국경을 넘는 20노드 전용 GPU 렌더팜 배포 방법 (2026)
개요
서론
크리에이티브 팀이 여러 나라에 걸친 전용 렌더팜을 요청할 때, 대개는 SaaS 렌더팜이 해결할 수 없는 제약을 우회하려는 것입니다. 계약상 제3자가 자격 증명을 보유하는 것이 허용되지 않는 스튜디오, 한 국가의 아티스트가 다른 국가의 노드를 운영하는 분산 팀, 또는 수개월짜리 계약으로 인해 프레임당 청구가 경제적으로 맞지 않는 프로덕션 하우스가 이에 해당합니다.
전용 클러스터를 배포해 온 경험상, 어려운 부분은 거의 "GPU를 더 많이 빌리는 것"이 아닙니다. 올바른 구성 요소들을 연결하는 것이 핵심입니다: 고객 소유 클라우드 스토리지, 워크로드에 맞게 크기가 조정된 프라이빗 GPU 플릿, 지터를 견디는 암호화된 국경 간 전송, 그리고 무거운 3D 뷰포트에서도 안정적으로 작동하는 원격 데스크톱 계층이 필요합니다. 한 가지 요소라도 잘못 구성되면 클러스터는 겉으로는 작동하지만 아티스트들은 문제를 인식하게 되고, 서비스 품질은 점차 저하됩니다.
저희는 상당한 CPU + GPU 플릿을 보유한 클라우드 렌더팜인 Super Renders Farm을 운영하며, 기본 관리형 서비스로는 워크플로가 맞지 않는 팀을 위해 전용 GPU 클러스터도 구축합니다. 이 글은 그러한 배포에서 얻은 현장 가이드로, 단일 전용 시설에서 국경을 넘어 분산된 크리에이티브 팀 아티스트에게 서비스를 제공하는 20노드 전용 GPU 렌더팜을 어떻게 설계하는지를 다룹니다. 저희가 내린 선택, 철회한 결정, 그리고 현재 기본으로 적용하는 교훈을 솔직하게 기술합니다. 관리형 렌더팜 임대와 전용 인프라를 비교 검토하고 계신다면, 이 가이드가 전용 경로의 아키텍처 복잡성이 감수할 가치가 있는지 판단하는 데 도움이 될 것입니다.
전용 vs SaaS 결정 기준
대부분의 렌더링 워크로드에는 전용 클러스터가 필요하지 않습니다. 관리형 클라우드 렌더팜은 씬을 받아 프레임을 스케줄링하고 분당 청구합니다. 소유할 인프라도, 유지할 방화벽도, 고객 측에서 담당할 운영 팀도 없습니다. 프로젝트 기반 작업 — 단편 영상, 30초 광고, 스틸 배치 — 의 경우 관련된 모든 지표에서 이 모델이 우위를 점합니다.
전용 클러스터는 다음 조건 중 하나 이상이 해당될 때에만 그 복잡성이 정당화됩니다:
- 지적 재산권 통제가 선호 사항이 아닌 계약 의무입니다. 고객의 마스터 서비스 계약 또는 최종 고객 계약이 제3자의 씬 파일 또는 렌더 자격 증명 보유를 금지하고 있습니다. 씬 업로드를 중개하는 SaaS 파이프라인은 기본 컴퓨팅이 동일하더라도 이 제약을 위반합니다.
- 계약 기간이 며칠이 아닌 수개월입니다. 고정 형태의 작업 — 장기 애니메이션 시리즈, 다분기 archviz 파이프라인, 진행 중인 가상 프로덕션 스테이지 — 은 초기 아키텍처 비용을 충분히 회수할 수 있습니다. 반면 프레임당 청구는 기간에 비례해 선형적으로 증가하며 일정 기간이 지나면 경쟁력을 잃습니다.
- 워크플로가 관리형 파이프라인으로 호스팅하기 어려울 만큼 사용자 정의되어 있습니다. 사용자 정의 DCC 플러그인 스택, 사내 렌더 매니저, 공유 캐시에 pre-bake하는 시뮬레이션 중심 파이프라인, 또는 독점 도구 체인은 모두 고객이 직접 구성할 수 있는 전용 노드를 필요로 합니다.
- Bring-your-own-cloud가 필수 요건입니다. 고객의 프로젝트 자산이 고객 계정 하의 cloud file-streaming 플랫폼에 있는 경우, 클러스터는 인프라 제공자가 아닌 고객 자격으로 로그인해야 합니다. 이것이 아래에서 자세히 설명할 "Model B" 패턴입니다.
- 네트워크 분리 요건이 테넌트별 VLAN을 초과합니다. 일부 워크플로는 클러스터가 제공자의 더 넓은 네트워크에서 완전히 보이지 않아야 합니다 — 논리적 격리뿐만 아니라 라우팅 수준에서도.
이러한 기준 중 해당되는 것이 없다면 관리형 렌더팜이 거의 항상 올바른 선택입니다. 두 가지 이상이 해당된다면 전용 방향으로 논의가 전환됩니다. 남은 질문은 지리적입니다: 작업을 진행하는 아티스트가 시설 근처에 있는지, 아니면 국가 간 공용 ISP 백본을 통해 서비스해야 하는지가 핵심입니다.
아키텍처 개요
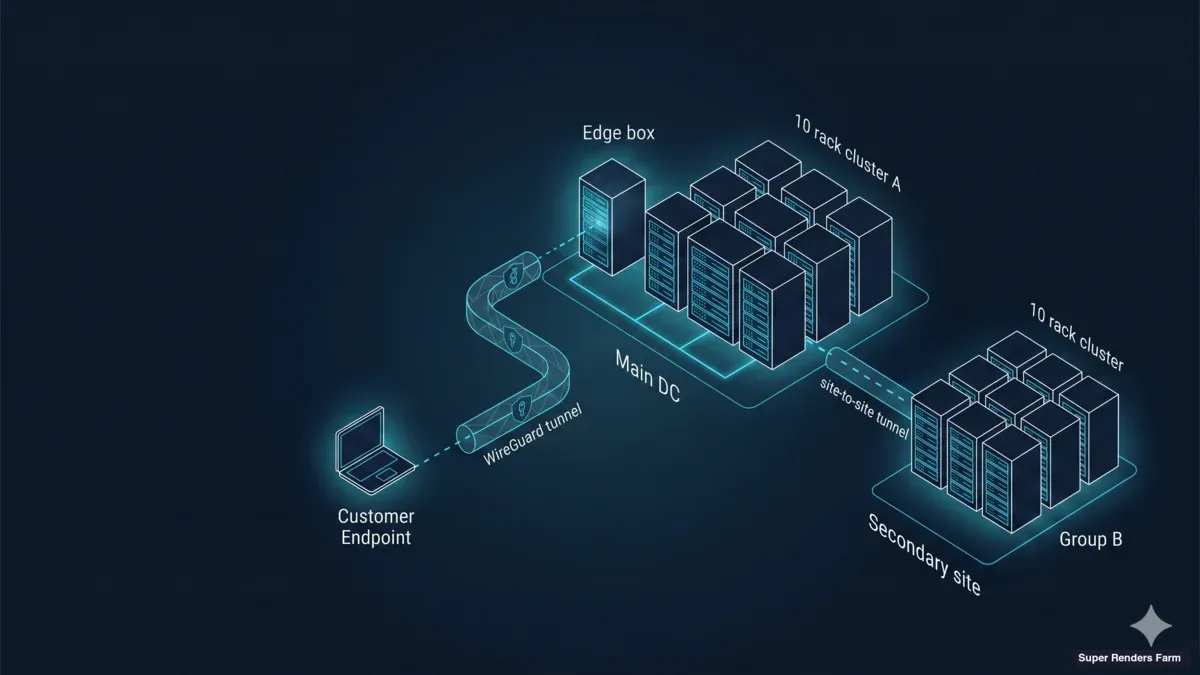
국경 간 전용 클러스터를 위해 배포하는 아키텍처는 세 가지 플레인으로 구성됩니다: 전송 플레인, 컴퓨팅 플레인, 그리고 스토리지 가속 플레인. 각 플레인에는 단일 장애 모드가 있으며, 경험상 이것이 깨질 때 대부분의 운영 문제가 발생합니다.
[ 원격 아티스트 — 여러 국가에 분산 ]
│
│ WireGuard hub-and-spoke
│ (UDP 51820, 종단 간 암호화,
│ BBR + MSS 클램핑 전송)
▼
┌─────────────────────────────────────────────────────┐
│ Super Renders Farm — 전용 클러스터 시설 │
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ EDGE + CACHE BOX (단일 Ubuntu 호스트) │ │
│ │ • WireGuard hub (NAT/MASQUERADE) │ │
│ │ • Samba SMB3 캐시 (단일 SSD, ext4) │ │
│ │ • dnsmasq (.lan 존) │ │
│ │ • chrony (NTP) │ │
│ │ • ufw + BBR + TCP MSS 클램프 │ │
│ └────────────────────┬────────────────────────┘ │
│ │ LAN │
│ ┌────────────────────▼────────────────────────┐ │
│ │ 20 × RTX 5090 렌더 노드 │ │
│ │ (Windows 11 Pro, Sunshine, cloud file- │ │
│ │ stream 클라이언트, 캐시 마운트 — 플릿 │ │
│ │ 전체 균일 이미지) │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
[ 고객의 cloud file-streaming 플랫폼 —
고객이 각 노드에서 직접 로그인;
Super Renders Farm은 자격 증명을 보유하지 않음 (Model B) ]
전송 플레인은 hub-and-spoke 패턴의 WireGuard입니다. 모든 아티스트의 워크스테이션은 암호화된 UDP 터널을 통해 클러스터 시설의 허브에 연결되며, 아티스트가 어느 나라에 있든 동일한 터널 토폴로지를 통해 트래픽이 전달됩니다. 컴퓨팅 플레인은 단일 시설의 단일 균일 풀로 배포된 20개의 Windows 11 Pro 노드이며, 각 노드는 32 GB VRAM의 NVIDIA RTX 5090을 구동합니다. 스토리지 가속 플레인은 ext4의 단일 SSD를 백엔드로 하는 Samba SMB3 공유를 호스팅하는 단일 edge-and-cache 박스이며, 클러스터가 의존하는 네트워크 서비스(DNS, NTP, 방화벽)도 함께 담당합니다.
핵심 설계 결정: edge 박스와 cache 박스는 동일한 머신입니다. 이 아키텍처의 이전 버전에서는 edge 게이트웨이를 별도의 어플라이언스에, 캐시를 NAS에 두었는데, 이로 인해 콜드 풀 시 경쟁 조건과 두 가지 패치 대상이 생겼습니다. 단일 Ubuntu 22.04 LTS 호스트로 통합하면서 두 문제가 모두 해결되었습니다. 이 박스는 중요한 리소스가 되지만, 고객 프로젝트 데이터는 여전히 cloud file-streaming 플랫폼에 있으므로 로컬 장애 후에는 업스트림에서 캐시를 다시 웜업할 수 있습니다.
20노드 GPU 클러스터 설정
설명하는 배포의 기본 크기는 단일 시설 내 단일 균일 풀로 배포된 20개의 RTX 5090 노드입니다. 이 크기는 IP 민감 워크플로에 전용 클러스터가 적합한 10~20명 아티스트 규모의 크리에이티브 팀에 일관되게 잘 매핑됩니다.
각 노드는 동일한 하드웨어 형태를 가집니다: 32 GB VRAM의 RTX 5090, 현대적 멀티코어 CPU, 64 GB 또는 128 GB 시스템 RAM, 그리고 OS와 스크래치 전용으로 크기가 조정된 NVMe 로컬 디스크. 영구 프로젝트 데이터는 공유 캐시 또는 업스트림 cloud file-streaming 플랫폼에 저장됩니다 — 절대 노드 자체에는 두지 않습니다.
각 노드의 운영 체제는 클린 이미지에서 배포된 Windows 11 Pro입니다. 의도적으로 노드 이미지에 DCC 플러그인 스택을 미리 로드하지 않습니다. 고객이 자체 DCC 도구 설치를 직접 진행합니다 — Cinema 4D, Redshift, Houdini, After Effects, Blender 등 — 노드 이미지를 최소화하고 재현 가능한 상태로 유지하기 위해서입니다. 계약이 종료되면 동일한 클린 베이스라인에서 초기화합니다.
노드당 32 GB VRAM을 의도적으로 선택했습니다. 현대 GPU 렌더러 — Redshift, Octane, Arnold GPU, Cycles — 는 점점 더 많은 대규모 텍스처 씬을 로드하며, 24 GB 카드에는 단순히 들어가지 않습니다. RTX 5090의 32 GB는 현재 프로덕션 렌더러의 스위트 스팟으로, 대부분의 archviz, 모션 디자인, 애니메이션 작업을 시스템 RAM 페이징 없이 처리할 수 있습니다. RAM 페이징이 발생하는 것이 혼합 GPU 풀이 조용히 느려지는 지점입니다.
20개 노드는 동일하게 구성됩니다 — 동일한 이미지, 동일한 DCC 설치 세트, 동일한 캐시 마운트, 동일한 WireGuard 경로 — 고객의 렌더 매니저에게는 단일 풀로 표시됩니다. Deadline, Royal Render, 또는 고객의 자체 스케줄러는 플릿을 그룹별 라우팅이나 수동 재조정 없이 단일 리소스로 취급합니다. 프레임은 사용 가능한 노드에 할당되며, 작업 큐 계층에서 고객의 렌더 매니저가 부하 분산을 처리합니다.
플릿은 레이어 3 라우팅이 가능합니다 — 고객은 자체 렌더 매니저를 설치하고 원격 워크스테이션에서 제출하며, 원격 데스크톱으로 각 노드를 직접 조작하는 방식이 아닙니다. 이 차이는 예상보다 훨씬 중요합니다: 아티스트가 불편을 겪는 클러스터와 아티스트가 존재를 잊어버리는 클러스터의 차이를 만들어냅니다.
고객 소유 자격 증명 (Model B)
IP 민감 워크플로에 전용 클러스터를 가장 자주 올바른 선택으로 만드는 단일 아키텍처 결정은 저희가 Model B라고 부르는 것입니다: 고객 소유 자격 증명. Model A — 자체 SaaS 서비스를 포함한 관리형 렌더팜의 기본값 — 에서는 인프라 제공자가 렌더링 파이프라인의 자격 증명을 보유합니다. 고객이 씬 파일을 업로드하면 제공자의 파이프라인이 렌더를 중개합니다. 이것은 대부분의 워크로드에 적합하며 거의 모든 상업 클라우드 렌더팜의 모델입니다.
Model B에서 인프라 제공자는 하드웨어, 운영 체제, 네트워크, 캐시 계층을 공급하지만, cloud file-streaming 플랫폼이나 프로젝트 소스 데이터에 대한 고객의 인증 자료를 절대 보유하지 않습니다. 고객은 자신의 워크스테이션에서 하는 것과 정확히 같은 방식으로 각 노드에서 클라우드 플랫폼에 로그인합니다. 프로젝트 파일은 고객의 클라우드에서 스트리밍됩니다. 렌더 결과물도 고객의 클라우드에 기록됩니다. 제공자의 역할은 하드웨어-및-파이프라인 계층에 한정됩니다.
이것이 중요한 세 가지 이유가 있습니다:
- 계약상: 고객의 다운스트림 클라이언트에 자격 증명과 소스 파일의 보관 위치를 제한하는 NDA 또는 마스터 서비스 계약이 있는 경우, Model B는 제공자를 해당 제한의 범위 밖에 둡니다. 고객은 렌더링 제공자를 원래 설계되지 않은 계약 체인에 포함시킬 필요가 없습니다.
- 감사: 고객이 보안 감사관에게 렌더링 파이프라인이 제3자에게 자격 증명을 노출하지 않음을 증명해야 할 때, Model B는 명확한 답변을 제공합니다. 제공자는 하드웨어, 네트워크, 운영 문서를 제시하고, 고객은 자격 증명 체인을 제시합니다.
- 계약 종료: 제공자가 자격 증명을 보유한 적이 없으므로 계약 종료 정리가 더 간단합니다. 고객은 자신의 클라우드 세션을 취소합니다. 제공자는 캐시를 초기화하고, 노드를 재이미징하고, 캐시와 노드 이미지가 파기되었다는 서면 확인서를 제공합니다. 보유한 자격 증명이 없으므로 제공자 측의 자격 증명 교체 단계가 없습니다.
Model B가 모든 팀에 적합한 것은 아닙니다. 각 노드에서의 자격 증명 수명 주기를 고객의 운영 팀이 책임져야 합니다 — 비밀이 매월 교체된다면 20개의 교체를 조율해야 합니다. 이러한 운영 관행이 이미 갖춰진 팀은 이 트레이드오프를 수용할 수 있습니다. 그렇지 않은 팀은 Model A 관리형 렌더링을 유지하는 경향이 있습니다.
Cloud file-streaming 통합
논의하는 구성에서 고객의 프로젝트 자산은 cloud file-streaming 플랫폼에 있습니다 — 클라우드 기반 프로젝트 트리를 각 노드의 가상 파일 시스템으로 노출하는 서비스입니다. 아티스트가 프로젝트를 마운트하면 노드가 필요에 따라 파일을 읽으며, 플랫폼이 백업 스토리지, 버전 관리, 지역 간 복제를 처리합니다.
저희는 고객이 선택한 일반적인 cloud file-streaming 플랫폼과 통합합니다. 플랫폼은 고객 계정을 사용한 각 노드의 로그인 이벤트를 확인하고, 노드의 플랫폼 클라이언트가 프로젝트 트리를 알려진 경로에 마운트하며, 고객의 DCC 애플리케이션은 로컬 워크스테이션에서와 동일한 방식으로 해당 경로에서 파일을 엽니다. 클라우드 플랫폼은 노드가 렌더 클러스터의 일부임을 인식할 필요가 없습니다.
20노드 클러스터에 이것을 연결할 때 변화하는 것은 액세스 패턴입니다. 단일 워크스테이션의 단일 아티스트는 작업하는 동안 한 번에 하나의 프로젝트 파일을 필요에 따라 가져옵니다. 프레임 범위에 대해 동시에 같은 씬을 여는 20개의 렌더 노드는 동일한 자산에 대한 동기화된 클라우드 읽기 버스트를 생성합니다. 캐시가 없으면 각 노드가 모든 텍스처, 모든 캐시된 시뮬레이션, 모든 종속 파일을 병렬로 가져옵니다 — 국제 대역폭의 낭비이자 모든 범위의 첫 프레임에서 속도 저하로 이어집니다.
공유 캐시가 존재하는 이유입니다. 다음 섹션에서 자세히 다루지만, cloud file-streaming과의 통합이 캐시가 반드시 필요한 이유입니다. 클라우드에서의 자산 풀은 캐시 박스를 통해 한 번 집중되며, 이후 LAN을 통해 20개 노드 모두에 배포됩니다. 클라우드 플랫폼은 동일한 텍스처에 대한 20개의 동시 요청을 보지 않습니다 — 하나의 요청과, 이후 네트워크 내부의 웜 SMB 읽기만 발생합니다.
또 다른 실용적인 세부 사항은 write-back입니다. 렌더 프레임이 완료되면 노드는 고객 계정을 통해 출력을 cloud file-streaming 플랫폼에 기록합니다. 원격 사무실의 고객 팀은 실시간으로 프로젝트 트리에 프레임이 나타나는 것을 볼 수 있습니다. 수동 업로드 단계도, 제공자를 통한 전송도 필요하지 않습니다. 클라우드 플랫폼이 왕복을 처리합니다.
공유 캐시 아키텍처
공유 캐시는 잘못 구성될 경우 클러스터의 가치를 조용히 잠식하는 두세 가지 아키텍처 선택 중 하나입니다. 이전 배포에서 잘못 구성한 경험이 있습니다. 여러 빌드에서 지속된 패턴은 의도적으로 보수적입니다.
단일 edge-and-cache 박스가 Ubuntu 22.04 LTS를 실행하며, ext4로 포맷되고 Samba SMB3를 통해 클러스터에 노출되는 단일 8 TB SATA SSD를 탑재합니다. 캐시 마운트는 각 렌더 노드의 고정 경로(예: \\cache.lan\proj)에 나타납니다. 노드가 cloud file-streaming 클라이언트를 통해 프로젝트 파일을 열면 로컬 캐시를 통해 스트리밍됩니다. 이후 동일한 파일을 어떤 노드에서 읽더라도 LAN을 통해 직접 SSD에 접근합니다.
이 단락에는 세 가지 의도적인 선택이 담겨 있습니다.
첫째, 노드별 캐시가 아닌 단일 캐시. 이 아키텍처의 이전 버전에서는 노드별로 캐시 자료를 저장했습니다. 20개의 5090 노드를 사용하면 관리해야 할 중복 스토리지가 최대 200 TB에 달하고, 무언가 달라졌을 때 디버깅할 캐시 상태가 20개나 됩니다. 하나의 공유 캐시로 통합하면 스토리지 공간이 20배 줄어들고, 캐시 상태가 운영 팀이 검사할 수 있는 단일 아티팩트가 됩니다.
둘째, XFS 위 LUKS를 적용한 RAID 10이 아닌 ext4의 단일 SSD. 초기 계획에서는 XFS에 LUKS 저장 암호화를 적용한 RAID 10 어레이에 캐시를 두는 방안을 검토했습니다. 실제 배포하는 하드웨어에 비해 과도하게 복잡한 설계였습니다 — SSD 하나, 파일 시스템 하나, 마운트 하나. RAID 레이어와 LUKS를 제거하고 ext4를 사용한 이유는 캐시가 프로젝트 데이터의 진실의 출처가 아니기 때문입니다. 고객의 클라우드가 진실의 출처입니다. 캐시 드라이브가 실패하면 교체하고 업스트림에서 다시 웜업합니다. 클라우드 계층에서 중복성을 확보하고 있으므로 캐시 계층에서 중복성이 필요하지 않습니다. (저장 암호화는 이 계약의 범위 밖이었지만 다운스트림 클라이언트가 요구할 경우 별도 계약으로 제공 가능합니다.)
셋째, 첫 렌더 일 전에 캐시를 pre-warm. 어렵게 배운 교훈입니다. D-Day에는 모든 캐시 미스가 클러스터에서 가장 비싼 읽기입니다 — 국제 링크를 통과하고, 고객의 클라우드에서 가져오고, 렌더러가 소비하기 전에 로컬 SSD에 기록합니다. Pre-warming은 프로덕션 시작 전날 프로젝트 자산 트리를 구조화하여 탐색하는 작업으로, D-Day 읽기를 콜드 클라우드 풀에서 웜 SMB 읽기로 전환합니다. 이제는 모든 전용 클러스터 계약에 pre-warm 창을 계획에 포함합니다.
시설 내부에서는 모든 노드가 LAN의 SMB3를 통해 동일한 고정 경로(\\cache.lan\proj)에 캐시를 마운트합니다. 시설 내부 트래픽은 WireGuard 터널을 통과하지 않으므로 MSS 클램핑이 적용되지 않으며 링크는 기가비트 이더넷 속도로 종단 간 실행됩니다. 캐시 마운트 경로가 모든 노드에서 동일하므로 고객의 렌더 매니저 구성이 단순해집니다 — 동일한 씬 파일 경로가 풀의 모든 구성원에서 동일하게 해석됩니다.
국경 간 네트워크 최적화
전송 계층은 국경 간 클러스터가 매끄럽게 느껴지는지 아닌지를 결정합니다. TCP/IP, IP 단편화, DNS-over-VPN의 기본 동작은 SMB와 원격 데스크톱을 운반하는 장거리 암호화 터널에 미묘하게 맞지 않습니다. 커널과 네트워크 구성을 조정하는 것은 선택 사항이 아닙니다. 이것이 작동하는 클러스터와 대규모 패킷을 이상하게 드롭하는 클러스터의 차이를 만듭니다.
WireGuard, hub-and-spoke. 모든 아티스트는 워크스테이션에서 WireGuard 클라이언트를 통해 클러스터 시설의 허브에 연결합니다. 아티스트와 클러스터 간의 모든 트래픽은 종단 간 암호화됩니다. 하나의 VPN 기술만 사용하며 프로토콜을 혼합하지 않습니다. IPSec을 한 역할에, 다른 VPN을 다른 역할에 사용하면 보안이 향상되지 않으면서 운영 복잡성만 증가합니다.
TCP BBR. Linux의 기본 혼잡 제어(CUBIC)는 패킷 손실이 적은 저지연 링크용으로 설계되었습니다. 암호화된 트래픽을 운반하는 장거리 공용 ISP 링크는 매우 다른 특성을 보입니다 — 중간 수준의 지연, 간헐적인 지터, 비대칭 손실 패턴. BBR은 이러한 링크에서 CUBIC보다 일관되게 더 사용 가능한 처리량을 생성합니다. 특히 링크가 고객의 다른 인터넷 트래픽과 공유될 때 효과적입니다. 커널의 스톡 BBR(BBR v1)을 사용합니다. 최신 BBRv3은 이 빌드에 배포하지 않았으며, 스톡 버전이 안정적으로 동작했습니다.
TCP MSS 클램핑. "클러스터가 대체로 작동하지만 대용량 파일에서 문제가 생긴다"는 불만의 가장 흔한 원인입니다. 트래픽이 유효 MTU를 감소시키는 터널을 통과할 때, 큰 패킷은 단편화되거나(느림) 조용히 드롭됩니다(더 나쁨). 작은 패킷과 ping은 잘 작동하므로 문제를 진단하기 어렵습니다. 수정 방법은 WireGuard 라우터에서 TCP MSS를 클램프하여 TCP가 터널 내에 맞는 패킷 크기를 협상하도록 하는 것입니다. 이를 적용하면 TLS 핸드셰이크, RDP 세션, SMB 대용량 파일 읽기에서의 중단이 사라집니다.
dnsmasq에 VPN 인터페이스 명시. 미묘한 함정: 클라이언트가 비공개 .lan 주소를 쿼리하더라도 dnsmasq는 구성에서 WireGuard 인터페이스(예: wg0)를 명시적으로 나열해야 합니다. 그렇지 않으면 터널을 통한 DNS 조회가 시간 초과됩니다 — 하지만 ping은 DNS를 거치지 않으므로 여전히 작동합니다. 다른 모든 테스트가 정상으로 보이기 때문에 가장 혼란스러운 진단 상황 중 하나를 만들어냅니다.
chrony for NTP. 시간 동기화는 사소해 보이지만 렌더 매니저(Deadline은 작업에 타임스탬프를 기록), 클러스터 전체의 로그 상관 관계, 시간 구성 요소가 있는 인증 토큰에 중요합니다. chrony는 고지연 링크에서의 시계 드리프트를 오래된 ntpd보다 잘 처리합니다. edge 박스에서 실행하고 각 노드가 동기화하도록 설정합니다.
이러한 선택들의 결합 효과는 대부분의 워크로드에서 LAN처럼 느껴지고 공용 경로가 비정상적으로 혼잡할 때도 우아하게 성능이 저하되는 터널을 만들어냅니다. 다음 섹션에서는 그 터널을 통해 3D 작업을 실행하는 것이 실제로 어떤 모습인지 다룹니다.
원격 데스크톱을 위한 Moonlight와 Sunshine
원격 데스크톱은 아티스트가 가장 직접적으로 경험하는 계층입니다. 이 계층이 느리거나 끊기게 느껴지면 렌더러가 아무리 빠르더라도 의미가 없습니다 — 아티스트의 손이 느려지고 서비스 품질이 저하됩니다.
원격 데스크톱을 위해 Moonlight(클라이언트)와 Sunshine(각 노드의 호스트)을 사용합니다. 이 조합은 RTX 5090의 NVIDIA NVENC 하드웨어 인코더를 사용하여 프레임 버퍼를 실시간으로 인코딩한 후 아티스트의 워크스테이션으로 스트리밍합니다. 인코딩이 이미 노드에 있는 GPU에서 발생하므로 렌더러와의 경쟁이 없으며, 원격 데스크톱에서 추가되는 지연은 인코딩 단계가 아닌 네트워크 왕복이 지배합니다.
3D 뷰포트 작업의 경우 이것은 전통적인 원격 데스크톱과 다른 방식으로 중요합니다. 이전 프로토콜 — RDP, VNC, 표준 Microsoft 원격 데스크톱 — 은 사무실 워크로드용으로 설계되었습니다. 텍스트, 다이얼로그, 천천히 변하는 창은 잘 처리하지만, 터닝테이블 프리뷰 중 전체 화면 3D 뷰포트에서는 성능이 저하됩니다. Moonlight + Sunshine은 프레임 버퍼를 비디오로 취급하는데, 이것이 3D 작업에 정확히 맞는 모델입니다.
노드를 아티스트에게 인계하기 전에 실행하는 품질 게이트 테스트가 있습니다 — 비공식적으로 "Test 8" — 부하 하에서 정의된 뷰포트 작업 시퀀스를 수행하고 원격 데스크톱 경험이 기준을 충족하는지 확인합니다. 노드가 테스트를 통과하지 못하면 인코딩 파이프라인을 디버깅하거나 문제가 해결될 때까지 노드를 로테이션에서 제외합니다. 모든 계약 시작 시와 노드 재이미징 후에 이 테스트를 실행합니다.
Parsec은 Sunshine에 호스트 특정 문제가 있을 때 사용 가능한 대체 수단입니다. Sunshine을 안정적으로 구성할 수 없는 경우 소수의 노드를 Parsec으로 출시한 적이 있으며, 아티스트 경험은 유사합니다. 계정 기반의 클라우드 조정 모델이 자체 호스팅 Sunshine만큼 Model B 자격 증명 처리에 깔끔하게 맞지 않으므로 표준화하지 않습니다.
초기 계획에서 다른 원격 데스크톱 옵션들을 고려했다가 제외했습니다 — GPU 인코딩이 없는 범용 원격 데스크톱 도구, 그리고 전체 화면 3D 뷰포트에서 품질 게이트를 통과하지 못한 오픈 소스 대안. 중요한 원칙: GPU 클러스터 노드에서는 하드웨어 인코딩 스트리밍이 규모에 맞게 유지되는 유일한 모델입니다.
용량 계획 및 예약 플로어
이 가이드의 20노드 구성은 계약 기간 동안 Super Renders Farm의 더 넓은 플릿에서 분리된 예약 전용 슬라이스입니다. 예약이란 노드가 관리형 서비스 풀과 공유되지 않고, 다른 테넌트와 공동 스케줄링되지 않으며, 프레임당 청구 대상이 아님을 의미합니다 — 고객은 킥오프부터 해제까지 해당 슬라이스에 대한 독점적 제어권을 갖고 균일한 운영 비용을 지불합니다.
슬라이스를 20노드로 크기를 정하는 것은 의도적인 선택입니다. 10노드 미만에서는 관리형 렌더팜에 비해 클러스터가 아키텍처 복잡성을 정당화하지 못합니다 — SaaS 방식이 더 단순하고 경제적입니다. 30노드 이상에서는 캐시 계층이 재설계가 필요하고(여러 캐시 박스, 지역별 캐시) 운영 모델이 변화합니다. 20노드는 단일 edge-and-cache 박스, 단일 WireGuard 허브, 균일한 Windows 이미지가 깔끔하게 유지되는 범위이며, 10~20명 아티스트 규모의 크리에이티브 팀이 크런치 기간에는 프레임을 계속 처리하고 안정적인 상태에서는 유휴 시간 없이 운영할 수 있는 노드 수를 갖추는 범위입니다.
Super Renders Farm은 이 전용 슬라이스 외에도 상당한 플릿을 운영하므로 계약에 확장이 필요할 때 헤드룸이 존재합니다. 동일한 시설 내에 추가 예약 노드를 추가하는 것은 조달 사이클이 아닌 구성 변경입니다. 수개월짜리 계약을 진행하는 고객은 일반적으로 킥오프 시 슬라이스 크기를 확정하고, 원래 계획 대비 실제 수요를 기반으로 분기 경계에서 재조정합니다.
네트워크 분리
이러한 클러스터의 네트워크 분리는 선택 사항이 아닙니다. 고객은 제공자의 인프라에서 운영하지만, 제공자의 더 넓은 네트워크 — 제공자의 NAS, 라우터 관리자 인터페이스, 다른 테넌트 — 를 절대 볼 수 없어야 합니다. 마찬가지로 제공자의 내부 시스템은 고객의 워크로드에 노출되어서는 안 됩니다.
두 계층으로 분리를 구현합니다.
Tier 1 — edge 방화벽. edge-and-cache 박스는 기본 거부 인바운드 자세로 ufw(uncomplicated firewall)를 실행합니다. WireGuard UDP 포트(51820)만 공용 인터넷에 노출됩니다. SSH, SMB, DNS, NTP 및 edge에서 실행되는 다른 서비스는 내부 인터페이스에 바인딩되어 클러스터 외부에서 접근할 수 없습니다. 포워딩 규칙은 WireGuard 인터페이스와 클러스터 LAN 사이의 패킷을 허용하지만 그 중 어느 것과 제공자의 다른 내부 네트워크 사이는 허용하지 않습니다. 기본 포워딩 자세는 명시적으로 허용되지 않는 한 드롭입니다.
Tier 2 — 각 노드의 호스트 방화벽. 모든 렌더 노드는 edge 자세를 미러링하는 자체 Windows 방화벽 구성을 가집니다 — 클러스터가 필요로 하는 서비스(SMB, 원격 데스크톱, 렌더 매니저)에 대해 클러스터 IP에서의 인바운드를 허용하고 나머지는 드롭합니다. 이것은 중복이 아닙니다. 심층 방어입니다. 노드가 잘못 구성되거나 손상되더라도 호스트 방화벽이 장벽으로 남습니다.
두 계층 모두의 원칙은 최소 권한입니다: 고객과 노드는 노드 그룹만 볼 수 있어야 합니다. 고객에게 제공자의 내부 네트워크로의 일반 경로를 제공하지 않습니다. 고객의 터널은 edge 박스에서 종료됩니다. edge 박스는 클러스터 LAN으로만 라우팅합니다. 클러스터 LAN은 클러스터 구성원 간에만 라우팅합니다.
실제로 고객이 원하더라도 제공자의 다른 시스템을 ping하거나 스캔할 수 없습니다. 공유 관리 플레인도, 다른 테넌트를 노출하는 공유 모니터링 경로도 없습니다.
배운 교훈
구축한 모든 전용 클러스터에서 디버깅 시간을 절약했거나 — 적용을 잊었을 때 — 디버깅 시간이 들었던 다섯 가지 운영 교훈입니다.
1. 듀얼 홈 게이트웨이 라우팅 함정. edge 박스가 두 개의 네트워크 인터페이스를 가질 때(하나는 공용, 하나는 LAN), 작업 순서가 중요합니다. LAN 경로는 기본 경로가 변경되기 전에 구성되어야 합니다. 기본 경로를 먼저 전환하고 LAN 경로를 추가하려 하면, 로그인에 사용한 SSH 세션이 기본 경로가 변경되는 순간 끊길 수 있어 박스에서 잠겨 버릴 수 있습니다. 수정은 기술적인 것이 아니라 절차적입니다: 항상 내부 경로를 먼저 구성하고 검증한 다음 기본 경로를 수정하세요.
2. WireGuard와 DNS. dnsmasq는 WireGuard 인터페이스를 포함하여 리스닝할 모든 인터페이스를 명시적으로 나열해야 합니다. LAN 인터페이스만 나열하면 VPN 클라이언트의 DNS 조회가 시간 초과됩니다 — 하지만 ping 응답은 여전히 작동합니다. DNS를 거치지 않기 때문입니다. 이것은 저희가 만난 가장 진단하기 혼란스러운 장애 모드 중 하나입니다. 수정은 dnsmasq 구성의 한 줄이지만, 어디를 확인해야 하는지 알아야 합니다.
3. 터널을 통한 TCP MSS 클램핑은 선택 사항이 아닙니다. TLS 핸드셰이크, RDP 세션, SMB 대용량 파일 읽기 — 큰 패킷을 전송하려는 모든 것 — 은 MSS가 클램프되지 않으면 조용히 드롭됩니다. 첫 번째 증상은 대개 "Moonlight가 10초 동안 작동하다가 멈춘다" 또는 "SMB가 디렉토리는 나열하지만 1 MB보다 큰 파일을 읽을 수 없다"입니다. 수정은 WireGuard 호스트에서의 iptables 규칙 하나입니다. 클러스터 인계 전에 적용하십시오.
4. 스토리지를 적절히 크기 조정하고 과도하게 설계하지 마세요. 이 아키텍처의 이전 버전에서는 XFS에 LUKS 암호화를 적용한 RAID 10을 지정했습니다. 배포한 캐시 하드웨어는 단일 SSD였습니다. RAID 레이어를 제거하고, LUKS 레이어를 제거하고, ext4를 사용했습니다 — 캐시가 진실의 출처가 아니라 클라우드 플랫폼이 진실의 출처이기 때문입니다. 캐시 계층의 문서상 중복성을 클라우드 계층의 실제 중복성으로 교환한 것은 옳은 결정이었습니다. 교훈: 계획 문서에서 안전해 보이는 것이 아니라 데이터가 실제로 필요로 하는 것을 중심으로 스토리지를 설계하세요.
5. 캐시를 pre-warm 하세요. D-Day에는 모든 캐시 미스가 국제 링크와 클라우드 플랫폼을 왕복하는 비용이 듭니다. 콜드 캐시에서의 첫 번째 생산 시간은 다른 모든 것이 올바르게 구성되어 있어도 느리게 느껴집니다. 이제는 모든 계약에 pre-warm 창을 계획합니다 — 보통 프로덕션 시작 하루 또는 이틀 전입니다. 아티스트는 pre-warm을 보지 못합니다. 첫 번째 프레임부터 이미 빠르게 느껴지는 클러스터를 경험합니다.
이것들은 아키텍처적 교훈이 아니라 운영 교훈입니다. 아키텍처 문서가 아닌 배포 체크리스트에 포함됩니다. 하지만 이것들이 이론상으로 작동하는 클러스터와 실제 프로덕션 부하를 견디는 클러스터를 구분합니다. 더 작은 패턴들은 계약별로 적용되며, 위의 다섯 가지는 모든 배포에 등장한 것들입니다.
결론
전용 20노드 국경 간 GPU 렌더팜은 IP 통제가 계약 의무이고, 계약 기간이 수개월이며, 워크플로가 사용자 정의 구성을 필요로 하고, BYOC 인증이 협상 불가능할 때 올바른 아키텍처입니다. 이러한 조건 외에는 관리형 렌더팜이 거의 항상 더 나은 선택입니다 — 여기서의 아키텍처 복잡성은 프로젝트 기반 작업이나 전담 운영 기능이 없는 팀에게는 정당화되지 않습니다.
조건이 해당될 때, 여기에서 다룬 패턴들 — Model B 자격 증명, ext4의 공유 캐시, WireGuard hub-and-spoke 전송, MSS 클램핑과 함께하는 BBR, 원격 데스크톱을 위한 Moonlight + Sunshine, 2계층 방화벽 — 은 기본적으로 배포하는 것들입니다. 유일하게 유효한 패턴은 아니지만, 여러 배포에서 지속된 것들입니다.
Super Renders Farm의 팀은 관리형 렌더팜 임대와 전용 클러스터 배포를 모두 운영합니다 — 이 가이드 전반에 걸쳐 설명된 전용 GPU 클러스터 구성 및 국경 간 토폴로지를 포함합니다.
FAQ
Q: 일반적인 20노드 전용 클러스터 배포는 얼마나 걸립니까? A: 범위, 시설의 하드웨어 준비 상태, 고객의 cloud file-streaming 설정에 따라 일반적인 계약은 하드웨어 및 네트워크 프로비저닝을 위한 몇 주의 리드 타임에서 프로덕션 시작 전 1~2일의 pre-warm 창까지 다양합니다. 고정된 템플릿이 아닌 고객의 프로덕션 일정에 맞춰 타임라인을 조정합니다.
Q: 우리 팀이 세 대륙에 분산되어 있다면 어떻게 됩니까? A: WireGuard hub-and-spoke 토폴로지는 클러스터 아키텍처를 변경하지 않고 추가 클라이언트 위치로 확장됩니다. 각 원격 아티스트는 WireGuard 클라이언트를 실행하고 클러스터 시설의 동일한 허브에 연결합니다. 각 지역에서의 지연은 해당 지역과 허브 사이의 공용 인터넷 경로에 따라 결정됩니다. 경험상 BBR과 MSS 클램핑이 이러한 경로에서 사용 가능한 것과 사용 불가능한 것의 차이를 만들어냅니다.
Q: 수개월 계약에 들어가기 전에 내 쪽에서 클러스터를 미리 확인할 수 있습니까? A: 일반적으로 범위 논의 중에 개념 증명(PoC) 창을 마련합니다. 정확한 형태는 고객의 프로젝트에 따라 다릅니다 — 때로는 아티스트 경험을 테스트하기 위한 단일 노드 원격 데스크톱 세션이고, 때로는 캐시와 cloud file-streaming 통합을 검증하기 위한 소규모 렌더 테스트입니다. 구체적인 조건은 비즈니스 논의 사항입니다. 타임라인에 맞는 방법을 논의하려면 영업팀에 문의하십시오.
Q: 계약 종료 시 데이터 보안은 어떻게 처리됩니까? A: Model B는 고객 자격 증명을 저희 손에 두지 않으므로, 계약 종료 정리는 하드웨어 및 캐시 정리에 집중됩니다. SMB 캐시를 초기화하고, 모든 노드를 클린 베이스라인에서 재이미징하고, 캐시와 노드 이미지가 파기되었다는 서면 확인서를 제공합니다. 고객은 자체 cloud file-streaming 세션을 취소하며, 이는 저희 시스템 밖의 일입니다. 구체적인 계약 언어(NDA, SLA, 확인서 문구)는 영업팀이 처리합니다.
Q: 20개 이상의 노드가 필요하면 어떻게 됩니까? A: 20노드 구성이 저희가 배포하는 가장 일반적인 형태이지만, 아키텍처는 그 이상으로 확장됩니다. 더 큰 플릿은 동일한 시설 내에 추가됩니다 — 추가 예약 노드가 동일한 WireGuard 허브, 동일한 SMB3 캐시, 동일한 균일 Windows 이미지로 연결됩니다. 실질적인 한계는 대개 캐시 대역폭입니다: 단일 edge-and-cache 박스는 유한한 SMB 읽기 상한이 있으며, 매우 큰 플릿 크기에서는 캐시 아키텍처 자체를 재고해야 합니다(여러 캐시 박스, 지역별 캐시). 이러한 설계 선택은 계약별로 논의합니다.
Q: Cinema 4D, Redshift 또는 다른 DCC 도구에 대해 자체 라이센스를 가져올 수 있습니까? A: 라이센스 모델 — bring-your-own-license 대 제공자 공급 — 은 특정 DCC와 고객의 기존 라이센스 인벤토리에 따른 비즈니스 결정입니다. 일부 구성은 고객 라이센스와 깔끔하게 작동하고, 다른 경우는 제공자 공급이 더 단순합니다. 범위 논의 중에 이것을 결정합니다. 구체적인 사항은 영업팀에 문의하십시오.
Q: EU와 미국 제공자의 클라우드 스토리지는 어떻게 처리됩니까? A: cloud file-streaming 플랫폼은 고객이 선택합니다. 저희 클러스터는 Windows에서 로그인 클라이언트를 실행하고 고객의 프로젝트 트리를 마운트된 파일 시스템으로 노출할 수 있는 모든 플랫폼과 통합됩니다. 업스트림 클라우드의 지리적 위치는 고객-클러스터 경로의 국제 지연에 영향을 미칩니다 — 국경 간 설정에 WireGuard hub-and-spoke 전송과 BBR 조정 구성을 권장하는 이유입니다. 클라우드 플랫폼 자체는 저희가 호스팅하지 않으며, 고객 계정 하에 유지됩니다.
Q: WireGuard 터널이 끊어지면 어떻게 됩니까? A: WireGuard는 기본 네트워크가 복구되면 자동으로 세션을 재설정합니다. 고객의 원격 데스크톱 세션은 재핸드셰이크 중에 잠시 일시 정지될 수 있습니다. 터널이 렌더링 진행 중에 끊어지면 렌더 자체는 노드에서 계속 실행됩니다(진행 중인 작업에는 터널에 의존하지 않음). 하지만 클라우드로의 write-back은 터널이 복구될 때까지 대기열에 쌓입니다. edge 박스에서 터널 상태를 모니터링하고 장시간 다운 시 알림을 받습니다.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



