
Automatización de carga en render farm con Python: guía de paramiko y rsync
Resumen
La parte más lenta de un render en la nube no siempre es el propio render. Para un estudio que envía un plano VFX multicámara o una caché de Houdini de 400 GB a una render farm cada noche, el cuello de botella es mover los datos: subir el proyecto de forma fiable y descargar los fotogramas terminados antes de que llegue alguien por la mañana. Hacer eso a mano, mirando una barra de progreso a medianoche, no es escalable. Automatizarlo, sí.
Esta guía trata sobre cómo automatizar esa capa de transferencia en Python. Ofrecemos Super Renders Farm, una render farm completamente gestionada, y "completamente gestionada" tiene un significado preciso en el contexto de la automatización: usted no accede de forma remota a las máquinas, no instala software ni gestiona licencias, por lo que la parte del pipeline que puede programar es la que le pertenece: los archivos que suben y los renders que bajan. La superficie de transferencia es genuinamente programable mediante SFTP, y Python es una herramienta de primera clase para gestionarla. Nuestra propia documentación de transferencia menciona directamente la librería paramiko de Python como cliente compatible, junto con rsync sobre SSH y el comando estándar sftp de línea de comandos.
Seremos igualmente precisos sobre lo que no se puede automatizar desde Python hoy, porque un pipeline construido sobre una funcionalidad inexistente es un pipeline que fallará en su primera ejecución desatendida. Si quiere un mapa conceptual más amplio —qué significa "headless" frente a "desatendido", cómo preparar escenas para el renderizado desde línea de comandos— existe una guía complementaria separada. Esta se mantiene en el nivel del código, centrada en la capa de transferencia: paramiko, rsync, claves SSH, reintentos y un patrón de sincronización nocturna que puede integrar directamente en la automatización de su estudio.
Qué puede automatizar en Python hoy
Conviene trazar los límites antes de escribir cualquier código. En una render farm gestionada, parte del pipeline es completamente programable, parte está deliberadamente orientada a la interfaz gráfica y una parte queda en un punto intermedio. Ser honesto sobre cuál es cuál evita que su automatización falle silenciosamente.
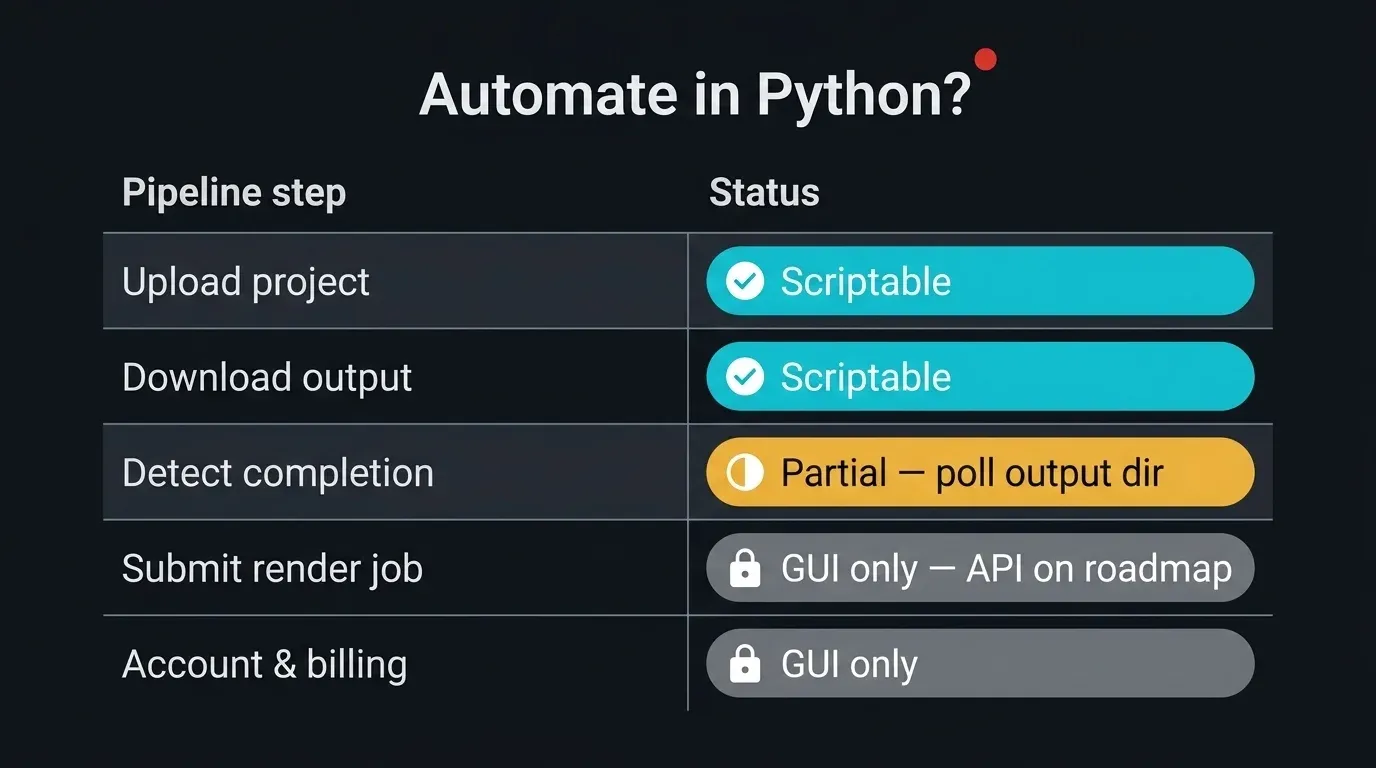
Diagrama en forma de matriz que muestra qué pasos del pipeline de una render farm gestionada en la nube pueden automatizarse en Python: cargar el proyecto (completamente programable mediante paramiko, rsync, sftp), descargar la salida (completamente programable), detectar la finalización del trabajo (parcial — monitorizar el directorio de salida SFTP, sin API de estado), enviar el trabajo de render (solo GUI — formulario web, Client App o plugin DCC), gestionar la cuenta y la facturación (solo GUI), con columnas de estado en verde, ámbar y gris
- Cargar un proyecto — completamente programable. SFTP con
paramiko,rsynco comandossftpprogramados funcionan con nuestro servidor SFTP. Este es el núcleo de lo que sigue. - Descargar fotogramas terminados — completamente programable. La salida aparece en un directorio por trabajo que puede descargar con las mismas herramientas.
- Detectar que un trabajo ha finalizado — parcial. No existe una API de estado pública que pueda consultar. Lo que sí puede hacer es monitorizar el directorio de salida SFTP y observar cómo aparecen los fotogramas y se estabilizan. Es una heurística, no una señal oficial, y la tratamos como tal más adelante.
- Enviar un trabajo de render — solo GUI hoy. El envío se realiza a través del formulario web, la SuperRenders Client App o un plugin de envío por DCC. Una API REST pública para el envío de trabajos, la consulta de estado y la recuperación de resultados está en nuestra hoja de ruta, pero actualmente no hay endpoints públicos disponibles para integraciones directas. Si su pipeline depende específicamente de una API de envío, contacte con el soporte y comparta el caso de uso: la hoja de ruta se nutre de requisitos reales de pipeline.
- Gestionar cuenta, créditos o facturación — solo GUI. Fuera del alcance de la automatización de transferencias.
La superficie automatizable es, por tanto, la transferencia: subir el proyecto, descargar los renders y salvar la diferencia observando el directorio de salida. El paso de envío sigue siendo una entrega deliberada, y lo marcaremos claramente en el pipeline final en lugar de ignorarlo. Para un tratamiento más completo de lo que expone y lo que no expone el renderizado gestionado, nuestra guía sobre qué es una render farm completamente gestionada describe el modelo; las cuentas nuevas pueden comenzar desde la guía de inicio rápido.
Requisitos previos: acceso SFTP, claves SSH y entorno Python
Hay tres cosas que deben estar configuradas antes de la primera carga programada.
Acceso SFTP, habilitado por cuenta. El SFTP se habilita por cuenta a petición. Inicie sesión, busque "Acceso SFTP" en la configuración de su cuenta y genere las credenciales allí; si no está visible, solicite al soporte que lo habilite. Sus credenciales incluyen el nombre de host del servidor (varía según la región y la asignación de almacenamiento, por lo que debe tratarlo como un valor que se lee desde la configuración, nunca codificado de forma fija), un nombre de usuario asociado a su cuenta, una contraseña o clave SSH y el puerto SFTP estándar 22. Hay dos rutas relevantes: /uploads/<su-carpeta-de-proyecto>/ es su área de escritura, y /output/<id-de-trabajo>/ es donde aparecen los renders terminados.
Una clave SSH, no una contraseña. Para cualquier proceso automatizado, la autenticación mediante clave SSH es la elección correcta: mantiene los secretos fuera de sus scripts y funciona en ejecuciones desatendidas sin solicitar entrada interactiva. Genere un par de claves moderno y registre la mitad pública en su cuenta:
ssh-keygen -t ed25519 -C "pipeline@yourstudio.example"
# añada el contenido de ~/.ssh/id_ed25519.pub en
# superrendersfarm.com -> Settings -> SFTP -> SSH Keys
Una nota sobre la seguridad de la cuenta: la autenticación de dos factores no está disponible actualmente en las cuentas, por lo que para SFTP el refuerzo más sólido es una frase de contraseña en el archivo de clave más un agente SSH que la mantenga desbloqueada durante la sesión. La clave, junto con el conocimiento de su frase de contraseña, cumple una función similar a la de un segundo factor: posesión más secreto.
Un entorno Python con paramiko. Todo lo que sigue utiliza paramiko, la implementación SSH/SFTP estándar en Python puro, y llama a rsync para transferencias incrementales de gran tamaño.
python3 -m venv .venv && source .venv/bin/activate
pip install paramiko
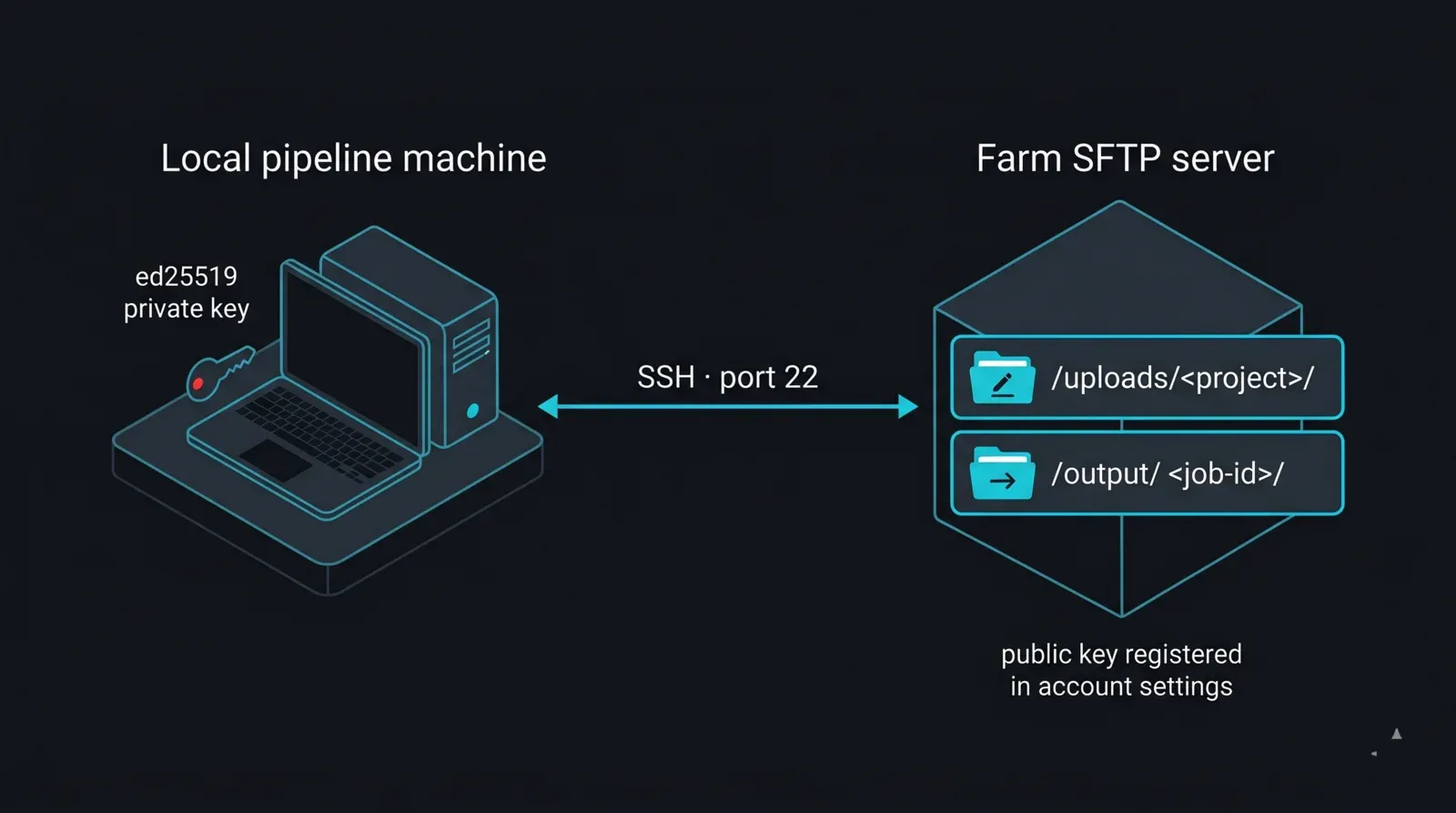
Diagrama del layout de la cuenta SFTP y la autenticación por clave para una render farm gestionada: una máquina de pipeline local con una clave privada ed25519 se conecta por SSH puerto 22 al servidor SFTP de la render farm, que expone dos directorios: /uploads/<proyecto>/ como área de escritura para proyectos entrantes y /output/<id-de-trabajo>/ como área de lectura para los fotogramas terminados; la clave pública correspondiente está registrada en la configuración de la cuenta
Empaquetar un proyecto para que sobreviva a una carga desatendida
La mayoría de los trabajos de render fallidos no son errores del motor: son problemas de empaquetado. Una escena que se renderiza en la estación de trabajo del artista falla en un nodo nuevo porque una ruta de textura apunta a una unidad solo local, o una sub-escena referenciada nunca se incluyó en el paquete. La automatización amplifica esto: una carga desatendida de un paquete defectuoso produce un fallo desatendido. Dos reglas mantienen los paquetes limpios.
Primero, haga que el proyecto sea autónomo con rutas relativas. Ejecute el comando de recopilación y empaquetado de su DCC (Archivar, Recopilar archivos, Guardar proyecto con recursos) para que cada textura, proxy y caché se resuelva en relación con la raíz del proyecto. Segundo, tenga en cuenta el formato de archivo si comprime antes de cargar: admitimos tar, tar.gz y 7z, pero no .zip — vuelva a empaquetar como .tar.gz u omita el archivado por completo y deje que rsync transfiera el árbol de carpetas, que generalmente es la mejor opción para proyectos en curso de todas formas. Como límite práctico, mantenga una sola carga por debajo de los ~300 GB; por encima de eso, use rsync con reanudación en lugar de una transferencia monolítica.
Cargar un proyecto con paramiko
El primer bloque de construcción es un cargador recursivo. Se conecta con una clave, recorre el árbol de proyectos local, recrea la estructura de directorios en /uploads/ y sube cada archivo. Fijamos las claves de host con RejectPolicy y leemos los detalles de conexión desde las variables de entorno para que no haya datos sensibles en el script.
import os
import paramiko
def connect():
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
key_path = os.environ["SRF_SFTP_KEY"] # ruta a la clave privada
client = paramiko.SSHClient()
client.load_system_host_keys() # confiar solo en ~/.ssh/known_hosts
client.set_missing_host_key_policy(paramiko.RejectPolicy())
client.connect(hostname=host, port=22, username=user, key_filename=key_path)
return client, client.open_sftp()
def _ensure_remote_dir(sftp, remote_dir):
# mkdir -p sobre SFTP: construir la ruta segmento a segmento
path = ""
for segment in remote_dir.strip("/").split("/"):
path += "/" + segment
try:
sftp.stat(path)
except IOError:
sftp.mkdir(path)
def upload_dir(sftp, local_dir, remote_dir):
for root, _dirs, files in os.walk(local_dir):
rel = os.path.relpath(root, local_dir)
remote_root = remote_dir if rel == "." else f"{remote_dir}/{rel.replace(os.sep, '/')}"
_ensure_remote_dir(sftp, remote_root)
for name in files:
local_path = os.path.join(root, name)
remote_path = f"{remote_root}/{name}"
sftp.put(local_path, remote_path)
print(f"uploaded {remote_path}")
Uso para un proyecto:
client, sftp = connect()
try:
upload_dir(sftp, "/local/projects/archviz-tower", "/uploads/archviz-tower-2026-06")
finally:
sftp.close()
client.close()
Esto es suficiente para proyectos pequeños y medianos. sftp.put también acepta un argumento callback= que recibe los bytes transferidos y el total, que puede conectar a un medidor de progreso o a una línea de log por archivo. Para las transferencias grandes y repetidas que caracterizan el trabajo de un estudio, rsync es la herramienta más adecuada.
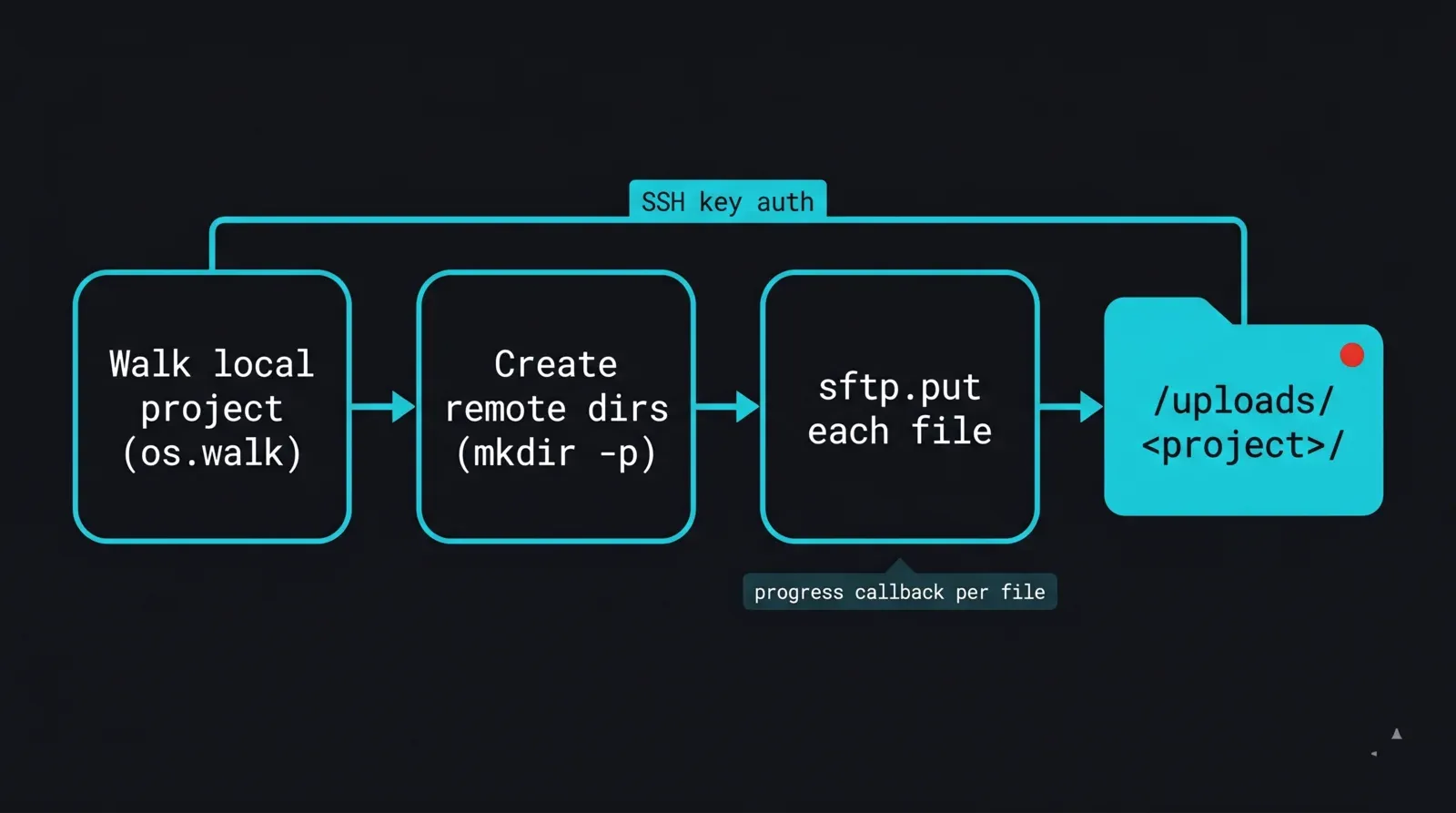
Diagrama de flujo de una rutina de carga con paramiko para una render farm: se recorre una carpeta de proyecto local archivo por archivo con os.walk, se crea el árbol de directorios remoto en /uploads con un bucle mkdir-p y luego se envía cada archivo con sftp.put a través de una conexión autenticada por clave SSH, con un callback de progreso que registra cada archivo completado
Sincronización incremental con rsync sobre SSH
Un proyecto de render rara vez se carga una sola vez. Se ajusta un shader, se vuelve a calcular una simulación, se corrige una luz y se vuelve a cargar. Enviar toda la carpeta cada vez desperdicia horas; rsync envía solo lo que ha cambiado. Para un estudio que carga todas las noches, este es el mayor ahorro de tiempo en la capa de transferencia, ya que transfiere solo el delta en lugar del proyecto completo.
La invocación canónica:
rsync -avz --partial --progress \
/local/projects/archviz-tower/ \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/uploads/archviz-tower-2026-06/"
-a preserva la estructura y las marcas de tiempo, -z comprime durante la transferencia, --partial conserva los archivos transferidos parcialmente para que una conexión interrumpida se reanude en lugar de reiniciarse, y --progress informa por archivo. Volver a ejecutar el mismo comando después de un cambio transfiere solo los archivos modificados. Como el objetivo es la automatización, envuélvalo en Python para que viva en el mismo script que todo lo demás y pueda reaccionar a su código de salida:
import subprocess
def rsync_up(local_dir, remote_subdir):
host = os.environ["SRF_SFTP_HOST"]
user = os.environ["SRF_SFTP_USER"]
dest = f"{user}@{host}:/uploads/{remote_subdir}/"
cmd = ["rsync", "-avz", "--partial", "--progress",
f"{local_dir.rstrip('/')}/", dest]
subprocess.run(cmd, check=True) # lanza CalledProcessError en caso de fallo
Para ejecutarlo de forma desatendida, prográmelo. Un estudio que sincroniza un directorio de trabajo con la render farm todas las noches a la 1 a.m. necesita una sola línea de cron:
0 1 * * * cd /studio/pipeline && /usr/bin/python3 nightly_sync.py >> sync.log 2>&1
Para que rsync sobre SSH autentique sin solicitar entrada, apúntelo a su clave con -e "ssh -i ~/.ssh/id_ed25519", o deje que un agente SSH mantenga la clave desbloqueada durante la sesión.
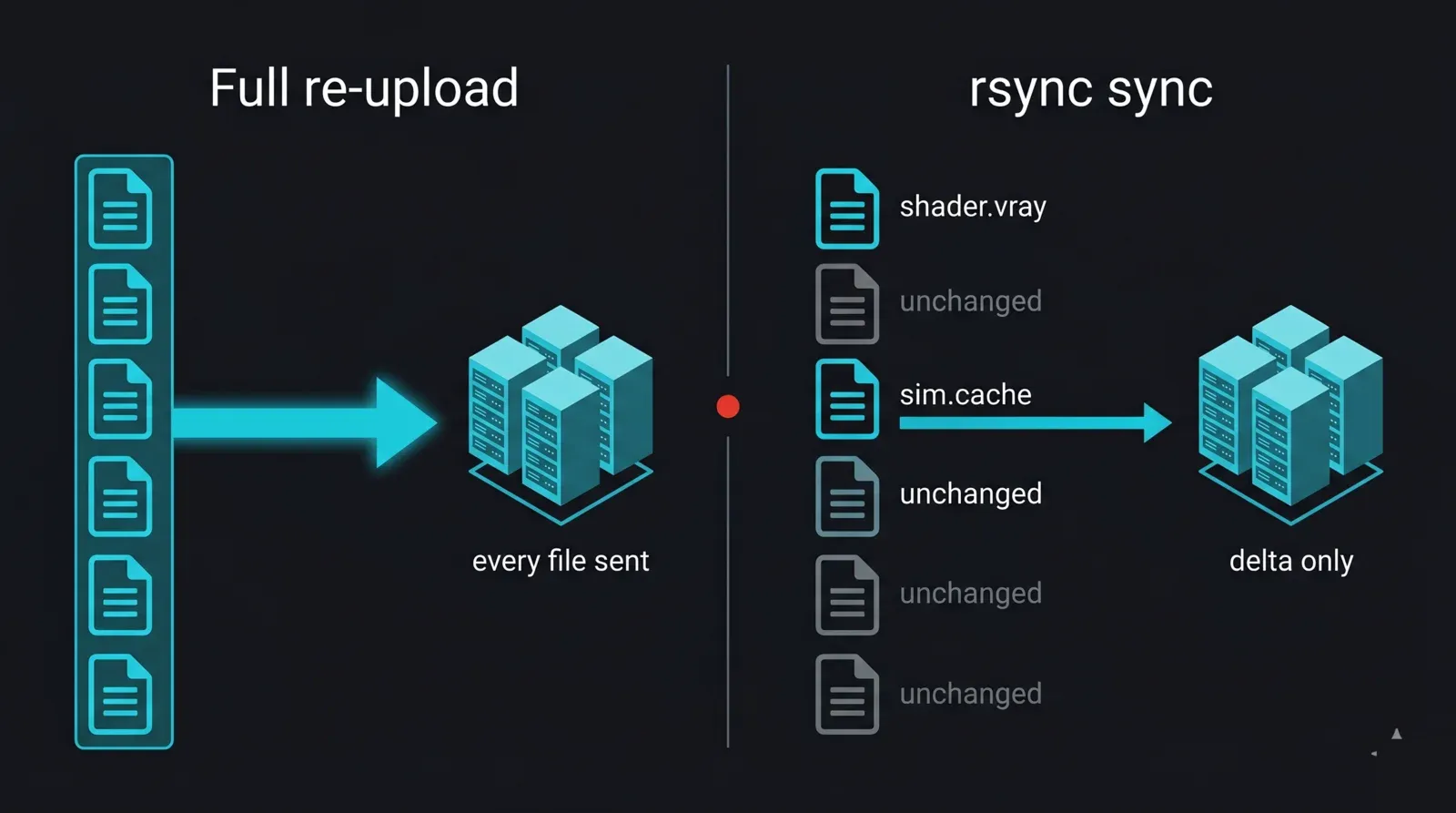
Diagrama de comparación entre una recarga completa y una sincronización incremental con rsync en una render farm: a la izquierda, cada archivo del proyecto se reenvía cada noche; a la derecha, rsync compara el estado local y remoto y transfiere solo los archivos modificados (un shader modificado y una nueva caché), omitiendo el grueso sin cambios, lo que ilustra la transferencia de solo el delta que hace que las cargas nocturnas de un estudio sean rápidas
Descargar fotogramas terminados automáticamente
Cuando un trabajo se completa, los fotogramas de salida se escriben en /output/<id-de-trabajo>/ en el servidor SFTP. El lado de la descarga es simétrico al de la carga: un get recursivo con paramiko, o un pull de rsync. La versión con paramiko recorre el directorio remoto y lo recrea localmente:
import stat
def download_dir(sftp, remote_dir, local_dir):
os.makedirs(local_dir, exist_ok=True)
for entry in sftp.listdir_attr(remote_dir):
remote_path = f"{remote_dir}/{entry.filename}"
local_path = os.path.join(local_dir, entry.filename)
if stat.S_ISDIR(entry.st_mode):
download_dir(sftp, remote_path, local_path)
else:
sftp.get(remote_path, local_path)
print(f"downloaded {local_path}")
Para conjuntos de salida grandes, el pull con rsync es de nuevo la opción más eficiente y reanudable:
rsync -avz --progress \
"$SRF_SFTP_USER@$SRF_SFTP_HOST:/output/<job-id>/" \
/local/downloads/<job-id>/
Un detalle operativo importante para los pipelines desatendidos: la salida renderizada se conserva durante 45 días tras la finalización del trabajo y luego se elimina automáticamente. SFTP no extiende ese período. El patrón seguro es una sincronización nocturna que copie la salida al archivo local en cuanto aparezca, para que la retención nunca sea el motivo de perder sus fotogramas.
Detectar la finalización del trabajo sin una API de estado
Aquí es donde el límite honesto se convierte en una decisión de ingeniería concreta. No existe un endpoint público para preguntar "¿ha terminado el trabajo 12345?" — pero el directorio de salida en sí es observable sobre SFTP. El patrón pragmático es monitorizar /output/<id-de-trabajo>/, contar los archivos y esperar a que el recuento llegue al total de fotogramas esperado y se mantenga estable en comprobaciones consecutivas (para no empezar a descargar a mitad de escritura).
import time
def wait_for_output(sftp, output_dir, expected_frames, poll=120, stable_checks=2):
last_count, stable = -1, 0
while True:
try:
files = sftp.listdir(output_dir)
except IOError:
files = [] # carpeta no creada aún -> no iniciado
count = len(files)
if count >= expected_frames and count == last_count:
stable += 1
if stable >= stable_checks:
return files # recuento alcanzado y estable -> tratar como terminado
else:
stable = 0
last_count = count
time.sleep(poll)
Tenga claro qué es esto. Los fotogramas aparecen de forma incremental, por lo que la simple presencia no indica finalización; comprobar el recuento frente al total esperado y confirmar que es estable entre comprobaciones es lo que lo hace suficientemente fiable para la automatización. Es una heurística de directorio, no un contrato. Cuando la API pública esté disponible, toda esta función se reducirá a una llamada de estado; hasta entonces, observar el directorio de salida es la forma fundamentada de salvar la distancia, y depende solo de capacidades que ya existen.
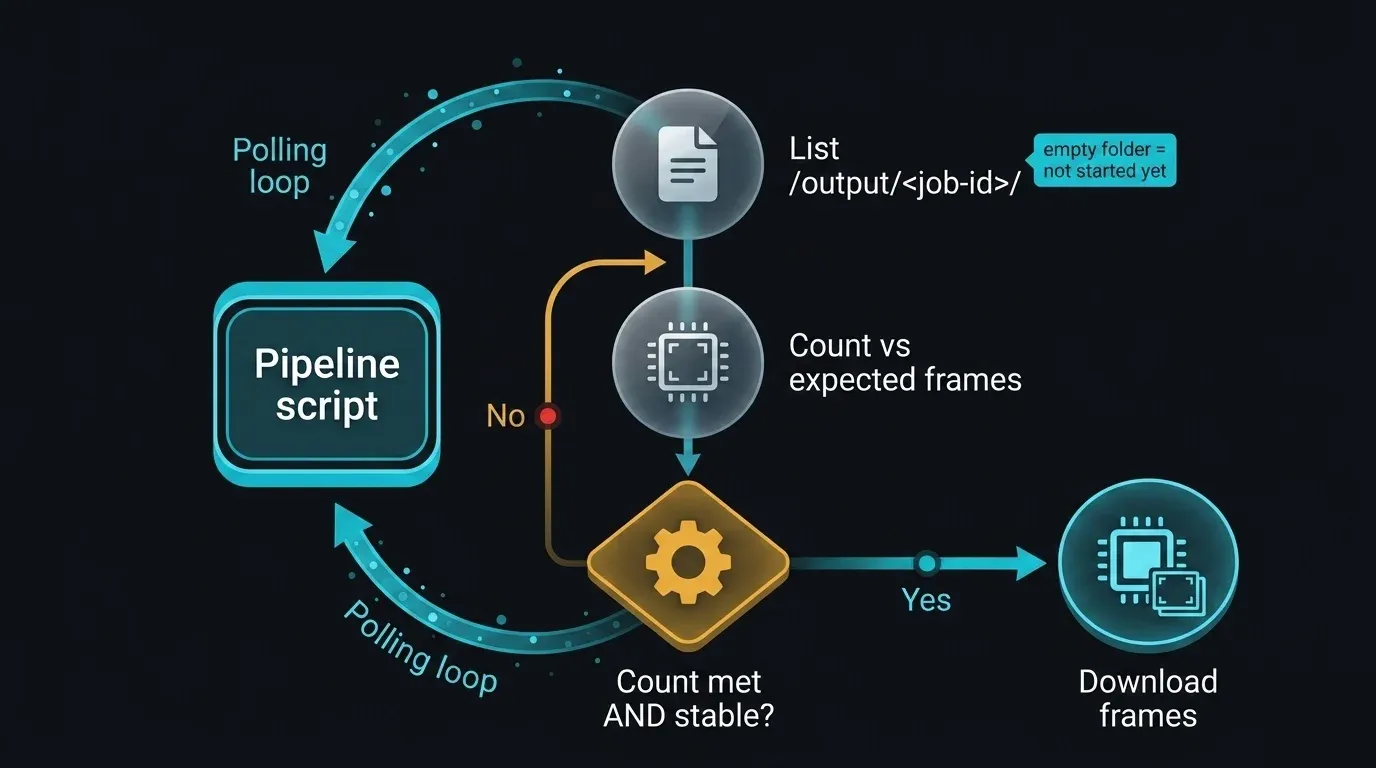
Diagrama de secuencia que muestra cómo monitorizar el directorio de salida SFTP para detectar la finalización del render sin una API de estado: un script de pipeline lista repetidamente /output/<id-de-trabajo>/, compara el recuento de fotogramas con el total esperado, espera hasta que el recuento alcanza el objetivo y se mantiene estable en dos comprobaciones consecutivas, y luego procede a la descarga — con un estado inicial de carpeta vacía que indica que el trabajo aún no ha comenzado
Uniendo todo: un pipeline de transferencia desatendido
Las piezas se combinan en un único script nocturno. La estructura es: sincronizar el proyecto, hacer la entrega al envío, esperar a que aparezca y se estabilice la salida, descargarla, verificarla y archivarla. El paso de envío es la entrega deliberada a la interfaz gráfica: en una render farm gestionada, usted envía a través del formulario web, la Client App o un plugin de envío por DCC, y los plugins por DCC pueden ser controlados desde el entorno de scripting de la propia aplicación (MAXScript, Python dentro del DCC) cuando el envío se encuentra dentro de una herramienta que ya programa. Marcamos ese paso honestamente en lugar de envolverlo en una función que finge que existe una API.
def nightly_pipeline(project_dir, remote_subdir, job_id, expected_frames):
client, sftp = connect()
try:
# with_retries() (definido en la siguiente sección) envuelve las llamadas de red más frágiles
with_retries(lambda: rsync_up(project_dir, remote_subdir)) # 1. subir delta
# 2. ENVIAR: GUI / Client App / plugin DCC -- no es una API pública (aún)
files = wait_for_output( # 3. observar directorio de salida
sftp, f"/output/{job_id}", expected_frames)
with_retries(lambda: # 4. descargar fotogramas terminados
download_dir(sftp, f"/output/{job_id}", f"/local/downloads/{job_id}"))
print(f"job {job_id}: {len(files)} frames retrieved")
finally:
sftp.close()
client.close()
Los pasos 1, 3 y 4 están completamente automatizados; el paso 2 es la entrega manual. Cuando llegue una API de envío pública, los pasos 2 y 3 se convertirán en llamadas a la API y el sondeo del directorio quedará obsoleto. La arquitectura no cambia: solo los tramos de envío y estado pasan de la interfaz gráfica y la heurística a endpoints.
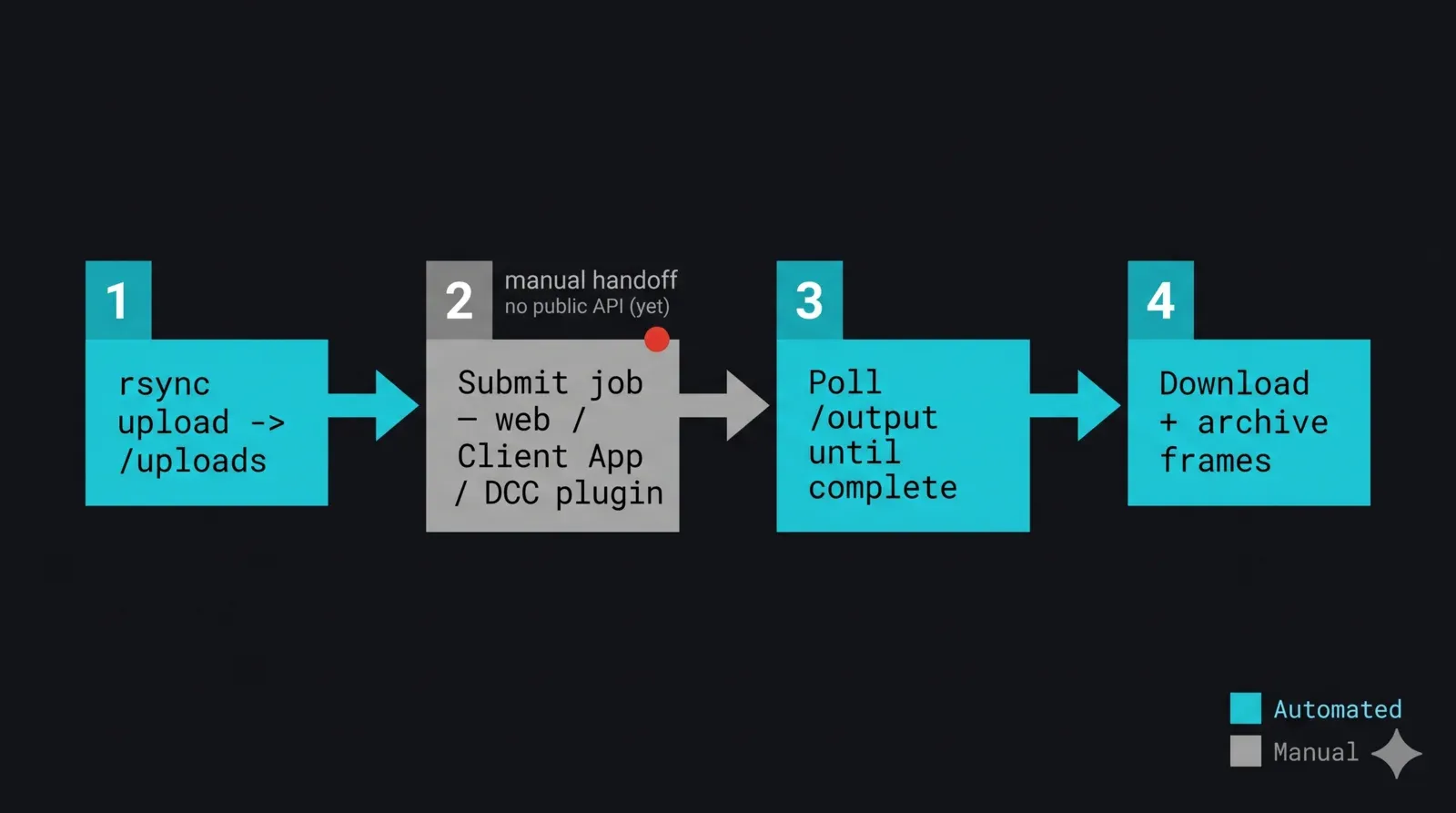
Diagrama de flujo de extremo a extremo de un pipeline de transferencia de render farm desatendido controlado desde Python: el paso 1 rsync carga el delta del proyecto en /uploads, el paso 2 es una entrega marcada claramente a la GUI donde el trabajo se envía mediante formulario web, Client App o plugin DCC (sin API pública), el paso 3 monitoriza /output/<id-de-trabajo> hasta que los fotogramas estén completos y estables, el paso 4 descarga y archiva los fotogramas terminados localmente — con los pasos automatizados en cian y el paso de envío manual en gris
Gestión de errores, reintentos y transferencias reanudables
Desatendido significa que nadie está mirando cuando una transferencia falla, por lo que el script tiene que recuperarse por sí mismo. Tres hábitos cubren la mayoría de los fallos.
Reintentar fallos transitorios con retroceso. Las interrupciones de red y las desconexiones breves son normales en transferencias largas. Envuelva las llamadas más frágiles —como hace nightly_pipeline arriba— para que una sola caída no detenga toda la ejecución. Capture los errores transitorios específicos en lugar de capturarlo todo: SSHException de paramiko, la familia OSError para sockets y CalledProcessError para un rsync fallido.
def with_retries(fn, attempts=3, backoff=5):
transient = (paramiko.SSHException, OSError, subprocess.CalledProcessError)
for i in range(1, attempts + 1):
try:
return fn()
except transient: # reintentar interrupciones SSH / red / rsync
if i == attempts:
raise
time.sleep(backoff * i) # retroceso: 5s, 10s, 15s
Aproveche la reanudabilidad. rsync --partial ya reanuda los archivos interrumpidos, y volver a ejecutar un rsync es idempotente: solo envía lo que falta, por lo que un reintento de sincronización es económico, no un reinicio. Para las transferencias con paramiko, un reintento más un nuevo recorrido logra el mismo efecto porque los archivos ya presentes se transfieren casi de forma instantánea.
Gestione explícitamente los errores de clave de host y conectividad. Un error de "verificación de clave de host fallida" significa que la clave almacenada en ~/.ssh/known_hosts ya no coincide con la del servidor, lo que ocurre con mayor frecuencia después de una rara rotación de clave de host. Elimine la línea obsoleta que indica el error y vuelva a conectarse para aceptar la nueva clave. "Conexión rechazada" o tiempo de espera agotado suele significar que el cortafuegos del estudio está bloqueando el TCP 22 saliente; permítalo o consulte al soporte sobre alternativas. Y si el rendimiento está muy por debajo de la velocidad de su enlace, la sobrecarga por paquete de SFTP es la causa en enlaces de larga distancia: lftp con segmentos paralelos, o varias sesiones SFTP concurrentes, recupera la mayor parte de la diferencia.
Resumen: qué automatizar y cómo
La capa de transferencia es la parte del pipeline de una render farm gestionada que usted controla en código, y Python cubre todo.
| Tarea | ¿Automatizable en Python? | Herramienta | Notas |
|---|---|---|---|
| Cargar un proyecto | Sí | paramiko o rsync | rsync para proyectos grandes/repetidos; --partial para reanudar |
| Recarga incremental | Sí | rsync sobre SSH | Transfiere solo los archivos modificados |
| Descargar fotogramas terminados | Sí | get de paramiko / pull de rsync | Sincronizar noche a noche — retención de 45 días |
| Detectar finalización | Parcial | Monitorizar /output/<id-de-trabajo>/ | Heurística de recuento + estabilidad, sin API de estado |
| Enviar un trabajo de render | No (hoy) | Web / Client App / plugin DCC | API pública en la hoja de ruta |
| Autenticar | Sí | Clave SSH (ed25519) | Clave + frase de contraseña; sin secretos codificados de forma fija |
Automatice la carga, automatice la descarga, salve el intermedio observando el directorio de salida y mantenga la entrega del envío explícita. Eso le da un pipeline nocturno que es honesto sobre sus costuras y fiable precisamente por ello. Para proyectos con simulaciones intensivas donde la fiabilidad de la transferencia importa más —cachés de Houdini de varios terabytes y similares— los mismos patrones escalan directamente en Super Renders Farm; nuestra página de Houdini cloud render farm cubre esa carga de trabajo.
FAQ
Q: ¿Qué librería de Python debo usar para cargar archivos en la render farm?
A: paramiko es la opción estándar y se menciona directamente en nuestra documentación SFTP como cliente compatible. Es Python puro, gestiona SFTP de forma limpia y funciona bien tanto para la lógica de carga como de descarga. Para transferencias muy grandes o que se repiten con frecuencia, llame a rsync sobre SSH desde Python con subprocess: solo envía los archivos modificados y reanuda los interrumpidos, algo que paramiko no hace de forma nativa.
Q: ¿Existe una API pública para enviar trabajos de render desde mi pipeline en Python? A: Todavía no. Una API REST pública para el envío, la consulta de estado y la recuperación de resultados está en nuestra hoja de ruta, pero actualmente no hay endpoints públicos disponibles. Las vías de envío programático actuales son la SuperRenders Client App y el plugin de envío por DCC, que se integra con el entorno de scripting de la propia aplicación, como MAXScript o Python dentro del DCC. Si su pipeline depende específicamente de una API de envío pública, contacte con el soporte y comparta el caso de uso: la hoja de ruta se nutre de requisitos reales de pipeline.
Q: ¿Cómo puedo detectar que un trabajo de render ha terminado si no hay API de estado?
A: Monitorice el directorio de salida SFTP del trabajo, /output/<id-de-trabajo>/, y observe el recuento de fotogramas. Trate el trabajo como completo solo cuando el recuento alcance el total esperado y se mantenga estable en comprobaciones consecutivas, para no empezar a descargar mientras aún se están escribiendo fotogramas. Es una heurística de directorio más que una señal de estado oficial, pero depende solo de capacidades que ya existen.
Q: ¿Debo usar claves SSH o contraseña para las transferencias automatizadas? A: Use una clave SSH. Codificar una contraseña de forma fija en un script es un riesgo de seguridad, y la autenticación por clave funciona de forma desatendida sin solicitar entrada interactiva. Genere una clave ed25519, registre la mitad pública en Settings → SFTP → SSH Keys y proteja la clave privada con una frase de contraseña custodiada por un agente SSH. Como la autenticación de dos factores no está disponible actualmente en las cuentas, la clave más su frase de contraseña es el refuerzo práctico más sólido para el acceso SFTP.
Q: ¿Puedo cargar un archivo .zip desde mi script?
A: No; los archivos .zip no están admitidos. Vuelva a empaquetar como .tar.gz (o .tar / .7z), u omita el archivado y deje que rsync transfiera el árbol de carpetas directamente, que generalmente es la mejor opción para proyectos que cambian entre cargas. Mantenga una sola carga por debajo de los 300 GB aproximadamente y use rsync --partial para cualquier proyecto mayor, de modo que una conexión interrumpida se reanude en lugar de reiniciarse.
Q: ¿Qué tamaño de proyecto puedo mover de esta forma?
A: Las transferencias de varios terabytes están admitidas sobre SFTP; el límite práctico es su propio ancho de banda de subida, no un límite impuesto por la render farm. Una carga de 1 TB a 100 Mbps tarda aproximadamente un día, así que planifique en función de su enlace. Para maximizar el rendimiento en conexiones de gran capacidad o larga distancia, use lftp con segmentos paralelos o varias sesiones SFTP concurrentes, ya que un único flujo SFTP está limitado por la sobrecarga por paquete.
Q: ¿Cuánto tiempo están disponibles para su descarga los fotogramas renderizados?
A: La salida se conserva durante 45 días tras la finalización de un trabajo y luego se elimina automáticamente; SFTP no extiende ese período. Para un pipeline desatendido, copie la salida al archivo local en cuanto aparezca: un pull nocturno de rsync de /output/<id-de-trabajo>/ evita que la retención sea nunca el motivo por el que se pierde un fotograma.
Q: ¿En qué se diferencia esto de su guía de flujo de trabajo headless y desatendido?
A: Esa guía es el mapa conceptual: qué significa el renderizado headless, cómo preparar escenas para el renderizado desde línea de comandos y cómo encaja el bucle desatendido en una render farm gestionada. Esta es la guía complementaria a nivel de código centrada en la capa de transferencia: el paramiko y el rsync concretos que se escriben para mover proyectos hacia arriba y fotogramas hacia abajo. Lea la guía de flujo de trabajo para la estructura; use esta para la implementación.
About Alice Harper
Blender and V-Ray specialist. Passionate about optimizing render workflows, sharing tips, and educating the 3D community to achieve photorealistic results faster.



