
2026年の3DレンダリングにおすすめのGPU:アーティスト向け実用ティアリスト
概要
はじめに
2026年の3DレンダリングにおけるGPU選びは、コア数が最も多いカードを選ぶだけでは済まない、より複雑な問題です。VRAMの容量、レンダリングエンジンとの互換性、ドライバーの安定性、そして具体的なワークフローがすべて重要な要素となります。V-Rayを使う建築ビジュアライゼーション(archviz)スタジオにとって「正解」のGPUと、Redshiftを使うモーションデザイナーにとっての正解は、大きく異なります。
私たちは10年以上にわたってGPUレンダリングインフラを運用しており、アーティストから最も多く寄せられる質問は、生のTFLOPS性能に関するものではありません。特定のカードがメモリ不足に陥ることなくシーンを処理できるかどうか、という点です。このガイドは、数千件の本番ジョブを通じて得られた知見を反映しています。どのGPUが実際のワークロードを安定して処理できるか、VRAMの制限がどこで問題になるか、そして異なるレンダリングエンジンが特定のハードウェアとどのように連携するかをまとめました。
このガイドはアフィリエイトレビューではありません。私たちはGPUを販売していません。私たちが提供できるのは、GPU レンダリングインフラ上のRTX 5090カードを含む、混合GPUフリートを大規模に運用することで得た運用データと、公開されているベンチマーク・エンジンドキュメントを組み合わせた情報です。
GPUレンダリングの仕組み(概要)
GPUレンダリングは、グラフィックスカードの大規模並列アーキテクチャを活用して、光の経路を同時に追跡します。CPUが16〜64コアでレイを処理するのに対し、現代のGPUは数千のCUDAコア(NVIDIA)またはストリームプロセッサ(AMD)を同じタスクに投入します。パストレーシングの本質的に並列な性質により、これが直接的なスピードアップにつながります。
2026年のレンダリングで重要なコアは3種類あります:
- CUDA/シェーダーコア — 一般的なレイトレーシング計算を担当
- RTコア — レイと三角形の交差テスト(BVHトラバーサル)専用ハードウェア
- テンソルコア — AIデノイジングを加速。現在は本番パイプラインの標準となっています
実際の結果として、RTX 5090一枚で、デュアルXeonワークステーションが15〜20分かかるフレームをわずか2〜4分でレンダリングできます。しかし、このスピードの優位性には厳しい制約が伴います。シーン全体(ジオメトリ、テクスチャ、ディスプレイスメント、ライトキャッシュ)がGPUのVRAMに収まる必要があります。これが、ゲーム向けGPU選びとレンダリング向けGPU選びを根本的に異なるものにしている理由です。
GPUとCPUのレンダリングアプローチを詳しく比較した資料については、GPU レンダリング vs CPU レンダリングガイドをご覧ください。
3Dレンダリング用GPUティアリスト(2026年)
本番パフォーマンスデータ、ドライバーの成熟度、そしてコストパフォーマンスに基づき、現在のGPUがプロフェッショナルな3Dレンダリングでどのように位置づけられるかを示します。
ティアS — 本番環境の主力
| GPU | VRAM | CUDAコア | RTコア | TDP | 市場価格(USD) | 最適用途 |
|---|---|---|---|---|---|---|
| NVIDIA RTX 5090 | 32 GB GDDR7 | 21,760 | 170 | 575W | $1,999 | 重い本番レンダリング、大規模シーン |
| NVIDIA RTX 4090 | 24 GB GDDR6X | 16,384 | 128 | 450W | $1,599〜1,799 | 本番レンダリング、優れたコスト/VRAM比 |
RTX 5090は、コンシューマークラスGPUレンダリングの現在の上限です。32 GBのGDDR7は、24 GBのカードではオーバーフローするシーンに対応します。4Kテクスチャを使った密度の高い建築ビジュアライゼーションインテリア、中程度の植生スキャッター、マルチライト設定などが対象です。24 GB(4090)から32 GB(5090)へのVRAMの増加は、多くの本番シナリオにおいて、生の計算性能の向上よりも重要です。
RTX 4090は依然として卓越したコストパフォーマンスを誇ります。24 GBで大多数の本番シーンを処理でき、そのCUDAコア数は2世代前のワークステーションカードが必要としていたレンダリング性能を実現します。

GPU比較チャート:RTX 5090、RTX 4090、RTX A6000、RTX 3090のVRAMと3Dレンダリング性能評価
ティアA — プロフェッショナル / マルチGPU
| GPU | VRAM | CUDAコア | RTコア | TDP | 市場価格(USD) | 最適用途 |
|---|---|---|---|---|---|---|
| NVIDIA RTX A6000 | 48 GB GDDR6 | 10,752 | 84 | 300W | $4,200〜4,600 | 最大VRAMシーン、VFX、シミュレーション |
| NVIDIA RTX 5080 | 16 GB GDDR7 | 10,752 | 84 | 360W | $999 | 中級予算の本番環境、中規模シーン |
| NVIDIA RTX 4080 SUPER | 16 GB GDDR6X | 10,240 | 80 | 320W | $979〜1,099 | 5080と同等、中古市場が充実 |
A6000の存在理由は一つ:48 GBのVRAMです。コストあたりの生レンダリング速度はコンシューマーカードより劣りますが、シーンが30 GB以上のGPUメモリを必要とする場合、これが唯一のシングルカードオプションです。大規模なシミュレーションキャッシュやディスプレイスメントが多い環境を扱うVFXスタジオは、このゆとりを日常的に必要としています。
RTX 5080とRTX 4080 SUPERは興味深い分岐点に位置しています。16 GBは製品ビジュアライゼーション、シンプルなインテリア、モーションデザインには十分ですが、建築ビジュアライゼーションの外観や重いテクスチャロードのあるシーンには限界があります。GPUエンジン専用のアーティストは、テクスチャ解像度とシーンの複雑さが増す中で、16 GBが引き続き十分かどうかを真剣に検討すべきです。
ティアB — エントリー本番 / ルックデブ
| GPU | VRAM | CUDAコア | RTコア | TDP | 市場価格(USD) | 最適用途 |
|---|---|---|---|---|---|---|
| NVIDIA RTX 4070 Ti SUPER | 16 GB GDDR6X | 8,448 | 66 | 285W | $749〜829 | 低予算本番環境、ルックデブのイテレーション |
| NVIDIA RTX 3090 Ti | 24 GB GDDR6X | 10,752 | 84 | 450W | $800〜1,000(中古) | 中古市場でのコスト効率、高いVRAM/コスト比 |
| NVIDIA RTX 3090 | 24 GB GDDR6X | 10,496 | 82 | 350W | $650〜850(中古) | 3090 Tiと同じ24 GB、より安価な中古品 |
RTX 3090/3090 Tiは特筆に値します。中古市場で$1,000以下の24 GBカードは、レンダリングにおける驚異的なVRAMコスト効率を誇ります。生の計算速度は現行世代より遅く(Redshiftでは RTX 4090の約60〜70%)、ですが本番作業においては、シーンの適合性(VRAMへの収まり)が生の速度よりも重要なことが多いです。多くのスタジオが3090を使う理由は、24 GBによって16 GBの現行世代カードではオーバーフローするシーンをレンダリングできるからです。
ティアC — 学習 / 軽量な本番環境
| GPU | VRAM | 備考 |
|---|---|---|
| NVIDIA RTX 4060 Ti 16 GB | 16 GB | VRAM十分、計算速度は低め — Redshift/Octaneの学習に適切 |
| NVIDIA RTX 4060 Ti 8 GB | 8 GB | 本番GPUレンダリングにはVRAMが不足 |
| AMD Radeon RX 7900 XTX | 24 GB | レンダリングエンジンのサポートが限定的(HIP/Cyclesのみ) |
AMDについて注記: Radeon 7900 XTXは魅力的な価格で24 GBを提供しますが、レンダリングエンジンのサポートは依然として限定的です。AMD GPUをサポートしているのは、Blender Cycles(HIP経由)、ProRender、そして一部の小規模エンジンのみです。Redshift、Octane、V-Ray GPUはNVIDIA専用です(CUDA/OptiX)。Blender中心のパイプラインであればAMDは選択肢になりますが、それ以外の場合、2026年のGPUレンダリングにはNVIDIAが実用的な選択肢となります。
用途別のVRAM要件
VRAMはレンダリングにおけるGPU選択で最も重要な要素です。本番データに基づいて、各ワークフローが実際にどれだけのVRAMを必要とするかを示します。
| 用途 | 一般的なVRAM使用量 | 最小GPU | おすすめGPU |
|---|---|---|---|
| 製品ビジュアライゼーション(単体オブジェクト、スタジオライティング) | 4〜8 GB | RTX 4070 Ti(16 GB) | RTX 4090(24 GB) |
| 建築ビジュアライゼーションインテリア(家具付き、4Kテクスチャ) | 10〜16 GB | RTX 4090(24 GB) | RTX 5090(32 GB) |
| 建築ビジュアライゼーション外観(植生、複数棟) | 18〜32 GB | RTX 5090(32 GB) | RTX A6000(48 GB)またはクラウド |
| モーションデザイン(スタイライズド、中規模ジオメトリ) | 6〜12 GB | RTX 4080(16 GB) | RTX 4090(24 GB) |
| VFX(シミュレーションキャッシュ、重いディスプレイスメント) | 20〜48 GB以上 | RTX A6000(48 GB) | マルチGPUまたはクラウド |
| アニメーション(フレームごと、安定したシーン) | フレームによる | シーンのピークVRAMに合わせる | +25%のヘッドルーム |
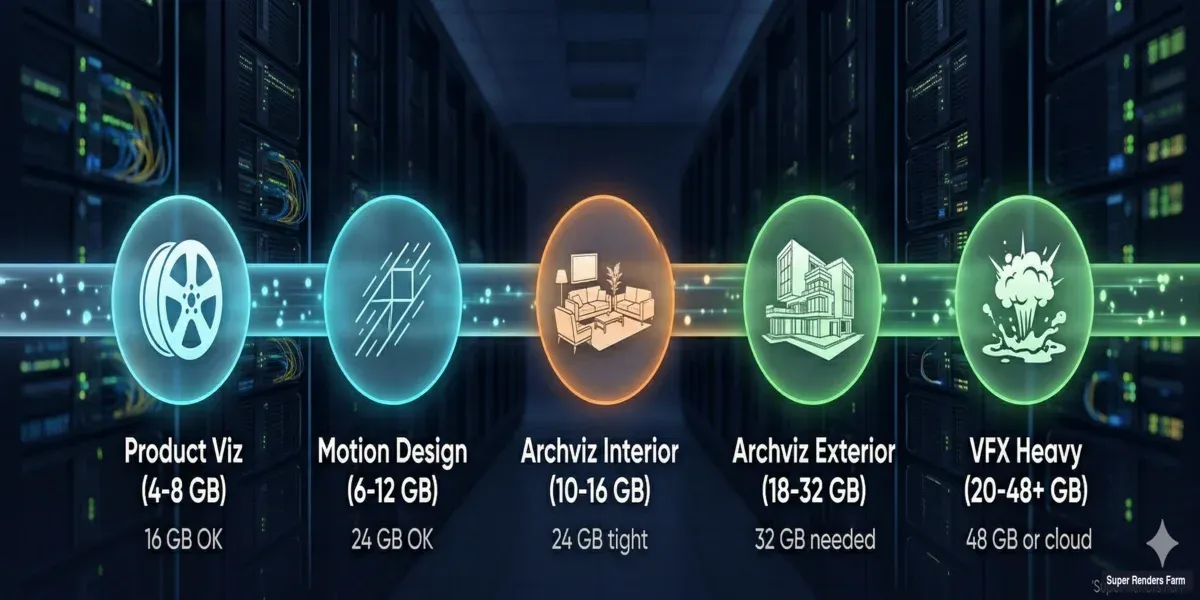
VRAM要件図:製品ビジュアライゼーション、建築ビジュアライゼーションインテリア・外観、VFXレンダリングに必要なGPUメモリ
実際にVRAMを消費するもの:
| アセットタイプ | おおよそのVRAMコスト |
|---|---|
| 4Kテクスチャ(GPU圧縮) | 16〜32 MB |
| 4Kテクスチャ(非圧縮) | 64 MB |
| 100万ポリゴン | 40〜80 MB |
| ディスプレイスメントマップ(密なサブディビジョン) | オブジェクトごとに200〜500 MB |
| ボリュームキャッシュ(煙・炎) | 500 MB〜4 GB |
| Forest Pack / スキャッター(1,000万インスタンス) | 2〜8 GB |
| HDRI環境(8K) | 128〜256 MB |
4Kテクスチャ(圧縮)80枚、500万ポリゴン、ディスプレイスメントオブジェクト2つ、8K HDRIを持つシーンは、レンダリングエンジンのオーバーヘッド(BVH構造、ライトキャッシュ、デノイザーバッファ)を加算する前の時点で約6〜10 GBを使用します。これは16 GBで管理可能です。しかし、Forest Packの植生に500万インスタンスを追加すると15〜20 GBになり、突然16 GBカードは処理できなくなり、最低でも24 GBが必要になります。
VRAMの制限が複雑なシーンにどのような影響を与えるかの詳細な分析については、RTX 5090 VRAMリミット分析をご覧ください。
レンダリングエンジンのGPU互換性(2026年)
すべてのGPUがすべてのレンダリングエンジンで動作するわけではありません。以下の表は現在の本番互換性を示しています。
| レンダリングエンジン | NVIDIA CUDA | NVIDIA OptiX(RTコア) | AMD HIP | Intel Arc | マルチGPU | アウト・オブ・コア(RAMフォールバック) |
|---|---|---|---|---|---|---|
| Redshift 3.6以降 | 完全対応 | 完全対応 | 非対応 | 非対応 | 対応(ほぼ線形スケーリング) | 対応(速度低下あり) |
| Octane 2024以降 | 完全対応 | 完全対応 | 非対応 | 非対応 | 対応 | 限定的 |
| V-Ray GPU 7 | 完全対応 | 完全対応 | 非対応 | 非対応 | 対応 | ハイブリッドCPU+GPUモード |
| Arnold GPU 7.3以降 | 完全対応 | 完全対応 | 非対応 | 非対応 | 対応 | ユニファイドメモリモデル |
| Cycles(Blender 4.x) | 完全対応 | 完全対応 | 完全対応(HIP) | 部分対応(oneAPI) | 対応 | 非対応 |
| Unreal Engine 5.4以降(パストレーサー) | 完全対応 | 完全対応 | 非対応 | 非対応 | 限定対応 | 非対応 |
| D5 Render | 完全対応 | 完全対応 | 非対応 | 非対応 | 非対応 | 非対応 |
| Enscape | 完全対応 | 完全対応 | 非対応 | 非対応 | 非対応 | 非対応 |
重要なポイント:
-
NVIDIAの優位性は構造的です。 主要なGPUレンダリングエンジンはすべてCUDAとOptiXに対応しています。AMDサポートは本番レンダリングでは事実上Blenderのみです。これはすぐには変わらないでしょう。エンジン開発者は実際に使っているユーザーのハードウェアを優先します。(私たちはRedshiftのMaxon公式レンダーパートナーであり、V-RayのChaos公式レンダーパートナーです。どちらのエンジンも毎日GPUフリートで稼動しています。)
-
OptiXは重要です。 OptiX経由のRTコア加速は、対応エンジンにおいて生のCUDAと比較して20〜40%のスピードアップをもたらします。すべてのRTXカード(20シリーズ以降)はRTコアを搭載していますが、新世代ほど高性能です。RTX 5090の第4世代RTコアは、重いレイトレーシングシーンで測定可能な改善を示しています。
-
マルチGPUのスケーリングは変動します。 Redshiftはほぼ線形にスケール(2 GPUで1.8〜1.9倍)します。Octaneは最終レンダリングではよくスケールしますが、ビューポートではそうではありません。V-Ray GPUとArnold GPUはマルチGPUをサポートしていますが、多くのワークロードで2枚を超えると収益逓減があります。2〜4枚を超えてスケールするにはクラウドレンダリングがより実用的です。PCIeの帯域幅ボトルネック、電力制約、初期投資を回避できます。
-
アウト・オブ・コアはセーフティネットであり、ワークフローではありません。 RedshiftのアウトオブコアレンダリングはシーンがVRAMを超えた際のクラッシュを防ぎますが、パフォーマンスは3〜8倍低下します。アウト・オブ・コアの能力に合わせてGPUをサイジングしないでください。典型的なシーンがVRAMに収まるようにサイジングしてください。
ベンチマーク比較:実際のレンダリング性能
これらのベンチマークは、標準化されたシーンを使用してレンダリングのスループットを比較します。すべての数値は公開されているベンチマークスイート(Blender Benchmark、OctaneBench、Redshiftのベンダーデータ)と私たちの内部テストを組み合わせたものです。
| GPU | Blender Classroom(サンプル/分) | OctaneBench 2024 | Redshift(建築ビジュアライゼーションインテリア、相対値) | V-Ray GPU(V-Rayベンチマーク、vraymarks) |
|---|---|---|---|---|
| RTX 5090 | 1,850 | 982 | 1.00x(基準) | 3,420 |
| RTX 4090 | 1,420 | 756 | 0.77x | 2,640 |
| RTX 5080 | 1,050 | 548 | 0.57x | 1,920 |
| RTX 4080 SUPER | 980 | 512 | 0.53x | 1,810 |
| RTX 3090 Ti | 920 | 482 | 0.50x | 1,680 |
| RTX 3090 | 870 | 458 | 0.47x | 1,590 |
| RTX A6000 | 780 | 412 | 0.42x | 1,440 |
| RTX 4070 Ti SUPER | 740 | 392 | 0.40x | 1,380 |
これらの数値についての重要なコンテキスト:
- ベンチマークはVRAMに収まるシーンの計算速度を測定します。実際のシーンが収まるかどうかは示しません。
- RTX A6000は生の計算では コンシューマーカードより低いスコアを出しますが、このリストの他のどのカードでもクラッシュするシーンをレンダリングできます。VRAM容量はベンチマークに現れません。
- RTX 5090の4090に対する30%の向上はエンジン間で一貫しており、エンジン固有の最適化ではなくアーキテクチャ的な改善を示しています。
- 実際の本番パフォーマンスはベンチマークと大きく異なります。重いディスプレイスメントのあるシーンはRTコアにより多くの負荷をかけ、複雑なシェーダーのあるシーンはCUDAコアに、多くのテクスチャがあるシーンはメモリ帯域幅に負荷をかけます。
クラウドGPUレンダリング vs ハードウェアの購入
必要なGPUのコストが所有するのに合理的な金額を超えたとき、あるいは締め切りに単一のワークステーション以上のレンダリング能力が必要になったとき、クラウドGPUレンダリングという選択肢が浮上します。
購入が適切な場合:
- 毎日レンダリングを行い、1日4時間以上GPUを活用できる場合
- シーンが単一GPUのVRAMに余裕で収まる場合
- 即時アクセスを重視する場合(アップロード時間なし、キューなし)
- ワークステーションGPUとして$1,500〜5,000の初期費用が許容できる場合
クラウドGPUレンダリングが適切な場合:
- 締め切りに多数のGPUによる並列レンダリングが必要な場合
- シーンがローカルGPUのVRAMを超える場合(クラウドファームはより高VRAM のオプションを提供)
- レンダリングが断続的(締め切り時は集中、それ以外は遊休)な場合
- 初期費用なしで最新世代のハードウェアにアクセスしたい場合
- 総所有コスト分析で使用パターンに対してクラウドが有利な場合
Super Renders Farmでは、GPUレンダリングジョブにRTX 5090 GPU(それぞれ32 GB VRAM)を使用しています。シーンが24 GBを超えるアーティスト(ローカルRTX 4090の上限)にとって、32 GBカードでのクラウドレンダリングは$4,000以上のA6000を購入することなくヘッドルームを提供します。ハードウェアの減価償却、電力コスト、繁忙期に数十のGPUにスケールする柔軟性を考慮すると、コスト的にも合理的です。
最も成功しているスタジオが採用するハイブリッドアプローチ:日々のルックデブとイテレーション用に高性能なローカルGPU(RTX 4090または5090)を使用し、最終本番フレームと締め切り前の集中期間にはクラウドレンダリングを組み合わせる方法です。クリエイティブ作業中は即時フィードバックを得られ、スループットが必要なときはバースト能力を活用できます。
予算と用途別のおすすめ
$1,000以下 — 学習と軽量な本番環境
おすすめ:RTX 3090(中古、約$700〜850)またはRTX 4070 Ti SUPER(約$799)
VRAMが速度より重要な場合(レンダリングではたいていそうです):中古のRTX 3090を選んでください。24 GBなら、中規模の本番シーンでメモリの壁に当たることはありません。保証付きの新品ハードウェアを希望する場合:4070 Ti SUPERは16 GBで製品ビジュアライゼーションとモーションデザインを快適に処理できます。
$1,000〜$1,800 — 本格的な本番環境
おすすめ:RTX 4090(約$1,599〜1,799)
RTX 4090は2026年のほとんどのプロフェッショナル3Dレンダリングワークフローにおいて、シングルカードのおすすめとして依然として最右翼です。24 GBで大多数の本番シーンを処理でき、計算パフォーマンスはRTX 5090の25〜30%以内で、$400〜600安価です。32 GBが特に必要な場合、またはすでに4090を持っている場合を除き、コストパフォーマンスが最も高い選択肢です。
$1,800〜$2,500 — シングルカードの最大性能
おすすめ:RTX 5090(約$1,999)
24 GBでは不十分だが、A6000の$4,000以上は正当化できない場合に適しています。32 GBのGDDR7は、密な建築ビジュアライゼーションインテリア、中程度の植生シーン、24 GBカードでオーバーフローするVFXショットを処理できます。これは私たちのGPUレンダーノードで稼動しているカードです。32 GBのVRAMと現行世代の計算性能の組み合わせは、最も幅広い本番シナリオをカバーします。
$4,000以上 — 最大VRAM
おすすめ:RTX A6000(48 GB、約$4,400)
32 GBを超えるシーンを定期的に扱う場合のみ対象です。ボリュームシミュレーションを伴う重いVFX、完全な植生を持つ密な都市環境、またはコンシューマーハードウェアには収まらない複数アセットのコンポジションなどです。この価格帯ではクラウドレンダリングを代替案として検討することをお勧めします。A6000への設備投資は、実質的なクラウドレンダリングクレジットに変換できます。
FAQ
Q: 2026年の3DレンダリングにおすすめのGPUは何ですか? A: NVIDIA RTX 5090(32 GB VRAM)は、プロフェッショナルな3D作業においてレンダリング速度とメモリ容量の最も優れた組み合わせを提供します。RTX 4090(24 GB)はほとんどのワークフローで依然として優れたコストパフォーマンスを誇ります。選択は主に、シーンが24 GBのVRAMを超えるかどうかによって決まります。
Q: GPUレンダリングに必要なVRAMはどれくらいですか? A: 製品ビジュアライゼーションとモーションデザインでは、16 GBが実用的です。4Kテクスチャを使った建築ビジュアライゼーションインテリアでは、24 GBが快適なヘッドルームを提供します。植生を使った建築ビジュアライゼーション外観やシミュレーションデータを含むVFXでは、32〜48 GBが必要になることが多いです。実際の要件は、シーンのテクスチャ数、ポリゴン密度、ディスプレイスメントの複雑さによって決まります。
Q: RedshiftはAMD GPUで動作しますか? A: いいえ。RedshiftにはNVIDIA GPU(CUDA/OptiX)が必要です。OctaneとV-Ray GPUも同様です。主要なレンダリングエンジンの中で、AMD GPUをHIP経由でサポートしているのはBlender Cyclesのみです。Redshift、Octane、またはV-Ray GPUを使うパイプラインには、NVIDIAハードウェアが必要です。
Q: レンダリング用にRTX 5090はRTX 4090からアップグレードする価値がありますか? A: RTX 5090は約30%高速なレンダリングと33%多いVRAM(32 GB vs 24 GB)を提供します。シーンが定期的に20〜24 GBのVRAMを使用していてメモリ制限に達している場合、アップグレードは即座に正当化されます。シーンが20 GB以下に余裕で収まる場合、4090は依然として非常に有能であり、30%の速度改善はコスト差を正当化しないかもしれません。詳細なベンチマークについてはRTX 5090レンダリング性能分析をご覧ください。
Q: レンダリングに複数のGPUを使用できますか? A: はい、ほとんどのGPUレンダリングエンジンはマルチGPU構成をサポートしています。Redshiftはほぼ線形にスケール(2 GPUで1.8〜1.9倍)します。OctaneとV-Ray GPUも複数カードをサポートしています。VRAMはGPU間でプールされません。各カードがシーンデータを独立して保持する必要があります。マルチGPUは速度を向上させますが、VRAMの制限は解決しません。
Q: レンダリングにワークステーションGPU(Quadro/RTX Aシリーズ)は必要ですか? A: レンダリングパフォーマンスという観点では必要ありません。コンシューマーRTXカード(4090、5090)は、パストレーシングのワークロードにおいてワークステーション同等品より高速で安価です。ワークステーションカード(A6000)のプレミアムが正当化されるのは、より多くのVRAM(48 GB)、特定のCAD/DCCアプリケーション向けの認定ドライバー、またはシミュレーションワークロード向けのECCメモリが必要な場合のみです。純粋なレンダリングにおいては、コンシューマーカードの方がコストあたりのパフォーマンスが高いです。
Q: GPUを購入する代わりにクラウドGPUレンダリングを使うべきはいつですか? A: クラウドGPUレンダリングが適切なのは以下の場合です:締め切りに所有するGPU以上の処理が必要な場合、シーンがローカルGPUのVRAMを超える場合、レンダリングのワークロードが常時ではなく断続的な場合、または総所有コスト(ハードウェア+電力+減価償却)が使用パターンに対してクラウドクレジットを超える場合。多くのスタジオは、日々のイテレーション用のローカルGPUと、最終本番アウトプット用のクラウドレンダリングを組み合わせています。
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



