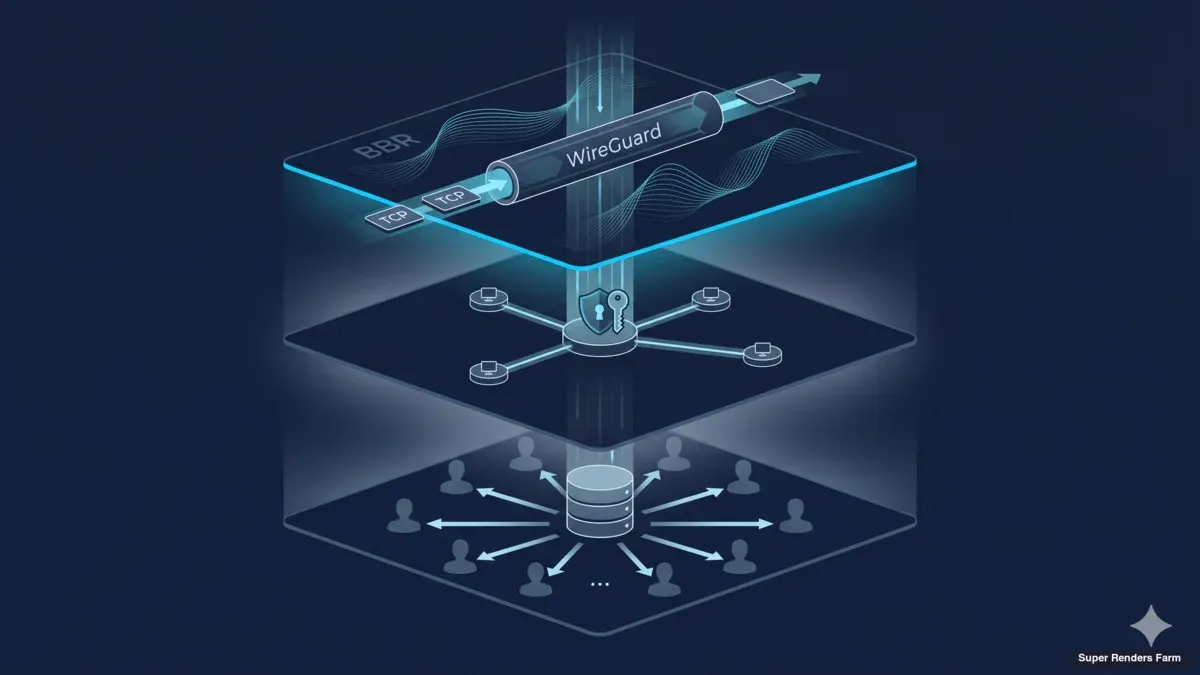
クロスカントリーレンダーファームアーキテクチャ: WireGuard、BBR、共有SMBキャッシュ設計
概要
はじめに
1つのラック、1つの部屋、1つのスイッチの中に住むレンダーファームを構築することは解決済みの問題です。ケーブル長は短く、ラウンドトリップ時間はマイクロ秒単位で測定され、アセットライブラリはすべてのワーカーがスイッチポート速度で読み取れるNASに存在します。ほとんどのレンダーファームガイドは黙ってこのトポロジーを前提としています。すべてがうまく動く形だからです。
ファームが複数のサイトにまたがる必要があるとき、アーキテクチャは変わります。同じメトロポリタンエリアの2か所に分割された20ノードクラスターはすでに別のネットワーク問題であり、国をまたがるクラスターはさらに別の問題です。ラウンドトリップ時間は1ミリ秒未満から数十または数百ミリ秒に伸び、公衆ISPルートのジッターは絶え間ない背景ノイズとなり、任意の2エンドポイント間のMTUは仮定ではなく質問となり、1つのNASに住んでいたアセットライブラリは今や各サイトに複製されるか、オンデマンドでキャッシュされなければなりません。素朴なアプローチ — 同じNAS、同じサブミッションキュー、同じSMB共有、ただ長いケーブル — は静かな失敗モードとして現れます。接続を維持するもののフレームを転送しないセッション、リモートノードへの最終アセットプッシュがタイムアウトして99%で止まるレンダーサブミッション、ローカルでは成功してリモートでは明らかな理由なしに失敗するライセンスチェックアウトなどです。
この記事では、クロスカントリーレンダーファーム展開のために運用しているアーキテクチャを説明します — WireGuardハブ&スポークトポロジー、TCP BBR輻輳制御、MSSクランピングの規律、共有SMB3キャッシュ層、ハードニング済みファイアウォール表面。コンポーネントは一般的で、構成上の選択はいつも自明とは限らず、学んだ教訓は誰かに金を失わせる前にほとんどデバッグ時間を費やすことになりました。対象読者は同様のビルドのサイジングを行うインフラアーキテクトとDevOpsエンジニア、そしてチームが何に手を出しているか知りたいIT意思決定者です。This article also has a Japanese translation for native readers. 同じスタックのステップバイステップの運用手順については、operational deployment guideが日ごとのロールアウトシーケンスをカバーします。より高レベルの概要については、cross-country render farm overviewページがビジネスケースをカバーします。
WireGuardハブ&スポークトポロジー

離れた2つの拠点を結ぶ暗号化トンネル
クラスターのトランスポート層はWireGuardです。クライアント接続(アーティストのワークステーションからファームへ)とメインデータセンターとセカンダリサイト間のサイト間リンクの両方に使用します。トポロジーはハブ&スポーク方式です。1つのWireGuardサーバーがメインデータセンターのゲートウェイで動作し、すべてのクライアントピアがそのハブに接続し、セカンダリサイトはルーティングされたサブネットを背後に持つもう1つのピアとして接続します。
この種のビルドにおけるWireGuardの魅力はほぼ機械的なものです。プロトコルは固定された現代の暗号化(鍵交換にCurve25519、データプレーンにChaCha20-Poly1305、ハッシュにBLAKE2s)を使用し、ユーザースペースではなくLinuxカーネルで動作し、1画面に収まるキーとAllowedIPsファイルで設定されます。OpenVPNと比較すると、構成表面はおよそ1桁小さく、典型的なXeonノードでのスループットは同じCPUコストで数倍高く、コードベースは監査が扱える程度に小さいです。IPsecと比較すると、興味深い方法で失敗する可能性のあるIKEネゴシエーション段階がなく、リキー時のピアアイデンティティダンスがなく、クラッシュする可能性のあるユーザースペースデーモンがありません。過去の展開で3つすべてを運用しましたが、介入なしで持ちこたえる構成はWireGuardのものです。
ハブ&スポーク配置はすべてのサイト間フローがメインデータセンターのゲートウェイを経由することを意味します。2サイトのクロスカントリー展開には正しいトレードオフです。パブリックIPの攻撃表面を1つのボックスに集中させ、単一のルーティングおよびファイアウォールルールセットを1つのチョークポイントに適用し、すべてのハンドシェイクとフローカウンターがハブで見えるためモニタリングを直感的にします。フルメッシュはサイト間トラフィックで1ホップ節約しますが、構成作業とパブリック攻撃表面をサイト数の2乗で乗算します。2サイトまたは3サイトでは、ハブ&スポークが運用上の単純さで勝ちます。
ハブはUDPポート51820(デフォルト)でリッスンし、パブリックインターフェースが受け入れる唯一のポートです。TCPフォールバックはありません。UDPのみは意図的です — WireGuardの輻輳挙動はUDPデータグラムを中心に構築されており、TCP-over-TCPトンネルは長距離スループットを確実に劣化させます。UDPを完全にブロックするネットワークでは、これを顧客側の制約として扱い、別のレイヤーで回避します。
各クライアントピアは、クラスターの内部サブネットをカバーする単一のAllowedIPsエントリで構成されます。サイト間ピアは、カーネルがどのパケットをカプセル化するかを知るためにリモートLANサブネットをカバーするAllowedIPsを持ちます。PersistentKeepaliveはNATの背後にあるすべてのピアで25秒に設定され、ハンドシェイク間のUDP conntrackエントリを生かしておきます。これを正確に1回省略し、次の2日間を「セカンダリサイトで90秒ごとに接続が切れる」のデバッグに費やしました。3番目のサイトでは、PersistentKeepaliveがconfigファイルの最初の行でした。
TCP BBR輻輳制御
WireGuardトンネルが立ち上がると、次の層はTCPの挙動です。Linuxはデフォルトの輻輳制御アルゴリズムとしてCUBICを提供します。CUBICは最後のロスイベントからの時間の関数として輻輳ウィンドウを3次曲線でスケーリングします。これはパケットロスが輻輳の信頼できる信号であるリンクで機能します。落とし穴は「信頼できる」という言葉にあります。長距離ISPルートでは、パケットロスはしばしばまったく輻輳ではありません — 中間ルーターのキューオーバーフロー、TCPに見えない方法で再送するワイヤレスリンク、誤って構成されたレートリミッター、または短いルーティングトランジェントです。CUBICはこれらすべてを輻輳として扱い、ボトルネックに容量がたくさん残っていてもウィンドウを崩壊させます。
BBR(Bottleneck BandwidthとRound-trip propagation time)はクロスカントリーリンクで使用する代替手段です。BBRは主要な輻輳信号としてパケットロスを無視し、代わりにパスのボトルネック帯域幅と最小ラウンドトリップ時間を直接測定します。次に送信者をボトルネック速度でペーシングし、ウィンドウサイズは正確に1つの帯域幅遅延積のデータを飛行中に保つようにします。ロングファットネットワーク — 高帯域幅、高RTT、控えめなランダムロス — では、BBRがパイプを満たし続けるのに対し、CUBICは輻輳ではないロスに対してウィンドウを繰り返し半分にします。
レンダーファームでの実際の効果は測定可能です。同じハードウェア上のクロスカントリートンネルを介したアセット転送は、CUBICでは頻繁な停止を伴うスパイクの多いスループットから、BBRではパスの実際の容量に近いより滑らかなスループット曲線へ変わります。見出しの数字はISPルートと時間帯によって異なりますが、クラスターの送信側をBBRに切り替えると、運用しているルートで一貫してより高い定常状態スループットとより短いテールレイテンシが得られました。
Linuxカーネルメインライン4.9から含まれているBBR実装を使用しており、1行のsysctlで有効化します。net.core.default_qdisc=fqプラスnet.ipv4.tcp_congestion_control=bbr。両方の行は/etc/sysctl.d/99-bbr.confに入り、再起動後も維持されます。メインラインカーネルBBRは、本番環境で何年も運用しているバージョンです。アルゴリズムのより新しい研究ブランチは存在しますが、特定のISPパスで検証する時間がなかった動作変更を導入します。アップグレードパスは別のロードマップ項目です。
BBRは大きなフロー — アセット転送のためのキャッシュボックスとレンダーマネージャー、ライセンスコールバックやログシッピングなどの逆方向フローのための受信側 — の送信側に設定します。1端のBBRでもメリットのほとんどが得られ、両端のBBRは双方向フローでもう少し役立ちます。
TCP MSSクランピング
WireGuardトンネルが立ち上がった後に現れるすべてのネットワーク問題の中で、最も多くのデバッグ時間を要したのがMTUです。症状は一貫していて混乱します。小さなパケットはクリーンに通過し(デフォルトサイズのpingが動作、SSHが文字をエコー、WireGuardハンドシェイクが完了)、大きなパケットはトンネル内で消え、決して出てきません。TLSハンドシェイクは途中で止まります。SMBセッションは接続し、最初の大きな読み取りで失敗します。RDPセッションは確立してログイン画面を表示し、ユーザーが何かを入力すると凍ります。ライセンスサーバーは小さなトークンをチェックアウトし、大きなものでタイムアウトします。
原因は、WireGuardトンネルのカプセル化オーバーヘッドが、エンドポイントがLANインターフェースに基づいて交渉するパスMTUより有効MTUを下げることです。WireGuardはすべてのパケットに60バイトのオーバーヘッド(20 IPv4 + 8 UDP + 32 WireGuard)を追加します。LAN側の1500バイトのペイロードはパブリック側で1560バイトのパケットになり、パスに応じて断片化または破棄されます。Path MTU Discovery(PMTUD)は送信者にICMP「Fragmentation Needed」を返送してこれを修正するはずですが、PMTUDは現代のインターネットで日常的に壊れます — ICMPはしばしば送信者の上流でフィルタリングされ、「より小さなパケットを使用しろ」という信号は決して届かず、トンネルは静かに大きなパケットを破棄します。
解決策はTCP MSS(Maximum Segment Size)クランピングです。ルーター側WireGuardインターフェースを構成して、トンネルを通過するすべてのTCP SYNのMSSオプションを書き換え、トンネルの有効MTUからTCP/IPオーバーヘッドを差し引いた値にキャップします。1420バイトのトンネルMTU(ほとんどの上流MTUバリエーションを生き残る安全な選択)では、MSSクランプは1380です。ルールが入った後に開始するTCP接続はすべて1380バイトのMSSを交渉し、送信者はクリーンに通過する1420バイトのパケットを発し、静かなドロップは止まります。
クランプはルーターモードのWireGuardホストのFORWARDチェーンのwg0インターフェースで、TCPハンドシェイクパケットに適用されます。iptablesのイディオムはiptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu(または固定値の場合--set-mss 1380)です。nftablesに同等のものがあります。両側がTCP接続を開始する場合、ルールは双方向に適用される必要があります。レンダーファームでは一般的なケースです。
大きな何かが失敗するまで、MSSクランプが欠けていることを感じる方法はありません — 小さなワークロードはクリーンにテストされます。クランプは、正しく適用するとコストがゼロで、省略すると何時間もの混乱したデバッグを生み出す構成の1つです。「SMB転送がランダムなサイズで止まる」という朝6時のサポートチケットが朝8時に1行のiptablesルールで解決した後、標準展開チェックリストに入れました。
共有SMB3キャッシュ設計

レンダーワーカーにアセットをローカルで提供する共有キャッシュ
レンダーワークロードはアセットが重く、読み取りが優位です。典型的なシーンは数百メガバイトから数十ギガバイトに及びます — ジオメトリ、テクスチャ、シミュレーションキャッシュ、レンダリングDCCのプロジェクトファイル。20ノードクラスター全体で、同じシーンはフレームを取るすべてのワーカーが読めなければなりません。素朴なアプローチは、レンダーが開始する前にシーンをすべてのノードにコピーすることです。10GBのシーンと20ノードでは、10GBのワーキングセットのためにネットワーク経由で200GBを移動します。スタジオごとに1日数十シーンをかけると、複製コストがビルドを支配します。
代わりに使用するアーキテクチャは、レンダーワーカーにSMB3経由で公開されるサイトごとの単一の共有キャッシュ層です。キャッシュは、ext4フォーマットの単一SSD(NVMeクラス)を備えたUbuntu 22.04 LTSボックス1つで、キャッシュディレクトリはSambaを介してSMB3で公開されます。各レンダーワーカーは起動時にcifs-utils経由でSMB共有をマウントし、キャッシュからアセットファイルをローカルであるかのように読み取ります。特定のアセットを必要とする最初のワーカーは、上流のクラウドアセットストアからキャッシュへのプルをトリガーします。後続のワーカーと後続のフレームは、スイッチポート速度でLANキャッシュから読み取ります。サイトごとに、キャッシュボックスはすべてのワーカーから1スイッチホップの距離にあります。アセットはクラスターに1回到達し、20人のワーカーにサービスします。
いくつかの設計選択は開く価値があります。キャッシュはRAIDアレイではなく単一のSSDです。キャッシュは定義上、上流のクラウドアセットストアから再構築可能だからです。SSDが故障した場合、最悪のケースは次のアセット要求がクラウドからプルする間の遅延と、キャッシュされていない中間ファイルに依存していた進行中のレンダーの再構築です。各ジョブの終了時にキャッシュからNASに完成したレンダー出力をrsyncすることで「進行中のレンダー」リスクを緩和し、SSDの故障は既に納品された成果物を失いません。RAIDをスキップすることで、ハードウェアコスト、コントローラの複雑さ、一部のRAIDレベルがSSDに課す書き込み増幅オーバーヘッドを節約します。
ファイルシステムはZFSやbtrfsではなくext4です。過去のビルドでZFSとbtrfsの両方を使用しましたが、それらがもたらす機能セット(スナップショット、チェックサミング、圧縮)は一部のワークフローで実際の利点です。レンダーキャッシュの場合、読み取りパターンはトランザクションが多いというよりも主にシーケンシャルで帯域幅制限であり、キャッシュコンテンツは設計上廃棄可能です。ext4はストレージスタックをシンプルに保ち、インシデント事後分析セットから1クラスの失敗モードを除去します。すでに大規模にZFSを運用しているオペレータはここで絶対に使用できますが、キャッシュ層のシンプルさが個々の機能の利点よりも重要な展開には、ext4が選択です。
プリウォーム戦略は重要です。締切駆動のジョブが開始する前に、アーティストまたはパイプラインTDはプリステージングツールを介してシーンのアセットをキャッシュにプッシュします。ワーカーに着地する最初のフレームは、コールドプルを待つのではなく、ウォームキャッシュから読み取ります。プリウォームステップは夜間に実行されるジョブにはオプション(コールドプルでも問題なし)で、制約された時間内に完了する必要があるジョブには重要です。
クロスサイトキャッシュ共有はWireGuardサイト間トンネルを介して機能します。セカンダリサイトには独自のキャッシュボックスとワーカーがありますが、そのキャッシュはトンネル経由でプライマリサイトのキャッシュにも到達でき、そこでウォームでローカルではまだウォームでないアセットを取得できます。実際には、上流クラウドに行く前にミスでプライマリキャッシュにフォールバックするようにセカンダリキャッシュを構成します — サイト間トラフィックを暗号化されたトンネル上に保ち、ファーム内に既に存在するアセットのクラウドエグレス料金を回避します。これは正しいMSSクランプの実用的な利点の1つです。サイト間の大きなアセット転送は、小さなパケットの上限で停止するのではなく、トンネルを飽和させるスループットで移動します。
内部サービス: DNSとNTP
クラスターは独自のホスト名を知る必要があります。素朴な選択は、各ノードの/etc/hostsにすべてのホストを入れることで、これは2ノードでは機能し、20ノードでは失敗し始めます。正しい選択は内部DNSで、WireGuardを実行するのと同じゲートウェイボックスでdnsmasqを運用します。クラスターは.lanゾーンに住みます — cache.lan、rn-a01.lanからrn-a20.lan、mgr.lan、nas.lan。各名前はクラスターサブネット内の対応する内部IPに解決され、各ワーカーの/etc/resolv.confはdnsmasqサーバーを指します。
利点は、IP再割り当て、ホスト交換、トポロジーの変更がすべて、各ノードに触れるのではなく、1つの設定ファイル(dnsmasqホストファイル)に触れることを必要とする点です。利点はサイト間トンネル経由で拡張されます。セカンダリサイトのワーカーは、ローカルdnsmasq経由でcache.lanをセカンダリキャッシュに解決でき、トンネル経由のDNSフォワーディング経由でmgr.lanをプライマリサイトのレンダーマネージャに解決できます。過去にレンダーマネージャ構成でIPリテラルを使用し、ノードが移動するたびに後悔しました。
私たちを噛んだ — そして独自の段落に値するほど十分なオペレータを噛む — dnsmasqの罠はinterface=の行です。dnsmasqはデフォルトですべてのインターフェースでリッスンしますが、ゲートウェイボックスに少なくとも3つあることに気付くまでは問題ないように見えます: パブリックWAN、内部LAN、WireGuardトンネルwg0。interface=eth1を設定してdnsmasqをLANに制限していると思っているなら、wg0がリストされていないため、WireGuardで接続されたセカンダリサイトが.lanの名前を解決できなくしたところです。正しい行はinterface=eth1,wg0(またはインターフェース名の同等品)、またはWANだけを名指しするexcept-interface=行です。この誤構成が「リモートサイトはIPでキャッシュをpingできるがホスト名でSMBマウントできない」症状を1回以上生み出すのを見ました。
NTPはもう1つの内部サービスです。ゲートウェイでchronyをNTPサーバーとして運用し、ゲートウェイ自体はパブリックNTPプールに同期され、すべてのノードはゲートウェイに同期されます。動機はレンダーマネージャのログ相関です。フレームが失敗した場合、レンダーマネージャのログエントリとワーカーのログエントリはミリ秒以内のタイムラインを共有する必要があります。特にノードが何週間も稼働している場合の20ノードクラスターのクロックドリフトは、「このログエントリは合わない」というデバッグ混乱の本当の原因となります。chronyはドリフトを数ミリ秒以下に保ち、その混乱の種類を除去します。
ファイアウォール: default-deny inboundのufw
ゲートウェイはパブリックインターネット上にあり、ファイアウォールの姿勢は「default-deny inbound、default-allow outbound、トンネルトラフィック用のdefault-allow forward」です。Ubuntu 22.04 LTSで使用するツールはufw — Uncomplicated Firewallです。ufwは小さなコマンド表面を公開し、驚くようなことをすることを拒否するnftables(または古いシステムではiptables)上のフロントエンドです。ファイアウォール構成が「安全」と「数時間以内に侵害された」の違いであるゲートウェイボックスでは、小さなコマンド表面は機能です。
設定されたパブリック表面は1つのルールです: ufw allow 51820/udp comment 'wireguard'。インバウンドの他には何もありません。パブリック側のSSHは閉じています。WireGuardトンネル経由で既知のオペレータIPからゲートウェイを管理します。SMB、DNS、NTP、HTTPS(レンダーマネージャUI用)はすべて内部インターフェースのみです。ufw default deny incomingとufw default allow outgoingの設定が残りの表面をカバーします。
フォワードチェーンは注意が必要です。ゲートウェイはwg0と内部LAN間のクラスタートラフィック用のルーターとして動作し、ufwのデフォルト姿勢はフォワードを拒否することです。/etc/default/ufwにDEFAULT_FORWARD_POLICY="ACCEPT"を設定し、その後、FORWARDチェーンの特定のソース/宛先ペアにフォワードルールを絞り込みます。組み合わせ — default-deny incoming、起動時のdefault-deny forward、その後既知のクラスターサブネット間の明示的なforward ACCEPT — は監査可能な姿勢を提供し、話すべきではないサイト間で誤ってトラフィックをルーティングすることはありません。
ノードごとのホストファイアウォールは、このTier-1ゲートウェイ層をTier-2ホスト層に拡張します。各レンダーノードはローカルでufwを実行し、クラスターのレンダーマネージャとキャッシュボックスのみが接続を開始できるルールを持ちます。侵害されたワーカーは、まずホストファイアウォールを倒さないと別のワーカーにピボットできず、ゲートウェイはすべての予期しないフォワード試行をログに記録します。2層モデル — ゲートウェイTier 1、ホストごとTier 2 — は、合理的なオンプレミスクラスターが運用するのと同じです。クロスカントリー展開で変わるのは、Tier 1の表面が今やパブリックインターネットに対して防御することです。ゲートウェイは境界であり、ホストごとのファイアウォールは多層防御です。
アーキテクチャ図

ハブ&スポーク型レンダーファームトポロジー、インターネットへの単一のセキュアなトンネル
上記のテキスト記述は、展開のキックオフ中にホワイトボードに描くのと同じ次のASCII図にマップされます。
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
図は意図的に汎用的です — 特定の都市ペア、特定のISP、特定のサブネット番号付けはありません。展開する各サイトは同じ形状に従いますが、数字は異なります。
パフォーマンス特性
スループット数値はISPルートと時間帯に依存しますが、パフォーマンスの形は運用している展開全体で一貫しています。同じメトロの2サイト間のトンネル(サブ10ミリ秒RTT)では、大きな転送はボトルネックリンクで回線速度近くで移動し、キャッシュから読むレンダーワーカーはローカルディスクから読むワーカーと区別がつきません。異なる国のサイト間のトンネル(ルートに応じて50–150ミリ秒RTT)では、大きな転送はMSSクランプがセグメントあたりのサイズをトンネルMTUに合わせ続ける中、ボトルネック帯域幅に近いBBRペースの安定したスループットに落ち着きます。
ローカルLANキャッシュ読み取りは、アーキテクチャがその対価を稼ぐ場所です。スイッチドギガビットLAN上のSMB3経由でcache.lanから4GBのテクスチャパックを読むレンダーワーカーは、スイッチポートがバイトを押し出すのにかかる時間 — クロスカントリーのクラウドストレージからのコールドプルにかかる複数分の時間枠ではなく、数十秒 — でほぼ完了します。200フレームにわたって同じテクスチャパックに触れるジョブの場合、キャッシュヒット率は最初のウォーム読み取り後1.0に近づき、クロスカントリートンネルは元のプリウォーム、セカンダリサイト出力のクロスサイト同期、定常状態のテレメトリにのみ使用されます。
特に4Kおよび8Kレンダーフレームの場合、アーキテクチャの価値はフレームサイズに合わせてスケールします。複数のAOVを持つ8K EXRシーケンスは、個々のフレーム出力を数百メガバイトに押し上げ、200個ではシーンあたり数十ギガバイトの書き込みになります。その書き込みをローカルLANに保ち、最終的な圧縮された出力のみをトンネル経由で出荷することが、「一晩で完了」と「明日のいつかアップロードが完了したら完了」の違いです。
よくある質問
Q: OpenVPNではなくWireGuardを選ぶ理由は何ですか? A: WireGuardの構成表面はより小さく、データプレーンのスループットは同じハードウェアで一貫してより高く、カーネル実装はユーザースペースの失敗モードを除去し、固定暗号姿勢は1クラスのネゴシエーションバグを除去します。OpenVPNは20年の運用履歴を持つ堅固なツールです。私たちが気にするメトリクスで長時間実行されるクラスタートンネルの運用特性が優れているため、WireGuardを使用します。WireGuardのUDPが完全にブロックされているルートでは、TCP 443上のOpenVPNが正当なフォールバックですが、TCP-over-TCPは独自の病態を導入するため、顧客側の制約として扱います。
Q: BBRはノイズの多いISPルートでどのように役立ちますか? A: BBRはパケットロスの代わりにボトルネック帯域幅とRTTを輻輳信号として使用します。ロスが中間ルーターのバッファオーバーフロー、ワイヤレス再送、または一時的なルーティングイベントによって支配されるルート — すなわち、ほとんどのパブリックISPルート — では、BBRは輻輳ではないロスに対してウィンドウを繰り返し半分にする代わりに、送信者のペースをパスの実際の帯域幅に保ちます。効果はより高い定常状態スループット、大きな転送でのより短いテールレイテンシ、長いフローでの「転送が30秒停止して再開した」インシデントの減少です。
Q: MSSクランピングとは何で、なぜ必要なのですか? A: MSSクランピングは、TCP SYNパケットのMaximum Segment Sizeオプションを書き換えて、交渉されたセグメントサイズが有効MTUが低減されたトンネルをクリーンに通過するようにします。それがないと、エンドポイントはLANインターフェースに基づいてセグメントサイズを交渉します(通常MTU 1500、MSS 1460)。WireGuardトンネルはそれらのパケットをフルサイズで運ぶことができず、Path MTU DiscoveryはICMPが上流のどこかでフィルタリングされるため失敗し、大きなパケットは静かに消えます。症状は「小さなパケットは動作するが、大きなものは動作しない」 — pingは通過し、TLSハンドシェイクは止まり、SMB転送はファイルの途中で止まります。解決策はルーター側WireGuardインターフェース上の1行のiptablesまたはnftablesルールです。
Q: このアーキテクチャを自分で展開できますか、それともレンダーファームベンダーが必要ですか?
A: アーキテクチャは完全にオープンソースコンポーネント — WireGuard、LinuxのBBR実装、iptables/nftables、Samba SMB3、dnsmasq、chrony、ufw、ext4 — から構築されています。SRF専用のコンポーネントはありません。インフラエンジニアリングのスキルを持つチームは同じスタックを自分で展開でき、この記事の構成選択は秘密ではありません。それらは機能したから私たちがした選択です。ベンダーが提供するのは運用経験です — dnsmasqのinterface=行のような罠、MSSクランプの発見ストーリー、キャッシュSSDの適切なサイジング、プリウォームツールリング — がすべてのビルドで再発見を必要としない展開プレイブックにまとめられています。チームがその経験曲線を吸収するか、それを過ぎる代金を払うかは、予算とタイムラインの問題です。
Q: 典型的なレンダーワークフローのキャッシュヒット率はどれくらいですか? A: 同じシーンが多くのフレームにわたってレンダリングされるフレーム並列ワークロード(アニメーション、VFX、アーキビズ、製品ビジュアライゼーションの支配的パターン)の場合、キャッシュヒット率は各アセットの最初のウォームプル後に1.0に近づきます。コールドプルペナルティはキャッシュあたりアセットあたり1回支払われ、同じサイトの後続のすべてのワーカーはLAN速度でウォームキャッシュから読み取ります。フレームごとに異なるアセットセットに触れるワークロード(まれですが、一部の手続き型ワークフローで発生)の場合、ヒット率は低く、キャッシュは長期ストアよりもトランジットバッファのように動作します。締切駆動のジョブの前のプリウォームステップは、計画されたワークロードでヒット率を事実上1.0にします。
Q: このアーキテクチャは20ノードを超えてどのようにスケールしますか? A: ハブ&スポークWireGuardトポロジーはピア数で線形にスケールします — ハブのCPUコストはピアごとの暗号化とパケットごとのルーティングで、現代のXeonゲートウェイはボトルネックになる前に数百のピアを楽に処理できます。キャッシュ層は単一キャッシュボックスを大きくする(SSD容量を増やす、より速いNIC)か、ワークロード認識マウント戦略で複数のボックスにシャーディングするかでスケールします。サイトあたり50ノードを超えるビルドの場合、通常2番目のキャッシュボックスを追加してワーカーをそれらの間で分割します。サイトあたり100ノードを超えると、キャッシュ層は単一のボックスではなく分散読み取りレプリカ設計になりますが、それは別の記事です。クロスカントリートンネル自体は、クラスターが成長してもアーキテクチャの変更を必要としません — 基盤となるISPリンクに容量がある限り、BBRペーシングとMSSクランプは任意の集計フロー速度で仕事を続けます。
このアーキテクチャを立ち上げる展開シーケンスについてのより実用的な詳細については、operational deployment guideをご覧ください。このネットワーク設計の上に重ねられたセキュリティ姿勢については、network segmentation security記事がTier-1とTier-2のファイアウォールモデルをより深くカバーします。そして、私たちがいつも最初に正しくできなかった現場テスト済みのエッジケースについては、deployment lessons learned書き出しが、このアーキテクチャを形作った特定の失敗モードをカバーします。
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



