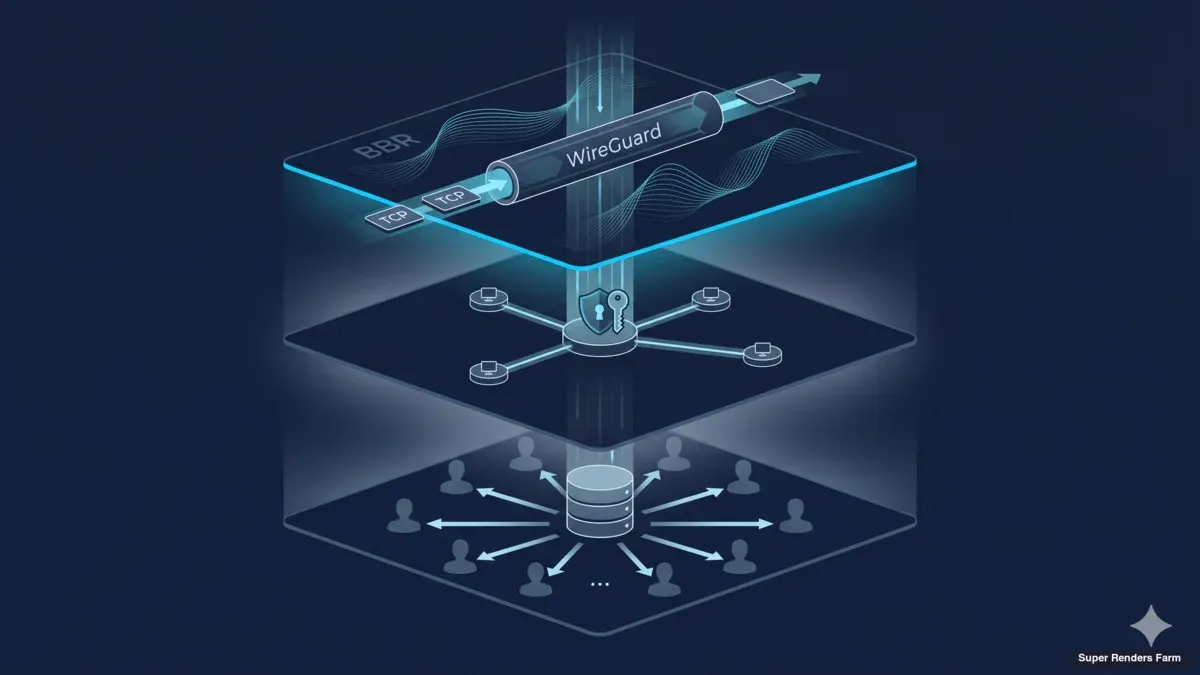
Architettura di render farm cross-country: WireGuard, BBR e cache SMB condivisa
Panoramica
Introduzione
Costruire una render farm che vive in un solo rack, in una sola stanza, su un solo switch, è un problema risolto. I tratti di cavo sono brevi, i tempi di andata e ritorno si misurano in microsecondi, e la libreria di asset vive su un NAS dal quale ogni worker legge alla velocità della porta dello switch. La maggior parte delle guide alle render farm assume silenziosamente questa topologia, perché è quella in cui tutto semplicemente funziona.
L'architettura cambia quando la farm deve estendersi su più di un sito. Un cluster da 20 nodi diviso tra due posizioni nella stessa metropoli è già un problema di rete diverso; un cluster che si estende tra paesi è un problema diverso ancora. I tempi di andata e ritorno passano da sotto il millisecondo a decine o centinaia di millisecondi, il jitter sulle rotte ISP pubbliche diventa un rumore di fondo costante, la MTU tra due endpoint diventa una domanda invece di un'assunzione, e la libreria di asset che viveva su un solo NAS deve ora essere replicata in ogni sito o messa in cache su richiesta. L'approccio ingenuo — stesso NAS, stessa coda di submission, stesso SMB share, solo con cavi più lunghi — emerge come modi di guasto silenziosi: sessioni che restano connesse senza mai trasferire un frame, submission di render che restano al 99 percento perché lo spinta finale di asset verso un nodo remoto va in timeout, license check-out che riescono localmente e falliscono da remoto senza motivo evidente.
Questo articolo descrive l'architettura che operiamo per deployment di render farm cross-country — la topologia WireGuard hub-and-spoke, il controllo di congestione TCP BBR, la disciplina di MSS clamping, uno strato di cache SMB3 condiviso, e una superficie di firewall irrobustita. I componenti sono comuni, le scelte di configurazione non sono sempre ovvie, e le lezioni apprese ci sono per lo più costate tempo di debugging prima di costare denaro a chiunque. Il pubblico è composto da architetti di infrastruttura e ingegneri DevOps che stanno dimensionando una build simile, più decision-maker IT che vogliono sapere a cosa si sta impegnando il loro team. Per una procedura operativa passo-passo dello stesso stack, la nostra operational deployment guide copre la sequenza di rollout giorno per giorno. Per una visione d'insieme, la pagina cross-country render farm overview copre il business case.
Topologia WireGuard hub-and-spoke

Tunnel cifrato che collega due sedi distanti
Lo strato di trasporto del cluster è WireGuard. Lo usiamo sia per le connessioni client (workstation degli artisti verso la farm) sia per il collegamento site-to-site tra il datacenter principale e il sito secondario. La topologia è hub-and-spoke: un server WireGuard gira sul gateway del datacenter principale, ogni peer client si connette a quell'hub, e il sito secondario si connette come ulteriore peer con una subnet instradata dietro.
L'attrattiva di WireGuard per questo tipo di build è soprattutto meccanica. Il protocollo usa crittografia moderna fissa (Curve25519 per lo scambio chiavi, ChaCha20-Poly1305 per il data plane, BLAKE2s per l'hashing), gira nel kernel Linux invece che in userspace, e si configura con un file chiave-e-AllowedIPs che sta in una schermata. Rispetto a OpenVPN, la superficie di configurazione è circa un ordine di grandezza più piccola, il throughput su un nodo Xeon tipico è diverse volte superiore allo stesso costo CPU, e il codebase è abbastanza piccolo da rendere trattabile l'audit. Rispetto a IPsec, non c'è fase di negoziazione IKE che possa fallire in modi interessanti, nessuna danza di identità peer al rekey, e nessun daemon userspace che possa andare in crash. Abbiamo operato tutti e tre in deployment passati; le configurazioni WireGuard sono quelle che restano in piedi senza intervento.
La disposizione hub-and-spoke significa che ogni flusso site-to-site transita per il gateway del datacenter principale. Per un deployment cross-country a due siti è il giusto trade-off: concentra la superficie di attacco IP pubblica su una box, applica un singolo set di regole di routing e firewall a un solo punto di strozzatura, e rende il monitoring diretto perché ogni handshake e contatore di flusso è visibile all'hub. Un full mesh risparmierebbe un hop sul traffico site-to-site ma moltiplicherebbe il lavoro di configurazione e la superficie di attacco pubblica al quadrato del numero di siti. Per due o tre siti, l'hub-and-spoke vince sulla semplicità operativa.
L'hub ascolta sulla porta UDP 51820 (default), ed è la sola porta che l'interfaccia pubblica accetta. Non c'è fallback TCP. Solo-UDP è deliberato — il comportamento di congestione di WireGuard è costruito attorno a datagrammi UDP, e un tunnel TCP-su-TCP degrada in modo affidabile il throughput a lunga distanza. Su reti che bloccano UDP del tutto trattiamo questo come un vincolo lato cliente e instradiamo intorno su un altro strato.
Ogni peer client è configurato con una sola voce AllowedIPs che copre la subnet interna del cluster. Il peer site-to-site ha AllowedIPs che coprono la subnet LAN remota in modo che il kernel sappia quali pacchetti incapsulare. PersistentKeepalive è impostato a 25 secondi su ogni peer dietro NAT, il che mantiene viva la voce conntrack UDP tra handshake. L'abbiamo omesso esattamente una volta e abbiamo passato i due giorni successivi a debuggare «cadute di connessione ogni 90 secondi sul sito secondario»; sul terzo sito, PersistentKeepalive era la prima riga del file di config.
Controllo di congestione TCP BBR
Una volta su il tunnel WireGuard, lo strato successivo è il comportamento TCP. Linux fornisce CUBIC come algoritmo di controllo congestione di default. CUBIC scala la sua finestra di congestione su una curva cubica come funzione del tempo dall'ultimo evento di perdita, il che funziona su collegamenti dove la perdita di pacchetti è un segnale affidabile di congestione. Il trucco sta nella parola «affidabile». Su rotte ISP a lunga distanza la perdita di pacchetti spesso non è congestione affatto — è overflow di coda su un router intermedio, un link wireless con retransmit invisibili a TCP, un rate-limiter mal configurato, o un transitorio di routing. CUBIC tratta tutto questo come congestione e collassa la finestra anche quando il bottleneck ha molta capacità libera.
BBR (Bottleneck Bandwidth and Round-trip propagation time) è l'alternativa che usiamo su link cross-country. BBR ignora la perdita di pacchetti come segnale primario di congestione e invece misura direttamente la banda del bottleneck e l'RTT minimo del percorso. Cadenza poi il mittente al tasso del bottleneck, con una finestra dimensionata per tenere un prodotto banda-per-ritardo di dati in volo. Su un long fat network — alta banda, RTT alto, perdita casuale modesta — BBR tiene la pipe piena mentre CUBIC dimezzerebbe ripetutamente la finestra per perdite non congestive.
L'effetto pratico su una render farm è misurabile. I trasferimenti di asset attraverso un tunnel cross-country, sullo stesso hardware, passano da un throughput a strappi con stall frequenti sotto CUBIC a una curva di throughput più liscia vicina alla capacità reale del percorso sotto BBR. I numeri di testa variano con la rotta ISP e l'ora del giorno, ma passare il lato mittente del cluster a BBR ha prodotto in modo costante un throughput a regime più alto e tail latency più corte sulle rotte che operiamo.
Usiamo l'implementazione BBR che è nel kernel Linux mainline dalla versione 4.9, abilitata con un sysctl di una riga: net.core.default_qdisc=fq più net.ipv4.tcp_congestion_control=bbr. Entrambe le righe vanno in /etc/sysctl.d/99-bbr.conf e sopravvivono al reboot. Il BBR del kernel mainline è la versione che operiamo in produzione da anni. Rami di ricerca più recenti dell'algoritmo esistono ma introducono cambi di comportamento che non abbiamo avuto tempo di validare sui nostri percorsi ISP specifici; il percorso di upgrade è una voce di roadmap separata.
BBR è impostato sul lato mittente di qualsiasi flusso grande — la box cache e il render manager per i trasferimenti di asset, il lato ricevente per qualsiasi flusso in senso inverso come license callback e log shipping. BBR a un'estremità basta per vedere la maggior parte del beneficio; BBR a entrambe le estremità aiuta un po' di più sui flussi bidirezionali.
TCP MSS clamping
Di tutti i problemi di rete che emergono dopo che il tunnel WireGuard si alza, quello che ci ha costato più tempo di debugging: la MTU. Il sintomo è coerente e confondente: i pacchetti piccoli passano puliti (il ping funziona a dimensione default, SSH echeggia i caratteri, l'handshake WireGuard completa), ma i pacchetti grandi spariscono nel tunnel e non escono mai. Gli handshake TLS restano sospesi a metà. Le sessioni SMB si connettono, falliscono al primo read grande. Le sessioni RDP si stabiliscono, mostrano la schermata di login, si congelano quando l'utente digita qualcosa. I server di licenza fanno checkout di token piccoli e vanno in timeout su quelli grandi.
La causa è l'overhead di incapsulamento del tunnel WireGuard che riduce la MTU effettiva sotto la MTU di percorso che gli endpoint negoziano in base alle loro interfacce LAN. WireGuard aggiunge 60 byte di overhead (20 IPv4 + 8 UDP + 32 WireGuard) a ogni pacchetto. Un carico utile di 1500 byte sul lato LAN diventa un pacchetto di 1560 byte sul lato pubblico, frammentato o scartato a seconda del percorso. Path MTU Discovery (PMTUD) dovrebbe risolverlo inviando ICMP «Fragmentation Needed» al mittente, ma PMTUD si rompe nella moderna internet di routine — l'ICMP è spesso filtrato a monte del mittente, il segnale «usa pacchetti più piccoli» non arriva mai, e il tunnel scarta silenziosamente i pacchetti grandi.
La soluzione è il TCP MSS (Maximum Segment Size) clamping. Configuriamo l'interfaccia WireGuard lato router per riscrivere l'opzione MSS in ogni TCP SYN che attraversa il tunnel, fissandola alla MTU effettiva del tunnel meno l'overhead TCP/IP. Con una MTU di tunnel di 1420 byte (una scelta sicura che sopravvive alla maggior parte delle variazioni a monte), il clamp MSS è 1380. Qualsiasi connessione TCP che parte dopo la regola negozia un MSS da 1380 byte, il mittente emette pacchetti da 1420 byte che passano puliti, e i drop silenziosi cessano.
Il clamp va sulla catena FORWARD dell'host WireGuard in modalità router, sull'interfaccia wg0, applicato ai pacchetti di handshake TCP. L'idioma iptables è iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (o --set-mss 1380 per un valore fisso). nftables ha l'equivalente. La regola deve applicarsi in entrambe le direzioni se entrambi i lati avviano connessioni TCP, che su una render farm è il caso comune.
Non c'è modo di sentire che manca il clamp MSS finché qualcosa di grande non fallisce — i carichi piccoli testano puliti. Il clamp è una di quelle configurazioni che non costano nulla quando applicate correttamente e producono ore di debugging confuso quando omesse. Lo abbiamo messo nella checklist di deployment standard dopo che un ticket di supporto alle 6 del mattino su «trasferimenti SMB che restano sospesi a dimensioni casuali» si è risolto alle 8 del mattino con una regola iptables di una riga.
Progettazione della cache SMB3 condivisa

Cache condivisa che serve gli asset localmente ai render worker
I carichi di render sono pesanti di asset e dominati dalla lettura. Una scena tipica va da poche centinaia di megabyte a diverse decine di gigabyte — geometria, texture, simulation cache e file di progetto della DCC di rendering. Attraverso un cluster da 20 nodi la stessa scena deve essere leggibile da ogni worker che prende un frame. L'approccio ingenuo è copiare la scena su ogni nodo prima dell'avvio del render. Con una scena da 10 GB e 20 nodi, questo muove 200 GB attraverso la rete per quello che è un working set da 10 GB. Moltiplica per decine di scene al giorno per studio e il costo di duplicazione domina la build.
L'architettura che usiamo invece è un singolo strato di cache condivisa per sito, esposto ai render worker tramite SMB3. La cache è una box Ubuntu 22.04 LTS con un solo SSD (classe NVMe), formattato ext4, con la directory di cache esposta da Samba via SMB3. Ogni render worker monta lo share SMB al boot tramite cifs-utils e legge i file di asset dalla cache come se fossero locali. Il primo worker che ha bisogno di un dato asset attiva un pull dall'asset store cloud upstream nella cache; i worker successivi e i frame successivi leggono dalla cache LAN a velocità di porta switch. Per sito, la box cache è a un hop di switch da ogni worker; l'asset raggiunge il cluster una volta e serve venti worker.
Alcune scelte di design meritano di essere disimballate. La cache è un singolo SSD, non un array RAID, perché la cache è per definizione ricostruibile dall'asset store cloud upstream. Se l'SSD si guasta, il caso peggiore è un ritardo mentre la prossima richiesta di asset pull dal cloud, più un rebuild di ogni render in volo che dipendeva da un file intermedio non cacheato. Mitighiamo il rischio «render in volo» rsincronizzando gli output di render terminati dalla cache verso un NAS alla fine di ogni job, così un guasto SSD non perde nessun deliverable già consegnato. Saltare il RAID risparmia il costo hardware, la complessità del controller e l'overhead di amplificazione di scrittura che alcuni livelli RAID impongono agli SSD.
Il file system è ext4 anziché ZFS o btrfs. Abbiamo usato ZFS e btrfs in build passate, e i feature set che portano (snapshot, checksumming, compressione) sono benefici reali in alcuni workflow. Per una cache di render, il pattern di lettura è perlopiù sequenziale e bandwidth-bound piuttosto che transazionale, e i contenuti della cache sono per design scartabili. Ext4 mantiene lo stack di storage semplice e rimuove una classe di failure mode dal set dei postmortem di incidenti. Operatori che già operano ZFS su larga scala possono assolutamente usarlo qui, ma per un deployment in cui la semplicità dello strato di cache pesa più dei guadagni di feature singoli, ext4 è la scelta.
La strategia di pre-warm conta. Prima che un job guidato da deadline inizi, l'artista o il TD di pipeline spinge gli asset della scena nella cache tramite un tool di pre-staging. Il primo frame che atterra su un worker legge allora da una cache calda invece di aspettare un cold pull. Il passo pre-warm è opzionale per job che girano di notte (cold pull va bene) e importante per job che devono terminare in una finestra ristretta.
La condivisione di cache cross-sito funziona attraverso il tunnel WireGuard site-to-site. Il sito secondario ha la propria box cache e i propri worker, ma la sua cache può anche raggiungere la cache del sito primario sul tunnel per qualsiasi asset che è caldo lì e non ancora caldo localmente. In pratica configuriamo la cache secondaria perché ricada sulla cache primaria per i miss prima di andare al cloud upstream — mantenendo il traffico inter-sito sul tunnel cifrato ed evitando addebiti di egress cloud per asset che già vivono dentro la farm. Questo è uno dei benefici pratici di un clamp MSS corretto: i trasferimenti grandi di asset tra siti si muovono a un throughput che satura il tunnel piuttosto che bloccarsi al soffitto dei pacchetti piccoli.
Servizi interni: DNS e NTP
Un cluster ha bisogno di conoscere i propri hostname. La scelta ingenua è mettere ogni host in /etc/hosts su ogni nodo, il che funziona con due nodi e inizia a fallire con venti. La scelta giusta è un DNS interno, e operiamo dnsmasq sulla stessa box gateway che esegue WireGuard. Il cluster vive in una zona .lan — cache.lan, da rn-a01.lan a rn-a20.lan, mgr.lan, nas.lan. Ogni nome risolve all'IP interno corrispondente nella subnet del cluster, e il /etc/resolv.conf di ogni worker punta al server dnsmasq.
Il beneficio è che ogni riassegnazione di IP, swap di host o cambio di topologia richiede di toccare un file di configurazione (il file hosts di dnsmasq) anziché ogni nodo. Il beneficio si estende sul tunnel site-to-site: un worker sul sito secondario può risolvere cache.lan verso la cache secondaria tramite il suo dnsmasq locale, e risolvere mgr.lan verso il render manager del sito primario tramite DNS forwarding attraverso il tunnel. In passato abbiamo usato letterali IP nelle configurazioni del render manager e ce ne siamo pentiti ogni volta che un nodo si spostava.
La trappola di dnsmasq che ci ha morso — e morde abbastanza operatori da meritare il proprio paragrafo — è la riga interface=. dnsmasq, di default, ascolta su ogni interfaccia, il che sembra a posto finché non realizzi che la box gateway ne ha almeno tre: il WAN pubblico, il LAN interno e il tunnel WireGuard wg0. Se imposti interface=eth1 pensando di restringere dnsmasq al LAN, hai appena reso il sito secondario connesso via WireGuard incapace di risolvere qualsiasi nome .lan, perché wg0 non è elencato. La riga corretta è interface=eth1,wg0 (o l'equivalente per i tuoi nomi di interfaccia), o una riga except-interface= che nomina solo il WAN. Abbiamo visto questa cattiva configurazione produrre il sintomo «il sito remoto può pingare la cache via IP ma non può fare SMB-mount via hostname» più di una volta.
NTP è l'altro servizio interno. Operiamo chrony sul gateway come server NTP, con il gateway stesso sincronizzato a pool NTP pubblici e ogni nodo sincronizzato al gateway. La motivazione è la correlazione dei log del render manager: se un frame fallisce, la voce di log del render manager e quella del worker devono condividere una timeline al millisecondo. La deriva di clock su un cluster da 20 nodi, specialmente quando i nodi sono up da settimane, diventa una vera fonte di confusione di debugging «questa voce di log non combacia bene». chrony mantiene la deriva sotto pochi millisecondi e rimuove quella classe di confusione.
Firewall: ufw con default-deny inbound
Il gateway è sull'internet pubblica, e la sua postura firewall è «default-deny inbound, default-allow outbound, default-allow forward per traffico tunneled». Su Ubuntu 22.04 LTS, lo strumento che usiamo è ufw — l'Uncomplicated Firewall. ufw è un frontend su nftables (o iptables su sistemi più vecchi) che espone una piccola superficie di comando e si rifiuta di fare cose sorprendenti. Per una box gateway la cui config firewall è la differenza tra «sicura» e «compromessa in ore», una piccola superficie di comando è una feature.
La superficie pubblica configurata è una regola: ufw allow 51820/udp comment 'wireguard'. Niente altro in inbound. SSH dal lato pubblico è chiuso; amministriamo il gateway attraverso il tunnel WireGuard da un IP operatore noto. SMB, DNS, NTP e HTTPS (per l'UI del render manager) sono tutti solo su interfacce interne. Le impostazioni ufw default deny incoming e ufw default allow outgoing coprono il resto della superficie.
La catena forward richiede cura. Il gateway agisce da router per traffico di cluster tra wg0 e il LAN interno, e la postura di default di ufw è negare il forward. Impostiamo DEFAULT_FORWARD_POLICY="ACCEPT" in /etc/default/ufw e poi restringiamo le regole forward a coppie source/destination specifiche nella catena FORWARD. La combinazione — default-deny incoming, default-deny forward al boot, poi ACCEPT forward espliciti tra subnet di cluster note — dà una postura auditabile che non instrada accidentalmente traffico tra siti che non dovrebbero parlarsi.
I firewall host per-nodo estendono questo strato Tier-1 gateway a uno strato Tier-2 host. Ogni nodo di render esegue ufw localmente con regole che permettono solo al render manager e alla box cache del cluster di iniziare connessioni. Un worker compromesso non può pivotare verso un altro worker senza prima sconfiggere il firewall host, e il gateway registra ogni tentativo di forward inatteso. Il modello a due tier — gateway Tier 1, per-host Tier 2 — è lo stesso che qualsiasi cluster on-prem ragionevole esegue; ciò che cambia su un deployment cross-country è che la superficie Tier 1 ora difende contro l'internet pubblica. Il gateway è il perimetro; i firewall per-host sono la difesa in profondità.
Diagramma di architettura

Topologia hub-and-spoke della render farm, singolo tunnel sicuro verso internet
La descrizione testuale sopra si mappa al seguente diagramma ASCII, lo stesso che disegniamo alla lavagna durante i kick-off di deployment:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
Il diagramma è intenzionalmente generico — nessuna coppia di città specifica, nessun ISP specifico, nessuna numerazione di subnet specifica. Ogni sito che dispieghiamo segue la stessa forma; i numeri variano.
Caratteristiche di prestazione
I numeri di throughput dipendono dalla rotta ISP e dall'ora del giorno, ma la forma della prestazione è coerente tra i deployment che abbiamo operato. Su un tunnel tra due siti nella stessa metropoli (RTT sotto i 10 ms), i trasferimenti grandi si muovono vicino alla velocità di linea sul link bottleneck, e un render worker che legge dalla cache è indistinguibile da un worker che legge da disco locale. Su un tunnel tra siti in paesi diversi (50–150 ms RTT a seconda della rotta), i trasferimenti grandi si assestano su un throughput stabile cadenzato da BBR vicino alla banda del bottleneck, con il clamp MSS che mantiene la dimensione per segmento allineata alla MTU del tunnel.
La lettura dalla cache LAN locale è dove l'architettura si guadagna il pane. Un render worker che legge un texture pack da 4 GB da cache.lan via SMB3 su una LAN gigabit switchata finisce all'incirca nel tempo che la porta switch impiega a spingere i byte — decine di secondi anziché i tempi di più minuti che impiegherebbe un cold pull da storage cloud cross-country. Per un job che tocca lo stesso texture pack su duecento frame, la cache hit ratio si avvicina a 1,0 dopo la prima lettura calda, e il tunnel cross-country viene usato solo per il pre-warm originale, la sync cross-sito degli output del sito secondario e la telemetria a regime.
Per frame di render 4K e 8K specificamente, il valore dell'architettura scala con la dimensione del frame. Una sequenza EXR 8K con AOV multiple può spingere singoli output di frame nei centinaia di megabyte, e 200 di essi sono una scrittura di decine di gigabyte per scena. Mantenere quella scrittura in local-LAN e spedire solo l'output compresso finale sul tunnel è la differenza tra «finisce in nottata» e «finisce quando l'upload completa, domani».
Domande frequenti
Q: Perché WireGuard e non OpenVPN? A: La superficie di configurazione di WireGuard è più piccola, il suo throughput sul data plane costantemente più alto sullo stesso hardware, la sua implementazione kernel rimuove una modalità di guasto userspace, e la sua postura a cifratura fissa rimuove una classe di bug di negoziazione. OpenVPN è uno strumento solido con vent'anni di storia operativa; usiamo WireGuard perché le proprietà operative per un tunnel di cluster a lunga durata sono migliori sulle metriche che ci interessano. Su rotte in cui l'UDP di WireGuard è bloccato del tutto, OpenVPN su TCP 443 è un fallback legittimo — ma TCP-su-TCP introduce le proprie patologie, e lo trattiamo come un vincolo lato cliente.
Q: Come aiuta BBR su rotte ISP rumorose? A: BBR usa la banda del bottleneck e l'RTT come segnale di congestione anziché la perdita di pacchetti. Su rotte dove la perdita è dominata da overflow di buffer su router intermedi, retransmit wireless o eventi transitori di routing — cioè la maggior parte delle rotte ISP pubbliche — BBR mantiene il pace del mittente alla banda reale del percorso anziché dimezzare la finestra ripetutamente per perdite non congestive. L'effetto è throughput a regime più alto, tail latency più corta sui trasferimenti grandi e meno incidenti «il trasferimento è rimasto fermo trenta secondi e poi ha ripreso» sui flussi lunghi.
Q: Cos'è il MSS clamping e perché ne ho bisogno? A: Il MSS clamping riscrive l'opzione Maximum Segment Size nei pacchetti TCP SYN affinché la dimensione di segmento negoziata passi pulita attraverso un tunnel con MTU effettiva ridotta. Senza, gli endpoint negoziano una dimensione di segmento basata sulle loro interfacce LAN (tipicamente MTU 1500, MSS 1460), il tunnel WireGuard non può trasportare quei pacchetti a piena dimensione, Path MTU Discovery fallisce perché ICMP è filtrato da qualche parte a monte, e i pacchetti grandi spariscono silenziosamente. Il sintomo è «pacchetti piccoli funzionano, grandi no» — i ping passano, gli handshake TLS restano sospesi, i trasferimenti SMB si bloccano a metà file. La soluzione è una regola iptables o nftables di una riga sull'interfaccia WireGuard lato router.
Q: Posso dispiegare questa architettura da solo, o ho bisogno di un fornitore di render farm?
A: L'architettura è costruita interamente con componenti open source — WireGuard, l'implementazione BBR di Linux, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. Non c'è componente SRF-only. Un team con competenze di ingegneria di infrastruttura può dispiegare lo stesso stack da solo, e le scelte di configurazione in questo articolo non sono segreti; sono le scelte che abbiamo fatto perché funzionavano. Quello che un fornitore porta è l'esperienza operativa — le trappole come la riga interface= di dnsmasq, la storia della scoperta del clamp MSS, il dimensionamento corretto dell'SSD di cache, gli strumenti di pre-warm — arrotolati in un playbook di deployment che non richiede riscoperta a ogni build. Se un team assorbe quella curva di esperienza o paga per saltarla è una questione di budget e tempistiche.
Q: Qual è la cache hit ratio per workflow di render tipici? A: Per carichi paralleli per frame in cui la stessa scena viene renderizzata su molti frame (il pattern dominante in animazione, VFX, archviz e visualizzazione di prodotto), la cache hit ratio si avvicina a 1,0 dopo il primo pull caldo di ogni asset. La penalità di cold pull viene pagata una volta per asset per cache, e ogni worker successivo sullo stesso sito legge dalla cache calda a velocità LAN. Per carichi che toccano un set di asset diverso per frame (rari, ma succede in alcuni workflow procedurali), la hit ratio è più bassa e la cache agisce più come buffer di transito che come store a lungo termine. Il passo di pre-warm prima di job guidati da deadline rende effettivamente la hit ratio 1,0 per il carico pianificato.
Q: Come scala questa architettura oltre i 20 nodi? A: La topologia WireGuard hub-and-spoke scala linearmente con il numero di peer — il costo CPU dell'hub è crypto per peer e routing per pacchetto, e un gateway Xeon moderno può gestire centinaia di peer prima di diventare il bottleneck. Lo strato di cache scala o facendo crescere la box cache singola (più capacità SSD, NIC più veloce) o suddividendo su più box con una strategia di mount consapevole del workload. Per build oltre i 50 nodi per sito, tipicamente aggiungiamo una seconda box cache e dividiamo i worker fra esse; oltre i 100 nodi per sito, lo strato di cache diventa un design read-replica distribuito, e quello è un altro articolo. Il tunnel cross-country in sé non ha bisogno di cambio architetturale al crescere del cluster — il pacing BBR e il clamp MSS continuano a fare il loro lavoro a qualsiasi tasso di flusso aggregato, finché il link ISP sottostante ha la capacità.
Per più dettaglio pratico sulla sequenza di deployment con cui alziamo questa architettura, vedere la nostra operational deployment guide. Per la postura di sicurezza sovrapposta a questo design di rete, il nostro articolo network segmentation security copre più in profondità il modello firewall Tier-1 e Tier-2. E per i casi limite testati sul campo che non abbiamo sempre risolto al primo tentativo, il writeup deployment lessons learned copre i modi di guasto specifici che hanno plasmato questa architettura.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



