
Renderização cloud-based vs cloud computing rendering: guia de distinção 2026
Visão geral
Introdução
Os resultados de pesquisa por "cloud rendering" misturam duas coisas genuinamente diferentes. Uma é a renderização cloud-based — serviços de renderização criados especificamente onde carrega um ficheiro de projeto e recebe fotogramas de volta. A outra é o cloud computing rendering — máquinas virtuais de uso geral de fornecedores de nuvem que configura para renderizar. Partilham os mesmos termos e muito do mesmo hardware, mas o fluxo de trabalho, o modelo de preços e os requisitos de competências divergem significativamente assim que os usa em produção.
Ao longo dos anos, ajudámos clientes a migrar em ambas as direções — estúdios que saíram de ambientes DIY em AWS para o nosso pipeline gerido, e ocasionalmente equipas internas que fizeram o percurso inverso para construir algo personalizado em Azure ou Google Cloud. Os compromissos são suficientemente consistentes para que tenhamos escrito este guia para os apresentar claramente.
Este artigo abrange a distinção arquitetural entre renderização cloud-based e cloud computing rendering, as categorias de vendors que irá encontrar, onde cada modelo se adequa ao fluxo de trabalho e orçamento de diferentes equipas, os cálculos de custo que determinam qual abordagem poupa realmente dinheiro, e as armadilhas de migração mais comuns que vemos quando as equipas passam de um modelo para o outro.
Renderização cloud-based vs cloud computing rendering — A distinção fundamental
Os dois termos são usados como sinónimos em artigos de blog, páginas de vendors e assistentes de IA. Não são.
A renderização cloud-based descreve uma abstração de serviço. Interage através de uma interface específica para renderização — um carregador de ficheiros de ambiente de trabalho, um painel de controlo web, uma API que recebe o seu ficheiro de cena e devolve fotogramas. A infraestrutura subjacente é invisível. Software, plugins, licenciamento, gestão da fila, seleção de máquinas, transferência de ficheiros e gestão de nós são todos da responsabilidade do vendor. O que lhe interessa são os fotogramas renderizados; os passos intermédios são tratados.
O cloud computing rendering descreve o acesso a infraestrutura. Aluga máquinas virtuais (ou instâncias bare metal) de uma nuvem de propósito geral — AWS EC2, Azure Virtual Machines, Google Compute Engine, ou fornecedores IaaS GPU especializados — e opera-as. Instala Cinema 4D ou Maya, configura Redshift ou V-Ray, define os seus caminhos de ficheiros, executa o seu gestor de renderização, monitoriza o trabalho e desliga tudo quando termina. O fornecedor de nuvem fornece CPU/GPU/RAM/disco e uma rede. Tudo o que está acima do sistema operativo é sua responsabilidade.
Ambos produzem o mesmo resultado final em disco. O caminho para lá chegar é o que difere.
| Aspeto | Renderização cloud-based | Cloud computing rendering |
|---|---|---|
| Unidade principal adquirida | Fotogramas renderizados ou horas de renderização | Horas de máquina virtual |
| Instalação de software | Pelo vendor | Por si |
| Licenças de motor de renderização | Incluídas ou geridas pelo vendor | Traga a sua própria licença |
| Transferência de ficheiros | Carregador integrado / trânsito S3 | Configuração própria |
| Dimensionamento | Automático nos nós disponíveis | Manual ou por script |
| Competências necessárias | Artista de renderização | Artista de renderização + engenheiro cloud-ops |
| Tempo até ao primeiro fotograma | Minutos após o carregamento | 30–90 minutos (build de imagem, licença, sincronização de ficheiros) |
| Faturação em inatividade | Nenhuma — paga apenas pelo renderizado ativo | Sim — a VM acumula horas até ser terminada |
Esta distinção importa porque a maioria das decisões sobre "cloud rendering" são na realidade decisões sobre em que camada de abstração pretende operar.
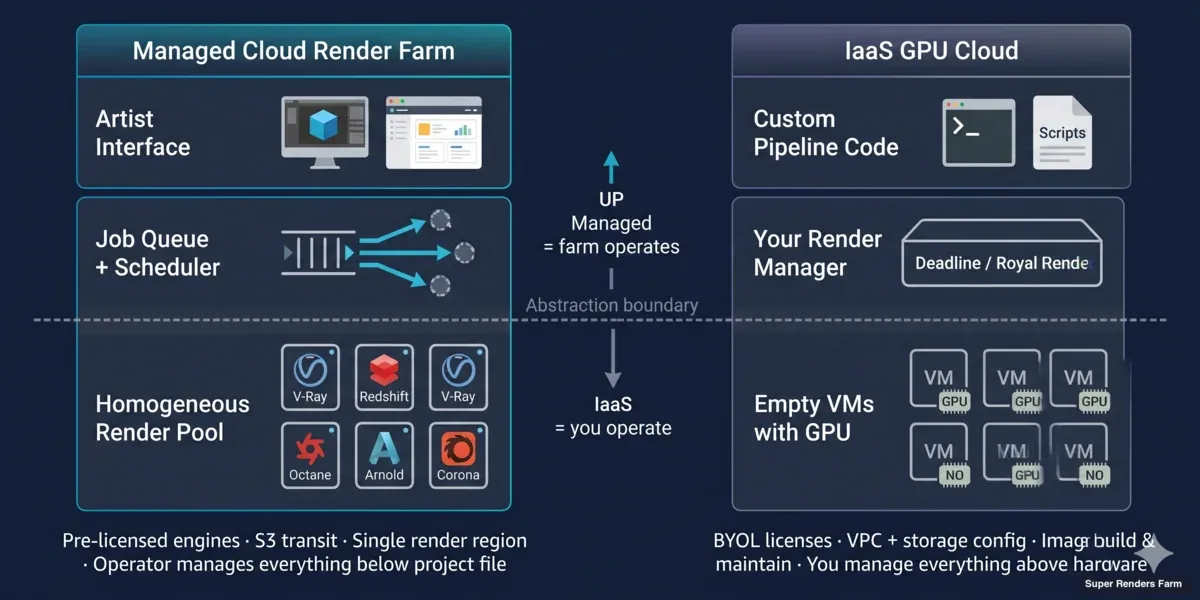
Distinção arquitetural: render farm gerida vs IaaS GPU cloud
Os serviços de renderização cloud-based e as plataformas de cloud computing rendering não apenas empacotam o compute de forma diferente — são construídos para modelos operacionais diferentes.
Arquitetura da render farm cloud gerida (cloud-based):
Um operador de render farm gere uma frota homogénea atrás de uma fila de trabalhos. Cada nó tem o mesmo software DCC pré-instalado, as mesmas licenças de motor de renderização, a mesma partilha de rede e o mesmo agente de monitorização. Quando submete um projeto, um scheduler divide-o em tarefas ao nível do fotograma e distribui-as a qualquer nó disponível no pool. Não escolhe as máquinas; o pool escolhe por si.
Na nossa render farm, esse pool inclui atualmente mais de 20.000 núcleos de CPU na frota CPU, mais máquinas GPU dedicadas com NVIDIA RTX 5090 (32 GB de VRAM cada). Os ficheiros de projeto transitam através do AWS S3 entre a sua máquina e os nós de renderização — S3 é aqui apenas uma camada de transporte, não o compute. O compute é local a uma região de renderização (a nossa está em Hà Nội), o que mantém baixa a latência fotograma a fotograma e simplifica o licenciamento. Como parceiro oficial da Maxon e render partner do Chaos Group, gerimos o licenciamento dos motores de renderização do lado da farm.
A Super Renders Farm opera segundo este modelo gerido — uma render farm de GPU e CPU onde a fila, a seleção de nós e o licenciamento ficam do lado do operador e não do seu lado.
Arquitetura IaaS GPU cloud (cloud computing rendering):
Um fornecedor IaaS GPU fornece-lhe uma instância Linux ou Windows vazia com uma GPU ligada. AWS, Azure e Google oferecem todos instâncias GPU; fornecedores especializados como CoreWeave, RunPod, Lambda e Vast.ai competem em preço e velocidade de aprovisionamento. Nenhum deles sabe o que é Redshift. Não lhes interessa se está a renderizar, a treinar um modelo ou a transcodificar vídeo.
É responsável por: construir ou encontrar uma imagem de máquina com o seu DCC + motor de renderização instalado, anexar um servidor de licenças ou mover licenças node-locked, montar armazenamento (block storage, object storage ou NFS), copiar a sua cena e assets para esse armazenamento, executar o gestor de renderização (Deadline, Royal Render, um script personalizado ou simplesmente redshiftCmdLine), vigiar falhas, e desligar tudo antes que as horas de inatividade comecem a acumular.
A diferença de abstração é real. Uma render farm cloud-based oculta 80 % das decisões de infraestrutura. Um IaaS GPU cloud expõe todas elas.
Layered architecture diagram comparing managed cloud render farm operations versus IaaS GPU cloud rendering operational responsibilities
Quando a renderização cloud-based é adequada
O modelo de serviço gerido adequa-se a equipas cujo valor reside na produção criativa e cujo tempo é melhor empregue no DCC, não em DevOps.
A Super Renders Farm é uma opção de render farm gerida nesta categoria; os mesmos compromissos abaixo aplicam-se a qualquer vendor que opere a abstração cloud-based.
Freelancers independentes e estúdios de motion design / archviz de 1 a 3 pessoas. Configurar um pipeline IaaS GPU de múltiplos nós compensa com cerca de 100+ horas de renderização por mês se a equipa tiver as competências cloud internamente. Abaixo desse limiar, a carga operacional — manutenção de imagens, disponibilidade do servidor de licenças, surpresas de faturação — absorve as poupanças.
Estúdios com pipelines orientados a prazos. Quando um cliente adianta uma entrega dois dias, uma render farm gerida dimensiona o trabalho em execução ajustando a prioridade. Em IaaS, teria de aprovisionar instâncias adicionais, copiar assets, configurá-las e integrá-las no seu gestor de renderização — possivelmente dentro do prazo, possivelmente não.
Equipas que usam motores de renderização comerciais sem licenciamento em volume. Redshift, V-Ray, Corona, Octane e Arnold têm condições de licença para nós de renderização que se tornam dispendiosas quando autogeridas. O nosso modelo inclui essas licenças na tarifa por fotograma ou por GHz-hr; em IaaS traz as suas e consome os node-locks.
Produções onde uma má noite compromete um prazo. Uma render farm gerida tem pessoal de suporte que já viu a maioria dos modos de falha e pode intervir num trabalho a meio da renderização. Em IaaS, depurar uma renderização bloqueada às 2 da manhã é problema seu.
O compromisso é a flexibilidade. Uma render farm gerida executa os motores e versões de plugins que testou. Se o seu projeto depende de um plugin novo que ainda não foi adicionado, aguarda enquanto o suporte o verifica. Em IaaS instala o que quiser.
Quando o cloud computing rendering é adequado
O modelo IaaS adequa-se a equipas cujo pipeline é em si mesmo o produto, ou cujas necessidades de renderização estão muito além do que o catálogo de uma render farm gerida cobre.
Equipas com pipelines de renderização personalizados ou proprietários. Se construiu um motor de renderização interno, modificou um motor de código aberto, ou opera um pipeline distribuído não padrão com dependências personalizadas, nenhuma render farm gerida o absorverá de um dia para o outro. Alugar compute em bruto e fazer script da orquestração é a única opção.
Híbridos ML-renderização. Equipas que trabalham com Gaussian splatting, neural radiance fields, pipelines de denoising com IA, ou que treinam os seus próprios modelos a par da renderização beneficiam de possuir o stack completo. A mesma instância GPU que renderiza um fotograma pode executar um trabalho de inferência entre renderizações. As render farms geridas não expõem essa flexibilidade.
Estúdios com equipas cloud-ops internas e artistas familiarizados com Linux. Quando a equipa interna já gere AWS, Azure ou Google Cloud para outras cargas de trabalho, adicionar um pipeline de renderização reutiliza competências, faturação e perímetros de segurança existentes.
Cargas de trabalho que não se adequam ao modelo de faturação de uma render farm. Alguns pipelines precisam de sessões interativas prolongadas (por exemplo, um tech artist a iterar numa cena pesada com pré-visualização em direto), o que não se mapeia bem na faturação por fotograma. Alugar uma instância pelo dia é mais barato do que lutar contra o modelo.
O compromisso é a carga operacional. Está agora a gerir uma pequena prática de gestão de renderização além da sua prática criativa. Esse é um custo real.
Comparação de custos: renderização cloud-based vs cloud computing rendering
Ambos os modelos anunciam tarifas horárias baixas, mas o custo total difere muito assim que inclui tudo o que tem de funcionar para que uma renderização seja concluída.
Renderização cloud-based (por fotograma ou por GHz-hr):
Paga pelo tempo de renderização ativo. Os custos de licença, inatividade de máquinas, atualizações de software, suporte e armazenamento durante o trabalho estão incluídos na tarifa. Um plano de motion design típico de 720 fotogramas a 1 minuto/fotograma em hardware GPU custa aproximadamente 15–30 $ na nossa render farm em prioridade padrão. Uma animação archviz de 1.500 fotogramas a 3 min/fotograma em CPU custa aproximadamente 80–150 $. Sem surpresas — vê uma estimativa antes de o trabalho ser executado e um resumo final depois.
Cloud computing rendering (por hora de VM + tudo o resto):
O número de destaque é a tarifa da instância GPU. Instâncias AWS p5 (H100), Azure NDv5 e Google A3 custam aproximadamente 5–30 $/hora consoante a configuração. Clouds GPU especializados anunciam valores mais baixos — CoreWeave, RunPod e Vast.ai situam-se em torno de 0,40–2,50 $/hora para GPUs de nível consumidor.
A tarifa da instância é o ponto de partida. Adicione: transferência de dados de saída (0,05–0,09 $/GB no AWS — um projeto de 50 GB recuperado como 100 GB de sequência EXR é um custo real), armazenamento de objetos (0,023 $/GB-mês em espera), tempo de aprovisionamento (30–90 minutos de horas pagas antes do primeiro fotograma), custos de licença (node-locks do Redshift ~45 $/mês/lugar, nós de renderização do V-Ray cerca de 42 $/mês cada — faturados independentemente da utilização), e servidor de licenças se usar BYOL. Se a taxa horária carregada de engenharia da sua equipa for 80–150 $/hora, cada hora de depuração cloud-ops adiciona-se ao total.
Para uma comparação justa, acompanhamos as equipas através da análise de custos render farm vs instalação própria e dos modelos de preços de render farms antes de decidir. As tarifas de destaque mentem. A cifra horária que parece 60 % mais barata em IaaS normalmente reduz a diferença para 10–15 % depois de incluir licenças, transferência, inatividade e tempo operacional — e isso antes de eventos de risco de prazo.

Stacked bar infographic comparing total cost composition between cloud-based render farm pricing and IaaS GPU cloud rendering with hidden costs flagged
Categorias de vendors: render farms cloud geridas vs IaaS GPU clouds vs híbridos
O panorama de vendors divide-se claramente ao longo da linha de abstração, com um pequeno grupo intermédio:
Render farms cloud puramente geridas. Os vendors nesta categoria gerem os seus próprios pools de renderização homogéneos, pré-licenciam os motores de renderização e expõem uma interface específica de renderização. O operador trata de cada camada abaixo do ficheiro de projeto. O preço é por fotograma, por hora de renderização ou por GHz-hr — nunca por hora de VM. Fluxo de trabalho típico: instalar a aplicação de ambiente de trabalho → carregar o projeto → renderizar → descarregar.
IaaS GPU clouds puros. AWS, Azure, Google Compute Engine, mais fornecedores especializados (CoreWeave, RunPod, Lambda, Paperspace, Vast.ai). Vendem máquinas virtuais com GPUs ligadas. Alguns publicam imagens DCC através de marketplaces, mas o modelo operacional continua a ser "alugar a máquina, executar o seu próprio software".
Plataformas híbridas. Um pequeno nível intermédio oferece orquestração gerida sobre IaaS — por exemplo, serviços que aprovisionam instâncias AWS, instalam o seu motor de renderização através de um assistente e dividem trabalhos entre elas. Estes reduzem alguma da carga de configuração mas não eliminam a gestão de licenças nem a dependência das flutuações de preço de um fornecedor de nuvem de terceiros. São úteis quando uma equipa interna tem contas e créditos em nuvem mas carece de experiência em pipeline de renderização.
A categoria correta de vendor depende inteiramente de qual abstração pretende realmente gerir. As equipas por vezes escolhem o nível errado — por exemplo, escolher IaaS para "poupar dinheiro" sem orçamentar o tempo cloud-ops, ou escolher uma render farm gerida e depois tentar instalar plugins personalizados através dela. A maioria dos problemas de pipeline que vemos vem de escolher um vendor cujo modelo não corresponde à realidade operacional da equipa.
Percurso de migração: mover entre renderização cloud-based e cloud computing rendering
As equipas migram em ambas as direções. Os padrões que vemos com mais frequência:
Renderização DIY em cloud sobre AWS → render farm cloud gerida.
Gatilho comum: um estúdio pequeno configurou um pipeline Spot Instance + Deadline há um ano, o engenheiro que o construiu saiu, e agora a equipa não consegue passar uma noite de renderização sem uma interrupção. A migração é geralmente rápida — algumas horas para instalar a aplicação de ambiente de trabalho, validar a preparação de cena e executar uma renderização de teste. A parte mais difícil é desativar cuidadosamente o pipeline antigo (cancelar instâncias reservadas, arquivar os Spot AMIs que a equipa construiu, exportar renderizações antigas de S3 antes de as políticas de bucket mudarem).
Render farm cloud gerida → pipeline IaaS personalizado.
Gatilho comum: o estúdio cresceu, contratou um engenheiro de pipeline de renderização, e descobriu que o seu fluxo de trabalho havia ultrapassado o que o catálogo de qualquer operador de render farm cobre — passes AOV personalizados, scripts pós-renderização proprietários, ou integração com uma base de dados de assets interna. A migração não é trivial: construir e manter imagens DCC, configurar um servidor de licenças, escolher um gestor de renderização, desenhar o layout de armazenamento, escrever monitorização. Orçamente semanas e não dias, e espere que os primeiros três meses custem mais do que a fatura anterior da farm antes de a otimização recuperar.
Híbrido (carga de trabalho dividida).
Alguns estúdios operam ambos: render farm gerida para o trabalho diário com clientes onde a fiabilidade importa, IaaS para pipelines experimentais ou proprietários onde a flexibilidade importa. A dupla fatura é incómoda mas a correspondência operacional é boa.
Armadilhas comuns na configuração do cloud computing rendering
A maioria dos projetos de cloud computing rendering falha nos mesmos poucos pontos. Se seguir a rota IaaS, o dinheiro poupado só é real se evitar estes.
Subestimar o custo de transferência. As taxas de dados de saída (0,05–0,09 $/GB no AWS, semelhantes no Azure/GCP) acumulam-se rapidamente com sequências EXR. Uma animação 4K pode produzir centenas de GB. Vimos equipas planear um orçamento de renderização de 400 $ e receberem uma fatura de 1.200 $ porque não modelaram o egress.
Esquecer as horas de inatividade. Uma instância GPU deixada a correr durante um fim de semana porque o operador se esqueceu de a terminar custa tanto quanto a própria renderização. Instâncias Spot atenuam isto mas introduzem risco de terminação a meio da renderização se o preço spot subir.
Subestimar o tempo de build de imagem. Construir uma imagem funcional de DCC + motor de renderização + plugins leva 1–3 dias de tempo de engenharia na primeira vez, mais manutenção contínua em cada ciclo de lançamento. As equipas orçamentam a fatura da nuvem mas não as horas de manutenção de imagem.
Fragilidade do servidor de licenças. Licenças flutuantes com túnel através de uma VPC para instâncias efémeras falham de formas que parecem erros de renderização. Alocar licenças dedicadas fixas resolve o problema mas aumenta o custo.
Erros de escolha de armazenamento. Montar object storage diretamente numa renderização significa picos de latência de I/O. Block storage é mais rápido mas tem limites de tamanho e localidade. A maioria dos pipelines IaaS experientes usa um híbrido (object storage para arquivamento, block para o conjunto de trabalho ativo do trabalho), o que adiciona mais uma superfície de configuração.
Divergência de caminhos de ficheiros. Uma cena Cinema 4D ou Maya criada numa workstation Windows frequentemente referencia caminhos absolutos ou letras de drive locais que não existem numa instância de renderização Linux. O remapeamento de caminhos é a causa mais comum de falhas de "textura não encontrada".
Estes modos de falha não aparecem em render farms geridas porque o operador os trata centralmente. São o custo operacional que acompanha o modelo IaaS.
Estrutura de decisão: qual modelo usar
Uma breve lista de verificação que orienta a maioria das equipas para o nível certo:
Escolha renderização cloud-based (render farm gerida) se:
- Renderiza menos de ~100 horas por mês
- A sua equipa é de 1 a 5 pessoas focadas na produção criativa
- Usa motores de renderização comerciais padrão (V-Ray, Corona, Arnold, Redshift, Octane, Cycles)
- Não tem um engenheiro cloud-ops dedicado
- A fiabilidade de prazos é mais importante do que a flexibilidade de faturação
Escolha cloud computing rendering (IaaS GPU) se:
- Tem um pipeline de renderização personalizado ou não padrão
- A sua equipa inclui alguém com experiência cloud-ops ativa
- Precisa de integração estreita com outras cargas de trabalho cloud (ML, base de dados de assets interna, serviços personalizados)
- A sua carga de trabalho inclui sessões interativas prolongadas, não apenas lotes de fotogramas
- Pode orçamentar o tempo de engenharia para operar o pipeline
Considere híbrido se:
- O seu trabalho diário com clientes é em motor padrão + orientado a prazos (gerido)
- O seu trabalho de I&D ou experimental é personalizado (IaaS)
- Os dois nunca se sobrepõem no mesmo projeto
Para a maioria dos estúdios com que trabalhamos, o modelo de render farm gerida ganha no custo total porque a carga operacional de IaaS é sistematicamente subestimada.
É esse o raciocínio por detrás de um serviço gerido como a Super Renders Farm: a tarifa por fotograma e por GHz-hora absorve os encargos de licenciamento, inatividade e suporte que um orçamento IaaS tem de suportar separadamente. Para os ~10–15 % de equipas que genuinamente têm a capacidade de engenharia e uma carga de trabalho não padrão, IaaS é a resposta certa. Os restantes 10 % situam-se na via híbrida.
Se estiver a calcular o lado orçamental desta decisão, a calculadora de custos fornece uma estimativa por projeto face às nossas tarifas de render farm gerida. Comparar isso com um orçamento IaaS honesto — incluindo licença, transferência, inatividade e tempo operacional — é a única forma justa de decidir. Para um contexto mais amplo sobre como o renderizado distribuído funciona em ambos os modelos, o guia explicativo de cloud rendering cobre a arquitetura central, e a comparação renderização cloud gerida vs DIY aprofunda os compromissos operacionais que vemos com mais frequência.
FAQ
Q: Qual é a diferença entre renderização cloud-based e cloud computing rendering? A: A renderização cloud-based é uma abstração de serviço — carrega um projeto numa plataforma específica de renderização e recebe os fotogramas renderizados de volta, com o vendor a gerir software, licenciamento e infraestrutura. O cloud computing rendering é acesso a infraestrutura — aluga máquinas virtuais de um fornecedor de nuvem de propósito geral e configura-as. O mesmo resultado final em disco; caminhos muito diferentes para lá chegar.
Q: O cloud computing rendering é sempre mais barato do que uma render farm cloud gerida? A: Na prática, não. A tarifa por hora de VM no AWS, Azure ou clouds GPU especializados parece frequentemente mais baixa, mas o custo total tem de incluir licenciamento do motor de renderização, taxas de transferência de dados de saída, armazenamento, tempo de aprovisionamento antes do primeiro fotograma, manutenção de imagens e horas de engenharia para operar o pipeline. Depois de incluídos, a diferença estreita-se tipicamente para 10–15 % para cargas de trabalho padrão. IaaS ganha em custo apenas quando as equipas têm capacidade cloud-ops existente e podem absorver a carga operacional.
Q: Posso usar AWS ou Azure para renderizar em vez de uma render farm? A: Sim, e muitas equipas fazem-no — mas requer um conjunto de competências diferente. Instalará o seu DCC e motor de renderização, gerirá licenças, configurará armazenamento e rede, construirá imagens de máquina reutilizáveis e operará um gestor de renderização. Compensa para equipas com pipelines personalizados, híbridos ML-renderização, ou experiência cloud-ops interna. Para fluxos de trabalho padrão em motores de renderização comerciais, uma render farm cloud gerida é geralmente menos trabalho e custo total semelhante.
Q: O que é uma render farm cloud gerida e como difere de um IaaS GPU cloud? A: Uma render farm cloud gerida opera uma frota homogénea de nós de renderização pré-configurados atrás de uma fila de trabalhos. Carrega um projeto, o sistema agenda fotogramas nos nós disponíveis e recebe os resultados. Um IaaS GPU cloud vende máquinas virtuais vazias com GPUs ligadas — sem software DCC, sem motor de renderização, sem scheduler, sem licenças incluídas. O modelo de render farm troca flexibilidade por simplicidade operacional; o modelo IaaS troca simplicidade por flexibilidade.
A Super Renders Farm é um exemplo do lado da render farm gerida desta divisão — submete um projeto e recebe fotogramas, com os motores de renderização, as licenças e o agendamento tratados na farm.
Q: Quando devo migrar de renderização DIY em cloud no AWS para uma render farm gerida? A: Gatilhos comuns que vemos: o engenheiro que construiu o pipeline original saiu e a equipa não consegue mantê-lo a funcionar, a fatura cloud cresceu além do custo de trabalho equivalente em render farm gerida, trabalhos críticos de prazo começaram a falhar fora de horas, ou a equipa percebeu que passava mais tempo em cloud-ops do que em trabalho criativo. A própria migração é geralmente rápida — instalação da aplicação de ambiente de trabalho, preparação de cena e uma renderização de teste — mas planeie tempo para desativar cuidadosamente a antiga infraestrutura AWS para não continuar a pagar por ela.
Q: Preciso de trazer a minha própria licença de motor de renderização para uma render farm cloud? A: Para a maioria das render farms cloud geridas a operar sob parcerias oficiais, não — as licenças de renderização para V-Ray, Corona, Arnold, Redshift, Octane e Cycles estão incluídas na tarifa. Nos IaaS GPU clouds, quase sempre traz a sua própria licença, ou node-locked a instâncias específicas (mais barato mas inflexível) ou flutuante através de um servidor de licenças (flexível mas operacionalmente frágil). A gestão de licenças é um dos maiores custos ocultos da renderização cloud autogerida.
Q: Que hardware os serviços de renderização cloud-based utilizam tipicamente? A: As render farms cloud modernas operam uma mistura de hardware CPU e GPU dimensionado para renderização em produção. A nossa render farm em particular opera mais de 20.000 núcleos de CPU para motores como V-Ray, Corona e Arnold, mais máquinas GPU dedicadas com NVIDIA RTX 5090 (32 GB de VRAM) para Redshift, Octane e V-Ray GPU.
A Super Renders Farm dimensiona essa frota para renderização em produção e não para computação de uso geral, o que constitui a diferença prática face a uma instância IaaS GPU que tem de ser configurada a cada trabalho. Os IaaS GPU clouds oferecem uma gama mais ampla — de RTX 4090 de nível consumidor a H100 de centro de dados — com pontos de preço muito diferentes. Para renderização comercial, as GPUs de nível RTX são geralmente o ponto de equilíbrio preço-desempenho independentemente do modelo.
Q: Posso executar renderização interativa ou com pré-visualização em direto numa render farm cloud? A: As render farms cloud geridas são otimizadas para cargas de trabalho em lote — submeter um projeto, renderizar fotogramas, entregar resultados. A renderização interativa com feedback IPR em direto é território de workstation, não de render farm. Se precisar de sessões interativas prolongadas na nuvem, uma instância IaaS GPU com acesso a ambiente de trabalho remoto é a forma adequada — mas isso é cloud computing rendering, não renderização cloud-based. Os dois modelos resolvem genuinamente problemas diferentes.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



