
RTX 5090 in der Produktion: 7 Wochen Felddaten einer render farm (38-Szenen-Studie)
Überblick
Launch-Benchmarks für die RTX 5090 sind über ein Jahr alt, und sie alle beschreiben dasselbe: eine Karte, eine inszenierte Szene, ideale Bedingungen. Was fast niemand veröffentlicht, ist das Sequel – was die Karte tut, sobald sie in einer Produktionswarteschlange steckt und Szenen anderer Nutzer nach einem Zeitplan rendert, den sie nicht kontrolliert. Also haben wir die Protokolle ausgewertet. Was folgt, sind die Felddaten auf Warteschlangen-Ebene: dieselben Produktionsdaten, nach denen wir Kapazitäten planen, als nachprüfbare Zahlen aufbereitet.
Das sind sieben Wochen davon. Vom 1. April bis 22. Mai 2026 – 51 Tage – betrieben wir einen Dual-RTX-5090-Node in unserer Live-render-farm und ließen ihn alles verarbeiten, was die Warteschlange ihm schickte. Keine inszenierten Tests, keine handverlesenen Frames. Das kurze Video unten zeigt die Eckdaten; die vollständigen Felddaten folgen.
Der Node selbst ist unspektakulär: zwei RTX 5090, 128 GiB RAM, 32 logische Kerne mit 4,3 GHz, Windows 11. Ein Detail prägt jede Zahl – der Scheduler führt pro GPU genau eine Render-Aufgabe aus, sodass jede Karte ihren eigenen Renderjob übernimmt und jede Zahl eine saubere Zahl pro Karte ist, der Multiplikator, mit dem man Kapazitäten plant. Über den Beobachtungszeitraum schloss der Node 99,6% seiner Aufgaben ab – 4,890 von rund 4,900 abgeschlossen, 18 fehlgeschlagen. Der Scheduler protokolliert den Fehler, nicht die Ursache, daher verzichten wir auf Spekulationen.
Eckdaten
- Zeitraum: 1. April – 22. Mai 2026 (51 Tage, ~7 Wochen), ein Dual-RTX-5090-Node
- Abschlussrate: 99,6% – 4,890 von ~4,900 Aufgaben abgeschlossen, 18 fehlgeschlagen (Ursache nicht protokolliert)
- Speedup: median 3.2x pro Frame in Blender Cycles gegenüber Nodes der Vorgängergeneration RTX 3080/2080 (mediane Frame-Zeit um ~69% gesunken); 95% CI 3.0-3.3x
- Streuung: IQR 2.7-3.4x, gesamte Spanne 1.6x-5.1x über 38 gepaarte Szenen – ein einziger Multiplikator beschreibt keine Warteschlange
- KI-Denoising: ~83% der Cycles-Jobs liefen mit einem KI-Denoising-Durchgang – dieselbe Rate wie auf der alten Hardware
- VRAM: Median 5.6 GB, 90. Perzentil 11.5 GB, schwerster Job ~37 GB
- Treiber: ein einziger Treiber (581.80 / CUDA 13.0) über den gesamten Zeitraum, null Wechsel
- Leistung: ~360-375 W/Karte unter Last (kontrollierter Benchmark), Spitze ~400 W, bei 68-83 °C – weit unter der ~575 W Nennklasse
Was 38 gepaarte Szenen zeigen
Der Vergleich, dem wir am meisten vertrauen, ist kein synthetischer Test, sondern die Jobs, die im normalen Geschäftsbetrieb auf beiden Generationen liefen – dieselbe Szene, derselbe Nutzer, mindestens drei Aufgaben pro Seite, bevor eine Szene gewertet wurde. Die Frame-Zeit pro Auftrag ist die Wanduhrzeit der Aufgabe geteilt durch die Frame-Anzahl, direkt aus der Warteschlange. Aus dem Beobachtungszeitraum erfüllten 38 Szenen diese Bedingung, gewonnen aus 1,419 einzelnen Render-Aufgaben (503 auf dem 5090-Node, 916 auf der Vorgängergeneration). 38 ist nicht die Größe unserer Datenbasis; es ist das, was einen bewusst strengen Filter übersteht.
| Metrik | Wert |
|---|---|
| Medianer Speedup pro Frame | 3.2x (≈ 69% Zeitersparnis) |
| Bootstrap-95%-CI (Median) | 3.0-3.3x |
| Interquartilsabstand | 2.7-3.4x |
| Gesamtspanne | 1.6-5.1x |
| Szenen / Aufgaben | 38 Szenen / 1,419 Aufgaben |
| Baseline | Vorgängergeneration RTX 3080/2080-Klasse (10-12 GB) |
Wir verwenden einen Median der Mediane: Jede Szene trägt den Median ihrer eigenen Frame-Zeiten auf jeder Seite bei, und der 3.2x-Wert ist der Median dieser 38 Verhältnisse – so kann ein einzelner langsamer Frame das Ergebnis nicht verzerren. Die Streuung ist ebenso wichtig wie der Mittelpunkt: Die mittlere Hälfte der Szenen liegt zwischen 2.7x und 3.4x, die gesamte Spanne reicht von 1.6x bis 5.1x.
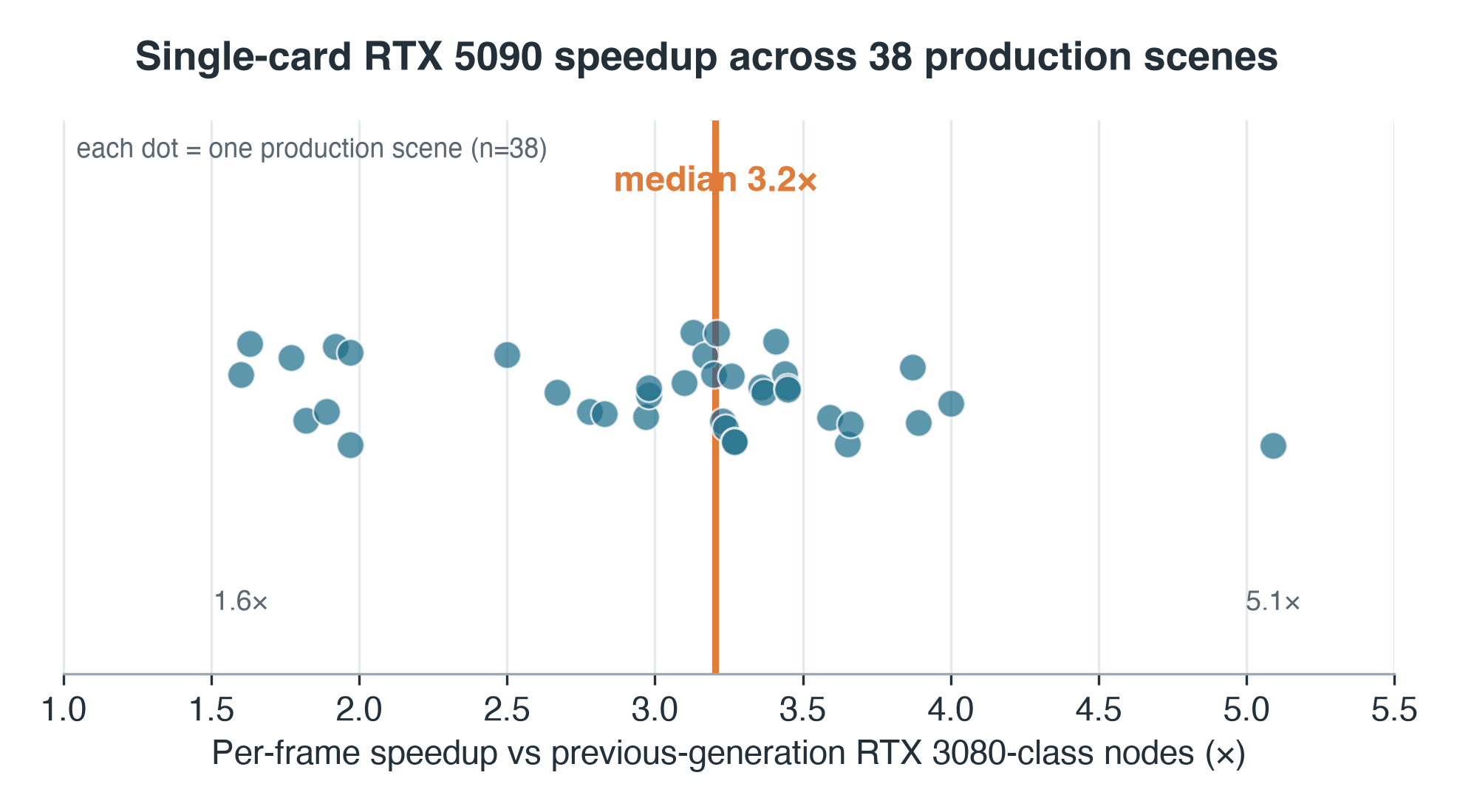
Pro-Szenen-RTX-5090-Speedup über 38 Blender-Cycles-Produktionsszenen, Median 3.2x mit einer Spanne von 1.6 bis 5.1x
Pro-Szenen-Speedup, RTX 5090 vs. die Nodes der Vorgängergeneration, auf denen diese Jobs liefen – 38-Szenen-Produktionsstichprobe. Median 3.2x; Spanne 1.6-5.1x.
Zwei Vorbehalte gehören zu dieser Zahl, nicht in eine Fußnote. Erstens lief die Vorgängergeneration virtualisiert – GPU-Passthrough in einer VM –, sodass ein nicht messbarer Anteil dieses 3.2x-Wertes Virtualisierungs-Overhead darstellt und kein roher Silizium-Unterschied ist; der saubere Vergleich auf demselben Host, RTX 5090 gegen eine aktuelle RTX 4090, ist der kontrollierte Folgetest, den wir schulden und noch nicht durchgeführt haben. Zweitens sind die 38 Szenen kein zufälliger Zug aus der Warteschlange: Es sind die Jobs, die ein Nutzer zufällig auf beiden Generationen neu gerendert hat – das verzerrt die Stichprobe hin zu längeren, iterativen Arbeiten. Lesen Sie die Verteilung daher als die der gematchten Paare, nicht der gesamten Warteschlange.
Drei Ehrlichkeitshinweise sind hier grundlegend. Es handelt sich um beobachtende Daten – Nutzer passen mitunter Einstellungen zwischen erneuten Rendervorgängen an, und wir haben ihre Szenen nicht eingefroren. Der Vergleich ist Node-zu-Node: Die 5090-Seite ist eine Bare-Metal-Karte, die Vorgängergeneration läuft als GPU-Passthrough in virtuellen Maschinen – ein Teil des Abstands ist also die Konfiguration, nicht das Silizium. Und die Baseline sind die RTX-3080/2080-Klasse-Karten, auf denen diese Jobs tatsächlich liefen – nicht eine aktuelle RTX 4090; ein sauberer aktueller Direktvergleich ist eine separate, kontrollierte Übung, die wir noch nicht durchgeführt haben. Dies sind Zahlen eines einzelnen Nodes, ausschließlich für Cycles; sie beschreiben unsere Warteschlange und sollten nicht auf andere Render-Engines oder Hardware verallgemeinert werden.
Was eine 1.6x-Szene von einer 5.1x-Szene unterscheidet, ist in den Daten teilweise sichtbar. Trägt man den Speedup jeder Szene gegen die Frame-Dauer auf der alten Hardware auf, zeigt sich ein loser positiver Trend – Spearman ρ ≈ 0.34 (zweiseitig p ≈ 0,04). Kurze, Overhead-gebundene Frames liegen unten: Wenn ein Frame in fünf Sekunden fertig ist, frisst der feste Aufwand pro Aufgabe – Szenenladung, Synchronisation, die alte Virtualisierungsschicht – den Großteil der Zeit, und eine schnellere Karte hat wenig Spielraum. Schwerere, Rechenleistungs-gebundene Frames profitieren stärker. Dennoch gibt es echte Streuung: Eine schwere Szene blieb bei nur 1.6x, weil ihr Flaschenhals nicht die GPU war, sondern wahrscheinlich Speicher oder eine CPU-gebundene Phase. Der Median sagt eines; die Spanne sagt: Es hängt von der Szene ab.
KI-Denoising war bereits Standard
Fragt man, wo KI in einer Produktions-Rendering-Pipeline im Jahr 2026 tatsächlich steckt, geben unsere Protokolle eine unspektakuläre Antwort: im Denoiser. Rund 83% der Cycles-Jobs auf dem 5090-Node liefen mit einem KI-Denoising-Durchgang – OptiX oder Intel Open Image Denoise – und die Rate auf unseren Vorgänger-Nodes ist praktisch identisch. Die neue Karte hat diese Praxis nicht eingeführt; sie war auf der alten Hardware bereits Standard und ist es auf der neuen geblieben. Für eine Denoising-intensive Pipeline kauft ein Generationssprung keine „KI", die ohnehin schon da war – er kauft Path-Tracing-Durchsatz um einen bereits routinemäßigen Schritt herum. Diese Zahl bezieht sich bewusst nur auf Cycles; seien Sie skeptisch gegenüber einem farm-weiten „KI-%-Wert", der nicht an eine bestimmte Render-Engine gebunden ist.
VRAM im Produktionsbetrieb
Cycles schreibt den Peak-Gerätespeicherwert in das Render-Protokoll – ein bescheidener, aber brauchbarer Anhaltspunkt für das, was die Produktion tatsächlich vom VRAM verlangt. Über die 57 Cycles-Jobs, bei denen diese Zeile aufgezeichnet wurde, lag der maximale Render-Gerätespeicher beim Median bei etwa 5.6 GB und beim 90. Perzentil bei 11.5 GB. Unsere Vorgänger-Karten sind 10-12-GB-Teile, sodass der Median-Job gepasst hätte – aber der Job am 90. Perzentil streifte bereits ihre Obergrenze. Und der Tail reicht weiter: Der schwerste Job protokollierte rund 37 GB – selbst über den eigenen 32 GB der 5090 – die Art von Szene, die auf einer GPU einen CPU-Fallback bedeutet oder gar kein Rendering. Das Protokoll enthält keine Szenen-Metadaten, daher können wir nicht sagen, um welche Art von Szene es sich handelte – nur ihre Klasse: Ein 37-GB-Working-Set ist das Merkmal von schwerem Geometrie-Volumen, hochauflösenden Textur-Sets oder Volumetrics, die Art von Job, der selbst eine 32-GB-Karte überwältigt und auf einer einzelnen GPU schlicht stoppt. Die Betreiber-Regel gilt weiterhin: Sie bemessen den VRAM nach dem Tail, nicht nach dem Median. Deshalb gibt es sowohl üppig dimensionierten On-Card-Speicher als auch geteilte GPU-Cloud-render-farm-Kapazität – damit Sie bei Bedarf auf eine größere Karte pro Job zurückgreifen können, anstatt sich eine kaufen zu müssen.
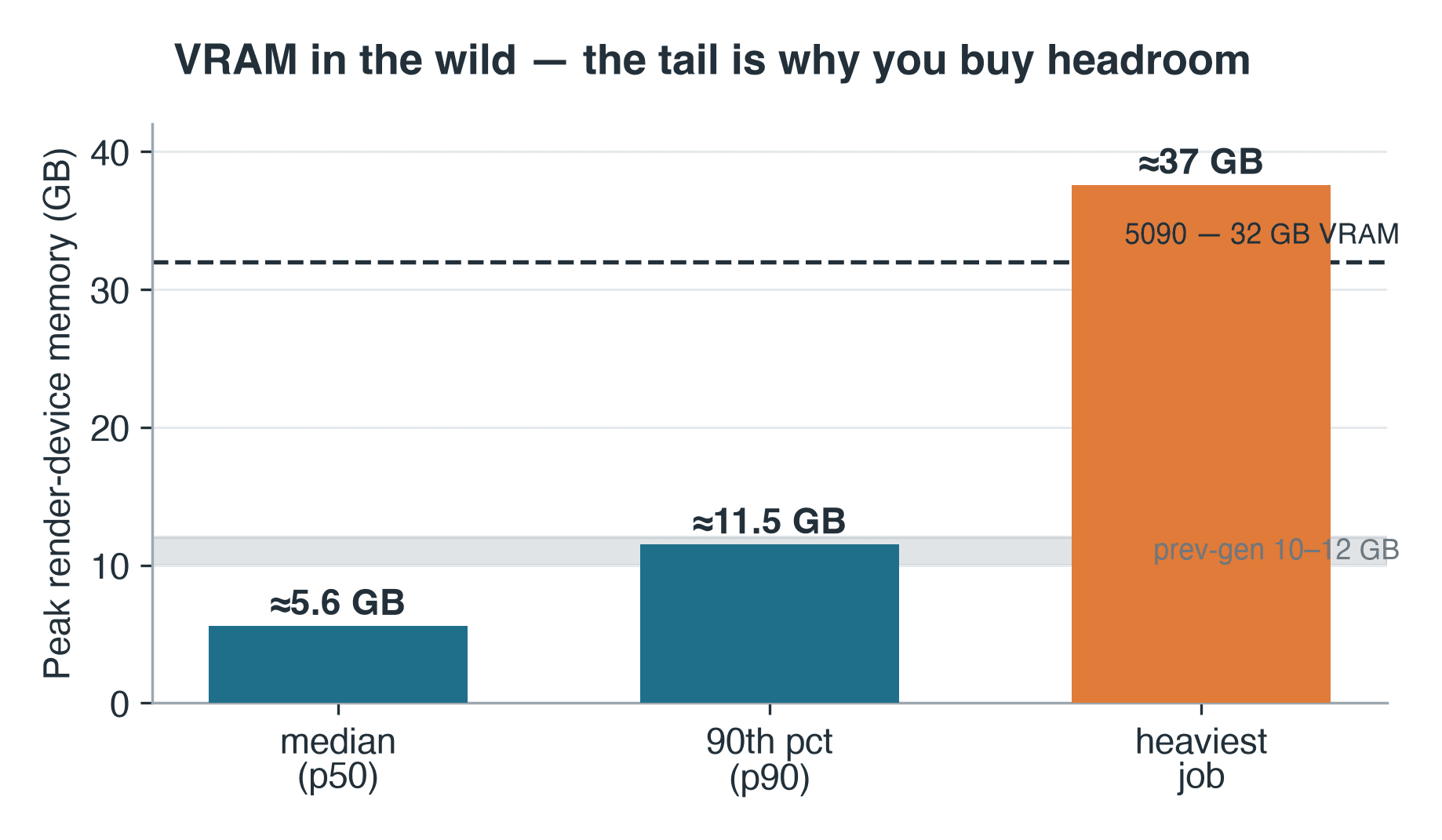
Peak-Render-Gerätespeicher für Blender-Cycles-Jobs auf dem RTX-5090-Node: Median 5.6 GB, 90. Perzentil 11.5 GB, schwerster Job 37 GB
Peak-Render-Gerätespeicher über 57 protokollierte Cycles-Jobs. Der schwerste Job überstieg sogar die eigenen 32 GB der 5090.
Ein einziger Treiber und geregelte Leistungsaufnahme
Der unspektakulärste Befund ist derjenige, den man vor einem Kauf am liebsten hätte. Ein einziger Treiber – 581.80 auf CUDA 13.0 – lief den gesamten Zeitraum mit null Wechseln: keine Rollbacks, keine zwischenzeitlichen Tausche. Für Hardware der ersten Produktionsgeneration in einer Produktionswarteschlange ist ein langweiliges Treiberprotokoll das größte Kompliment.
Die Leistungsaufnahme war ähnlich unaufgeregt. In einem kontrollierten Benchmark-Betrieb derselben Karten unter Dauerlast zog jede Karte etwa 360-375 W (Spitze nahe 400 W) bei 68-83 °C – die obere Karte in einem gestapelten Paar lief am heißesten, aber weit unter der ~575-W-Nennklasse. Kalkulieren Sie mit der Dauerlast, nicht mit dem Nennwert. Der Energieverbrauch pro fertigem Frame ergibt bei einer medianen Cycles-Frame-Dauer von rund 24 Sekunden ungefähr 2.5 Wh – behandeln Sie das jedoch als Schätzwert: Er basiert auf dem Benchmark-Verbrauch und wurde nur für die 5090 berechnet, nicht gegen die älteren Nodes gemessen.
Warum diese Felddaten mit Blender beginnen
In den zurückliegenden 90 Tagen machten GPU-Jobs etwa ein Viertel aller Rendervorgänge in unserer render farm aus – der Rest ist CPU-Arbeit. Innerhalb des GPU-Mixes ist Cycles mit rund 74% der Jobs vertreten, Redshift als klarer Zweiter mit rund 15% – deshalb beginnt ein RTX-5090-Bericht einer render farm mit Blender Cloud Rendering. Wie sich mehrere dieser Karten gemeinsam verhalten, lesen Sie in unseren Begleit-Notizen zur RTX-5090-Cluster-Performance, und speziell zur Speichergrenze, wo VRAM-Limits bei komplexen Szenen greifen.
Aus dieser Warteschlange lassen sich zwei Erkenntnisse ableiten. Erstens: Produktion ist kein Benchmark – eine Karte, die im Labor eine saubere Zahl liefert, muss in der Praxis Virtualisierungs-Overhead, gemischte Workloads und Szenen absorbieren, für die sie nicht optimiert wurde, und das Ergebnis ist eine Verteilung, kein Punktwert. Zweitens: Der Median ist nicht der Tail. Ein typischer Speedup von 3.2x und eine 37-GB-Speicherspitze bei einem einzelnen Job sind gleichzeitig wahr, und die Kapazitätsplanung berücksichtigt beides. Die Karte ist dort wirklich schnell, wo die Arbeit schwer ist. Wo das nicht der Fall ist, erklärt die Warteschlange warum.
Methode, kurz zusammengefasst
Jede Zahl hier stammt aus den eigenen Aufgabenprotokollen unseres Schedulers, nicht aus einem inszenierten Test. Die Frame-Zeit pro Auftrag ist die Wanduhrzeit der Aufgabe geteilt durch die Frame-Anzahl; der Haupt-Speedup ist ein Median der Pro-Szenen-Mediane über 38 gematchte Paare, und das Konfidenzintervall ist ein Bootstrap mit 20.000 Stichproben. Beachten Sie, welche Stichprobe welche Aussage stützt: 38 gepaarte Szenen für den Speedup, 57 protokollierte Jobs für VRAM und ein separater kontrollierter Benchmark für Leistung und Thermik – nicht die Produktionswarteschlange. Die 18 fehlgeschlagenen Aufgaben (von rund 4,900) werden als Fehler gezählt, nicht verworfen; der Scheduler protokolliert den Zustand, nicht die Ursache – wir lassen sie daher uninvestigiert, anstatt zu spekulieren. Dies ist im Grundsatz leicht zu reproduzieren – es ist das, was jeder Betreiber aus seinen eigenen Warteschlangenprotokollen ziehen kann, und wir erläutern die Methodik gerne ausführlicher gegenüber einem Studio.
FAQ
Q: Wie viel schneller ist die RTX 5090 gegenüber der Vorgängergeneration für Blender Cycles? A: Über 38 gepaarte Produktionsszenen (dieselbe Szene und derselbe Nutzer auf beiden Generationen) sank die mediane Frame-Zeit um rund 69% – ein medianer Speedup von 3.2x mit einem Bootstrap-95%-Konfidenzintervall von 3.0-3.3x. Einzelne Szenen lagen zwischen 1.6x und 5.1x. Es handelt sich um beobachtende Node-zu-Node-Daten, keinen kontrollierten Benchmark.
Q: Warum variieren die Speedups zwischen den Szenen so stark? A: Der Speedup folgt dem Frame-Workload als losen positiven Trend (Spearman ρ ≈ 0.34). Kurze, Overhead-gebundene Frames profitieren am wenigsten, weil der feste Aufwand pro Aufgabe – Szenenladung, Synchronisation, die alte Virtualisierungsschicht – dominiert; schwerere, Rechenleistungs-gebundene Frames gewinnen mehr. Eine schwere Szene blieb bei 1.6x, weil ihr Flaschenhals Speicher oder eine CPU-gebundene Phase war, nicht die GPU.
Q: Ist das ein kontrollierter Benchmark, den ich mit meiner eigenen Hardware vergleichen kann? A: Nein. Dies sind beobachtende Felddaten eines einzigen Live-Produktions-Nodes, ausschließlich für Blender Cycles. Nutzer haben ihre Szenen zwischen erneuten Rendervorgängen angepasst, und der Vergleich ist Node-zu-Node – eine Bare-Metal-5090 gegen virtualisierte Vorgänger-Nodes –, sodass ein Teil des Abstands auf die Konfiguration zurückgeht, nicht auf das Silizium. Die Baseline sind RTX-3080/2080-Klasse-Hardware, keine aktuelle RTX 4090.
Q: Wie viel VRAM haben Produktionsszenen tatsächlich belegt? A: Über 57 protokollierte Cycles-Jobs lag der maximale Render-Gerätespeicher beim Median bei etwa 5.6 GB und beim 90. Perzentil bei 11.5 GB. Der schwerste einzelne Job protokollierte rund 37 GB – über den eigenen 32 GB der 5090 –, was auf einer GPU einen CPU-Fallback oder gar kein Rendering bedeutet. Bemessen Sie den VRAM nach dem Tail, nicht nach dem Median.
Q: Hat die RTX 5090 verändert, wie oft KI-Denoising eingesetzt wurde? A: Nein. Rund 83% der Cycles-Jobs auf dem 5090-Node liefen mit einem KI-Denoising-Durchgang (OptiX oder Intel Open Image Denoise) – und die Rate war auf der Vorgängergeneration praktisch identisch. KI-Denoising war bereits Standard; die neue Karte hat nur die Geschwindigkeit von allem drumherum verändert.
Q: Wie stabil war der Treiber während der sieben Wochen? A: Ein einziger Treiber – 581.80 auf CUDA 13.0 – lief den gesamten 51-tägigen Zeitraum mit null Wechseln: keine Rollbacks, keine zwischenzeitlichen Tausche. Für Hardware der ersten Produktionsgeneration in einer Produktionswarteschlange ist diese Stabilität für sich genommen ein aussagekräftiges Ergebnis.
Q: Wie hoch war die Leistungsaufnahme und Temperatur unter Last? A: In einem kontrollierten Benchmark unter Dauerlast zog jede Karte etwa 360-375 W, Spitze nahe 400 W, bei 68-83 °C – komfortabel unter der ~575-W-Nennklasse der Karte. Der Energieverbrauch pro Frame ergibt rund 2.5 Wh – eine Schätzung aus dieser Benchmark-Messung, nur für die 5090 berechnet.
Q: Gelten diese Zahlen für andere Render-Engines? A: Nein. Diese Studie bezieht sich ausschließlich auf Blender Cycles GPU, an einem einzelnen Node. Andere Render-Engines protokollieren Denoising, Speicher und Timing unterschiedlich. Betrachten Sie diese Daten als Cycles-spezifische Felddaten, nicht als farm-weite oder Render-Engine-übergreifende Aussage.
About Richard Ta
Richard Ta is co-founder and technical lead of Super Renders Farm (superrendersfarm.com), a fully managed cloud render farm that supports Maya, 3ds Max, Cinema 4D, Blender, and Houdini across the major render engines. He has spent over a decade building and running large-scale CPU and GPU render infrastructure for studios in more than 50 countries.



