
Wie Renderfarms funktionieren: Ein technischer Leitfaden für 3D-Künstler
Überblick
Einleitung
Renderfarms existieren, weil einzelne Workstations an harte Grenzen stoßen. Eine 500-Frame-Animation mit 20 Minuten pro Frame braucht auf einem Rechner fast eine Woche. Verteile diese Frames auf 100 Maschinen, und derselbe Job ist in unter zwei Stunden fertig. Die Rechnung ist einfach — die Technik dahinter nicht.
Wir betreiben eine Renderfarm mit über 20.000 CPU-Kernen und einer dedizierten GPU-Flotte mit NVIDIA RTX 5090 Karten. Jeden Tag verarbeiten wir Hunderte von Jobs mit V-Ray, Corona, Arnold, Redshift, Cycles und anderen Render-Engines. Dieser Leitfaden erklärt, was tatsächlich zwischen dem Moment passiert, in dem du eine Szene hochlädst, und dem Moment, in dem du fertige Frames herunterlädst — die Warteschlangen-Systeme, die Dateiverteilung, die Fehlerbehandlung und die Infrastruktur-Entscheidungen, die verteiltes Rendering im großen Maßstab zuverlässig machen.
Wenn du ganz neu beim Thema Renderfarms bist, erklärt unser Leitfaden zu Renderfarms die Grundlagen. Dieser Artikel geht tiefer in die technischen Abläufe.
Was passiert, wenn du einen Renderjob einreichst
Der Einreichungsprozess umfasst mehr Schritte, als die meisten Künstler vermuten. Hier ist die Abfolge, von deiner Workstation bis zum ersten gerenderten Pixel.
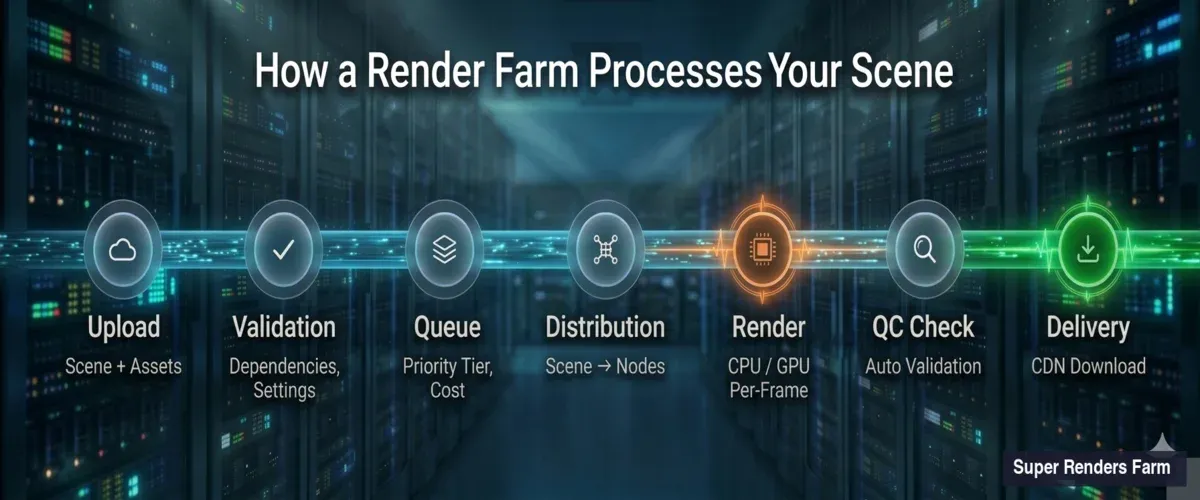
Renderfarm-Pipeline mit 7 Phasen von Szenen-Upload über Validierung, Queuing, Verteilung, Rendering, Qualitätsprüfung bis zur finalen Lieferung
Szenen-Upload und Analyse. Wenn du eine .max-, .blend-, .ma- oder andere Szenedatei einreichst, entpackt das Ingestion-System der Farm diese und katalogisiert jede Abhängigkeit — Texturen, Caches, Proxy-Meshes, HDRI-Maps, Plugin-Assets. Fehlende Abhängigkeiten sind die häufigste Ursache für fehlgeschlagene Renders. Unser System kennzeichnet fehlende Dateien, bevor dein Job in die Warteschlange kommt, sodass du Pfade korrigieren kannst, anstatt Renderzeit mit schwarzen Frames zu verschwenden.
Validierung der Render-Einstellungen. Die Farm liest deine eingebetteten Render-Einstellungen: Engine-Typ, Version, Auflösung, Frame-Bereich, Ausgabeformat, Sampling-Parameter. Diese werden mit den verfügbaren Node-Konfigurationen abgeglichen. Wenn du V-Ray 7 angegeben hast, die Szene aber im V-Ray 6-Format gespeichert wurde, erkennt das System diese Diskrepanz, bevor das Rendering beginnt.
Kostenschätzung. Basierend auf Szenenkomplexität, Auflösung, Sample-Anzahl und historischen Daten ähnlicher Jobs erstellt das System eine Zeit- und Kostenschätzung. Das ist kein Raten — wir haben genug Jobs verarbeitet, um statistische Modelle aufzubauen, die die Renderzeit für die meisten Standardszenen mit vernünftiger Genauigkeit vorhersagen.
Job-Queuing und Prioritätssysteme
Sobald dein Job validiert ist, kommt er in eine Warteschlange. Wie Renderfarms diese Warteschlange verwalten, entscheidet darüber, ob du deine Frames in zwei oder zwölf Stunden bekommst.
Prioritätsstufen. Die meisten Farms bieten mehrere Prioritätsstufen an. Jobs mit höherer Priorität erhalten Zugang zu mehr Nodes gleichzeitig und können Aufgaben mit niedrigerer Priorität verdrängen. Auf unserer Farm ist der Unterschied zwischen Standard- und Hochpriorität erheblich — ein 200-Frame-Job könnte bei Standardpriorität auf 20 Nodes rendern, bei Hochpriorität auf 80 Nodes.
Faires Scheduling. Der Warteschlangenmanager verteilt die Ressourcen gleichmäßig auf alle aktiven Nutzer. Kein einzelner Job monopolisiert die gesamte Farm, auch nicht bei hoher Priorität. Wenn die Farm 400 verfügbare CPU-Nodes hat und drei Hochprioritäts-Jobs gleichzeitig laufen, verteilt der Scheduler die Nodes proportional nach Jobgröße, geschätzter Fertigstellungszeit und Nutzer-Stufe.
Preemption und Requeuing. Wenn ein Hochprioritäts-Job eintrifft und die Farm ausgelastet ist, kann der Scheduler Frames von Jobs niedrigerer Priorität pausieren und deren Nodes neu zuweisen. Pausierte Frames kommen automatisch zurück in die Warteschlange — es geht keine Arbeit verloren, auch wenn Jobs niedrigerer Priorität länger brauchen.
Erkennung ausgefallener Nodes. Wenn ein Rendernode nicht mehr antwortet (Hardware-Ausfall, Treiber-Absturz, Netzwerk-Timeout), erkennt der Warteschlangenmanager die fehlende Antwort innerhalb von Sekunden und weist die laufenden Frames dieses Nodes einem intakten Node zu. Das geschieht transparent — du siehst den Ausfall nicht in deiner Ausgabe.
Szenenverteilung: Wie Dateien zu den Rendernodes gelangen
Bevor ein Node Frame 47 deiner Animation rendern kann, braucht er deine komplette Szene — Geometrie, Texturen, Caches und Konfiguration. Diese Daten effizient zu transportieren, ist eine zentrale Infrastruktur-Herausforderung.
Netzwerk-Dateisysteme. Die meisten professionellen Renderfarms nutzen Hochgeschwindigkeits-Shared-Storage (NFS, SMB oder proprietäre verteilte Dateisysteme), anstatt Szenedateien einzeln auf jeden Node zu kopieren. Die Szene liegt auf einem zentralen Speicher-Cluster, und Rendernodes greifen über das Netzwerk darauf zu. Das vermeidet den Engpass, eine 50 GB große Szene sequenziell auf 100 Nodes zu kopieren.
Caching und Lokalität. Intelligente Farms cachen häufig genutzte Assets lokal auf den Rendernodes. Wenn drei Jobs heute dasselbe HDRI-Paket oder dieselbe V-Ray-Materialbibliothek verwenden, überspringen Nodes, die diese Dateien bereits gecacht haben, den Netzwerktransfer. Das reduziert die Startzeit pro Frame von Minuten auf Sekunden bei wiederholten Texturen.
Texture Streaming. Bei Szenen mit massiven Textur-Sets (verbreitet in der Architekturvisualisierung mit 4K+ Materialbibliotheken) streamen manche Farm-Konfigurationen Texturen bei Bedarf, anstatt alles vorab zu laden. Die Render-Engine fordert eine Texturkachel an, das Speichersystem liefert sie, und der Node cacht sie lokal für nachfolgende Frames. Das tauscht etwas höhere Latenz pro Kachel gegen deutlich geringere initiale Ladezeit.
Die Rendering-Phase: CPU- und GPU-Verarbeitung
Mit geladener Szene und zugewiesenem Frame beginnt das eigentliche Rendering. Wie Farms CPU- und GPU-Ressourcen zuweisen, spiegelt reale Leistungs- und Kosten-Abwägungen wider.

Vergleich CPU-Rendering vs. GPU-Rendering mit Unterschieden bei Geschwindigkeit, Speicher, Anwendungsfällen, unterstützter Software und Hardware-Spezifikationen
CPU-Rendering. CPU-basierte Engines (V-Ray CPU, Corona, Arnold CPU) verteilen die Arbeit auf alle verfügbaren Kerne eines Nodes. Ein typischer Farm-CPU-Node hat 44 oder mehr Kerne mit 96–256 GB RAM. Der große Arbeitsspeicher bedeutet, dass CPU-Nodes Szenen bewältigen, die den VRAM einer GPU sprengen würden — komplexe Architekturvisualisierungs-Innenräume mit Displacement Maps, Partikelsimulationen mit Millionen von Elementen oder volumetrische Effekte mit hochauflösenden Caches.
Auf unserer Farm laufen etwa 70 % der Renderjobs auf CPU-Nodes. Das spiegelt die Architekturvisualisierungs- und VFX-Produktions-Workflows wider, die professionelles Rendering dominieren — diese Szenen sind tendenziell speicherintensiv und nutzen Engines wie V-Ray und Corona, die für Mehrkern-CPU-Leistung optimiert sind.
GPU-Rendering. GPU-basierte Engines (Redshift, Octane, V-Ray GPU, Cycles mit OptiX) nutzen die Tausenden parallelen Kerne moderner Grafikkarten. Unsere GPU-Nodes verwenden NVIDIA RTX 5090 Karten mit 32 GB VRAM. GPU-Rendering ist typischerweise schneller pro Frame bei Szenen, die in den VRAM passen, aber diese Grenzen sind real — eine Szene, die 40 GB an Textur- und Geometriedaten benötigt, kann auf einer 32 GB Karte nicht ohne Out-of-Core-Fallbacks rendern, die die Leistung reduzieren.
Hybride Zuweisung. Manche Jobs profitieren davon, auf CPU- und GPU-Nodes aufgeteilt zu werden. Ein gängiges Muster: GPU-Nodes bearbeiten Beauty-Passes (schnell pro Frame, VRAM-beschränkt), während CPU-Nodes volumetrische oder Partikel-Passes verarbeiten, die die VRAM-Kapazität übersteigen. Der Job-Scheduler der Farm unterstützt diese Aufteilung und leitet verschiedene Render-Layer an die passende Hardware weiter.
Frame-Zusammenstellung und Qualitätsprüfung
Ein Frame zu rendern ist nur die halbe Arbeit. Die Farm muss auch die Ausgabequalität prüfen und Frames zu einem schlüssigen Lieferpaket zusammenstellen.
Automatische Qualitätsprüfungen. Nach dem Rendern jedes Frames führt die Farm eine grundlegende Validierung durch: Dateigröße im erwarteten Bereich (eine 1-Byte-PNG bedeutet, dass der Render still fehlgeschlagen ist), Auflösung entspricht der Spezifikation, keine komplett schwarzen oder weißen Frames (häufige Indikatoren für fehlende Lichter oder Materialien), und das Ausgabeformat ist korrekt. Frames, die diese Prüfungen nicht bestehen, werden automatisch auf einem anderen Node neu gerendert.
Frame-Zusammenfügung bei kachelbasiertem Rendering. Manche Engines und Konfigurationen teilen ein einzelnes hochauflösendes Frame in Kacheln auf — das obere linke Viertel wird auf einem Node gerendert, das obere rechte auf einem anderen, und so weiter. Nachdem alle Kacheln fertig sind, setzt die Farm sie zum finalen Bild in voller Auflösung zusammen. Dieser Ansatz eignet sich gut für extrem hochauflösende Standbilder (8K+), bei denen ein einzelner Node Stunden pro Frame benötigen würde.
Ausgabe-Lieferung. Fertige Frames werden in den Ausgabespeicher der Farm geschrieben und zum Download bereitgestellt. Wir nutzen Cloud-Storage mit CDN-Beschleunigung, um sicherzustellen, dass Download-Geschwindigkeiten nicht durch die Upload-Bandbreite der Farm begrenzt werden. Für große Animationssequenzen (Tausende EXR-Dateien) bieten wir Massen-Download-Optionen und können Sequenzen für schnelleren Transfer komprimieren.
Netzwerkarchitektur einer Renderfarm
Die Infrastruktur, die Rendernodes, Speicher und Management-Systeme verbindet, ist genauso wichtig wie die Hardware selbst.
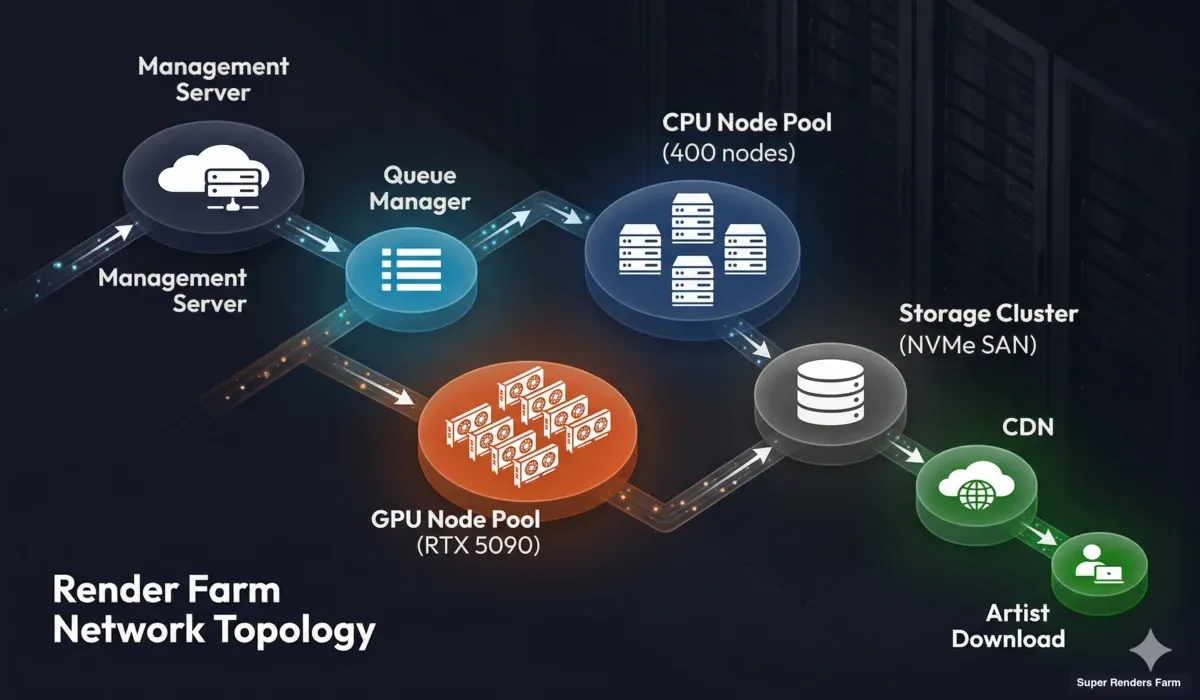
Renderfarm-Netzwerktopologie mit Management-Server, Warteschlangenmanager, CPU- und GPU-Rendernode-Pools, Speicher-Cluster und CDN-Lieferung an Nutzer
Management-Schicht. Ein zentraler Management-Server orchestriert alles — Job-Ingestion, Warteschlangenverwaltung, Node-Gesundheitsüberwachung und Nutzerkommunikation. Dieser Server ist redundant ausgelegt (Failover-fähig), denn wenn er ausfällt, hört die gesamte Farm auf, Jobs anzunehmen und zu verarbeiten.
Rendernode-Netzwerk. Nodes kommunizieren mit Management und Speicher über ein internes Hochbandbreiten-Netzwerk. Bei modernen Farms sind das typischerweise 10 Gbps Ethernet oder schneller. Bandbreite ist am wichtigsten bei der Szenenverteilung (Laden von Texturen) und der Frame-Ausgabe (Schreiben hochauflösender EXR-Dateien in den Speicher).
Speicher-Cluster. Der zentrale Speicher ist die gemeinsame Ressource, von der jeder Rendernode liest und auf die er schreibt. Er muss gleichzeitige Lesezugriffe von Hunderten Nodes, die Texturkacheln anfordern, und gleichzeitige Schreibzugriffe von Nodes, die gerenderte Frames ausgeben, bewältigen. Hochleistungs-Speicher-Arrays (NVMe-basierte SANs oder verteilte Dateisysteme) sind unerlässlich. Ein langsames Speichersystem erzeugt einen Engpass, den keine noch so große CPU- oder GPU-Leistung überwinden kann.
Internetanbindung. Die Verbindung der Farm zur Außenwelt bestimmt, wie schnell Nutzer Szenen hochladen und Ergebnisse herunterladen können. Redundante Multi-Gigabit-Anbindungen sind Standard für professionelle Farms. Auch die geografische Nähe zu großen Nutzergruppen spielt eine Rolle — eine Farm in den USA, die einen europäischen Kunden bedient, hat höhere Latenz als eine mit europäischem Zugangspunkt.
Monitoring und Fehlerbehebung
Im großen Maßstab kommt es ständig zu Ausfällen. Eine Farm mit Hunderten von Nodes rechnet mit täglichen Hardware-Zwischenfällen. Der Unterschied zwischen einer zuverlässigen und einer unzuverlässigen Farm liegt darin, wie Fehler erkannt und behandelt werden.
Node-Gesundheitsüberwachung. Jeder Rendernode meldet seinen Status (CPU-Temperatur, Speicherauslastung, GPU-Auslastung, Festplattenplatz, Netzwerkdurchsatz) in regelmäßigen Abständen an das Management-System. Nodes, die keine Statusmeldung senden, werden sofort gekennzeichnet. Nodes mit abnormalen Mustern (steigende Temperatur, sinkender Durchsatz) werden präventiv aus dem Pool entfernt, bevor sie mitten im Render ausfallen.
Frame-basierte Wiederherstellung. Wenn ein Node während des Renderings abstürzt, wird der Frame, den er gerade bearbeitet hat, als fehlgeschlagen markiert und einem intakten Node zugewiesen. Die Farm verfolgt, welche Frames erfolgreich abgeschlossen, welche in Bearbeitung und welche fehlgeschlagen sind. Diese Zustandsverfolgung stellt sicher, dass kein Frame verloren geht oder dupliziert wird, selbst bei kaskadierenden Node-Ausfällen.
Behandlung von Render-Engine-Abstürzen. Neben Hardware-Ausfällen können auch Render-Engines selbst abstürzen — Speicherüberläufe, beschädigte Szenenelemente oder Engine-Bugs. Die Farm unterscheidet zwischen behebbaren Abstürzen (erneuter Versuch auf einem anderen Node mit mehr RAM) und nicht behebbaren (die Szenedatei selbst enthält einen Fehler, der jeden Node zum Absturz bringt). Nach einer konfigurierbaren Anzahl von Wiederholungsversuchen meldet die Farm den Fehler mit Diagnoseinformationen an den Nutzer, anstatt endlos zu wiederholen.
Datenintegrität. Gerenderte Frames werden beim Schreiben mit Prüfsummen versehen. Wenn ein Netzwerkfehler einen Frame während des Transfers zum Speicher beschädigt, löst die Prüfsummen-Diskrepanz ein automatisches Neu-Rendering aus. Das ist besonders wichtig bei EXR-Dateien, bei denen ein einziges beschädigtes Byte sichtbare Artefakte beim Compositing erzeugen kann.
Renderfarm-Software-Stack
Die Software, die all das koordiniert, ist ebenso kritisch wie die Hardware.
Render-Manager. Speziell entwickelte Render-Management-Software übernimmt Job-Scheduling, Node-Zuweisung und Farm-Administration. Diese Systeme sind auf die spezifischen Anforderungen von verteiltem Rendering ausgelegt — Frame-basiertes Dependency-Tracking, Engine-Versionsverwaltung pro Node und Multi-User-Ressourcenzuweisung.
Szenenanalyse-Tools. Bevor ein Job in die Render-Warteschlange kommt, parsen Analyse-Tools die Szenedatei, um Abhängigkeiten zu identifizieren, Ressourcenanforderungen abzuschätzen und häufige Fehler zu prüfen. Diese Tools sind Engine-spezifisch — ein V-Ray-Szenenanalysetool prüft andere Probleme als ein Blender Cycles-Analysetool.
Versionsverwaltung. Eine professionelle Farm betreibt mehrere Versionen jeder Render-Engine gleichzeitig. Ein Nutzer braucht vielleicht V-Ray 6 für ein älteres Projekt, während ein anderer V-Ray 7 benötigt. Die Software-Infrastruktur der Farm stellt sicher, dass jeder Node die korrekte Engine-Version für seinen zugewiesenen Job lädt und zwischen Versionen wechselt, wenn verschiedene Jobs durchlaufen.
Monitoring-Dashboards. Farm-Betreiber nutzen Echtzeit-Dashboards, die Node-Status, Warteschlangentiefe, aktive Jobs, Fertigstellungsraten und Fehlerhäufigkeiten anzeigen. Diese Dashboards ermöglichen schnelle Reaktionen auf Probleme — wenn Fehlerquoten bei einer bestimmten Node-Gruppe ansteigen, kann der Betreiber sofort nachforschen, anstatt das Problem erst Stunden später zu entdecken.
Wie sich vollständig verwaltete Farms von Self-Service-Plattformen unterscheiden
Nicht alle Renderfarms funktionieren gleich. Die zwei Hauptkategorien — vollständig verwaltet und Self-Service — handhaben die Pipeline unterschiedlich.
Vollständig verwaltete Farms (wie Super Renders Farm) übernehmen den gesamten technischen Stack. Du lädst eine Szene hoch, wählst deine Einstellungen, und die Farm kümmert sich um alles: Software-Installation, Versionsverwaltung, Plugin-Kompatibilität, Fehlerbehebung und Ausgabe-Lieferung. Du musst dich auf keinem Rechner per Remote-Desktop einloggen oder Infrastruktur verwalten. Das ist wichtig, weil die Konfiguration von Render-Engines komplex ist — allein V-Ray hat Dutzende versionsspezifische Einstellungen, die die Farm-Kompatibilität beeinflussen.
Self-Service- oder IaaS-Plattformen vermieten dir virtuelle Maschinen mit vorinstallierter Rendering-Software. Du verbindest dich per Remote-Desktop, konfigurierst die Software selbst, verwaltest deine eigene Render-Warteschlange und kümmerst dich um die Fehlerbehebung. Das gibt mehr Kontrolle, erfordert aber deutlich mehr technisches Wissen und Zeitaufwand.
Einen detaillierten Vergleich findest du in unserem Leitfaden: Managed vs. DIY Cloud Rendering.
Die Kostenstruktur hinter Renderfarm-Preisen
Zu verstehen, wie Renderfarms funktionieren, bedeutet auch zu verstehen, wofür du bezahlst.
Ressourcenbasierte Preise. Die meisten Farms berechnen nach verbrauchten Rechenressourcen — GHz-Stunden für CPU-Rendering oder OBs (Recheneinheiten) für GPU. Du kannst die Kosten vorab schätzen, zum Beispiel mit unserem Kostenrechner. Das bedeutet, deine Kosten skalieren linear mit dem Ressourcenverbrauch deines Jobs. Ein 10-Minuten-Frame auf einem Node kostet gleich viel, egal ob die Farm 10 oder 1.000 andere Jobs gleichzeitig verarbeitet — du zahlst für das, was du verbrauchst.
Infrastruktur-Overhead. Der Preis pro GHz-Stunde einer Renderfarm beinhaltet nicht nur den Strom für die CPU, sondern auch amortisierte Hardware-Kosten, Speicherinfrastruktur, Netzwerkbandbreite, Software-Lizenzen (Farm-Lizenzen für Render-Engines sind teuer), Kühlung, Redundanz und das Engineering-Team, das alles am Laufen hält. Ein wesentlicher Teil der Kosten deckt die Zuverlässigkeits- und Komfortschicht, die dir erspart, diese Infrastruktur selbst zu verwalten.
Prioritätszuschläge. Höhere Priorität kostet mehr, weil sie Zugang zu mehr Nodes gleichzeitig gewährt, was bedeutet, dass andere Jobs Ressourcen abgeben. Das ist ein bewusster Kompromiss — dringende Deadlines rechtfertigen den Aufpreis.
Eine umfassende Preisübersicht findest du in unserem Renderfarm-Preisleitfaden.
Zusammenfassung: Die Renderfarm-Pipeline
Die vollständige Pipeline, von der Einreichung bis zur Lieferung:
- Upload — Szenedatei und Abhängigkeiten werden auf den Farm-Speicher übertragen
- Validierung — Abhängigkeiten geprüft, Render-Einstellungen verifiziert, Kosten geschätzt
- Warteschlange — Job tritt in prioritätsbasierte Warteschlange ein, wartet auf Node-Zuweisung
- Verteilung — Szenendaten werden zugewiesenen Rendernodes über Netzwerkspeicher bereitgestellt
- Rendering — CPU- oder GPU-Nodes verarbeiten zugewiesene Frames parallel
- Qualitätsprüfung — jeder Frame wird validiert (Dateigröße, Auflösung, Inhalt)
- Zusammenstellung — Frames organisiert, Kacheln zusammengefügt falls nötig
- Lieferung — fertige Frames stehen über CDN-beschleunigten Speicher zum Download bereit
Jeder Schritt hat Fehlermöglichkeiten, und jeder Fehlermodus hat eine automatische Wiederherstellung. Das Ergebnis ist ein System, das deine Szenedateien zuverlässig in gerenderte Frames umwandelt — mit Geschwindigkeiten, die keine einzelne Workstation erreichen kann.
FAQ
Q: Wie lange braucht eine Renderfarm für einen typischen Animationsjob? A: Das hängt von der Frame-Komplexität und Prioritätsstufe ab. Eine 500-Frame-Architekturvisualisierungs-Animation in 1080p mit V-Ray wird auf einer Farm typischerweise in 2–6 Stunden fertig, im Vergleich zu 3–7 Tagen lokal. GPU-beschleunigte Jobs (Redshift, Cycles) sind oft schneller pro Frame, aber durch VRAM bei komplexen Szenen begrenzt.
Q: Was passiert, wenn ein Rendernode während meines Jobs abstürzt? A: Der Warteschlangenmanager der Farm erkennt den Ausfall innerhalb von Sekunden und weist den laufenden Frame einem intakten Node zu. Keine Frames gehen verloren. Wenn der Absturz durch einen Szenenfehler verursacht wurde (nicht durch Hardware), versucht das System es auf einer anderen Node-Konfiguration erneut, bevor es als nutzerseitiges Problem gekennzeichnet wird.
Q: Muss ich Rendering-Software selbst auf der Farm installieren? A: Bei vollständig verwalteten Farms wie Super Renders Farm, nein. Wir warten alle unterstützten Render-Engines (V-Ray, Corona, Arnold, Redshift, Cycles und andere) auf unserer gesamten Node-Flotte, einschließlich mehrerer Versionen für Kompatibilität. Self-Service-Plattformen erfordern möglicherweise, dass du die Software-Installation selbst verwaltest.
Q: Kann eine Renderfarm Szenen verarbeiten, die den VRAM meiner lokalen GPU übersteigen? A: Ja. CPU-Rendernodes auf unserer Farm haben 96–256 GB RAM, womit sie Szenen bewältigen, die eine Workstation-GPU überfordern würden. Für GPU-spezifische Engines bieten unsere RTX 5090-Nodes 32 GB VRAM — mehr als die meisten Desktop-GPUs. Szenen, die selbst das übersteigen, werden automatisch an CPU-Nodes weitergeleitet.
Q: Wie geht die Farm mit verschiedenen Render-Engine-Versionen um? A: Professionelle Farms betreiben mehrere Versionen jeder Engine gleichzeitig. Wenn du einen Job einreichst, ordnet das System die Engine-Version deiner Szene kompatiblen Nodes zu. Wenn du deine Szene in V-Ray 6 gespeichert hast, wird sie auf V-Ray 6-Nodes gerendert — nicht auf V-Ray 7, das Einstellungen möglicherweise anders interpretiert.
Q: Sind meine Szenendaten auf einer Renderfarm sicher? A: Seriöse Farms nutzen verschlüsselte Übertragungen (TLS/SSL für Upload und Download), zugriffskontrollierten Speicher (deine Dateien sind von anderen Nutzern isoliert) und automatische Löschung von Szenendaten nach einer Aufbewahrungsfrist. Auf unserer Farm werden Szenedateien nach Jobabschluss plus einem konfigurierbaren Aufbewahrungsfenster automatisch gelöscht.
Q: Welche Dateiformate sollte ich beim Einreichen an eine Renderfarm verwenden?
A: Verwende das native Format deiner DCC-Software (.max für 3ds Max, .blend für Blender, .ma/.mb für Maya). Für die Ausgabe wähle EXR für Compositing-Workflows oder PNG für die Auslieferung. Rendere immer als Bildsequenzen, nicht als Videodateien — wenn ein Frame fehlschlägt, muss nur dieser Frame neu gerendert werden.
Q: Wie gehen Renderfarms mit Plugin-Abhängigkeiten wie Forest Pack oder Scatter um? A: Verwaltete Farms halten gängige Plugins auf ihrer gesamten Node-Flotte bereit. Wenn du eine Szene mit Forest Pack einreichst, stellt die Farm sicher, dass die deinem Job zugewiesenen Nodes die korrekte Forest Pack-Version installiert haben. Weniger verbreitete Plugins erfordern möglicherweise eine Vorabmeldung, damit die Farm sie vor deinem Job bereitstellen kann.
Weiterführende Lektüre
- Was ist eine Renderfarm? — grundlegender Leitfaden zu Renderfarm-Konzepten
- Renderfarm-Preisleitfaden — wie Preismodelle in der Branche funktionieren
- Cloud vs. lokales Rendering — wann Farm-Rendering im Vergleich zu lokalem Rendering sinnvoll ist
- Autodesk Knowledge Network — verteiltes Rendering — offizielle 3ds Max-Dokumentation zum verteilten Rendering
- Blender-Handbuch — Render-Ausgabe — Blender Render-Ausgabe-Konfiguration
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



