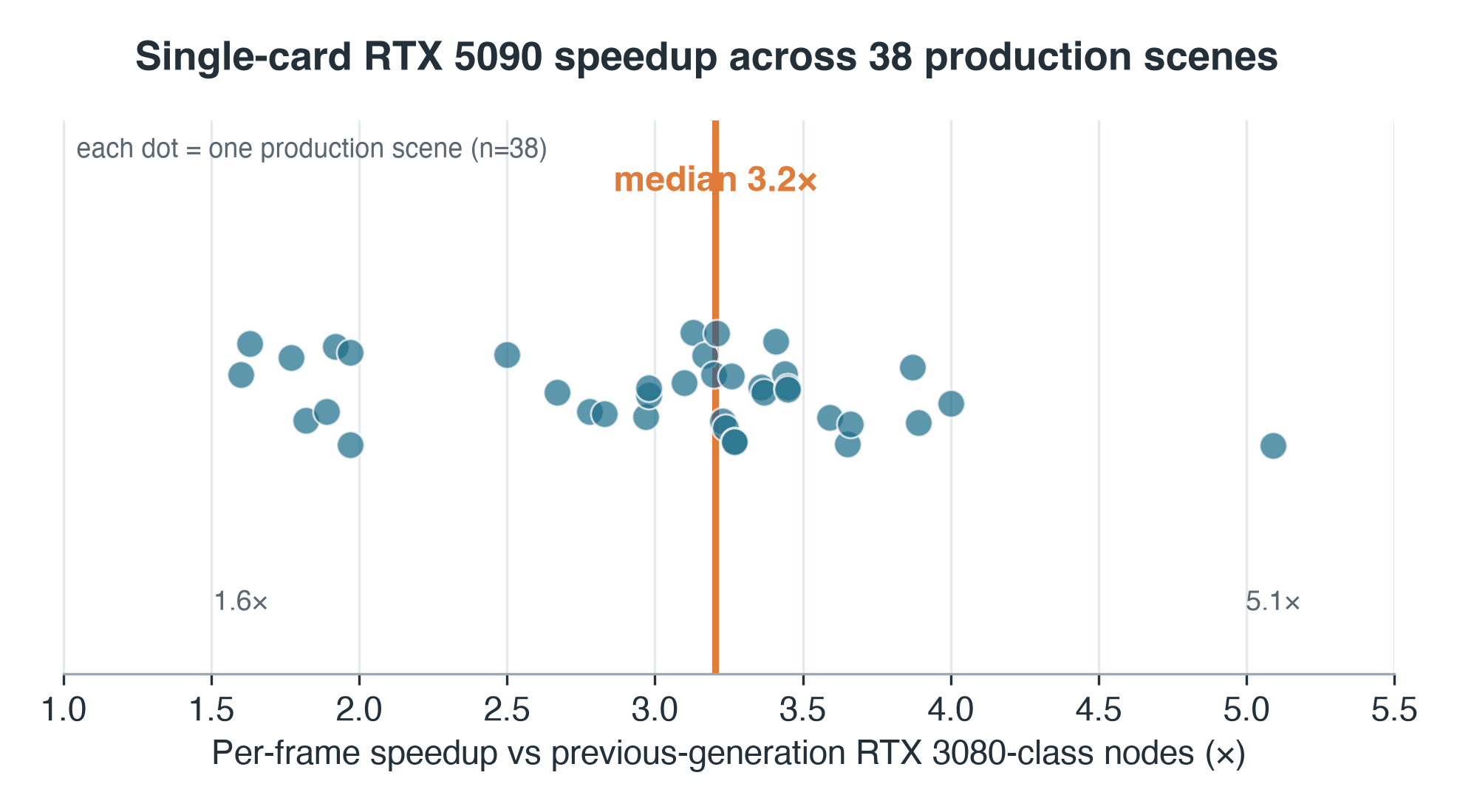
38本番Blender CyclesシーンにわたるRTX 5090の高速化(シーン単位)。中央値3.2倍、1.6倍〜5.1倍の分布
シーン単位の高速化(RTX 5090と旧世代ノードの比較)——38シーンの本番サンプル。中央値3.2倍;全範囲1.6〜5.1倍。
この数値には、脚注ではなく本文に記載すべき2つの注意事項があります。第一に、旧世代側は仮想化環境——VM内のGPUパススルー——で稼働していたため、この3.2倍の一部は測定されていない仮想化オーバーヘッドであり、シリコン本来の性能差ではありません。RTX 5090と現行のRTX 4090を同一ホスト上で比較するクリーンな検証は、まだ実施できていない次のステップです。第二に、38シーンはキューからランダムに抽出されたものではありません:あるユーザーがたまたま両世代で再レンダリングしたジョブであり、長時間かつ反復的な作業に偏っているため、サンプルはキュー全体ではなく、その対応ペアの分布として読んでください。
ここで3つの誠実な注記が重要です。これは観察データです——ユーザーは再レンダリング時に設定を調整することがあり、私たちはシーンを固定していませんでした。比較はノード対ノードです:RTX 5090側はベアメタルの1枚のカード、旧世代側は仮想マシン内のGPUパススルーで動作しているため、差の一部はセットアップの違いであり、シリコン性能差ではありません。そしてベースラインは、これらのジョブが実際に動作していたRTX 3080/2080クラスのカードです——現行のRTX 4090ではありません。クリーンな現行カードとの直接比較は、別途実施する必要のある制御された検証です。これらはシングルノード、Cyclesのみの数値であり、私たちのキューを表すものであって、他のエンジンやハードウェアに一般化すべきではありません。
1.6倍のシーンと5.1倍のシーンを分けるものは、データの一部から見えています。各シーンの高速化を旧ハードウェアでのフレーム処理時間に対してプロットすると、緩やかな正の傾向が現れます——Spearman ρ ≈ 0.34(両側p ≈ 0.04)。短くオーバーヘッド律速のフレームは下部に位置します:フレームが5秒で完了する場合、タスク単位の固定コスト——シーンロード、同期、旧仮想化レイヤー——が時間の大部分を占め、高速なカードが作用できる余地がほとんどありません。重くコンピュート律速のフレームほど高速化の恩恵が大きくなります。しかし実際の散らばりは大きく、あるヘビーなシーンが1.6倍にとどまったのは、そのボトルネックがGPUではなく、ストレージまたはCPU律速の段階にあったためと考えられます。中央値は一つのことを示し、レンジはシーンによって異なることを示しています。
AIデノイジングはすでにデフォルトだった
2026年の本番レンダリングパイプラインにAIが実際にどこに位置するかを問えば、私たちのログは華やかでない答えを返します:デノイザーの中です。RTX 5090ノードのCyclesジョブの約83%がAIデノイズパス——OptiXまたはIntel Open Image Denoise——を実行しており、旧世代ノードでの比率もほぼ同一です。新しいカードがこの習慣を始めたわけではありません。それは旧ハードウェアですでに標準であり、新しいハードウェアでも標準のままです。デノイズ主体のパイプラインにとって、世代交代は「すでにそこにあった」AIを購入することではありません——すでに日常的なステップとなっている処理の周囲に、パストレーシングのスループットを購入することです。この数値はCyclesに限定した意図的なものです。1つのエンジンに紐付けられていないファーム全体の「AI比率」については懐疑的に見てください。
実際のVRAM使用状況
Cyclesはレンダーログにピーク時のデバイスメモリの数値を書き込みます——これは本番環境がVRAMに実際に何を要求しているかを示す、謙虚ではありますが有用な指標です。そのラインが記録された57件のCyclesジョブにわたって、レンダーデバイスのピークメモリは中央値で約5.6 GB、90パーセンタイルで11.5 GBでした。旧世代のカードは10〜12 GBのものであるため、中央値のジョブは収まりますが、90パーセンタイルのジョブはすでにその上限に近づいていました。そして末尾はさらに延びています:最も重いジョブは約37 GBを記録し、RTX 5090自身の32 GBをも超えています——GPUにとってはCPUフォールバックかレンダー不可を意味するシーンの種類です。ログにはシーンのメタデータがないため、そのシーンの種類を特定することはできません——ただそのクラスはわかります:37 GBのワーキングセットは、重いジオメトリ、高解像度テクスチャセット、またはボリュメトリクスの特徴であり、32 GBのカードさえも使い切るジョブであり、シングルGPUでは単純に停止します。オペレーターの原則は変わりません:VRAMはテールに合わせてサイジングしてください、中央値ではなく。そのため、オンカードの大容量メモリと共有GPUクラウドレンダーファームの両方が存在するのです——ジョブごとに大容量カードを使えるようにし、1台を所有する必要がないようにするためです。
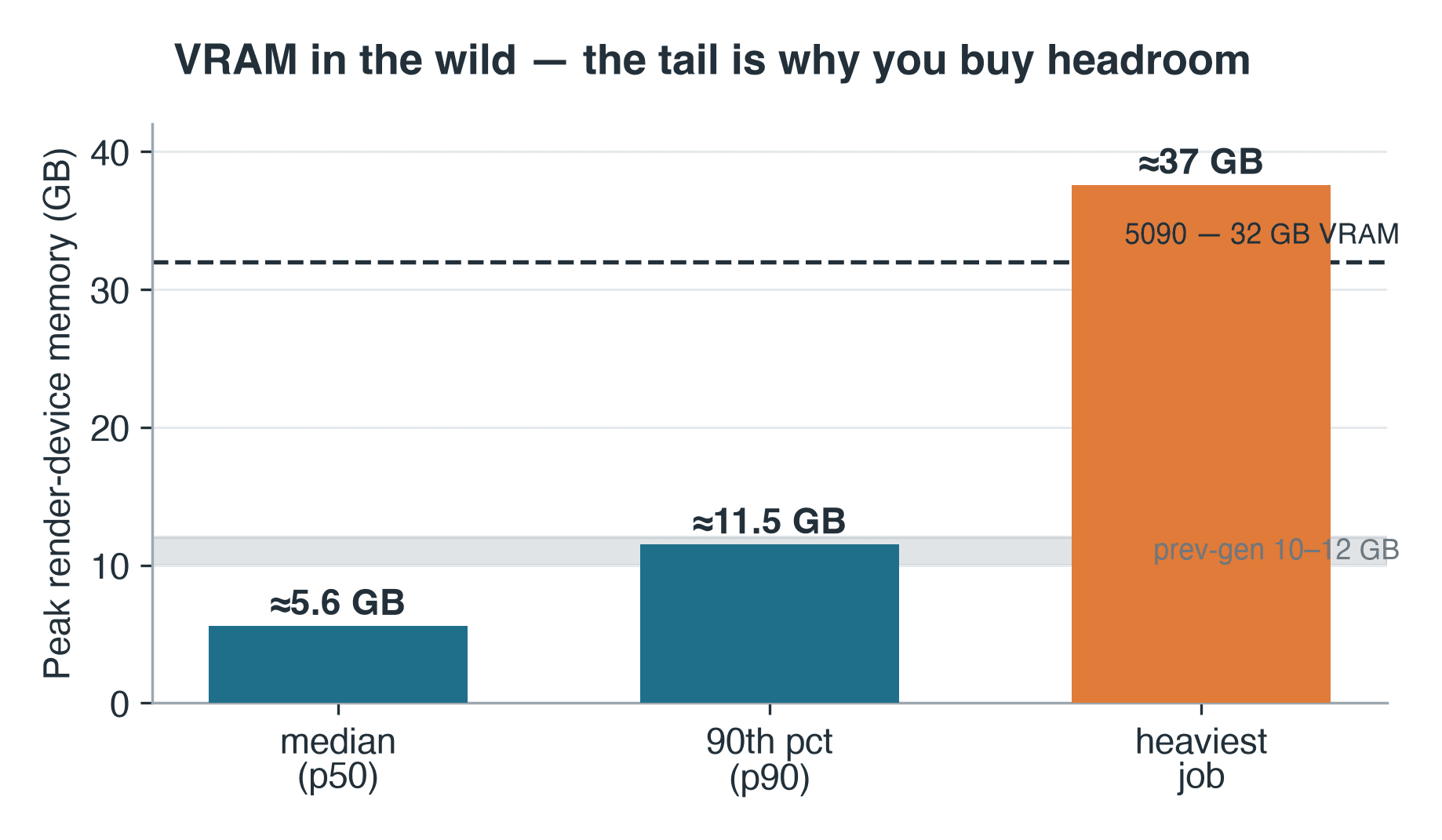
RTX 5090ノードのBlender Cyclesジョブにおけるレンダーデバイスのピークメモリ:中央値5.6 GB、90パーセンタイル11.5 GB、最大37 GB
57件のログ済みCyclesジョブにわたるレンダーデバイスのピークメモリ。最大ジョブはRTX 5090自身の32 GBを超えた。
1つのドライバー、制御された消費電力
最もドラマチックでない発見が、購入前に最も確認したいものかもしれません。1つのドライバー——CUDA 13.0上の581.80——が、51日間の全期間を変更ゼロで稼働しました:ロールバックなし、期間中の交換なし。本番キュー上の初期サイクルハードウェアにとって、退屈なドライバーログこそが最高の褒め言葉です。
消費電力も同様に安定していました。同じカードを持続負荷下で制御ベンチで稼働させたところ、各カードは約360〜375 W(ピーク近く400 W)を消費し、温度は68〜83 °Cでした——スタック配置の上部カードが最も熱くなりますが、定格クラスの約575 Wを大幅に下回ります。定格ピークではなく、その持続的な消費に合わせて予算を計画してください。完成フレームあたりのエネルギーは、約24秒のCycles中央値フレームで約2.5 Whとなります——ただしこれは推論であり、ベンチ測定値に基づいており、旧世代ノードとの比較なしにRTX 5090単体について計算されたものです。
これらのノートがBlenderを先頭に置く理由
直近90日間において、GPUジョブはファーム全体でレンダリングされたものの約4分の1を占め——残りはCPU作業です。そのGPUの中で、Cyclesはジョブの約74%を占め、Redshiftが明確な2位で約15%です。これが、レンダーファームのRTX 5090の記事がBlenderクラウドレンダリングから始まる理由です。これらのカードが複数台でどのように動作するかについては、RTX 5090クラスターパフォーマンスに関するコンパニオンノートをご覧ください。また、特にメモリの限界については、複雑なシーンでVRAMの限界が問題になる場所をご参照ください。
このキューから持ち帰れることが2つあります。第一に、本番環境はベンチマークではありません——クリーンなラボの数値を出すカードも、仮想化オーバーヘッド、混合ワークロード、最適化されたことのないシーンを吸収しなければならず、その結果は1点ではなく分布です。第二に、中央値はテールではありません。3.2倍の典型的な高速化と1ジョブで37 GBのメモリスパイクは、同時に真実であり、その両方に合わせてキャパシティを計画します。作業が重い場所では、このカードは本当に速いです。そうでない場所では、キューがその理由を教えてくれます。
方法論の概要
ここに掲載されているすべての数値は、ステージングテストではなく私たちのスケジューラー自身のタスクレコードから来ています。フレーム単位の時間はタスクの実時間をフレーム数で割ったもの。ヘッドラインの高速化は38の対応ペアにわたるシーン単位中央値の中央値であり、信頼区間は20,000サンプルのブートストラップです。どのサンプルがどのクレームを裏付けているかに注意してください:高速化については38組のシーン、VRAMについては57件のログ済みジョブ、そして消費電力と温度については本番キューではなく別途実施した制御ベンチです。失敗した18タスク(約4,900件中)は落としではなく失敗としてカウントされています。スケジューラーは状態を記録しますが原因は記録しないため、推測はせずそのままにしています。これらはいずれも精神的に再現困難なものではありません——あらゆるオペレーターが自身のキューログから引き出せるものであり、私たちはスタジオがこの方法論をより詳しく理解したい場合には喜んでご説明します。
FAQ
Q: Blender CyclesにおいてRTX 5090は旧世代より何倍速いですか? A: 38組の本番シーンのペア(両世代で同じシーン・同じユーザー)にわたって、フレーム単位の中央値時間は約69%短縮——中央値3.2倍の高速化で、ブートストラップ95%信頼区間は3.0〜3.3倍です。個別シーンは1.6倍〜5.1倍の範囲に及びます。これは観察データであり、ノード対ノードのフィールドデータであって、制御されたベンチマークではありません。
Q: シーン間でこれほど高速化の幅があるのはなぜですか? A: 高速化はフレーム単位のワークロードと緩やかな正の傾向を示します(Spearman ρ ≈ 0.34)。短くオーバーヘッド律速のフレームは最も恩恵が少なく、それはシーンロード、同期、旧仮想化レイヤーといったタスク単位の固定コストが支配的だからです。重くコンピュート律速のフレームほど高速化が大きくなります。あるヘビーなシーンが1.6倍にとどまったのは、そのボトルネックがGPUではなくストレージかCPU律速の段階にあったためです。
Q: これは自分のハードウェアと比較できる制御されたベンチマークですか? A: いいえ。これらは1台のライブ本番ノードからの観察フィールドノートであり、Blender Cyclesのみです。ユーザーは再レンダリング間に自分のシーンを調整しており、比較はノード対ノードです——ベアメタルのRTX 5090と仮想化された旧世代ノード——そのため差の一部はセットアップの違いであり、シリコン性能差ではありません。ベースラインは現行のRTX 4090ではなく、RTX 3080/2080クラスのハードウェアです。
Q: 本番シーンのVRAM使用量はどのくらいでしたか? A: 57件のログ済みCyclesジョブにわたって、レンダーデバイスのピークメモリは中央値で約5.6 GB、90パーセンタイルで11.5 GBでした。単一の最大ジョブは約37 GBを記録し——RTX 5090自身の32 GBを超えており——GPUではCPUフォールバックかレンダー不可を意味します。VRAMは中央値ではなくテールに合わせてサイジングしてください。
Q: RTX 5090はAIデノイジングの使用頻度を変えましたか? A: いいえ。RTX 5090ノードのCyclesジョブの約83%がAIデノイズパス(OptiXまたはIntel Open Image Denoise)を実行しており——その比率は旧世代とほぼ同一でした。AIデノイジングはすでに標準でした。新しいカードはその周囲すべての速度だけを変えました。
Q: 7週間のドライバーの安定性はどうでしたか? A: 1つのドライバー——CUDA 13.0上の581.80——が51日間の全期間を変更ゼロで稼働しました:ロールバックなし、期間中の交換なし。本番キュー上の初期サイクルハードウェアにとって、その安定性は単独で意味ある結果です。
Q: 負荷時の消費電力と温度はどうでしたか? A: 持続負荷下での制御ベンチで、各カードは約360〜375 W(ピーク近く400 W)を消費し、温度は68〜83 °Cでした——カードの定格クラスである約575 Wを大幅に下回ります。フレームあたりのエネルギーは約2.5 Whとなりますが、これはそのベンチ測定値からの推論であり、RTX 5090のみについて計算されたものです。
Q: これらの数値は他のレンダリングエンジンにも適用されますか? A: いいえ。この調査はBlender Cycles GPUのみ、シングルノードです。他のエンジンはデノイジング、メモリ、タイミングをそれぞれ異なる方法で記録します。これらはCycles固有のフィールドノートとして扱い、ファーム全体またはクロスエンジンのクレームとして解釈しないでください。
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



