
Como Funcionam as Render Farms: Guia Técnico para Artistas 3D
Visão geral
Introdução
As render farms existem porque as estações de trabalho individuais atingem limites rígidos. Uma animação de 500 frames a 20 minutos por frame demora quase uma semana numa única máquina. Distribua esses frames por 100 máquinas e o mesmo trabalho fica concluído em menos de duas horas. A matemática é simples — a engenharia por detrás não é.
Operamos uma render farm com mais de 20.000 núcleos CPU e uma frota dedicada de GPU com placas NVIDIA RTX 5090. Todos os dias, processamos centenas de trabalhos em V-Ray, Corona, Arnold, Redshift, Cycles e outros motores. Este guia explica o que realmente acontece entre o momento em que carrega um ficheiro de cena e o momento em que descarrega os frames finalizados — os sistemas de filas, a distribuição de ficheiros, o tratamento de erros e as decisões de infraestrutura que tornam a renderização distribuída fiável em escala.
Se o conceito de render farm é novo, o nosso guia sobre o que é uma render farm cobre os fundamentos. Este artigo aprofunda os mecanismos técnicos.
O Que Acontece Quando Submete um Trabalho de Renderização
O processo de submissão envolve mais passos do que a maioria dos artistas imagina. Eis a sequência, desde a estação de trabalho até ao primeiro pixel renderizado.
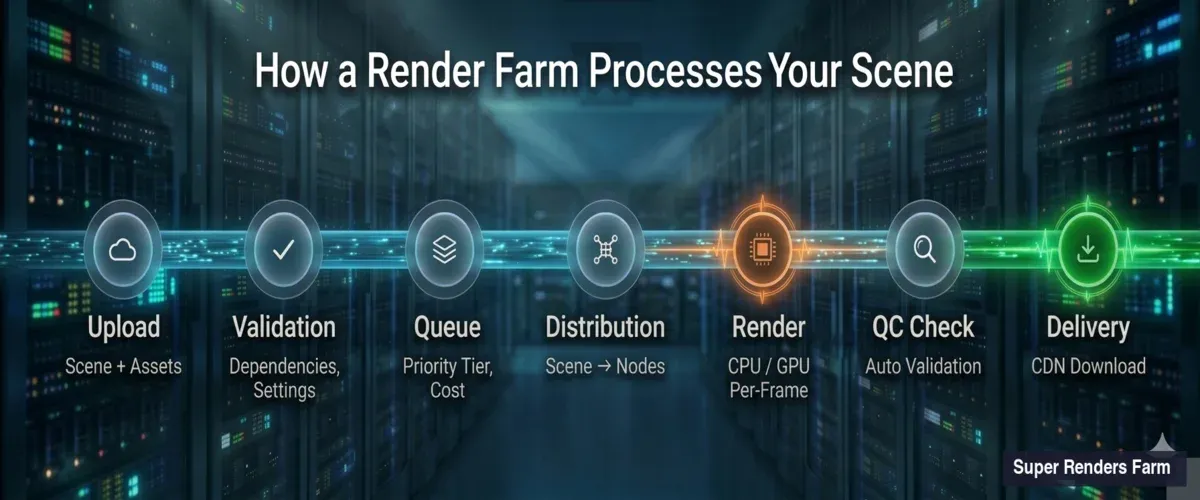
Pipeline de uma render farm mostrando 7 etapas: desde o upload da cena, passando pela validação, fila, distribuição, renderização, verificação de qualidade, até à entrega final
Upload e análise da cena. Quando submete um ficheiro .max, .blend, .ma ou outro ficheiro de cena, o sistema de ingestão da farm descompacta-o e cataloga todas as dependências — texturas, caches, meshes proxy, mapas HDRI, assets de plugins. Dependências em falta são a causa mais comum de renderizações falhadas. O nosso sistema sinaliza ficheiros em falta antes de o trabalho entrar na fila, para que possa corrigir caminhos em vez de desperdiçar tempo de renderização com frames pretos.
Validação das definições de renderização. A farm lê as definições de renderização incorporadas: tipo de motor, versão, resolução, intervalo de frames, formato de saída, parâmetros de amostragem. Cruza estes dados com as configurações de nós disponíveis. Se especificou V-Ray 7 mas a cena foi guardada no formato V-Ray 6, o sistema deteta esta incompatibilidade antes de a renderização começar.
Estimativa de custos. Com base na complexidade da cena, resolução, contagem de amostras e dados históricos de trabalhos semelhantes, o sistema gera uma estimativa de tempo e custo. Não se trata de adivinhação — processámos trabalhos suficientes para construir modelos estatísticos que preveem o tempo de renderização com uma margem razoável para a maioria das cenas padrão.
Filas de Trabalho e Sistemas de Prioridade
Após a validação, o trabalho entra numa fila. A forma como as render farms gerem esta fila determina se recebe os frames em duas horas ou doze.
Níveis de prioridade. A maioria das farms oferece múltiplos níveis de prioridade. Trabalhos de prioridade mais alta obtêm acesso a mais nós simultaneamente e podem interromper trabalhos de prioridade inferior. Na nossa farm, a diferença entre prioridade standard e alta é significativa — um trabalho de 200 frames pode renderizar em 20 nós com prioridade standard versus 80 nós com prioridade alta.
Agendamento justo. O gestor de filas equilibra recursos entre todos os utilizadores ativos. Nenhum trabalho monopoliza toda a farm, mesmo com prioridade alta. Se a farm tem 400 nós CPU disponíveis e três trabalhos de prioridade alta estão a correr simultaneamente, o agendador distribui nós proporcionalmente com base no tamanho do trabalho, tempo estimado de conclusão e nível do utilizador.
Preempção e reagendamento. Quando um trabalho de prioridade alta chega e a farm está na capacidade máxima, o agendador pode pausar frames de trabalhos de prioridade inferior e reatribuir esses nós. Os frames pausados reentram na fila automaticamente — nenhum trabalho se perde, embora os trabalhos de prioridade inferior demorem mais a concluir.
Deteção de nós inativos. Se um nó de renderização deixa de responder (falha de hardware, crash de driver, timeout de rede), o gestor de filas deteta o silêncio em segundos e reatribui os frames em curso desse nó a nós saudáveis. Isto acontece de forma transparente — nunca se vê a falha no resultado final.
Distribuição de Cenas: Como os Ficheiros Chegam aos Nós de Renderização
Antes de um nó poder renderizar o frame 47 da animação, precisa da cena completa — geometria, texturas, caches e configuração. Mover estes dados de forma eficiente é um desafio central de infraestrutura.
Sistemas de ficheiros em rede. A maioria das render farms de produção utiliza armazenamento partilhado de alta velocidade (NFS, SMB ou sistemas de ficheiros distribuídos proprietários) em vez de copiar ficheiros de cena para cada nó individualmente. A cena reside num cluster de armazenamento central e os nós de renderização acedem-lhe pela rede. Isto evita o gargalo de copiar uma cena de 50 GB para 100 nós sequencialmente.
Cache e localidade. As farms inteligentes fazem cache de assets acedidos frequentemente nos nós de renderização localmente. Se três trabalhos no mesmo dia utilizam o mesmo pacote HDRI ou a mesma biblioteca de materiais V-Ray, os nós que já têm esses ficheiros em cache evitam a transferência de rede. Isto reduz o tempo de arranque por frame de minutos para segundos com texturas repetidas.
Streaming de texturas. Para cenas com conjuntos massivos de texturas (comum em visualização arquitectónica com bibliotecas de materiais 4K+), algumas configurações de farm fazem streaming de texturas a pedido em vez de pré-carregar tudo. O motor de renderização solicita um tile de textura, o sistema de armazenamento entrega-o e o nó faz cache localmente para frames subsequentes. Isto troca uma latência ligeiramente superior por tile por um tempo de carregamento inicial significativamente menor.
A Fase de Renderização: Processamento CPU e GPU
Com a cena carregada e o frame atribuído, a renderização propriamente dita começa. A forma como as farms alocam recursos CPU versus GPU reflete compromissos reais de desempenho e custo.

Comparação entre renderização CPU e GPU mostrando diferenças em velocidade, memória, melhores casos de uso, software suportado e especificações de hardware
Renderização CPU. Os motores baseados em CPU (V-Ray CPU, Corona, Arnold CPU) distribuem o trabalho por todos os núcleos disponíveis num nó. Um nó CPU típico de farm tem 44 ou mais núcleos com 96–256 GB de RAM. O grande volume de memória significa que os nós CPU lidam com cenas que transbordariam a VRAM de uma GPU — interiores complexos de visualização arquitectónica com mapas de deslocamento, simulações de partículas com milhões de elementos ou efeitos volumétricos com caches de alta resolução.
Na nossa farm, aproximadamente 70 % dos trabalhos de renderização correm em nós CPU. Isto reflete os fluxos de trabalho de produção de visualização arquitectónica e VFX que dominam a renderização profissional — estas cenas tendem a ser pesadas em memória e utilizam motores como V-Ray e Corona que são otimizados para desempenho multi-core de CPU.
Renderização GPU. Os motores baseados em GPU (Redshift, Octane, V-Ray GPU, Cycles com OptiX) aproveitam os milhares de núcleos paralelos das placas gráficas modernas. Os nossos nós GPU utilizam placas NVIDIA RTX 5090 com 32 GB de VRAM. A renderização GPU é tipicamente mais rápida por frame para cenas que cabem nos limites de VRAM, mas esses limites são reais — uma cena que requer 40 GB de dados de textura e geometria não pode renderizar numa placa de 32 GB sem fallbacks out-of-core que reduzem o desempenho.
Alocação híbrida. Alguns trabalhos beneficiam da divisão entre nós CPU e GPU. Um padrão comum: os nós GPU tratam dos beauty passes (rápidos por frame, limitados por VRAM), enquanto os nós CPU processam passes volumétricos ou de partículas que excedem a capacidade de VRAM. O agendador de trabalhos da farm suporta esta divisão, encaminhando diferentes render layers para o hardware adequado.
Montagem de Frames e Verificação de Qualidade
Renderizar um frame é apenas metade do trabalho. A farm também deve verificar a qualidade do resultado e montar os frames num pacote de entrega coerente.
Verificações de qualidade automáticas. Após a renderização de cada frame, a farm executa validações básicas: tamanho de ficheiro dentro do intervalo esperado (um PNG de 1 byte significa que a renderização falhou silenciosamente), resolução correspondente à especificação, ausência de frames totalmente pretos ou brancos (indicadores comuns de luzes ou materiais em falta) e formato de saída correto. Os frames que falham estas verificações são automaticamente re-renderizados num nó diferente.
Montagem de frames para renderização por tiles. Alguns motores e configurações dividem um único frame de alta resolução em tiles — renderizando o quadrante superior esquerdo num nó, o superior direito noutro, e assim por diante. Após todos os tiles estarem completos, a farm monta-os na imagem final de resolução completa. Esta abordagem funciona bem para imagens estáticas de resolução extremamente alta (8K+) onde um único nó demoraria horas por frame.
Entrega do resultado. Os frames concluídos são escritos no armazenamento de saída da farm e disponibilizados para download. Utilizamos armazenamento na nuvem com aceleração CDN para garantir que as velocidades de download não são limitadas pela largura de banda de upload da farm. Para sequências de animação grandes (milhares de ficheiros EXR), oferecemos opções de download em lote e podemos comprimir sequências para transferência mais rápida.
Arquitetura de Rede de uma Render Farm
A infraestrutura que liga nós de renderização, armazenamento e sistemas de gestão é tão importante quanto o hardware em si.
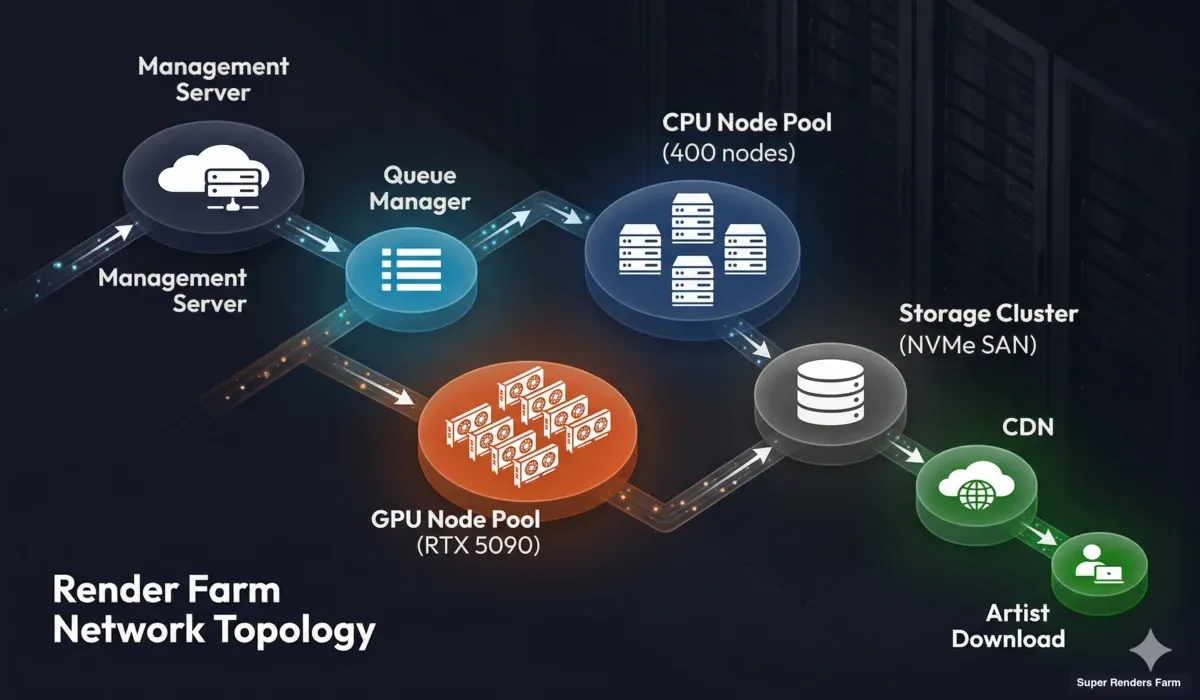
Topologia de rede de uma render farm mostrando servidor de gestão, gestor de filas, pools de nós de renderização CPU e GPU, cluster de armazenamento e entrega CDN aos utilizadores
Camada de gestão. Um servidor de gestão central orquestra tudo — ingestão de trabalhos, gestão de filas, monitorização do estado dos nós e comunicação com utilizadores. Este servidor é redundante (com capacidade de failover) porque, se falhar, toda a farm deixa de aceitar e processar trabalhos.
Rede dos nós de renderização. Os nós comunicam com a gestão e o armazenamento através de uma rede interna de alta largura de banda. Nas farms modernas, isto é tipicamente Ethernet de 10 Gbps ou superior. A largura de banda é mais importante durante a distribuição de cenas (carregamento de texturas) e saída de frames (escrita de ficheiros EXR de alta resolução para o armazenamento).
Cluster de armazenamento. O armazenamento central é o recurso partilhado de que todos os nós de renderização leem e para o qual escrevem. Deve lidar com leituras simultâneas de centenas de nós a solicitar tiles de textura e escritas simultâneas de nós a produzir frames renderizados. Arrays de armazenamento de alto desempenho (SANs baseadas em NVMe ou sistemas de ficheiros distribuídos) são essenciais. Um sistema de armazenamento lento cria um gargalo que nenhuma quantidade de potência CPU ou GPU consegue superar.
Conectividade à Internet. A ligação da farm ao mundo exterior determina a rapidez com que os utilizadores podem carregar cenas e descarregar resultados. Ligações redundantes multi-gigabit são padrão para farms de produção. A proximidade geográfica às principais bases de utilizadores também importa — uma farm nos EUA a servir um cliente europeu terá maior latência do que uma com ponto de presença na Europa.
Monitorização e Recuperação de Erros
As falhas são constantes em escala. Uma farm com centenas de nós espera incidentes diários de hardware. A diferença entre uma farm fiável e uma não fiável é a forma como as falhas são detetadas e tratadas.
Monitorização do estado dos nós. Cada nó de renderização reporta o seu estado (temperatura do CPU, utilização de memória, utilização de GPU, espaço em disco, débito de rede) ao sistema de gestão em intervalos regulares. Os nós que falham check-ins são sinalizados imediatamente. Os nós que mostram padrões anómalos (temperatura crescente, débito decrescente) são removidos preventivamente do pool antes de falharem a meio de uma renderização.
Recuperação ao nível do frame. Quando um nó falha durante a renderização, o frame que estava a processar é marcado como falhado e reatribuído a um nó saudável. A farm regista quais frames foram concluídos com sucesso versus quais estão em curso ou falharam. Este rastreio de estado garante que nenhum frame se perde ou duplica, mesmo durante falhas em cascata de nós.
Tratamento de crashes do motor de renderização. Para além de falhas de hardware, os próprios motores de renderização podem falhar — condições de falta de memória, elementos de cena corrompidos ou bugs do motor. A farm distingue entre crashes recuperáveis (tentar novamente num nó diferente com mais RAM) e não recuperáveis (o próprio ficheiro de cena tem um erro que fará crashar todos os nós). Após um número configurável de tentativas, a farm reporta a falha ao utilizador com informação de diagnóstico em vez de tentar indefinidamente.
Integridade dos dados. Os frames renderizados são verificados com checksums durante a escrita. Se uma falha de rede corrompe um frame durante a transferência para o armazenamento, a incompatibilidade de checksum aciona uma re-renderização automática. Isto é particularmente importante para ficheiros EXR, onde um único byte corrompido pode produzir artefactos visíveis no compositing.
Software Stack de uma Render Farm
O software que coordena tudo isto é tão crítico quanto o hardware.
Gestores de renderização. Software de gestão de renderização construído de raiz lida com agendamento de trabalhos, alocação de nós e administração da farm. Estes sistemas são concebidos para as exigências específicas da renderização distribuída — rastreio de dependências ao nível do frame, gestão de versões de motores por nó e alocação de recursos multi-utilizador.
Ferramentas de análise de cenas. Antes de um trabalho entrar na fila de renderização, ferramentas de análise examinam o ficheiro de cena para identificar dependências, estimar requisitos de recursos e verificar erros comuns. Estas ferramentas são específicas por motor — um analisador de cenas V-Ray verifica problemas diferentes de um analisador Blender Cycles.
Gestão de versões. Uma farm de produção mantém múltiplas versões de cada motor de renderização em simultâneo. Um utilizador pode necessitar do V-Ray 6 para um projeto mais antigo enquanto outro requer o V-Ray 7. A infraestrutura de software da farm garante que cada nó carrega a versão correta do motor para o trabalho atribuído, alternando entre versões à medida que diferentes trabalhos passam pelo sistema.
Painéis de monitorização. Os operadores da farm utilizam painéis em tempo real que mostram o estado dos nós, profundidade da fila, trabalhos ativos, taxas de conclusão e frequências de erros. Estes painéis permitem resposta rápida a problemas — se as taxas de erro disparam num grupo particular de nós, o operador pode investigar imediatamente em vez de descobrir o problema horas depois.
Como as Farms Totalmente Geridas Diferem das Plataformas Self-Service
Nem todas as render farms funcionam da mesma forma. As duas categorias principais — totalmente geridas e self-service — lidam com o pipeline de forma diferente.
Farms totalmente geridas (como a Super Renders Farm) tratam de toda a stack técnica. Carrega uma cena, seleciona as definições e a farm gere tudo: instalação de software, gestão de versões, compatibilidade de plugins, recuperação de erros e entrega do resultado. Não é necessário aceder remotamente a nenhuma máquina nem gerir qualquer infraestrutura. Isto é importante porque a configuração de motores de renderização é complexa — o V-Ray sozinho tem dezenas de definições específicas por versão que afetam a compatibilidade com a farm.
Plataformas self-service ou IaaS alugam máquinas virtuais com software de renderização pré-instalado. O utilizador acede remotamente, configura o software, gere a própria fila de renderização e trata da resolução de problemas. Isto confere mais controlo mas requer significativamente mais experiência técnica e investimento de tempo.
Para uma comparação detalhada, o nosso guia de renderização na nuvem gerida vs DIY analisa os compromissos.
A Estrutura de Custos por Detrás dos Preços das Render Farms
Compreender como as render farms funcionam também significa compreender pelo que se paga.
Preços por recurso. A maioria das farms cobra com base nos recursos de computação consumidos — GHz-hora para renderização CPU ou OBs (unidades de computação) para GPU. É possível estimar custos antes de se comprometer utilizando ferramentas como a nossa calculadora de custos. Isto significa que o custo escala linearmente com a quantidade de recursos que o trabalho utiliza. Um frame de 10 minutos num nó custa o mesmo quer a farm tenha 10 outros trabalhos a correr ou 1.000 — paga-se pelo que se consome.
Overhead de infraestrutura. O preço por GHz-hora da render farm inclui não apenas a eletricidade para alimentar o CPU, mas custos de hardware amortizados, infraestrutura de armazenamento, largura de banda de rede, licenciamento de software (as licenças de farm para motores de renderização são caras), refrigeração, redundância e a equipa de engenharia que mantém tudo a funcionar. Uma parte significativa do custo cobre a camada de fiabilidade e conveniência que evita a gestão desta infraestrutura pelo próprio utilizador.
Multiplicadores de prioridade. Prioridade mais alta custa mais porque concede acesso a mais nós simultaneamente, o que significa que outros trabalhos cedem recursos. Trata-se de um compromisso deliberado — prazos urgentes justificam o valor adicional.
Para uma análise abrangente de preços, consulte o nosso guia de preços de render farms.
Resumo: O Pipeline de uma Render Farm
O pipeline completo, da submissão à entrega:
- Upload — ficheiro de cena e dependências transferidos para o armazenamento da farm
- Validação — dependências verificadas, definições de renderização confirmadas, custo estimado
- Fila — o trabalho entra numa fila baseada em prioridades, aguarda alocação de nós
- Distribuição — dados da cena disponibilizados aos nós de renderização atribuídos via armazenamento em rede
- Renderização — nós CPU ou GPU processam os frames atribuídos em paralelo
- Verificação de qualidade — cada frame validado (tamanho de ficheiro, resolução, conteúdo)
- Montagem — frames organizados, tiles montados se aplicável
- Entrega — frames concluídos disponíveis para download via armazenamento com aceleração CDN
Cada passo tem modos de falha e cada modo de falha tem recuperação automatizada. O resultado é um sistema que converte de forma fiável os ficheiros de cena em frames renderizados a velocidades que nenhuma estação de trabalho individual consegue igualar.
FAQ
Q: Quanto tempo demora uma render farm a processar um trabalho de animação típico? A: Depende da complexidade do frame e do nível de prioridade. Uma animação de visualização arquitectónica de 500 frames a 1080p com V-Ray conclui tipicamente em 2–6 horas numa farm versus 3–7 dias localmente. Trabalhos acelerados por GPU (Redshift, Cycles) são frequentemente mais rápidos por frame mas limitados por VRAM em cenas complexas.
Q: O que acontece se um nó de renderização falhar durante o meu trabalho? A: O gestor de filas da farm deteta a falha em segundos e reatribui o frame em curso a um nó saudável. Nenhum frame se perde. Se o crash foi causado por um erro na cena (não por hardware), o sistema tenta novamente numa configuração de nó diferente antes de o sinalizar como problema do lado do utilizador.
Q: Preciso de instalar software de renderização na farm? A: Em farms totalmente geridas como a Super Renders Farm, não. Mantemos todos os motores de renderização suportados (V-Ray, Corona, Arnold, Redshift, Cycles e outros) em toda a nossa frota de nós, incluindo múltiplas versões para compatibilidade. Plataformas self-service podem exigir que o utilizador gira a instalação de software.
Q: Uma render farm consegue lidar com cenas que excedem a VRAM da minha GPU local? A: Sim. Os nós de renderização CPU na nossa farm têm 96–256 GB de RAM, o que permite lidar com cenas que sobrecarregariam uma GPU de estação de trabalho. Para motores específicos de GPU, os nossos nós RTX 5090 fornecem 32 GB de VRAM — mais do que a maioria das GPUs de secretária. Cenas que excedem mesmo esse limite são encaminhadas para nós CPU automaticamente.
Q: Como é que a farm lida com diferentes versões de motores de renderização? A: As farms de produção mantêm múltiplas versões de cada motor simultaneamente. Quando submete um trabalho, o sistema corresponde a versão do motor da cena a nós compatíveis. Se guardou a cena em V-Ray 6, renderiza em nós V-Ray 6 — não V-Ray 7, que poderia interpretar definições de forma diferente.
Q: Os meus dados de cena estão seguros numa render farm? A: As farms reputadas utilizam transferências encriptadas (TLS/SSL para upload e download), armazenamento com controlo de acesso (os ficheiros ficam isolados de outros utilizadores) e eliminação automática dos dados de cena após um período de retenção. Na nossa farm, os ficheiros de cena são eliminados automaticamente após a conclusão do trabalho mais uma janela de retenção configurável.
Q: Que formatos de ficheiro devo usar ao submeter para uma render farm?
A: Utilize o formato nativo do seu software (.max para 3ds Max, .blend para Blender, .ma/.mb para Maya). Para a saída, especifique EXR para fluxos de trabalho de compositing ou PNG para entrega. Renderize sempre para sequências de imagens, não ficheiros de vídeo — se um frame falhar, apenas esse frame precisa de re-renderização.
Q: Como é que as render farms lidam com dependências de plugins como Forest Pack ou Scatter? A: As farms geridas mantêm plugins comuns em toda a sua frota de nós. Quando submete uma cena que utiliza Forest Pack, a farm garante que os nós atribuídos ao seu trabalho têm a versão correta do Forest Pack instalada. Plugins menos comuns podem requerer aviso prévio para que a farm os possa instalar antes do trabalho correr.
Leitura Adicional
- O Que É uma Render Farm? — guia fundamental sobre conceitos de render farms
- Guia de Preços de Render Farms — como funcionam os modelos de preços na indústria
- Renderização na Nuvem vs Local — quando a renderização em farm faz sentido versus local
- Autodesk Knowledge Network — Distributed Rendering — documentação oficial de renderização distribuída do 3ds Max
- Blender Manual — Render Output — configuração de saída de renderização do Blender
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



