Come distribuire una render farm GPU dedicata da 20 nodi oltre i confini nazionali (2026)
Panoramica
Introduzione
Quando un team creativo richiede una render farm dedicata che si estende su più paesi, di solito sta aggirando un vincolo che una render farm SaaS non è in grado di risolvere. Potrebbe trattarsi di uno studio che contrattualmente non può consentire a terze parti di detenere le proprie credenziali, di un team distribuito in cui gli artisti in un paese operano nodi in un altro, o di una casa di produzione il cui impegno plurimensile rende economicamente inadatta la fatturazione per frame.
Nella nostra esperienza, il problema difficile è raramente "noleggiare più GPU". È connettere i pezzi giusti: storage cloud di proprietà del cliente, una flotta GPU privata dimensionata per il carico di lavoro, un trasporto transfrontaliero cifrato che regga al jitter e un livello di desktop remoto che non collassi su un pesante viewport 3D. Quando un elemento è sbagliato, il cluster funziona, ma gli artisti se ne accorgono — e l'impegno si degrada silenziosamente.
Operiamo Super Renders Farm, una render farm cloud con una flotta CPU e GPU sostanziale, e installiamo anche cluster GPU dedicati per team i cui workflow non si adattano al nostro servizio gestito. Questo articolo è una guida operativa tratta da quei deployment — come architettiamo una render farm GPU dedicata da 20 nodi che serve un team creativo distribuito di artisti oltre i confini da un'unica struttura dedicata, con note oneste sulle scelte fatte, su quelle riviste e sulle lezioni che ora applichiamo per impostazione predefinita. Se si sta valutando l'infrastruttura dedicata rispetto al nostro noleggio di render farm gestita, questa guida aiuterà a decidere se il percorso dedicato vale la superficie architetturale che comporta.
Criteri decisionali: dedicato rispetto a SaaS
La maggior parte dei carichi di rendering non necessita di un cluster dedicato. Una render farm cloud gestita riceve una scena, pianifica i frame e fattura al minuto. Non c'è infrastruttura da possedere, nessun firewall da mantenere e nessun team operativo da assegnare sul lato cliente. Per il lavoro su base progetto — un cortometraggio, uno spot da 30 secondi, un batch di still — quel modello vince su ogni asse rilevante.
Un cluster dedicato si giustifica solo quando uno o più dei seguenti criteri sono verificati:
- Il controllo della proprietà intellettuale è contrattuale, non preferenziale. Il contratto principale di servizio del cliente o il contratto con il cliente finale vieta a terze parti di detenere file di scena o credenziali di render. Le pipeline SaaS che mediano l'upload della scena violano questo vincolo anche se la potenza di calcolo sottostante è identica.
- L'impegno dura mesi, non giorni. Il lavoro a forma fissa — una serie animata di lunga durata, una pipeline archviz pluritrimestrale, uno stage di produzione virtuale continuativo — ripaga il costo architetturale iniziale. La fatturazione per frame, al contrario, si moltiplica linearmente con la durata e cessa di essere competitiva oltre una certa prospettiva.
- Il workflow è sufficientemente personalizzato da rendere impossibile l'hosting su una pipeline gestita. Stack di plugin DCC personalizzati, render manager interni, pipeline ad alta simulazione che pre-generano su una cache condivisa, o catene di strumenti proprietari spingono tutti verso nodi dedicati che il cliente può configurare direttamente.
- Il bring-your-own-cloud è un requisito irrinunciabile. Quando gli asset del progetto del cliente risiedono in una piattaforma cloud file-streaming sotto il suo account, il cluster deve autenticarsi come il cliente, non come il provider dell'infrastruttura. Questo è il pattern "Modello B" discusso in dettaglio più avanti.
- Le esigenze di segmentazione di rete vanno oltre la VLAN per tenant. Alcuni workflow richiedono che il cluster sia invisibile alla rete più ampia del provider — non solo isolato logicamente, ma isolato anche per routing.
Se nessuno di questi criteri si applica, una render farm gestita è quasi sempre la scelta corretta. Se due o più si applicano, la conversazione si sposta verso il dedicato. La domanda residua è geografica: gli artisti che eseguono il lavoro si trovano vicino alla struttura, o il cluster deve servirli attraverso una dorsale ISP pubblica che attraversa confini nazionali?
Panoramica dell'architettura
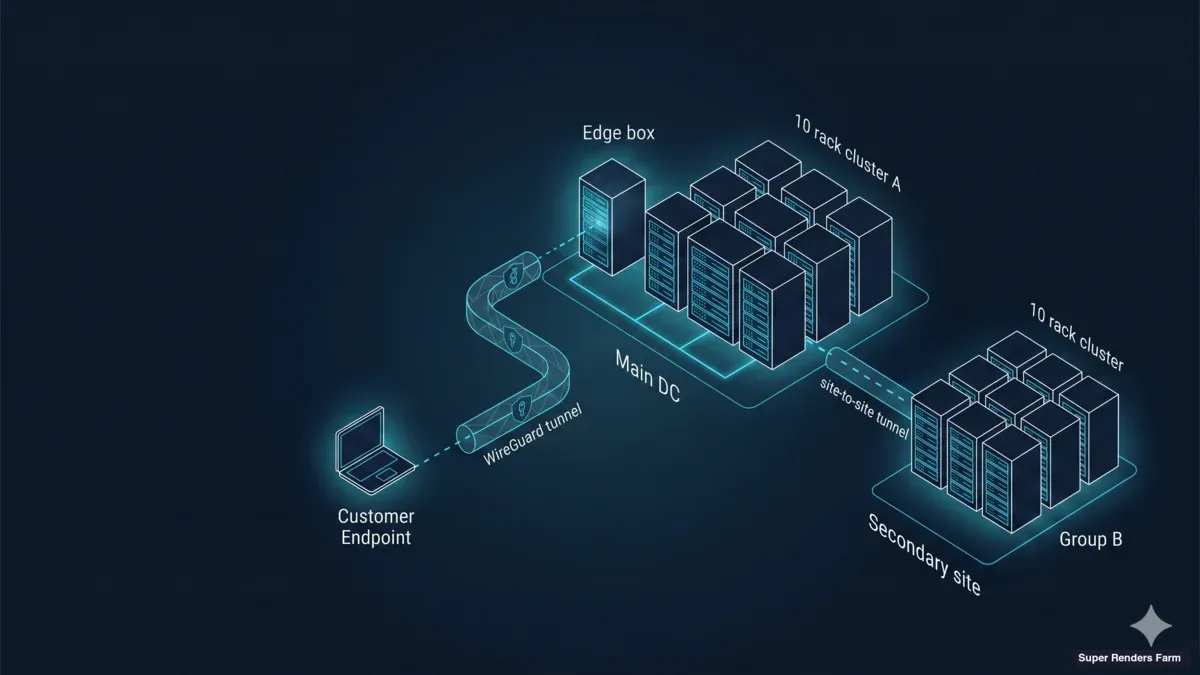
L'architettura che distribuiamo per cluster dedicati transfrontalieri ha tre piani: un piano di trasporto, un piano di calcolo e un piano di accelerazione dello storage. Ogni piano ha un'unica modalità di guasto che, nella nostra esperienza, rappresenta la maggior parte del dolore operativo quando si rompe.
[ Artisti remoti — distribuiti tra paesi ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, cifrato end-to-end,
│ trasporto BBR + MSS clamped)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — struttura cluster dedicata │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (singolo host Ubuntu) │ │
│ │ • WireGuard hub (NAT/MASQUERADE) │ │
│ │ • Cache Samba SMB3 (SSD singolo, ext4) │ │
│ │ • dnsmasq (zona .lan) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + TCP MSS clamp │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × nodi di rendering RTX 5090 │ │
│ │ (Windows 11 Pro, Sunshine, client cloud │ │
│ │ file-stream, mount cache — immagine │ │
│ │ uniforme su tutta la flotta) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ Piattaforma cloud file-streaming del cliente —
il cliente accede su ciascun nodo; Super Renders
Farm non detiene le credenziali (Modello B) ]
Il piano di trasporto è WireGuard, in un pattern hub-and-spoke. La workstation di ogni artista si connette all'hub presso la struttura del cluster tramite un tunnel UDP cifrato; tutto il traffico artista-cluster, indipendentemente dal paese in cui si trova l'artista, attraversa la stessa topologia di tunnel. Il piano di calcolo è composto da venti nodi Windows 11 Pro, ciascuno con una singola NVIDIA RTX 5090 da 32 GB di VRAM, distribuiti come un unico pool uniforme in un'unica struttura. Il piano di accelerazione dello storage è un singolo box edge-e-cache presso la struttura che ospita una condivisione Samba SMB3 supportata da un singolo SSD su ext4 — insieme ai servizi di rete da cui dipende il cluster (DNS, NTP, firewall).
Una decisione progettuale fondamentale: il box edge e il box cache sono la stessa macchina. Una versione precedente di questa architettura posizionava il gateway edge su un'appliance separata e la cache su un NAS, il che creava race condition durante i cold pull e due superfici da aggiornare. Il consolidamento su un singolo host Ubuntu 22.04 LTS ha eliminato entrambi i problemi. Il box diventa una risorsa critica — ma i dati del progetto del cliente risiedono ancora nella piattaforma cloud file-streaming, quindi la cache si riscalda dall'upstream dopo qualsiasi guasto locale.
Configurazione del cluster GPU da 20 nodi
Il dimensionamento predefinito per i deployment che stiamo descrivendo è di venti nodi RTX 5090, distribuiti come un unico pool uniforme all'interno di una struttura. Questa è la dimensione che si adatta costantemente a un team creativo nella fascia tra dieci e venti artisti — la fascia in cui i cluster dedicati risultano convenienti per i workflow IP-sensitive.
Ogni nodo ha la stessa configurazione hardware: una singola RTX 5090 da 32 GB di VRAM, una CPU multi-core moderna, 64 GB o 128 GB di RAM di sistema e un disco NVMe locale dimensionato solo per il sistema operativo e lo scratch. I dati del progetto persistenti risiedono sulla cache condivisa o nella piattaforma cloud file-streaming upstream, mai sul nodo stesso.
Il sistema operativo su ciascun nodo è Windows 11 Pro, distribuito da un'immagine pulita. Deliberatamente non pre-carichiamo stack di plugin DCC sull'immagine del nodo. Il cliente gestisce l'installazione dei propri strumenti DCC — Cinema 4D, Redshift, Houdini, After Effects, Blender e altri — in modo che l'immagine del nodo rimanga minimale e riproducibile. Al termine dell'impegno, eseguiamo il wipe e il reimage dallo stesso baseline pulito.
Abbiamo scelto deliberatamente 32 GB di VRAM per nodo. I renderer GPU moderni — Redshift, Octane, Arnold GPU, Cycles — caricano sempre più spesso scene con texture di grandi dimensioni che semplicemente non entrano in schede da 24 GB. RTX 5090 a 32 GB è attualmente il punto ottimale per i renderer di produzione; gestisce la maggior parte del lavoro di archviz, motion design e animazione senza paginare nella RAM di sistema, ed è lì che i pool GPU eterogenei diventano silenziosamente lenti.
I venti nodi sono configurati in modo identico — stessa immagine, stesso set di installazione DCC, stesso mount della cache, stesso routing WireGuard — e si presentano come un unico pool al render manager del cliente. Deadline, Royal Render o lo scheduler del cliente tratta la flotta come una singola risorsa senza alcun routing per gruppo o logica di ribilanciamento manuale. I frame vengono assegnati a qualsiasi nodo libero; il render manager del cliente gestisce la distribuzione del carico a livello di job queue.
La flotta è instradabile a livello 3 — il cliente installa il proprio render manager e invia lavori da una workstation remota piuttosto che operare su ciascun nodo tramite desktop remoto. Questo è più importante di quanto si pensi: è la differenza tra un cluster con cui gli artisti lottano e uno che dimenticano.
Credenziali di proprietà del cliente (Modello B)
La singola decisione architetturale che più spesso rende un cluster dedicato la risposta giusta per i workflow IP-sensitive è quello che chiamiamo Modello B: credenziali di proprietà del cliente. Nel Modello A — il predefinito per le render farm gestite, incluso il nostro servizio SaaS — il provider dell'infrastruttura detiene le credenziali per la pipeline di rendering. Il cliente carica i file di scena; la pipeline del provider media il render. Questo funziona per la stragrande maggioranza dei carichi di lavoro ed è il modello alla base di quasi ogni render farm cloud commerciale.
Nel Modello B, il provider dell'infrastruttura fornisce hardware, sistema operativo, rete e livello cache, ma non detiene mai il materiale di autenticazione del cliente per la piattaforma cloud file-streaming o per i dati sorgente del progetto. Il cliente accede alla piattaforma cloud su ciascun nodo, esattamente come se fosse seduto alla propria workstation. I file di progetto vengono trasmessi dal cloud del cliente. I render vengono scritti nuovamente sul cloud del cliente. Il ruolo del provider è limitato al livello hardware-e-pipeline.
Questo è rilevante per tre motivi:
- Contrattuale: Quando il cliente downstream del cliente ha un NDA o un contratto principale di servizio che limita dove le credenziali e i file sorgente possono essere detenuti, il Modello B mantiene il provider fuori dall'ambito di tali restrizioni. Il cliente non ha bisogno di negoziare l'inserimento del provider di rendering in una catena contrattuale che non era progettata per includerlo.
- Audit: Quando il cliente deve dimostrare a un revisore di sicurezza che la propria pipeline di rendering non espone le credenziali a terze parti, il Modello B fornisce una risposta netta. Il provider può produrre documentazione hardware, di rete e operativa; il cliente produce la catena delle credenziali.
- Chiusura di fine impegno: Poiché il provider non ha mai detenuto le credenziali, la chiusura di fine impegno è più semplice. Il cliente revoca le proprie sessioni cloud; il provider cancella la cache, esegue il reimage dei nodi e fornisce un'attestazione scritta che la cache e le immagini dei nodi sono state distrutte. Non c'è alcun passaggio di rotazione delle credenziali da certificare per il provider perché nessuna credenziale è mai stata detenuta.
Il Modello B non è adatto a tutti. Mette il team operativo del cliente nell'obbligo di gestire il ciclo di vita delle credenziali su ogni nodo — venti rotazioni da coordinare se i segreti ruotano mensilmente. I team che hanno già questa pratica operativa trovano il compromesso accettabile. I team che non ce l'hanno tendono a restare sul rendering gestito Modello A.
Integrazione con cloud file-streaming
Nelle configurazioni che stiamo discutendo, gli asset del progetto del cliente risiedono in una piattaforma cloud file-streaming — un servizio che espone il loro albero di progetto su cloud come filesystem virtuale su ciascun nodo. L'artista monta il progetto; il nodo legge i file su richiesta; la piattaforma gestisce lo storage di backing, il versioning e la replica cross-region.
Ci integriamo con una piattaforma cloud file-streaming generica a scelta del cliente. La piattaforma vede un evento di accesso da ciascun nodo tramite l'account del cliente; il client della piattaforma in esecuzione sul nodo monta l'albero del progetto in un percorso noto; l'applicazione DCC del cliente apre i file da quel percorso esattamente come farebbe su una workstation locale. La piattaforma cloud non ha bisogno di sapere che il nodo fa parte di un cluster di rendering.
Ciò che cambia quando questo viene collegato a un cluster da 20 nodi è il pattern di accesso. Un singolo artista su una singola workstation richiama un file di progetto alla volta, su richiesta, mentre lavora. Venti nodi di rendering che aprono la stessa scena contemporaneamente per un intervallo di frame creano un burst sincronizzato di letture cloud per gli stessi asset. Senza una cache, ogni nodo richiama ogni texture, ogni simulazione cached, ogni file di dipendenza, in parallelo — il che è sia dispendioso di larghezza di banda internazionale sia lento al primo frame di ogni intervallo.
Ecco perché esiste la cache condivisa. Ne parliamo in dettaglio nella sezione successiva, ma l'integrazione con il cloud file-streaming è il motivo per cui deve esistere. I pull di asset dal cloud vengono concentrati attraverso il box cache una sola volta, poi distribuiti a tutti i venti nodi tramite LAN. La piattaforma cloud non vede mai venti richieste simultanee della stessa texture — ne vede una, più letture SMB warm all'interno della nostra rete.
L'altro dettaglio pratico è il write-back. Quando un frame di rendering è completato, il nodo scrive l'output sulla piattaforma cloud file-streaming — attraverso l'account del cliente. Il team del cliente nell'ufficio remoto vede i frame apparire nell'albero del progetto in tempo reale. Non c'è alcun passaggio di upload manuale, nessun trasferimento mediato dal provider; la piattaforma cloud gestisce il percorso di andata e ritorno.
Architettura della cache condivisa
La cache condivisa è una delle due o tre scelte architetturali che, se sbagliate, corroderanno silenziosamente il valore di un cluster. Le abbiamo sbagliate nei deployment precedenti. Il pattern che ha resistito nel corso di più build è deliberatamente conservativo.
Un singolo box edge-e-cache esegue Ubuntu 22.04 LTS, con un singolo SSD SATA da 8 TB formattato come ext4 ed esposto al cluster tramite Samba SMB3. Il mount della cache appare su ogni nodo di rendering in un percorso fisso (ad esempio \\cache.lan\proj). Quando un nodo apre un file di progetto tramite il client cloud file-streaming, il file viene trasmesso attraverso la cache locale; le letture successive dello stesso file su qualsiasi nodo colpiscono direttamente l'SSD tramite LAN.
Ci sono tre scelte deliberate in quel paragrafo.
Prima, una singola cache, non cache per nodo. Una versione precedente di questa architettura memorizzava il materiale della cache per nodo. Con venti nodi 5090, ciò significava fino a 200 TB di storage ridondante da gestire e venti stati di cache separati da debuggare quando qualcosa divergeva. Il consolidamento su un'unica cache condivisa riduce l'impronta di storage di un fattore venti e rende lo stato della cache un singolo artefatto che il team operativo può ispezionare.
Seconda, un singolo SSD su ext4, non RAID 10 con LUKS su XFS. Il piano precedente prevedeva che la cache risiedesse su un array RAID 10 con cifratura LUKS a riposo su XFS. Quel piano era sovra-ingegnerizzato per l'hardware effettivo su cui distribuiamo — un SSD, un filesystem, un mount. Abbiamo rimosso il livello RAID, rimosso LUKS e usato ext4 perché la cache non è la fonte di verità per i dati del progetto. Il cloud del cliente è la fonte di verità. Se il disco della cache si guasta, lo sostituiamo e ri-scaldiamo dall'upstream; non abbiamo bisogno di ridondanza al livello cache perché abbiamo ridondanza al livello cloud. (La cifratura a riposo era al di fuori dello scope di questo contratto, ma è disponibile come impegno separato quando un cliente downstream la richiede.)
Terza, pre-riscaldare la cache prima del primo giorno di rendering. Questa è la lezione che abbiamo imparato a caro prezzo. Il giorno D, ogni cache miss è la lettura più costosa nel cluster — attraversa il link internazionale, richiama dal cloud del cliente e scrive sull'SSD locale prima che il renderer possa consumarla. Il pre-riscaldamento, che è un walk strutturato attraverso l'albero degli asset del progetto il giorno prima dell'inizio della produzione, converte le letture del giorno D da cold cloud pull a letture SMB warm. Ora pianifichiamo una finestra di pre-riscaldamento in ogni impegno di cluster dedicato.
All'interno della struttura, ogni nodo monta la cache allo stesso percorso fisso (\\cache.lan\proj) tramite SMB3 sulla LAN locale. Poiché il traffico intra-struttura non attraversa il tunnel WireGuard, l'MSS clamping non si applica qui e il link funziona a velocità Gigabit Ethernet end-to-end. Il percorso di mount della cache è identico su ogni nodo, il che semplifica la configurazione del render manager del cliente — lo stesso percorso del file di scena si risolve allo stesso modo su ogni membro del pool.
Ottimizzazione della rete transfrontaliera
Il livello di trasporto è quello in cui un cluster transfrontaliero si percepisce fluido o rotto. I comportamenti predefiniti di TCP/IP, IP-fragmentation e DNS-over-VPN sono sottilmente sbagliati per i tunnel cifrati a lunga distanza che trasportano SMB e desktop remoto. Il tuning del kernel e della configurazione di rete non è opzionale; è la differenza tra un cluster funzionante e uno che misteriosamente scarta pacchetti di grandi dimensioni.
WireGuard, hub-and-spoke. Ogni artista si connette dalla propria workstation tramite un client WireGuard all'hub presso la struttura del cluster. Tutto il traffico tra l'artista e il cluster è cifrato end-to-end. Usiamo deliberatamente una sola tecnologia VPN anziché combinare protocolli; mescolare IPSec per un ruolo e una VPN diversa per un altro aggiunge superficie operativa senza migliorare la sicurezza.
TCP BBR. Il controllo di congestione predefinito di Linux (CUBIC) è stato progettato per link a bassa latenza con perdita di pacchetti ridotta. I link ISP pubblici a lunga distanza che trasportano traffico cifrato sono molto diversi — latenza moderata, jitter occasionale e pattern di perdita asimmetrici. BBR produce costantemente throughput più utilizzabile su questi link rispetto a CUBIC, specialmente quando il link è condiviso con altro traffico internet del cliente. Usiamo il BBR stock del kernel (BBR v1); BBRv3 più recente non è stato distribuito in questa build, e la versione stock è stata stabile per noi.
TCP MSS clamping. Questa è la singola causa più comune di reclami del tipo "il cluster funziona per lo più, tranne per i file di grandi dimensioni". Quando il traffico attraversa un tunnel che riduce l'MTU effettivo, i pacchetti grandi vengono frammentati (lento) o scartati silenziosamente (peggio). I pacchetti piccoli e i ping funzionano bene, il che rende il problema difficile da diagnosticare. La soluzione è fare il clamp del TCP MSS sul router WireGuard in modo che TCP negozi una dimensione di pacchetto che entra nel tunnel. Dopo aver applicato questo, gli handshake TLS, le sessioni RDP e le letture di file di grandi dimensioni SMB smettono di bloccarsi.
dnsmasq con l'interfaccia VPN elencata. Un gotcha sottile: dnsmasq deve elencare esplicitamente l'interfaccia WireGuard (ad esempio wg0) nella sua configurazione, anche se il client interroga un indirizzo .lan privato. Senza di esso, le ricerche DNS attraverso il tunnel scadono, ma il ping funziona ancora perché il ping non passa per il DNS. Questo produce alcune delle sessioni di diagnosi più confuse che abbiamo gestito, perché ogni altro test sembra sano.
chrony per NTP. La sincronizzazione dell'orologio sembra banale ma è importante per i render manager (Deadline assegna timestamp ai job), per la correlazione dei log attraverso il cluster e per qualsiasi token di autenticazione con una componente temporale. chrony gestisce la deriva dell'orologio attraverso un link ad alta latenza meglio del vecchio ntpd; lo eseguiamo sul box edge e facciamo sincronizzare ciascun nodo con esso.
L'effetto combinato di queste scelte è un tunnel che si comporta come una LAN per la maggior parte dei carichi di lavoro e si degrada in modo controllato quando il percorso pubblico è insolitamente congestionato. La sezione successiva illustra come appare il lavoro 3D che gira su quel tunnel nella pratica.
Moonlight e Sunshine per il desktop remoto
Il desktop remoto è il livello che gli artisti sperimentano più direttamente. Se il livello di desktop remoto sembra lento o traballante, non importa quanto sia veloce il renderer — le mani dell'artista sono lente e l'impegno si degrada.
Usiamo Moonlight (client) e Sunshine (host su ciascun nodo) per il desktop remoto. La combinazione utilizza l'encoder hardware NVENC di NVIDIA sull'RTX 5090 per codificare il frame buffer in tempo reale, poi lo trasmette alla workstation dell'artista. Poiché la codifica avviene sulla GPU già presente nel nodo, non c'è contesa con il renderer e la latenza aggiunta dal desktop remoto è dominata dal round trip di rete — non dalla fase di codifica.
Per il lavoro sul viewport 3D, questo è rilevante in un modo che non lo è per il desktop remoto tradizionale. I protocolli più vecchi — RDP, VNC, il desktop remoto Microsoft standard — erano progettati per carichi di lavoro da ufficio. Gestiscono bene testo, finestre di dialogo e finestre a variazione lenta, ma collassano su un viewport 3D a schermo intero durante un'anteprima di turntable. Moonlight + Sunshine trattano il frame buffer come video, che è esattamente il modello giusto per il lavoro 3D.
Abbiamo un test di verifica della qualità che eseguiamo prima di consegnare un nodo a un artista — informalmente "Test 8" — che esegue una sequenza definita di operazioni sul viewport sotto carico e conferma che l'esperienza di desktop remoto soddisfa un baseline. Se un nodo non supera il test, eseguiamo il debug della pipeline di codifica o togliamo il nodo dalla rotazione fino a quando non risolviamo il problema. Eseguiamo questo test all'inizio di ogni impegno e dopo qualsiasi reimage del nodo.
Parsec è una valida alternativa quando Sunshine ha un problema specifico dell'host. Abbiamo distribuito un numero ridotto di nodi su Parsec quando Sunshine non poteva essere configurato in modo affidabile; l'esperienza dell'artista è simile. Non la standardizziamo perché il modello basato su account e coordinamento cloud non si adatta alla gestione delle credenziali Modello B in modo altrettanto pulito rispetto a Sunshine self-hosted.
Abbiamo considerato altre opzioni di desktop remoto nella pianificazione iniziale e le abbiamo abbandonate — strumenti generici di desktop remoto senza codifica GPU, e un'alternativa open source che non ha superato il nostro quality gate su un viewport 3D a schermo intero. Il principio che conta: per i nodi del cluster GPU, lo streaming con codifica hardware è l'unico modello che regge su scala.
Pianificazione della capacità e slice riservata
La configurazione da 20 nodi in questa guida è una slice dedicata riservata della flotta più ampia di Super Renders Farm, ritagliata per la durata dell'impegno. Riservata significa che i nodi non sono condivisi con il pool del servizio gestito, non sono co-schedulati con altri tenant e non sono soggetti a fatturazione per frame — il cliente paga per la slice come spesa operativa fissa e ha il controllo esclusivo di quei nodi dal kickoff al teardown.
Dimensionare la slice a venti nodi è una scelta deliberata. Al di sotto di dieci nodi, un cluster non giustifica la superficie architetturale rispetto a una render farm gestita — il percorso SaaS è più semplice e meno oneroso. Al di sopra di trenta, il livello cache deve essere re-architettato (più box cache, cache regionali) e il modello operativo cambia forma. Venti è la fascia in cui un singolo box edge-e-cache, un singolo hub WireGuard e un'immagine Windows uniforme reggono in modo pulito — e in cui un team creativo da dieci a venti artisti ha abbastanza nodi per mantenere i frame in flusso durante i picchi senza tempo inattivo durante il regime stazionario.
Poiché Super Renders Farm opera una flotta sostanziale al di là di questa slice dedicata, esiste margine per lo scale-up quando l'impegno lo richiede. Aggiungere nodi riservati aggiuntivi all'interno della stessa struttura è una modifica alla configurazione, non un ciclo di approvvigionamento. I clienti che eseguono impegni plurimensili tipicamente bloccano la dimensione della slice al kickoff e ri-definiscono lo scope ai confini di trimestre in base alla domanda effettiva rispetto al piano originale.
Segmentazione della rete
La segmentazione della rete in un cluster come questo non è opzionale. Il cliente opera sull'infrastruttura del provider, ma il cliente non deve mai poter vedere la rete più ampia del provider — né il NAS del provider, né le interfacce di amministrazione del router del provider, né altri tenant. Allo stesso modo, i sistemi interni del provider non devono mai essere esposti ai carichi di lavoro del cliente.
Implementiamo la segmentazione in due livelli.
Livello 1 — firewall edge. Il box edge-e-cache esegue ufw (uncomplicated firewall) in una postura default-deny in entrata. Solo la porta UDP WireGuard (51820) è esposta a internet pubblico. SSH, SMB, DNS, NTP e qualsiasi altro servizio in esecuzione sull'edge sono legati alle interfacce interne e inaccessibili dall'esterno del cluster. Le regole di inoltro permettono i pacchetti tra l'interfaccia WireGuard e la LAN del cluster, ma non tra nessuno dei due e le altre reti interne del provider. La postura predefinita di inoltro è scartare a meno che non sia esplicitamente permesso.
Livello 2 — host firewall su ciascun nodo. Ogni nodo di rendering ha la propria configurazione del firewall Windows che rispecchia la postura edge — accetta in entrata dagli IP del cluster per i servizi di cui il cluster ha bisogno (SMB, desktop remoto, render manager) e scarta tutto il resto. Questo non è ridondante; è difesa in profondità. Se un nodo è mal configurato o compromesso, l'host firewall rimane una barriera.
Il principio alla base di entrambi i livelli è il privilegio minimo: il cliente e i nodi devono vedere solo il gruppo di nodi e nient'altro. Non forniamo al cliente percorsi di routing verso la rete interna del provider. Il tunnel del cliente termina al box edge; il box edge instrada solo verso la LAN del cluster; la LAN del cluster instrada solo tra i membri del cluster.
In pratica, il cliente non può eseguire ping o scan dei sistemi del provider anche se lo volesse. Nessun piano di gestione condiviso, nessun percorso di monitoraggio condiviso che esponga altri tenant.
Lezioni apprese
Queste sono cinque lezioni operative che, su ogni cluster dedicato che abbiamo installato, hanno risparmiato ore di debug o — quando ci siamo dimenticati di applicarle — ci sono costate ore di debug.
1. Trappola del routing dual-home del gateway. Quando il box edge ha due interfacce di rete (una pubblica, una LAN), l'ordine delle operazioni è importante. Il route LAN deve essere configurato prima che il route predefinito venga modificato. Se si cambia prima il route predefinito e poi si tenta di aggiungere il route LAN, la sessione SSH usata per il login può cadere nel momento in cui il route predefinito cambia, e si può restare fuori dalla macchina. La soluzione è procedurale, non tecnica: configurare sempre prima i route interni, validarli, e solo allora toccare il route predefinito.
2. WireGuard e DNS. dnsmasq deve elencare esplicitamente ogni interfaccia su cui deve ascoltare, inclusa l'interfaccia WireGuard. Se si elenca solo l'interfaccia LAN, le ricerche DNS dai client VPN scadono — ma le risposte ping funzionano ancora, perché il ping non passa per il DNS. Questa è una delle modalità di guasto diagnosticamente più fuorvianti che abbiamo incontrato. La soluzione è una riga nella configurazione di dnsmasq, ma bisogna sapere dove cercarla.
3. Il TCP MSS clamping non è opzionale attraverso un tunnel. Gli handshake TLS, le sessioni RDP, le letture di file di grandi dimensioni SMB — qualsiasi cosa voglia inviare pacchetti di grandi dimensioni — verrà scartata silenziosamente se l'MSS non è clamped. Il primo sintomo è solitamente "Moonlight funziona per dieci secondi, poi si blocca" o "SMB elenca le directory ma non riesce a leggere file di dimensioni superiori a 1 MB". La soluzione è una regola iptables sull'host WireGuard. Applicarla prima della consegna del cluster.
4. Dimensionare correttamente lo storage, non sovra-ingegnerizzarlo. La versione precedente di questa architettura specificava RAID 10 con cifratura LUKS su XFS. L'hardware di cache che abbiamo distribuito era un singolo SSD. Abbiamo rimosso il livello RAID, rimosso il livello LUKS e usato ext4 — perché la cache non è la fonte di verità, la piattaforma cloud lo è. Scambiare la ridondanza cartacea al livello cache per la ridondanza effettiva al livello cloud è stata la scelta corretta. La lezione è progettare lo storage intorno a ciò che i dati richiedono effettivamente, non intorno a ciò che sembra sicuro in un documento di pianificazione.
5. Pre-riscaldare la cache. Il giorno D, ogni cache miss costa il link internazionale e la piattaforma cloud un round trip. La prima ora di produzione su una cache fredda sembra lenta anche quando tutto il resto è configurato correttamente. Ora pianifichiamo una finestra di pre-riscaldamento in ogni impegno — solitamente uno o due giorni prima dell'inizio della produzione. L'artista non vede il pre-riscaldamento; vede un cluster che sembra già veloce al primo frame.
Queste sono lezioni operative, non architetturali. Vivono nella checklist di deployment, non nel documento di architettura. Ma separano un cluster che funziona in teoria da uno che regge sotto un vero carico di produzione. I pattern più piccoli vengono applicati su base per-impegno — i cinque precedenti sono quelli che sono comparsi in ogni deployment.
Conclusione
Una render farm GPU cross-country dedicata da 20 nodi è l'architettura giusta quando il controllo della proprietà intellettuale è contrattuale, l'impegno è plurimensile, il workflow richiede configurazione personalizzata e l'autenticazione bring-your-own-cloud è irrinunciabile. Al di fuori di queste condizioni, una render farm gestita è quasi sempre la risposta migliore — la complessità architetturale qui non si giustifica per il lavoro su base progetto o per team privi di una funzione operativa dedicata.
Quando le condizioni si applicano, i pattern illustrati qui — credenziali Modello B, cache condivisa su ext4, trasporto WireGuard hub-and-spoke, BBR con MSS clamping, Moonlight + Sunshine per desktop remoto, firewalling a due livelli — sono quelli che distribuiamo per impostazione predefinita. Non sono gli unici pattern validi, ma sono quelli che hanno resistito nel corso di più deployment.
Il team dietro Super Renders Farm opera sia il noleggio di render farm gestita sia i deployment di cluster dedicati — incluse le configurazioni di cluster GPU dedicato e le topologie cross-country descritte in questa guida.
FAQ
Q: Quanto tempo richiede un tipico deployment di cluster dedicato da 20 nodi? A: A seconda dello scope, della disponibilità dell'hardware presso la struttura e della configurazione del cloud file-streaming del cliente, un tipico impegno richiede alcune settimane di lead time per il provisioning hardware e di rete, più una finestra di pre-riscaldamento di uno o due giorni prima dell'inizio della produzione. Dimensioniamo la tempistica in base al calendario di produzione del cliente, non in base a un template fisso.
Q: E se il team fosse distribuito su tre continenti? A: La topologia WireGuard hub-and-spoke si scala ad ulteriori posizioni cliente senza modificare l'architettura del cluster. Ogni artista remoto esegue un client WireGuard e si connette allo stesso hub presso la struttura del cluster. La latenza da ciascuna regione è determinata dal percorso internet pubblico tra quella regione e l'hub; nella nostra esperienza BBR e MSS clamping fanno la differenza tra utilizzabile e non utilizzabile su quei percorsi.
Q: È possibile vedere il cluster prima di impegnarsi in un contratto plurimensile? A: Tipicamente organizziamo una finestra di proof-of-concept durante la conversazione di scoping. La forma esatta dipende dal progetto del cliente — a volte è una sessione di desktop remoto su un singolo nodo per testare l'esperienza dell'artista, a volte è un test di rendering su piccola scala per validare la cache e l'integrazione cloud file-streaming. I termini specifici sono una questione commerciale; si prega di contattare il nostro team di vendita per discutere di cosa funzionerebbe per la sua tempistica.
Q: Come viene gestita la sicurezza dei dati al termine dell'impegno? A: Poiché il Modello B mantiene le credenziali del cliente fuori dalle nostre mani, la chiusura di fine impegno si concentra sulla pulizia hardware e della cache. Cancelliamo la cache SMB, eseguiamo il reimage di ogni nodo dal baseline pulito e forniamo un'attestazione scritta che la cache e le immagini dei nodi sono state distrutte. Il cliente revoca le proprie sessioni cloud file-streaming, che sono al di fuori del nostro sistema. Il linguaggio contrattuale specifico (NDA, SLA, formulazione della lettera di attestazione) è gestito dal nostro team di vendita.
Q: E se fossero necessari più di 20 nodi? A: La configurazione da 20 nodi è la forma più comune che distribuiamo, ma l'architettura si scala oltre. Le flotte più grandi vengono aggiunte all'interno della stessa struttura — nodi riservati aggiuntivi confluiscono nello stesso hub WireGuard, nella stessa cache SMB3 e nella stessa immagine Windows uniforme. Il limite pratico è solitamente la larghezza di banda della cache: un singolo box edge-e-cache ha un soffitto di lettura SMB finito, e a dimensioni di flotta molto grandi l'architettura della cache stessa deve essere ripensata (più box cache, cache regionali). Discutiamo queste scelte progettuali su base per-impegno.
Q: È possibile portare la propria licenza per Cinema 4D, Redshift o altri strumenti DCC? A: Il modello di licenza — bring-your-own-license rispetto a licenza fornita dal provider — è una decisione commerciale che dipende dallo specifico DCC e dall'inventario di licenze esistente del cliente. Alcune configurazioni funzionano in modo pulito con le licenze del cliente; altre sono più semplici con quelle fornite dal provider. Risolviamo questo durante la conversazione di scoping. Contattare il nostro team di vendita per i dettagli.
Q: Come viene gestito il cloud storage di provider europei rispetto a quelli statunitensi? A: La piattaforma cloud file-streaming è a scelta del cliente. Il nostro cluster si integra con qualsiasi piattaforma in grado di eseguire un client di accesso su Windows ed esporre l'albero del progetto del cliente come filesystem montato. La posizione geografica del cloud upstream influisce sulla latenza internazionale del percorso cliente-cluster — motivo per cui raccomandiamo il trasporto WireGuard hub-and-spoke e la configurazione ottimizzata con BBR per le configurazioni cross-country. Non ospitiamo la piattaforma cloud stessa; rimane sotto l'account del cliente.
Q: Cosa succede se il tunnel WireGuard cade? A: WireGuard ristabilisce automaticamente la sessione quando la rete sottostante si riprende; la sessione di desktop remoto del cliente potrebbe interrompersi brevemente durante il re-handshake. Se il tunnel cade mentre un rendering è in corso, il rendering stesso continua a girare sul nodo (non dipende dal tunnel per il lavoro in corso), ma il write-back al cloud si metterà in coda fino al ripristino del tunnel. Monitoriamo lo stato del tunnel dal box edge e inviamo alert in caso di downtime prolungato.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



