
Houdini Karma XPU numa Cloud Render Farm: Guia Técnico 2026
Visão geral
Introdução
Karma XPU é o motor de renderização que um número crescente de estúdios Houdini está a adotar como padrão, e com boas razões: é o motor de renderização próprio da SideFX, integra-se nativamente no Solaris e no USD, e a sua execução híbrida CPU+GPU torna o look-dev quase interativo. Numa estação de trabalho individual, é um prazer usar. O problema começa quando se retira uma cena Karma XPU da estação de trabalho e se tenta executar algumas centenas de frames numa render farm.
À escala de render farm, o Karma XPU deixa de se comportar como uma versão mais rápida do Karma CPU e começa a comportar-se como um motor diferente. A VRAM torna-se um limite rígido e não apenas uma sugestão. Simulações que corriam bem de forma interativa não podem ser distribuídas até serem colocadas em cache. O motor pode cair silenciosamente para o modo CPU numa frame pesada, deixando a questão em aberto de por que razão um determinado plano demorou seis vezes mais do que o plano adjacente. Nada disto são erros — é a arquitetura que se revela sob carga.
Temos anos de experiência em renderização distribuída para trabalhos em Houdini, e Karma XPU é um dos motores disponíveis na nossa render farm Houdini na nuvem, a par de Redshift, Mantra, Arnold, V-Ray for Houdini e Octane. Este guia é o mergulho técnico aprofundado: o que é realmente o Karma XPU, em que difere do Karma CPU e do Mantra, o que muda ao renderizar em modo headless numa render farm, como o cache de simulações tem de funcionar primeiro e como decidir entre Karma XPU e Redshift para um determinado plano. Se preferir uma lista de verificação passo a passo para preparação de cenas, o nosso guia de configuração Houdini cobre esse terreno; este artigo pressupõe que já conhece bem o Solaris.
Por que razão o Karma XPU é mais difícil de escalar do que parece
O ponto essencial a compreender sobre o Karma XPU é que "XPU" não é um motor de renderização — é um modo de execução. Karma é um único delegado de renderização USD, e XPU é o caminho que distribui trabalho pelos núcleos do CPU e pela GPU NVIDIA em simultâneo, com ambos os dispositivos a contribuir com amostras para a mesma imagem. Karma CPU é o mesmo delegado, mas com a GPU desligada. Este design é elegante numa estação de trabalho e incómodo numa render farm, por quatro razões.
Em primeiro lugar, o caminho GPU corre em OptiX, o que significa que carrega geometria, texturas e estruturas de aceleração para a VRAM da GPU. Quando uma cena cabe na VRAM, obtém-se a aceleração híbrida completa. Quando não cabe, o Karma XPU tende a cair para a execução por CPU em vez de transmitir dados em streaming como alguns motores GPU fazem. A renderização termina na mesma, mas a uma fração da velocidade esperada — e nada no registo de tarefas habitual chama a atenção para isso.
Em segundo lugar, o XPU é mais recente do que os motores com que compete. O Houdini 20.0 foi o seu primeiro marco de estabilidade em produção, e o 20.5 alargou consideravelmente a cobertura de funcionalidades, mas ainda há um conjunto de funcionalidades que favorece o Karma CPU. Se um plano usar uma delas, parte da renderização pode cair silenciosamente para o caminho CPU.
Em terceiro lugar, a fixação de versões importa mais do que se poderia esperar. Uma cena criada numa versão pontual do Houdini deve ser renderizada em nós de render farm que executem essa mesma versão; a superfície do Karma mudou suficientemente entre as versões 20.0, 20.5 e a linha 21 para que renderizações entre versões diferentes não possam ser assumidas como idênticas.
Em quarto lugar — e este engana toda a gente a primeira vez — as simulações não são frames. Não basta enviar uma configuração Pyro ou FLIP para uma render farm e esperar que ela se distribua. Este ponto merece a sua própria secção, e tem uma abaixo.
Karma XPU vs Karma CPU vs Mantra
Três motores de renderização são fornecidos com o Houdini, e a escolha entre eles é a primeira decisão real para qualquer tarefa de render farm. Não são intermutáveis.
O Mantra é o motor legado. É anterior ao USD, opera no pipeline de descrição de cenas próprio do Houdini e usa shaders baseados em VEX (CVEX) em vez de MaterialX. A SideFX não o removeu e continua totalmente funcional, mas não recebe novas funcionalidades — a direção futura é claramente o Karma. O Mantra ainda se justifica em dois cenários: pipelines com bibliotecas extensas de shaders VEX que seriam dispendiosas de reconstruir, e o comportamento ocasional de micropolígono ou deslocamento que ainda não tem um equivalente limpo em Karma. Se os shaders forem CVEX, não se traduzem para Karma, e isso por si só pode manter um plano em Mantra.
O Karma CPU é o caminho de referência. É nativo em USD, implementa o conjunto completo de funcionalidades do Karma e é a referência quando é necessário saber como uma frame "deve" ficar. Corre em multi-thread nos núcleos CPU sem envolvimento de GPU. Numa render farm com uma frota CPU de grande dimensão é genuinamente prático — contorna completamente o limite de VRAM, tornando-se a escolha sensata para cenas demasiado pesadas para caber confortavelmente na memória GPU.
O Karma XPU é o caminho acelerado híbrido: CPU mais GPU NVIDIA, ambos a traçar para a mesma frame, usando shading em MaterialX e a mesma base nativa em USD que o Karma CPU. Ao combinar a GPU com o CPU, renderiza look-dev interativo e frames finais dentro da VRAM mais rapidamente do que qualquer um dos caminhos só-CPU, e é o padrão natural para novos pipelines Solaris. A sua limitação é que constitui um subconjunto de funcionalidades do Karma CPU — a maioria das lacunas remanescentes diz respeito a casos extremos de volumes, shading ou AOV, e a SideFX tem vindo a fechá-las lançamento após lançamento. A regra honesta de produção é renderizar uma frame de comparação em XPU e CPU antes de comprometer uma sequência com XPU, porque quando XPU e CPU divergem, CPU está correto.
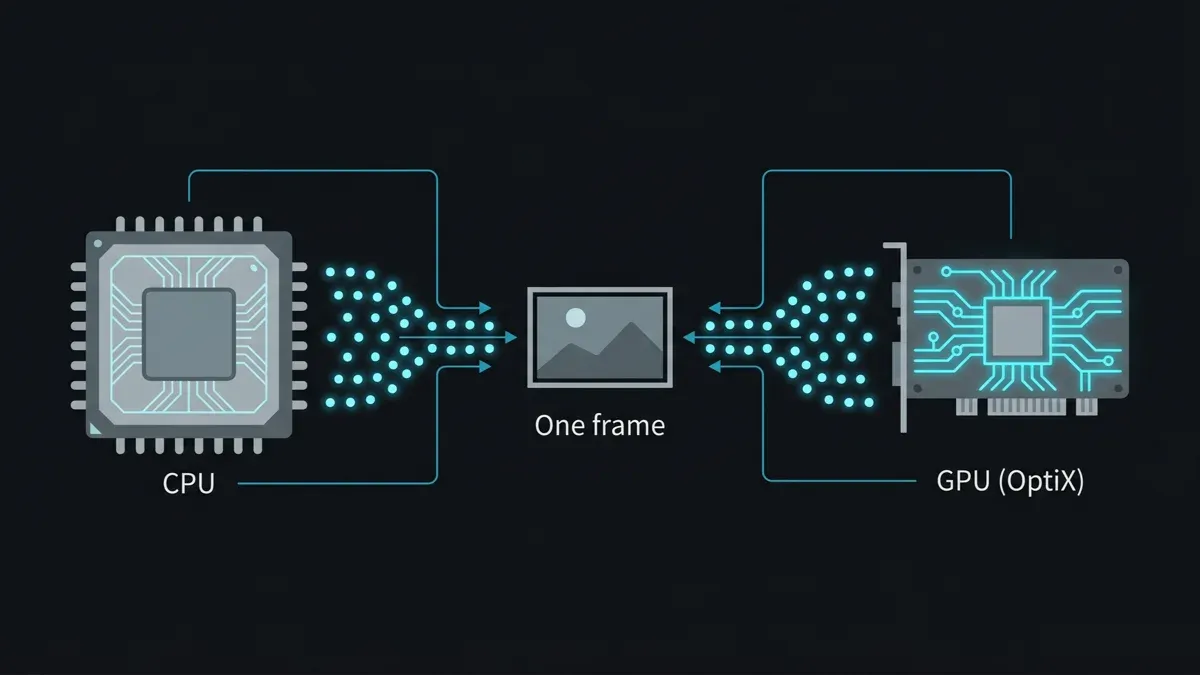
Diagrama do Houdini Karma XPU a dividir o trabalho de renderização pelo CPU e GPU em simultâneo, ambos a contribuir com amostras para uma única frame.
| Aspeto | Mantra | Karma CPU | Karma XPU |
|---|---|---|---|
| Fundação de cena | Pré-USD (pipeline nativo) | USD / Solaris | USD / Solaris |
| Computação | CPU | CPU | CPU + GPU NVIDIA |
| Shading | VEX / CVEX | MaterialX | MaterialX |
| Completude de funcionalidades | Congelado (sem novas funcionalidades) | Referência (completo) | Subconjunto do CPU, em maturação |
| Limite de VRAM | Nenhum | Nenhum | Sim — limitado pela memória GPU |
| Adequado para | Pipelines VEX legados | Cenas pesadas, ground-truth | Look-dev nativo USD + frames finais dentro da VRAM |
Executar o Karma XPU em modo headless numa render farm na nuvem
De forma interativa, renderiza-se ao clicar no botão no viewport do Solaris. Numa render farm, esse botão é um programa de linha de comandos chamado husk. É o motor de renderização USD standalone da SideFX — um processo leve que carrega um stage USD composto e renderiza-o sem iniciar uma sessão interativa completa do Houdini. Vem incluído com o Houdini e é a forma canónica de renderizar Karma à escala. Uma submissão tem, em essência, este aspeto:
husk --renderer Karma \
--frame 1001 --frame-count 50 \
--output /project/render/shot_010.$F4.exr \
/project/usd/shot_010.usd
Cada nó de render farm executa husk contra o mesmo stage USD mas para um intervalo de frames diferente, o que é o que torna possível a distribuição ao nível das frames. O stage em si é um ficheiro .usd/.usdc completamente composto que referencia toda a geometria, luzes, câmaras e materiais. Os AOVs não são parâmetros de linha de comandos — são prims Render Var USD integrados no stage a partir das definições Render Settings e Render Var LOPs, de modo que o husk os lê sem necessitar de uma rede Houdini ativa. Beleza, alfa, normais, albedo e o restante viajam dentro do USD.
Há algumas mecânicas específicas de render farm que vale a pena conhecer. O Karma suporta checkpointing, escrevendo estado intermédio de renderização a intervalos de amostragem para que uma frame hero longa possa ser retomada em vez de reiniciada caso um nó falhe — valioso para frames únicas com milhares de amostras, menos relevante para animações com amostras moderadas onde cada frame é barata de refazer. O denoising corre através do denoiser OptiX na GPU ou do OIDN da Intel na CPU; numa render farm tendemos para o OIDN quando a estabilidade temporal entre muitos nós importa, porque produz saída idêntica independentemente de qual máquina processou a frame.
Quanto ao licenciamento, seremos diretos, porque é uma questão comum. O Karma não é um plugin licenciado separadamente como Redshift, Arnold, V-Ray e Octane — vem incluído com o Houdini. Executamos o Houdini e o Karma sob utilização render-only para renderizar os trabalhos; não somos parceiros da SideFX e não revendemos licenças Houdini. Por a render farm ser totalmente gerida, não é necessário aceder remotamente a um nó, instalar o Houdini manualmente ou fornecer uma licença — basta carregar a cena e os dados em cache, e o licenciamento do lado da renderização nos nossos nós é tratado como parte da operação do serviço. Para os motores comerciais na stack Houdini, as licenças Redshift, Arnold, V-Ray e Octane estão incluídas na taxa de renderização.
A stack Houdini da Super Renders Farm
Uma render farm que executa apenas um motor obriga todos os planos a suportar um único conjunto de compromissos. O trabalho em Houdini raramente coopera com isso, por isso a nossa render farm Houdini na nuvem executa o conjunto completo: Karma (nos modos XPU e CPU), Mantra, Redshift, Arnold, V-Ray for Houdini e Octane. O objetivo da diversidade é permitir escolher o motor certo para cada plano em vez de para cada estúdio — Karma XPU para o look-dev nativo USD, Karma CPU para a frame hero demasiado pesada para VRAM, Redshift para a sequência onde a velocidade é prioritária, Mantra para a configuração de shaders legados.
O hardware subjacente divide-se pela mesma linha CPU/GPU que o trabalho em Houdini exige. A nossa frota CPU contribui com mais de 20.000 núcleos CPU, onde acontece a maioria da renderização de produção efetiva — em toda a indústria, e na nossa render farm, a renderização CPU ainda representa a maior quota de trabalhos. Esta capacidade CPU é o que torna Karma CPU e Mantra práticos à escala de sequência e o que apanha Karma XPU quando uma frame é demasiado pesada para a GPU. Para trabalho GPU, as nossas máquinas GPU dedicadas executam placas NVIDIA RTX 5090 com 32 GB de VRAM cada. Para Karma XPU especificamente, esses 32 GB são o número que mais importa: a VRAM é o limite efetivo da complexidade que uma cena pode ter antes que o XPU pare de acelerar na GPU. Um conjunto de texturas UDIM 4K, um ambiente instanciado denso ou um VDB de alta resolução podem rapidamente consumir esse orçamento, e quanto maior for a placa, mais longe se chega antes de a renderização cair silenciosamente para o CPU. Para uma análise mais aprofundada do trabalho GPU em geral, as nossas notas de renderização GPU RTX 5090 aprofundam a placa, e a página de render farm GPU cobre a frota.

Diagrama do Karma XPU e VRAM GPU: uma cena que cabe em 32 GB de VRAM renderiza à velocidade híbrida CPU+GPU, enquanto uma cena que excede a VRAM cai para CPU.
A faturação segue o hardware: a renderização CPU é medida por GHz-hora e a renderização GPU por OctaneBench-hora, de modo que uma sequência Karma CPU e uma sequência Redshift são cobradas nas unidades que realmente descrevem o trabalho realizado. Como o Karma XPU pode usar ambos os dispositivos, o modelo mental mais simples é que fatura como tempo GPU quando corre num nó GPU e permanece dentro da VRAM, com a contribuição CPU incluída — mais uma razão para respeitar o limite de VRAM.
Cache de simulações: o passo que não pode ser ignorado
Aqui está o conceito mais importante para renderizar Houdini em qualquer render farm, e o mais suscetível de desperdiçar um dia se for mal compreendido: as frames são paralelamente independentes, mas as simulações não são.
A frame 1042 de uma animação renderizada não precisa que a frame 1041 exista primeiro — ambas podem ser renderizadas em máquinas separadas no mesmo momento. Esta independência é a razão pela qual as render farms funcionam. Uma simulação é o oposto. A frame 1042 de uma simulação Pyro é calculada a partir do estado do fumo na frame 1041, que derivou da 1040, tudo o caminho até à primeira frame. Não é possível calcular o meio de uma simulação sem calcular tudo o que está antes, por ordem, numa única máquina. Enviar uma simulação bruta para uma render farm não tem nada para distribuir.
A resolução é determinista e inegociável: simular primeiro, colocar em cache no disco, depois renderizar o cache na render farm. A simulação corre sequencialmente numa máquina (ou numa máquina dedicada a simulações) e escreve o resultado de cada frame no disco. Esses ficheiros de cache — agora dados estáticos, independentes de frames — são o que a render farm renderiza. Os nós de render não re-simulam; leem geometria e volumes pré-computados e traçam frames em paralelo como qualquer outra animação.
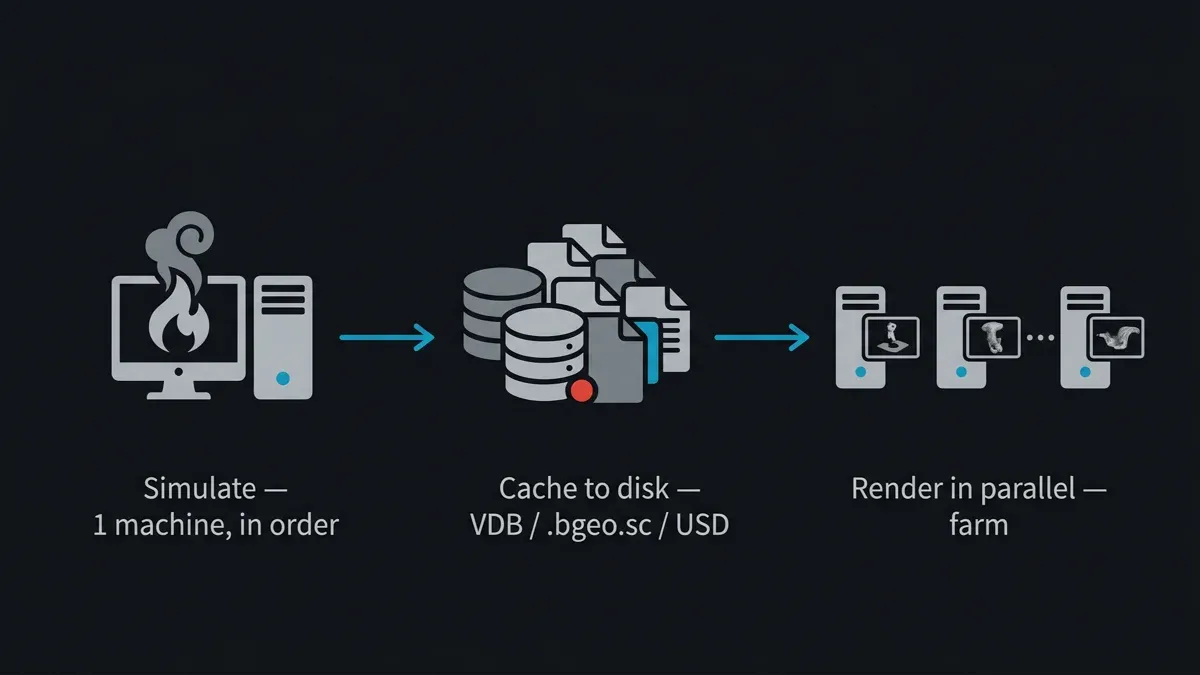
Diagrama do pipeline: uma simulação é resolvida sequencialmente numa máquina, colocada em cache no disco como VDB ou bgeo, e depois renderizada frame a frame em paralelo numa render farm.
O que se coloca em cache depende do solver:
| Simulação | Solver | Formato de cache | Notas |
|---|---|---|---|
| Fumo / fogo | Sparse Pyro | .vdb | Volumes esparsos standard da indústria; lidos diretamente para o stage de renderização |
| Líquidos | FLIP | Partículas .bgeo.sc → superfície em mesh | O meshing a partir de partículas em cache é independente por frame, pelo que pode ser enviado separadamente para render farm |
| Tecido / grão / corpo mole | Vellum | .bgeo.sc | Caches de tecido hero crescem rapidamente — atenção ao throughput de armazenamento |
| Corpos rígidos, multidões, instâncias | RBD / Agents | .bgeo.sc ou USD | USD (PointInstancer) é a forma mais limpa de passar para Karma |
Há um detalhe que vale a pena salientar: existe uma diferença real entre a simulação em si e o trabalho a jusante dela. O surfacing FLIP — transformar partículas em cache num mesh de renderização — depende apenas das partículas de cada frame, não da frame anterior, pelo que esse passo é paralelizável e pode ser enviado para a render farm como um passe próprio, mesmo que a simulação subjacente não pudesse. O padrão cada vez mais comum nos pipelines Houdini 20+ é colocar a geometria diretamente em cache para USD, para que o husk a leia nativamente no momento da renderização, sem passo de tradução SOP-para-USD no nó.
É também aqui que o PDG/TOPs ocupa o seu lugar. O PDG é o grafo de tarefas com gestão de dependências do Houdini, e modela exatamente a relação que a renderização em render farm precisa: "colocar em cache esta simulação e, apenas quando o cache existir, renderizar estas frames a partir dele." Um File Cache TOP produz o cache da simulação como dependência de saída; uma tarefa de renderização a jusante aguarda por ele e depois ramifica por frame. O PDG pode conduzir tanto o caching como a renderização husk através dos seus nós de agendamento, razão pela qual se tornou a espinha dorsal dos pipelines Houdini sérios.
Uma nota prática da experiência: caches de tecido e líquidos de alta resolução podem atingir gigabytes por frame, e quando dezenas de nós puxam a mesma sequência do armazenamento partilhado em simultâneo, o throughput de leitura — não o cálculo — torna-se o fator limitante. Suportamos uploads sem limite de tamanho rígido (sugerimos manter-se abaixo dos 300 GB por upload, utilizando SFTP ou a aplicação cliente acima desse valor), e aceitamos ficheiros .tar, .tar.gz e .7z — mas não .zip. Recompacte sequências de cache pesadas como .tar.gz antes do upload. A saída renderizada fica disponível durante 45 dias após a conclusão de um trabalho, tempo mais do que suficiente para descarregar uma sequência completa.
Submeter um trabalho Karma XPU, do início ao fim
Juntando tudo, um trabalho Karma XPU limpo numa render farm corre numa ordem previsível:

Fluxo de trabalho em seis passos para submeter um trabalho Karma XPU numa render farm na nuvem: colocar simulações em cache, exportar o stage USD, fazer upload, escolher o motor, distribuir frames, fazer denoising e descarregar.
- Colocar todas as simulações em cache. Pyro para VDB, FLIP e Vellum para
.bgeo.scou USD. Confirmar que os caches estão completos e contíguos por frame — uma frame intermédia em falta manifesta-se como uma lacuna na renderização, não como um erro. - Exportar um stage USD composto com as configurações Render Settings e as prims Render Var integradas, todos os caminhos de assets resolvidos para serem acessíveis a partir de um nó de render em vez de a partir das unidades locais da estação de trabalho.
- Empacotar o projeto — cena, caches, texturas e qualquer configuração OCIO — e fazer o upload. Por a render farm ser totalmente gerida, não há nó para aceder nem instalação do Houdini para gerir.
- Escolher o motor. Karma XPU para o look-dev dentro da VRAM e passes finais; mudar para Karma CPU para frames que se sabe serem demasiado pesadas para 32 GB; recorrer ao Redshift quando a velocidade é a prioridade.
- Distribuir as frames. A render farm distribui o intervalo de frames pelos nós, cada um a executar
huskpara a sua fatia. O progresso é monitorizado em vez de gerido. - Denoising e download. Descarregar os EXRs (com OIDN aplicado se assim estiver configurado) dentro da janela de 45 dias.
O modo de falha recorrente em todo este processo é a resolução de assets. O USD resolve caminhos relativamente à layer que os referencia ou como caminhos absolutos, e um caminho absoluto que aponta para a unidade local da estação de trabalho irá simplesmente produzir texturas ou geometria em falta num nó de render — muitas vezes sem erro explícito, apenas preto onde um asset deveria estar. Resolva os caminhos contra uma raiz de projeto partilhada, mantenha a configuração OCIO consistente em todo o trabalho para que a cor não derive, e integre as dependências de HDA personalizadas no USD antes da exportação para que um nó não necessite de um plugin que nunca lhe foi fornecido. Para os fundamentos de como a renderização na nuvem distribui este tipo de trabalho, a nossa visão geral de render farm na nuvem estabelece o contexto.
Quando escolher Karma XPU vs Redshift
Tanto o Karma XPU como o Redshift podem renderizar Houdini numa render farm GPU, e a escolha não é sobre qual é "melhor" — é sobre o que o plano e o pipeline precisam. Vêm de filosofias diferentes. O Karma XPU é fisicamente baseado, nativo em USD, com shading MaterialX, e feito pelo mesmo fornecedor que o Houdini. O Redshift é um motor GPU maduro, predominantemente biased, com mais de uma década de historial em produção, um plugin para Houdini e — esta é a sua característica marcante em render farm — um robusto sistema out-of-core que derrama graciosamente da VRAM para a RAM do sistema e NVMe quando uma cena cresce demasiado. Enquanto o Karma XPU tende a cair para CPU em caso de overflow de VRAM, o Redshift continua a renderizar na GPU com uma penalização de desempenho previsível, razão pela qual uma placa de 32 GB consegue conduzir cenas com muito mais de 32 GB de texturas em Redshift.
Essa diferença conduz a maior parte da decisão:
| Escolher Karma XPU quando… | Escolher Redshift quando… |
|---|---|
| O pipeline é nativo em USD / Solaris | A velocidade GPU bruta é a prioridade |
| Os shaders são MaterialX | A cena é intensiva em VRAM (VDBs grandes, conjuntos de texturas extensos) |
| É necessário transporte de luz fisicamente baseado, sem flicker de GI-cache | É necessária estabilidade out-of-core acima do limite de VRAM |
| A standardização na stack SideFX completa é o objetivo | A equipa já tem shaders e look-dev em Redshift |
| O fator de custo do motor importa (Karma vem com o Houdini) | O trabalho abrange C4D / Maya / Houdini e é desejável um aspeto uniforme |
Os outros motores preenchem as lacunas. O Arnold é a escolha para VFX pesados com subsuperfície complexa, cabelo e volumes, ou quando um pipeline já depende de shaders específicos do Arnold — basta fixar a versão HtoA nos nós da render farm e pré-converter texturas para .tx. O V-Ray for Houdini faz sentido para estúdios já standardizados em V-Ray no 3ds Max e Maya que pretendem um aspeto consistente entre DCCs; pode ler mais na nossa página Redshift sobre o lado GPU dessa comparação. O Octane adapta-se a equipas já inseridas no seu ecossistema espectral baseado em nós e fatura de forma limpa por OctaneBench-hora. Para uma comparação mais ampla entre fornecedores em vez de entre motores, o nosso artigo de comparação de render farms Houdini cobre essa decisão.
Uma precaução específica do Karma XPU numa render farm: como uma sequência pode conter frames leves (aceleradas por GPU) e frames pesadas (limitadas silenciosamente ao CPU), os tempos de renderização podem variar muito naquilo que parece ser um trabalho uniforme. A solução é uma verificação de memória de preflight na frame mais pesada antes de comprometer todo o intervalo — se vai ultrapassar os 32 GB de VRAM, é preferível decidir deliberadamente entre Karma CPU na frota CPU e o caminho out-of-core do Redshift, em vez de deixar o motor decidir sozinho a meio da sequência. Para além do motor em si, as armadilhas habituais da render farm continuam a aplicar-se: fixar a versão do Houdini, manter a configuração do denoiser explícita em vez de depender dos padrões por nó, e verificar que cada caminho de asset é resolvido a partir de um nó e não apenas a partir da própria máquina.
Para os detalhes oficiais do motor, a SideFX mantém documentação completa para Karma e para o husk como motor de renderização de linha de comandos — recomenda-se a leitura antes da primeira submissão de grande dimensão.
FAQ
Q: Qual é a diferença entre Karma XPU e Karma CPU? A: São o mesmo motor Karma nativo em USD em dois modos de execução. Karma CPU corre apenas nos núcleos CPU e implementa o conjunto completo de funcionalidades de referência. Karma XPU adiciona a GPU NVIDIA e renderiza em CPU e GPU em conjunto para maior velocidade, mas suporta atualmente um subconjunto das funcionalidades do Karma CPU e é limitado pela VRAM da GPU. O hábito prático é confirmar uma frame em Karma CPU quando a saída do XPU parece incorreta, porque CPU é a referência ground-truth.
Q: É necessária uma licença SideFX ou Houdini para renderizar Karma numa render farm na nuvem? A: Não da parte do utilizador, numa render farm totalmente gerida. O Karma vem incluído com o Houdini, em vez de ser licenciado separadamente como Redshift ou Octane, e executamos o Houdini sob utilização render-only para renderizar os trabalhos — não somos parceiros da SideFX e não revendemos licenças Houdini. O utilizador faz o upload da cena e dos caches; o licenciamento do lado da renderização nos nossos nós é tratado como parte do serviço gerido.
Q: Por que razão as simulações têm de ser colocadas em cache antes da renderização numa render farm?
A: Porque as simulações são sequenciais e as frames não são. Cada frame de simulação depende do estado da frame anterior, pelo que uma simulação tem de ser resolvida por ordem numa única máquina. As frames de renderização, pelo contrário, são independentes e podem correr em centenas de nós em simultâneo. Colocar a simulação concluída em cache no disco (VDB para Pyro, .bgeo.sc ou USD para FLIP e Vellum) transforma-a em dados estáticos que a render farm pode renderizar em paralelo sem re-simular.
Q: Como é que o Karma XPU lida com uma cena que excede a VRAM da GPU? A: Ao contrário do Redshift, que transmite out-of-core a partir da memória do sistema, o Karma XPU tende a cair para a execução por CPU quando uma cena não cabe na VRAM. A renderização conclui na mesma, mas a aceleração GPU é perdida e a frame pode demorar dramaticamente mais tempo — sem nada óbvio no registo. Para cenas que se sabe serem pesadas, é preferível escolher deliberadamente Karma CPU na frota CPU ou o caminho out-of-core do Redshift, em vez de deixar que o fallback aconteça a meio da sequência.
Q: O Karma XPU é mais rápido do que o Redshift? A: Depende do plano. O Redshift é um motor GPU altamente otimizado, predominantemente biased, e é muitas vezes mais rápido em cenas de produção típicas, especialmente as intensivas em VRAM onde o sistema out-of-core mantém o trabalho na GPU. O Karma XPU é fisicamente baseado e totalmente nativo em USD, o que é mais adequado para pipelines Solaris e shading MaterialX, mesmo que precise de mais amostras para ruído equivalente. A velocidade por si só não decide — a adequação ao pipeline e a margem de VRAM geralmente decidem.
Q: O que é o husk e é necessário usá-lo diretamente?
A: O husk é o motor de renderização USD standalone de linha de comandos da SideFX, e é o que realmente renderiza Karma num nó de render farm — um processo leve que carrega um stage USD composto sem uma sessão Houdini completa. Numa render farm gerida, não é necessário invocá-lo manualmente; basta submeter a cena e a render farm executa husk por frame nos nós. Saber que existe ajuda a compreender por que razão uma exportação USD limpa e totalmente resolvida importa tanto.
Q: O PDG/TOPs pode conduzir uma renderização Karma na render farm?
A: Sim. O PDG modela a dependência entre o cache de uma simulação e a renderização a partir dele, e os seus nós de agendamento podem despachar tanto o passo File Cache como a renderização husk a jusante numa render farm. É a forma standard como os pipelines Houdini sérios expressam "colocar em cache primeiro, depois ramificar a renderização por frame", e mantém as partes sequenciais e paralelas do trabalho na ordem correta automaticamente.
Q: Que outros motores de renderização Houdini podem ser usados além do Karma XPU? A: A nossa stack Houdini executa Karma nos modos XPU e CPU, mais Mantra, Redshift, Arnold, V-Ray for Houdini e Octane. Este leque permite adaptar o motor ao plano — Karma XPU para look-dev nativo USD, Karma CPU para frames hero intensivas em VRAM, Redshift para velocidade e out-of-core, Mantra para shaders VEX legados, e Arnold, V-Ray ou Octane onde um pipeline já deles depende.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



