
Automatização de Upload para Render Farm com Python: Guia paramiko e rsync
Visão geral
A parte mais lenta de uma renderização na nuvem muitas vezes não é a própria renderização. Para um estúdio que envia uma cena VFX com várias câmaras ou uma cache Houdini de 400 GB para uma render farm todas as noites, o ponto crítico é mover os dados — garantir que o projeto sobe de forma fiável e que os frames terminados descem antes da chegada da equipa de manhã. Fazer isso manualmente, a observar uma barra de progresso à meia-noite, não é escalável. Com scripts, é.
Este guia trata de automatizar essa camada de transferência em Python. Operamos a Super Renders Farm, uma render farm totalmente gerida, e "totalmente gerida" tem um significado preciso para automação: não é preciso aceder remotamente às máquinas, instalar software ou gerir licenças — a parte do pipeline que se programa é a que é nossa — os ficheiros a subir e as renderizações a descer. A superfície de transferência é genuinamente programável via SFTP, e Python é uma forma de primeira classe para a controlar. A nossa própria documentação de transferência menciona diretamente a biblioteca paramiko do Python como cliente suportado, a par de rsync via SSH e da linha de comandos sftp padrão.
Seremos igualmente precisos sobre o que não é possível automatizar a partir de Python hoje em dia, porque um pipeline construído sobre uma funcionalidade que não existe é um pipeline que falha na primeira execução desacompanhada. Se pretender o mapa conceptual mais amplo — o que significa "sem cabeça" versus "desacompanhado", como preparar cenas para renderização por linha de comandos — existe um guia complementar separado para esse efeito. Este fica ao nível do código, focado na camada de transferência: paramiko, rsync, chaves SSH, retentativas e um padrão de sincronização noturna que pode ser integrado na automação de um estúdio.
O que é possível automatizar em Python hoje
É útil definir o limite antes de escrever qualquer código. Numa render farm gerida, uma parte do pipeline é totalmente programável, outra é deliberadamente controlada por interface gráfica, e uma parte fica entre ambas. Ser honesto sobre qual é qual evita que a automação falhe silenciosamente.
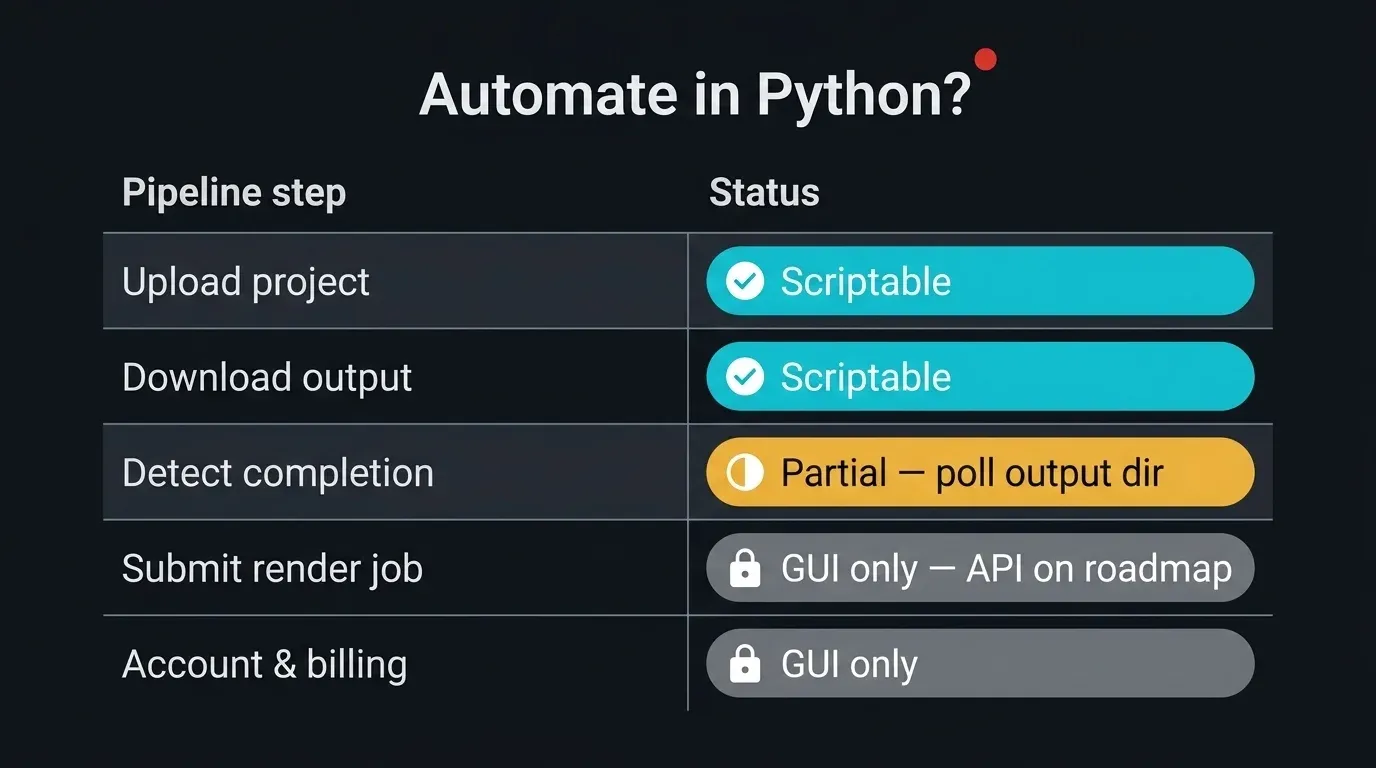
Diagrama de matriz a mostrar quais os passos do pipeline de uma render farm na nuvem gerida que podem ser automatizados em Python: Upload do projeto (totalmente programável via paramiko, rsync, sftp), Download de output (totalmente programável), Detetar conclusão de trabalho (parcial — sondagem do diretório SFTP de output, sem API de estado), Submeter trabalho de renderização (apenas interface gráfica — formulário web, Client App, ou plugin DCC), Gerir conta e faturação (apenas interface gráfica), com colunas de estado verde, âmbar e cinzento
- Upload de um projeto — totalmente programável. SFTP via
paramiko,rsync, ou comandossftpprogramados funcionam todos com o nosso servidor SFTP. É o núcleo do que se segue. - Download de frames terminados — totalmente programável. O output fica num diretório por trabalho que pode ser obtido com as mesmas ferramentas.
- Detetar que um trabalho terminou — parcial. Não existe uma API de estado pública para sondar. O que é possível fazer é sondar o diretório SFTP de output e aguardar que os frames apareçam e estabilizem. É uma heurística, não um sinal oficial, e tratamos o assunto como tal mais adiante.
- Submeter um trabalho de renderização — interface gráfica hoje. A submissão é feita através do formulário web, da SuperRenders Client App, ou de um plugin de submissão por DCC. Uma API REST pública para submissão de trabalhos, sondagem de estado e obtenção de output está no nosso roadmap, mas de momento não existem endpoints públicos disponíveis para integração direta. Se o pipeline estiver especificamente bloqueado numa API de submissão, contacte o suporte e partilhe o caso de uso — o roadmap é moldado por requisitos reais de pipeline.
- Gerir conta, créditos ou faturação — interface gráfica. Fora do âmbito da automação de transferência.
Portanto, a superfície automatizável é a transferência: enviar o projeto, obter as renderizações e preencher o intervalo intermédio através da monitorização do diretório de output. O passo de submissão fica como uma entrega deliberada, e vamos assinalá-lo claramente no pipeline final em vez de o ignorar. Para um tratamento mais completo do que a renderização gerida expõe e não expõe, o guia sobre o que é uma render farm totalmente gerida cobre o modelo; as novas contas podem começar pelo guia de introdução.
Pré-requisitos: acesso SFTP, chaves SSH e ambiente Python
Três coisas precisam de estar configuradas antes do primeiro upload programado.
Acesso SFTP, ativado por conta. O SFTP é ativado por conta mediante pedido. Inicie sessão, procure "SFTP access" nas definições da conta e gere as credenciais nesse local; se não estiver visível, peça ao suporte para o ativar. As credenciais incluem um hostname do servidor (varia por região e alocação de armazenamento, por isso trate-o como um valor lido da configuração, nunca escrito diretamente no código), um nome de utilizador associado à conta, uma palavra-passe ou chave SSH, e a porta SFTP padrão 22. Dois caminhos são relevantes: /uploads/<pasta-do-projeto>/ é a área de escrita, e /output/<id-do-trabalho>/ é onde as renderizações terminadas aparecem.
Uma chave SSH, não uma palavra-passe. Para qualquer coisa automatizada, a autenticação por chave SSH é a escolha certa — mantém os segredos fora dos scripts e funciona em execuções desacompanhadas sem necessidade de interação. Gere um par de chaves moderno e registe a metade pública na conta:
ssh-keygen -t ed25519 -C "pipeline@yourstudio.example"
# adicione o conteúdo de ~/.ssh/id_ed25519.pub em
# superrendersfarm.com -> Settings -> SFTP -> SSH Keys
Uma nota sobre segurança da conta: a autenticação de dois fatores não é atualmente suportada nas contas, por isso para SFTP o maior reforço de segurança é uma frase-chave no ficheiro de chave mais um agente SSH que a mantenha desbloqueada para a sessão. A chave, mais o conhecimento da sua frase-chave, desempenha um papel semelhante ao de um segundo fator — posse mais segredo.
Um ambiente Python com paramiko. Tudo o que se segue usa paramiko, a implementação padrão de SSH/SFTP em Python puro, e invoca rsync para transferências incrementais de grande dimensão.
python3 -m venv .venv && source .venv/bin/activate
pip install paramiko
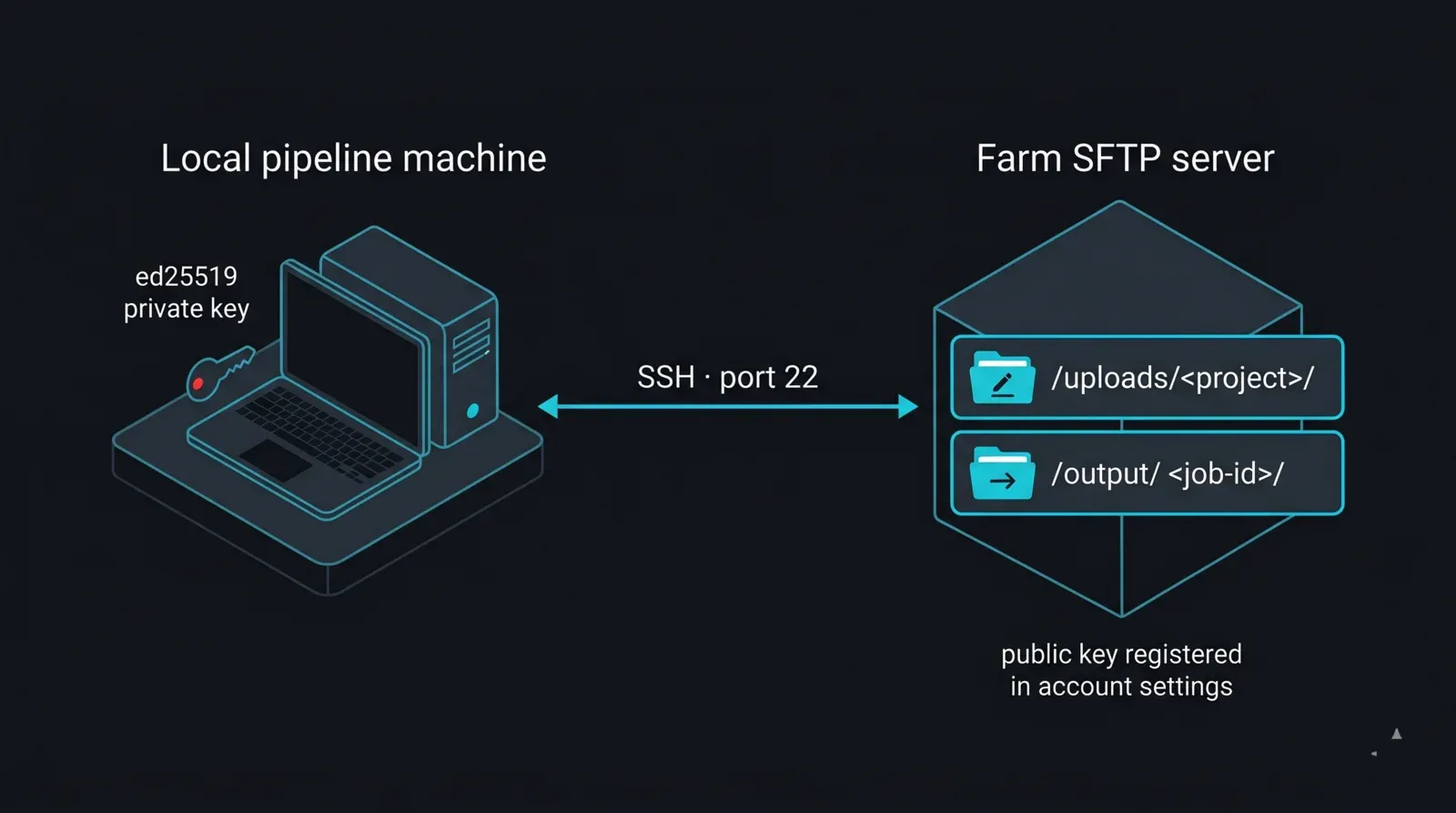
Diagrama do layout de conta SFTP e autenticação por chave para uma render farm gerida: uma máquina de pipeline local com uma chave privada ed25519 liga-se via porta SSH 22 ao servidor SFTP da render farm, que expõe dois diretórios — /uploads/<projeto>/ como área de escrita para projetos recebidos e /output/<id-do-trabalho>/ como área de leitura para frames terminados; a chave pública correspondente está registada nas definições da conta
Empacotar um projeto para sobreviver a um upload desacompanhado
A maioria dos trabalhos de renderização que falham não são falhas do motor — são lacunas no empacotamento. Uma cena que renderiza na workstation do artista falha num worker limpo porque um caminho de textura aponta para uma unidade local, ou uma sub-cena referenciada nunca foi incluída no pacote. A automação amplifica isto: um upload desacompanhado de um pacote com problemas produz uma falha desacompanhada. Duas regras mantêm os pacotes limpos.
Primeiro, torne o projeto autocontido com caminhos relativos. Execute o comando de recolha e empacotamento do DCC (Archive, Collect Files, Save Project with Assets) para que cada textura, proxy e cache resolva relativamente à raiz do projeto. Segundo, tenha em atenção o formato do arquivo se comprimir antes do upload: suportamos tar, tar.gz e 7z, mas não .zip — reempacote como .tar.gz, ou ignore o arquivamento e deixe o rsync transferir a árvore de pastas, o que normalmente é a melhor opção para projetos em curso. Como limite prático, mantenha um único upload abaixo de ~300 GB; acima disso, use rsync com retoma em vez de uma única transferência monolítica.
Fazer upload de um projeto com paramiko
O primeiro bloco de construção é um uploader recursivo. Liga-se com uma chave, percorre a árvore do projeto local, recria a estrutura de diretórios em /uploads/ e envia cada ficheiro. Fixamos as chaves do host com RejectPolicy e lemos os detalhes de ligação a partir do ambiente para que nada sensível fique no script.
import os
import paramiko
def connect():
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
key_path = os.environ["SRF_SFTP_KEY"] # caminho para a chave privada
client = paramiko.SSHClient()
client.load_system_host_keys() # confiar apenas em ~/.ssh/known_hosts
client.set_missing_host_key_policy(paramiko.RejectPolicy())
client.connect(hostname=host, port=22, username=user, key_filename=key_path)
return client, client.open_sftp()
def _ensure_remote_dir(sftp, remote_dir):
# mkdir -p via SFTP: construir o caminho segmento a segmento
path = ""
for segment in remote_dir.strip("/").split("/"):
path += "/" + segment
try:
sftp.stat(path)
except IOError:
sftp.mkdir(path)
def upload_dir(sftp, local_dir, remote_dir):
for root, _dirs, files in os.walk(local_dir):
rel = os.path.relpath(root, local_dir)
remote_root = remote_dir if rel == "." else f"{remote_dir}/{rel.replace(os.sep, '/')}"
_ensure_remote_dir(sftp, remote_root)
for name in files:
local_path = os.path.join(root, name)
remote_path = f"{remote_root}/{name}"
sftp.put(local_path, remote_path)
print(f"enviado {remote_path}")
A utilização para um projeto:
client, sftp = connect()
try:
upload_dir(sftp, "/local/projects/archviz-tower", "/uploads/archviz-tower-2026-06")
finally:
sftp.close()
client.close()
Isto é suficiente para projetos pequenos e médios. sftp.put também aceita um argumento callback= que recebe os bytes transferidos e o total, o qual pode ser ligado a um medidor de progresso ou a uma linha de registo por ficheiro. Para as transferências grandes e repetidas que caracterizam o trabalho de estúdio, porém, rsync é a ferramenta mais adequada.
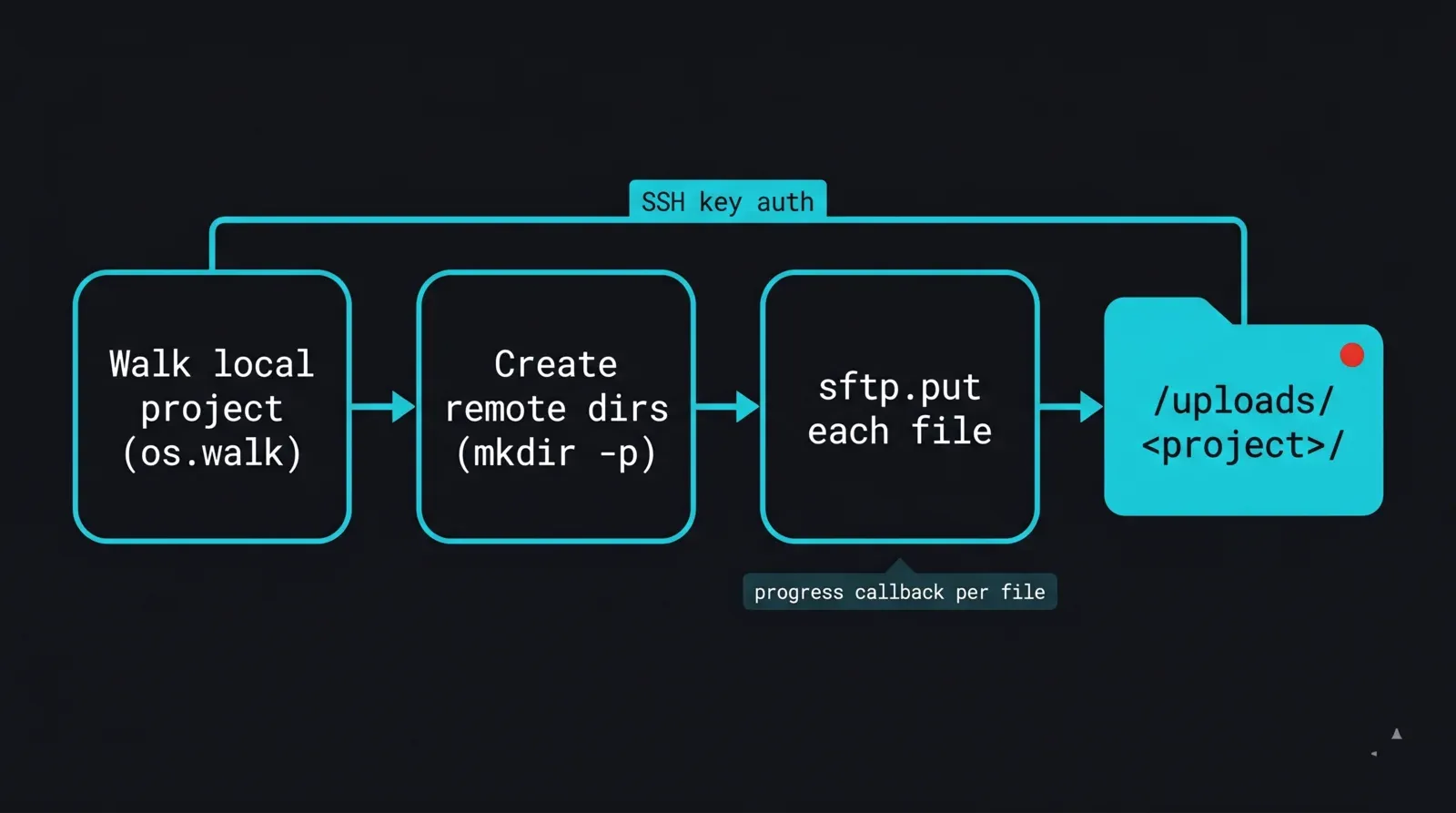
Diagrama de fluxo de uma rotina de upload paramiko para uma render farm: uma pasta de projeto local é percorrida ficheiro a ficheiro com os.walk, a árvore de diretórios remota é criada em /uploads com um ciclo mkdir-p, depois cada ficheiro é enviado com sftp.put numa ligação autenticada por chave SSH, com um callback de progresso a registar cada ficheiro concluído
Sincronização incremental com rsync via SSH
Um projeto de renderização raramente é enviado apenas uma vez. Ajusta-se um shader, recalcula-se uma simulação, corrige-se uma luz e faz-se um novo upload. Enviar a pasta completa de cada vez desperdiça horas; o rsync envia apenas o que mudou. Para um estúdio que faz uploads noturnos, esta é a maior poupança de tempo na camada de transferência, porque transfere apenas o delta e não o projeto inteiro.
A invocação canónica:
rsync -avz --partial --progress \
/local/projects/archviz-tower/ \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/uploads/archviz-tower-2026-06/"
-a preserva a estrutura e os timestamps, -z comprime durante a transferência, --partial mantém os ficheiros parcialmente transferidos para que uma ligação interrompida retome em vez de recomeçar, e --progress reporta por ficheiro. Executar o mesmo comando após uma alteração transfere apenas os ficheiros modificados. Como o objetivo é a automação, encapsule-o em Python para que fique no mesmo script que todo o resto e para poder reagir ao seu código de saída:
import subprocess
def rsync_up(local_dir, remote_subdir):
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
dest = f"{user}@{host}:/uploads/{remote_subdir}/"
cmd = ["rsync", "-avz", "--partial", "--progress",
f"{local_dir.rstrip('/')}/", dest]
subprocess.run(cmd, check=True) # lança CalledProcessError em caso de falha
Para executar de forma desacompanhada, agende a tarefa. Um estúdio que espelha um diretório de trabalho para a render farm todas as noites à 1h00 precisa de uma linha de cron:
0 1 * * * cd /studio/pipeline && /usr/bin/python3 nightly_sync.py >> sync.log 2>&1
Para que o rsync via SSH autentique sem necessidade de interação, aponte-o para a chave com -e "ssh -i ~/.ssh/id_ed25519", ou deixe um agente SSH manter a chave desbloqueada para a sessão.
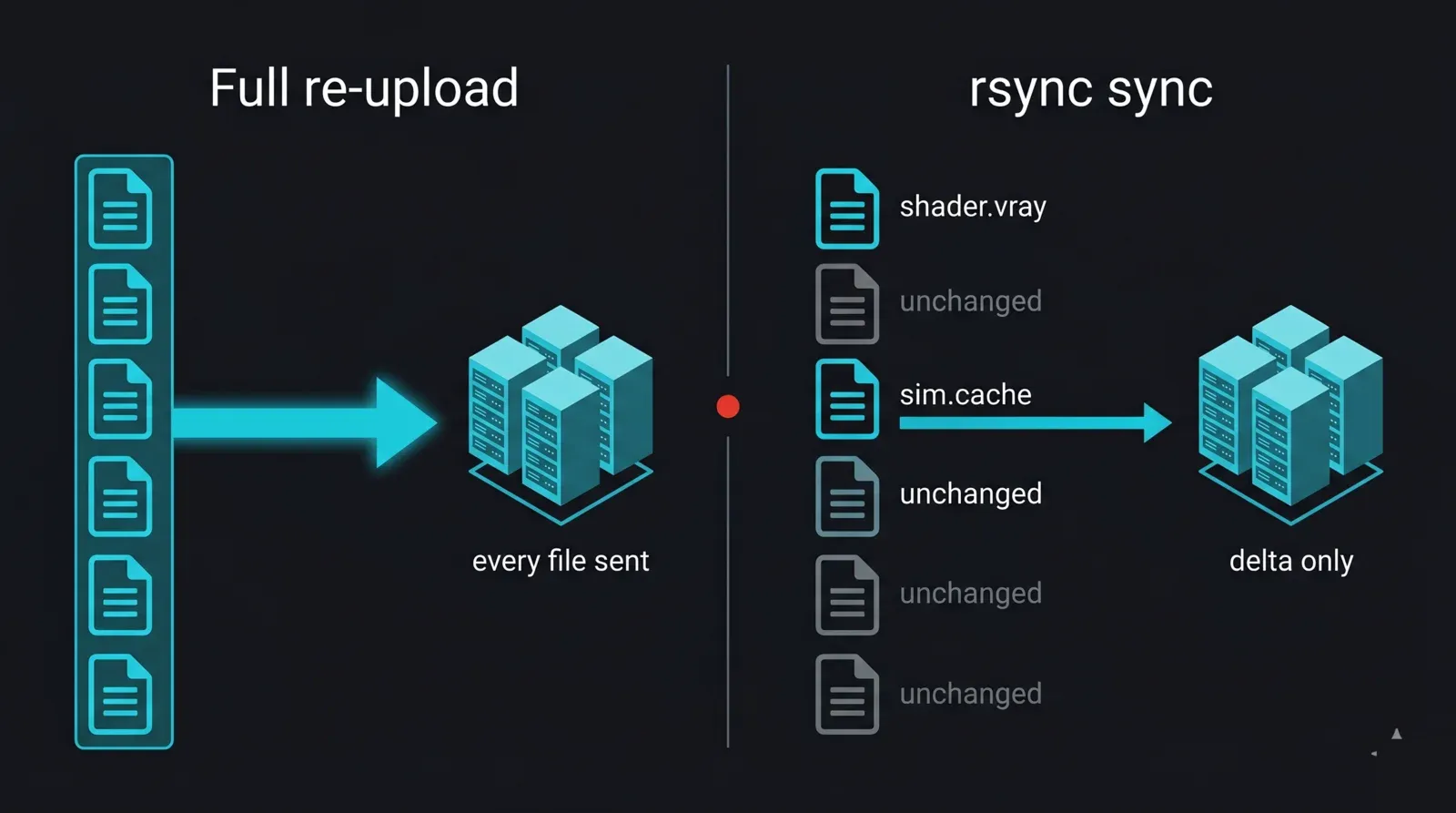
Diagrama de antes e depois a contrastar um re-upload completo com uma sincronização incremental rsync para uma render farm: à esquerda, todos os ficheiros de um projeto são reenviados cada noite; à direita, o rsync compara o local e o remoto e transfere apenas os ficheiros alterados (um shader modificado e uma nova cache), com a maior parte inalterada a ser ignorada, ilustrando a transferência apenas do delta que torna os uploads noturnos de estúdio rápidos
Download automático de frames terminados
Quando um trabalho conclui, os frames de output são escritos em /output/<id-do-trabalho>/ no servidor SFTP. O lado do download espelha o lado do upload — um get recursivo com paramiko, ou um pull rsync. A versão paramiko percorre o diretório remoto e recria-o localmente:
import stat
def download_dir(sftp, remote_dir, local_dir):
os.makedirs(local_dir, exist_ok=True)
for entry in sftp.listdir_attr(remote_dir):
remote_path = f"{remote_dir}/{entry.filename}"
local_path = os.path.join(local_dir, entry.filename)
if stat.S_ISDIR(entry.st_mode):
download_dir(sftp, remote_path, local_path)
else:
sftp.get(remote_path, local_path)
print(f"descarregado {local_path}")
Para conjuntos de output de grande dimensão, o pull rsync é de novo a escolha mais eficiente e com retoma:
rsync -avz --progress \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/output/<id-do-trabalho>/" \
/local/downloads/<id-do-trabalho>/
Um detalhe operacional importante para pipelines desacompanhados: o output renderizado é retido durante 45 dias após a conclusão do trabalho, sendo depois eliminado automaticamente. O SFTP não estende esse período. O padrão seguro é uma sincronização noturna que espelha o output para arquivo local assim que aparece, para que a retenção nunca seja o motivo pelo qual um frame se perde.
Detetar a conclusão de um trabalho sem uma API de estado
É aqui que o limite honesto se torna uma escolha de engenharia concreta. Não existe um endpoint público para perguntar "o trabalho 12345 terminou?" — mas o próprio diretório de output é observável via SFTP. O padrão pragmático é sondar /output/<id-do-trabalho>/, contar os ficheiros e aguardar que a contagem atinja o total de frames esperado e se mantenha estável entre verificações consecutivas (para não começar a descarregar a meio da escrita).
import time
def wait_for_output(sftp, output_dir, expected_frames, poll=120, stable_checks=2):
last_count, stable = -1, 0
while True:
try:
files = sftp.listdir(output_dir)
except IOError:
files = [] # pasta ainda não criada -> não iniciado
count = len(files)
if count >= expected_frames and count == last_count:
stable += 1
if stable >= stable_checks:
return files # contagem atingida e estável -> tratar como concluído
else:
stable = 0
last_count = count
time.sleep(poll)
É importante ter consciência do que isto representa. Os frames aparecem de forma incremental, por isso a presença por si só não é conclusão; verificar a contagem face ao total esperado e confirmar que está estável entre sondagens é o que a torna suficientemente fiável para automação. É uma heurística de diretório, não um contrato. Quando a API pública for lançada, esta função inteira colapsa numa chamada de estado — entretanto, monitorizar o diretório de output é a forma fundamentada de preencher o intervalo, e não depende de nada que não exista já.
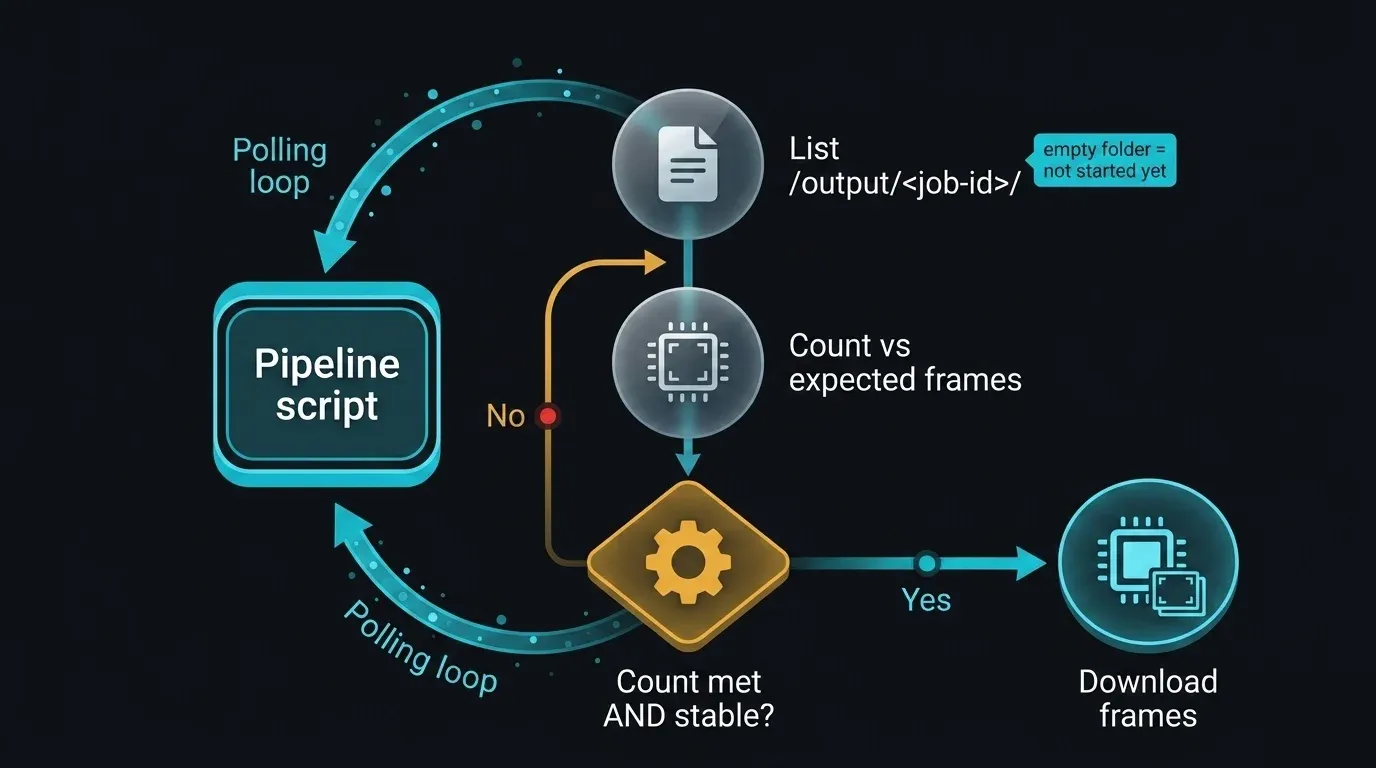
Diagrama de sequência da sondagem do diretório SFTP de output para detetar a conclusão da renderização sem uma API de estado: um script de pipeline lista repetidamente /output/<id-do-trabalho>/, compara a contagem de frames com o total esperado, aguarda até que a contagem atinja o objetivo e se mantenha estável em duas verificações consecutivas, e depois prossegue para o download — com um estado inicial de pasta vazia a indicar que o trabalho ainda não começou
A juntar tudo: um pipeline de transferência desacompanhado
As peças compõem-se num único script noturno. A forma é: sincronizar o projeto, entregar para submissão, aguardar que o output apareça e estabilize, obtê-lo, verificar e arquivar. O passo de submissão é a entrega deliberada via interface gráfica — numa render farm gerida, a submissão é feita através do formulário web, da Client App ou de um plugin de submissão DCC, e os plugins por DCC podem ser controlados a partir do ambiente de scripting próprio da aplicação (MAXScript, Python dentro do DCC) quando a submissão existe dentro de uma ferramenta que já se programa. Assinalamos esse passo com honestidade em vez de o envolver numa função que simula a existência de uma API.
def nightly_pipeline(project_dir, remote_subdir, job_id, expected_frames):
client, sftp = connect()
try:
# with_retries() (definida na secção seguinte) envolve as chamadas de rede frágeis
with_retries(lambda: rsync_up(project_dir, remote_subdir)) # 1. enviar delta
# 2. SUBMETER: interface gráfica / Client App / plugin DCC -- sem API pública (ainda)
files = wait_for_output( # 3. monitorizar diretório de output
sftp, f"/output/{job_id}", expected_frames)
with_retries(lambda: # 4. obter frames terminados
download_dir(sftp, f"/output/{job_id}", f"/local/downloads/{job_id}"))
print(f"trabalho {job_id}: {len(files)} frames obtidos")
finally:
sftp.close()
client.close()
Os passos 1, 3 e 4 são totalmente automatizados; o passo 2 é a entrega. Quando uma API de submissão pública for disponibilizada, os passos 2 e 3 tornam-se chamadas de API e a sondagem de diretório é retirada. A arquitetura não muda — apenas as fases de submissão e de estado passam de interface gráfica e heurística para endpoint.
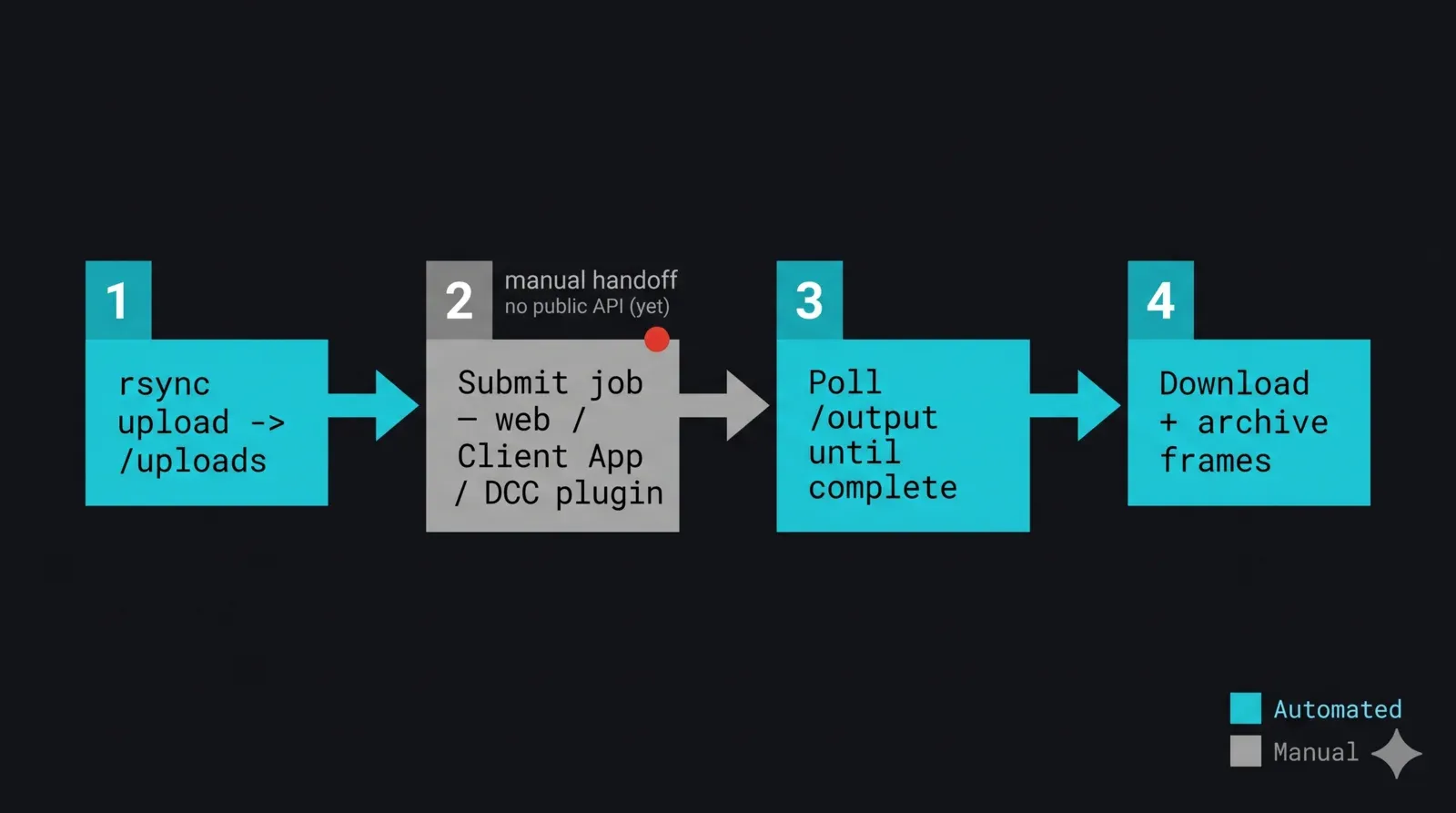
Diagrama de fluxo de ponta a ponta de um pipeline de transferência de render farm desacompanhado controlado a partir de Python: o passo 1 rsync faz upload do delta do projeto para /uploads, o passo 2 é uma entrega via interface gráfica claramente assinalada onde o trabalho é submetido através de formulário web, Client App ou plugin DCC (sem API pública), o passo 3 sonda /output/<id-do-trabalho>/ até os frames estarem completos e estáveis, o passo 4 descarrega e arquiva os frames terminados localmente — com os passos automatizados em ciano e o passo de submissão manual em cinzento
Tratamento de erros, retentativas e transferências com retoma
Desacompanhado significa que ninguém está a observar quando uma transferência falha, por isso o script tem de se recuperar sozinho. Três hábitos cobrem a maioria das falhas.
Retente falhas transitórias com backoff. Falhas de rede e desligamentos breves são normais em transferências longas. Envolva as chamadas frágeis — como nightly_pipeline faz acima — para que uma única interrupção não mate a execução. Capture os erros transitórios específicos em vez de tudo: o SSHException do paramiko, a família OSError para sockets, e CalledProcessError para um rsync falhado.
def with_retries(fn, attempts=3, backoff=5):
transient = (paramiko.SSHException, OSError, subprocess.CalledProcessError)
for i in range(1, attempts + 1):
try:
return fn()
except transient: # retente falhas SSH / rede / rsync
if i == attempts:
raise
time.sleep(backoff * i) # backoff: 5s, 10s, 15s
Tire partido da retomabilidade. rsync --partial já retoma ficheiros interrompidos, e executar novamente um rsync é idempotente — envia apenas o que falta — por isso uma sincronização refeita é barata, não um recomeço. Para transferências paramiko, uma retentativa mais uma nova travessia obtém o mesmo efeito porque os ficheiros já presentes transferem quase instantaneamente.
Trate erros de chave do host e de conectividade explicitamente. Um erro "host key verification failed" significa que a chave em cache em ~/.ssh/known_hosts já não corresponde à do servidor — habitualmente após uma rara rotação de chave do host. Remova a linha obsoleta que o erro identifica e ligue novamente para aceitar a nova chave. Ligação recusada ou timeout normalmente significa que uma firewall do estúdio está a bloquear o TCP 22 de saída; permita-o ou pergunte ao suporte sobre alternativas. E se o débito estiver muito abaixo da velocidade da ligação, o overhead por pacote do SFTP é a causa em ligações de longa distância — lftp com segmentos paralelos, ou várias sessões SFTP concorrentes, recupera a maior parte da diferença.
Resumo: o que automatizar, e como
A camada de transferência é a parte de um pipeline de render farm gerida que se possui em código, e Python cobre tudo.
| Tarefa | Automatizável em Python? | Ferramenta | Notas |
|---|---|---|---|
| Fazer upload de um projeto | Sim | paramiko ou rsync | rsync para transferências grandes/repetidas; --partial para retomar |
| Re-upload incremental | Sim | rsync via SSH | Transfere apenas os ficheiros alterados |
| Descarregar frames terminados | Sim | paramiko get / rsync pull | Espelhar noturnamente — retenção de 45 dias |
| Detetar conclusão | Parcial | Sondar /output/<id-do-trabalho>/ | Heurística de contagem + estabilidade, sem API de estado |
| Submeter um trabalho de renderização | Não (hoje) | Web / Client App / plugin DCC | API pública no roadmap |
| Autenticar | Sim | Chave SSH (ed25519) | Chave + frase-chave; sem segredos no código |
Automatize o upload, automatize o download, preencha o intervalo intermédio através da monitorização do diretório de output, e mantenha a entrega de submissão explícita. Isto dá um pipeline noturno que é honesto sobre as suas costuras e fiável por isso mesmo. Para projetos com simulações pesadas onde a fiabilidade de transferência é mais crítica — caches Houdini de múltiplos terabytes e semelhantes — os mesmos padrões escalam diretamente na Super Renders Farm; a nossa página sobre render farm Houdini na nuvem cobre essa carga de trabalho.
FAQ
Q: Qual a biblioteca Python a usar para fazer upload para a render farm?
A: paramiko é a escolha padrão e é mencionada diretamente na nossa documentação SFTP como cliente suportado. É Python puro, gere o SFTP de forma limpa e funciona bem para lógica de upload e download. Para transferências muito grandes ou frequentemente repetidas, invoque rsync via SSH a partir de Python com subprocess — envia apenas os ficheiros alterados e retoma os interrompidos, o que paramiko não faz nativamente.
Q: Existe uma API pública para submeter trabalhos de renderização a partir do meu pipeline Python? A: Ainda não. Uma API REST pública para submissão, sondagem de estado e obtenção de output está no nosso roadmap, mas nenhum endpoint público está disponível atualmente. Os caminhos de submissão programáticos atuais são a SuperRenders Client App e o plugin de submissão por DCC, que se integra com o ambiente de scripting próprio da aplicação, como MAXScript ou Python dentro do DCC. Se o pipeline estiver especificamente bloqueado numa API de submissão pública, contacte o suporte e partilhe o caso de uso — o roadmap é influenciado por requisitos reais de pipeline.
Q: Como detetar que um trabalho de renderização terminou se não existe API de estado?
A: Sonde o diretório SFTP de output do trabalho, /output/<id-do-trabalho>/, e observe a contagem de frames. Trate o trabalho como concluído apenas quando a contagem atingir o total esperado e se mantiver estável entre verificações consecutivas, para não começar a descarregar enquanto os frames ainda estão a ser escritos. É uma heurística de diretório e não um sinal de estado oficial, mas baseia-se apenas em capacidades que existem hoje.
Q: Devo usar chaves SSH ou uma palavra-passe para transferências automatizadas? A: Use uma chave SSH. Escrever uma palavra-passe diretamente num script é um risco de segurança, e a autenticação por chave funciona de forma desacompanhada sem necessidade de interação. Gere uma chave ed25519, registe a metade pública em Settings → SFTP → SSH Keys, e proteja a chave privada com uma frase-chave mantida por um agente SSH. Uma vez que a autenticação de dois fatores não é atualmente suportada nas contas, a chave mais a sua frase-chave é o reforço prático mais forte para o acesso SFTP.
Q: Posso fazer upload de um arquivo .zip a partir do script?
A: Não — os arquivos .zip não são suportados. Reempacote como .tar.gz (ou .tar / .7z), ou ignore o arquivamento e deixe o rsync transferir a árvore de pastas diretamente, o que normalmente é a melhor opção para projetos que mudam entre uploads. Mantenha um único upload abaixo de aproximadamente 300 GB e use rsync --partial para qualquer coisa maior, para que uma ligação interrompida retome em vez de recomeçar.
Q: Qual o tamanho máximo de projeto que pode ser transferido desta forma?
A: As transferências de múltiplos terabytes são suportadas via SFTP; o limite prático é a largura de banda de upload própria, não um limite imposto pela render farm. Um upload de 1 TB a 100 Mbps demora aproximadamente um dia, por isso planeie em função da sua ligação. Para um débito máximo em ligações largas ou de longa distância, use lftp com segmentos paralelos ou várias sessões SFTP concorrentes, uma vez que um único fluxo SFTP é limitado pelo overhead por pacote.
Q: Durante quanto tempo ficam os frames renderizados disponíveis para download?
A: O output é retido durante 45 dias após a conclusão de um trabalho, sendo depois eliminado automaticamente, e o SFTP não estende esse período. Para um pipeline desacompanhado, espelhe o output para arquivo local assim que aparecer — um pull rsync noturno de /output/<id-do-trabalho>/ garante que a retenção nunca seja a razão pela qual um frame se perde.
Q: Em que é que este guia difere do guia de fluxo de trabalho headless e desacompanhado?
A: Esse guia é o mapa conceptual — o que significa renderização headless, como preparar cenas para renderização por linha de comandos, e como o ciclo desacompanhado se encaixa numa render farm gerida. Este é o guia complementar ao nível do código focado na camada de transferência: o paramiko e rsync concretos que se escrevem para mover projetos para cima e frames para baixo. Leia o guia de fluxo de trabalho para a forma geral; use este para a implementação.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



