
Renderizado cloud-based vs cloud computing rendering: guía de distinción 2026
Resumen
Introducción
Los resultados de búsqueda de "cloud rendering" mezclan dos cosas genuinamente diferentes. Una es el renderizado cloud-based — servicios de renderizado diseñados específicamente donde subes un archivo de proyecto y recibes los fotogramas de vuelta. La otra es el cloud computing rendering — máquinas virtuales de propósito general de proveedores de nube que tú mismo configuras para renderizar. Comparten las mismas palabras clave y gran parte del mismo hardware, pero el flujo de trabajo, el modelo de precios y los requisitos de habilidades divergen considerablemente en cuanto empiezas a usarlos en producción.
A lo largo de los años hemos ayudado a clientes a migrar en ambas direcciones — estudios que pasaron de entornos DIY en AWS a nuestro pipeline gestionado, y ocasionalmente equipos internos que tomaron el camino contrario para construir algo personalizado en Azure o Google Cloud. Los compromisos son suficientemente consistentes como para que hayamos escrito esta guía para exponerlos claramente.
Este artículo cubre la distinción arquitectónica entre renderizado cloud-based y cloud computing rendering, las categorías de vendors que encontrarás, dónde encaja cada modelo en el flujo de trabajo y presupuesto de distintos equipos, los cálculos de costo que determinan qué enfoque ahorra realmente dinero, y los errores de migración más frecuentes que vemos cuando los equipos cambian de un modelo al otro.
Renderizado cloud-based vs cloud computing rendering — La distinción fundamental
Los dos términos se usan como sinónimos en artículos de blog, páginas de vendors y asistentes de IA. No lo son.
El renderizado cloud-based describe una abstracción de servicio. Interactúas a través de una interfaz específica para renderizado — un uploader de escritorio, un panel de control web, una API que recibe tu archivo de escena y devuelve fotogramas. La infraestructura subyacente es invisible. El software, los plugins, las licencias, la gestión de la cola, la selección de máquinas, la transferencia de archivos y la gestión de nodos son responsabilidad del vendor. Lo que te importa son los fotogramas renderizados; los pasos intermedios están gestionados.
El cloud computing rendering describe el acceso a infraestructura. Alquilas máquinas virtuales (o instancias bare metal) de una nube de propósito general — AWS EC2, Azure Virtual Machines, Google Compute Engine, o proveedores IaaS GPU especializados — y las operas tú mismo. Instalas Cinema 4D o Maya, configuras Redshift o V-Ray, estableces tus rutas de archivo, ejecutas tu gestor de renderizado, monitorizas el trabajo y apagas todo cuando termina. El proveedor de nube suministra CPU/GPU/RAM/disco y una red. Todo lo que está por encima del sistema operativo es tuyo.
Ambos producen el mismo resultado final en disco. El camino para llegar es lo que difiere.
| Aspecto | Renderizado cloud-based | Cloud computing rendering |
|---|---|---|
| Unidad principal comprada | Fotogramas renderizados u horas de renderizado | Horas de máquina virtual |
| Instalación de software | Por el vendor | Por ti |
| Licencias del motor de renderizado | Incluidas o gestionadas por el vendor | Trae tu propia licencia |
| Transferencia de archivos | Uploader integrado / tránsito S3 | Tú configuras |
| Escalado | Automático en los nodos disponibles | Manual o mediante scripts |
| Habilidades requeridas | Artista de renderizado | Artista de renderizado + ingeniero cloud-ops |
| Tiempo hasta el primer fotograma | Minutos después de la subida | 30–90 minutos (build de imagen, licencia, sincronización de archivos) |
| Facturación en inactividad | Ninguna — pagas solo por el renderizado activo | Sí — la VM acumula horas hasta que se detiene |
Esta distinción importa porque la mayoría de las decisiones sobre "cloud rendering" son en realidad decisiones sobre en qué capa de abstracción quieres operar.
Distinción arquitectónica: render farm gestionada vs IaaS GPU cloud
Los servicios de renderizado cloud-based y las plataformas de cloud computing rendering no solo empaquetan el compute de forma diferente — están construidos para modelos operativos distintos.
Arquitectura de la render farm cloud gestionada (cloud-based):
Un operador de render farm gestiona una flota homogénea detrás de una cola de trabajos. Cada nodo tiene el mismo software DCC preinstalado, las mismas licencias de motor de renderizado, el mismo recurso compartido de red y el mismo agente de monitorización. Cuando envías un proyecto, un scheduler lo divide en tareas a nivel de fotograma y las distribuye a cualquier nodo disponible del pool. No eliges las máquinas; el pool elige por ti.
En nuestra render farm, ese pool comprende actualmente más de 20.000 núcleos CPU en la flota CPU, más máquinas GPU dedicadas con NVIDIA RTX 5090 (32 GB de VRAM cada una). Los archivos de proyecto transitan a través de AWS S3 entre tu máquina y los nodos de renderizado — S3 aquí es solo una capa de transporte, no el compute. El compute es local a una región de renderizado (la nuestra está en Hà Nội), lo que mantiene baja la latencia fotograma a fotograma y simplifica la gestión de licencias. Como socio oficial de Maxon y render partner de Chaos Group, gestionamos las licencias de los motores de renderizado del lado de la farm.
Super Renders Farm opera este modelo gestionado — una render farm de GPU y CPU donde la cola, la selección de nodos y las licencias recaen en el lado del operador y no en el tuyo.
Arquitectura IaaS GPU cloud (cloud computing rendering):
Un proveedor IaaS GPU te da una instancia Linux o Windows vacía con una GPU conectada. AWS, Azure y Google ofrecen todos instancias GPU; proveedores especializados como CoreWeave, RunPod, Lambda y Vast.ai compiten en precio y velocidad de aprovisionamiento. Ninguno de ellos sabe qué es Redshift. No les importa si estás renderizando, entrenando un modelo o transcodificando vídeo.
Eres responsable de: construir o encontrar una imagen de máquina con tu DCC + motor de renderizado instalado, conectar un servidor de licencias o mover licencias node-locked, montar el almacenamiento (block storage, object storage o NFS), copiar tu escena y assets a ese almacenamiento, ejecutar el gestor de renderizado (Deadline, Royal Render, un script personalizado o simplemente redshiftCmdLine), vigilar los fallos y apagar todo antes de que las horas de inactividad empiecen a acumularse.
La diferencia de abstracción es real. Una render farm cloud-based oculta el 80% de las decisiones de infraestructura. Un IaaS GPU cloud las expone todas.
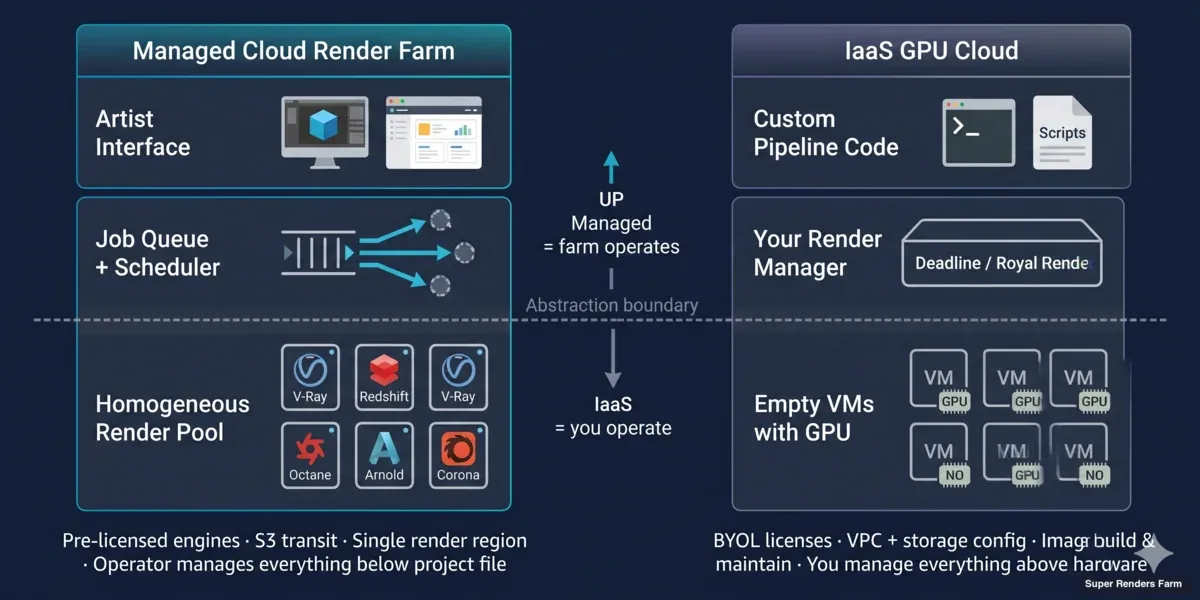
Layered architecture diagram comparing managed cloud render farm operations versus IaaS GPU cloud rendering operational responsibilities
Cuándo encaja el renderizado cloud-based
El modelo de servicio gestionado encaja en equipos cuyo valor reside en la producción creativa y cuyo tiempo está mejor empleado en el DCC, no en DevOps.
Super Renders Farm es una opción de render farm gestionada dentro de esta categoría; los mismos compromisos que se exponen a continuación se aplican a cualquier vendor que ejecute la abstracción cloud-based.
Freelancers independientes y estudios de motion design / archviz de 1 a 3 personas. Configurar un pipeline IaaS GPU multinodo resulta rentable a partir de unas 100+ horas de renderizado al mes si el equipo tiene las habilidades cloud internamente. Por debajo de ese umbral, la carga operativa — mantenimiento de imágenes, disponibilidad del servidor de licencias, sorpresas en la factura — consume los ahorros.
Estudios con pipelines orientados a plazos de entrega. Cuando un cliente adelanta una entrega dos días, una render farm gestionada escala el trabajo en curso ajustando la prioridad. En IaaS, tendrías que aprovisionar instancias adicionales, copiar los assets, configurarlas e integrarlas en tu gestor de renderizado — quizá a tiempo, quizá no.
Equipos que usan motores de renderizado comerciales sin licencia por volumen. Redshift, V-Ray, Corona, Octane y Arnold tienen condiciones de licencia para nodos de renderizado que se encarecen al gestionarlos uno mismo. Nuestro modelo incluye esas licencias en la tarifa por fotograma o por GHz-hora; en IaaS traes las tuyas y consumes los node-locks.
Producciones donde una mala noche arruina un plazo. Una render farm gestionada cuenta con personal de soporte que ya ha visto la mayoría de los modos de fallo y puede intervenir en un trabajo a mitad del renderizado. En IaaS, depurar un renderizado bloqueado a las 2 de la madrugada es asunto tuyo.
El compromiso es la flexibilidad. Una render farm gestionada ejecuta los motores y versiones de plugins que ha probado. Si tu proyecto depende de un plugin nuevo que aún no se ha añadido, esperas a que el soporte lo valide. En IaaS instalas lo que quieras.
Cuándo encaja el cloud computing rendering
El modelo IaaS encaja en equipos cuyo pipeline es en sí mismo el producto, o cuyos requerimientos de renderizado quedan muy fuera de lo que cubre el catálogo de una render farm gestionada.
Equipos con pipelines de renderizado personalizados o propietarios. Si has construido un motor de renderizado interno, modificado un motor de código abierto, o ejecutas un pipeline distribuido no estándar con dependencias personalizadas, ninguna render farm gestionada lo absorberá de la noche a la mañana. Alquilar compute en bruto y escribir scripts de orquestación es la única opción.
Híbridos ML-renderizado. Los equipos que trabajan con Gaussian splatting, neural radiance fields, pipelines de denoising con IA, o que entrenan sus propios modelos junto al renderizado se benefician de poseer el stack completo. La misma instancia GPU que renderiza un fotograma puede ejecutar un trabajo de inferencia entre renderizados. Las render farms gestionadas no ofrecen esa flexibilidad.
Estudios con cloud-ops internos y artistas cómodos con Linux. Cuando el equipo interno ya gestiona AWS, Azure o Google Cloud para otras cargas de trabajo, añadir un pipeline de renderizado reutiliza habilidades, facturación y perímetros de seguridad existentes.
Cargas de trabajo que no encajan en el modelo de facturación de una render farm. Algunos pipelines necesitan sesiones interactivas de larga duración (por ejemplo, un tech artist iterando en una escena pesada con vista previa en vivo), que no se adaptan bien a la facturación por fotograma. Alquilar una instancia por el día sale más barato que luchar contra ese modelo.
El compromiso es la carga operativa. Ahora gestionas una pequeña práctica de gestión del renderizado además de tu práctica creativa. Ese es un costo real.
Comparativa de costos: renderizado cloud-based vs cloud computing rendering
Ambos modelos anuncian tarifas horarias bajas, pero el costo total difiere mucho en cuanto incluyes todo lo necesario para que un renderizado termine realmente.
Renderizado cloud-based (por fotograma o por GHz-hora):
Pagas por el tiempo de renderizado activo. Los costos de licencia, el tiempo de inactividad de las máquinas, las actualizaciones de software, el soporte y el almacenamiento durante el trabajo están incluidos en la tarifa. Un plano de motion design típico de 720 fotogramas a 1 minuto/fotograma en hardware GPU cuesta aproximadamente 15–30 $ en nuestra render farm con prioridad estándar. Una animación archviz de 1.500 fotogramas a 3 min/fotograma en CPU cuesta aproximadamente 80–150 $. Sin sorpresas — ves una estimación antes de que empiece el trabajo y un resumen final al terminar.
Cloud computing rendering (por hora de VM + todo lo demás):
La cifra de cabecera es la tarifa de la instancia GPU. Las instancias AWS p5 (H100), Azure NDv5 y Google A3 cuestan aproximadamente 5–30 $/hora según la configuración. Los clouds GPU especializados anuncian tarifas más bajas — CoreWeave, RunPod y Vast.ai rondan los 0,40–2,50 $/hora para GPUs de nivel consumidor.
La tarifa de la instancia es el punto de partida. Añade: transferencia de datos de salida (0,05–0,09 $/GB en AWS — un proyecto de 50 GB recuperado como 100 GB de secuencia EXR es un costo real), almacenamiento de objetos (0,023 $/GB-mes en espera), tiempo de aprovisionamiento (30–90 minutos de horas facturadas antes del primer fotograma), costos de licencia (node-locks de Redshift ~45 $/mes/asiento, nodos de renderizado de V-Ray aproximadamente 42 $/mes cada uno — facturados independientemente de la utilización), y el servidor de licencias si usas BYOL. Si la tarifa cargada de ingeniería de tu equipo es de 80–150 $/hora, cada hora de depuración cloud-ops se suma al total.
Para una comparación justa, acompañamos a los equipos a través del análisis de costos render farm vs instalación propia y los modelos de precios de render farms antes de decidir. Las tarifas de cabecera mienten. La cifra horaria que parece un 60% más barata en IaaS suele reducir la diferencia al 10–15% una vez incluidos licencias, transferencia, inactividad y tiempo operativo — y eso antes de eventos de riesgo por plazos.

Stacked bar infographic comparing total cost composition between cloud-based render farm pricing and IaaS GPU cloud rendering with hidden costs flagged
Categorías de vendors: render farms cloud gestionadas vs IaaS GPU clouds vs híbridas
El panorama de vendors se divide claramente a lo largo de la línea de abstracción, con un pequeño grupo intermedio:
Render farms cloud puramente gestionadas. Los vendors en esta categoría gestionan sus propios pools de renderizado homogéneos, incluyen licencias prelicenciadas de los motores de renderizado y exponen una interfaz específica de renderizado. El operador gestiona cada capa por debajo del archivo de proyecto. Los precios son por fotograma, por hora de renderizado o por GHz-hora — nunca por hora de VM. Flujo de trabajo típico: instalar la app de escritorio → subir el proyecto → renderizar → descargar.
IaaS GPU clouds puros. AWS, Azure, Google Compute Engine, más proveedores especializados (CoreWeave, RunPod, Lambda, Paperspace, Vast.ai). Venden máquinas virtuales con GPUs conectadas. Algunos publican imágenes DCC a través de marketplaces, pero el modelo operativo sigue siendo "alquila la máquina, ejecuta tu propio software".
Plataformas híbridas. Un pequeño nivel intermedio ofrece orquestación gestionada sobre IaaS — por ejemplo, servicios que aprovisionan instancias AWS, instalan tu motor de renderizado mediante un asistente y dividen los trabajos entre ellas. Estos reducen parte de la carga de configuración pero no eliminan la gestión de licencias ni la dependencia de las fluctuaciones de precios de un proveedor de nube de terceros. Son útiles cuando un equipo interno tiene cuentas y créditos en la nube pero carece de experiencia en pipelines de renderizado.
La categoría correcta de vendor depende enteramente de qué abstracción quieres realmente. Los equipos a veces eligen el nivel equivocado — por ejemplo, optar por IaaS para "ahorrar dinero" sin presupuestar el tiempo cloud-ops, o elegir una render farm gestionada e intentar instalar plugins personalizados a través de ella. La mayoría de los problemas de pipeline que vemos vienen de elegir un vendor cuyo modelo no coincide con la realidad operativa del equipo.
Ruta de migración: moverse entre renderizado cloud-based y cloud computing rendering
Los equipos migran en ambas direcciones. Los patrones que vemos con más frecuencia:
Renderizado DIY en cloud sobre AWS → render farm cloud gestionada.
Desencadenante habitual: un estudio pequeño configuró un pipeline Spot Instance + Deadline hace un año, el ingeniero que lo construyó se marchó, y ahora el equipo no puede pasar una noche de renderizado sin una interrupción. La migración suele ser rápida — unas pocas horas para instalar la app de escritorio, validar la preparación de escena y ejecutar un renderizado de prueba. La parte más difícil es dar de baja el pipeline antiguo cuidadosamente (cancelar instancias reservadas, archivar los Spot AMIs que el equipo había construido, exportar renderizados antiguos de S3 antes de que cambien las políticas del bucket).
Render farm cloud gestionada → pipeline IaaS personalizado.
Desencadenante habitual: el estudio creció, contrató un ingeniero de pipeline de renderizado, y descubrió que su flujo de trabajo había superado lo que cubre el catálogo de cualquier operador de render farm — passes AOV personalizados, scripts post-renderizado propietarios, o integración con una base de datos de assets interna. La migración no es trivial: construir y mantener imágenes DCC, configurar un servidor de licencias, elegir un gestor de renderizado, diseñar el layout del almacenamiento, escribir la monitorización. Presupuesta semanas, no días, y espera que los primeros tres meses cuesten más que la factura anterior de la farm antes de que la optimización alcance.
Híbrido (carga de trabajo dividida).
Algunos estudios usan ambos: render farm gestionada para el trabajo diario con clientes donde la fiabilidad importa, IaaS para pipelines experimentales o propietarios donde importa la flexibilidad. La doble factura es incómoda, pero la coincidencia operativa es buena.
Errores comunes en la configuración del cloud computing rendering
La mayoría de los proyectos de cloud computing rendering fallan en los mismos pocos puntos. Si vas por la ruta IaaS, el dinero ahorrado solo es real si evitas estos.
Subestimar el costo de transferencia. Las tarifas de datos de salida (0,05–0,09 $/GB en AWS, similares en Azure/GCP) se acumulan rápidamente con las secuencias EXR. Una animación 4K puede producir cientos de GB. Hemos visto equipos planificar un presupuesto de renderizado de 400 $ y recibir una factura de 1.200 $ porque no modelaron el egress.
Olvidar las horas de inactividad. Una instancia GPU dejada en funcionamiento un fin de semana entero porque el operador se olvidó de apagarla cuesta tanto como el renderizado en sí. Las Spot instances mitigan esto pero introducen riesgo de terminación a mitad del renderizado si el precio spot sube.
Subestimar el tiempo de build de imagen. Construir una imagen funcional de DCC + motor de renderizado + plugins lleva 1–3 días de tiempo de ingeniería la primera vez, más mantenimiento continuo en cada ciclo de releases. Los equipos presupuestan la factura de la nube pero no las horas de mantenimiento de imagen.
Fragilidad del servidor de licencias. Las licencias flotantes tunelizadas a través de una VPC hacia instancias efímeras fallan de formas que parecen errores de renderizado. Asignar licencias dedicadas fijas lo resuelve pero eleva el costo.
Errores en la elección del almacenamiento. Montar almacenamiento de objetos directamente en un renderizado provoca picos de latencia de I/O. El block storage es más rápido pero tiene límites de tamaño y localidad. La mayoría de los pipelines IaaS experimentados usan una solución híbrida (objetos para el archivo, block para el conjunto de trabajo activo del trabajo), lo que añade otra superficie de configuración.
Divergencia de rutas de archivo. Una escena de Cinema 4D o Maya creada en una workstation Windows suele referenciar rutas absolutas o letras de unidad locales que no existen en una instancia de renderizado Linux. El remapping de rutas es la causa más frecuente de fallos de "textura no encontrada".
Estos modos de fallo no aparecen en las render farms gestionadas porque el operador los gestiona centralmente. Son la carga operativa que viene con el modelo IaaS.
Marco de decisión: qué modelo usar
Una breve lista de verificación que orienta a la mayoría de los equipos hacia el nivel correcto:
Elige el renderizado cloud-based (render farm gestionada) si:
- Renderizas menos de ~100 horas al mes
- Tu equipo es de 1 a 5 personas centradas en la producción creativa
- Usas motores de renderizado comerciales estándar (V-Ray, Corona, Arnold, Redshift, Octane, Cycles)
- No tienes un ingeniero cloud-ops dedicado
- La fiabilidad de los plazos importa más que la flexibilidad de facturación
Elige el cloud computing rendering (IaaS GPU) si:
- Tienes un pipeline de renderizado personalizado o no estándar
- Tu equipo incluye a alguien con experiencia cloud-ops activa
- Necesitas integración estrecha con otras cargas de trabajo cloud (ML, base de datos de assets interna, servicios personalizados)
- Tu carga de trabajo incluye sesiones interactivas de larga duración, no solo lotes de fotogramas
- Puedes presupuestar el tiempo de ingeniería para operar el pipeline
Considera un enfoque híbrido si:
- Tu trabajo diario con clientes es en motor estándar + orientado a plazos (gestionado)
- Tu trabajo de I+D o experimental es personalizado (IaaS)
- Los dos nunca se solapan en el mismo proyecto
Para la mayoría de los estudios con los que trabajamos, el modelo de render farm gestionada gana en costo total porque la carga operativa de IaaS está sistemáticamente subestimada.
Ese es el razonamiento detrás de un servicio gestionado como Super Renders Farm: la tarifa por fotograma y por GHz-hora absorbe la carga de licencias, inactividad y soporte que un presupuesto IaaS tiene que asumir por separado. Para el ~10–15% de equipos que genuinamente tienen la capacidad de ingeniería y una carga de trabajo no estándar, IaaS es la respuesta correcta. El 10% restante se sitúa en el carril híbrido.
Si estás calculando el lado presupuestario de esta decisión, la calculadora de costos ofrece una estimación por proyecto frente a nuestras tarifas de render farm gestionada. Comparar eso con un presupuesto IaaS honesto — incluyendo licencia, transferencia, inactividad y tiempo operativo — es la única forma justa de decidir. Para un contexto más amplio sobre cómo funciona el renderizado distribuido en ambos modelos, la guía de cloud rendering explicado cubre la arquitectura central, y la comparación renderizado cloud gestionado vs DIY profundiza en los compromisos operativos que vemos con más frecuencia.
FAQ
Q: ¿Cuál es la diferencia entre renderizado cloud-based y cloud computing rendering? A: El renderizado cloud-based es una abstracción de servicio — subes un proyecto a una plataforma específica de renderizado y recibes los fotogramas renderizados, con el vendor gestionando el software, las licencias y la infraestructura. El cloud computing rendering es acceso a infraestructura — alquilas máquinas virtuales de un proveedor de nube de propósito general y las configuras tú mismo. El mismo resultado final en disco; caminos muy diferentes para llegar.
Q: ¿Es el cloud computing rendering siempre más barato que una render farm cloud gestionada? A: En la práctica, no. La tarifa por hora de VM en AWS, Azure o clouds GPU especializados suele parecer más baja, pero el costo total tiene que incluir las licencias del motor de renderizado, las tarifas de transferencia de datos de salida, el almacenamiento, el tiempo de aprovisionamiento antes del primer fotograma, el mantenimiento de imágenes y las horas de ingeniería para operar el pipeline. Una vez incluidos, la diferencia suele reducirse al 10–15% para cargas de trabajo estándar. IaaS gana en costo solo cuando los equipos tienen capacidad cloud-ops existente y pueden absorber la carga operativa.
Q: ¿Puedo usar AWS o Azure para renderizar en lugar de una render farm? A: Sí, y muchos equipos lo hacen — pero requiere un conjunto de habilidades diferente. Instalarás tu DCC y motor de renderizado tú mismo, gestionarás las licencias, configurarás el almacenamiento y la red, construirás imágenes de máquina reutilizables y operarás un gestor de renderizado. Resulta rentable para equipos con pipelines personalizados, híbridos ML-renderizado, o experiencia cloud-ops interna. Para flujos de trabajo estándar en motores de renderizado comerciales, una render farm cloud gestionada suele ser menos trabajo y un costo total similar.
Q: ¿Qué es una render farm cloud gestionada y en qué se diferencia de un IaaS GPU cloud? A: Una render farm cloud gestionada opera una flota homogénea de nodos de renderizado preconfigurados detrás de una cola de trabajos. Subes un proyecto, el sistema programa los fotogramas en los nodos disponibles y recibes los resultados. Un IaaS GPU cloud vende máquinas virtuales vacías con GPUs conectadas — sin software DCC, sin motor de renderizado, sin scheduler, sin licencias incluidas. El modelo de render farm intercambia flexibilidad por simplicidad operativa; el modelo IaaS intercambia simplicidad por flexibilidad.
Super Renders Farm es un ejemplo del lado de la render farm gestionada de esta división — envías un proyecto y recibes los fotogramas, con los motores de renderizado, las licencias y la programación gestionados en la farm.
Q: ¿Cuándo debería migrar del renderizado cloud DIY en AWS a una render farm gestionada? A: Los desencadenantes habituales que vemos: el ingeniero que construyó el pipeline original se marchó y el equipo no puede mantenerlo funcionando, la factura cloud creció por encima del costo del trabajo equivalente en render farm gestionada, los trabajos críticos de deadline empezaron a fallar fuera de horario, o el equipo se dio cuenta de que pasaba más tiempo en cloud-ops que en trabajo creativo. La migración en sí misma suele ser rápida — una instalación de app de escritorio, preparación de escena y un renderizado de prueba — pero planifica tiempo para dar de baja la antigua infraestructura AWS cuidadosamente para no seguir pagando por ella.
Q: ¿Necesito traer mi propia licencia de motor de renderizado a una render farm cloud? A: Para la mayoría de las render farms cloud gestionadas que operan bajo acuerdos de asociación oficiales, no — las licencias de renderizado para V-Ray, Corona, Arnold, Redshift, Octane y Cycles están incluidas en la tarifa. En los IaaS GPU clouds, casi siempre traes tu propia licencia, ya sea node-locked a instancias específicas (más barato pero inflexible) o flotante a través de un servidor de licencias (flexible pero operativamente frágil). La gestión de licencias es uno de los costos ocultos más grandes del cloud rendering autogestionado.
Q: ¿Qué hardware utilizan típicamente los servicios de renderizado cloud-based? A: Las render farms cloud modernas utilizan una mezcla de hardware CPU y GPU dimensionado para el renderizado en producción. Nuestra render farm en particular opera con más de 20.000 núcleos CPU para motores como V-Ray, Corona y Arnold, más máquinas GPU dedicadas con NVIDIA RTX 5090 (32 GB de VRAM) para Redshift, Octane y V-Ray GPU.
Super Renders Farm dimensiona esa flota para el renderizado en producción y no para el cómputo de propósito general, que es la diferencia práctica frente a una instancia GPU IaaS que hay que configurar para cada trabajo. Los IaaS GPU clouds ofrecen un rango más amplio — desde RTX 4090 de nivel consumidor hasta H100 de centro de datos — con puntos de precio muy diferentes. Para el renderizado comercial, las GPUs de nivel RTX suelen ser el punto de equilibrio precio-rendimiento independientemente del modelo.
Q: ¿Puedo ejecutar renderizado interactivo o con vista previa en vivo en una render farm cloud? A: Las render farms cloud gestionadas están optimizadas para cargas de trabajo en lote — enviar un proyecto, renderizar fotogramas, entregar resultados. El renderizado interactivo con retroalimentación IPR en vivo es territorio de workstation, no de render farm. Si necesitas sesiones interactivas de larga duración en la nube, una instancia IaaS GPU con acceso a escritorio remoto es la forma correcta — pero eso es cloud computing rendering, no renderizado cloud-based. Los dos modelos resuelven genuinamente problemas diferentes.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



