
클라우드 렌더팜에서의 Octane: GPU 렌더링, OctaneBench 가격, 2026년 DCC 지원
개요
소개
OctaneRender는 명확한 평판을 가지고 있습니다. 물리적으로 정확하고, 스펙트럼 기반이며, 적합한 하드웨어에서 빠릅니다. 또한 이 엔진에 관한 모든 결정을 좌우하는 하나의 엄격한 규칙이 있습니다. GPU에서만 작동하며 다른 방법은 없습니다. 바로 이 단일 제약 조건이 Octane을 잘 갖춰진 머신에서는 사용하기 즐거우면서도, 렌더팜 전반에 걸쳐 확장하기에는 실질적인 도전 과제로 만듭니다.
저희는 GPU 렌더팜에서 V-Ray, Corona, Arnold 같은 CPU 엔진과 함께 Octane 작업을 처리합니다. GPU 부문(Octane, Redshift, V-Ray GPU)은 전체 작업량에서 의미 있고 꾸준히 성장하는 비중을 차지하고 있으며, 수천 건의 작업을 통해 이 엔진이 빛을 발하는 곳과 문제가 생기는 곳을 파악하게 되었습니다.
이 가이드는 클라우드에서 OctaneRender를 규모에 맞게 운영하는 실제 현실을 다룹니다. GPU 전용 렌더링이 렌더팜의 작동 방식을 어떻게 바꾸는지, OctaneBench-시간 가격이 어떻게 작동하며 왜 단순한 카드 시간 요금보다 더 정직한 단위인지, 어떤 3D 애플리케이션이 Octane과 잘 어울리는지, 그리고 무거운 씬을 업로드하기 전에 VRAM을 어떻게 고려해야 하는지를 설명합니다. 마케팅 문구 없이, 실제 작동 방식만을 다룹니다.
OctaneRender가 다른 이유: GPU 전용, 비편향, 스펙트럼 기반
OctaneRender는 OTOY의 비편향, 스펙트럼 정확도 패스 트레이서입니다. "비편향"이란 실제 빛의 전파를 근사하는 것이 아니라 시뮬레이션함으로써 물리적으로 올바른 결과로 수렴한다는 의미입니다. "스펙트럼"이란 단순한 RGB가 아닌 전체 광 스펙트럼에 걸쳐 색상을 계산한다는 것으로, Octane 렌더링이 그토록 깔끔하게 보이는 이유 중 하나입니다. 렌더팜 논의에서 핵심적인 사실은 이 엔진이 요구하는 하드웨어입니다.
Octane은 CUDA와 NVIDIA OptiX 레이 트레이싱 API를 통해 NVIDIA GPU에서만 작동합니다. CPU 렌더링 모드는 없습니다. 폴백으로도, 하이브리드 옵션으로도, 오버플로 경로로도 존재하지 않습니다. 씬이 GPU에서 실행될 수 없다면 Octane에서는 전혀 실행되지 않습니다. 이는 CPU 또는 하이브리드 경로를 제공하는 V-Ray나 Redshift와 다릅니다. 또한 AMD GPU와 Apple Silicon은 지원되지 않습니다. Octane은 CUDA가 필요하고, CUDA는 NVIDIA 전용입니다. 저희 GPU 플리트는 각 32GB VRAM을 탑재한 NVIDIA RTX 5090 카드를 기반으로 구축되어 있습니다. Octane과 다른 GPU 엔진이 요구하는 바로 그 사양입니다.
RTX 세대 카드(Ampere, Ada, 그리고 현재의 Blackwell)에서 Octane은 하드웨어 가속 레이 트레이싱에 OptiX를 사용합니다. 소프트웨어 에뮬레이션이 아닌 RT 코어에서의 실제 BVH 탐색입니다. 또한 누적 샘플에 대해 후처리로 동일한 GPU에서 실행되는 스펙트럼 AI 디노이저를 제공합니다. 디노이저는 주어진 시드와 샘플 수에 대해 결정론적입니다. 이는 생각보다 중요합니다. 애니메이션을 여러 노드에 분산할 때, 디노이저가 46번 프레임과 미묘하게 다르게 보이는 47번 프레임을 만들어내는 것을 원하지 않기 때문입니다.
한 가지 사항이 다른 어떤 것보다 더 많은 혼란을 일으킵니다. 아웃오브코어 메모리입니다. Octane은 텍스처가 VRAM을 초과할 때 PCIe 버스를 통해 시스템 메모리에서 텍스처를 페이징할 수 있으므로, 무거운 텍스처 세트를 가진 씬도 렌더링할 수 있습니다. 단, PCIe 대역폭이 카드의 온보드 GDDR7 대역폭의 일부에 불과하므로 성능 비용이 발생합니다. 아웃오브코어가 커버하지 못하는 것은 지오메트리입니다. 삼각형 데이터와 BVH 가속 구조는 VRAM에 맞아야 합니다. 지오메트리만으로 카드의 메모리를 초과하는 씬은 렌더링되지 않습니다. "아웃오브코어는 무제한 씬 크기를 의미한다"고 가정하기 전에, 그렇지 않다는 점을 분명히 해두겠습니다. 이는 유연한 텍스처와 엄격한 지오메트리 상한을 의미합니다.
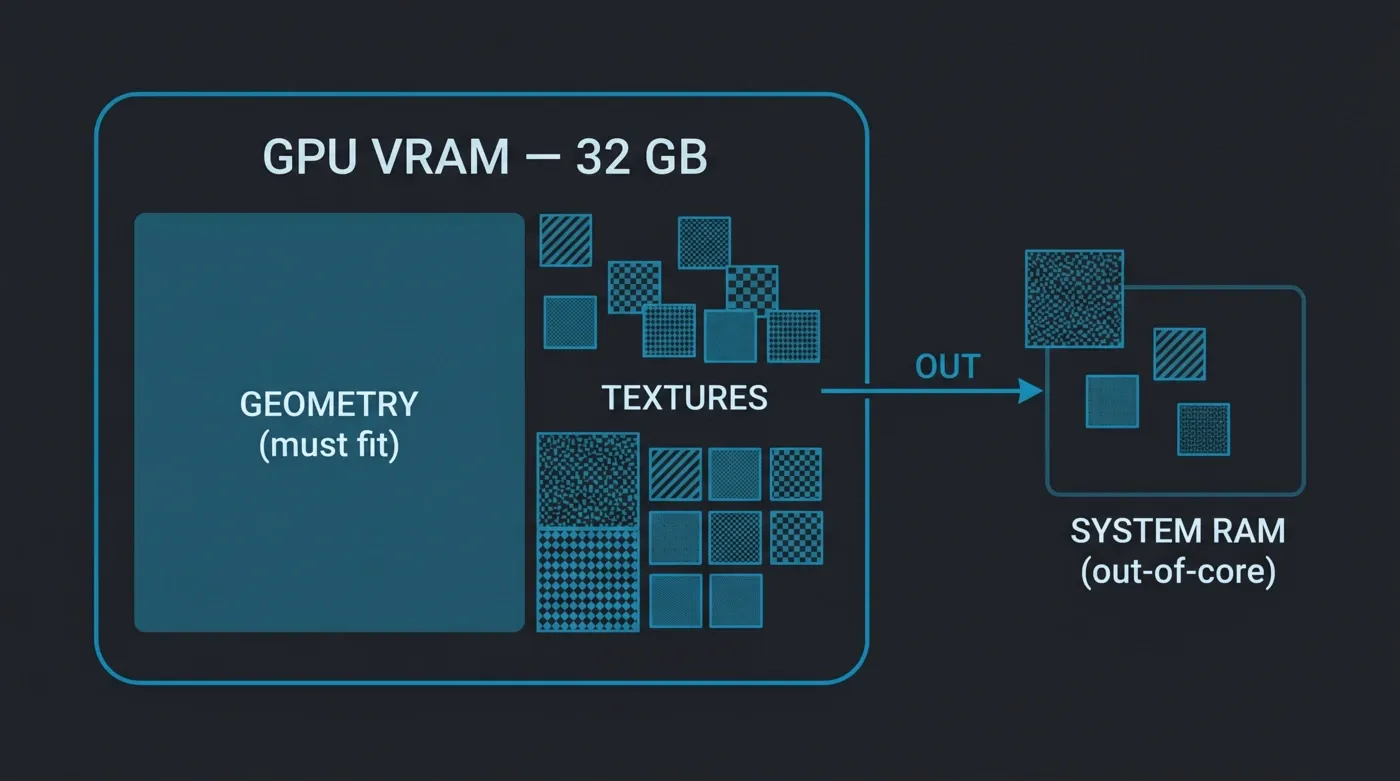
Octane 아웃오브코어 메모리: 지오메트리는 32GB GPU VRAM 내에 맞아야 하며, 텍스처는 시스템 RAM으로 넘칠 수 있습니다
클라우드 렌더팜에서 Octane 실행: 실제로 까다로운 부분
CPU 렌더링을 렌더팜에 분산하는 것은 비교적 관대한 문제입니다. 프레임을 분할하고, 씬을 전송하고, 결과를 수집하면 됩니다. Octane을 이용한 GPU 렌더링은 CPU 렌더팜이 고려할 필요가 없는 제약 조건을 도입합니다.
각 GPU는 독립된 섬입니다. 애니메이션을 분산할 때 표준 모델은 프레임 분산입니다. 각 GPU는 독립적으로 서로 다른 프레임을 렌더링합니다. 이는 거의 선형적으로 확장됩니다. 카드가 두 배가 되면 시간당 프레임도 대략 두 배가 됩니다. Octane에는 여러 GPU가 하나의 프레임에서 협력하는 네트워크 렌더링 모드가 있지만, 이는 오버헤드가 높은 다른 워크플로입니다. 렌더팜 모델은 카드당 하나의 프레임입니다. 실질적인 결과: 인접한 카드에서 VRAM을 빌릴 수 없기 때문에 모든 노드가 자체 32GB에 전체 씬을 수용할 수 있어야 합니다.
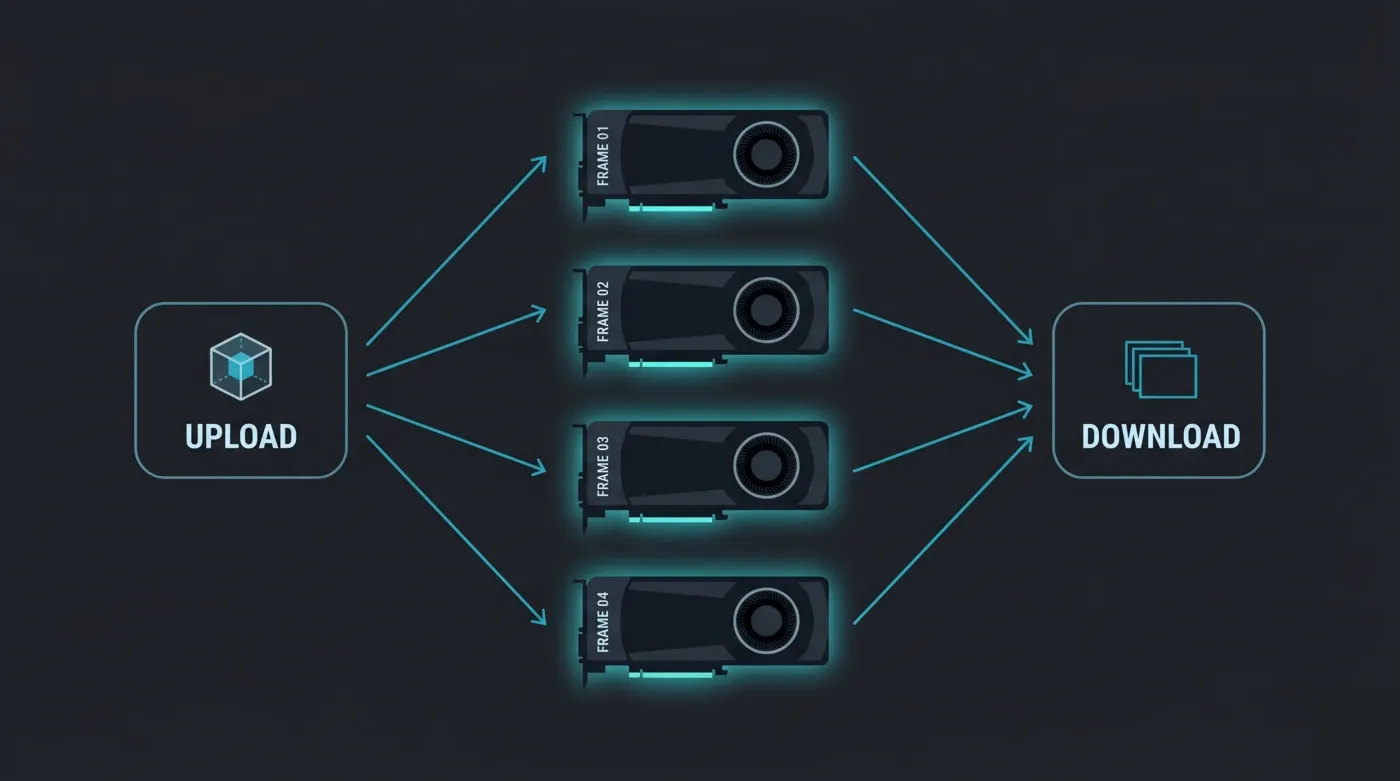
Octane 렌더팜 프레임 분산: 각 RTX 5090 GPU 노드가 서로 다른 애니메이션 프레임을 독립적으로 렌더링한 후 완성된 프레임을 다운로드를 위해 수집합니다
드라이버 및 버전 매칭은 화려하지 않지만 매우 중요합니다. Octane은 CUDA 드라이버 버전에 엄격하며, DCC의 Octane 플러그인은 렌더팜의 Octane 코어 빌드와 일치해야 합니다. 플리트 전반에 걸친 드라이버 불일치는 충돌 또는 더 나쁜 경우 노드 간 조용한 렌더 차이를 유발할 수 있습니다. 자체 관리 IaaS 인스턴스에서는 드라이버를 고정하고 플러그인 버전을 직접 조율해야 합니다. 풀 매니지드 렌더팜에서는 플리트가 지원되는 Octane 빌드에 버전이 잠겨 있으며, 엔진 라이센스(Octane 포함)가 요금에 번들로 포함되어 있어 설치하거나 활성화할 것이 없습니다.
애셋은 프레임이 할당될 수 있는 모든 곳에 있어야 합니다. 씬이 기대하는 정확한 경로에서 어느 노드든 프레임을 처리할 수 있도록 모든 텍스처, HDRI, 참조된 파일에 접근할 수 있어야 합니다. 관리형 파이프라인은 업로드한 프로젝트에서 해당 애셋을 해석하고 배포합니다. DIY GPU 렌더팜은 공유 스토리지 구성과 경로 재매핑을 직접 처리해야 합니다.
자체 관리 GPU 설정과 풀 매니지드 렌더팜 간의 역할 분담은 다음과 같습니다:
| 작업 | 자체 관리 / IaaS GPU 렌더팜 | 풀 매니지드 렌더팜 |
|---|---|---|
| CUDA 드라이버 관리 | 인스턴스별로 직접 패치 및 고정 | 플리트 관리, 지원되는 Octane 빌드에 잠김 |
| Octane 엔진 설치 | 모든 노드에 직접 설치 | 사전 설치, 플러그인과 버전 일치 |
| 렌더 엔진 라이센스 | 노드별로 직접 구매 및 활성화 | OBh 요금에 번들 포함 |
| 애셋 경로 해석 | 공유 스토리지 구성 / 경로 재매핑 직접 설정 | 업로드한 프로젝트에서 자동 해석 |
| 원격 데스크탑 설정 (RDP) | 노드 구성을 위해 보통 필요 | 불필요 — 렌더링이 헤드리스로 실행 |
| 프레임 분산 | 직접 조율 | 제출 라우팅으로 처리 |
마지막 행이 중요합니다. Octane 렌더팜 렌더링은 완전히 헤드리스이므로, 원격 데스크탑 단계가 없습니다. DCC에서 제출하면 렌더팜이 렌더링하므로, GPU IaaS 임대에서 여전히 부과되는 설정 마찰의 전체 범주가 제거됩니다.
OctaneBench와 OBh 가격 모델
이 부분은 대부분의 아티스트들이 명확하게 설명을 들어본 적이 없는 Octane 경제학의 핵심이므로, 천천히 살펴볼 가치가 있습니다.
OctaneBench는 OTOY의 표준화된 GPU 벤치마크입니다. 고정된 참조 씬을 렌더링하고, GPU가 기준 카드 대비 초당 얼마나 많은 Octane 작업을 수행할 수 있는지를 나타내는 단일 단위 없는 점수를 출력합니다. 점수가 높을수록 더 많은 처리량을 의미합니다. OTOY가 이를 공개하고 누구나 실행할 수 있기 때문에, Octane에 특화된 GPU 비교를 위한 신뢰할 수 있고 벤더 중립적인 방법이 되었습니다.
이 벤치마크는 또한 여기서 GPU 작업 과금의 기반이 됩니다. 저희는 GPU 렌더링을 OctaneBench-시간(OBh)당 $0.003으로 청구합니다. OctaneBench-시간은 하나의 OctaneBench 처리량 단위를 제공하는 GPU에서 1시간의 컴퓨팅을 의미합니다. OctaneBench 점수가 높은 카드는 실제 경과 시간당 더 많은 OBh를 제공하고, 느린 카드는 더 적게 제공합니다. 작업이 실제로 소비하는 OctaneBench-시간에 대해 과금됩니다.
왜 이것이 중요합니까? 단순한 카드 시간당 요금을 생각해보세요. 두 렌더팜이 모두 "GPU 시간당 $X"를 광고할 수 있지만, 하나는 최신 세대 카드를 임대하고 다른 하나는 두 세대 전 카드를 임대한다면, 매우 다른 양의 작업에 같은 시간당 가격을 지불하게 됩니다. 더 빠른 카드는 짧은 시간에 끝나고, 느린 카드는 더 많은 시간을 청구합니다. OctaneBench-시간 과금은 이를 정규화합니다. 기계를 점유한 시간이 아닌, 제공된 렌더 처리량에 대해 지불합니다. 더 빠른 카드가 더 빨리 완료되면 작업에 필요한 OBh를 소비하고 멈춥니다.
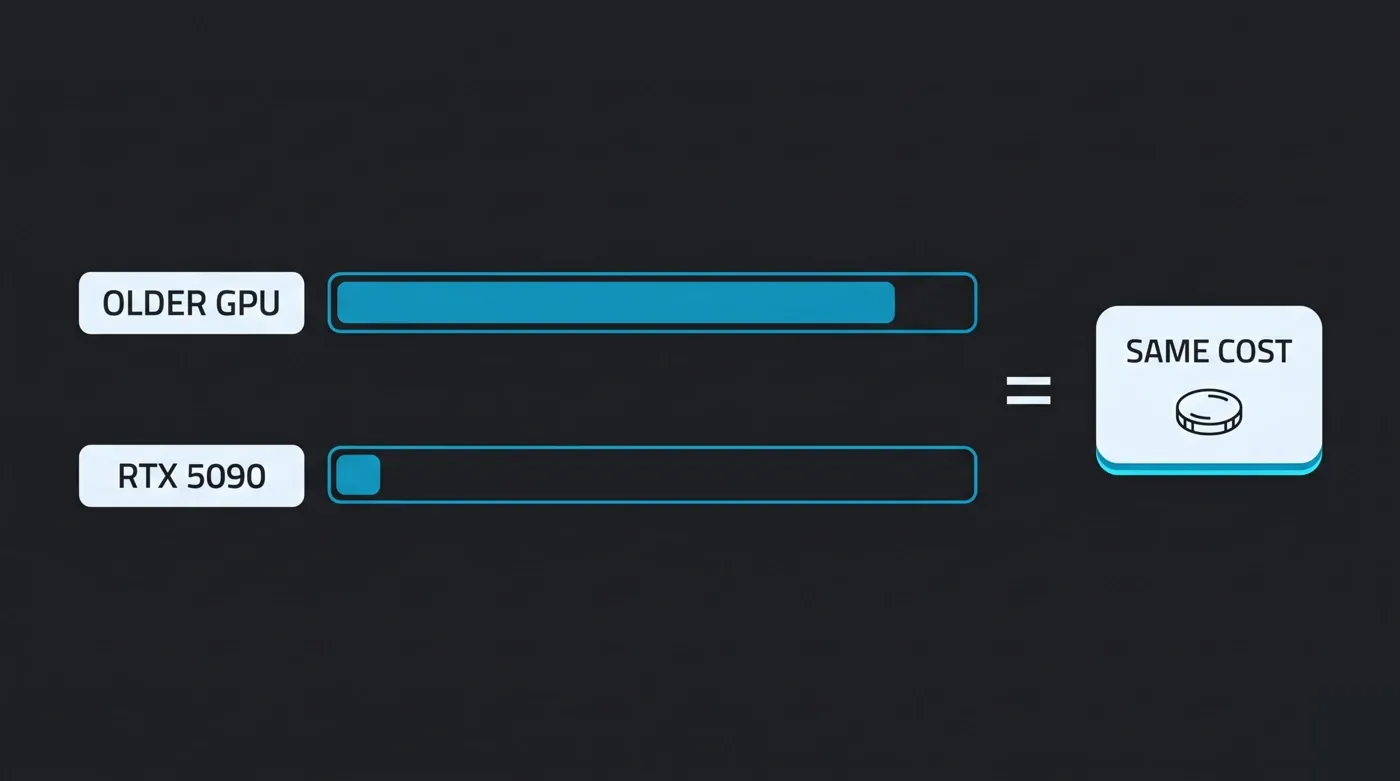
OctaneBench-시간 과금은 렌더 비용을 제공된 처리량으로 정규화합니다: 더 빠른 GPU는 더 적은 시간에 완료되므로, 카드 세대에 관계없이 동일한 작업의 비용은 같습니다
참고로, RTX 5090은 실제 경과 시간당 약 1,730 OctaneBench-시간의 처리량을 제공합니다. 이 수치는 Blackwell 아키텍처의 공개된 벤치마크와 일치하지만, 정확한 점수는 씬 복잡도와 시스템 구성에 따라 달라집니다. 고정된 핵심 수치는 요금 자체입니다: $0.003/OBh. 작업 비용 계산 방법은 다음과 같습니다:
| 항목 | 값 |
|---|---|
| 과금 요율 (공식) | $0.003 / OBh |
| RTX 5090 처리량 (예시) | 카드 시간당 약 1,730 OBh |
| 유효 카드 시간당 비용 | 약 $5.20 / 카드-시간 |
| 예시 작업: 90프레임 애니메이션, 프레임당 약 1 카드-시간 (예시) | 약 90 카드-시간 |
| 예시 총액 | 약 90 × $5.20 ≈ $468 |
이 표의 프레임당 렌더 시간과 OctaneBench 점수는 예시로 처리하세요. 두 수치 모두 씬에 따라 완전히 달라집니다. 요율이 고정된 부분입니다. 신규 계정은 $25의 무료 렌더 크레딧으로 시작하며, 크레딧은 만료되지 않으므로 전체 작업을 맡기기 전에 실제 테스트 씬을 실행하고 직접 수치를 확인할 수 있습니다. 전체 모델은 렌더팜 가격 가이드에서 설명하며, 프레임별 작업 비용 추정 방법에 대한 자세한 분석은 프레임당 비용 가이드에 있습니다.
한 가지 주의 사항을 명확히 말씀드리겠습니다. 프로바이더를 비교할 때 사람들이 자주 혼동하는 부분이 있기 때문입니다. OctaneBench-시간은 OctaneRender를 실제로 실행하지 않는 렌더팜에서도 과금 단위로 사용되는 경우가 있습니다. 벤치마크를 자신들이 제공하는 GPU 엔진의 정규화 지표로 차용하는 것입니다. Octane 지원이 구체적으로 중요하다면, 해당 렌더팜이 실제로 엔진을 실행하는지 확인하세요. 그리고 카드 시간당 견적은 어떤 카드를 임대하는지 알기 전까지는 의미가 없습니다. GPU 세대가 실제 비용을 결정하는 수치이기 때문입니다.
DCC 별 Octane 지원: Cinema 4D, Maya, 3ds Max, Houdini
Octane은 플러그인을 통해 작업에 연결되며, 이 플러그인의 성숙도는 애플리케이션마다 다릅니다. Octane이 가장 강력한 곳을 알면 이 엔진이 파이프라인에 적합한지 판단하는 데 도움이 됩니다.
Cinema 4D는 Octane의 대표적인 홈입니다. C4D용 OctaneRender 플러그인은 OTOY가 제공하는 가장 성숙하고 가장 많이 사용되는 인테그레이션으로, 네이티브 C4D 머티리얼, MoGraph 및 이펙터, 멀티패스 출력을 위한 테이크 시스템, 네이티브 모션 블러에 대한 깊은 지원을 제공합니다. Cinema 4D에서 작업하는 모션 디자이너나 제품 시각화 아티스트라면 Octane이 자연스러운 선택입니다. 또한 "프로덕션에서 Octane"을 말할 때 대부분의 사람들이 의미하는 바로 그 엔진입니다. Redshift와의 선택 문제가 가장 자주 발생하는 곳이기도 합니다. 두 엔진을 고려 중이라면 Cinema 4D Redshift 가이드에서 그 트레이드오프를 다룹니다.
Maya는 Arnold나 Redshift에 전념하지 않고 GPU 패스 트레이싱을 원하는 VFX 및 모션 파이프라인에서 사용되는 견고한 OctaneRender 플러그인을 보유하고 있습니다. 머티리얼 네트워크, 카메라 및 라이팅 인테그레이션, Alembic 캐시가 모두 지원됩니다. C4D 조합만큼 커뮤니티가 지배적이지는 않지만 상업적으로 중요합니다.
3ds Max는 특히 건축 시각화와 제품 시각화 분야에서 Octane을 잘 실행합니다. 3ds Max 건축 시각화 시장은 여전히 V-Ray와 Corona 같은 CPU 엔진에 크게 의존하므로, 여기서 Octane은 기본 선택이 아닌 의도적인 선택입니다. 하지만 플러그인은 유능하고 머티리얼 변환도 우수합니다.
Houdini는 절차적 지오메트리를 잘 처리하는 OctaneRender 플러그인을 보유하고 있으며 VFX 작업에 등장합니다. Houdini GPU 분야에서는 SideFX의 자체 Karma XPU와 Redshift가 더 큰 비중을 차지하므로, Houdini용 Octane은 실제적이지만 작은 틈새 시장입니다. Octane이 이미 스튜디오 표준이라면 좋은 옵션입니다.
Blender 아티스트를 위한 참고 사항. Blender의 프로덕션 표준 패스 트레이서는 Cycles이며, 저희는 렌더팜에서 Blender 작업에 Cycles를 사용합니다. RTX 5090 노드에서 Cycles는 OptiX 하드웨어 레이 트레이싱을 사용하므로, 별도의 Octane 구독 없이도 Octane 작업과 동일한 하드웨어 티어에서 GPU 패스 트레이싱을 통해 비편향적, 물리 기반 출력을 얻을 수 있습니다. (EEVEE, Blender의 실시간 엔진은 전혀 다른 문제입니다. 활성 디스플레이 컨텍스트가 필요하고 헤드리스 렌더 노드에서는 실행되지 않으므로, EEVEE 씬은 업로드 전에 Cycles로 전환해야 합니다.) 특별히 Octane이 선택한 엔진이라면 Cinema 4D, Maya, 3ds Max, Houdini가 가장 적합한 환경입니다. Blender를 사용한다면 GPU에서의 Cycles가 동일한 수준의 결과를 제공합니다.
GPU 요구 사항과 Octane이 적합한 경우
Octane은 GPU에 의존하므로, 몇 가지 하드웨어 현실을 염두에 두어야 합니다.
VRAM이 가장 중요한 수치입니다. RTX 5090의 32GB가 Octane의 지오메트리 상한을 설정합니다. 전체 가구 라이브러리와 디스플레이스먼트가 적용된 건축 시각화 인테리어, 또는 밀도 높은 캐릭터 지오메트리와 볼륨이 있는 VFX 샷은 24GB 카드로 처리하기 어려운 경우가 많습니다. 24GB GPU에서 로드에 실패하는 씬이 32GB에서는 성공할 수 있습니다. 이는 구체적이고 검증 가능한 차이이며, 마케팅 문구가 아닙니다. 아웃오브코어는 그 위에 텍스처 여유 공간을 추가하지만, 지오메트리는 맞도록 계획하세요. GPU 렌더링에서 RTX 5090의 위치에 대한 자세한 내용은 RTX 5090 성능 글에서 확인할 수 있습니다.
항상 CUDA와 NVIDIA. Octane은 CUDA 지원 NVIDIA GPU(컴퓨팅 능력 5.0 이상, 현재 카드는 모두 여유 있게 충족)가 필요합니다. AMD 카드나 Apple Silicon에서 렌더링하는 것에 대한 온라인 조언은 Octane 워크플로에는 적용되지 않습니다. 엔진이 이를 사용할 수 없기 때문입니다. 이것이 NVIDIA 하드웨어로 특별히 구축된 렌더팜이 Octane의 올바른 매칭인 이유이며, 단서 조항이 없습니다.
Octane이 적합한 경우와 다른 것이 더 나은 경우는? 균형 있는 사고 방식은 다음과 같습니다:
| 상황 | 주로 맞는 엔진 | 이유 |
|---|---|---|
| GPU 기반 C4D 모션 디자인, 건축 시각화, 제품 시각화 | OctaneRender | 가장 성숙한 인테그레이션, 대규모 커뮤니티, 깔끔한 스펙트럼 출력 |
| 이미 Maxon 생태계에 있음 | Redshift | 편향 엔진, 빠른 수렴, Maxon 구독에 번들 포함 |
| Maya / VFX, GPU 우선 | Octane 또는 Redshift | 둘 다 가능; Redshift가 VFX에서 더 일반적, Octane은 모션 작업에 강점 |
| 3ds Max 건축 시각화 | V-Ray 또는 Corona (CPU) | 이 분야의 시장 기본 선택 |
| Blender, GPU 패스 트레이싱 | Cycles (OptiX) | GPU에서의 Blender 네이티브 프로덕션 표준 |
| Houdini VFX / 절차적 | Karma XPU 또는 Redshift | Houdini GPU 시장의 더 큰 비중; Octane은 보조 옵션 |
| 32GB에 근접한 지오메트리 중심 씬 | 32GB 노드의 Octane | VRAM 여유 공간 논거가 여기서 가장 강력 |
| CPU 전용 예산 또는 파이프라인 | V-Ray, Corona, Arnold (CPU) | Octane은 CPU에서 전혀 실행되지 않음 |
Octane을 포함한 GPU 렌더링이 저희 렌더팜의 전부가 아님을 명확히 말씀드려야 합니다. 저희가 처리하는 작업의 대부분은 여전히 CPU 기반으로, V-Ray와 Corona 건축 시각화 작업이 대부분의 볼륨을 차지합니다. Octane은 성장하는 GPU 세그먼트에 자리하고 있으며, 모든 것의 중심이 아닙니다. 파이프라인이 CPU 우선이라면 위에서 언급한 Octane 특화 제약 조건은 적용되지 않으며, CPU 엔진이 훨씬 더 나은 선택일 가능성이 높습니다. 이 가이드의 목적은 Octane이 그 가치를 입증하는 곳, 그리고 그렇지 않은 곳에 대해 솔직하게 이야기하는 것입니다.
FAQ
Q: Super Renders Farm은 OctaneRender를 지원합니까? A: 지원합니다. Octane은 저희 NVIDIA RTX 5090 GPU 노드(각 32GB VRAM)에서 실행되며, OctaneRender 라이센스는 렌더 요금에 포함되어 있습니다. 렌더링이 완전히 헤드리스로 실행되므로 설치하거나 활성화할 것도, 원격 데스크탑도 필요하지 않습니다.
Q: OctaneBench-시간(OBh)이란 무엇이며 가격은 어떻게 작동합니까? A: OctaneBench-시간은 OTOY의 표준화된 GPU 벤치마크인 OctaneBench의 하나의 처리량 단위를 제공하는 GPU에서 1시간의 컴퓨팅을 의미합니다. 저희는 GPU 렌더링을 OBh당 $0.003으로 청구하므로, 카드를 점유한 시간이 아닌 실제로 제공된 렌더 처리량에 대해 지불하게 됩니다. 더 빠른 GPU는 더 빨리 완료되고 작업에 필요한 OBh만 소비합니다.
Q: 렌더팜에서 Octane 렌더링을 위해 어떤 GPU가 필요합니까? A: 렌더팜에서 렌더링하는 데 자체 GPU가 필요하지 않습니다. 렌더링은 저희 RTX 5090 노드에서 이루어집니다. Octane 자체는 CUDA 지원 NVIDIA GPU가 필요합니다(AMD나 Apple Silicon에서는 실행되지 않음). 플리트가 정확히 그 하드웨어를 기반으로 구축되어 있으므로 씬이 엔진에 맞는 하드웨어에서 실행됩니다.
Q: Octane은 GPU VRAM보다 큰 씬을 렌더링할 수 있습니까? A: 부분적으로 가능합니다. Octane은 텍스처가 VRAM을 초과할 때 아웃오브코어를 통해 시스템 메모리에서 텍스처를 페이징할 수 있지만, 성능 비용이 발생합니다. 지오메트리는 다릅니다. 삼각형 데이터와 가속 구조는 VRAM에 맞아야 하므로, 지오메트리만으로 카드의 32GB를 초과하는 씬은 인스턴싱, 프록시 또는 테셀레이션 감소로 최적화할 때까지 렌더링되지 않습니다.
Q: 렌더팜에서 Octane과 함께 사용할 수 있는 3D 애플리케이션은 무엇입니까? A: Octane이 가장 많이 사용되는 환경은 Cinema 4D(대표 인테그레이션), Maya, 3ds Max, Houdini입니다. Cinema 4D는 가장 깊고 널리 사용되는 OctaneRender 플러그인을 보유하고 있으며, 나머지는 VFX, 건축 시각화, 모션 작업에 걸쳐 사용되는 성숙한 플러그인을 보유하고 있습니다.
Q: Octane으로 Blender 씬을 렌더링할 수 있습니까? A: Blender의 경우 저희는 Blender의 프로덕션 표준 패스 트레이서인 Cycles를 실행합니다. RTX 5090 노드에서 Cycles는 OptiX 하드웨어 레이 트레이싱을 사용하므로, 별도의 Octane 구독 없이 Octane 작업과 동일한 하드웨어 티어에서 GPU 패스 트레이싱을 얻을 수 있습니다. Octane이 특별히 선택한 엔진이라면 Cinema 4D, Maya, 3ds Max, Houdini가 적합합니다. Blender 아티스트는 일반적으로 Cycles를 통해 동등한 GPU 결과를 얻을 수 있습니다.
Q: 씬이 GPU에 맞지 않으면 Octane이 CPU로 폴백합니까? A: 아닙니다. OctaneRender는 GPU 전용이며 CPU 모드나 하이브리드 폴백이 없습니다. 씬이 GPU에서 실행될 수 없다면 맞도록 최적화하거나, 저희가 모두 실행하는 V-Ray, Corona, Arnold 같은 CPU 렌더링을 지원하는 엔진으로 렌더링해야 합니다.
Q: 프로젝트를 렌더팜으로 어떻게 전송하며, 렌더링 결과는 얼마나 보관됩니까? A: 프로젝트 번들을 업로드하면(tar, tar.gz, 7z 아카이브 허용; .zip은 지원하지 않음) 렌더팜이 렌더 노드로 애셋을 해석하고 배포합니다. 완성된 렌더링은 45일간 보관되며, 웹, SFTP, 또는 클라이언트 앱의 자동 다운로드를 통해 다운로드할 수 있습니다.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



