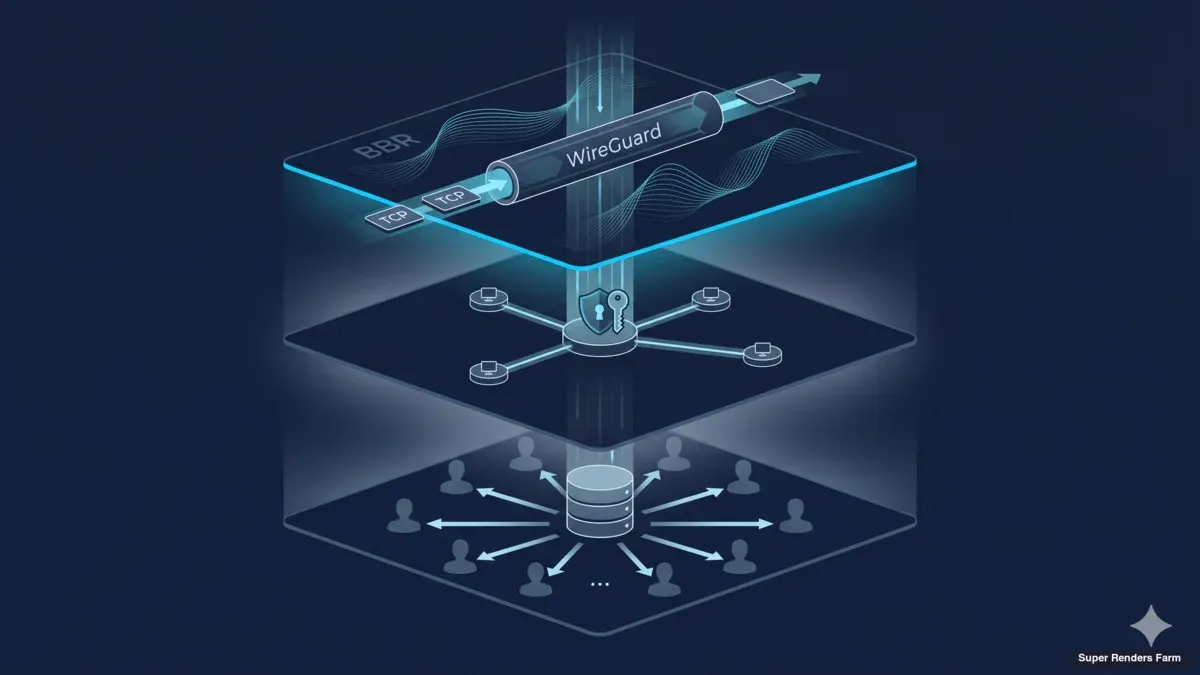
Kiến trúc render farm cross-country: WireGuard, BBR và thiết kế cache SMB chia sẻ
Tổng quan
Giới thiệu
Xây dựng một render farm sống trong một rack, một phòng, một switch là vấn đề đã được giải quyết. Đường cáp ngắn, thời gian round-trip đo bằng microsecond, và thư viện asset nằm trên một NAS mà mọi worker có thể đọc với tốc độ switch port. Phần lớn hướng dẫn render farm âm thầm giả định topology này, vì đó là topology mà mọi thứ chỉ việc chạy.
Kiến trúc thay đổi khi render farm phải trải dài qua hơn một địa điểm. Một cluster 20 node chia giữa hai vị trí trong cùng một khu đô thị đã là một bài toán mạng khác; một cluster trải dài qua các quốc gia lại là một bài toán khác nữa. Thời gian round-trip kéo từ dưới một millisecond lên hàng chục hoặc hàng trăm millisecond, jitter trên các tuyến ISP công cộng trở thành tiếng ồn nền liên tục, MTU giữa bất kỳ hai endpoint nào trở thành câu hỏi thay vì giả định, và thư viện asset trước đây sống trên một NAS bây giờ phải hoặc được replicate đến từng site hoặc được cache theo nhu cầu. Cách tiếp cận ngây thơ — cùng NAS, cùng hàng đợi submission, cùng SMB share, chỉ là cáp dài hơn — xuất hiện dưới dạng các chế độ lỗi im lặng: session kết nối và duy trì kết nối nhưng không bao giờ chuyển một frame nào, render submission treo ở 99 phần trăm vì cú push asset cuối cùng đến node remote bị timeout, license check-out thành công cục bộ và thất bại từ xa không vì lý do rõ ràng.
Bài viết này mô tả kiến trúc chúng tôi vận hành cho các triển khai render farm cross-country — topology WireGuard hub-and-spoke, TCP BBR congestion control, kỷ luật MSS clamping, một lớp cache SMB3 chia sẻ và một bề mặt firewall đã được hardening. Các thành phần là phổ biến, các lựa chọn cấu hình không phải lúc nào cũng hiển nhiên, và các bài học chủ yếu khiến chúng tôi mất thời gian debug trước khi khiến ai đó mất tiền. Đối tượng độc giả là kiến trúc sư hạ tầng và kỹ sư DevOps đang dimensioning một build tương tự, cộng với những người ra quyết định IT muốn biết team của họ đang dấn thân vào việc gì. Để có hướng dẫn vận hành từng bước cho cùng stack này, operational deployment guide của chúng tôi bao quát trình tự rollout từng ngày. Để có cái nhìn tổng quan cao hơn, trang cross-country render farm overview bao quát business case.
Topology WireGuard hub-and-spoke

Tunnel mã hóa kết nối hai site cách xa nhau
Lớp transport của cluster là WireGuard. Chúng tôi dùng nó cả cho kết nối client (workstation của artist đến render farm) và cho liên kết site-to-site giữa datacenter chính và site thứ cấp. Topology là hub-and-spoke: một server WireGuard chạy trên gateway datacenter chính, mỗi client peer kết nối vào hub đó, và site thứ cấp kết nối như một peer khác với một subnet được route phía sau.
Sức hấp dẫn của WireGuard cho loại build này phần lớn mang tính cơ học. Giao thức dùng cryptography hiện đại cố định (Curve25519 cho key exchange, ChaCha20-Poly1305 cho data plane, BLAKE2s cho hashing), chạy trong Linux kernel thay vì userspace, và cấu hình với một file key-and-allowedips vừa một màn hình. So với OpenVPN, bề mặt cấu hình nhỏ hơn khoảng một bậc độ lớn, throughput trên một node Xeon điển hình cao hơn vài lần với cùng chi phí CPU, và codebase đủ nhỏ để audit khả thi. So với IPsec, không có giai đoạn IKE negotiation có thể thất bại theo những cách thú vị, không có điệu nhảy peer-identity khi rekey, và không có daemon userspace có thể crash. Chúng tôi đã vận hành cả ba trong các triển khai trước; các cấu hình WireGuard là những cấu hình trụ vững không cần can thiệp.
Bố trí hub-and-spoke có nghĩa là mọi luồng site-to-site đều đi qua gateway datacenter chính. Với triển khai cross-country hai site, đây là trade-off đúng: tập trung bề mặt tấn công IP công cộng vào một box, áp dụng một bộ quy tắc routing và firewall tại một điểm thắt cổ chai, và làm cho monitoring trực tiếp vì mọi handshake và flow counter đều hiển thị tại hub. Full mesh sẽ tiết kiệm một hop cho lưu lượng site-to-site nhưng nhân công việc cấu hình và bề mặt tấn công công cộng lên bình phương số site. Với hai hoặc ba site, hub-and-spoke thắng về sự đơn giản vận hành.
Hub lắng nghe trên cổng UDP 51820 (mặc định), và đó là cổng duy nhất giao diện công cộng chấp nhận. Không có TCP fallback. Chỉ-UDP là cố ý — hành vi congestion của WireGuard được xây dựng quanh UDP datagram, và một tunnel TCP-over-TCP làm suy giảm throughput đường dài một cách đáng tin cậy. Trên các mạng chặn UDP hoàn toàn, chúng tôi coi đó là ràng buộc bên phía khách hàng và đi vòng ở lớp khác.
Mỗi client peer được cấu hình với một entry AllowedIPs duy nhất bao phủ subnet nội bộ của cluster. Peer site-to-site có AllowedIPs bao phủ subnet LAN remote để kernel biết encapsulate những gói nào. PersistentKeepalive được đặt ở 25 giây trên mỗi peer ở sau NAT, giữ entry UDP conntrack sống giữa các handshake. Chúng tôi đã bỏ qua điều này đúng một lần và đã dành hai ngày sau đó debug «kết nối rớt mỗi 90 giây trên site thứ cấp»; ở site thứ ba, PersistentKeepalive là dòng đầu tiên của file config.
TCP BBR congestion control
Khi tunnel WireGuard đã lên, lớp tiếp theo là hành vi TCP. Linux mặc định dùng CUBIC làm thuật toán congestion control. CUBIC scale congestion window theo đường cong bậc ba như một hàm của thời gian kể từ lần mất gói cuối, hoạt động tốt trên các link mà mất gói là tín hiệu congestion đáng tin cậy. Bẫy nằm ở từ "đáng tin cậy". Trên các tuyến ISP đường dài, mất gói thường không phải congestion chút nào — đó là tràn queue trên router trung gian, một link không dây retransmit vô hình với TCP, một rate-limiter cấu hình sai, hoặc một transient routing. CUBIC coi tất cả những điều này là congestion và sụp đổ window ngay cả khi bottleneck còn dư nhiều dung lượng.
BBR (Bottleneck Bandwidth and Round-trip propagation time) là thay thế chúng tôi dùng trên các link cross-country. BBR bỏ qua mất gói như tín hiệu congestion chính và thay vào đó đo trực tiếp băng thông bottleneck và RTT tối thiểu của đường truyền. Sau đó nó pace sender ở tốc độ bottleneck, với window có kích thước giữ chính xác một bandwidth-delay product dữ liệu trong flight. Trên long fat network — băng thông cao, RTT cao, mất gói ngẫu nhiên vừa phải — BBR giữ pipe đầy nơi CUBIC sẽ chia đôi window liên tục cho các mất gói không-congestion.
Hiệu quả thực tế trên render farm là đo được. Truyền asset qua tunnel cross-country, trên cùng phần cứng, chuyển từ throughput nhấp nhô với stall thường xuyên dưới CUBIC sang đường cong throughput mượt hơn gần dung lượng thực của đường truyền dưới BBR. Các con số headline thay đổi theo tuyến ISP và thời điểm trong ngày, nhưng chuyển phía sender của cluster sang BBR đã liên tục tạo ra throughput steady-state cao hơn và tail latency ngắn hơn trên các tuyến chúng tôi vận hành.
Chúng tôi dùng implementation BBR đã có trong Linux kernel mainline từ phiên bản 4.9, kích hoạt bằng sysctl một dòng: net.core.default_qdisc=fq cộng net.ipv4.tcp_congestion_control=bbr. Cả hai dòng đi vào /etc/sysctl.d/99-bbr.conf và sống sót qua reboot. BBR kernel mainline là phiên bản chúng tôi đã vận hành production trong nhiều năm. Các nhánh nghiên cứu mới hơn của thuật toán tồn tại nhưng giới thiệu các thay đổi hành vi mà chúng tôi chưa có thời gian validate trên các tuyến ISP cụ thể của mình; con đường upgrade là một mục roadmap riêng.
BBR được đặt ở phía sender của bất kỳ luồng lớn nào — cache box và render manager cho việc truyền asset, phía receiver cho bất kỳ luồng ngược nào như license callback và log shipping. BBR ở một đầu đủ để thấy phần lớn lợi ích; BBR ở cả hai đầu giúp thêm một chút trên các luồng hai chiều.
TCP MSS clamping
Trong tất cả các vấn đề mạng xuất hiện sau khi tunnel WireGuard lên, vấn đề tốn nhiều thời gian debug nhất của chúng tôi: MTU. Triệu chứng nhất quán và rối: gói nhỏ đi qua sạch sẽ (ping kích thước mặc định hoạt động, SSH echo ký tự, handshake WireGuard hoàn thành), nhưng gói lớn biến mất trong tunnel và không bao giờ ra. TLS handshake treo nửa chừng. Session SMB kết nối, thất bại ở lần read lớn đầu tiên. Session RDP thiết lập, hiện màn hình đăng nhập, đóng băng ngay khi người dùng gõ gì đó. License server checkout token nhỏ và timeout với token lớn.
Nguyên nhân là overhead encapsulation của tunnel WireGuard làm giảm MTU hiệu dụng xuống dưới path MTU mà các endpoint thương lượng dựa trên giao diện LAN của chúng. WireGuard thêm 60 byte overhead (20 IPv4 + 8 UDP + 32 WireGuard) cho mỗi gói. Một payload 1500 byte ở phía LAN trở thành gói 1560 byte ở phía công cộng, bị fragment hoặc drop tùy đường truyền. Path MTU Discovery (PMTUD) phải vá điều này bằng cách gửi ICMP «Fragmentation Needed» về sender, nhưng PMTUD bị hỏng trên internet hiện đại một cách thường xuyên — ICMP thường bị filter ở upstream của sender, tín hiệu «dùng gói nhỏ hơn» không bao giờ đến, và tunnel drop các gói lớn một cách im lặng.
Giải pháp là TCP MSS (Maximum Segment Size) clamping. Chúng tôi cấu hình giao diện WireGuard phía router để viết lại tùy chọn MSS trong mọi TCP SYN đi qua tunnel, giới hạn ở MTU hiệu dụng của tunnel trừ overhead TCP/IP. Với MTU tunnel 1420 byte (lựa chọn an toàn sống sót qua phần lớn biến động upstream), MSS clamp là 1380. Bất kỳ kết nối TCP nào bắt đầu sau khi rule có hiệu lực sẽ thương lượng MSS 1380 byte, sender phát ra gói 1420 byte đi qua sạch, và các drop im lặng dừng lại.
Clamp đi trên chain FORWARD của host WireGuard chế độ router, trên giao diện wg0, áp dụng cho các gói TCP handshake. Idiom iptables là iptables -t mangle -A FORWARD -o wg0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu (hoặc --set-mss 1380 cho giá trị cố định). nftables có tương đương. Rule cần áp dụng cả hai chiều nếu cả hai phía đều khởi tạo kết nối TCP, mà trên render farm là trường hợp thường gặp.
Không có cách nào để cảm nhận MSS clamp đang thiếu cho đến khi một thứ gì lớn thất bại — workload nhỏ test sạch. Clamp là một trong những cấu hình không tốn gì khi áp dụng đúng và tạo ra hàng giờ debug rối ren khi bỏ sót. Chúng tôi đưa nó vào checklist deployment chuẩn sau khi một ticket support lúc 6 giờ sáng về «SMB transfer treo ở kích thước ngẫu nhiên» được giải quyết lúc 8 giờ sáng bằng một rule iptables một dòng.
Thiết kế cache SMB3 chia sẻ

Cache chia sẻ phục vụ asset cục bộ cho các render worker
Workload render nặng asset và đọc-trội. Một scene điển hình từ vài trăm megabyte đến vài chục gigabyte — geometry, texture, simulation cache và file project của DCC rendering. Trên cluster 20 node, cùng scene phải đọc được bởi mọi worker nhận frame. Cách tiếp cận ngây thơ là copy scene đến mọi node trước khi render khởi động. Với scene 10 GB và 20 node, điều đó di chuyển 200 GB qua mạng cho một working set 10 GB. Nhân với hàng chục scene mỗi ngày mỗi studio và chi phí trùng lặp chiếm ưu thế trong build.
Kiến trúc chúng tôi dùng thay vào đó là một lớp cache chia sẻ duy nhất mỗi site, expose cho render worker qua SMB3. Cache là một box Ubuntu 22.04 LTS với một SSD đơn (cấp NVMe), format ext4, với thư mục cache expose bởi Samba qua SMB3. Mỗi render worker mount SMB share lúc boot qua cifs-utils và đọc file asset từ cache như thể chúng cục bộ. Worker đầu tiên cần một asset cụ thể kích hoạt pull từ asset store cloud upstream vào cache; các worker tiếp theo và frame tiếp theo đọc từ cache LAN ở tốc độ switch port. Mỗi site, cache box cách mỗi worker một switch hop; asset đến cluster một lần và phục vụ hai mươi worker.
Vài lựa chọn thiết kế đáng để mở ra. Cache là một SSD đơn, không phải mảng RAID, vì cache theo định nghĩa có thể rebuild từ asset store cloud upstream. Nếu SSD hỏng, trường hợp xấu nhất là độ trễ trong khi yêu cầu asset tiếp theo pull từ cloud, cộng với rebuild của bất kỳ render in-flight nào phụ thuộc vào file trung gian chưa cache. Chúng tôi giảm thiểu rủi ro «render in-flight» bằng rsync output render hoàn thành từ cache sang một NAS vào cuối mỗi job, vì vậy lỗi SSD không mất bất kỳ deliverable nào đã giao. Bỏ qua RAID tiết kiệm chi phí phần cứng, độ phức tạp controller và overhead write amplification mà một số mức RAID áp đặt lên SSD.
File system là ext4 thay vì ZFS hoặc btrfs. Chúng tôi đã dùng cả ZFS và btrfs trong các build trước, và feature set chúng mang lại (snapshot, checksumming, compression) là lợi ích thực trong một số workflow. Với cache render, pattern đọc chủ yếu tuần tự và giới hạn băng thông thay vì transactional, và nội dung cache theo thiết kế là có thể bỏ. Ext4 giữ stack storage đơn giản và loại bỏ một lớp failure mode khỏi tập postmortem sự cố. Các operator đã vận hành ZFS ở quy mô lớn hoàn toàn có thể dùng nó ở đây, nhưng với triển khai mà tính đơn giản của lớp cache quan trọng hơn lợi ích feature riêng lẻ, ext4 là lựa chọn.
Chiến lược pre-warm có ý nghĩa. Trước khi một job deadline-driven khởi động, artist hoặc pipeline TD đẩy asset của scene vào cache qua công cụ pre-staging. Frame đầu tiên rơi vào worker sau đó đọc từ cache ấm thay vì chờ cold pull. Bước pre-warm là tùy chọn cho job chạy qua đêm (cold pull ổn) và quan trọng cho job phải hoàn thành trong cửa sổ chật.
Cache sharing cross-site hoạt động qua tunnel WireGuard site-to-site. Site thứ cấp có cache box riêng và worker riêng, nhưng cache có thể đến được cache của site chính qua tunnel cho bất kỳ asset nào ấm ở đó và chưa ấm cục bộ. Trong thực tế, chúng tôi cấu hình cache thứ cấp fallback về cache chính cho miss trước khi đi đến cloud upstream — giữ lưu lượng inter-site trên tunnel mã hóa và tránh phí egress cloud cho asset đã sống bên trong render farm. Đây là một trong những lợi ích thực tế của MSS clamp đúng: các transfer asset lớn giữa các site di chuyển ở throughput bão hòa tunnel thay vì stall ở trần gói nhỏ.
Dịch vụ nội bộ: DNS và NTP
Một cluster cần biết hostname của chính nó. Lựa chọn ngây thơ là đưa từng host vào /etc/hosts trên mỗi node, hoạt động với hai node và bắt đầu thất bại với hai mươi. Lựa chọn đúng là DNS nội bộ, và chúng tôi vận hành dnsmasq trên cùng gateway box chạy WireGuard. Cluster sống trong zone .lan — cache.lan, rn-a01.lan đến rn-a20.lan, mgr.lan, nas.lan. Mỗi name resolve về IP nội bộ tương ứng trên subnet cluster, và /etc/resolv.conf của mỗi worker trỏ đến server dnsmasq.
Lợi ích là mọi reassign IP, swap host hoặc thay đổi topology yêu cầu chạm vào một file cấu hình (file hosts của dnsmasq) thay vì từng node. Lợi ích mở rộng qua tunnel site-to-site: một worker ở site thứ cấp có thể resolve cache.lan về cache thứ cấp qua dnsmasq local, và resolve mgr.lan về render manager của site chính qua DNS forwarding qua tunnel. Trong quá khứ chúng tôi đã dùng IP literal trong cấu hình render manager và hối tiếc mỗi lần một node di chuyển.
Bẫy dnsmasq cắn chúng tôi — và cắn đủ operator để xứng đáng có đoạn riêng — là dòng interface=. dnsmasq mặc định lắng nghe trên mọi giao diện, có vẻ ổn cho đến khi bạn nhận ra gateway box có ít nhất ba: WAN công cộng, LAN nội bộ và tunnel WireGuard wg0. Nếu bạn đặt interface=eth1 nghĩ rằng đang giới hạn dnsmasq vào LAN, bạn vừa làm cho site thứ cấp kết nối qua WireGuard không thể resolve bất kỳ name .lan nào, vì wg0 không được liệt kê. Dòng đúng là interface=eth1,wg0 (hoặc tương đương cho tên giao diện của bạn), hoặc dòng except-interface= chỉ đặt tên WAN. Chúng tôi đã thấy cấu hình sai này tạo ra triệu chứng «site remote có thể ping cache bằng IP nhưng không thể SMB-mount bằng hostname» nhiều hơn một lần.
NTP là dịch vụ nội bộ khác. Chúng tôi vận hành chrony trên gateway như server NTP, với chính gateway đồng bộ với pool NTP công cộng và mỗi node đồng bộ với gateway. Động lực là tương quan log render manager: nếu một frame thất bại, entry log của render manager và của worker phải chia sẻ timeline trong vòng millisecond. Clock drift trên cluster 20 node, đặc biệt khi node đã up trong nhiều tuần, trở thành nguồn thực sự của rối ren debug «entry log này không khớp». chrony giữ drift dưới vài millisecond và loại bỏ lớp rối ren đó.
Firewall: ufw với default-deny inbound
Gateway đứng trên internet công cộng, và tư thế firewall là «default-deny inbound, default-allow outbound, default-allow forward cho lưu lượng tunneled». Trên Ubuntu 22.04 LTS, công cụ chúng tôi dùng là ufw — Uncomplicated Firewall. ufw là frontend trên nftables (hoặc iptables trên hệ thống cũ hơn) expose một bề mặt lệnh nhỏ và từ chối làm điều bất ngờ. Với gateway box mà cấu hình firewall là khác biệt giữa «an toàn» và «bị compromise trong vài giờ», bề mặt lệnh nhỏ là một feature.
Bề mặt công cộng đã cấu hình là một rule: ufw allow 51820/udp comment 'wireguard'. Không có gì khác inbound. SSH từ phía công cộng đóng; chúng tôi quản trị gateway qua tunnel WireGuard từ một IP operator đã biết. SMB, DNS, NTP và HTTPS (cho UI render manager) đều chỉ trên giao diện nội bộ. Cài đặt ufw default deny incoming và ufw default allow outgoing bao quát phần còn lại của bề mặt.
Chain forward cần cẩn thận. Gateway hoạt động như router cho lưu lượng cluster giữa wg0 và LAN nội bộ, và tư thế mặc định của ufw là từ chối forward. Chúng tôi đặt DEFAULT_FORWARD_POLICY="ACCEPT" trong /etc/default/ufw và sau đó thu hẹp các rule forward về các cặp source/destination cụ thể trong chain FORWARD. Kết hợp — default-deny incoming, default-deny forward khi boot, sau đó forward ACCEPT explicit giữa các subnet cluster đã biết — cho tư thế có thể audit và không vô tình route lưu lượng giữa các site không nên nói chuyện.
Firewall host per-node mở rộng lớp Tier-1 gateway này thành lớp Tier-2 host. Mỗi node render chạy ufw cục bộ với rule chỉ cho phép render manager và cache box của cluster khởi tạo kết nối. Một worker bị compromise không thể pivot sang worker khác mà không trước tiên đánh bại firewall host, và gateway log mọi cố gắng forward bất ngờ. Mô hình hai-tier — gateway Tier 1, per-host Tier 2 — giống mô hình mà bất kỳ cluster on-prem hợp lý nào vận hành; điều thay đổi trên triển khai cross-country là bề mặt Tier 1 bây giờ phòng thủ chống lại internet công cộng. Gateway là chu vi; firewall per-host là phòng thủ chiều sâu.
Sơ đồ kiến trúc

Topology render farm hub-and-spoke, một tunnel bảo mật duy nhất ra internet
Mô tả văn bản phía trên ánh xạ vào sơ đồ ASCII sau, cũng là sơ đồ chúng tôi vẽ trên whiteboard trong các kick-off triển khai:
PUBLIC INTERNET
|
| UDP 51820 (only port open)
v
+------------------------+------------------------+
| MAIN DATACENTER |
| |
| +----------------+ +---------------+ |
| | Gateway |--LAN-->| Render Mgr | |
| | (ufw + wg0 + | | (mgr.lan) | |
| | dnsmasq + | +---------------+ |
| | chrony + BBR) | |
| +-------+--------+ +---------------+ |
| | -->| Cache | |
| | | | (cache.lan) | |
| v | | SSD ext4 SMB3| |
| +----------------+ | +-------+-------+ |
| | Worker Subnet |<----+ | |
| | rn-a01..a20 | v |
| | (Tier-2 ufw) | +---------------+ |
| +----------------+ | NAS | |
| | (archive) | |
| +---------------+ |
+------------------+------------------------------+
| WireGuard site-to-site
| (BBR + MSS clamp)
v
+------------------+------------------------------+
| SECONDARY SITE |
| |
| +----------------+ +-----------------+ |
| | Site Gateway |----->| Local Cache | |
| | (wg0 spoke) | | (falls back | |
| +-------+--------+ | to primary) | |
| | +--------+--------+ |
| v | |
| +----------------+ v |
| | Worker Subnet | (renders run |
| | rn-b01..b08 | locally; outputs |
| | (Tier-2 ufw) | ship over tunnel) |
| +----------------+ |
+-------------------------------------------------+
Sơ đồ là cố ý chung — không cặp thành phố cụ thể, không ISP cụ thể, không đánh số subnet cụ thể. Mỗi site chúng tôi triển khai theo cùng hình dạng; số liệu thay đổi.
Đặc trưng hiệu năng
Các con số throughput phụ thuộc vào tuyến ISP và thời điểm trong ngày, nhưng hình dạng hiệu năng nhất quán trên các triển khai chúng tôi đã vận hành. Trên tunnel giữa hai site cùng khu đô thị (RTT dưới 10 ms), các transfer lớn di chuyển gần line-rate trên link bottleneck, và một render worker đọc từ cache không phân biệt được với worker đọc từ đĩa local. Trên tunnel giữa các site khác quốc gia (RTT 50–150 ms tùy tuyến), các transfer lớn ổn định ở throughput pace bởi BBR gần băng thông bottleneck, với MSS clamp giữ kích thước per-segment khớp với MTU tunnel.
Đọc cache LAN local là nơi kiến trúc kiếm cơm. Một render worker đọc texture pack 4 GB từ cache.lan qua SMB3 trên LAN gigabit switched hoàn thành trong khoảng thời gian switch port đẩy bytes — hàng chục giây thay vì khoảng thời gian nhiều phút mà cold pull từ cloud storage cross-country sẽ mất. Cho một job chạm cùng texture pack qua hai trăm frame, cache hit ratio tiệm cận 1,0 sau lần đọc ấm đầu tiên, và tunnel cross-country chỉ được dùng cho pre-warm gốc, sync cross-site output site thứ cấp, và telemetry steady-state.
Với frame render 4K và 8K cụ thể, giá trị kiến trúc scale theo kích thước frame. Một sequence EXR 8K với nhiều AOV có thể đẩy output frame riêng lẻ vào hàng trăm megabyte, và 200 trong số chúng là một write hàng chục gigabyte mỗi scene. Giữ write đó trong local-LAN và chỉ ship output nén cuối cùng qua tunnel là khác biệt giữa «xong qua đêm» và «xong khi upload hoàn thành, ngày mai lúc nào đó».
Câu hỏi thường gặp
Q: Tại sao WireGuard mà không phải OpenVPN? A: Bề mặt cấu hình WireGuard nhỏ hơn, throughput data plane nhất quán cao hơn trên cùng phần cứng, implementation kernel loại bỏ một failure mode userspace, và tư thế cipher cố định loại bỏ một lớp bug negotiation. OpenVPN là công cụ vững chắc với hai mươi năm lịch sử vận hành; chúng tôi dùng WireGuard vì các thuộc tính vận hành cho tunnel cluster chạy lâu tốt hơn trên các metric chúng tôi quan tâm. Trên các tuyến UDP của WireGuard bị block hoàn toàn, OpenVPN trên TCP 443 là fallback hợp lệ — nhưng TCP-over-TCP giới thiệu pathology riêng, và chúng tôi coi đó là ràng buộc bên phía khách hàng.
Q: BBR giúp gì trên các tuyến ISP nhiễu? A: BBR dùng băng thông bottleneck và RTT như tín hiệu congestion thay vì mất gói. Trên các tuyến mất gói chủ yếu do tràn buffer router trung gian, retransmit không dây, hoặc sự kiện routing tạm thời — tức là phần lớn các tuyến ISP công cộng — BBR giữ pace sender ở băng thông thực của đường truyền thay vì chia đôi window liên tục cho các mất gói không-congestion. Hiệu quả là throughput steady-state cao hơn, tail latency ngắn hơn trên các transfer lớn, và ít sự cố «transfer dừng ba mươi giây rồi tiếp tục» trên các luồng dài.
Q: MSS clamping là gì và tại sao tôi cần? A: MSS clamping viết lại tùy chọn Maximum Segment Size trong gói TCP SYN để kích thước segment thương lượng đi qua sạch qua tunnel với MTU hiệu dụng giảm. Không có nó, các endpoint thương lượng kích thước segment dựa trên giao diện LAN (điển hình MTU 1500, MSS 1460), tunnel WireGuard không thể mang các gói đó đầy kích thước, Path MTU Discovery thất bại vì ICMP bị filter đâu đó upstream, và các gói lớn biến mất im lặng. Triệu chứng là «gói nhỏ hoạt động, gói lớn không» — ping đi qua, TLS handshake treo, SMB transfer stall giữa file. Giải pháp là một rule iptables hoặc nftables một dòng trên giao diện WireGuard phía router.
Q: Tôi có thể tự triển khai kiến trúc này, hay cần một vendor render farm?
A: Kiến trúc được xây dựng hoàn toàn từ các thành phần open source — WireGuard, implementation BBR của Linux, iptables/nftables, Samba SMB3, dnsmasq, chrony, ufw, ext4. Không có thành phần SRF-only. Một team có kỹ năng kỹ sư hạ tầng có thể tự triển khai cùng stack, và các lựa chọn cấu hình trong bài này không phải bí mật; chúng là các lựa chọn chúng tôi đã làm vì chúng hoạt động. Cái vendor mang lại là kinh nghiệm vận hành — các bẫy như dòng interface= của dnsmasq, câu chuyện khám phá MSS clamp, right-sizing SSD cache, tooling pre-warm — gói trong một playbook triển khai không yêu cầu phát hiện lại mỗi build. Một team hấp thụ đường cong kinh nghiệm đó hay mua để bỏ qua nó là câu hỏi ngân sách và thời gian.
Q: Cache hit ratio cho workflow render điển hình là bao nhiêu? A: Với workload song song theo frame mà cùng scene được render qua nhiều frame (pattern thống trị trong animation, VFX, archviz và visualization sản phẩm), cache hit ratio tiệm cận 1,0 sau lần pull ấm đầu tiên của mỗi asset. Phạt cold pull được trả một lần mỗi asset mỗi cache, và mỗi worker tiếp theo trên cùng site đọc từ cache ấm ở tốc độ LAN. Với workload chạm bộ asset khác nhau mỗi frame (hiếm, nhưng xảy ra trong một số workflow procedural), hit ratio thấp hơn và cache hoạt động giống buffer transit hơn là store dài hạn. Bước pre-warm trước job deadline-driven hiệu quả làm hit ratio bằng 1,0 cho workload đã lập kế hoạch.
Q: Kiến trúc này scale ra ngoài 20 node thế nào? A: Topology WireGuard hub-and-spoke scale tuyến tính với số peer — chi phí CPU hub là crypto per peer và routing per gói, và một gateway Xeon hiện đại có thể xử lý hàng trăm peer trước khi trở thành bottleneck. Lớp cache scale bằng cách hoặc làm lớn cache box đơn (thêm dung lượng SSD, NIC nhanh hơn) hoặc sharding qua nhiều box với chiến lược mount workload-aware. Với build trên 50 node mỗi site, chúng tôi thường thêm cache box thứ hai và chia worker giữa chúng; trên 100 node mỗi site, lớp cache trở thành thiết kế read-replica phân tán, và đó là bài khác. Bản thân tunnel cross-country không cần thay đổi kiến trúc khi cluster phát triển — pacing BBR và MSS clamp tiếp tục làm việc ở bất kỳ tốc độ flow tổng nào, miễn link ISP nền có dung lượng.
Để biết thêm chi tiết thực tế về trình tự triển khai chúng tôi dùng để dựng kiến trúc này, xem operational deployment guide của chúng tôi. Cho tư thế bảo mật phủ lên thiết kế mạng này, bài viết network segmentation security bao quát sâu hơn mô hình firewall Tier-1 và Tier-2. Và cho các edge case đã được kiểm chứng trên thực địa mà chúng tôi không phải lúc nào cũng làm đúng từ lần đầu, bài viết deployment lessons learned bao quát các failure mode cụ thể đã định hình kiến trúc này.
About Thierry Marc
3D Rendering Expert with over 10 years of experience in the industry. Specialized in Maya, Arnold, and high-end technical workflows for film and advertising.



