
クラウドレンダーファームでのHoudini Karma XPU:2026年テクニカルガイド
概要
はじめに
Karma XPUは、多くのHoudiniスタジオが採用しているレンダラーです。理由は明確です。SideFXが開発した本格的なプロダクションレンダラーであり、SolarisとUSDにネイティブで統合されており、CPUとGPUを組み合わせたハイブリッド実行によってルックデブがほぼインタラクティブに感じられます。シングルワークステーションでの操作は快適です。問題が生じるのは、Karma XPUシーンをワークステーションから取り出して、ファーム上で数百フレームを実行しようとするときです。
ファーム規模では、Karma XPUはKarma CPUの高速版としてではなく、全く異なる存在として振る舞います。VRAMは提案というよりも絶対的な上限になります。インタラクティブには問題なく動いたシミュレーションも、キャッシュされるまでは分散できません。重いフレームでレンダラーが暗黙的にCPUにフォールバックし、隣り合うカットで1つだけ6倍の時間がかかる場合があります。これらはバグではなく、負荷がかかったときに露わになるアーキテクチャの特性です。
私たちはHoudiniの分散レンダリングを長年実施しており、Karma XPUは私たちのHoudiniクラウドレンダーファーム上でRedshift、Mantra、Arnold、V-Ray for Houdini、Octaneと並んで利用可能なエンジンのひとつです。本ガイドは技術的な深掘りを目的としています。Karma XPUとは何か、Karma CPUおよびMantraとどう異なるか、ファーム上でヘッドレス実行するときに何が変わるか、シミュレーションキャッシュを事前に済ませる必要がある理由、そして特定ショットでKarma XPUとRedshiftをどう選択するかを解説します。ステップバイステップのシーン準備チェックリストが必要な場合は、Houdiniセットアップガイドをご参照ください。本記事はSolarisの基本操作を理解していることを前提としています。
Karma XPUがスケールしにくい理由
Karma XPUについて最初に理解すべきことは、「XPU」がレンダラーではなく実行モードだということです。KarmaはUSDレンダーデリゲートであり、XPUはCPUコアとNVIDIA GPUの両方に同時に処理を振り分けるパスで、両デバイスが同じ画像にサンプルを加算します。Karma CPUは同じデリゲートでGPUをオフにしたものです。この設計はワークステーションでは洗練されていますが、ファームでは4つの理由から扱いにくくなります。
第一に、GPUパスはOptiXで動作しており、ジオメトリ・テクスチャ・アクセラレーション構造をGPU VRAMにロードします。シーンがVRAMに収まるとき、フルハイブリッドの高速化が得られます。収まらないとき、Karma XPUは一部のGPUレンダラーのようにデータをストリーミングするのではなく、CPU実行へフォールバックする傾向があります。レンダリング自体は完了しますが、期待した速度の何分の一かになります。しかも通常のジョブログには何も警告が表示されません。
第二に、XPUは競合エンジンよりも歴史が浅いです。Houdini 20.0が最初のプロダクション安定版マイルストーンであり、20.5でフィーチャーカバレッジが大幅に拡張されましたが、いくつかの機能は今もKarma CPUに有利なままです。あるショットでその機能を使うと、レンダリングの一部が暗黙的にCPUパスに落ちる可能性があります。
第三に、バージョン固定が多くの人が思う以上に重要です。あるHoudiniポイントリリースで制作されたシーンは、同じリリースを実行するファームノードでレンダリングすべきです。Karmaのサーフェスは20.0・20.5・21系の間で十分に変わっているため、バージョンをまたいだレンダリングは前提にできません。
第四に——これは誰もが最初に引っかかる落とし穴ですが——シミュレーションはフレームではありません。PyroやFLIPのセットアップをファームに投げ込んで分散されると期待することはできません。これについては以下で独立したセクションとして詳しく解説します。
Karma XPU対Karma CPU対Mantra
Houdiniには3つのレンダラーが同梱されており、ファームジョブにとってその選択が最初の重要な決断になります。これらは互換性がありません。
Mantraはレガシーエンジンです。USDが存在する以前から使われており、Houdini独自のシーン記述パイプラインで動作し、MaterialXではなくVEXベース(CVEX)のシェーダーを使用します。SideFXはMantraを廃止しておらず、完全に機能しますが、新機能の追加はありません。Karmaが明確な将来の方向性です。Mantraが活躍するのは2つの場面です。再構築コストの高い独自VEXシェーダーの大規模ライブラリを持つパイプライン、そしてKarmaではまだ対応していないマイクロポリゴンやディスプレイスメントの挙動が必要な場合です。シェーダーがCVEXであれば、Karmaに変換できないため、それだけでそのショットはMantra上に留まることになります。
Karma CPUはリファレンスパスです。USDネイティブで、完全なKarmaフィーチャーセットを実装しており、あるフレームが「どう見えるべきか」の基準となります。GPUを使わずCPUコアにわたってマルチスレッド実行します。大規模なCPUフリートを持つファームでは実用的で、VRAMの上限を完全に回避できるため、GPU メモリに収まらないシーンの賢い選択肢です。
Karma XPUはハイブリッド高速化パスです。CPUとNVIDIA GPUが両方とも同じフレームにトレースを加算し、MaterialXシェーディングとKarma CPUと同じUSDネイティブ基盤を使用します。GPUとCPUを組み合わせることで、インタラクティブなルックデブとVRAM内での最終フレームをCPU単独のパスより高速にレンダリングでき、新しいSolarisパイプラインのデフォルト選択肢です。制約はKarma CPUのフィーチャーサブセットであることで、残る差異はほとんどがエキゾチックなボリューム・シェーディング・AOVのエッジケースに集中しており、SideFXはリリースごとにこれを埋め続けています。実際のプロダクションルールとして、シーケンスをXPUに確定する前にXPUとCPUの両方で比較フレームをレンダリングすることをお勧めします。XPUとCPUが一致しない場合はCPUが正しいです。
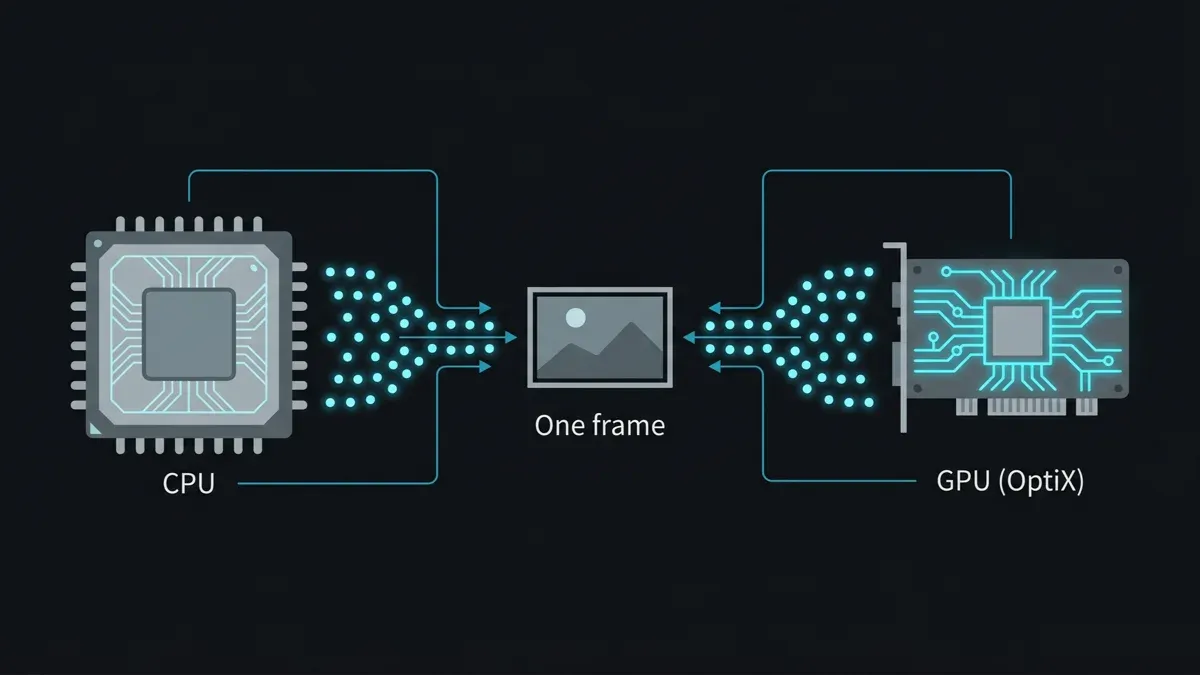
HoudiniのKarma XPUがCPUとGPUに同時にレンダリング作業を分割し、両方が単一フレームにサンプルを加算している図。
| 項目 | Mantra | Karma CPU | Karma XPU |
|---|---|---|---|
| シーン基盤 | USD以前(ネイティブパイプライン) | USD / Solaris | USD / Solaris |
| 演算 | CPU | CPU | CPU + NVIDIA GPU |
| シェーディング | VEX / CVEX | MaterialX | MaterialX |
| フィーチャー完成度 | 凍結(新機能なし) | リファレンス(完全) | CPUのサブセット、成熟中 |
| VRAMの上限 | なし | なし | あり — GPUメモリ依存 |
| 適用場面 | レガシーVEXパイプライン | 重いシーン、基準値 | USDネイティブルックデブ+VRAM内最終フレーム |
クラウドレンダーファームでKarma XPUをヘッドレス実行する
インタラクティブな環境では、Solarisビューポートのボタンをクリックしてレンダリングします。ファームでは、そのボタンに相当するのがhuskというコマンドラインプログラムです。これはSideFXのスタンドアロンUSDレンダラーで、フルインタラクティブHoudiniセッションを起動せずに、合成済みUSDステージを読み込んでレンダリングする軽量プロセスです。Houdiniに同梱されており、ファーム規模でKarmaをレンダリングするための正式な方法です。投入は本質的に次のようになります。
husk --renderer Karma \
--frame 1001 --frame-count 50 \
--output /project/render/shot_010.$F4.exr \
/project/usd/shot_010.usd
各ファームノードは同じUSDステージに対してそれぞれ異なるフレーム範囲でhuskを実行し、これによってフレームレベルの分散が機能します。ステージ自体は、すべてのジオメトリ・ライト・カメラ・マテリアルを参照する完全に合成された.usd/.usdcファイルです。AOVはコマンドラインフラグではなく、Render SettingsとRender Var LOPからステージに焼き込まれたUSD Render Varプリムです。そのためhuskはライブHoudiniネットワークなしにそれらを読み取ります。ビューティー・アルファ・ノーマル・アルベドなどはすべてUSD内に含まれます。
ファーム特有のいくつかのメカニクスを知っておくと役立ちます。Karmaはチェックポイントをサポートしており、サンプルインターバルで中間レンダリング状態を書き出すため、ノードが不安定になった場合に長尺のヒーローフレームが最初からやり直しではなく再開できます。これはサンプル数が多い単一フレームには価値がありますが、各フレームのやり直しが安価なサンプル数が適切なアニメーションには重要ではありません。デノイジングはGPU上のOptiXデノイザーまたはCPU上のIntelのOIDNで実行されます。多くのノードにまたがった時間的安定性が重要な場合、ファームではOIDNを推奨します。どのマシンが処理したかに関係なく同一の出力を生成するためです。
ライセンスについては、よくある質問なので率直にお答えします。KarmaはRedshift・Arnold・V-Ray・Octaneのように別途ライセンスが必要なプラグインではなく、Houdini本体に同梱されています。私たちはお客様のジョブをレンダリングするためにHoudiniとKarmaをレンダー専用利用で実行しています。私たちはSideFXのパートナーではなく、Houdiniライセンスを再販しておりません。ファームはフルマネージドであるため、ノードにリモートデスクトップ接続したり、Houdiniを自分でインストールしたり、ライセンスを提供していただく必要はありません。シーンとキャッシュデータをアップロードするだけで、ノード側のライセンス処理はサービス運営の一部として行われます。HoudiniスタックのRedshift・Arnold・V-Ray・Octaneのライセンスはレンダー料金に含まれています。
Super Renders FarmのHoudiniスタック
ひとつのエンジンしか動かさないレンダーファームは、すべてのショットを同じトレードオフに従わせます。Houdiniの仕事はそれに従いません。そのため、私たちのHoudiniクラウドレンダーファームはフルラインナップで動作しています。Karma(XPUとCPUの両モード)、Mantra、Redshift、Arnold、V-Ray for Houdini、そしてOctane。 このラインナップの意義は、スタジオ単位ではなくショット単位で適切なエンジンを選べることです。USDネイティブのルックデブにはKarma XPU、VRAMに収まらないボリューム重視のヒーローフレームにはKarma CPU、スピード重視のシーケンスにはRedshift、レガシーシェーダーのセットアップにはMantraという形です。
その下のハードウェアは、Houdiniの仕事と同様にCPU/GPU系統に分かれています。私たちのCPUフリートはCPUコア20,000以上を提供しており、プロダクションレンダリングの大部分が実際に行われる場所です。業界全体として、また私たちのファームでも、CPUレンダリングはジョブのシェアとして依然として大きい部分を占めています。このCPU容量がKarma CPUとMantraをシーケンス規模で実用的にしており、フレームがGPUに重すぎる場合にKarma XPUを受け止めます。GPU作業のために、専用GPUマシンはそれぞれNVIDIA RTX 5090カード、32 GB VRAMを搭載しています。Karma XPU専用としてはこの32 GBが最も重要な数値です。VRAMはシーンがどれだけ複雑でもGPUアクセラレーションが機能する前にXPUが止まる実効的な上限だからです。4K UDIMテクスチャセット・密なインスタンス環境・高解像度VDBはそれぞれこのバジェットを急速に消費します。カードが大きいほど、レンダリングが暗黙的にCPUに落ちる前に進められます。GPU依存の作業全般を検討している方は、RTX 5090 GPUレンダリングノートでカードの詳細を、GPU render farmページでフリートの概要をご覧いただけます。

Karma XPUとGPU VRAMの図:32 GB VRAMに収まるシーンはCPU+GPU両方のハイブリッド速度でレンダリングされ、VRAMを超えるシーンはCPUにフォールバックする。
料金はハードウェアに従います。CPUレンダリングはGHz時間単位、GPUレンダリングはOctaneBench時間単位で課金されるため、Karma CPUのシーケンスとRedshiftのシーケンスは、実際に行った処理を表す単位で料金が決まります。Karma XPUは両デバイスを使用できるため、最も直感的な考え方は、GPUノード上で動作してVRAMに収まっているときにGPU時間として課金され、CPUの貢献はそれに乗っかるというものです。これがVRAMの上限を守ることが重要なもうひとつの理由です。
シミュレーションキャッシュ:省略できないステップ
これはいかなるファームでもHoudiniをレンダリングする上で最も重要なコンセプトであり、誤解すると一日を無駄にする可能性が最も高い点です。フレームは「恥ずかしいほど並列」ですが、シミュレーションはそうではありません。
レンダリングされたアニメーションのフレーム1042はフレーム1041より先に存在する必要はありません。両方が同時に別々のマシンでレンダリングできます。この独立性こそがレンダーファームが機能する根本的な理由です。シミュレーションは正反対です。Pyroシミュのフレーム1042はフレーム1041の状態から計算され、それは1040から来ており、最初のフレームまで遡ります。一台のマシン上で順番に計算せずにシミュの中間を計算することはできません。生のシミュレーションをファームに渡しても、分散させるものが何もありません。
解決策は確定的かつ交渉の余地がありません。まずシミュレーションを実行し、ディスクにキャッシュし、そのキャッシュをファームでレンダリングします。 シミュレーションは1台のマシン(または専用シムボックス)で順次実行され、各フレームの結果をディスクに書き出します。これらのキャッシュファイル——今や静的でフレーム独立なデータ——がファームがレンダリングするものです。レンダーノードは再シミュレーションをしません。事前計算されたジオメトリとボリュームを読み込み、他のアニメーションと同様にフレームを並列にトレースします。
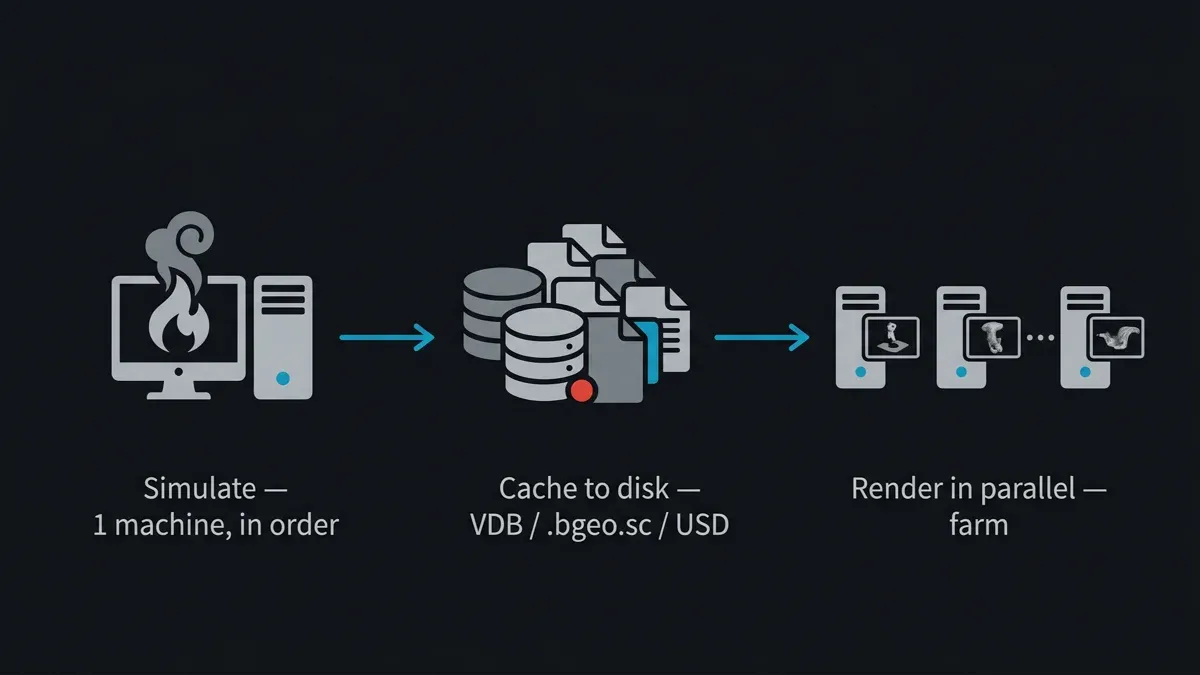
パイプライン図:シミュレーションが1台のマシンで順次解かれ、VDBまたはbgeoとしてディスクにキャッシュされ、その後レンダーファーム上でフレームごとに並列レンダリングされる。
何をキャッシュするかはソルバーによります。
| シミュレーション | ソルバー | キャッシュ形式 | 備考 |
|---|---|---|---|
| スモーク / ファイア | Sparse Pyro | .vdb | 業界標準のスパースボリューム。レンダーステージに直接読み込む |
| 液体 | FLIP | .bgeo.sc パーティクル → メッシュサーフェス | キャッシュされたパーティクルからのメッシュ化はフレーム独立なのでファームに投げることができる |
| クロス / グレイン / ソフトボディ | Vellum | .bgeo.sc | ヒーロークロスキャッシュは急速に大きくなる——ストレージスループットに注意 |
| リジッドボディ、群衆、インスタンス | RBD / Agents | .bgeo.sc またはUSD | USD(PointInstancer)がKarmaへの最もクリーンな引き渡し方 |
注目すべき点があります。シミュレーション自体とその下流作業の間には実際の違いがあります。FLIPサーフェシング——キャッシュされたパーティクルをレンダーメッシュに変換する作業——は各フレーム自身のパーティクルだけに依存し、前のフレームには依存しないため、そのステップは並列化可能であり、基盤のシムが分散できなかったとしても独自のパスとしてファームに送ることができます。Houdini 20以降のパイプラインでますます一般的になっているのは、ジオメトリを直接USDにキャッシュするパターンで、これによりhuskはレンダリング時にSOP-to-USDの変換ステップなしにネイティブに読み取れます。
ここでPDG/TOPsが活躍します。PDGはHoudiniの依存関係を考慮したタスクグラフで、ファームレンダリングが必要とする関係をそのままモデル化します。「このシミュレーションをキャッシュし、キャッシュが存在してから初めてこれらのフレームをレンダリングする」という構造です。File Cache TOPはシムキャッシュを出力依存として生成し、下流のレンダータスクはそれを待ってからフレームごとに展開します。PDGはスケジューラーノードを通じてキャッシュとhuskレンダー両方を駆動できるため、本格的なHoudiniファームパイプラインのバックボーンになっています。
実際の経験から注意点をひとつ挙げます。クロスや高解像度液体のキャッシュはフレームあたり数ギガバイトになることがあり、数十のノードが共有ストレージから同じシーケンスを一度に取得するとき、演算ではなく読み取りスループットがボトルネックになります。私たちはハードサイズ上限なしにアップロードをサポートしています(1回のアップロードは300 GB未満を推奨しており、それ以上の場合はSFTPまたはクライアントアプリを使用してください)。.tar・.tar.gz・.7zアーカイブを受け付けています——ただし.zipは非対応です。重いキャッシュシーケンスはアップロード前に.tar.gzに再パックしてください。レンダリング出力はジョブ完了から45日間利用可能です。これはフルシーケンスをダウンロードするのに十分な期間です。
Karma XPUジョブの投入:最初から最後まで
各要素を組み合わせると、クリーンなKarma XPUファームジョブは予測可能な順序で進みます。

クラウドレンダーファームへのKarma XPUジョブ投入の6ステップワークフロー:シミュレーションのキャッシュ、USDステージのエクスポート、アップロード、エンジン選択、フレームの分散、デノイズとダウンロード。
- すべてのシミュレーションをキャッシュします。 PyroはVDBへ、FLIPとVellumは
.bgeo.scまたはUSDへ。キャッシュが完全でフレームが連続していることを確認してください——中間フレームの欠落はレンダーにエラーではなく穴として現れます。 - 合成済みUSDステージをエクスポートします。 Render SettingsとRender Varプリムを焼き込み、すべてのアセットパスがワークステーションのローカルドライブではなくレンダーノードからアクセス可能な形で解決されている必要があります。
- プロジェクトをパックします。 シーン、キャッシュ、テクスチャ、OCIOコンフィグをアップロードします。ファームはフルマネージドなので、ノードにログインしたりHoudiniのインストールを管理したりする必要はありません。
- エンジンを選択します。 VRAM内のルックデブと最終パスにはKarma XPU。32 GBには重すぎると分かっているフレームにはKarma CPU。速度が優先事項の場合はRedshiftに切り替えます。
- フレームを分散します。 ファームがフレーム範囲をノード間に展開し、それぞれのスライスに
huskを実行します。管理ではなく進捗を見守るだけです。 - デノイズしてダウンロードします。 45日間のウィンドウ内にEXR(設定されていればOIDN適用済み)をダウンロードします。
これらすべてにわたる繰り返し失敗パターンはアセット解決です。USDはパスをそれを参照するレイヤーからの相対パスまたは絶対パスとして解決し、ワークステーションのローカルドライブを指す絶対パスはレンダーノード上でテクスチャやジオメトリが単純に見つからないことになります——しばしばハードエラーなしに、アセットがあるべき場所が黒くなるだけです。共有プロジェクトルートに対してパスを解決し、ジョブ全体で色がずれないようにOCIOコンフィグを一致させ、ノードが提供されていないプラグインを必要としないようにカスタムHDAの依存関係をUSDに平坦化してからエクスポートしてください。クラウドレンダリングがこの種の作業をどのように分散するかの基礎知識については、クラウドレンダーファームの概要で全体像を掴めます。
Karma XPU対Redshift:どちらを選ぶか
Karma XPUとRedshiftはどちらもGPUファームでHoudiniをレンダリングできますが、選択はどちらが「優れているか」ではなく、ショットとパイプラインが何を必要とするかによります。両者は異なる思想から来ています。Karma XPUは物理ベース・USDネイティブ・MaterialXシェーディングで、Houdini自体と同じベンダーが制作しています。Redshiftは10年以上のプロダクション実績を持つ成熟した主にバイアスドGPUレンダラーで、Houdiniプラグインを持ち——そして、これがファームでの際立った特性ですが——シーンが大きくなりすぎたときにVRAMからシステムRAMおよびNVMeへ優雅にスピルする堅牢なアウトオブコアシステムを持ちます。Karma XPUがVRAMオーバーフロー時にCPUにフォールバックする傾向があるのに対し、RedshiftはGPU上での処理を予測可能なパフォーマンスペナルティとともに続けます。そのため32 GBのカードでもRedshiftでは32 GB以上のテクスチャを持つシーンを処理できます。
この違いが大部分の決断を左右します。
| Karma XPUを選ぶ状況 | Redshiftを選ぶ状況 |
|---|---|
| パイプラインがUSD / Solarisネイティブ | 純粋なGPU速度が優先 |
| シェーダーがMaterialX | シーンがVRAM重視(大きなVDB、巨大テクスチャセット) |
| GIキャッシュのちらつきなしに物理ベースのライト転送が必要 | VRAMの上限を超えたアウトオブコアの安定性が必要 |
| 完全なSideFXスタックに統一している | チームにすでにRedshiftのシェーダーとルックデブがある |
| レンダラーコストが重要(KarmaはHoudiniに同梱) | C4D / Maya / Houdini全体で統一されたルックが必要 |
他のエンジンはエッジケースを補完します。Arnoldは複雑なサブサーフェス・ヘア・ボリュームを持つ重いVFX向け、またはパイプラインがArnold固有のシェーダーに依存している場合の選択肢です。HtoAバージョンをファームノードにピン留めし、テクスチャを事前に.txに変換してください。V-Ray for Houdiniは3ds MaxやMayaですでにV-Rayに統一されているスタジオがDCC全体で統一されたルックを求める場合に適しています。GPUサイドの比較についてはRedshiftページでご確認いただけます。Octaneはそのスペクトラルなノードベースエコシステムをすでに使っているチームに適しており、OctaneBench時間単位でクリーンに課金されます。エンジン比較ではなくプロバイダー比較が必要な場合は、Houdiniレンダーファーム比較がその決断をカバーしています。
ファーム上のKarma XPU特有の注意点があります。シーケンスには軽いフレーム(GPU高速化)と重いフレーム(暗黙的にCPU依存)が混在する可能性があるため、一見均一なジョブでもレンダリング時間が大幅に変動することがあります。修正方法は、全範囲をコミットする前に最も重いフレームで事前メモリチェックを実行することです。32 GB VRAMを超えるようなら、レンダラーがシーケンス中に自動で決定するよりも、CPUフリートのKarma CPUかRedshiftのアウトオブコアパスを意図的に選択してください。エンジン自体を超えて、標準的なファームの注意点も同様に適用されます。Houdiniバージョンをピン留めし、デノイザーの設定をノードごとのデフォルトに頼らず明示的にし、パスがワークステーションからではなくノードから解決されることを確認してください。
公式レンダラーの詳細については、SideFXがKarmaとhuskコマンドラインレンダラーの詳細なドキュメントを提供しています——最初の大規模投入前に読む価値があります。
FAQ
Q: Karma XPUとKarma CPUの違いは何ですか? A: どちらも同じUSDネイティブKarmaレンダラーの2つの実行モードです。Karma CPUはCPUコアのみで動作し、完全なリファレンス品質のフィーチャーセットを実装しています。Karma XPUはNVIDIA GPUを追加し、CPUとGPUの両方で速度向上のためにレンダリングしますが、現在Karma CPUのフィーチャーのサブセットのみをサポートしており、GPU VRAMに依存します。実践的なルールとして、XPUの出力がおかしいときはKarma CPUでフレームを確認してください。CPUが基準値だからです。
Q: クラウドレンダーファームでKarmaをレンダリングするためにSideFXまたはHoudiniのライセンスが必要ですか? A: フルマネージドファームではお客様側からは不要です。KarmaはRedshiftやOctaneとは異なり個別ライセンスではなくHoudiniに同梱されており、私たちはお客様のジョブをレンダリングするためにHoudiniをレンダー専用利用で実行しています。私たちはSideFXのパートナーではなく、Houdiniライセンスを再販していません。シーンとキャッシュをアップロードするだけで、ノード側のライセンス処理はマネージドサービスの一部として行われます。
Q: なぜファームでのレンダリング前にシミュレーションをキャッシュしなければならないのですか?
A: シミュレーションは順次的で、フレームはそうではないからです。各シミュレーションフレームは直前のフレームの状態に依存するため、シムは1台のマシンで順番に解かれなければなりません。レンダーフレームは反対に独立しており、何百ものノードで同時に実行できます。完成したシミュレーションをディスクにキャッシュする(PyroはVDB、FLIPとVellumは.bgeo.scまたはUSD)と、ファームが再シミュレーションなしに並列レンダリングできる静的データになります。
Q: Karma XPUはGPU VRAMを超えるシーンをどう処理しますか? A: VRAMからシステムメモリに対してアウトオブコアでスピルするRedshiftとは異なり、Karma XPUはVRAMにシーンが収まらない場合CPU実行へフォールバックする傾向があります。レンダリングは完了しますが、GPUアクセラレーションが失われ、フレームはログに何も表示されずに劇的に遅くなる場合があります。重いことが分かっているシーンに対しては、フォールバックがシーケンス中に起こるままにするのではなく、CPUフリートのKarma CPUかRedshiftのアウトオブコアパスを意図的に選択することを推奨します。
Q: Karma XPUはRedshiftより速いですか? A: ショット次第です。Redshiftは高度に最適化された主にバイアスドGPUレンダラーで、特にアウトオブコアシステムがGPU上での処理を維持するVRAM重視のシーンでは一般的なプロダクションシーンでより速いことが多いです。Karma XPUは物理ベースで完全にUSDネイティブであり、Solarisパイプラインとデータのシェーディングにより適していますが、同等のノイズに対してより多くのサンプルが必要な場合があります。速度だけでは決まりません——パイプラインの適合性とVRAMのヘッドルームが通常の決め手です。
Q: huskとは何ですか?直接使う必要がありますか?
A: huskはSideFXのスタンドアロンコマンドラインUSDレンダラーで、ファームノード上で実際にKarmaをレンダリングするものです——フルHoudiniセッションなしに合成済みUSDステージを読み込む軽量プロセスです。マネージドファームでは手動で呼び出す必要はなく、シーンを投入するとファームがノード全体でフレームごとにhuskを実行します。これが存在することを知ることで、クリーンで完全に解決されたUSDエクスポートがなぜ重要なのかを理解しやすくなります。
Q: PDG/TOPsはファーム上のKarmaレンダリングを駆動できますか?
A: はい。PDGはシミュレーションのキャッシュとそこからのレンダリングの依存関係をモデル化しており、スケジューラーノードはFile CacheステップとダウンストリームのHoudini huskレンダーの両方をファーム全体に分散できます。「まずキャッシュし、フレームごとにレンダリングを展開する」をパイプラインで表現する標準的な方法であり、ジョブの順次部分と並列部分を自動的に正しい順序に保ちます。
Q: Karma XPU以外にどのHoudiniレンダラーを使えますか? A: 私たちのHoudiniスタックはKarma(XPUとCPUの両モード)、Mantra、Redshift、Arnold、V-Ray for Houdini、Octaneで動作しています。このラインナップにより、ショットに適切なエンジンを選べます——USDネイティブルックデブにはKarma XPU、VRAMが重いヒーローフレームにはKarma CPU、速度とアウトオブコアにはRedshift、レガシーVEXシェーダーにはMantra、パイプラインがそれらに依存している場合はArnold・V-Ray・Octaneという形です。
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



