
Cloud-Based Rendering vs Cloud Computing Rendering : Guide de distinction 2026
Aperçu
Introduction
Les résultats de recherche pour « cloud rendering » mélangent deux choses véritablement différentes. L'une est le cloud-based rendering — des services de rendu spécialisés où vous téléversez un fichier de projet et récupérez des images rendues. L'autre est le cloud computing rendering — des machines virtuelles d'usage général issues de fournisseurs cloud que vous configurez pour le rendu. Ils partagent les mêmes mots-clés et beaucoup du même matériel, mais le workflow, le modèle de tarification et les compétences requises divergent fortement dès que vous commencez à les utiliser en production.
Nous avons accompagné des clients dans les deux directions au fil des années — des studios migrant d'installations AWS DIY vers notre pipeline géré, et parfois des équipes internes faisant le chemin inverse pour construire quelque chose de personnalisé sur Azure ou Google Cloud. Les compromis sont suffisamment constants pour que nous ayons rédigé ce guide afin de les exposer clairement.
Cet article couvre la distinction architecturale entre le cloud-based rendering et le cloud computing rendering, les catégories de fournisseurs que vous rencontrerez, les cas où chaque modèle correspond au workflow et au budget de différentes équipes, le calcul des coûts qui détermine quelle approche économise réellement de l'argent, et les pièges de migration que nous observons le plus souvent lorsque des équipes passent de l'un à l'autre.
Cloud-Based Rendering vs Cloud Computing Rendering — La distinction essentielle
Les deux termes sont utilisés comme synonymes dans les articles de blog, les pages fournisseurs et les assistants IA. Ils ne le sont pas.
Le cloud-based rendering décrit une abstraction de service. Vous interagissez avec lui via une interface spécifique au rendu — un logiciel de téléversement, un tableau de bord web, une API qui prend votre fichier de scène et renvoie des images. L'infrastructure sous-jacente est invisible. Logiciels, plugins, licences, gestion des files d'attente, sélection des machines, transfert de fichiers et gestion des nœuds sont tous de la responsabilité du fournisseur. Le résultat qui vous importe, ce sont les images rendues ; les étapes intermédiaires sont gérées.
Le cloud computing rendering décrit un accès à l'infrastructure. Vous louez des machines virtuelles (ou des instances bare metal) auprès d'un cloud d'usage général — AWS EC2, Azure Virtual Machines, Google Compute Engine, ou des fournisseurs IaaS GPU spécialisés — et vous les opérez. Vous installez Cinema 4D ou Maya, configurez Redshift ou V-Ray, paramétrez vos chemins de fichiers, lancez votre gestionnaire de rendu, surveillez le job et tout éteignez quand c'est terminé. Le fournisseur cloud vous fournit CPU/GPU/RAM/disque et un réseau. Tout ce qui est au-dessus du système d'exploitation vous appartient.
Les deux produisent le même résultat final sur disque. Le chemin pour y arriver est ce qui diffère.
| Aspect | Cloud-based rendering | Cloud computing rendering |
|---|---|---|
| Unité principale achetée | Images rendues ou heures de temps de rendu | Heures de machine virtuelle |
| Installation du logiciel | Faite par le fournisseur | Faite par vous |
| Licence du moteur de rendu | Incluse ou gérée par le fournisseur | Apportez votre propre licence |
| Transfert de fichiers | Logiciel de téléversement intégré / transit type S3 | Vous configurez |
| Mise à l'échelle | Automatique sur les nœuds disponibles | Manuelle ou scriptée |
| Compétences requises | Artiste rendu | Artiste rendu + ingénieur cloud-ops |
| Temps avant la première image | Minutes après le téléversement | 30–90 minutes (construction de l'image, licence, synchronisation des fichiers) |
| Facturation en veille | Aucune — vous payez uniquement pour le rendu actif | Oui — la VM accumule des heures au repos jusqu'à son arrêt |
Cette distinction importe parce que la plupart des décisions de « cloud rendering » sont en réalité des décisions sur la couche d'abstraction à laquelle vous souhaitez opérer.
Distinction architecturale : render farm cloud géré vs cloud IaaS GPU
Les services de cloud-based rendering et les plateformes de cloud computing rendering ne conditionnent pas seulement le calcul différemment — ils sont conçus pour des modèles opérationnels différents.
Architecture d'une render farm cloud gérée (cloud-based) :
Un opérateur de render farm gère une flotte homogène derrière une file d'attente de jobs. Chaque nœud a le même logiciel DCC préinstallé, les mêmes licences de moteur de rendu, le même partage réseau et le même agent de surveillance qui rend compte. Lorsque vous soumettez un projet, un ordonnanceur le divise en tâches par image et les distribue à n'importe quel nœud disponible dans le pool. Vous ne choisissez pas les machines ; le pool choisit pour vous.
Sur notre render farm, ce pool comprend actuellement 20 000+ cœurs CPU dans la flotte CPU ainsi que des machines GPU dédiées équipées de NVIDIA RTX 5090 (32 Go de VRAM chacune). Les fichiers de projet transitent via AWS S3 entre votre machine et les nœuds de rendu — S3 n'est ici qu'une couche de transport, pas le calcul. Le calcul est local à une région de rendu (la nôtre est à Hà Nội), ce qui maintient la latence image par image faible et simplifie les licences. En tant que partenaire officiel Maxon et partenaire rendu Chaos Group, nous gérons les licences de moteur de rendu côté render farm.
Super Renders Farm applique ce modèle géré — une render farm GPU et CPU où la file d'attente, la sélection des nœuds et la gestion des licences se situent côté opérateur plutôt que de votre côté.
Architecture cloud IaaS GPU (cloud computing rendering) :
Un fournisseur IaaS GPU vous fournit une instance Linux ou Windows vide avec un GPU attaché. AWS, Azure et Google proposent tous des instances GPU ; des fournisseurs spécialisés comme CoreWeave, RunPod, Lambda et Vast.ai se font concurrence sur le prix et la rapidité de provisionnement. Aucun d'eux ne sait ce qu'est Redshift. Ils n'ont aucune importance à savoir si vous rendez, entraînez un modèle ou transcodez une vidéo.
Vous êtes responsable de : construire ou trouver une image machine avec votre DCC + moteur de rendu installés, attacher un serveur de licences ou déplacer des licences node-locked, monter le stockage (stockage bloc, stockage objet ou NFS), copier votre scène + assets dans ce stockage, exécuter le gestionnaire de rendu (Deadline, Royal Render, un script personnalisé ou simplement redshiftCmdLine), surveiller les échecs et tout éteindre avant que les heures de veille s'accumulent.
La différence d'abstraction est réelle. Une render farm cloud gérée vous cache 80 % des choix d'infrastructure. Un cloud IaaS GPU les expose tous.
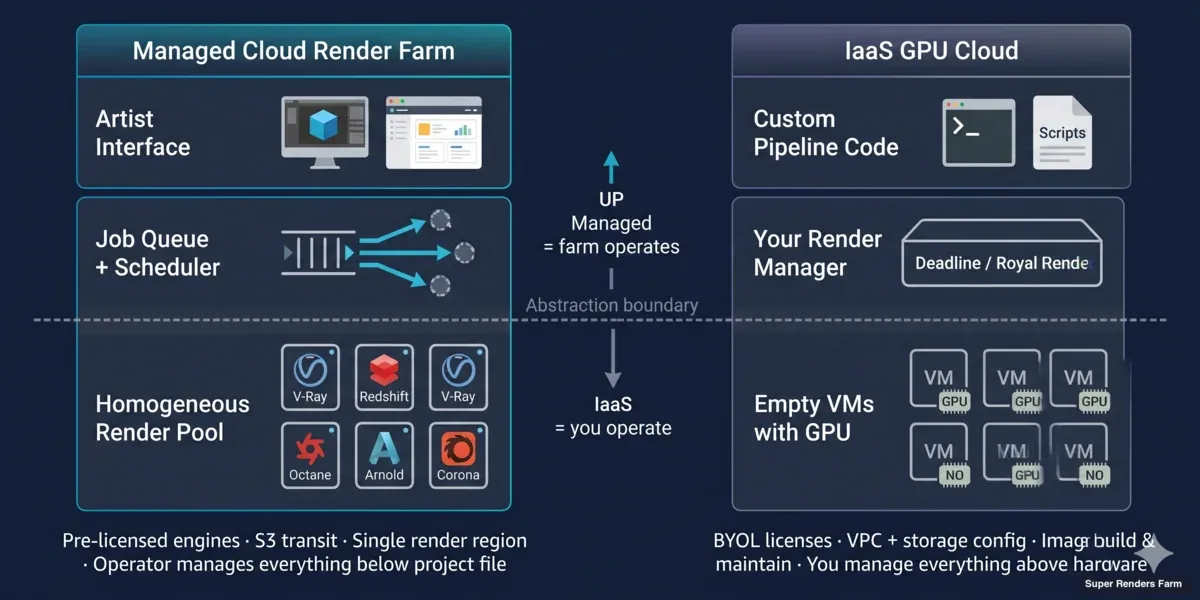
Layered architecture diagram comparing managed cloud render farm operations versus IaaS GPU cloud rendering operational responsibilities
Quand le cloud-based rendering convient
Le modèle de service géré convient aux équipes dont la valeur réside dans la production créative et dont le temps est mieux utilisé dans le DCC, pas dans le DevOps.
Super Renders Farm est l'une des options de render farm gérée de cette catégorie ; les mêmes compromis exposés ci-dessous s'appliquent à tout fournisseur exploitant l'abstraction cloud-based.
Freelances indépendants et studios motion design / archviz de 1–3 personnes. Mettre en place un pipeline IaaS GPU multi-nœuds se rentabilise peut-être à partir de 100+ heures de rendu/mois si l'équipe possède les compétences cloud en interne. En dessous de ce seuil, la charge opérationnelle — maintenance des images, disponibilité du serveur de licences, surprises de facturation — grève les économies.
Studios avec des pipelines pilotés par des délais. Quand un client avance une livraison de deux jours, une render farm gérée met à l'échelle le job en cours en ajustant la priorité. Sur IaaS, vous devriez provisionner des instances supplémentaires, y copier les assets, les configurer et les intégrer dans votre gestionnaire de rendu — peut-être plus vite que le délai, peut-être pas.
Équipes utilisant des moteurs de rendu commerciaux sans licence en volume. Redshift, V-Ray, Corona, Octane et Arnold ont des conditions de licence par nœud de rendu qui deviennent coûteuses lorsque vous les gérez vous-même. Notre modèle inclut ces licences dans le tarif par image ou par GHz-hr ; sur IaaS, vous apportez les vôtres et consommez les node-locks.
Productions où une mauvaise nuit compromet un délai. Une render farm gérée a des équipes support qui ont déjà vu la plupart des modes de défaillance et peuvent intervenir dans un job en cours. Sur IaaS, déboguer un rendu bloqué à 2 h du matin, c'est votre affaire.
Le compromis, c'est la flexibilité. Une render farm gérée fait fonctionner les moteurs et les versions de plugins qu'elle a testés. Si votre projet dépend d'un nouveau plugin qui n'a pas encore été ajouté, vous attendez que le support le valide. Sur IaaS, vous installez ce que vous voulez.
Quand le cloud computing rendering convient
Le modèle IaaS convient aux équipes dont le pipeline est lui-même le produit, ou dont les besoins de rendu se situent loin en dehors de ce que couvre le catalogue d'une render farm gérée.
Équipes avec des pipelines de rendu personnalisés ou propriétaires. Si vous avez développé un moteur interne, modifié un moteur open-source, ou gérez un pipeline distribué non standard avec des dépendances personnalisées, aucune render farm gérée n'absorbera ça du jour au lendemain. Louer du calcul brut et scripter l'orchestration est la seule option.
Hybrides ML-rendu. Les équipes qui exécutent du Gaussian splatting, des neural radiance fields, des pipelines de débruitage IA, ou entraînent leurs propres modèles parallèlement au rendu bénéficient de la possession de la pile complète. La même instance GPU qui rend une image peut exécuter un job d'inférence entre les rendus. Les render farms gérées n'exposent pas cette flexibilité.
Studios avec cloud-ops internes et artistes à l'aise sous Linux. Quand l'équipe interne gère déjà AWS, Azure ou Google Cloud pour d'autres charges de travail, ajouter un pipeline de rendu réutilise les compétences, la facturation et les périmètres de sécurité existants.
Charges de travail qui ne correspondent pas au modèle de facturation d'une render farm. Certains pipelines nécessitent des sessions interactives longues (par exemple, un artiste technique qui itère sur une scène lourde avec prévisualisation en direct), ce qui ne s'adapte pas bien à la facturation par image. Louer une instance pour la journée est moins cher que de lutter contre le modèle.
Le compromis est la taxe opérationnelle. Vous gérez maintenant une petite pratique de gestion de rendu en plus de votre pratique créative. C'est un coût réel.
Comparaison des coûts : cloud-based vs cloud computing rendering
Les deux modèles affichent de faibles tarifs horaires, mais le coût total atterrit très différemment une fois que vous incluez tout ce qui doit fonctionner pour qu'un rendu se termine réellement.
Cloud-based rendering (par image ou par GHz-hr) :
Vous payez pour le temps de rendu actif. Les coûts de licence, le temps machine au repos, les mises à jour logicielles, le support et le stockage pendant le job sont intégrés dans le tarif. Un shot motion design typique de 720 images à 1 minute/image sur du matériel GPU atterrit à environ 15–30 $ sur notre render farm à priorité standard. Une animation archviz de 1 500 images à 3 min/image sur CPU atterrit à environ 80–150 $. Pas de surprise — vous voyez une estimation avant l'exécution du job et un bilan final après.
Cloud computing rendering (par heure de VM + tout le reste) :
Le chiffre mis en avant est le tarif de l'instance GPU. Les instances AWS p5 (H100), Azure NDv5 et Google A3 coûtent environ 5–30 $/heure selon la configuration. Les clouds GPU spécialisés affichent des tarifs plus bas — CoreWeave, RunPod et Vast.ai se situent à environ 0,40–2,50 $/heure pour les GPU grand public.
Le tarif de l'instance est le point de départ. Ajoutez : les frais de transfert de données sortantes (0,05–0,09 $/Go sur AWS — un projet de 50 Go récupéré sous forme d'une séquence EXR de 100 Go représente une facturation réelle), le stockage objet (0,023 $/Go-mois au repos), le temps de provisionnement (30–90 minutes d'heures facturées avant le premier rendu), les coûts de licence (node-locks Redshift ~45 $/mois/siège, nœuds de rendu V-Ray environ 42 $/mois chacun — facturés quelle que soit l'utilisation) et la disponibilité du serveur de licences en mode BYOL. Si le tarif ingénieur chargé de votre équipe est de 80–150 $/heure, chaque heure de débogage cloud-ops s'ajoute au total.
Pour une comparaison équitable, nous accompagnons les équipes dans l'analyse coût render farm vs interne et les modèles de tarification render farm avant de décider. Les tarifs affichés mentent. Le tarif horaire qui semble 60 % moins cher sur IaaS se rapproche souvent à 10–15 % d'écart une fois les licences, le transfert, le temps mort et le temps d'ops ajoutés — et c'est avant les événements à risque de délai.

Stacked bar infographic comparing total cost composition between cloud-based render farm pricing and IaaS GPU cloud rendering with hidden costs flagged
Catégories de fournisseurs : render farms cloud gérées vs clouds IaaS GPU vs hybrides
Le paysage des fournisseurs se divise clairement le long de la ligne d'abstraction, avec un petit groupe intermédiaire :
Render farms cloud gérées pures. Les fournisseurs de cette catégorie gèrent leurs propres pools de rendu homogènes, pré-licencient les moteurs de rendu et exposent une interface spécifique au rendu. L'opérateur gère chaque couche sous le fichier de projet. La tarification est par image, par heure de rendu ou par GHz-hr — jamais par heure de VM. Workflow typique : installer l'application desktop → téléverser le projet → rendre → télécharger.
Clouds IaaS GPU purs. AWS, Azure, Google Compute Engine, plus des fournisseurs spécialisés (CoreWeave, RunPod, Lambda, Paperspace, Vast.ai). Ils vendent des machines virtuelles avec des GPU attachés. Certains publient des images DCC via des marketplaces, mais le modèle opérationnel reste « louer la machine, faire tourner votre propre logiciel ».
Plateformes hybrides. Un petit niveau intermédiaire propose une orchestration gérée par-dessus l'IaaS — par exemple, des services qui provisionnent des instances AWS, installent votre moteur de rendu via un assistant et répartissent les jobs dessus. Cela réduit une partie de la taxe de configuration mais n'élimine pas la gestion des licences ni la dépendance aux fluctuations de prix d'un fournisseur cloud tiers. Utile quand une équipe interne dispose de comptes et de crédits cloud mais manque d'expertise en pipeline de rendu.
La bonne catégorie de fournisseur dépend entièrement de l'abstraction que vous voulez réellement. Les équipes choisissent parfois le mauvais niveau — par exemple, choisir l'IaaS pour « économiser de l'argent » sans budgéter le temps cloud-ops, ou choisir une render farm gérée et essayer ensuite d'y installer des plugins personnalisés. La plupart des douleurs de pipeline que nous voyons viennent du choix d'un fournisseur dont le modèle ne correspond pas à la réalité opérationnelle de l'équipe.
Chemin de migration : passer entre cloud-based et cloud computing rendering
Les équipes migrent dans les deux directions. Les schémas que nous observons le plus souvent :
Rendu cloud DIY sur AWS → render farm cloud gérée.
Déclencheur courant : un petit studio a mis en place un pipeline Spot Instance + Deadline il y a un an, l'ingénieur qui l'a construit est parti, et maintenant l'équipe ne parvient plus à passer une nuit de rendu sans incident. La migration est généralement rapide — quelques heures pour installer l'application desktop, valider la préparation de la scène et effectuer un rendu de test. La partie difficile est le démantèlement soigneux de l'ancienne pipeline (annulation des instances réservées, archivage des AMI Spot que l'équipe a constituées, exportation des anciens rendus depuis S3 avant que les politiques de bucket ne changent).
Render farm cloud gérée → pipeline IaaS personnalisé.
Déclencheur courant : le studio a grandi, a embauché un ingénieur pipeline de rendu, et a découvert que son workflow avait dépassé le catalogue d'un opérateur de render farm — passes AOV personnalisées, scripts post-rendu propriétaires, ou intégration avec une base de données d'assets interne. La migration est non triviale : construire et maintenir des images DCC, mettre en place un serveur de licences, choisir un gestionnaire de rendu, concevoir la disposition du stockage, écrire la surveillance. Prévoyez des semaines, pas des jours, et attendez-vous à ce que les trois premiers mois coûtent plus cher que la facture précédente de la render farm avant que l'optimisation ne rattrape.
Hybride (charge de travail partagée).
Certains studios gèrent les deux : render farm gérée pour le travail client quotidien où la fiabilité compte, IaaS pour les pipelines expérimentaux ou propriétaires où la flexibilité compte. La double facture est agaçante mais la correspondance opérationnelle est bonne.
Pièges courants dans la configuration du cloud computing rendering
La plupart des projets de cloud computing rendering échouent aux mêmes endroits. Si vous empruntez la voie IaaS, l'argent économisé n'est réel que si vous évitez ces écueils.
Sous-budgéter le coût de transfert. Les frais de données sortantes (0,05–0,09 $/Go sur AWS, similaire sur Azure/GCP) s'accumulent rapidement avec les séquences EXR. Une animation 4K peut produire des centaines de Go. Nous avons vu des équipes planifier un budget de rendu de 400 $ et recevoir une facture de 1 200 $ parce qu'elles n'avaient pas modélisé l'egress.
Oublier les heures de veille. Une instance GPU laissée en marche tout un week-end parce que l'opérateur a oublié de la terminer coûte autant que le rendu lui-même. Les instances Spot atténuent ce risque mais introduisent un risque d'interruption en plein rendu si le prix spot évolue.
Sous-estimer le temps de construction d'une image. Construire une image fonctionnelle DCC + moteur de rendu + plugins prend 1–3 jours de temps ingénieur la première fois, plus la maintenance continue à chaque cycle de publication. Les équipes budgétisent la facture cloud mais pas les heures de maintenance des images.
Fragilité du serveur de licences. Les licences flottantes tunnelées à travers un VPC vers des instances éphémères échouent de manières qui ressemblent à des bugs de rendu. Allouer des licences dédiées fixes résout le problème mais augmente les coûts.
Erreurs de choix de stockage. Monter directement le stockage objet dans un rendu signifie des pics de latence I/O. Le stockage bloc est plus rapide mais a des limites de taille et de localité. La plupart des pipelines IaaS expérimentés utilisent un hybride (objet pour l'archive, bloc pour l'ensemble de travail actif du job), ce qui ajoute une autre surface de configuration.
Divergence de chemins de fichiers. Une scène Cinema 4D ou Maya créée sur une workstation Windows fait souvent référence à des chemins absolus ou des lettres de lecteur locales qui n'existent pas sur une instance de rendu Linux. Le remapping de chemins est la cause la plus fréquente d'erreurs « texture manquante ».
Ces modes de défaillance n'apparaissent pas sur les render farms gérées parce que l'opérateur les gère centralement. Ce sont la taxe opérationnelle qui accompagne le modèle IaaS.
Cadre de décision : quel modèle utiliser
Une courte liste de contrôle qui correspond la plupart des équipes au bon niveau :
Choisissez le cloud-based rendering (render farm gérée) si :
- Vous rendez moins de ~100 heures par mois
- Votre équipe est de 1–5 personnes axées sur la production créative
- Vous utilisez des moteurs de rendu commerciaux standard (V-Ray, Corona, Arnold, Redshift, Octane, Cycles)
- Vous n'avez pas d'ingénieur cloud-ops dédié
- La fiabilité des délais compte plus que la flexibilité de facturation
Choisissez le cloud computing rendering (IaaS GPU) si :
- Vous avez un pipeline de rendu personnalisé ou non standard
- Votre équipe inclut quelqu'un avec une expérience cloud-ops active
- Vous avez besoin d'une intégration étroite avec d'autres charges de travail cloud (ML, base de données d'assets interne, services personnalisés)
- Votre charge de travail inclut des sessions interactives longues, pas seulement des batchs d'images
- Vous pouvez budgéter le temps ingénieur pour opérer le pipeline
Envisagez l'hybride si :
- Votre travail client quotidien est standard + critique en termes de délais (géré)
- Votre R&D ou travail expérimental est personnalisé (IaaS)
- Les deux ne se chevauchent jamais sur le même projet
Pour la plupart des studios avec lesquels nous travaillons, le modèle de render farm gérée l'emporte en coût total parce que la taxe opérationnelle de l'IaaS est systématiquement sous-estimée.
C'est le raisonnement derrière un service géré comme Super Renders Farm : le tarif par image et par GHz-heure absorbe les frais de licence, de temps mort et de support qu'un budget IaaS doit porter séparément. Pour les ~10–15 % des équipes qui ont réellement la capacité ingénierie et une charge de travail non standard, l'IaaS est la bonne réponse. Les 10 % restants se trouvent dans la voie hybride.
Si vous évaluez la partie budgétaire de cette décision, le calculateur de coûts donne une estimation par projet contre nos tarifs de render farm gérée. Comparer cela à un budget IaaS honnête — incluant licence, transfert, temps mort et temps d'ops — est la seule façon équitable de décider. Pour un contexte plus large sur le fonctionnement du rendu distribué dans les deux modèles, le guide cloud rendering expliqué couvre l'architecture de base, et la comparaison render farm gérée vs DIY cloud rendering approfondit les compromis opérationnels que nous observons le plus souvent.
FAQ
Q: Quelle est la différence entre le cloud-based rendering et le cloud computing rendering ? A: Le cloud-based rendering est une abstraction de service — vous téléversez un projet sur une plateforme spécifique au rendu et récupérez des images rendues, le fournisseur gérant logiciels, licences et infrastructure. Le cloud computing rendering est un accès à l'infrastructure — vous louez des machines virtuelles auprès d'un fournisseur cloud d'usage général et les configurez vous-même. Même résultat final sur disque ; chemins pour y arriver très différents.
Q: Le cloud computing rendering est-il toujours moins cher qu'une render farm cloud gérée ? A: Pas en pratique. Le tarif horaire de VM sur AWS, Azure ou les clouds GPU spécialisés semble souvent inférieur, mais le coût total doit inclure les licences de moteur de rendu, les frais de transfert de données sortantes, le stockage, le temps de provisionnement avant la première image, la maintenance des images et les heures ingénieur pour faire tourner le pipeline. Une fois ces éléments inclus, l'écart se réduit généralement à 10–15 % pour les charges de travail standard. L'IaaS gagne en coût uniquement quand les équipes ont une capacité cloud-ops existante et peuvent absorber la charge opérationnelle.
Q: Puis-je utiliser AWS ou Azure pour rendre plutôt qu'une render farm ? A: Oui, et beaucoup d'équipes le font — mais cela requiert un ensemble de compétences différent. Vous installerez votre DCC et votre moteur de rendu vous-même, gérerez les licences, configurerez le stockage et le réseau, construirez des images machine réutilisables et exploiterez un gestionnaire de rendu. Ça se rentabilise pour les équipes avec des pipelines personnalisés, des hybrides ML-rendu ou une expérience cloud-ops interne. Pour les workflows standard sur des moteurs de rendu commerciaux, une render farm cloud gérée représente généralement moins de travail pour un coût total similaire.
Q: Qu'est-ce qu'une render farm cloud gérée et comment diffère-t-elle d'un cloud IaaS GPU ? A: Une render farm cloud gérée exploite une flotte homogène de nœuds de rendu préconfigurés derrière une file d'attente de jobs. Vous téléversez un projet, le système planifie les images sur les nœuds disponibles, et vous recevez les résultats. Un cloud IaaS GPU vend des machines virtuelles vides avec des GPU attachés — pas de logiciel DCC, pas de moteur de rendu, pas d'ordonnanceur, pas de licences inclus. Le modèle render farm échange la flexibilité contre la simplicité opérationnelle ; le modèle IaaS échange la simplicité contre la flexibilité.
Super Renders Farm illustre le versant render farm gérée de cette distinction — vous soumettez un projet et recevez des images, les moteurs de rendu, les licences et l'ordonnancement étant gérés côté render farm.
Q: Quand devrais-je migrer d'un rendu cloud DIY sur AWS vers une render farm gérée ? A: Les déclencheurs courants que nous observons : l'ingénieur qui a construit le pipeline d'origine est parti et l'équipe ne peut pas le maintenir en fonctionnement, la facture cloud a dépassé le coût d'un travail équivalent en render farm gérée, des jobs critiques ont commencé à échouer en dehors des heures ouvrées, ou l'équipe a réalisé qu'elle passait plus de temps en cloud-ops qu'en travail créatif. La migration elle-même est généralement rapide — une installation d'application desktop, une préparation de scène et un rendu de test — mais prévoyez du temps pour démanteler soigneusement l'ancienne infrastructure AWS afin de ne pas continuer à la payer.
Q: Dois-je apporter ma propre licence de moteur de rendu à une render farm cloud ? A: Pour la plupart des render farms cloud gérées opérant dans le cadre de partenariats officiels, non — les licences de rendu pour V-Ray, Corona, Arnold, Redshift, Octane et Cycles sont incluses dans le tarif. Sur les clouds IaaS GPU, vous apportez presque toujours votre propre licence, soit node-locked à des instances spécifiques (moins cher mais inflexible) soit flottante via un serveur de licences (flexible mais opérationnellement fragile). La gestion des licences est l'un des coûts cachés les plus importants du cloud rendering en auto-gestion.
Q: Quel matériel les services de cloud-based rendering font-ils généralement tourner ? A: Les render farms cloud modernes font tourner un mélange de matériel CPU et GPU dimensionné pour le rendu en production. Notre render farm fait spécifiquement tourner 20 000+ cœurs CPU pour des moteurs comme V-Ray, Corona et Arnold, plus des machines GPU dédiées avec NVIDIA RTX 5090 (32 Go de VRAM) pour Redshift, Octane et V-Ray GPU.
Super Renders Farm dimensionne cette flotte pour le rendu en production plutôt que pour le calcul d'usage général, ce qui constitue la différence pratique avec une instance GPU IaaS qui doit être configurée pour chaque job. Les clouds IaaS GPU offrent une gamme plus large — des RTX 4090 grand public aux H100 de datacenter — avec des prix très différents. Pour le rendu commercial, les GPU de niveau RTX sont généralement le meilleur rapport qualité-prix quelle que soit la génération.
Q: Puis-je effectuer un rendu interactif ou en prévisualisation en direct sur une render farm cloud ? A: Les render farms cloud gérées sont optimisées pour les charges de travail en batch — soumettre un projet, rendre des images, livrer les résultats. Le rendu interactif avec retour IPR en direct, c'est le domaine de la workstation, pas de la render farm. Si vous avez besoin de sessions interactives longues dans le cloud, une instance IaaS GPU avec accès bureau à distance est la bonne forme — mais c'est du cloud computing rendering, pas du cloud-based rendering. Les deux modèles résolvent vraiment des problèmes différents.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



