
Cómo funcionan las granjas de render: guía técnica para artistas 3D
Resumen
Introducción
Las granjas de render existen porque las estaciones de trabajo individuales tienen límites claros. Una animación de 500 fotogramas a 20 minutos por fotograma tarda casi una semana en una sola máquina. Si distribuyes esos fotogramas entre 100 máquinas, el mismo trabajo se completa en menos de dos horas. La matemática es sencilla: la ingeniería detrás no lo es.
Operamos una granja de render con más de 20.000 núcleos CPU y una flota GPU dedicada con tarjetas NVIDIA RTX 5090. Cada día procesamos cientos de trabajos con V-Ray, Corona, Arnold, Redshift, Cycles y otros motores. Esta guía explica qué sucede realmente entre el momento en que cargas un archivo de escena y el momento en que descargas los fotogramas terminados: los sistemas de cola, la distribución de archivos, el manejo de errores y las decisiones de infraestructura que hacen que el renderizado distribuido sea confiable a escala.
Si eres nuevo en el concepto de granjas de render, nuestra guía sobre qué es una granja de render cubre los fundamentos. Este artículo profundiza en los mecanismos técnicos.
Qué sucede cuando envías un trabajo de renderizado
El proceso de envío implica más pasos de los que la mayoría de los artistas imaginan. Esta es la secuencia, desde tu estación de trabajo hasta el primer píxel renderizado.
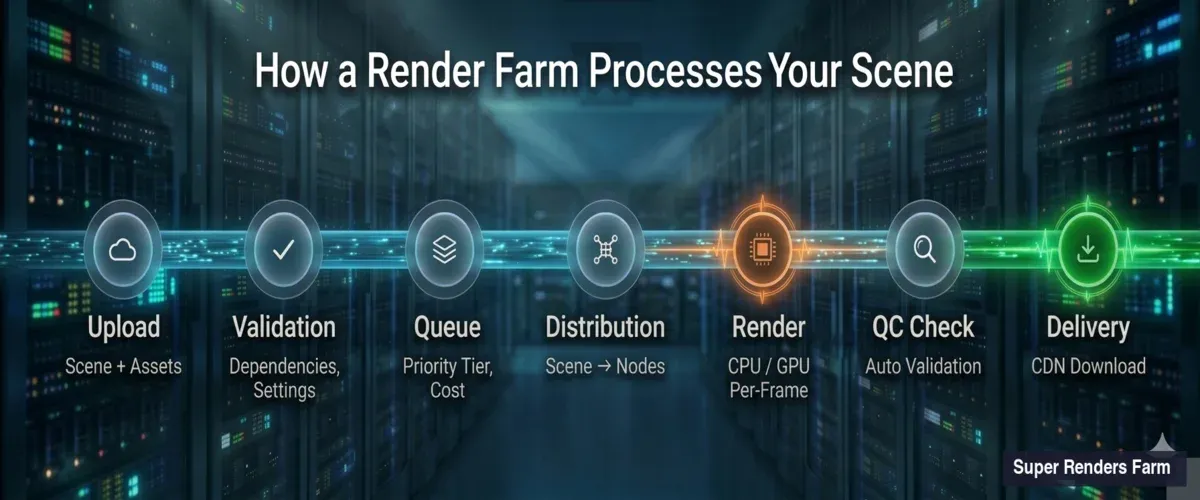
Flujo de trabajo de una granja de render mostrando 7 etapas desde la carga de la escena, pasando por validación, cola, distribución, renderizado, control de calidad, hasta la entrega final
Carga y análisis de la escena. Cuando envías un archivo .max, .blend, .ma u otro tipo de escena, el sistema de ingesta de la granja lo descomprime y cataloga cada dependencia: texturas, cachés, meshes proxy, mapas HDRI, assets de plugins. Las dependencias faltantes son la causa más común de renders fallidos. Nuestro sistema señala los archivos faltantes antes de que tu trabajo entre en la cola, para que puedas corregir las rutas en lugar de desperdiciar tiempo de renderizado en fotogramas negros.
Validación de configuración de renderizado. La granja lee tu configuración de renderizado incorporada: tipo de motor, versión, resolución, rango de fotogramas, formato de salida, parámetros de muestreo. Compara estos datos con las configuraciones de nodos disponibles. Si especificaste V-Ray 7 pero la escena fue guardada en formato V-Ray 6, el sistema detecta esta incompatibilidad antes de que comience el renderizado.
Estimación de costo. Basándose en la complejidad de la escena, la resolución, los conteos de muestras y datos históricos de trabajos similares, el sistema genera una estimación de tiempo y costo. No se trata de suposiciones: hemos procesado suficientes trabajos como para construir modelos estadísticos que predicen el tiempo de renderizado con un margen razonable para la mayoría de las escenas estándar.
Cola de trabajos y sistemas de prioridad
Una vez validado, tu trabajo entra en una cola. La forma en que las granjas de render gestionan esta cola determina si recibes tus fotogramas en dos horas o en doce.
Niveles de prioridad. La mayoría de las granjas ofrecen múltiples niveles de prioridad. Los trabajos de mayor prioridad acceden a más nodos simultáneamente y pueden interrumpir trabajos de menor prioridad. En nuestra granja, la diferencia entre prioridad estándar y alta es significativa: un trabajo de 200 fotogramas podría renderizarse en 20 nodos con prioridad estándar frente a 80 nodos con prioridad alta.
Planificación equitativa. El gestor de cola equilibra los recursos entre todos los usuarios activos. Ningún trabajo monopoliza toda la granja, ni siquiera con prioridad alta. Si la granja tiene 400 nodos CPU disponibles y tres trabajos de alta prioridad se ejecutan simultáneamente, el planificador distribuye los nodos proporcionalmente según el tamaño del trabajo, el tiempo estimado de finalización y el nivel del usuario.
Interrupción y reubicación en cola. Cuando llega un trabajo de alta prioridad y la granja está a plena capacidad, el planificador puede pausar fotogramas de trabajos de menor prioridad y reasignar esos nodos. Los fotogramas pausados vuelven a entrar en la cola automáticamente: no se pierde ningún trabajo, aunque los de menor prioridad tardan más en completarse.
Detección de nodos inactivos. Si un nodo de renderizado deja de responder (fallo de hardware, caída de driver, timeout de red), el gestor de cola detecta el silencio en segundos y reasigna los fotogramas en progreso de ese nodo a nodos funcionales. Esto ocurre de forma transparente: nunca verás la falla en tu resultado.
Distribución de la escena: cómo llegan los archivos a los nodos de renderizado
Antes de que un nodo pueda renderizar el fotograma 47 de tu animación, necesita tu escena completa: geometría, texturas, cachés y configuración. Mover estos datos de manera eficiente es un desafío fundamental de infraestructura.
Sistemas de archivos en red. La mayoría de las granjas de render de producción utilizan almacenamiento compartido de alta velocidad (NFS, SMB o sistemas de archivos distribuidos propietarios) en lugar de copiar los archivos de escena a cada nodo individualmente. La escena reside en un clúster de almacenamiento central y los nodos de renderizado acceden a ella a través de la red. Esto evita el cuello de botella de copiar una escena de 50 GB a 100 nodos secuencialmente.
Caché y localidad. Las granjas inteligentes almacenan en caché los assets de acceso frecuente localmente en los nodos de renderizado. Si tres trabajos del día usan el mismo paquete HDRI o la misma biblioteca de materiales de V-Ray, los nodos que ya tienen esos archivos en caché omiten la transferencia de red. Esto reduce el tiempo de inicio por fotograma de minutos a segundos para texturas repetidas.
Streaming de texturas. Para escenas con conjuntos masivos de texturas (común en visualización arquitectónica con bibliotecas de materiales 4K+), algunas configuraciones de granja transmiten texturas bajo demanda en lugar de precargar todo. El motor de renderizado solicita un tile de textura, el sistema de almacenamiento lo entrega y el nodo lo almacena en caché localmente para fotogramas posteriores. Esto intercambia una latencia ligeramente mayor por tile por un tiempo de carga inicial significativamente menor.
La fase de renderizado: procesamiento CPU y GPU
Con la escena cargada y el fotograma asignado, comienza el renderizado real. La forma en que las granjas asignan recursos CPU frente a GPU refleja compensaciones reales de rendimiento y costo.

Comparación entre renderizado CPU y GPU mostrando diferencias en velocidad, memoria, mejores casos de uso, software compatible y especificaciones de hardware
Renderizado CPU. Los motores basados en CPU (V-Ray CPU, Corona, Arnold CPU) distribuyen el trabajo entre todos los núcleos disponibles de un nodo. Un nodo CPU típico de una granja tiene 44 o más núcleos con 96-256 GB de RAM. El amplio grupo de memoria significa que los nodos CPU manejan escenas que desbordarían la VRAM de una GPU: interiores complejos de visualización arquitectónica con mapas de desplazamiento, simulaciones de partículas con millones de elementos o efectos volumétricos con cachés de alta resolución.
En nuestra granja, aproximadamente el 70% de los trabajos de renderizado se ejecutan en nodos CPU. Esto refleja los flujos de trabajo de producción en visualización arquitectónica y VFX que dominan el renderizado profesional: estas escenas tienden a ser pesadas en memoria y utilizan motores como V-Ray y Corona que están optimizados para rendimiento CPU multinúcleo.
Renderizado GPU. Los motores basados en GPU (Redshift, Octane, V-Ray GPU, Cycles con OptiX) aprovechan los miles de núcleos paralelos de las tarjetas gráficas modernas. Nuestros nodos GPU utilizan tarjetas NVIDIA RTX 5090 con 32 GB de VRAM. El renderizado GPU es típicamente más rápido por fotograma para escenas que caben dentro de los límites de VRAM, pero esos límites son reales: una escena que requiere 40 GB de datos de textura y geometría no puede renderizarse en una tarjeta de 32 GB sin recurrir a mecanismos out-of-core que reducen el rendimiento.
Asignación híbrida. Algunos trabajos se benefician de dividirse entre nodos CPU y GPU. Un patrón común: los nodos GPU manejan los pases de belleza (rápidos por fotograma, limitados por VRAM), mientras que los nodos CPU procesan pases volumétricos o de partículas que exceden la capacidad de VRAM. El planificador de trabajos de la granja soporta esta división, dirigiendo diferentes capas de renderizado al hardware apropiado.
Ensamblaje de fotogramas y control de calidad
Renderizar un fotograma es solo la mitad del trabajo. La granja también debe verificar la calidad del resultado y ensamblar los fotogramas en un paquete de entrega coherente.
Controles de calidad automáticos. Después de que cada fotograma se renderiza, la granja ejecuta una validación básica: tamaño de archivo dentro del rango esperado (un PNG de 1 byte significa que el render falló silenciosamente), resolución que coincida con la especificación, sin fotogramas completamente negros o completamente blancos (indicadores comunes de luces o materiales faltantes) y formato de salida correcto. Los fotogramas que no pasan estos controles se vuelven a renderizar automáticamente en un nodo diferente.
Unión de fotogramas para renderizado por tiles. Algunos motores y configuraciones dividen un solo fotograma de alta resolución en tiles, renderizando la esquina superior izquierda en un nodo, la superior derecha en otro, y así sucesivamente. Después de que todos los tiles se completan, la granja los une en la imagen final de resolución completa. Este enfoque funciona bien para imágenes fijas de resolución extremadamente alta (8K+) donde un solo nodo tardaría horas por fotograma.
Entrega de resultados. Los fotogramas completados se escriben en el almacenamiento de salida de la granja y se ponen a disposición para descargar. Utilizamos almacenamiento en la nube con aceleración CDN para asegurar que las velocidades de descarga no estén limitadas por el ancho de banda de carga de la granja. Para secuencias de animación grandes (miles de archivos EXR), ofrecemos opciones de descarga masiva y podemos comprimir secuencias para una transferencia más rápida.
Arquitectura de red de una granja de render
La infraestructura que conecta los nodos de renderizado, el almacenamiento y los sistemas de gestión es tan importante como el hardware en sí.
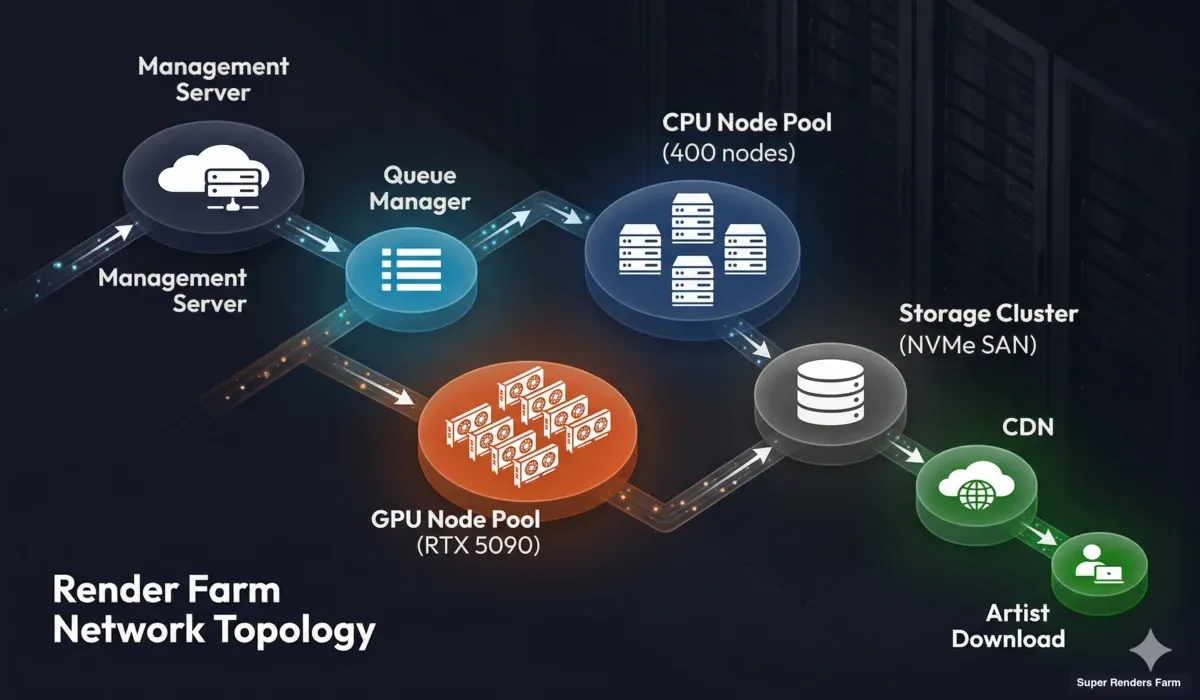
Topología de red de una granja de render mostrando servidor de gestión, gestor de cola, pools de nodos de renderizado CPU y GPU, clúster de almacenamiento y entrega CDN a los usuarios
Capa de gestión. Un servidor de gestión central orquesta todo: ingesta de trabajos, gestión de cola, monitoreo de estado de los nodos y comunicación con el usuario. Este servidor es redundante (con capacidad de failover) porque si se cae, toda la granja deja de aceptar y procesar trabajos.
Red de nodos de renderizado. Los nodos se comunican con la gestión y el almacenamiento a través de una red interna de alto ancho de banda. En las granjas modernas, esto es típicamente Ethernet de 10 Gbps o más rápido. El ancho de banda importa más durante la distribución de la escena (carga de texturas) y la salida de fotogramas (escritura de archivos EXR de alta resolución en el almacenamiento).
Clúster de almacenamiento. El almacenamiento central es el recurso compartido del que cada nodo de renderizado lee y en el que escribe. Debe manejar lecturas simultáneas de cientos de nodos solicitando tiles de textura y escrituras simultáneas de nodos produciendo fotogramas renderizados. Los arreglos de almacenamiento de alto rendimiento (SANs basadas en NVMe o sistemas de archivos distribuidos) son esenciales. Un sistema de almacenamiento lento crea un cuello de botella que ninguna cantidad de potencia CPU o GPU puede superar.
Conectividad a internet. La conexión de la granja con el mundo exterior determina qué tan rápido los usuarios pueden cargar escenas y descargar resultados. Las conexiones redundantes de múltiples gigabits son estándar en las granjas de producción. La proximidad geográfica a las principales bases de usuarios también importa: una granja en EE. UU. que atiende a un cliente europeo tendrá mayor latencia que una con un punto de presencia europeo.
Monitoreo y recuperación de errores
Las cosas fallan constantemente a escala. Una granja con cientos de nodos espera incidentes de hardware a diario. La diferencia entre una granja confiable y una que no lo es radica en cómo se detectan y manejan los fallos.
Monitoreo de estado de nodos. Cada nodo de renderizado informa su estado (temperatura CPU, uso de memoria, utilización GPU, espacio en disco, throughput de red) al sistema de gestión a intervalos regulares. Los nodos que no reportan se señalan de inmediato. Los nodos que muestran patrones anormales (temperatura en aumento, throughput en descenso) se eliminan preventivamente del pool antes de que fallen durante un renderizado.
Recuperación a nivel de fotograma. Cuando un nodo falla durante el renderizado, el fotograma que estaba procesando se marca como fallido y se reasigna a un nodo funcional. La granja registra qué fotogramas se han completado exitosamente frente a cuáles están en progreso o fallidos. Este seguimiento de estado asegura que ningún fotograma se pierda o duplique, incluso durante fallos en cascada de nodos.
Manejo de caídas del motor de renderizado. Más allá de los fallos de hardware, los propios motores de renderizado pueden fallar: condiciones de falta de memoria, elementos de escena corruptos o errores del motor. La granja distingue entre caídas recuperables (reintentar en un nodo diferente con más RAM) y no recuperables (el propio archivo de escena tiene un error que hará fallar todos los nodos). Después de un número configurable de reintentos, la granja informa el fallo al usuario con información de diagnóstico en lugar de reintentar indefinidamente.
Integridad de datos. Los fotogramas renderizados se verifican con checksums durante la escritura. Si un fallo de red corrompe un fotograma durante la transferencia al almacenamiento, la discrepancia en el checksum activa un re-renderizado automático. Esto es particularmente importante para archivos EXR, donde un solo byte corrupto puede producir artefactos visibles en la composición.
Pila de software de una granja de render
El software que coordina todo esto es tan crítico como el hardware.
Gestores de renderizado. Software de gestión de renderizado especializado se encarga de la planificación de trabajos, la asignación de nodos y la administración de la granja. Estos sistemas están diseñados para las demandas específicas del renderizado distribuido: seguimiento de dependencias a nivel de fotograma, gestión de versiones de motor por nodo y asignación de recursos multiusuario.
Herramientas de análisis de escenas. Antes de que un trabajo entre en la cola de renderizado, las herramientas de análisis examinan el archivo de escena para identificar dependencias, estimar requisitos de recursos y verificar errores comunes. Estas herramientas son específicas del motor: un analizador de escenas V-Ray comprueba problemas diferentes a un analizador de Blender Cycles.
Gestión de versiones. Una granja de producción mantiene múltiples versiones de cada motor de renderizado simultáneamente. Un usuario puede necesitar V-Ray 6 para un proyecto antiguo mientras otro requiere V-Ray 7. La infraestructura de software de la granja asegura que cada nodo cargue la versión correcta del motor para el trabajo asignado, alternando entre versiones a medida que diferentes trabajos se turnan.
Paneles de monitoreo. Los operadores de la granja utilizan paneles en tiempo real que muestran el estado de los nodos, la profundidad de la cola, los trabajos activos, las tasas de finalización y las frecuencias de errores. Estos paneles permiten una respuesta rápida ante problemas: si las tasas de error aumentan en un grupo de nodos en particular, el operador puede investigar de inmediato en lugar de descubrir el problema horas después.
Cómo se diferencian las granjas completamente gestionadas de las plataformas de autoservicio
No todas las granjas de render funcionan de la misma manera. Las dos categorías principales, completamente gestionadas y de autoservicio, manejan el flujo de trabajo de forma diferente.
Las granjas completamente gestionadas (como Super Renders Farm) se encargan de toda la infraestructura técnica. Cargas una escena, seleccionas tu configuración y la granja gestiona todo lo demás: instalación de software, gestión de versiones, compatibilidad de plugins, recuperación de errores y entrega de resultados. No necesitas conectarte remotamente a ninguna máquina ni gestionar ninguna infraestructura. Esto importa porque la configuración de motores de renderizado es compleja: solo V-Ray tiene docenas de configuraciones específicas por versión que afectan la compatibilidad con la granja.
Las plataformas de autoservicio o IaaS te alquilan máquinas virtuales con software de renderizado preinstalado. Te conectas remotamente, configuras el software tú mismo, gestionas tu propia cola de renderizado y te encargas de la resolución de problemas. Esto te da más control, pero requiere significativamente más experiencia técnica e inversión de tiempo.
Para una comparación detallada, nuestra guía de renderizado en la nube gestionado vs DIY desglosa las ventajas y desventajas.
La estructura de costos detrás de los precios de las granjas de render
Entender cómo funcionan las granjas de render también implica entender qué estás pagando.
Precios por recurso. La mayoría de las granjas cobran según los recursos de cómputo consumidos: GHz-hora para renderizado CPU u OBs (unidades de cómputo) para GPU. Puedes estimar los costos antes de comprometerte usando herramientas como nuestra calculadora de costos. Esto significa que tu costo escala linealmente con la cantidad de recursos que usa tu trabajo. Un fotograma de 10 minutos en un nodo cuesta lo mismo independientemente de si la granja tiene 10 trabajos más ejecutándose o 1.000: pagas por lo que consumes.
Gastos generales de infraestructura. El precio por GHz-hora de la granja de render incluye no solo la electricidad para operar el CPU, sino también los costos amortizados de hardware, la infraestructura de almacenamiento, el ancho de banda de red, las licencias de software (las licencias de motor de renderizado para granjas son costosas), la refrigeración, la redundancia y el equipo de ingeniería que mantiene todo en funcionamiento. Una porción significativa del costo cubre la capa de confiabilidad y conveniencia que te ahorra gestionar esta infraestructura por tu cuenta.
Multiplicadores de prioridad. La prioridad más alta cuesta más porque otorga acceso a más nodos simultáneamente, lo que implica que otros trabajos ceden recursos. Esta es una compensación deliberada: los plazos urgentes justifican el costo adicional.
Para un desglose completo de precios, consulta nuestra guía de precios de granjas de render.
Resumen: el flujo de trabajo de una granja de render
El flujo completo, desde el envío hasta la entrega:
- Carga — el archivo de escena y las dependencias se transfieren al almacenamiento de la granja
- Validación — se verifican las dependencias, se comprueban los ajustes de renderizado y se estima el costo
- Cola — el trabajo entra en una cola basada en prioridades y espera la asignación de nodos
- Distribución — los datos de la escena se ponen a disposición de los nodos de renderizado asignados a través del almacenamiento en red
- Renderizado — los nodos CPU o GPU procesan los fotogramas asignados en paralelo
- Control de calidad — cada fotograma se valida (tamaño de archivo, resolución, contenido)
- Ensamblaje — los fotogramas se organizan y los tiles se unen si corresponde
- Entrega — los fotogramas completados están disponibles para descarga a través de almacenamiento acelerado por CDN
Cada paso tiene modos de fallo, y cada modo de fallo tiene recuperación automatizada. El resultado es un sistema que convierte de manera confiable tus archivos de escena en fotogramas renderizados a velocidades que ninguna estación de trabajo individual puede igualar.
FAQ
Q: ¿Cuánto tarda una granja de render en procesar un trabajo de animación típico? A: Depende de la complejidad del fotograma y el nivel de prioridad. Una animación de visualización arquitectónica de 500 fotogramas a 1080p con V-Ray típicamente se completa en 2-6 horas en una granja frente a 3-7 días localmente. Los trabajos acelerados por GPU (Redshift, Cycles) suelen ser más rápidos por fotograma pero están limitados por la VRAM para escenas complejas.
Q: ¿Qué sucede si un nodo de renderizado falla durante mi trabajo? A: El gestor de cola de la granja detecta el fallo en segundos y reasigna el fotograma en progreso a un nodo funcional. No se pierde ningún fotograma. Si la caída fue causada por un error de la escena (no del hardware), el sistema reintenta en una configuración de nodo diferente antes de señalarlo como un problema del usuario.
Q: ¿Necesito instalar el software de renderizado en la granja yo mismo? A: En granjas completamente gestionadas como Super Renders Farm, no. Mantenemos todos los motores de renderizado compatibles (V-Ray, Corona, Arnold, Redshift, Cycles y otros) en toda nuestra flota de nodos, incluyendo múltiples versiones para compatibilidad. Las plataformas de autoservicio pueden requerir que gestiones la instalación del software por tu cuenta.
Q: ¿Puede una granja de render manejar escenas que exceden la VRAM de mi GPU local? A: Sí. Los nodos de renderizado CPU en nuestra granja tienen 96-256 GB de RAM, lo que permite manejar escenas que desbordarían la GPU de una estación de trabajo. Para motores específicos de GPU, nuestros nodos RTX 5090 proporcionan 32 GB de VRAM, más que la mayoría de las GPU de escritorio. Las escenas que exceden incluso eso se dirigen a nodos CPU automáticamente.
Q: ¿Cómo maneja la granja las diferentes versiones de motores de renderizado? A: Las granjas de producción mantienen múltiples versiones de cada motor simultáneamente. Cuando envías un trabajo, el sistema empareja la versión del motor de tu escena con nodos compatibles. Si guardaste tu escena en V-Ray 6, se renderiza en nodos V-Ray 6, no en V-Ray 7, que podría interpretar la configuración de manera diferente.
Q: ¿Están seguros mis datos de escena en una granja de render? A: Las granjas de buena reputación utilizan transferencias cifradas (TLS/SSL para carga y descarga), almacenamiento con control de acceso (tus archivos están aislados de otros usuarios) y eliminación automática de los datos de escena después de un periodo de retención. En nuestra granja, los archivos de escena se eliminan automáticamente después de la finalización del trabajo más una ventana de retención configurable.
Q: ¿Qué formatos de archivo debo usar al enviar a una granja de render?
A: Usa el formato nativo de tu DCC (.max para 3ds Max, .blend para Blender, .ma/.mb para Maya). Para la salida, especifica EXR para flujos de trabajo de composición o PNG para entrega. Siempre renderiza a secuencias de imágenes, no a archivos de video: si un fotograma falla, solo ese fotograma necesita re-renderizarse.
Q: ¿Cómo manejan las granjas de render las dependencias de plugins como Forest Pack o Scatter? A: Las granjas gestionadas mantienen los plugins comunes en toda su flota de nodos. Cuando envías una escena que usa Forest Pack, la granja asegura que los nodos asignados a tu trabajo tengan la versión correcta de Forest Pack instalada. Los plugins menos comunes pueden requerir aviso previo para que la granja pueda desplegarlos antes de que se ejecute tu trabajo.
Lecturas adicionales
- ¿Qué es una granja de render? — guía fundamental sobre conceptos de granjas de render
- Guía de precios de granjas de render — cómo funcionan los modelos de precios en la industria
- Renderizado en la nube vs local — cuándo tiene sentido el renderizado en granja frente al local
- Autodesk Knowledge Network — Distributed Rendering — documentación oficial de renderizado distribuido de 3ds Max
- Blender Manual — Render Output — configuración de salida de renderizado de Blender
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



